Command Palette
Search for a command to run...
MIT/IBM Hat ChartNet Veröffentlicht, Den Bisher Größten Synthetischen Chart-Datensatz Mit 1,5 Millionen Verschiedenen Chart-Beispielen.

In den letzten zwei Jahren hat die Entwicklung multimodaler Großmodelle die Erwartungen weit übertroffen. Von der Bilderkennung über das Verständnis komplexer Dokumente bis hin zur Videoanalyse erweitern visuelle Sprachmodelle (VLMs) kontinuierlich ihre Leistungsfähigkeit. Doch ein scheinbar einfaches, aber extrem anspruchsvolles visuelles Objekt führt nach wie vor häufig zum Versagen vieler hochentwickelter Modelle: Diagramme.
Für Menschen lassen sich Balken-, Linien- oder Streudiagramme schnell erfassen, um Trends, Vergleiche und wichtige Schlussfolgerungen zu erkennen. Für KI sind Diagramme jedoch weit mehr als nur Bilder. Modelle müssen nicht nur visuelle Elemente erkennen, sondern auch die Beziehungen zwischen Achsen, Datenpunkten, Legenden und Beschriftungen verstehen und darüber hinaus numerische Daten extrahieren, Trendanalysen durchführen und sogar Kausalzusammenhänge herstellen können. Anders ausgedrückt: Das Verständnis von Diagrammen ist eine komplexe Aufgabe, die visuelle, numerische und sprachliche Fähigkeiten erfordert, und aktuelle visuelle Lernmodelle können dies nur teilweise leisten.
In den letzten Jahren haben einige Datensätze die Entwicklung verwandter Forschungsarbeiten vorangetrieben, doch leiden sie im Allgemeinen unter drei Problemen: geringem Umfang, begrenzten Graphtypen und fehlenden vollständigen multimodalen Informationen. Viele Datensätze konzentrieren sich lediglich auf eine einzelne Aufgabe (wie die Beantwortung von Fragen oder die Beschreibung von Graphen) oder weisen Lücken in Bezug auf wichtige Modalitäten auf, sodass Open-Source-Modelle bei komplexen Aufgaben des Graph-Reasoning weiterhin hinter proprietären Systemen zurückbleiben.
Um diese Lücke zu schließen,ChartNet wurde von zahlreichen Experten des MIT, des MIT-IBM Computing Research Laboratory und von IBM Research vorgeschlagen.—Ein hochwertiger, multimodaler Datensatz mit Millionen von Datensätzen zum Verständnis von Graphen, der die Fähigkeiten zum Verständnis und zur logischen Argumentation von Graphen verbessern soll.
Dies ist der bisher größte Datensatz synthetischer Diagramme. Mithilfe eines neuartigen, codebasierten Syntheseverfahrens wurden 1,5 Millionen verschiedene Diagrammbeispiele generiert, die 24 Diagrammtypen und 6 Plotbibliotheken abdecken. Umfangreiche Experimente bestätigen die Praxistauglichkeit von ChartNet und zeigen, dass sein optimal feinabgestimmtes Modell deutlich größere Modelle und GPT-4o in allen Aufgaben übertrifft.
Nutzen Sie den Datensatz online:https://go.hyper.ai/lGPsc
Die zugehörigen Forschungsergebnisse mit dem Titel „ChartNet: Ein millionenfacher, qualitativ hochwertiger multimodaler Datensatz für ein robustes Chart-Verständnis“ werden auf der IEEE-Konferenz für Computer Vision und Mustererkennung veröffentlicht.
Forschungshighlights:
Der codebasierte Synthese- und Generierungsprozess von ChartNet ermöglicht die Erzeugung von Diagrammbeispielen in großem Umfang und erfasst gleichzeitig visuelle, strukturelle, numerische und textuelle Informationen zum Diagrammverständnis.
ChartNet integriert reale Daten und manuell gekennzeichnete Daten und beinhaltet eine spezialisierte Teilmenge, die visuelles Zeigen und Sicherheitsanalyse unterstützt, wodurch der Wert von Datensätzen beim Modelltraining und der Evaluierung erweitert wird.
Durch Feinabstimmung anhand dieses Datensatzes kann die Leistung des visuellen Sprachmodells bei Aufgaben wie der Rekonstruktion von Diagrammen, der Datenextraktion und der Zusammenfassung von Diagrammen kontinuierlich verbessert werden.

Papieradresse:
https://hyper.ai/papers/2603.27064
Datensatz: Besteht aus 1,5 Millionen multimodal ausgerichteten synthetischen Proben
Der ChartNet-Kerndatensatz besteht aus 1,5 Millionen multimodal ausgerichteten synthetischen Stichproben.Jedes Beispiel umfasst: ein Diagrammbild, den zugehörigen Code, tabellarische Daten, eine Beschreibung in natürlicher Sprache sowie ein Frage-Antwort-Paar mit verketteter Argumentation (CoT). Eine vollständige Übersicht der verwendeten Datenattribute, Diagrammtypen und Visualisierungsbibliotheken ist in der folgenden Abbildung dargestellt:
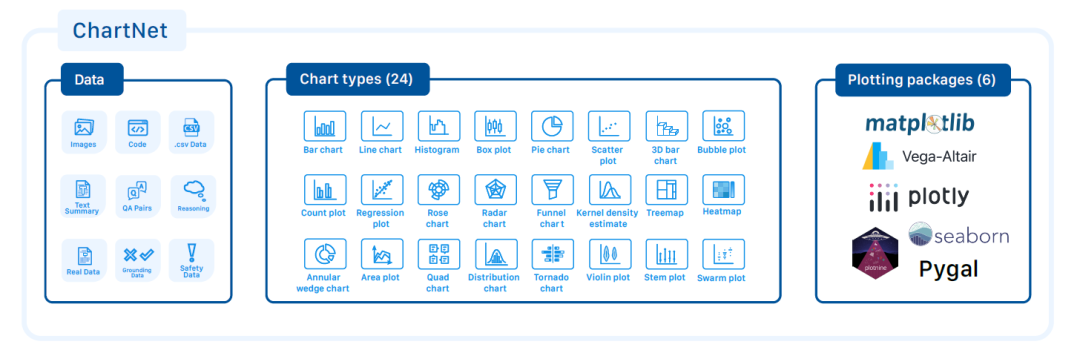
Um das gesamte Spektrum der Möglichkeiten zum Verständnis von Graphen abzudecken, enthält ChartNet auch mehrere spezialisierte Teilmengen: manuell beschriftete Daten, Graphen aus der realen Welt, Referenzdaten und Sicherheitsdaten.
Manuell beschriftete zusammengesetzte Diagrammdaten:Es enthält 96.643 ausgerichtete synthetische Diagrammbilder, Beschreibungen und Tabellendaten, die alle einer strengen menschlichen Validierung und Annotation unterzogen wurden.
Hochwertige, praxisnahe Diagrammdaten:Zur Ergänzung des synthetischen Diagrammkorpus trugen die Forschenden 30.000 reale Diagramme aus renommierten internationalen Medien und Datenvisualisierungsorganisationen wie der Weltbank, Bain & Company, dem Pew Research Center, Our World in Data und anderen weltweit bekannten Verlagen zusammen und annotierten diese. Die Sammlung deckt ein breites Spektrum aktueller Themen ab, darunter Wirtschaft, Technologie, Geopolitik, Umweltwissenschaften und soziale Trends, und gewährleistet dabei eine hohe Datenvielfalt und starke Praxisrelevanz. Diagramme mit geringem Informationsgehalt oder mangelhafter Qualität wurden explizit entfernt, um die Interpretierbarkeit sicherzustellen.
Fundierte Qualitätssicherung auf Datenbasis:Moderne visuelle Modellierung (VLM) hat nach wie vor Schwierigkeiten, Diagrammbereiche und syntaktische Elemente zu identifizieren, die für spezifische Fragestellungen relevant sind. Um diese Fähigkeit zu verbessern, entwickelten Forscher ein Frage-Antwort-Paar zur Diagrammgrundlage. Zunächst extrahierten sie geometrisch fundierte Annotationen aus den Plotcode-Elementen (Achsen, Teilstriche, Gitternetzlinien, Legenden und Grafikblöcke), um dichte Diagrammgrundlagen-Annotationen zu generieren. Mithilfe einer entropiebasierten Methode wurden die Begrenzungsrahmen weiter gefiltert. Anschließend wurde anhand der generierten Grundlagen-Annotationen für jedes Diagramm ein Satz von standardisierten Fragen und Antworten erstellt, um die Übereinstimmung zwischen dem erwarteten räumlichen Layout der visuellen Elemente und dem tatsächlichen Inhalt des Diagramms zu erfassen.
Der erwartete Ort wird mithilfe einer serialisierten Begrenzungsrahmendarstellung in die Antwortzeichenkette kodiert. Vorlagen umfassen einzigartige und wiederkehrende visuelle Elemente und kombinieren Indizes, Textbeschriftungen im Diagramm sowie visuelle Attribute wie die Elementfarbe, um Zitatausdrücke zu generieren. Der Generator unterstützt sowohl kurze als auch lange Antworten und kann optional Begründungsinformationen enthalten. Der endgültige Datensatz generiert ein Frage-Antwort-Paar pro Diagramm, indem alle Vorlagentypen und Ausgabemodalitäten gleichmäßig abgetastet werden. Zusätzlich werden mithilfe von gpt-oss-120b inferenzbasierte Begründungs-Frage-Antwort-Paare generiert.
Sicherheitsdaten:Um Sicherheitsbedenken zu begegnen, erweiterten die Forscher den Datengenerierungsprozess, um sicherheitskonforme, diagrammbezogene Daten zu erzeugen. Dadurch wurden schädliche Inhalte in der Modellausgabe und das Risiko eines „Jailbreakings“ reduziert.
Die Kernidee von ChartNet: Codegestützte Synthese von Diagrammen zur automatischen Generierung.
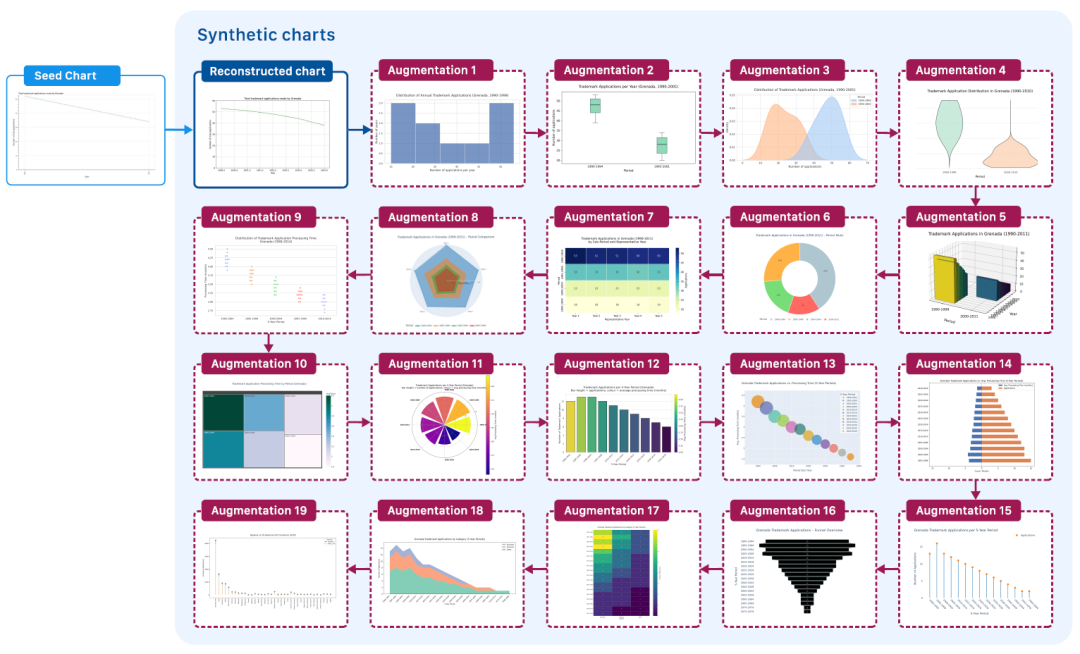
Die Grundidee der ChartNet-Datengenerierung besteht darin, Diagramme programmatisch zu erstellen, wobei ausführbarer Code als strukturierte Zwischenrepräsentation für die Datenvisualisierung dient. Forscher haben einen umfangreichen, codebasierten Prozess zur automatisierten Diagrammgenerierung vorgeschlagen (siehe Abbildung unten). Dieser Prozess beginnt mit einer begrenzten Menge an Diagrammbilddaten („Seeds“) und verwendet ein visuelles Sprachmodell (VLM), um Code zu generieren, der diese Diagramme annähernd rekonstruieren kann.
Codegestützter Diagrammerweiterungsprozess
Im Einzelnen umfasst der Datengenerierungsprozess die folgenden Phasen:
① Rekonstruktion von Diagrammen zu Code:VLM wird verwendet, um Python-Code für die Darstellung von Diagrammen zu generieren, mit dem sich ein gegebener Satz von Diagrammbildern annähernd rekonstruieren lässt. In diesem Schritt werden 150.000 eindeutige Diagrammbilder aus dem TinyChart-Datensatz als Ausgangspunkte ausgewählt, der Prozess ist jedoch nicht von dieser Auswahl abhängig.
② Codegestützte Diagrammerweiterung:Der generierte Plotcode dient als Eingabe und wird mithilfe eines Large Language Model (LLM) iterativ umgeschrieben. Dabei bleiben die zugrundeliegenden Datenwerte und Beschriftungen im Vergleich zur vorherigen Iteration erhalten, um sie besser an den gewünschten Diagrammtyp anzupassen. Die Abbildung unten veranschaulicht die iterative Codeverbesserung und den Diagrammrendering-Prozess. Dieser Schritt ist entscheidend für die Skalierung des Datensatzes, da jedes Ausgangsbild beliebig viele Varianten generieren kann.
③ Diagrammdarstellung:Führen Sie den gesamten generierten Plotcode aus, um Diagrammbilder zu erzeugen. Erfolgreich ausgeführte Skripte werden mit den entsprechenden generierten Bildern verknüpft.
④ Qualitätsfilterung:Jedes Diagrammbild wird mithilfe von VLM ausgewertet, um verschiedene potenzielle Darstellungsfehlerkategorien (wie Textüberlappung, Beschneidung von Beschriftungen, Verdeckung von Diagrammelementen usw.) zu erkennen. Bilder mit visuellen Problemen und deren Plotcode werden entfernt.
⑤ Codebasierte Attributgenerierung:Abschließend wird VLM verwendet, um zusätzliche semantische Attribute für die Diagrammbild-Code-Paare zu generieren. Datenwerte und Beschriftungen werden aus dem Diagramm im Kontext des Codes extrahiert und in einer tabellarischen Darstellung dargestellt. Durch die Kombination von visuellen Informationen, Code und tabellarischen Daten wird zudem eine fundierte Diagrammbeschreibung erstellt.
Es führt zu signifikanten und beständigen Verbesserungen bei allen Aufgaben des Graphenverständnisses.
Um die Effektivität von ChartNet bei der Verbesserung der Fähigkeit des Modells, Diagramme zu verstehen, zu überprüfen, trainierten die Forscher visuelle Sprachmodelle unterschiedlicher Größe mit dem ChartNet-Datensatz, darunter ultrakompakte (≤1B Parameter), kleine (≤4B Parameter) und mittlere (≤7B Parameter).
Insgesamt führt die Feinabstimmung anhand des ChartNet-Datensatzes zu signifikanten und konsistenten Verbesserungen bei allen Aufgaben des Diagrammverständnisses (siehe Tabelle unten) – die Einheitlichkeit und das Ausmaß dieser Verbesserungen sind unabhängig von der Modellgröße.Dies beweist, dass es den bestehenden VLMs an Möglichkeiten für ein qualitativ hochwertiges multimodales graphenüberwachtes Training mangelt, während ChartNet diese Lücke effektiv schließt.
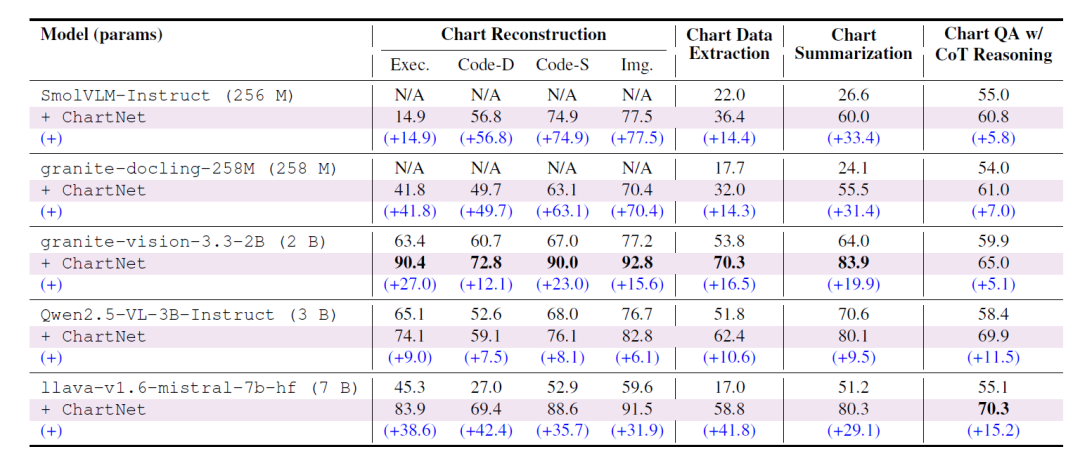
① Rekonstruktion des Diagramms
Modelle, die mit dem Chart-to-Code-Teildatensatz trainiert wurden, erzielten signifikante Verbesserungen hinsichtlich Codeausführungsrate, Datenkonsistenz, Struktur-/Codeähnlichkeit und Bildähnlichkeit: Ultrakompakte Modelle (SmolVLM-256M, Granite-Docling-258M), die zuvor überhaupt keine Diagramme rekonstruieren konnten, verfügen nun über die volle Funktionalität; kleinere Modelle (wie Granite-Vision-2B) erreichten eine nahezu perfekte Rekonstruktion, wobei mehrere Metriken 90% überstiegen; das Modell LLaVA-7B erzielte eine Verbesserung der Datenkonsistenz um bis zu +42,4 Punkte. Dieser skalenunabhängige Trend deutet darauf hin, dass die multimodale Ausrichtung von ChartNet zwischen Bildern und Code dem Modell eine strukturierte Überwachung bietet, die im Datensatz zuvor fehlte.
② Diagrammdatenextraktion
ChartNet verbessert die Fähigkeit aller Modelle, numerische Tabellen direkt aus Diagrammen zu extrahieren, deutlich. Granite-Vision-2B erzielt dabei mit 70,31 TP3T die beste Leistung. Das optimierte LLaVA-7B zeigt eine Leistungssteigerung von +41,8 Punkten und übertrifft damit alle Open-Source-Vergleiche sowie sogar GPT-4o (nur 46,71 TP3T). Dies verdeutlicht den Wert der engen Verknüpfung von ChartNet zwischen codegenerierten Diagrammen und CSV-Daten, wodurch das Modell sowohl auf die visuelle Geometrie als auch auf die zugrunde liegende numerische Struktur zugreifen kann.
③ Zusammenfassung der Diagramme
Die Qualität der Zusammenfassungen aller Modellfamilien verbesserte sich signifikant, mit Steigerungen von +9,5 (Qwen2.5-VL-3B) bis +31,4 (Granite-Docling-2B). Das optimierte Granite-Vision-2B erreichte 83,91 TP3T und übertraf damit GPT-4o sowie alle Open-Source-Baselines in Tabelle 3, einschließlich Modelle mit einer um eine Größenordnung größeren Parameteranzahl. Dies belegt, dass die synthetische Zusammenfassung von ChartNet (gemeinsam aus Code und gerenderten Diagrammen erstellt) strukturierte und semantisch vollständige Überwachungssignale für das deskriptive Diagrammverständnis liefert.
④ Fragen und Antworten mit CoT-Argumentation
Bei komplexen, mehrstufigen Inferenzaufgaben zeigte jedes Modell eine stetige Verbesserung der Genauigkeit – LLaVA-7B zeigte die größte Verbesserung (+15,17) und erreichte 70,3%, womit es das spezielle Chart-Inferenzmodell ChartGemma und alle vergleichbaren oder größeren Open-Source-Modelle (einschließlich GPT-4o) übertraf.
⑤ Vergleich mit handelsüblichen Modellen
Die folgende Tabelle zeigt, dass das mit ChartNet feinabgestimmte Modell das Standardmodell mit größeren Parametern in nahezu allen Metriken übertrifft. Nach der Feinabstimmung erzielen die Modelle mit 2 Milliarden bzw. 7 Milliarden Parametern durchweg bessere Ergebnisse als Modelle mit 20 bis 72 Milliarden Parametern. Insbesondere bei Aufgaben wie der Rekonstruktion von Diagrammen und der Datenextraktion ist das mit ChartNet feinabgestimmte Modell GPT-4o deutlich überlegen.
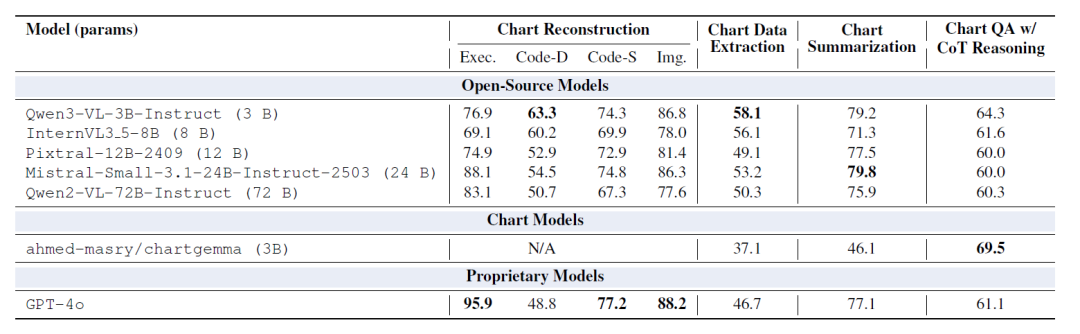
Dies legt nahe, dass in Bereichen, in denen Bildverarbeitung, numerische Daten und Sprache eng miteinander verknüpft sind, wie beispielsweise beim Graphverständnis, die Bereitstellung einer qualitativ hochwertigen, code-ausgerichteten multimodalen Überwachung effektiver ist als eine einfache Vergrößerung des Modells.
⑥ Verallgemeinerung auf öffentliche Benchmarks
Wie die folgende Tabelle zeigt, erzielten alle Modelle nach dem Feintuning auf dem ChartNet-Kerndatensatz signifikante Verbesserungen auf öffentlichen Benchmarks: Granite-Vision-2B verbesserte sich von 1,6 auf 12,4 BLEU auf ChartCap und von 30,8 auf 58,4 auf ChartMimic-v2; selbst das ultrakompakte Modell (SmolVLM-256M) erreichte eine deutliche Leistungssteigerung. Diese Verbesserung war sowohl bei der Chart-Zusammenfassung als auch bei der Chart-zu-Code-Generierung konsistent und beweist, dass die multimodale Ausrichtungsüberwachung von ChartNet effektiv auf reale Benchmarks übertragen werden kann und nicht nur auf synthetische Trainingsdatensätze.
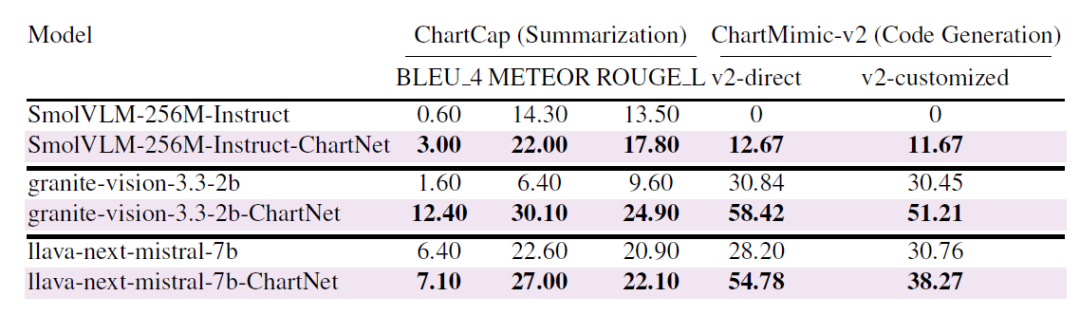
Verbesserung der Generalisierungsfähigkeit der ChartNet-Synthesedaten anhand zweier realer, öffentlicher Benchmarks.
Abschluss
ChartNet zielt darauf ab, einen zentralen Engpass im Bereich des Diagrammverständnisses zu beheben: den Mangel an großflächigen, hochpräzisen Überwachungssignalen zur Ausrichtung von Bildern, dargestelltem Code, numerischen Daten, Textbeschreibungen und Inferenzpfaden. Es bietet eine skalierbare und offene Basisplattform für die multimodale Modellierungsforschung in den Bereichen numerisches Schließen, Visualisierungsverständnis, Dokumentenanalyse und Codeausrichtung und treibt die visuelle Modellierung (VLM) von der reinen Diagrammbeschreibung hin zum Verständnis der in Diagrammen kodierten strukturierten Informationen voran.
„Viele bisherige Trainingsdatensätze konzentrierten sich lediglich auf die Beantwortung einfacher Fragen zu Diagrammen“, sagte Jovana Kondic, Doktorandin am Department für Elektrotechnik und Informatik (EECS) des MIT und Erstautorin der ChartNet-Veröffentlichung. „Mit ChartNet wollten wir einen Schritt weiter gehen und Daten generieren, die ein umfassendes und tiefgreifendes Verständnis von Diagrammen ermöglichen.“
Zukünftig planen die Forscher, ChartNet durch die Einbeziehung komplexerer Daten weiter auszubauen und so einen echten Mehrwert für weitere Branchen zu schaffen.
Quellen:
https://arxiv.org/abs/2603.27064
https://news.mit.edu/2026/mit-researchers-teach-ai-models-to-interpret-charts-0603