Command Palette
Search for a command to run...
Paper Weekly Report | ProgramBench Ermöglicht Es KI, Software Von Grund Auf Neu Zu Schreiben, Wobei 9 Wichtige Modelle Massenhaft Scheitern; ExoActor Demonstriert Eine Starke Fähigkeit Zur Szenengeneralisierung Ohne Zusätzliche Reale Daten… Ein Kurzer Überblick Über Die Neuesten KI-Veröffentlichungen Der Woche

Da Sprachmodelle zunehmend in der langfristigen Softwareentwicklung eingesetzt werden, reichen bestehende Benchmarks nicht mehr aus, um ihre Leistungsfähigkeit in den Bereichen Systemarchitektur, Modulpartitionierung und allgemeine Implementierung zu messen. Um dem entgegenzuwirken, schlug das SWE-Bench-Team den ProgramBench-Benchmark vor: Dabei erhalten die Modelle lediglich die ausführbare Datei und die zugehörige Dokumentation und müssen den Code umschreiben, um das Programmverhalten zu reproduzieren.
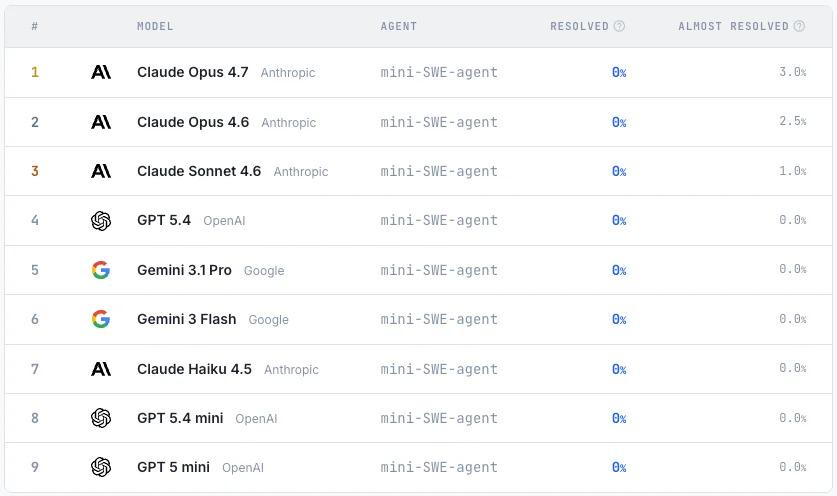
Die Studie erstellte 200 Aufgaben, die verschiedene Softwaretypen abdeckten, darunter Datenbanken, Compiler und Kommandozeilenprogramme, und bewertete die Übereinstimmung zwischen dem modellgenerierten Programm und dem Originalprogramm durch Verhaltenstests.Experimentelle Ergebnisse zeigen, dass die derzeitigen gängigen Modelle immer noch Schwierigkeiten haben, komplexe Software-Rekonstruktionsaufgaben zu bewältigen, und kein Modell alle Tests bestehen kann.Selbst das leistungsstärkste Modell, Claude Opus 4.7, erreichte nur bei wenigen Aufgaben eine hohe Erfolgsquote, was darauf hindeutet, dass große Sprachmodelle hinsichtlich ihrer allgemeinen Softwareentwicklungsfähigkeiten immer noch erhebliche Defizite aufweisen.
Link zum Artikel:https://go.hyper.ai/wExzR
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Um mehr Nutzern die neuesten Entwicklungen auf dem Gebiet der künstlichen Intelligenz in der akademischen Welt näherzubringen,Die Website von HyperAI (hyper.ai) verfügt nun über einen Bereich „Neueste Veröffentlichungen“, der regelmäßig mit hochaktuellen KI-Forschungsarbeiten aktualisiert wird.Hier sind 8 beliebte KI-Veröffentlichungen, die wir empfehlen. Werfen wir einen kurzen Blick auf die neuesten KI-Erfolge dieser Woche ⬇️
Die Zeitungsempfehlung dieser Woche
1. ProgramBench
Titel des Artikels:
ProgramBench: Können Sprachmodelle Programme von Grund auf neu erstellen?
Das Forschungsteam entwickelte ProgramBench, um die Fähigkeit von Softwareentwicklungsagenten zu evaluieren, vollständige Softwareprojekte von Grund auf zu erstellen. Dieser Benchmark verlangt vom Agenten, eine Codebasis zu implementieren, die sich – ausschließlich basierend auf dem Programm und der Dokumentation – konsistent mit einer Referenz-Executable verhält, und eine End-to-End-Evaluierung mittels agentengesteuertem Fuzzing durchzuführen.
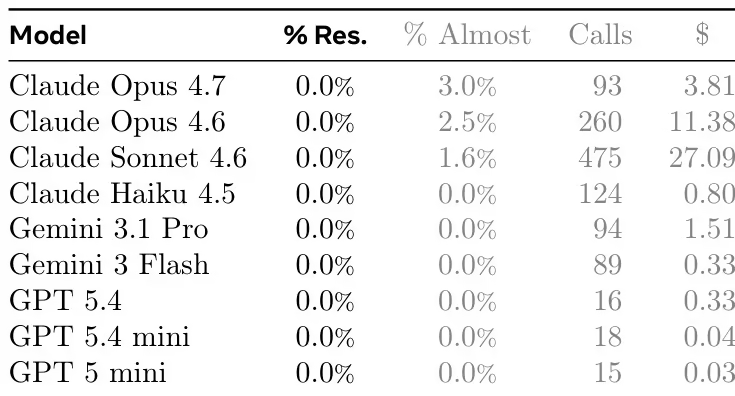
ProgramBench umfasst 200 Aufgaben, die verschiedene Softwaretypen abdecken, darunter CLI-Tools, FFmpeg, SQLite und PHP-Interpreter. Experimente mit neun Sprachmodellen zeigen, dass die aktuellen Modelle nur eine begrenzte Gesamtleistung aufweisen. Das beste Modell bestand den Test von 95% lediglich in der Aufgabe 3%, und der generierte Code weist im Allgemeinen eine monolithische, eindateiige Struktur auf, die sich deutlich von der üblichen Softwareentwicklungspraxis unterscheidet.
Papier und detaillierte Interpretation:https://go.hyper.ai/wExzR
Zusammensetzung und Quellen des Datensatzes: Die Autoren stellten 200 Aufgabeninstanzen aus Open-Source-GitHub-Repositories zusammen. Die Quellen stammen aus Projekten, die eigenständige ausführbare Dateien erzeugen, vorwiegend in Rust, Go oder C/C++. Die Sammlung umfasst verschiedene Funktionskategorien wie Textverarbeitung, Systemdienstprogramme und Sprachinterpreter.

2. Uni-OPD
Titel des Artikels:
Uni-OPD: Vereinheitlichung der Richtlinienkonformität durch ein Rezept aus zwei Perspektiven
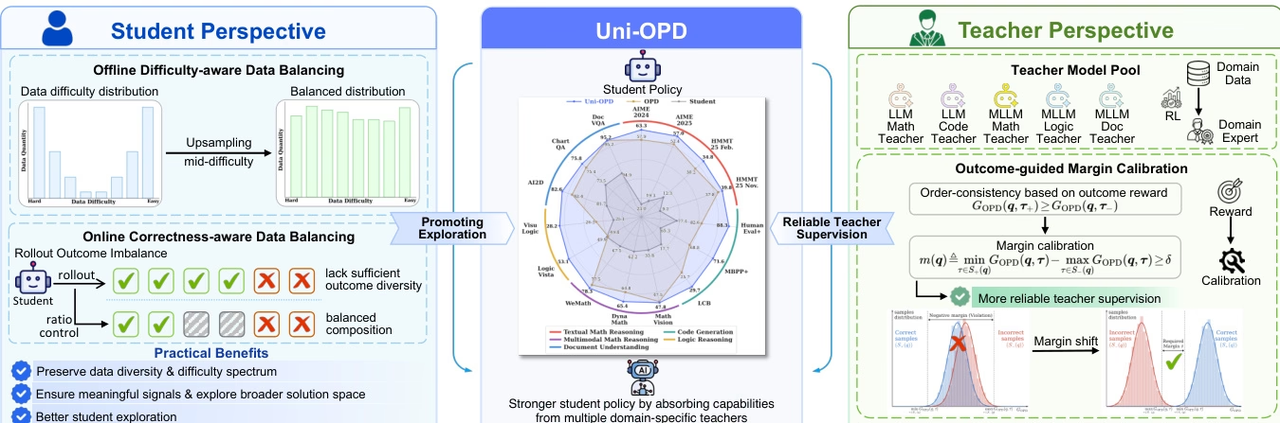
Uni-OPD ist ein einheitliches Online-Destillationsframework für LLMs und MLLMs, das den Transfer von Expertenwissen auf studentische Modelle verbessern soll. Forschungsergebnisse zeigen, dass bestehende OPD-Methoden hauptsächlich durch zwei Probleme eingeschränkt sind: unzureichende Exploration informationsreicher Zustände und unzuverlässige Signale der Lehrendenaufsicht.
Um diesem Problem zu begegnen, verwendet Uni-OPD eine Optimierungsstrategie mit zwei Perspektiven: Auf der Seite der Lernenden wird eine Datenausgleichsstrategie eingeführt, um die Erkundung informationsreicher Zustände zu verbessern; auf der Seite der Lehrenden wird ein ergebnisorientierter Mechanismus zur marginalen Kalibrierung vorgeschlagen, um die sequentielle Konsistenz zwischen korrekten und inkorrekten Lernpfaden wiederherzustellen und so die Zuverlässigkeit der Betreuung zu erhöhen. Experimente in fünf Domänen und 16 Benchmarks, die verschiedene Szenarien wie Einzellehrer, Mehrlehrer, von starken zu schwachen Lernpfaden und modalitätsübergreifende Destillation umfassen, bestätigten die Wirksamkeit der Methode.
Papier und detaillierte Interpretation:https://go.hyper.ai/8k4du
3. Treue Ungewissheit
Titel des Artikels:
Halluzinationen untergraben das Vertrauen; Metakognition ist ein Weg nach vorn
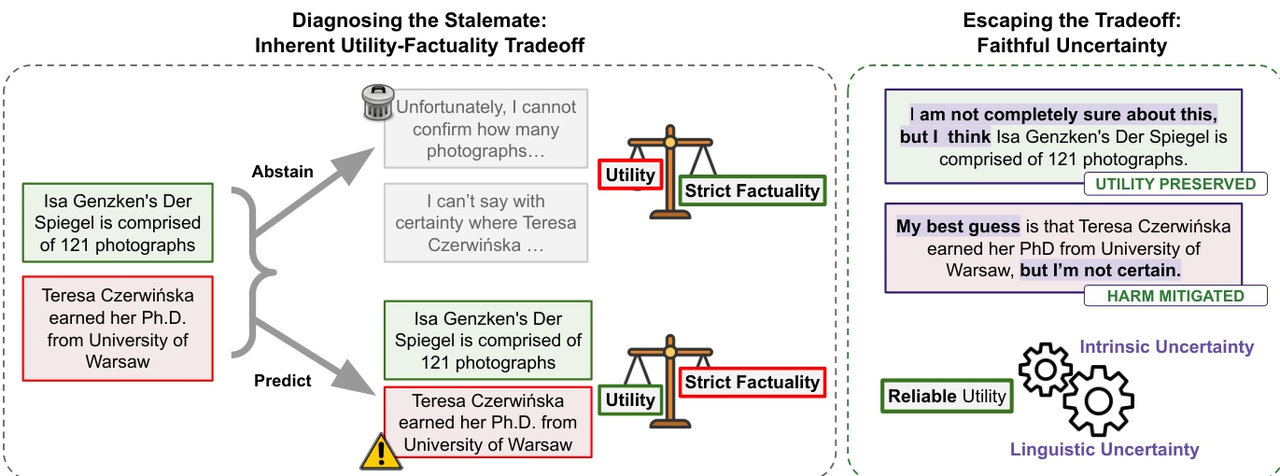
Das Forschungsteam weist darauf hin, dass sich große Sprachmodelle zwar hinsichtlich ihrer faktischen Zuverlässigkeit stetig verbessern, das Problem der „Illusionen“ jedoch weiterhin besteht, insbesondere bei der Beantwortung faktischer Fragen, wenn externe Hilfsmittel fehlen. Die Studie argumentiert, dass der aktuelle Fortschritt eher auf der Erweiterung des Wissensumfangs als auf der tatsächlichen Fähigkeit des Modells beruht, zwischen „Bekanntem“ und „Unbekanntem“ zu unterscheiden. Daher könnte die vollständige Beseitigung von Illusionen einen natürlichen Kompromiss mit der Praktikabilität des Modells darstellen.
Ausgehend von dieser Perspektive schlägt die Studie das Konzept der „authentischen Unsicherheit“ vor und betont, dass Modelle ihre eigene Unsicherheit wahrheitsgemäß ausdrücken sollten, um die Konsistenz zwischen sprachlicher Unsicherheit und interner Kognition zu gewährleisten. Diese metakognitive Fähigkeit trägt nicht nur zur Verbesserung der Modellglaubwürdigkeit bei, sondern bietet auch einen zuverlässigeren Kontrollmechanismus für Suche und Entscheidungsfindung in intelligenten Agentensystemen.
Papier und detaillierte Interpretation:https://go.hyper.ai/G77rj
Zusammensetzung und Quelle des Datensatzes: Die Autoren erstellten einen synthetischen Datensatz mit 25.000 Stichproben, um die von Nakkiran et al. (2025) aufgezeichneten empirischen Konfidenzverteilungseigenschaften zu reproduzieren.

4. PRISMA
Titel des Artikels:
Über SFT-zu-RL hinaus: Vorabgleich mittels Black-Box-On-Policy-Destillation für multimodales RL
Um das Problem der Verteilungsverschiebung zu lösen, die das nachfolgende Reinforcement Learning während der Feinabstimmung großer multimodaler Modelle beeinflusst, schlug das Forschungsteam ein dreistufiges Verfahren namens PRISM vor. Dieses Verfahren fügt eine Verteilungsanpassungsphase auf Basis einer Intra-Policy-Destillation zwischen überwachter Feinabstimmung und Reinforcement Learning ein und nutzt einen hybriden Expertendiskriminator (MoE), um Entkopplungskorrektursignale bereitzustellen.
Unter Verwendung von 113.000 hochwertigen Gemini-Demo-Datensätzen verbesserte PRISM die Leistung des nachgelagerten Reinforcement Learning im Qwen3-VL-Experiment signifikant und erhöhte die Genauigkeit der 4B- und 8B-Modelle um 4,4 bzw. 6,0 Punkte.
Papier und detaillierte Interpretation:https://go.hyper.ai/5fsD3
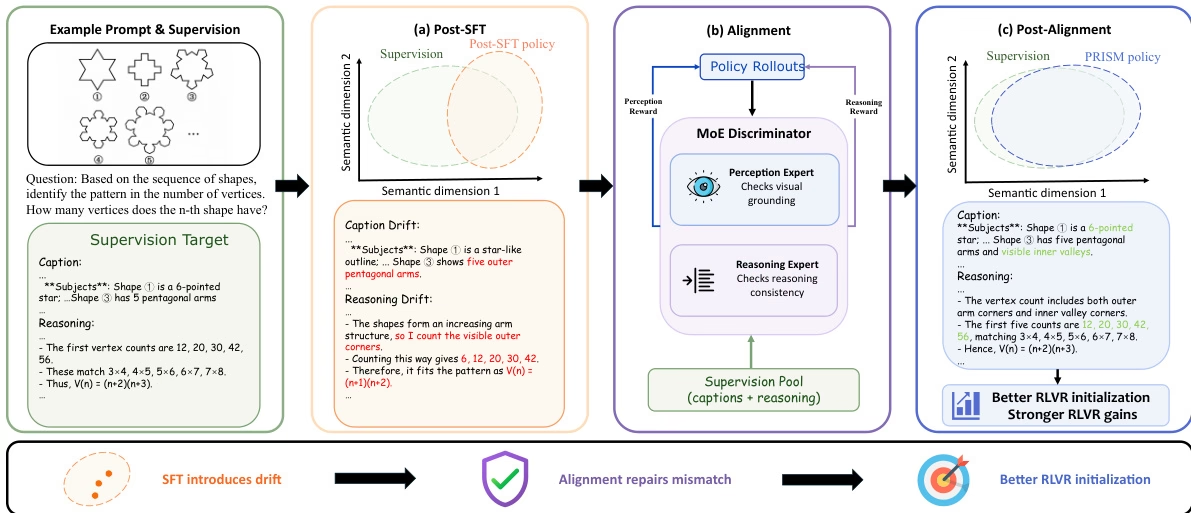
Zusammensetzung und Quellen des Datensatzes: Diese Arbeit erstellt ein multimodales Schlussfolgerungskorpus mit Daten aus öffentlich verfügbaren Benchmark-Tests, die mathematisches Denken, wissenschaftliches Graphverständnis, Graphinterpretation und räumliches Denken abdecken. Um die Abdeckung und Stabilität zu erhöhen, wird dieser sorgfältig ausgewählte Datensatz durch 1,26 Millionen öffentlich verfügbare Demodaten ergänzt, die mit derselben Gemini-Modellreihe generiert wurden.
5. ExoActor
Titel des Artikels:
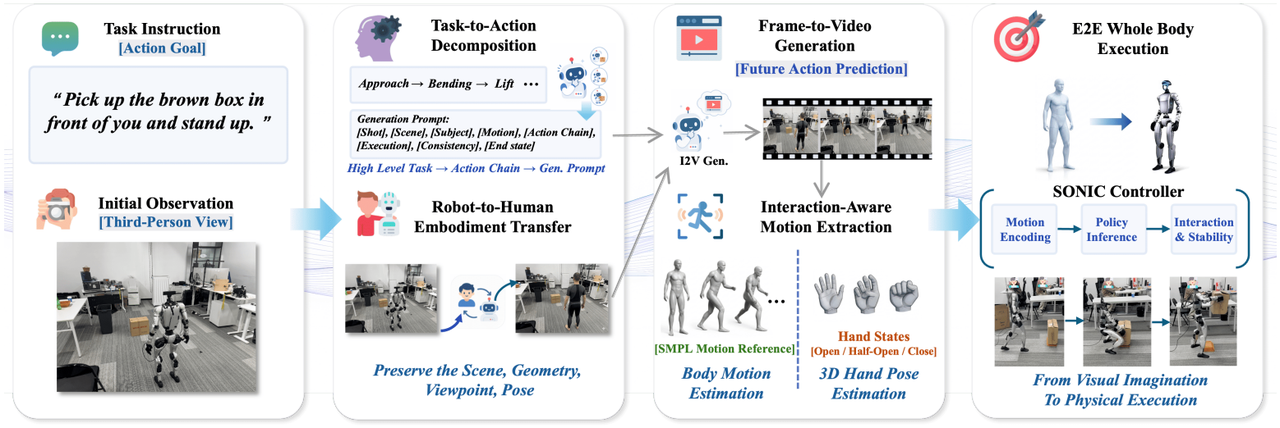
ExoActor: Exozentrische Videogenerierung als generalisierbare interaktive humanoide Steuerung
Das Forschungsteam entwickelte das ExoActor-Framework, das exozentrische Videogenerierung als einheitliche Schnittstelle nutzt, um die kollaborativen Interaktionen zwischen Roboter, Umgebung und Objekten implizit zu kodieren. Es wandelt das synthetisierte Ausführungsvideo mithilfe von Bewegungsabschätzung und einem allgemeinen Bewegungscontroller in ausführbare Verhaltensweisen des humanoiden Roboters um und demonstriert so die Fähigkeit, ohne zusätzliche Datenerfassung vor Ort auf neue Szenarien zu generalisieren.
Papier und detaillierte Interpretation:https://go.hyper.ai/OE5IH
6. Edit-R1
Titel des Artikels:
Nutzung von verifiziererbasiertem Reinforcement Learning in der Bildbearbeitung
Das Forschungsteam entwickelte Edit-R1, ein Reinforcement-Learning-Framework für die Bildbearbeitung. Im Gegensatz zu herkömmlichen Belohnungsmodellen, die lediglich eine Gesamtpunktzahl ausgeben, zerlegt Edit-R1 Bearbeitungsanweisungen in mehrere Prinzipien und überprüft die Ergebnisse Element für Element anhand von Denkketten. Dadurch werden differenziertere und besser interpretierbare Belohnungssignale generiert. Die Forschung kombiniert zudem überwachtes Feintuning mit GCPO-Reinforcement-Learning-Strategien, um die Fähigkeit des Belohnungsmodells zur Modellierung menschlicher Präferenzen zu verbessern, und nutzt GCPO zum Trainieren nachgelagerter Bearbeitungsmodelle.
Experimentelle Ergebnisse zeigen, dass Edit-RRM leistungsstarke VLMs wie Seed-1.5-VL und Seed-1.6-VL bei der Bildbearbeitungsbewertung übertrifft und die Leistung von Bearbeitungsmodellen wie FLUX.1-kontext deutlich verbessert, während gleichzeitig signifikante Vorteile durch die Parametererweiterung aufgezeigt werden.
Papier und detaillierte Interpretation:https://go.hyper.ai/MtBLB
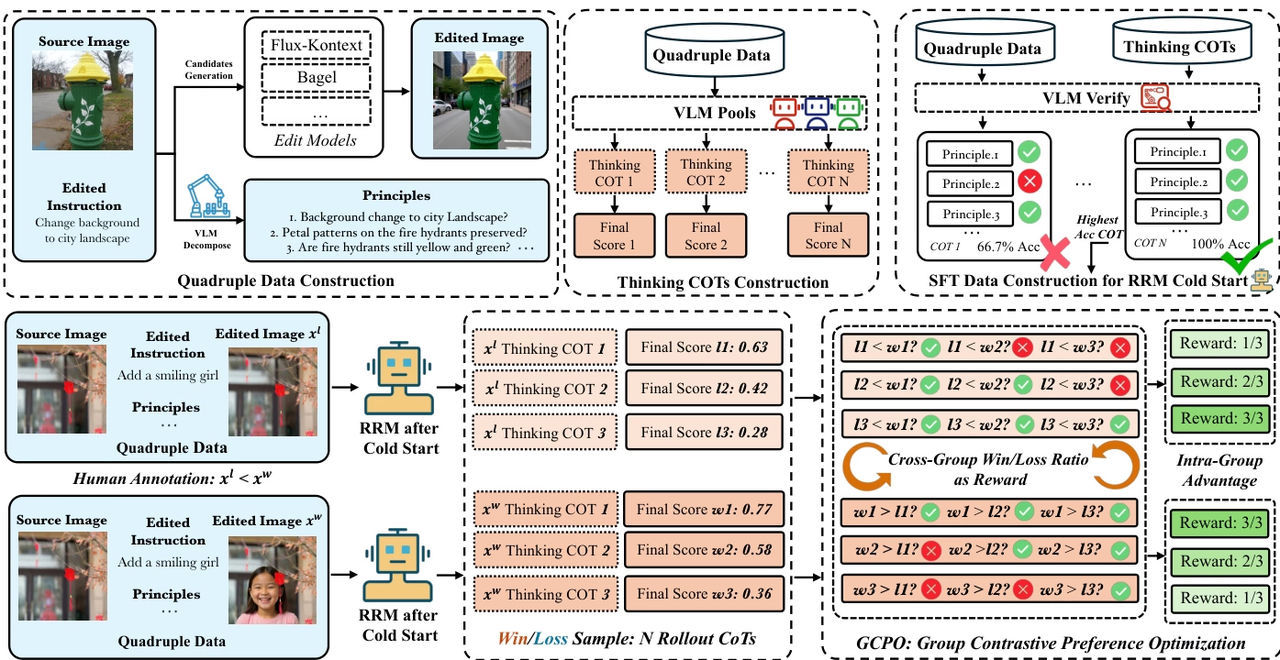
Zusammensetzung und Quelle des Datensatzes: Das Forschungsteam erstellte einen überwachten Datensatz für ein Cold-Start-Inferenz-Belohnungsmodell, indem es 200.000 Beispiele aus öffentlich verfügbaren Bildbearbeitungs-Benchmarks zusammenstellte. Dieser ursprüngliche Datensatz wurde durch Multi-Modell-Generierung und systematische Validierung auf etwa 2 Millionen Datenvierfache erweitert.

7. Gemeinsame Entwicklung der Politik – Destillation
Titel des Artikels:
Gemeinsame Entwicklung der Politik – Destillation
Das Forschungsteam führte eine einheitliche Analyse der beiden gängigen Nachschulungsparadigmen, RLVR und OPD, durch und wies darauf hin, dass diese unterschiedliche Einschränkungen bei der Integration mehrerer Expertenkompetenzen aufweisen: Das hybride RLVR ist anfällig für „Kosten der Kompetenzdivergenz“, während der traditionelle Prozess, „erst Experten auszubilden und dann OPD zu implementieren“, Kompetenzkonflikte vermeidet, es aber aufgrund der großen Unterschiede in den Verhaltensmustern zwischen Lehrern und Schülern schwierig ist, Expertenkompetenzen vollständig zu übernehmen.
Um dieses Problem zu lösen, schlägt diese Studie eine koevolutionäre Strategie vor, CoPD (Koevolutionäre Verarbeitung). Diese führt bidirektionale OPD (Optische Verarbeitungsderivate) ein, während Experten kontinuierlich für RLVR (Referenzbasiertes RLVR) trainieren. Dadurch können Experten sich gegenseitig als Lehrende fungieren und gemeinsam weiterentwickeln, was die Verhaltenskonsistenz verbessert und gleichzeitig komplementäre Fähigkeiten erhält. Experimentelle Ergebnisse zeigen, dass CoPD Text-, Bild- und Videoanalyse effektiv integriert und starke Vergleichsmodelle wie hybrides RLVR und MOPD deutlich übertrifft. In einigen Aufgaben übertrifft CoPD sogar Domänenexpertenmodelle.
Papier und detaillierte Interpretation:https://go.hyper.ai/cCyrG
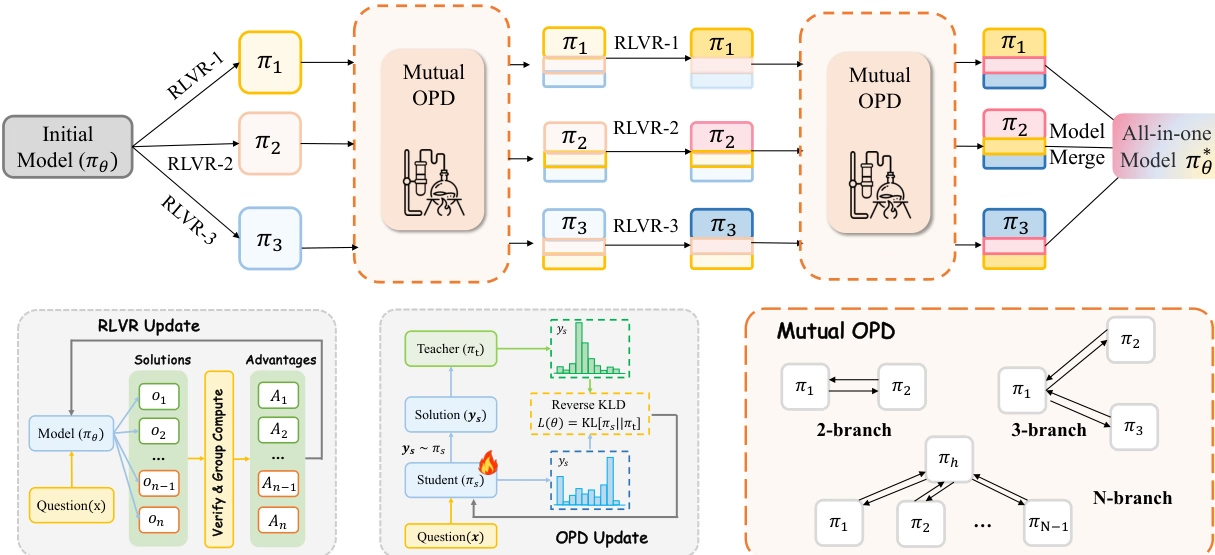

8. ClawGym
Titel des Artikels:
ClawGym: Ein skalierbares Framework zum Erstellen effektiver Claw-Agenten
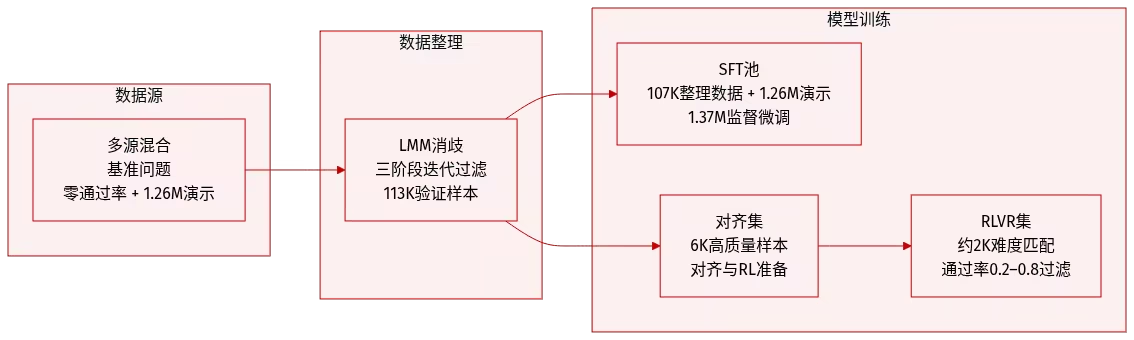
Das Forschungsteam entwickelte ClawGym, ein skalierbares Framework für den gesamten Lebenszyklus der Entwicklung persönlicher Agenten im Claw-Stil, um komplexe, mehrstufige Arbeitsabläufe mit lokalen Dateien, Tool-Aufrufen und persistenten Arbeitsbereichszuständen zu unterstützen.
Das Framework umfasst den synthetischen Datensatz ClawGym-SynData mit 13.500 ausgewählten Aufgaben und kombiniert menschliche Intention, Fertigkeitsausführung, simulierten Arbeitsbereich und hybride Verifikationsmechanismen. ClawGym-Agenten werden anhand von Black-Box-Rollout-Trajektorien trainiert und ihre Fähigkeiten durch eine ressourcenschonende Reinforcement-Learning-Pipeline verbessert. Zusätzlich wurde für eine zuverlässige Evaluierung ein Benchmark-Set, ClawGym-Bench, erstellt, das automatisch ausgewählt und gemeinsam von Menschen und LLM überprüft und kalibriert wird.
Papier und detaillierte Interpretation:https://go.hyper.ai/yZwa5
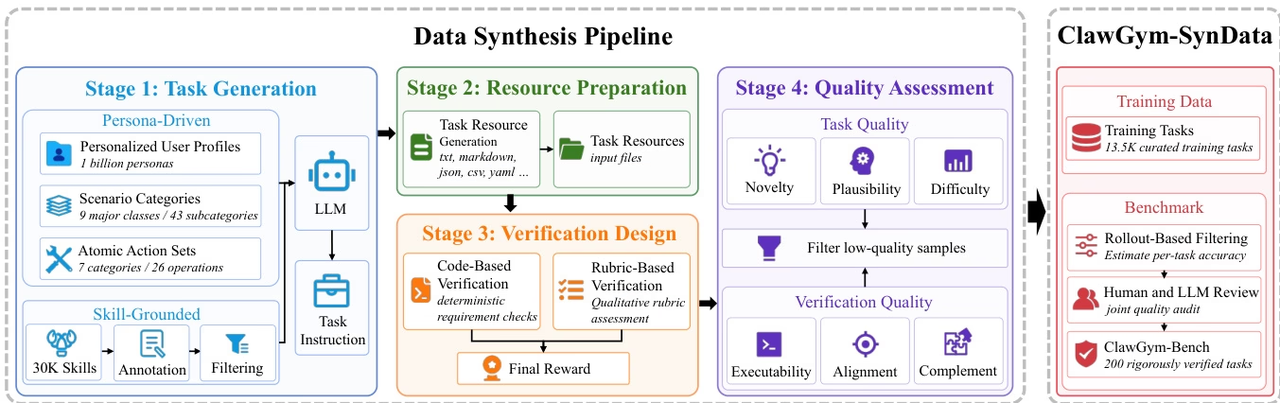
Datenquelle: Das Forschungsteam generierte Trainingsdaten mithilfe des ClawGym-SynData-Frameworks, das persönlichkeitsorientierte Top-Down-Synthese für verschiedene Benutzerszenarien mit Bottom-Up-Synthese kombiniert, die auf der Technologie der Verbindung von OpenClaw-Funktionen in einen realen Arbeitsablauf basiert.
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








