Command Palette
Search for a command to run...
Paper Weekly Report | Microsoft MAI-Thinking Erforscht Die Selbstentwicklung Von Reinem Reinforcement Learning Und Erreicht Eine AIME-Genauigkeit Von 97%; VLM³ Erreicht 3D-Aufgabengeneralisierung Mithilfe Von Klartextkoordinaten Ohne Architektonische Modifikationen… Ein Kurzer Überblick Über Die Neuesten KI-Veröffentlichungen Der Woche

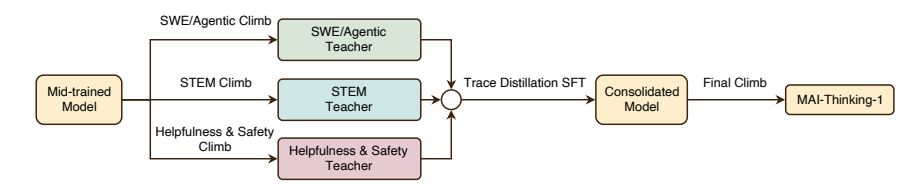
Fortschritte in der künstlichen Intelligenz hängen nicht nur von Durchbrüchen bei einzelnen Modellen ab, sondern vor allem von der Entwicklung von Systemen, die zur kontinuierlichen Selbstverbesserung fähig sind. Aus diesem Grund betrachtet das KI-Team von Microsoft die Modellentwicklung als ein Optimierungsproblem auf Systemebene.Es wird ein Rahmenkonzept vorgeschlagen, das auf eine Art „Bergsteigermaschine“ basiert und schnelle und nachhaltige Leistungsverbesserungen ermöglichen soll."Auf dieser Grundlage wurde ein MoE-Inferenzmodell MAI-Thinking-1 mit einem Gesamtparameter von 1T und einem Aktivierungsparameter von 35B von Grund auf trainiert.
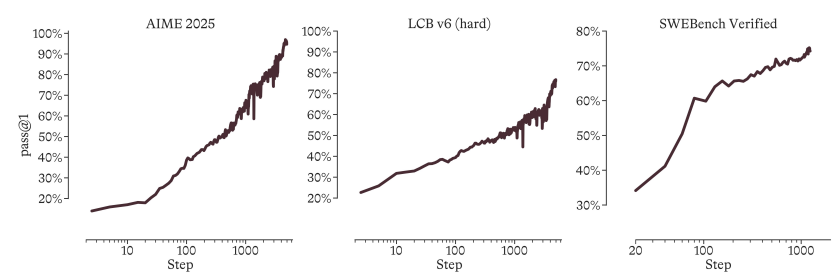
Das Modell verwirft während der Vortrainingsphase vollständig Destillationsdaten von Drittmodellen und führt während der Reinforcement-Learning-Phase (RL) den GRPO-Algorithmus mit adaptiver Entropiekontrolle und einem Selbstdestillationsmechanismus ein.Experimentelle Ergebnisse zeigen, dass MAI-Thinking-1 selbst ohne vorherige Inferenztrajektorien ein langfristiges und stabiles logarithmisch-lineares Leistungswachstum erzielen kann.Letztendlich erreichte es auf Kern-Benchmarks wie AIME 2025 (97,0%) und SWE-Bench Pro (52,8%) ein Höchstmaß an komplexer Inferenz und Codegenerierung.
Link zum Artikel:https://go.hyper.ai/QeSWd
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Um mehr Nutzern die neuesten Entwicklungen auf dem Gebiet der künstlichen Intelligenz in der akademischen Welt näherzubringen,Die Website von HyperAI (hyper.ai) verfügt nun über einen Bereich „Neueste Veröffentlichungen“, der regelmäßig mit hochaktuellen KI-Forschungsarbeiten aktualisiert wird.Hier sind neun beliebte KI-Veröffentlichungen, die wir empfehlen. Werfen wir einen kurzen Blick auf die neuesten KI-Erfolge dieser Woche ⬇️
Die Zeitungsempfehlung dieser Woche
1. MAI-Denken-1
Titel des Artikels:
MAI-Denken-1: Bau einer Bergsteigermaschine
Das KI-Team von Microsoft schlug einen „Hill-Climbing“-Ansatz vor, der die Modellentwicklung als systemweites Optimierungsproblem behandelt. Sie trainierten das MoE-Inferenzmodell MAI-Thinking-1 von Grund auf mit insgesamt 1T Parametern und 35 Milliarden Aktivierungsparametern. Das Vortraining des Modells basierte ausschließlich auf sauberen Daten, ohne Verwendung von aufbereiteten Daten Dritter. Während der Reinforcement-Learning-Phase erzielte das Team durch den Einsatz des GRPO-Algorithmus mit adaptiver Entropiekontrolle und einem Selbstaufbereitungsmechanismus ein stabiles und langfristiges Leistungswachstum ohne anfängliche Inferenztrajektorie. Das Modell integriert schließlich Fähigkeiten aus drei Expertenbereichen: STEM, Code-Agent und Sicherheit und demonstriert erstklassige Inferenz- und Code-Performance auf Benchmarks wie AIME 2025 (97,0%) und SWE-Bench Pro (52,8%).
Papier und detaillierte Interpretation:https://go.hyper.ai/QeSWd
2. VLM³
Titel des Artikels:
VLM³: Vision Language Models Are Native 3D Learners
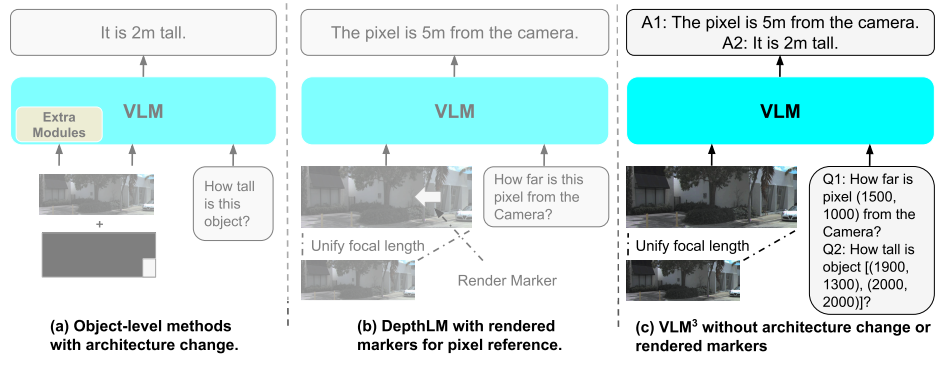
Meta und sein Team entdeckten in groß angelegten Experimenten, dass effizientes 3D-Lernen von visuellen Lernmodellen (VLMs) weder komplexe Architekturen noch spezielle Designs erfordert. Es bedarf lediglich einer einheitlichen Brennweite, textbasierter Pixelreferenzen sowie sinnvoller Strategien zur Datenmischung und -erweiterung. Basierend auf dieser Erkenntnis entwickelte das Forschungsteam VLM³, ein minimalistisches Design, das es Standard-VLMs ermöglicht, gleichzeitig Aufgaben wie Tiefenschätzung, pixelbasierte Korrespondenz, Kameraposenschätzung und 3D-Objekterkennung auszuführen. Unter Beibehaltung der ursprünglichen Architektur und der textbasierten Trainingsmethode erreichte VLM³ eine Leistung, die der von Expertenmodellen nahekam oder diese sogar übertraf. Dies eröffnet einen einfacheren und skalierbareren Weg für universelle visuelle Modelle, die 3D-Welt zu erlernen.
Papier und detaillierte Interpretation:https://go.hyper.ai/5ks6r
3. Alles finden
Titel des Artikels:
LocateAnything: Schnelle und hochwertige visuelle und sprachbasierte Erdung mit paralleler Box-Dekodierung
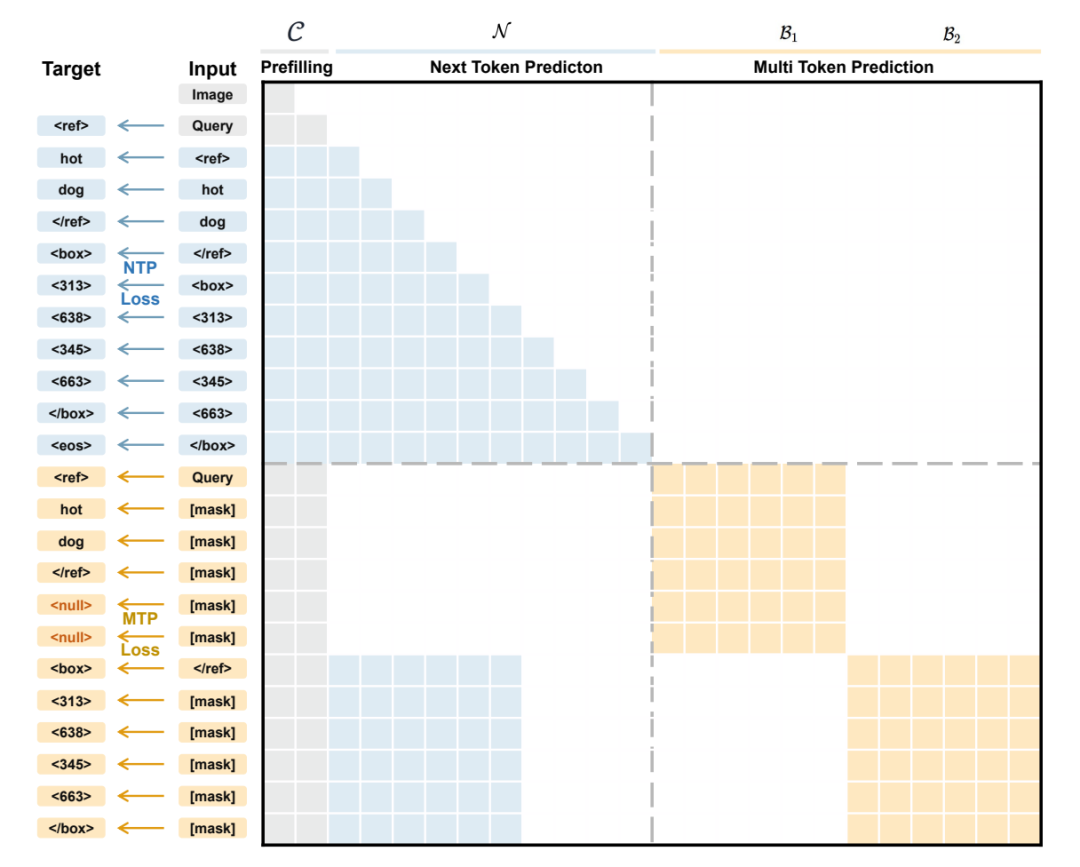
Herkömmliche visuelle Sprachmodelle modellieren die Objektlokalisierung typischerweise als schrittweisen Generierungsprozess von Koordinaten-Tokens, der die sequentielle Vorhersage von Begrenzungsrahmenkoordinaten erfordert. Dies ignoriert nicht nur die geometrischen Beziehungen innerhalb der Rahmen, sondern begrenzt auch die Inferenzgeschwindigkeit. Um dieses Problem zu lösen, schlug das NVIDIA-Team LocateAnything vor. Dieses Modell verwendet einen parallelen Box-Decoding-Mechanismus (PBD), um den Begrenzungsrahmen als atomare Einheit zu behandeln und dessen vollständigen Koordinatensatz parallel in einem einzigen Schritt zu generieren. In Kombination mit einem umfangreichen Datensatz mit 138 Millionen Anfragen und einem hybriden Inferenzmodus mit intelligentem Fehler-Fallback erzielt dieses Modell einen höheren Dekodierungsdurchsatz und eine bessere Lokalisierungsgenauigkeit mit hohem IoU-Wert in verschiedenen Benchmarks. Dadurch werden die Grenzen der Geschwindigkeit und Genauigkeit von einheitlichen visuellen Lokalisierungs- und Erkennungsaufgaben erweitert.
Papier und detaillierte Interpretation:https://go.hyper.ai/C8jXC
Zusammensetzung und Quelle des Datensatzes: Das Forschungsteam erstellte LocateAnything-Data, ein umfangreiches Korpus mit 12 Millionen einzigartigen Bildern, 138 Millionen natürlichsprachlichen Anfragen und 785 Millionen beschrifteten Begrenzungsrahmen.

4. Qwen-VLA
Titel des Artikels:
Qwen-VLA: Vereinheitlichung der Modellierung von Bildverarbeitung, Sprache und Handlung über Aufgaben, Umgebungen und Roboterformen hinweg
Die Forschung zur verkörperten Intelligenz stützte sich lange auf spezialisierte Modelle für Einzelaufgaben, was zu fragmentierten Fähigkeiten und begrenzter Generalisierbarkeit führte. Das Qianwen-Team schlägt Qwen-VLA vor, ein einheitliches Basismodell für Bildverarbeitung, Sprache und Handlung. Mithilfe eines DiT-basierten Handlungsdecoders erweitert es die Bild-Sprach-Wahrnehmung, das Verständnis und das Schlussfolgern auf kontinuierliche Handlungen und die Generierung von Trajektorien. Das Modell nutzt ein umfangreiches gemeinsames Vortraining, das Roboterbetriebstrajektorien, Demonstrationen aus der Ich-Perspektive, Simulationsdaten, Navigationsaufgaben und zusätzliche Bild-Sprach-Signale umfasst. Es passt sich zudem durch einen Mechanismus zur Konditionierung verkörperter Wahrnehmungshinweise an verschiedene Roboterplattformen an. Qwen-VLA integriert Betrieb, Navigation und Trajektorienvorhersage in ein einheitliches Framework und erreicht so die Übertragbarkeit auf verschiedene Aufgaben, Umgebungen und Roboterformen. Experimente zeigen, dass das Modell über verschiedene Betriebs- und Navigations-Benchmarks hinweg eine stabile Multitasking-Leistung und eine hohe Generalisierbarkeit aufweist.
Papier und detaillierte Interpretation:https://go.hyper.ai/5x2Tj
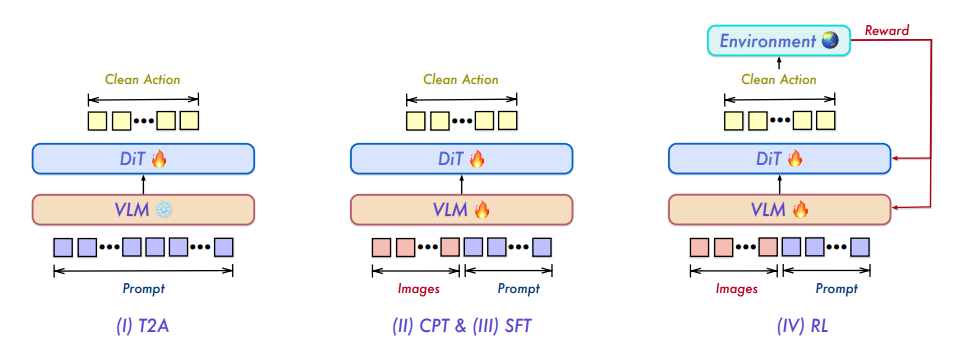
Zusammensetzung und Quellen des Datensatzes: Das Forschungsteam erstellte einen umfangreichen, heterogenen, vortrainierten Korpus, um visuelle, sprachliche und handlungsbezogene Modellierung zu vereinheitlichen. Zu den Datenquellen gehören mehr als zehn öffentliche Roboter-Benchmarks, ein umfangreiches Videokorpus von Menschen, firmeneigene, intern erhobene Daten und intern entwickelte Simulationspipelines.

5. SDPG
Titel des Artikels:
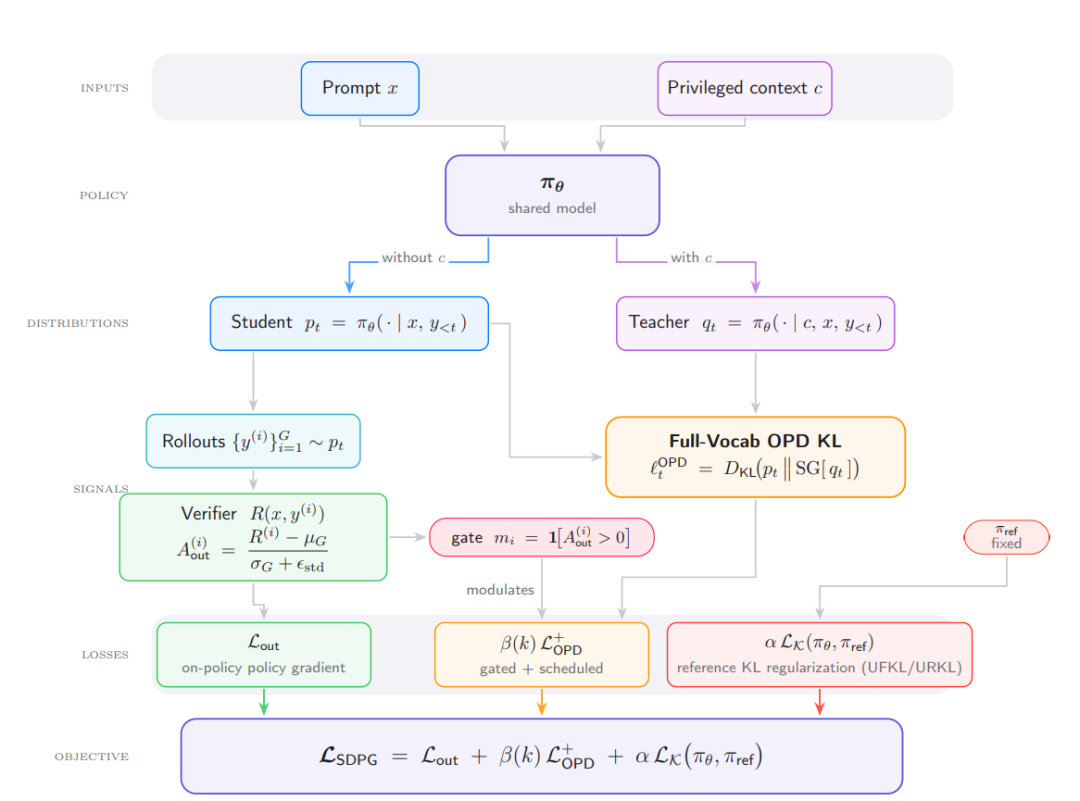
Selbstdestillierter Politikgradient
Policy-basierte Selbstdestillation (SDPG) nutzt den privilegierten Kontext des Modells, um die generierten Ergebnisse zu überwachen und so dichtere Lernsignale für spärliches Reward Reinforcement Learning (RLVR) bereitzustellen. Sie lässt sich als umgekehrter KL-Schüler-Lehrer-Verlust über den gesamten Wortschatz formalisieren. Darauf aufbauend entwickelten Forscher der UCLA und der Princeton University gemeinsam das SDPG-Framework. Dieses kombiniert den relativen Gruppenvalidatorvorteil, die Standardabweichungsnormalisierung, die Online-Selbstdestillation des gesamten Wortschatzes und die Referenz-Policy-KL-Regularisierung. Experimente zeigen, dass SDPG die Stabilität und Leistung im Vergleich zu RLVR und bestehenden Selbstdestillationsverfahren verbessert.
Papier und detaillierte Interpretation:https://go.hyper.ai/p5irp
6. GSM-Symbolisch
Titel des Artikels:
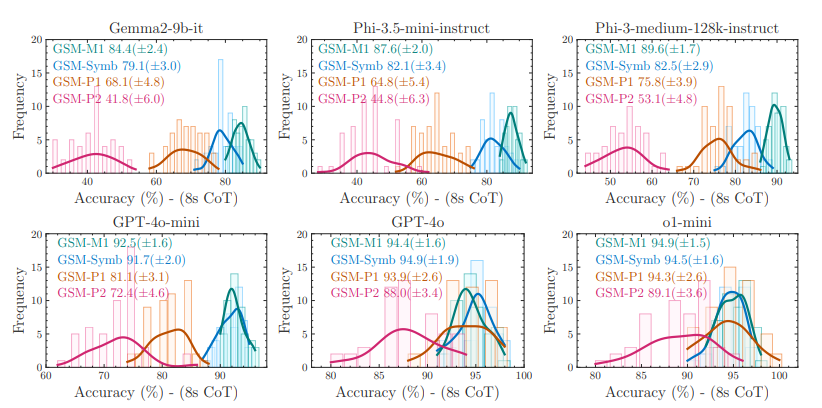
GSM-Symbolik: Die Grenzen mathematischen Denkens in großen Sprachmodellen verstehen
Untersuchungen zeigen, dass die traditionellen GSM8K-Benchmarks die tatsächliche Leistungsfähigkeit von Modellen nicht ausreichend abbilden. Daher entwickelte das Apple-Team mit GSM-Symbolic einen kontrollierbaren Benchmark, der auf symbolischen Vorlagen basiert. Experimente belegen, dass bereits die Änderung von Zahlen oder Entitätsnamen in den Fragen erhebliche Schwankungen in der Leistung großer Modelle verursacht; das Hinzufügen irrelevanter, ablenkender Klauseln reduziert die Genauigkeit zusätzlich drastisch. Das Forschungsteam vermutet, dass aktuelle LLMs keine echten logischen Denkfähigkeiten besitzen, sondern lediglich versuchen, die in ihren Trainingsdaten beobachteten Denkprozesse zu reproduzieren.
Papier und detaillierte Interpretation:https://go.hyper.ai/n3UfJ
7. MUSE-Autoskill
Titel des Artikels:
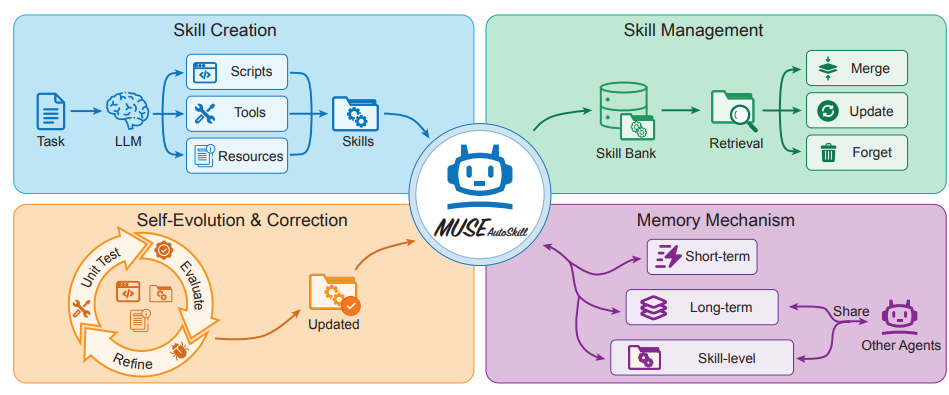
MUSE-Autoskill: Selbstlernende Agenten durch Kompetenzerstellung, -speicherung, -verwaltung und -bewertung
Teams wie ByteDance haben das intelligente Agenten-Framework MUSE-Autoskill entwickelt, das die Erstellung, Speicherung, Verwaltung, Bewertung und Optimierung von Fähigkeiten in einem vollständigen Lebenszyklus vereint. Dieses Framework überwindet die Einschränkungen traditioneller, statischer und isolierter Fähigkeiten, indem es ein auf Fähigkeiten basierendes Gedächtnis einführt, um Erfahrung über verschiedene Aufgaben hinweg zu sammeln. Experimente mit SkillsBench liefern erste Hinweise darauf, dass lebenszyklusverwaltete Fähigkeiten die Erfolgsquote, die Ausführungseffizienz, die Wiederverwendbarkeit und die Übertragbarkeit zwischen verschiedenen Agenten verbessern können. Dies unterstreicht die Bedeutung, Fähigkeiten als langlebige, erfahrungsbasierte und testbare Ressourcen zu betrachten.
Papier und detaillierte Interpretation:https://go.hyper.ai/mdgB2
8. Nemotron 3 Ultra
Titel des Artikels:
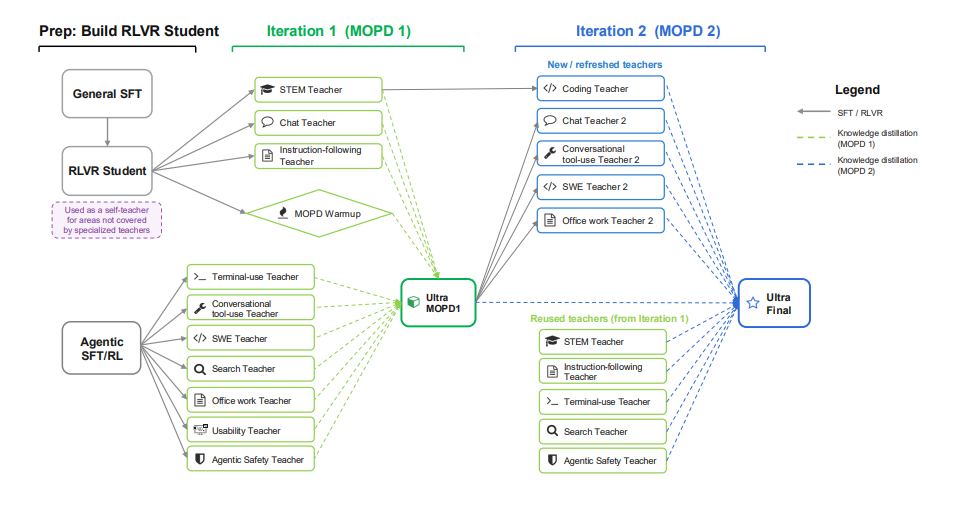
Nemotron 3 Ultra: Offenes, effizientes Hybrid-Mamba-Transformer-Modell mit Expertenmix für agentenbasiertes Schließen
NVIDIA hat Nemotron 3 Ultra veröffentlicht, ein Mamba-Attention-MoE-Sprachmodell mit 550 Milliarden Parametern und 55 Milliarden Aktivierungsparametern. Dieses Modell wurde mit 20 Billionen Token vortrainiert, wobei die Kontextlänge auf 1 Million Token erweitert wurde. Das Nachtraining erfolgte mit SFT, RL und Multi-Teacher Online Policy Distillation (MOPD). Durch den Einsatz von Techniken wie LatentMoE, Multi-Token-Vorhersage, NVFP4, RLVR, MOPD und Inferenzbudgetkontrolle erreicht Nemotron 3 Ultra einen etwa sechsmal höheren Inferenzdurchsatz als bestehende öffentliche LLMs bei gleichzeitig hoher Genauigkeit. Dadurch eignet es sich für langfristige autonome Aufgaben.
Papier und detaillierte Interpretation:https://go.hyper.ai/lm6S1
9. Kosmos 3
Titel des Artikels:
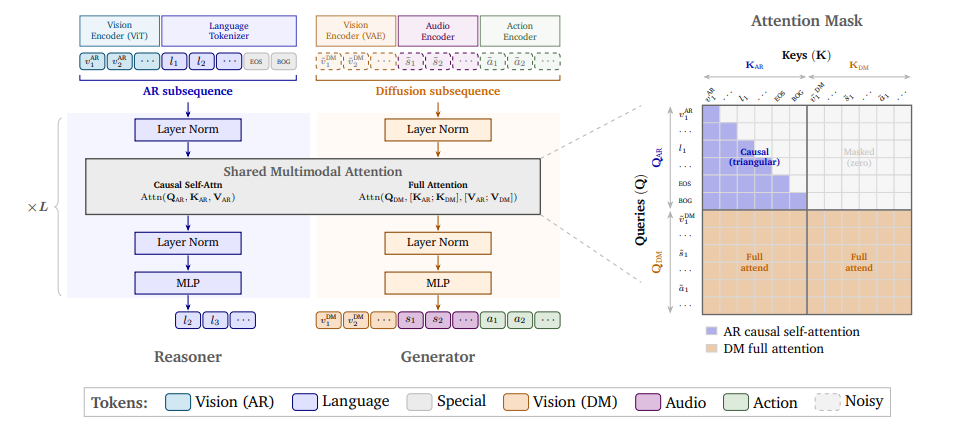
Cosmos 3: Omnimodale Weltmodelle für physikalische KI
NVIDIA hat Cosmos 3 veröffentlicht, eine Suite multimodaler Weltmodelle, die Sprache, Bilder, Videos, Audio und Aktionssequenzen in einer einheitlichen hybriden Transformer-Architektur verarbeiten und generieren. Cosmos 3 unterstützt hochflexible Eingabe-/Ausgabekonfigurationen und integriert visuelle Sprachmodelle, Videogeneratoren, Weltsimulatoren und Aktionsmodelle in ein einziges Framework. Evaluierungen zeigen, dass es in verschiedenen Aufgaben des Verstehens und Generierens herausragende Ergebnisse erzielt und multimodale Weltmodelle als allgemeine Backbone-Netzwerke für verkörperte Agenten validiert. Die trainierten Modelle wurden als beste Open-Source-Text-zu-Bild-/Bild-zu-Video-Modelle und beste Richtlinienmodelle bewertet.
Papier und detaillierte Interpretation:https://go.hyper.ai/RoY2u
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








