Command Palette
Search for a command to run...
4-stufige Bildausgabe/4K-Qualität/6-fache Beschleunigung, PiD Verwendet Pixeldiffusion Zur Vereinheitlichung Von Dekodierung Und Superauflösungsausgabe; SA-3DAO: Ein Datensatz Mit 1000 Paaren Realer Bilder, Die Mit Von Künstlern Handgefertigten 3D-Netzen Gepaart sind.

PiD ist ein neues Paradigma zur Dekodierung latenter Räume von NVIDIA. Es definiert den traditionellen VAE-Dekodierungsprozess als bedingte Pixeldiffusionsgenerierung neu und vereint Dekodierung und Super-Resolution-Upsampling in einem einzigen Generierungsmodul. Traditionelle Modelle der latenten Diffusion stellen latente Variablen mittels VAE im Bild wieder her, was zu einer begrenzten Ausgabeauflösung führt. Darüber hinaus haben rekonstruktionsorientierte Decoder Schwierigkeiten, hochfrequente Details wiederherzustellen und Artefakte in latenten Variablen zu korrigieren.PiD führt einen leichtgewichtigen, rauschsensitiven latenten Variablenadapter (Sigma-sensitiver Adapter) ein, um verrauschte latente Variablen in das Pixel Spatial Diffusion Backbone-Netzwerk einzuspeisen.Dies ermöglicht dem Modell, sowohl vollständig entrauschte latente Variablen zu verarbeiten als auch den Diffusionsprozess für teilweise entrauschte latente Variablen vorzeitig zu beenden. Mithilfe der DMD2-Destillationstechnologie kann die Inferenz in nur vier Entrauschungsschritten abgeschlossen werden.
Auf der HyperAI-Website wird jetzt „PiD: 4K Super-Resolution Image Generation and Editing“ vorgestellt – probieren Sie es doch gleich aus!
Online-Nutzung:https://go.hyper.ai/a34Cx
Besuchen Sie unsere offizielle Website für weitere Informationen:
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 19. bis 26. Juni:
* Hochwertige öffentliche Datensätze: 7
* Eine Auswahl hochwertiger Tutorials: 14
* Interpretation von Community-Artikeln: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. SAM 3D Artist Objects 3D-Objektrekonstruktionsdatensatz
SAM 3D Artist Objects ist ein Datensatz mit 3D-Netzpaaren, der von Meta im Juni 2026 veröffentlicht wurde. Er dient der Evaluierung der Leistungsfähigkeit von 3D-Rekonstruktionsalgorithmen für Objektformen und -anordnungen in realen Szenen und wird häufig für Leistungstests von Bild-zu-3D-Objekt-Algorithmen, Modelloptimierung und verwandte Forschungsarbeiten im Bereich Computer Vision verwendet. Dieser Datensatz enthält 1.000 Paare aus realen Bildern und von professionellen Künstlern handgefertigten 3D-Netzen.
Online-Nutzung:https://go.hyper.ai/rn2aF
2. RHELM-Datensatz zur Langzeitgedächtnisbewertung
RHELM ist ein von Microsoft im Jahr 2026 veröffentlichter Datensatz zur Langzeitgedächtnisbewertung. Er zielt darauf ab, das Langzeitgedächtnis, das mehrstufige Schließen und die Synthese zeitlicher Informationen großer Modelle in komplexen und dynamischen Szenarien zu verbessern. Dieser Datensatz findet breite Anwendung in Forschungsbereichen wie der Bewertung des zeitlichen Langzeitgedächtnisses großer Sprachmodelle, der Überprüfung der Langzeitinteraktionsfähigkeiten von KI-Assistenten, dem mehrstufigen Schließen großer Modelle, der Fusion zeitlicher Informationen und der Halluzinationserkennung.
Online-Nutzung:https://go.hyper.ai/OGkUl
3. MAKIEVAL-Datensatz zur Bewertung mehrsprachigen kulturellen Wissens
MAKIEVAL ist ein mehrsprachiger Datensatz zur Evaluierung kulturellen Wissens, der 2026 vom MaiNLP-Forschungslabor der Universität München in Zusammenarbeit mit dem Munich Machine Learning Center veröffentlicht wurde. Er dient als umfangreicher Benchmark für die Evaluierung mehrsprachigen kulturellen Wissens für große Sprachmodelle und findet breite Anwendung in der Forschung zur mehrsprachigen Wissensrepräsentation und zur Modellierung kulturellen Wissens. Der Datensatz enthält Texte, die von sieben großen Sprachmodellen in 13 Sprachen, 19 Ländern/Regionen und 6 Kulturbereichen generiert wurden, sowie die automatisch extrahierten kulturellen Entitäten und die Ergebnisse des Abgleichs mit Wikidata.
Online-Nutzung:https://go.hyper.ai/v7zip
4. Datensatz zur Extraktion von Beweisen für Abfragebedingungen mit wörtlichen Spannen
Verbatim Spans, im April 2026 von der TU Wien in Zusammenarbeit mit KRLabs veröffentlicht, ist ein Datensatz zur domänenübergreifenden Extraktion bedingter Evidenz. Er dient als allgemeiner Benchmark für das Training von Modellen zur Extraktion bedingter Evidenz und ist breit anwendbar für Retrieval Augmentation (RAG) und extraktiven Frage-Antwort-Aufgaben. Der Datensatz umfasst 174.383 Zeilen Trainingsdaten und 20.174 Zeilen Validierungsdaten und deckt drei Hauptkorpora ab: wissenschaftliche Arbeiten zur Verarbeitung natürlicher Sprache, domänenübergreifende Frage-Antwort-Systeme sowie Code- und Tool-Ausgaben.
Online-Nutzung:https://go.hyper.ai/hbpjR
5. Nemotron-SFT-Math-v4 Mathematische Inferenz SFT-Datensatz
Nemotron-SFT-Math-v4 ist ein Datensatz für mathematisches Schlussfolgern, der von NVIDIA im Mai 2026 veröffentlicht wurde. Er zielt darauf ab, die Probleme inkonsistenter Qualität, nicht standardisierter Schlussfolgerungspfade, geringer Genauigkeit und begrenzter Szenariovielfalt traditioneller mathematischer Datensätze zu beheben und so die Fähigkeiten des Modells in Bezug auf strukturiertes Schlussfolgern, Multi-Trajektorien-Schlussfolgern und Antwortverifizierung effektiv zu verbessern. Dieser Datensatz enthält 545.431 Trainingsbeispiele, darunter 285.516 Beispiele für inhaltsorientiertes Schlussfolgern (COT) und 259.915 Beispiele für das Tracking-Inference-Tool (TIR). Er deckt mathematische Szenarien auf Wettbewerbs- und Forschungsniveau in Algebra, Geometrie, Zahlentheorie, Kombinatorik und anderen Gebieten ab.
Online-Nutzung:https://go.hyper.ai/6ooPw
6. Auswirkungen von KI auf Arbeitsplätze und Entlassungsrisiko: KI-gestützter Datensatz zu den Auswirkungen auf die Beschäftigung
Der Datensatz „KI-Auswirkungen auf Arbeitsplätze und Entlassungsrisiko“ ist ein synthetisches, strukturiertes Machine-Learning-Datenset, das die Auswirkungen künstlicher Intelligenz auf die Beschäftigung untersucht. Er erforscht den Einfluss von KI-Einführung, Automatisierung von Arbeitsplätzen, Arbeitsplatzmerkmalen und Qualifikationen der Arbeitskräfte auf die Beschäftigungsergebnisse in der modernen Wirtschaft. Der Datensatz findet breite Anwendung in Bereichen wie Klassifizierungsmodellierung, Arbeitsmarktanalyse, Automatisierungsforschung und Personalmanagement.
Online-Nutzung:https://go.hyper.ai/38bZl
7. Globaler Klima- und Energiewandel 2000 – 2026 Globaler Klima- und Energiedatensatz
Der Datensatz „Globaler Klimawandel und Energiewandel 2000–2026“ dient der Forschung zu Klimawandel, Energiewende und CO₂-Emissionsreduktion und zielt darauf ab, die globalen Klima- und Energiewendeprozesse systematisch darzustellen. Er erfasst diese Prozesse von 2000 bis 2026 und deckt globale sowie regionale Temperaturabweichungen ab.
Online-Nutzung:https://go.hyper.ai/ogrSa
Ausgewählte öffentliche Tutorials
1. PiD: 4K-Superauflösungsbildgenerierung und -bearbeitung
PiD ist ein sofort einsatzbereiter Super-Resolution-Decoder des NVIDIA-Teams. Herkömmliche Diffusionsmodelle verwenden einen VAE-Decoder, um die latente Repräsentation eines Bildes wiederherzustellen, wobei die Ausgabeauflösung auf etwa 1024 Pixel begrenzt ist. PiD ersetzt den letzten Schritt der VAE-Dekodierung durch einen Diffusionsprozess im Pixelraum. Dadurch sind nur vier Entrauschungsschritte erforderlich, um direkt ein klares 4K-Bild ohne Nachbearbeitung zu erzeugen. PiD durchbricht somit den Auflösungsengpass herkömmlicher Methoden, ohne die ursprüngliche Modellarchitektur zu verändern.
Online ausführen:https://go.hyper.ai/a34Cx
2. LTX-2.3-Turbo-Videogenerator
LTX-2.3-turbo ist ein Open-Source-Videogenerierungsmodell, das von Lightricks im März 2026 veröffentlicht wurde und die Grenzen der Open-Source-Videogenerierungsmöglichkeiten erweitern soll. Dieses Modell nutzt eine fortschrittliche Diffusionstransformator-Architektur und kombiniert diese mit multimodalen Analysefunktionen, um qualitativ hochwertige Videoinhalte in verschiedenen Auflösungen zu generieren.
Online ausführen: https://go.hyper.ai/oepch
3. DiffBrush: Generieren handgeschriebener Textzeilen
Die Nankai-Universität und Kunlun Tech veröffentlichten im August 2025 gemeinsam das DiffBrush-Modell zur Generierung handgeschriebener Textzeilen. Es wurde im Oktober desselben Jahres offiziell von der ICCV 2025 angenommen. Basierend auf der Stable Diffusion VAE+UNet-Architektur unterstützt das Modell beliebige englische Texteingaben und 496 Handschriftstile aus dem IAM-Datensatz und gibt ein 1024×64 Pixel großes Graustufenbild aus. Textinhalt und Handschriftstil sind unabhängig voneinander steuerbar. Die Implementierung ist ressourcenschonend und das Modell kann direkt für die Generierung von OCR-Trainingsdatensätzen, die Erweiterung handgeschriebener Daten und die Dokumentensimulation verwendet werden.
Online ausführen: https://go.hyper.ai/qVvl5
4. Wiederverwendung: Ein allgemeines Sprachverbesserungsmodell
RE-USE ist ein universelles Sprachverbesserungsmodell, das von NVIDIA im März 2026 veröffentlicht wurde. Es basiert auf der Mamba-Architektur, kann verrauschte Sprachsignale mit verschiedenen Abtastraten und Beeinträchtigungsarten verarbeiten und ist sprachunabhängig.
Online ausführen:https://go.hyper.ai/MJ0p5
5. TADA-1b: Einheitliches Sprachsprachmodell
TADA-1b ist ein einheitliches Sprachmodell, das vom HumeAI-Team im Februar 2026 veröffentlicht wurde und speziell für Audiogenerierungsaufgaben wie Sprachsynthese, Sprachklonung und mehrsprachige Synchronisation entwickelt wurde. Basierend auf Llama 3.2-1B zeichnet sich dieses Modell durch geringes Speichervolumen, hohe Geschwindigkeit und stabile Audiogenerierung aus und eignet sich für englische Text-to-Speech (TTS), Zero-Shot-Sprachklonung, längere Erzählungen und Sprachfortsetzung.
Online ausführen: https://go.hyper.ai/nCSpT
6. Gsplat 3D-Gaußsches-Splash-Training und -Visualisierung
Gsplat ist eine Open-Source-Bibliothek für 3DGS-Rasterisierung mit CUDA-Beschleunigung, die von Berkeley, NVIDIA, der ShanghaiTech University und weiteren Institutionen gemeinsam entwickelt wurde. Basierend auf der ursprünglichen Implementierung wurde sie umfassend optimiert, wodurch der Speicherbedarf für das Training um das Vierfache reduziert und die Trainingszeit um 151 TP3T verkürzt wurde. Zu den wichtigsten technischen Merkmalen gehören: eine hocheffiziente CUDA-basierte differentielle Rasterisierungs-Engine, eine adaptive Strategie zur Steuerung der Gaußschen Dichte, ein flexibles Daten-Backend, das mit gängigen Datenformaten wie COLMAP kompatibel ist, und eine Echtzeit-Webvisualisierungsschnittstelle auf Basis von Viser. Anwendungsszenarien umfassen digitale Zwillinge, die Umgebungserkennung für autonomes Fahren, die Digitalisierung von Kulturgütern und die visuelle Synthese im E-Commerce.
Online ausführen: https://go.hyper.ai/Zihdr

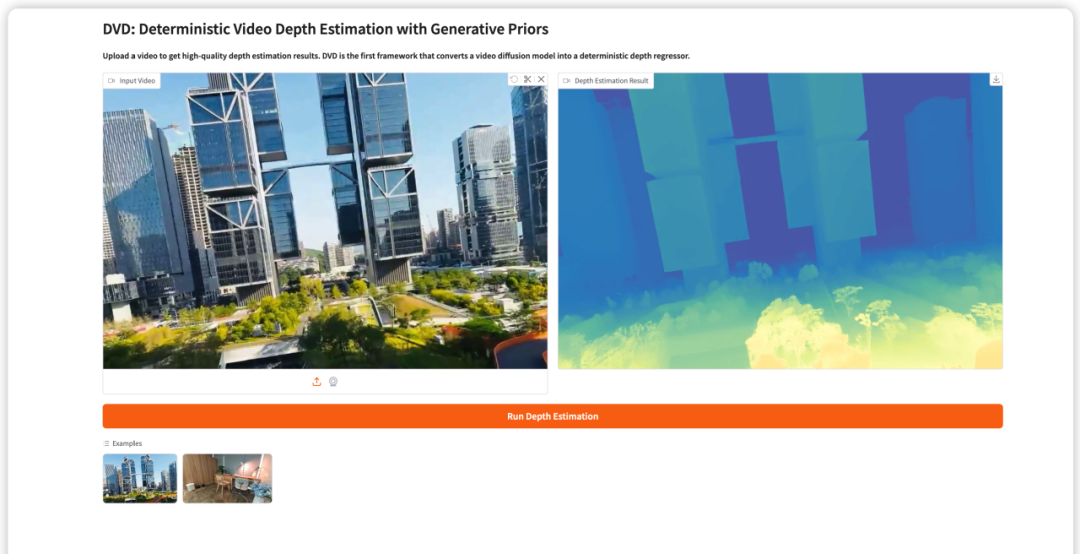
7. DVD: Deterministische Videotiefenschätzung basierend auf generativen Priors
DVD (Deterministic Video Depth Estimation) ist das erste deterministische Videotiefenschätzungs-Framework, das im März 2026 vom Team der Hong Kong University of Science and Technology (Guangzhou) vorgestellt wurde. Durch die Umwandlung des vortrainierten Videodiffusionsmodells (Wan2.1) in einen einfachen Vorwärtspropagierungs-Tiefenregressor wird das durch Zufälligkeit verursachte Problem der geometrischen Illusion vollständig beseitigt, während gleichzeitig die starke semantische Vorinformation des generativen Modells erhalten bleibt.
Online ausführen:https://go.hyper.ai/AisLp
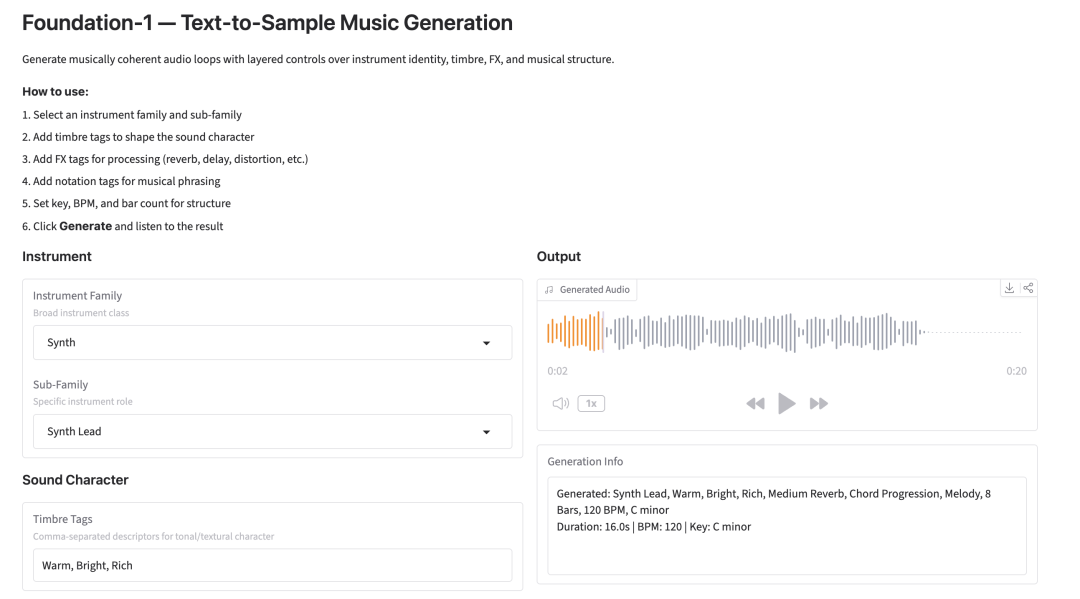
8. Grundlagen-1: Strukturierte Text-zu-Musik-Beispielgenerierung
Foundation-1, im März 2026 vom RoyalCities-Team veröffentlicht, ist ein Text-zu-Sample-Audiogenerierungsmodell für professionelle Musikproduktions-Workflows. Die offizielle Version unterstützt die mehrschichtige, steuerbare Generierung und ermöglicht es Nutzern, Instrumentenfamilien, Subgenres, Klangfarben, Effekte, theoretische Akkorde, Tempo/Tonart und Taktlängen individuell anzupassen, um rhythmisch synchronisierte und tonal aufeinander abgestimmte Musikloops zu erzeugen. Darüber hinaus bietet die Software eine einheitliche Webdemo mit umfassenden interaktiven Generierungsfunktionen.
Online ausführen: https://go.hyper.ai/NxUAC
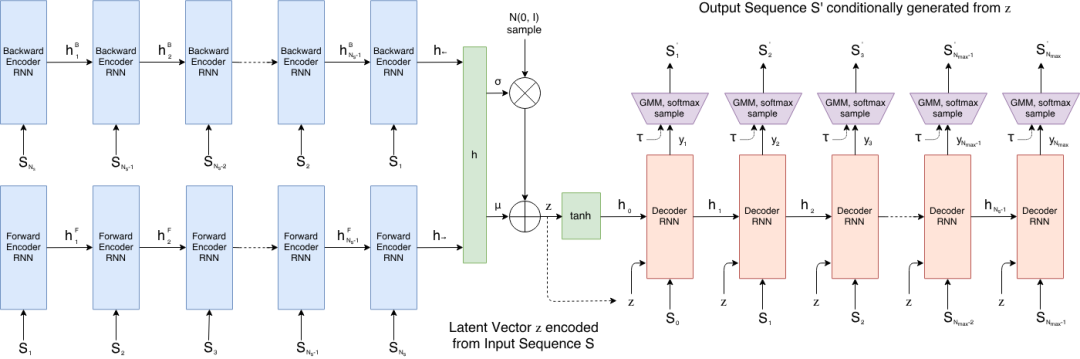
9. Sketch-RNN: Vektorskizzengenerierung und latente räumliche Interpolation
Sketch-RNN ist ein Vektorskizzensequenz-Generierungsmodell, das 2017 vom Google Brain-Team veröffentlicht wurde. Diese Methode ist speziell für handgezeichnete Skizzendaten konzipiert, die Strichversätze und Stiftzustandsinformationen enthalten. Sie kann sukzessive latente Repräsentationen von Skizzen lernen und neue Vektorskizzensequenzen generieren. Sketch-RNN verwendet eine Encoder-Decoder-Architektur. Es bildet die Eingabeskizze auf einen latenten Raum ab und verwendet anschließend einen rekurrenten neuronalen Netzwerk-Decoder, um schrittweise Striche zu generieren.
Online ausführen: https://go.hyper.ai/HmcT9
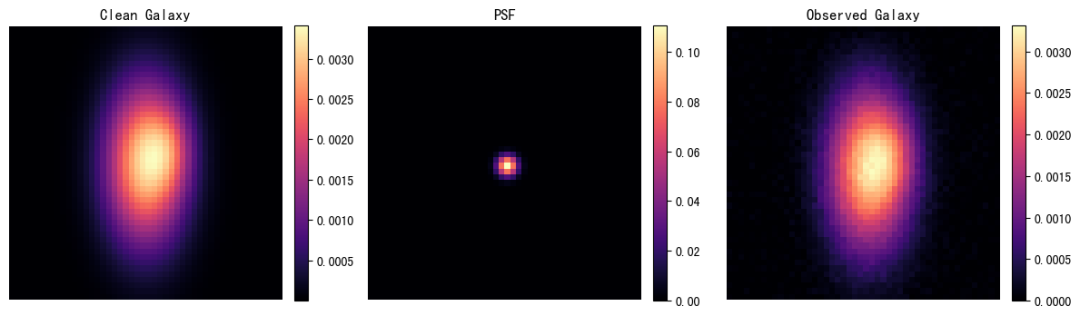
10. Galaxy-Deconv: Ein Dekonvolutionsrahmen für Galaxienbilder mit schwacher Gravitationslinsenwirkung
Galaxy-Deconv wurde von Tianyao Li (Tsinghua-Universität) und Emma Alexander (Northwestern University) entwickelt. Das Projekt konzentriert sich auf die Bildrestaurierung schwach gravitativ verzerrter Galaxien. Es verwendet den entfalteten Plug-and-Play-ADMM-Algorithmus zur Dekonvolution von Galaxienbildern, die durch PSF-Unschärfe (Punktspreizfunktion) und Rauschen beeinträchtigt sind. Dieses Tutorial fasst gängige Arbeitsabläufe zur Galaxiendekonvolution in einem Notebook zusammen und behandelt Bildsimulation, das Laden von COSMOS-Daten, Dekonvolutionsinferenz, die Überprüfung des HDF5-Datensatzes sowie grundlegende Dekonvolutionsübungen.
Online ausführen: https://go.hyper.ai/qGvI1
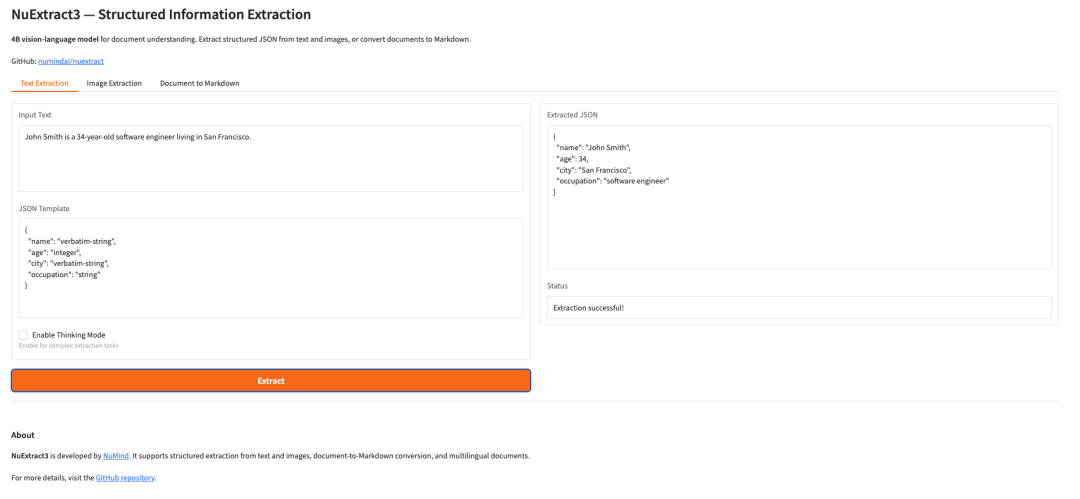
11. NuExtract3: Ein multimodales Dokumentenverständnis- und strukturiertes Informationsextraktionsmodell
NuExtract3 ist ein multimodales visuelles Sprachmodell mit 4 Milliarden Parametern, das von NuMind im Juni 2026 veröffentlicht wurde und speziell für das Dokumentenverständnis entwickelt wurde. Das Modell integriert die Extraktion strukturierter Informationen und die Konvertierung von Dokumentbildern in Markdown, unterstützt Text-, Bild- und gemischte Text-Bild-Eingaben und kann direkt strukturierte Ergebnisse basierend auf benutzerdefinierten JSON-Vorlagen ausgeben, wobei Tabellen, Formeln und Layoutinformationen vollständig erhalten bleiben.
Online ausführen:https://go.hyper.ai/xirTj
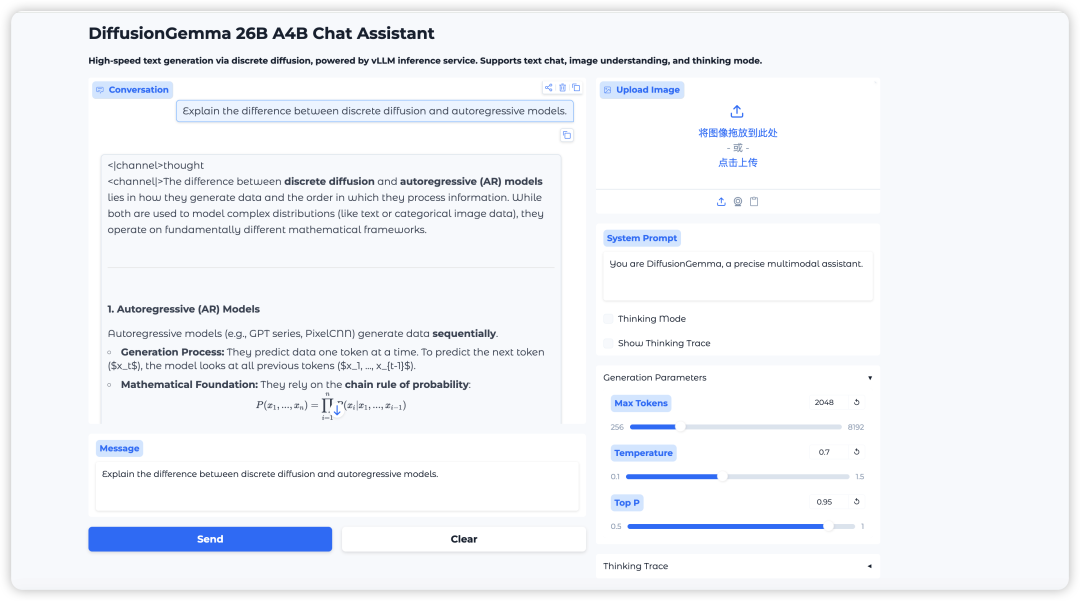
12. DiffusionGemma: Ein Hochgeschwindigkeits-Textgenerierungsmodell basierend auf diskreter Diffusion
DiffusionGemma ist ein von Google DeepMind entwickeltes Textgenerierungsmodell, das auf diskreten Diffusionstechniken basiert. Es verwendet eine Mixture-of-Experts-Architektur (MoE) mit 26 Milliarden Parametern, von denen insgesamt 25,2 Milliarden Parameter berechnet werden, von denen jedoch nur 3,8 Milliarden gültig sind. Durch paralleles Block-Level-Diffusion-Sampling erreicht es extrem hohe Textgenerierungsgeschwindigkeiten und generiert über 1100 Token pro Sekunde auf einer einzelnen H100-GPU.
Online ausführen: https://go.hyper.ai/HV3eM
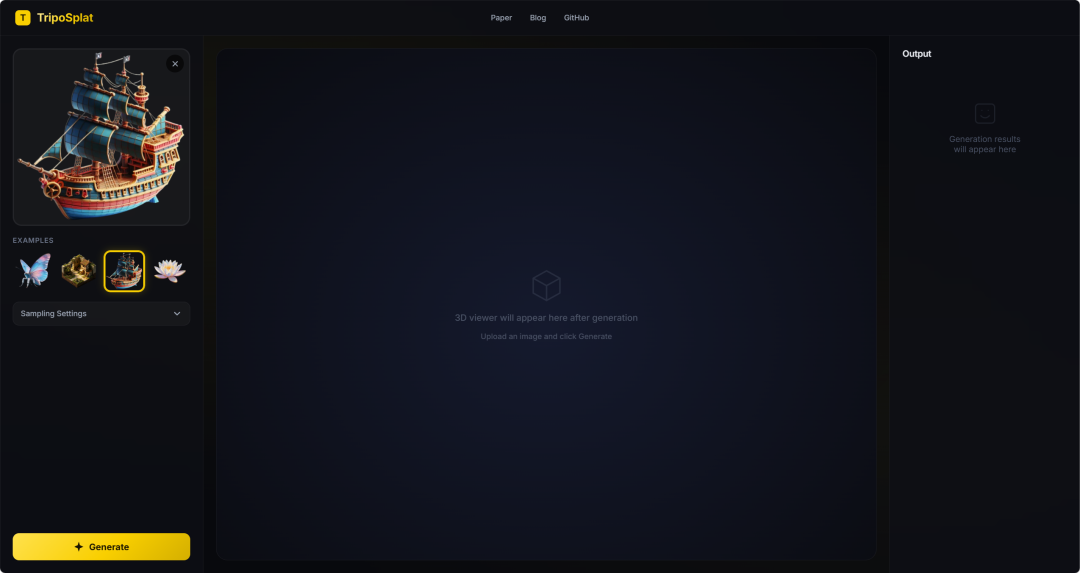
13. TripoSplat: Generieren Sie hochwertige 3D-Gaußsche Assets aus einem einzigen Bild.
TripoSplat ist eine Methode zur Generierung von 3D-Gaußverteilungen aus Einzelbildern, die im Mai 2026 von VAST-AI Research und TripoAI gemeinsam veröffentlicht wurde. Das Modell wandelt ein einzelnes 2D-Bild in ein hochwertiges 3D-Gaußverteilungsmodell um und ermöglicht die Kontrolle der Anzahl der Gaußverteilungen. Es verwendet die Density-Sampled Gaussian (DeG)-Technologie, verteilt die Gaußverteilungszentren adaptiv entsprechend der geometrischen Komplexität des Objekts und nutzt VecSeq zur deterministischen Neuordnung ungeordneter latenter Variablen, wodurch die Stabilität des Generierungsprozesses verbessert wird.
Online ausführen: https://go.hyper.ai/wOxUG
14. North Mini Code 1.0: Ein Agentenmodell für Codegenerierung und Softwareentwicklungsaufgaben
North Mini Code 1.0 ist ein offenes, gewichtetes Code-Modell, das von Cohere und Cohere Labs im Juni 2026 veröffentlicht wurde und für Codegenerierung, Endpunktaufgaben und Softwareentwicklungsszenarien für Agenten optimiert ist. Das Modell unterstützt lange Codierungssitzungen, Code-Argumentation, Tool-Aufrufe und verschachteltes Denken und eignet sich hervorragend für die Implementierung von Funktionen, das Schreiben von Skripten, das Debuggen, die Planung von Endpunktaufgaben und mehrstufige Softwareentwicklungs-Workflows.
Online ausführen: https://go.hyper.ai/ycCuG

💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~
Interpretation von Gemeinschaftsartikeln
1. MIT/IBM hat ChartNet veröffentlicht, den bisher größten synthetischen Chart-Datensatz mit 1,5 Millionen verschiedenen Chart-Beispielen.
Eine Expertengruppe des MIT, des MIT-IBM Computing Research Lab und von IBM Research hat ChartNet entwickelt – einen hochwertigen, multimodalen Datensatz mit Millionen von Datensätzen zum Verständnis von Graphen, der die Fähigkeiten zum Verständnis und zur logischen Argumentation von Graphen verbessern soll.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Kk87Q
2. Die neueste Veröffentlichung von Google DeepMind enthüllt das ultimative Ziel der KI: Von AGI zu ASI gibt es 4 Wege und 6 Hürden.
Google DeepMind hat in Zusammenarbeit mit mehreren führenden Universitäten eine neue Studie veröffentlicht, die sich mit den grundlegenden Fragen rund um die Entwicklung von Künstlicher Allgemeiner Intelligenz (AGI) zu Künstlicher Superintelligenz (ASI) auseinandersetzt. Die Studie betrachtet Intelligenz als Kontinuum und analysiert systematisch die potenziellen Entwicklungspfade und Herausforderungen, denen KI nach Übertreffen des durchschnittlichen menschlichen Niveaus begegnen wird. Die Studie bietet eine strukturierte und objektive Grundlage für das Verständnis der langfristigen Entwicklung von KI.
Den vollständigen Bericht ansehen:https://go.hyper.ai/AOObx
3. Durch die Nutzung der umfangreichen Kontextanalysefähigkeiten von Gemini 1.5 erreichte Googles dialogbasiertes Gesundheitssystem AMIE in 100 Szenarien mit mehreren Patientenbesuchen das Denkvermögen eines Allgemeinmediziners.
Eine aktuelle Studie von Google DeepMind und Google Research hat ein neuartiges, auf dem LLM-Modell basierendes intelligentes Agentensystem weiterentwickelt, das auf ihrem dialogorientierten Gesundheitssystem AMIE aufbaut. Dieses System ermöglicht klinisches Management und optimiert den Arzt-Patienten-Dialog für verschiedene Nachsorgeszenarien. AMIE nutzt die umfangreichen Kontextinformationen des Gemini-Modells und kombiniert kontextbezogene Abfrage mit strukturiertem Schließen, um sicherzustellen, dass die Ergebnisse den neuesten klinischen Leitlinien und Arzneimittelkatalogen entsprechen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/65aHo
4. Die KI der Materialwissenschaften bewegt sich auf eine „erklärbare Ära“ zu: Ein japanisches Team knackt die Blackbox der hochdimensionalen Spektroskopie und identifiziert Schlüsselmerkmale für die Entdeckung neuer Materialien.
Ein Forschungsteam des Tokyo Institute of Science in Japan hat eine Methode zur Interpretation von Deep-Learning-Modellen entwickelt, die hochdimensionale Spektraldaten in der Materialwissenschaft verarbeiten kann. Die Forscher erstellten einen Datensatz mittels Ab-initio-Berechnungen, der die optischen Absorptionsspektren von 2681 Oxiden, Chalkogeniden und verwandten Verbindungen enthält. Im Vergleich zu Standard-Dichtefunktionalrechnungen zeigen die berechneten Ergebnisse nach Korrektur der spektralen Einsatzenergie und Form eine deutlich verbesserte Übereinstimmung mit publizierten experimentellen Spektren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/VJbaU
Beliebte Enzyklopädieartikel
1. Großes Sprachmodell (LLM)
2. Struktur
3. Weltaktionsmodell (WAM)
4. Rotationspositionskodierung (RoPE)
5. Groß angelegtes Multitasking-Sprachverständnis (MMLU)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








