Command Palette
Search for a command to run...
MiniCPM5-1B, Trainiert Mit RL+OPD, Erzielt Bestleistungen (SOTA) Bei Mehreren Komplexen Aufgaben; Der CHI-Bench-Datensatz Zur Evaluierung Von Medizinischen Agenten, Der Für Die Automatisierung Komplexer Prozesse Im Gesundheitswesen Entwickelt Wurde, Wurde veröffentlicht.

MiniCPM5-1B ist ein Open-Source-Sprachmodell mit einer Milliarde Parametern, das für den Einsatz in Edge-Umgebungen und ressourcenbeschränkten Szenarien entwickelt wurde. Es ist das erste Modell der MiniCPM5-Serie. Basierend auf der Standard-Llama-Architektur bietet es unter anderem folgende Funktionen: … Ein hybrides Inferenzparadigma basierend auf Tags. Darüber hinaus nutzt dieses Modell fortschrittliche RL+OPD-Trainingstechniken, um die Kernleistung deutlich zu verbessern und gleichzeitig Ausgaberedundanz effektiv zu eliminieren. Es unterstützt nativ extrem lange Kontexte von bis zu 131.000 Zeichen.Es hat bei komplexen Aufgaben wie dem Aufruf von Agenten und der Codesynthese einen Stand der Technik (SOTA) von 1B erreicht.Dieses Modell umgeht effektiv die Latenz- und Datenschutzprobleme cloudbasierter Inferenz und bietet somit eine ideale Lösung für den Aufbau einer effizienten lokalen KI-Plattform.
Auf der HyperAI-Website wird jetzt „MiniCPM5-1B: Ein hocheffizienter 1B-LLM für Edge-Anwendungen“ vorgestellt. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/OBlhv
Besuchen Sie unsere offizielle Website für weitere Informationen:
Ein kurzer Überblick über die Aktualisierungen der hyper.ai-Website vom 30. Mai bis zum 5. Juni:
* Hochwertige öffentliche Datensätze: 6
* Eine Auswahl hochwertiger Tutorials: 5
* Analyse von Community-Artikeln: 1 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Chi-Bench Medical Intelligent Agent Benchmark Evaluation Dataset
Chi-Bench ist ein von Actava AI im Jahr 2026 veröffentlichter Datensatz zur Evaluierung von Systemen im Gesundheitswesen. Dieser Datensatz bildet eine hochrealistische Simulationsumgebung für den Gesundheitssektor ab, indem er 20 Anwendungssysteme des Gesundheitswesens über die offene MCP-Schnittstelle (Model Context Protocol) integriert und eine Wissensbasis mit 1.279 Dokumenten zu Abläufen im Gesundheitswesen bereitstellt. Die Evaluierungsszenarien decken drei Hauptbereiche des US-amerikanischen Gesundheitssystems ab: Vorabgenehmigungsmanagement, Zitationsmanagement für Krankenversicherungen/Versicherer und Bevölkerungsmanagement.
Online-Nutzung:https://go.hyper.ai/j8pCr
2. SMOL Multilingual Translation Parallel Dataset
SMOL ist ein professioneller Übersetzungsdatensatz, der 2025 von Google veröffentlicht wurde. Er enthält professionell übersetzte Texte in 221 Sprachen, darunter Amharisch, Suaheli und Afar, sowie weniger häufig annotierte/regionale Sprachen mit geringer Datenbasis. Der Datensatz deckt ein breites Spektrum an Sprachpaaren ab, darunter sowohl professionelle Übersetzungen als auch von Freiwilligen beigesteuerte Texte. Für einige Sprachen enthält er zudem vertikale Daten und sachliche Annotationen mit Bezug zum medizinischen Bereich.
Online-Nutzung:https://go.hyper.ai/84QS4
3. TACK Targeted Chimera Knowledge Base Dataset
TACK ist ein standardisierter Wissensdatenbank-Datensatz und Benchmark-Satz, der 2026 vom AI Laboratory for Molecular Engineering veröffentlicht wurde. Er zielt darauf ab, die Probleme der Datenknappheit, des Mangels an strengen Evaluierungen und der begrenzten Abdeckung bestehender PROTAC-Benchmarks für maschinelles Lernen zu beheben. TACK findet breite Anwendung in Bereichen wie der Vorhersage der PROTAC-Abbauaktivität, der Forschung zum gezielten Proteinabbau (TPD), der KI-gestützten Wirkstoffentwicklung (AIDD), dem computergestützten Wirkstoffdesign (CADD), dem virtuellen Wirkstoffscreening, dem Multitask-Learning, der Vorhersage molekularer Eigenschaften, der Forschung zu Graph-Neuronalen Netzen und dem Testen von Benchmarks für maschinelles Lernen.
Online-Nutzung:https://go.hyper.ai/7gDJu
4. EAVSD E-Commerce-Werbevideo-Storyboard-Datensatz
EAVSD ist ein Datensatz für Storyboards von E-Commerce-Werbevideos, der 2026 von einem Team der Peking-Universität veröffentlicht wurde. Er dient der Unterstützung themenorientierter Mehrbildgenerierung und narrativer Planungsaufgaben. Dieser Datensatz wird häufig für diese Aufgaben eingesetzt, insbesondere für die Generierung von Storyboards für E-Commerce-Werbevideos und die Forschung zur kontrollierten visuellen Konsistenz über längere Zeiträume.
Online-Nutzung:https://go.hyper.ai/hyzLx
5. DeepCrack-Datensatz zur Erkennung von Infrastrukturrissen
DeepCrack ist ein Benchmark-Datensatz zur Erkennung von Infrastrukturrissen, der vom Labor für Computer Vision und Fernerkundung der Universität Wuhan bereitgestellt wird. Er dient der Bereitstellung standardisierter und hochpräziser Daten für überwachtes Lernen im Rahmen der Forschung zu Algorithmen der Risserkennung. DeepCrack kann direkt zum Training und zur Evaluierung von Deep-Learning-Modellen wie U-Net, DeepLab und SegNet verwendet werden und findet breite Anwendung in Forschungsbereichen wie der Zustandsüberwachung von Bauwerken, der Straßeninspektion und der Identifizierung von Gebäudefehlern.
Online-Nutzung:https://go.hyper.ai/88zlH

6. Weltweiter Datensatz zur Luftverschmutzung und zum Luftqualitätsindex
Der Datensatz „World Air Pollution and AQI“ ist ein globaler Datensatz zur Luftqualität für Forschung und Datenanalyse. Er enthält monatliche Messdaten auf Stadtebene aus dem Zeitraum von 2014 bis 2025 mit insgesamt 331.920 Datensätzen aus 24 Ländern auf fünf Kontinenten, darunter China, die USA, Großbritannien, Frankreich, Deutschland, Japan und Südkorea. Der Datensatz umfasst 24 Merkmale, darunter Schadstoffkonzentrationen, den Luftqualitätsindex, meteorologische Variablen sowie soziale und ökologische Indikatoren.
Online-Nutzung:https://go.hyper.ai/QL8VK
Ausgewählte öffentliche Tutorials
1. MiniCPM5-1B: Hocheffizienter 1B-LLM für Anwendungen an der Kante
MiniCPM5-1B ist das erste Modell der MiniCPM5-Serie, das vom OpenBMB-Team veröffentlicht wurde. Es ist für den Einsatz in Edge-Umgebungen und ressourcenbeschränkten Szenarien konzipiert. Es verwendet eine parametrisierte Transformer-Architektur mit 1 Milliarde Parametern und erzielt im Vergleich zu anderen Open-Source-Modellen gleicher Größe eine herausragende Leistung. Es eignet sich besonders gut für agentenbasierte Tool-Aufrufe, Codegenerierung und anspruchsvolle Inferenzaufgaben.
Online ausführen:https://go.hyper.ai/OBlhv
2. HiDream-O1-Image Bildgenerierungssystem
HiDream-O1-Image ist ein natives, einheitliches Bildgenerierungsmodell, das 2026 vom HiDream.ai-Team eingeführt wurde. Das Modell basiert auf einer pixelgenauen, einheitlichen Transformer-Architektur (UiT). Im Gegensatz zu herkömmlichen Modellen benötigt es keine externen VAEs oder separate Textkodierer, sondern kodiert Pixel und Text nativ in einem einzigen, gemeinsamen Tokenraum.
Online ausführen:https://go.hyper.ai/XkyGK
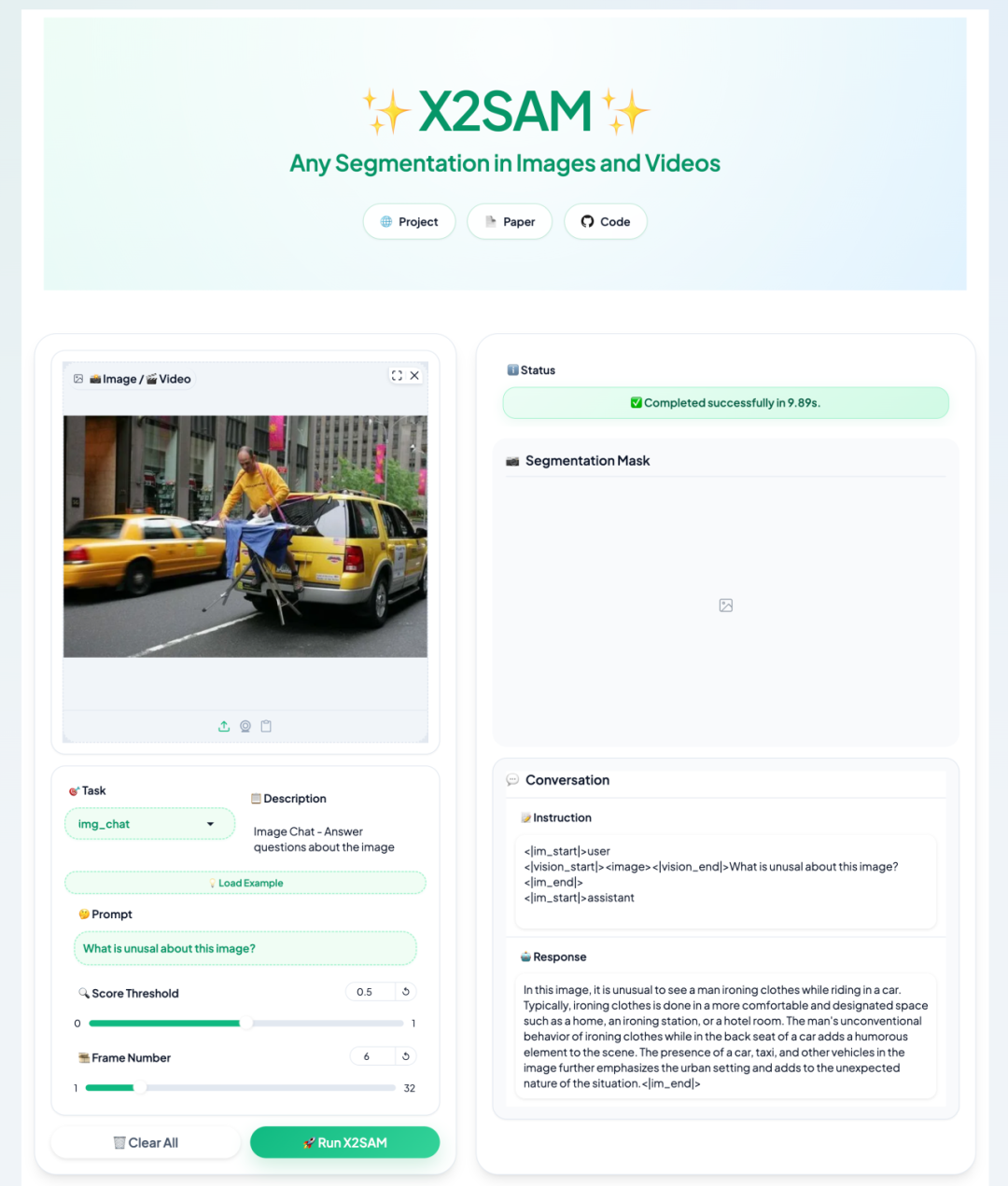
3. X2SAM: Ein einheitliches Modell für die Segmentierung beliebiger Bilder und Videos
X2SAM, im April 2026 von der Sun-Yat-sen-Universität, dem Pengcheng-Labor und dem Meituan-Team veröffentlicht, ist ein multimodales Großmodell für einheitliche Bild- und Videosegmentierungsszenarien. Das Kernmerkmal dieses Projekts ist die Integration von Text- und visuellen Anweisungen sowie der Bild-/Videosegmentierung in einen einzigen interaktiven Prozess.
Online ausführen:https://go.hyper.ai/OAndb
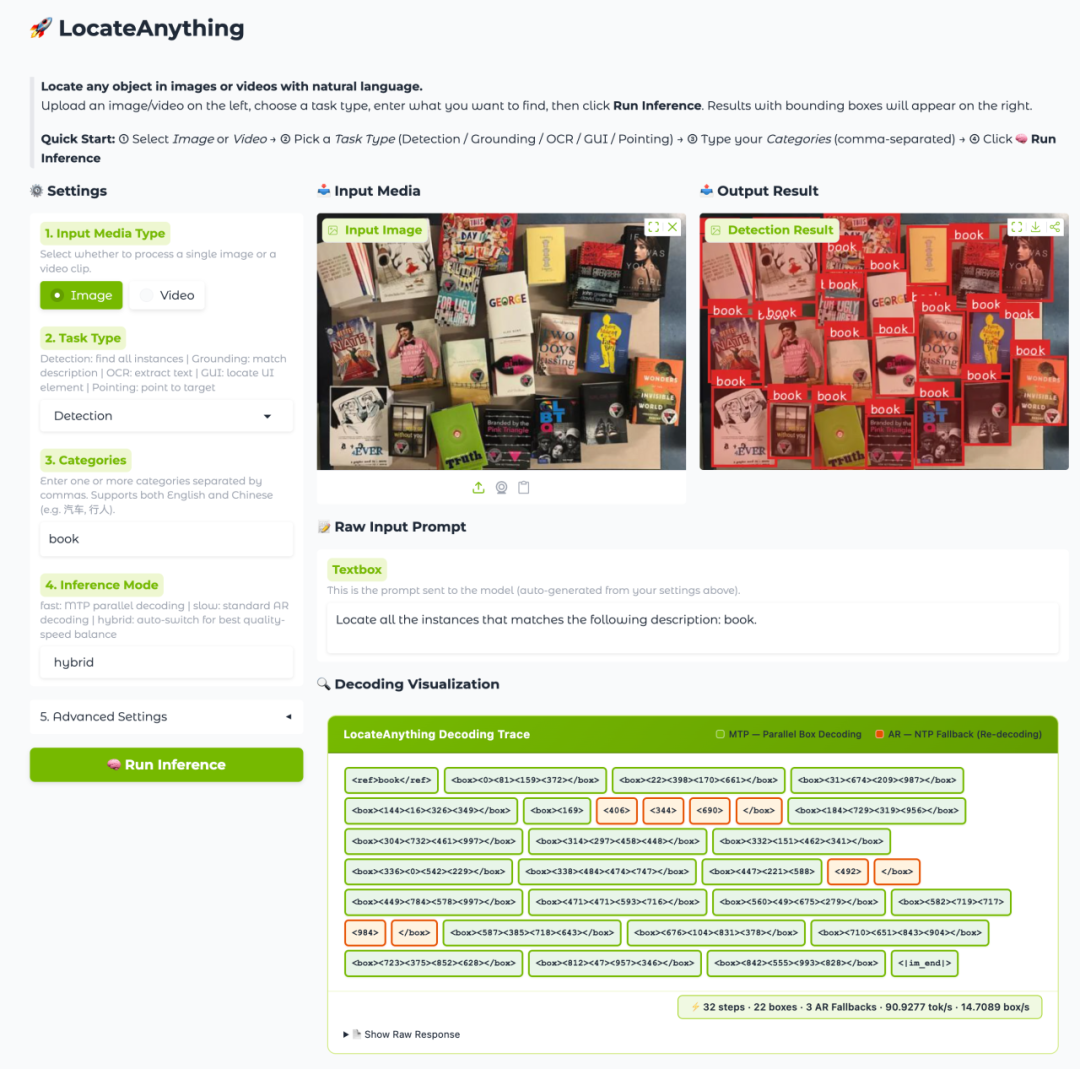
4. LocateAnything-3B: Ein schnelles, hochwertiges visuelles Sprachlokalisierungsmodell
LocateAnything-3B, 2026 von NVIDIA veröffentlicht, ist ein 3B-Parameter-Modell zur Lokalisierung visueller Sprache aus der Eagle VLM-Serie. Es wurde für Aufgaben wie die Erkennung offener Objekte, die Lokalisierung von Punktausdrücken, die OCR-Textlokalisierung, die Lokalisierung von GUI-Elementen sowie das Zeigen in Bildern und Videos entwickelt. Kernmerkmal dieses Modells ist die parallele Box-Dekodierung: Anstatt Koordinaten tokenweise durch Autoregression zu generieren, sagt es vollständige Begrenzungsrahmenkoordinaten als strukturierte Blöcke parallel voraus. Dadurch wird der Lokalisierungsdurchsatz bei gleichzeitiger Wahrung der geometrischen Konsistenz verbessert.
Online ausführen:https://go.hyper.ai/DxUFC
5. Granite 4.1 8B: Unterstützt Dialoge, Kodierung, RAG und Werkzeugaufrufe.
Die Granite 4.1-Sprachmodelle sind eine neue Generation von Open-Source-Basismodellen, die IBM 2026 eingeführt hat. Sie umfassen dichte Decoderarchitekturen in drei Größen: 3B, 8B und 30B. Granite 4.1 8B, die leistungsstärkste Version dieser Reihe, erzielt die für Unternehmensanwendungen erforderliche überragende Performance bei gleichzeitig geringem Parameteraufwand. Dieses Modell unterstützt nativ Mehrsprachigkeit, eine Vielzahl von Kodierungsaufgaben, Retrieval Enhancement Generation (RAG), die Verwendung von Tools und strukturierte JSON-Ausgabe und bietet somit robuste technische Unterstützung für reale Anwendungen.
Online ausführen:https://go.hyper.ai/Fpzl7
Interpretation von Gemeinschaftsartikeln
1. Die Nationale Universität von Singapur schlägt einen KI-gestützten, computergestützten Chemieprozess vor, um die Neupositionierung von Medikamenten zur Wundheilung bei Diabetes zu beschleunigen und den F&E-Zyklus um über 701 TP3T zu verkürzen!
Ein Forschungsteam der National University of Singapore hat einen kollaborativen computergestützten Forschungsprozess für die Nanomedizin vorgeschlagen, der künstliche Intelligenz und Computerchemie (AI-CC) kombiniert. Dieser Prozess verknüpft die Literaturanalyse mithilfe großer Sprachmodelle (qualitative Erkenntnisse) eng mit mehrstufigen, computerchemisch dominierten Molekülsimulationen (quantitative Verifizierung). Dadurch entsteht ein geschlossenes Forschungssystem für die Nano-Interaktionen von Wirkstoffen und Proteinen, das die Neupositionierung und Entwicklung von Medikamenten zur Behandlung diabetischer Wunden beschleunigt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/OXs3N
Beliebte Enzyklopädieartikel
1. Weltaktionsmodell (WAM)
2. Visuelles Sprachaktionsmodell (VLA)
3. Der Mensch im Regelkreis
4. Lernen während der Implementierung
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








