Command Palette
Search for a command to run...
Online-Tutorial | NVIDIA Open Source LocateAnything, Ein 3B-Modell, Das Bild- Und Videozielerkennung, Objekterkennung Mit Offenem Vokabular, Ziellokalisierung, OCR-Textlokalisierung Und Weitere Funktionen ermöglicht.

Da sich visuelle Sprachmodelle (VLMs) in Richtung Agenten, multimodaler Interaktion und realweltlicher Aufgaben weiterentwickeln, ist das „Verstehen von Bildern“ nicht mehr das Endziel; vielmehr geht es darum, das Ziel präzise zu lokalisieren. Dies gilt für die Objekterkennung mit offenem Vokabular, die Bedienung von GUI-Agentenschnittstellen, das Dokumentenverständnis und die Umgebungswahrnehmung in der Robotik und bei autonomen Fahrsystemen.All diese Faktoren stellen immer höhere Anforderungen an die visuelle Orientierungsfähigkeit.
Gängige visuelle Sprachmodelle verwenden jedoch bei Lokalisierungsaufgaben in der Regel ein Verfahren zur „Koordinaten-Token-Generierung“. Dabei wird ein zweidimensionaler Begrenzungsrahmen in mehrere eindimensionale Koordinaten-Tokens zerlegt, die anschließend nacheinander generiert und dekodiert werden. Dieser Ansatz hat nicht nur Schwierigkeiten, die Konsistenz der internen Geometrie des Begrenzungsrahmens zu wahren, sondern auch…Darüber hinaus begrenzt der strikt sequentielle Generierungsmechanismus die Geschwindigkeit des Schlussfolgerns.Wenn ein Modell eine große Anzahl von Zielen gleichzeitig verarbeiten muss, ist es oft schwierig, Lokalisierungseffizienz und Genauigkeit in Einklang zu bringen.
Als Reaktion auf diesen seit langem bestehenden EngpassNVIDIA hat kürzlich ein neues Mitglied der Eagle VLM-Serie – LocateAnything-3B – als Open Source veröffentlicht.Es handelt sich um ein visuelles Sprachlokalisierungsmodell mit 3 Milliarden Parametern, das verschiedene Aufgaben wie die Objekterkennung mit offenem Vokabular, die Lokalisierung von Zeigerausdrücken, die OCR-Textlokalisierung, die Lokalisierung von GUI-Elementen und die Zielmarkierung in Bildern und Videos unterstützt, mit dem Ziel, ein einheitliches visuelles Lokalisierungs- und Erkennungsframework zu schaffen.
Die Kerninnovation von LocateAnything-3B liegt in einem neuen Mechanismus namens Parallel Box Decoding (PBD). Im Gegensatz zu herkömmlichen Methoden, die Koordinaten-Tokens einzeln generieren,PBD kann geometrische Elemente wie Begrenzungsrahmen und Schlüsselpunkte als vollständige Struktur in einem einzigen parallelen Prozess vorhersagen.Dieses Design erhält nicht nur die geometrische Konsistenz innerhalb des Begrenzungsrahmens, sondern verbessert auch den Dekodierungsdurchsatz erheblich, wodurch das Modell eine schnellere Inferenzgeschwindigkeit erreicht und gleichzeitig hochpräzise Lokalisierungsfähigkeiten beibehält.
Neben der architektonischen Innovation entwickelte NVIDIA auch ein umfangreiches Trainingssystem für dieses Modell. Das Forschungsteam entwickelte eine skalierbare Daten-Engine und veröffentlichte den LocateAnything-Data-Datensatz mit über 138 Millionen Trainingsbeispielen aus verschiedenen Bereichen wie Naturszenen, Robotik, autonomes Fahren, GUI-Interaktion, Dokumentenanalyse und OCR. Dadurch wurde die Generalisierungsfähigkeit des Modells in komplexen Szenarien deutlich verbessert.
Experimentelle Ergebnisse zeigen, dass LocateAnything in mehreren Benchmarks zur visuellen Lokalisierung sowohl eine höhere Lokalisierungsqualität als auch eine schnellere Dekodierungsgeschwindigkeit erzielt und damit die traditionellen Kompromisse zwischen Geschwindigkeit und Genauigkeit bei einheitlichen visuellen Lokalisierungsmodellen überwindet. Für die rasche Entwicklung von GUI-Agenten, automatischen Annotationssystemen und multimodalen Agenten der nächsten Generation wird diese effiziente und präzise räumliche Verständnisfähigkeit zu einer kritischen Infrastrukturfunktion.
Aktuell ist im Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) das Projekt „LocateAnything-3B: Ein schnelles und qualitativ hochwertiges visuelles Sprachlokalisierungsmodell“ gestartet, das die Einstiegshürde in Form eines Notebooks senkt.
Online ausführen:https://go.hyper.ai/4l9jB
Weitere Online-Tutorials:
Besuchen Sie unsere offizielle Website für weitere Informationen:
Demolauf
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „LocateAnything-3B: Schnelles und hochwertiges visuelles Sprachlokalisierungsmodell“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
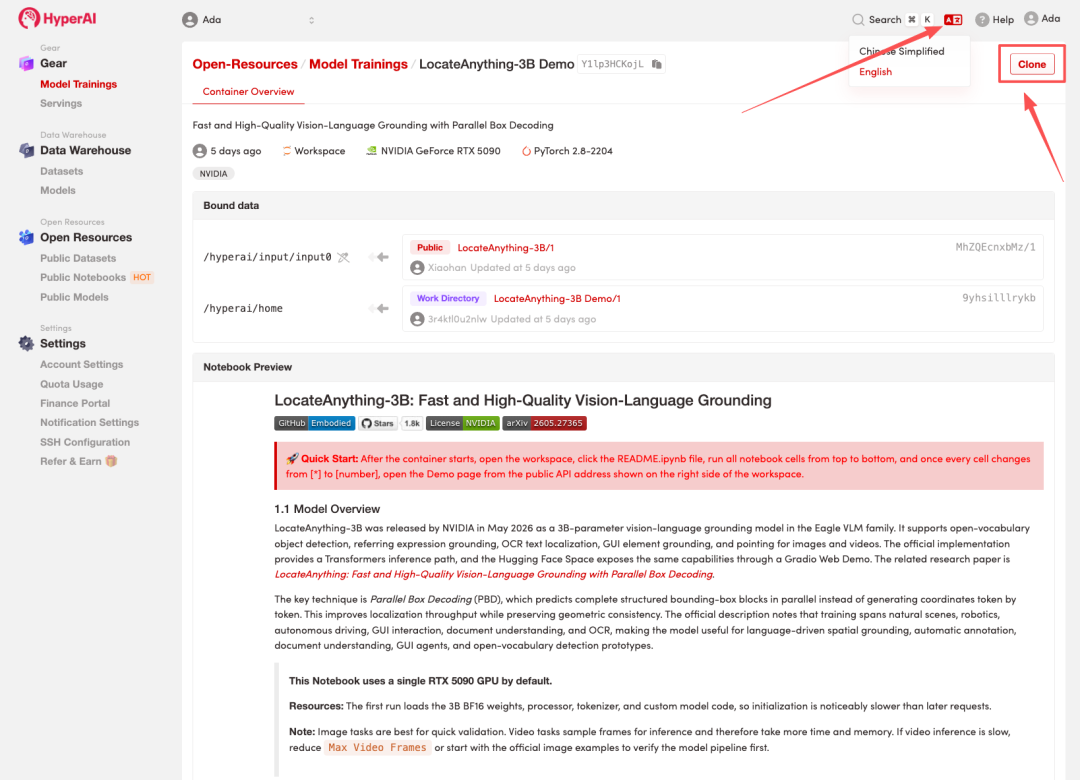
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
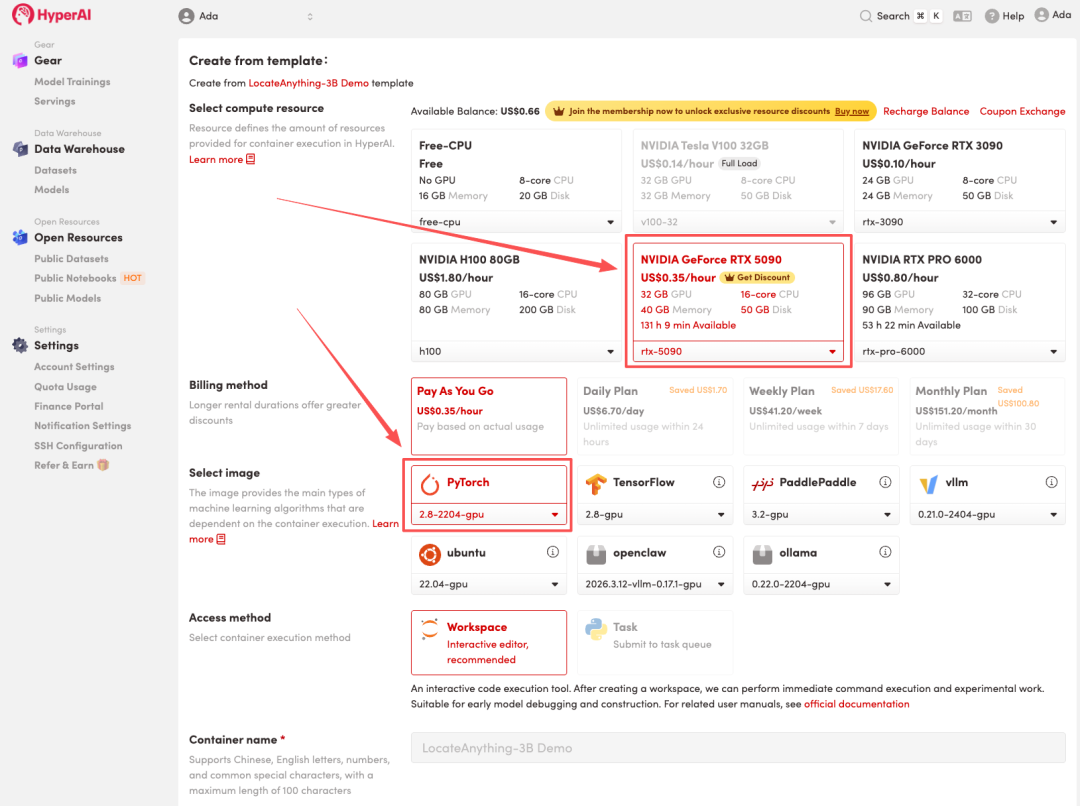
3. Wählen Sie die Images „NVIDIA RTX 5090“ und „PyTorch“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
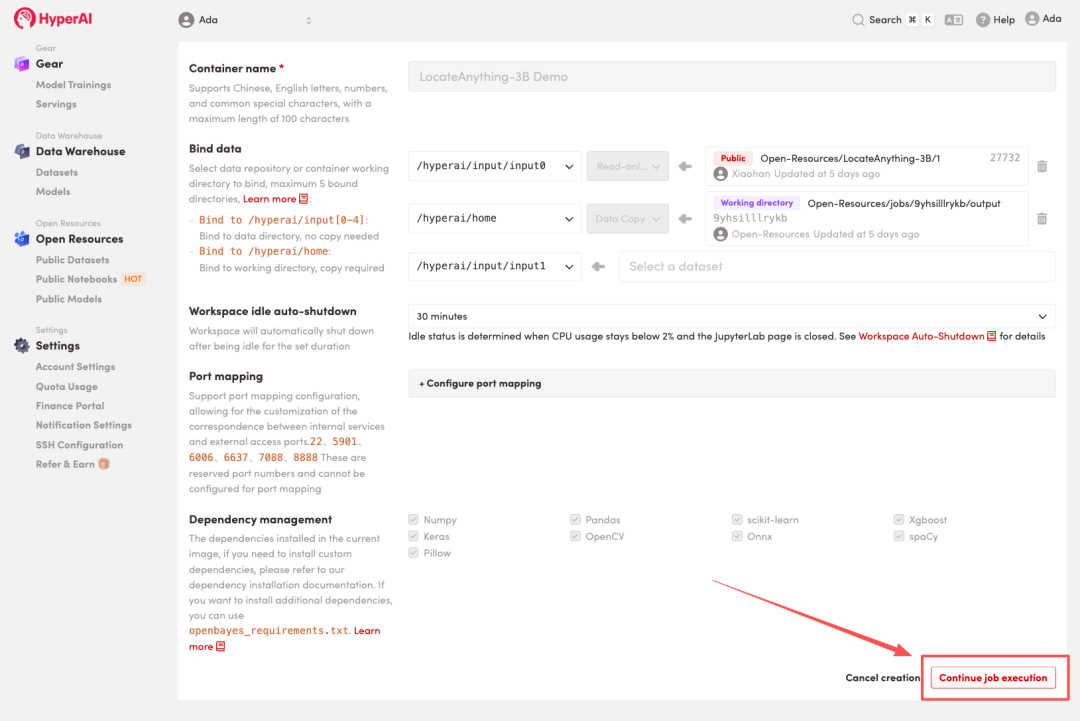
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
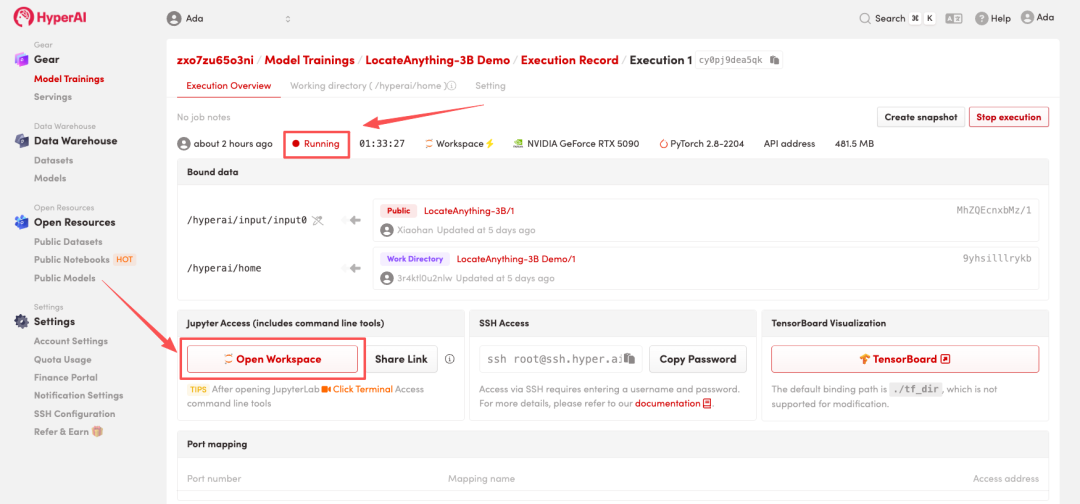
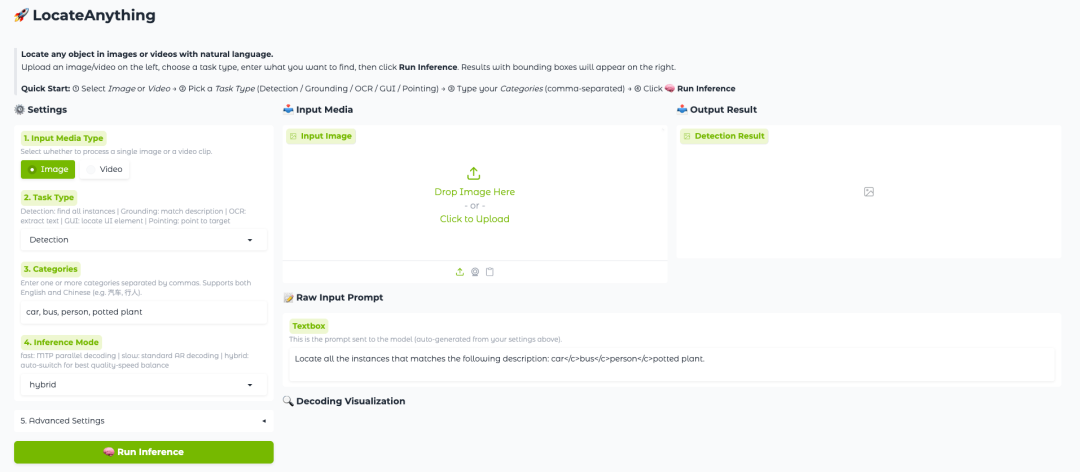
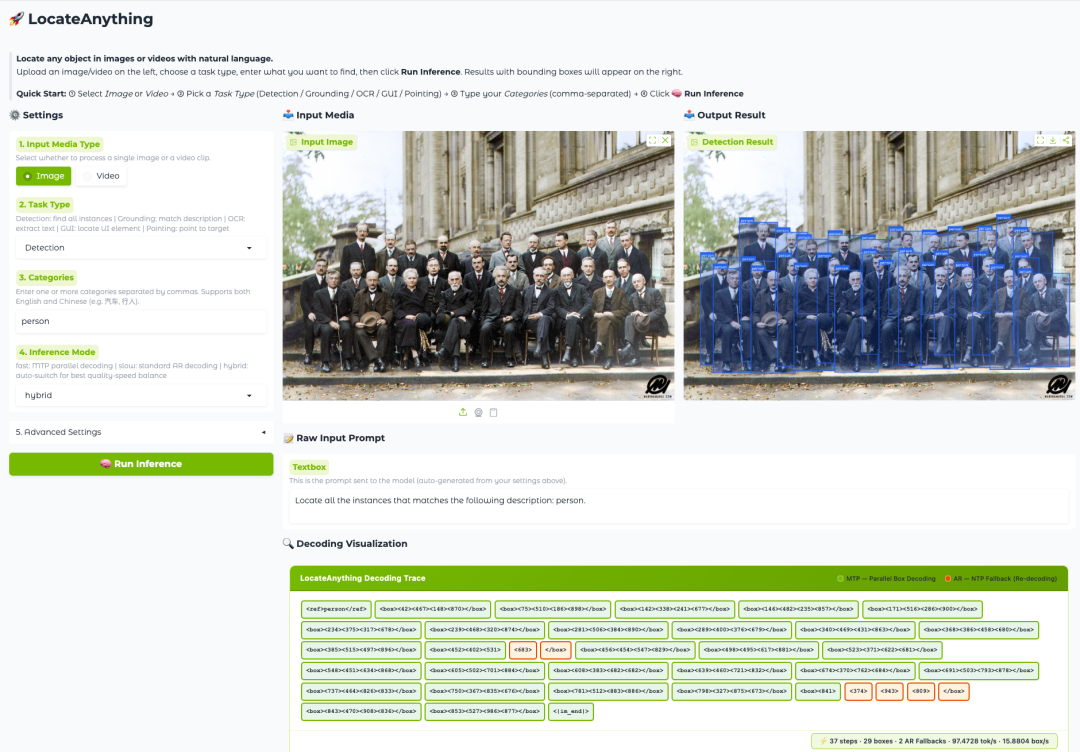
Effektanzeige
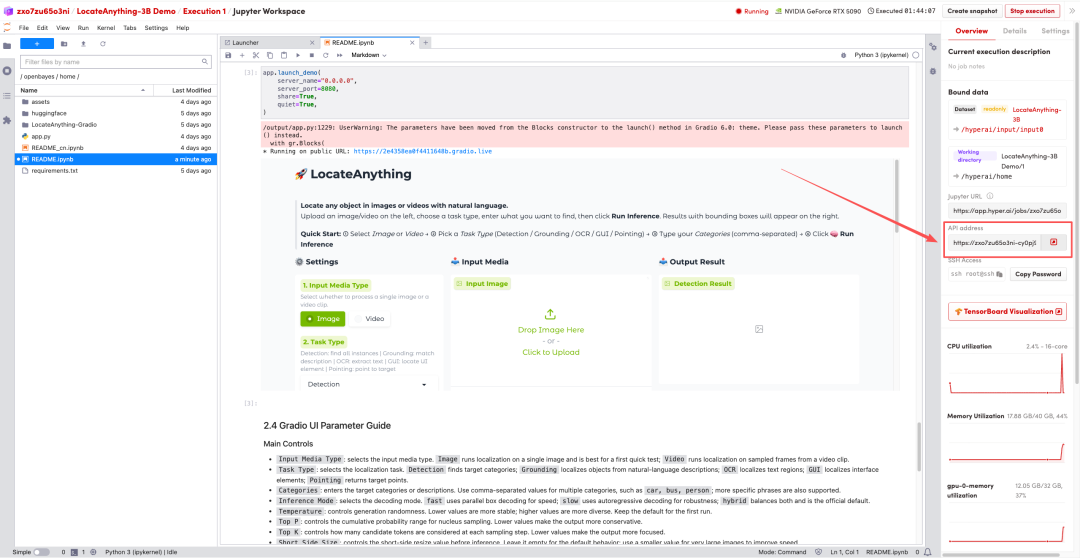
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
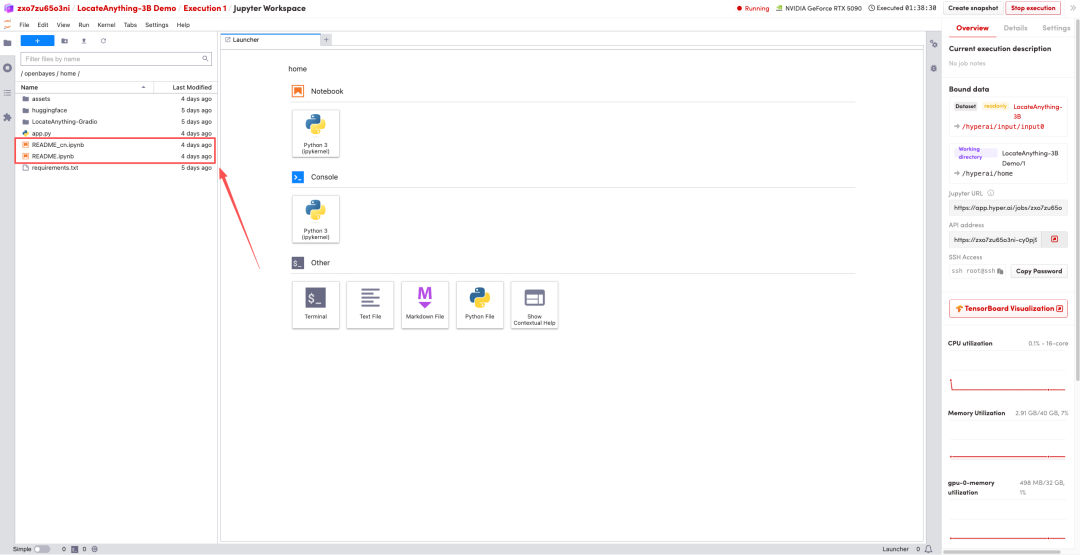
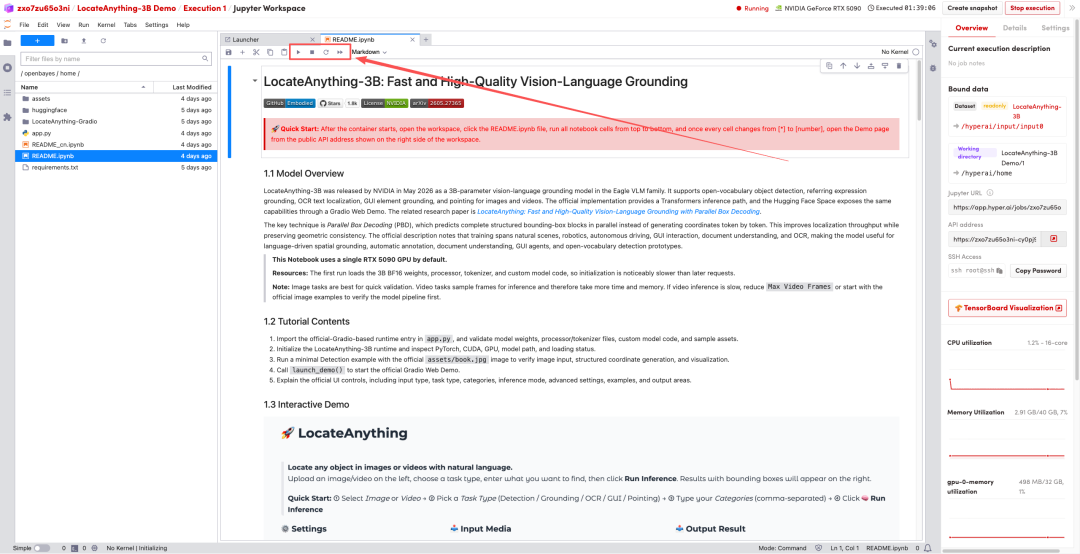
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.