Command Palette
Search for a command to run...
Unterstützt Die Generierung Von Live-Action-/Animations-/Tier-basierten Videos; Meituans Open-Source-Framework LongCat 1.5 Zur Generierung Von Audio-basierten Videos in Verschiedenen Stilen Erweitert Die Diagrammrekonstruktions- Und Tabellenextraktionsfunktionen Von VLM Mithilfe Des Millionenfachen Diagrammverständnis-Datensatzes ChartNet.

LongCat-Video-Avatar 1.5, das vom Meituan LongCat-Team im Mai 2026 veröffentlicht wurde, ist ein brandneues Open-Source-Framework zur audiobasierten Videogenerierung (AI2V).Nutzer müssen lediglich ein statisches Referenzbild und einen Audioclip bereitstellen, um ein dynamisches Avatar-Video mit präziser Lippensynchronisation zu generieren.Dieses Modell nutzt die flüstergesteuerte Sprachmerkmalsextraktion; die schrittweise Destillationstechnologie komprimiert den DiT-Generierungsprozess auf extrem schnelle 8 Schritte und gewährleistet so nicht nur hochauflösende Bilder, sondern auch die Generierung langer Videoinhalte. Seine umfassende Generalisierungsfähigkeit deckt reale Porträts, 2D/3D-Anime-Charaktere und Tier-Avatare ab und bietet damit eine effiziente und zuverlässige Lösung für die Generierung von Videos mit mehreren Szenen.
Auf der HyperAI-Website ist jetzt das „LongCat-Video-Avatar 1.5 Digital Human Model“ zu finden – probieren Sie es doch gleich aus!
Online-Nutzung:https://go.hyper.ai/NROTv
Besuchen Sie unsere offizielle Website für weitere Informationen:
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 6. bis 12. Juni:
* Hochwertige öffentliche Datensätze: 6
* Auswahl an hochwertigen Tutorials: 3
* Interpretation von Community-Artikeln: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. ChartNet-Diagrammverständnis multimodaler Datensätze
ChartNet ist ein umfangreicher, qualitativ hochwertiger multimodaler Datensatz, der 2026 vom MIT in Zusammenarbeit mit IBM Research und anderen Institutionen veröffentlicht wurde. Er zielt darauf ab, die Schwächen bestehender Modelle bei der gemeinsamen Inferenz mithilfe geometrischer visueller Muster, strukturierter numerischer Daten und Textbeschreibungen zu beheben. Der Datensatz enthält 4,2 Millionen synthetische Diagrammbeispiele, 94.643 manuell validierte Diagrammbeispiele und 30.000 reale Diagramme, die 24 Diagrammtypen und 6 Plotbibliotheken abdecken.
Online-Nutzung:https://go.hyper.ai/0CNr7
2. OpenSAL360 Panorama-Video-Saliency-Datensatz
OpenSAL360 ist derzeit der größte umfassende Datensatz zur Video-Saliency und wurde entwickelt, um die Forschung in den Bereichen visuelle Aufmerksamkeit, Saliency-Vorhersage und multimodale Videoanalyse zu unterstützen. Der Datensatz enthält 500 verschiedene Panoramavideos von YouTube mit einer durchschnittlichen Dauer von 18,1 Sekunden. Die Datenannotationen wurden von über 2.000 Beobachtern durchgeführt.
Online-Nutzung:https://go.hyper.ai/u7NqD
3. Datensatz „Filmgefühle“
Movie Feelings ist ein Datensatz mit Filmemotionsmerkmalen, der die feinen emotionalen Nuancen, die Filme hervorrufen, systematisch charakterisiert und damit die Grenzen traditioneller Klassifizierungen überwindet, die sich ausschließlich auf positive/negative oder Basisemotionen stützen. Dieser Datensatz umfasst 1.500 repräsentative und kulturell einflussreiche Filme aus den Jahren 1920 bis 2024 und deckt 50 emotionale Zustände ab.
Online-Nutzung:https://go.hyper.ai/b4m71
4. FigureBench: Generierung von Benchmark-Datensätzen für wissenschaftliche Illustrationen.
FigureBench ist ein Benchmark-Datensatz für die Generierung wissenschaftlicher Illustrationen, der 2026 vom Text Intelligence Lab der Westlake University veröffentlicht wurde. Er zielt darauf ab, die Aufgabe der automatischen Generierung hochwertiger wissenschaftlicher Illustrationen aus langen wissenschaftlichen Texten zu lösen und bietet eine anspruchsvolle und vielfältige Testplattform für die Forschung zur automatischen Generierung wissenschaftlicher Illustrationen.
Online-Nutzung:https://go.hyper.ai/Agaku
5. Auswirkungen von KI auf Studierende: KI-gestütztes Lernen beeinflusst Datensätze.
Das AI Student Impact Dataset ist ein umfangreicher Datensatz zum Lernverhalten, der verschiedene Dimensionen umfasst und die systematische Analyse der realen Auswirkungen generativer KI-Tools in Lernszenarien der Hochschulbildung ermöglicht. Dieser Datensatz enthält 50.000 Studierendenproben und 16 strukturierte Merkmalsfelder, die Daten wie den akademischen Hintergrund der Studierenden, ihr KI-Nutzungsverhalten, ihr Lernverhalten, ihren institutionellen Hintergrund, ihren psychischen Gesundheitszustand und Anwendungsszenarien abdecken.
Online-Nutzung:https://go.hyper.ai/zWoGM
6. Datensatz mit verrauschten medizinischen Dokumentenbildern
„Noisy Medical Document“ ist ein Datensatz mit verrauschten medizinischen Dokumentenbildern, der für OCR- und Dokumentenanalyseaufgaben entwickelt wurde. Er simuliert die komplexen Störungen, die beim Scannen von Dokumenten in realen medizinischen Szenarien auftreten, und verbessert so die Robustheit und Generalisierungsfähigkeit von OCR- und Dokumentenanalysemodellen in realen Umgebungen. Der Datensatz enthält 1.000 hochauflösende synthetische medizinische Dokumentenbilder, darunter 500 Krankenhausrechnungen und 500 Entlassungsberichte.
Online-Nutzung:https://go.hyper.ai/kL7gc
Ausgewählte öffentliche Tutorials
1. LongCat-Video-Avatar 1.5 Digitales menschliches Modell
LongCat-Video-Avatar 1.5, veröffentlicht vom Meituan-Team im Mai 2026, ist ein aktualisiertes Open-Source-Framework zur audiobasierten Videogenerierung (AI2V). Es erzeugt hochrealistische, perfekt lippensynchrone dynamische Avatar-Videos mit nur einem statischen Referenzbild und einem Audio-Clip und bewältigt dabei problemlos sowohl komplexe reale Szenen als auch stilisierte Motive wie Animationen und Tiere.
Online ausführen:https://go.hyper.ai/NROTv
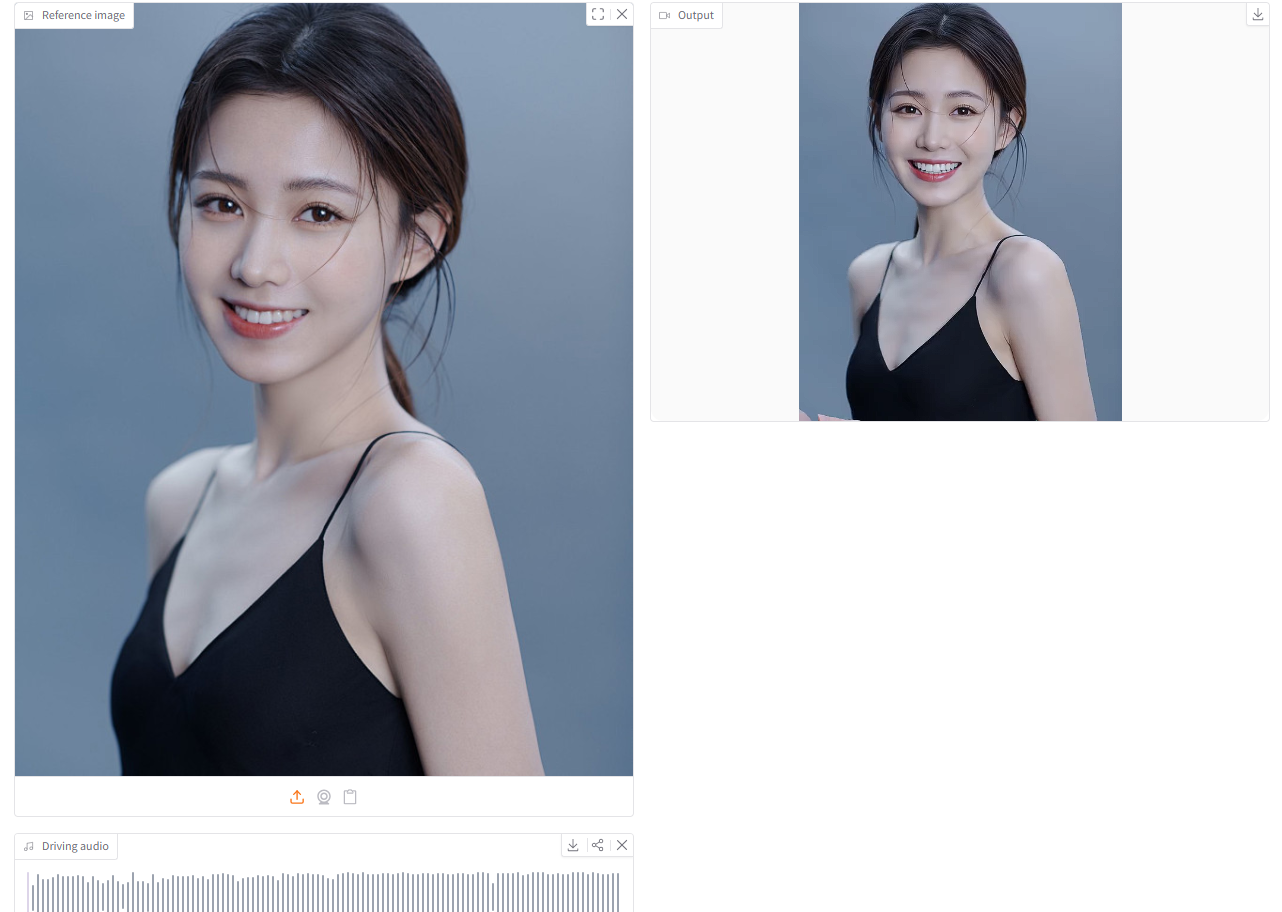
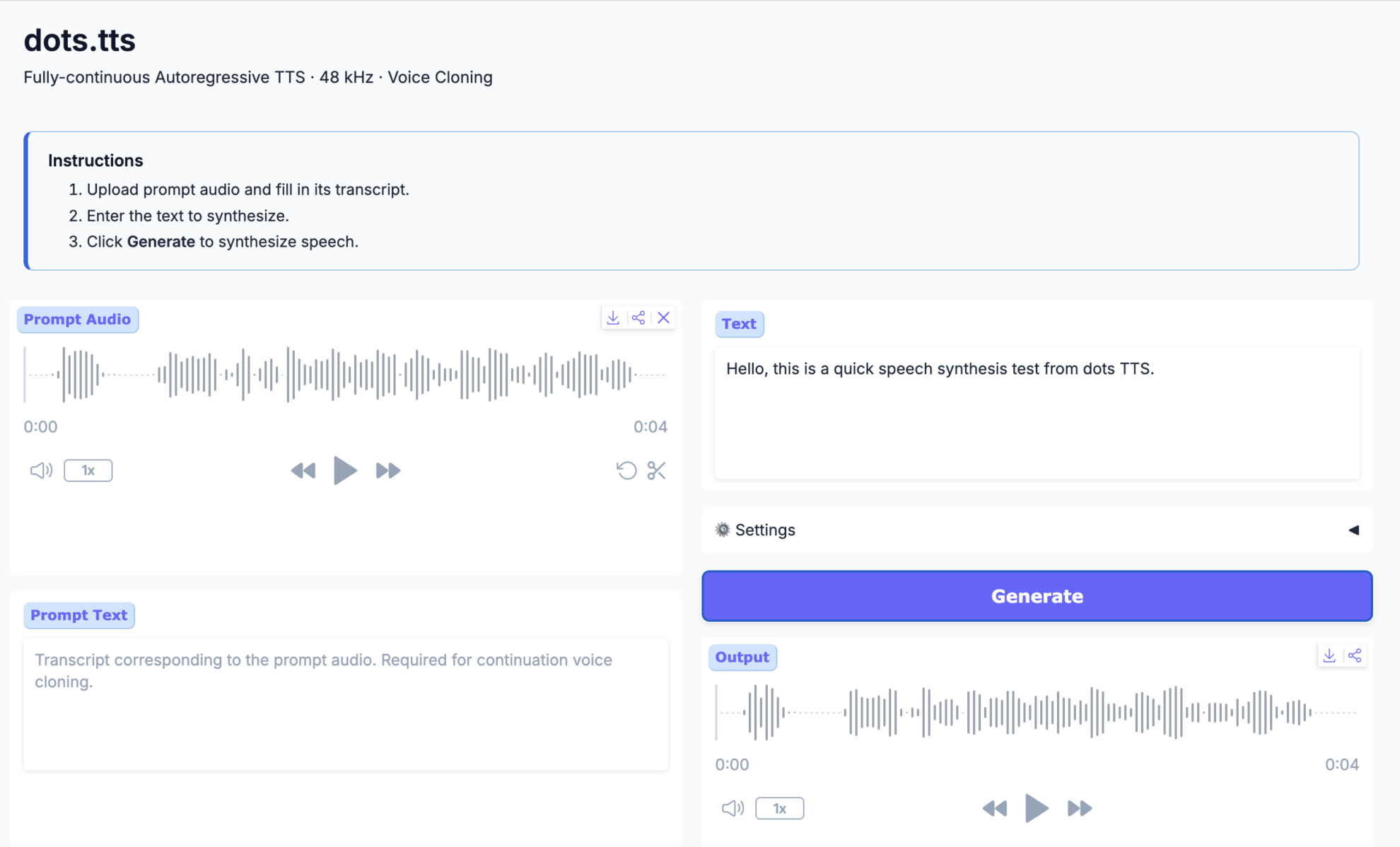
2. dots.tts: Ein vollständig kontinuierliches autoregressives Text-zu-Sprache-System
Das im Juni 2026 von rednote-hilab veröffentlichte dots.tts ist ein vollständig kontinuierliches, autoregressives Text-zu-Sprache-System mit 2 Milliarden Parametern. Sein Kern besteht aus einem semantischen Encoder, einem LLM (Late-Level-Machine) und einem autoregressiven, flussanpassenden akustischen Kopf. Es modelliert kontinuierliche Audiodarstellungen direkt auf Basis von 48 kHz AudioVAE, ohne diskrete Sprach-Token zu verwenden.
Online ausführen:https://go.hyper.ai/YT3g3
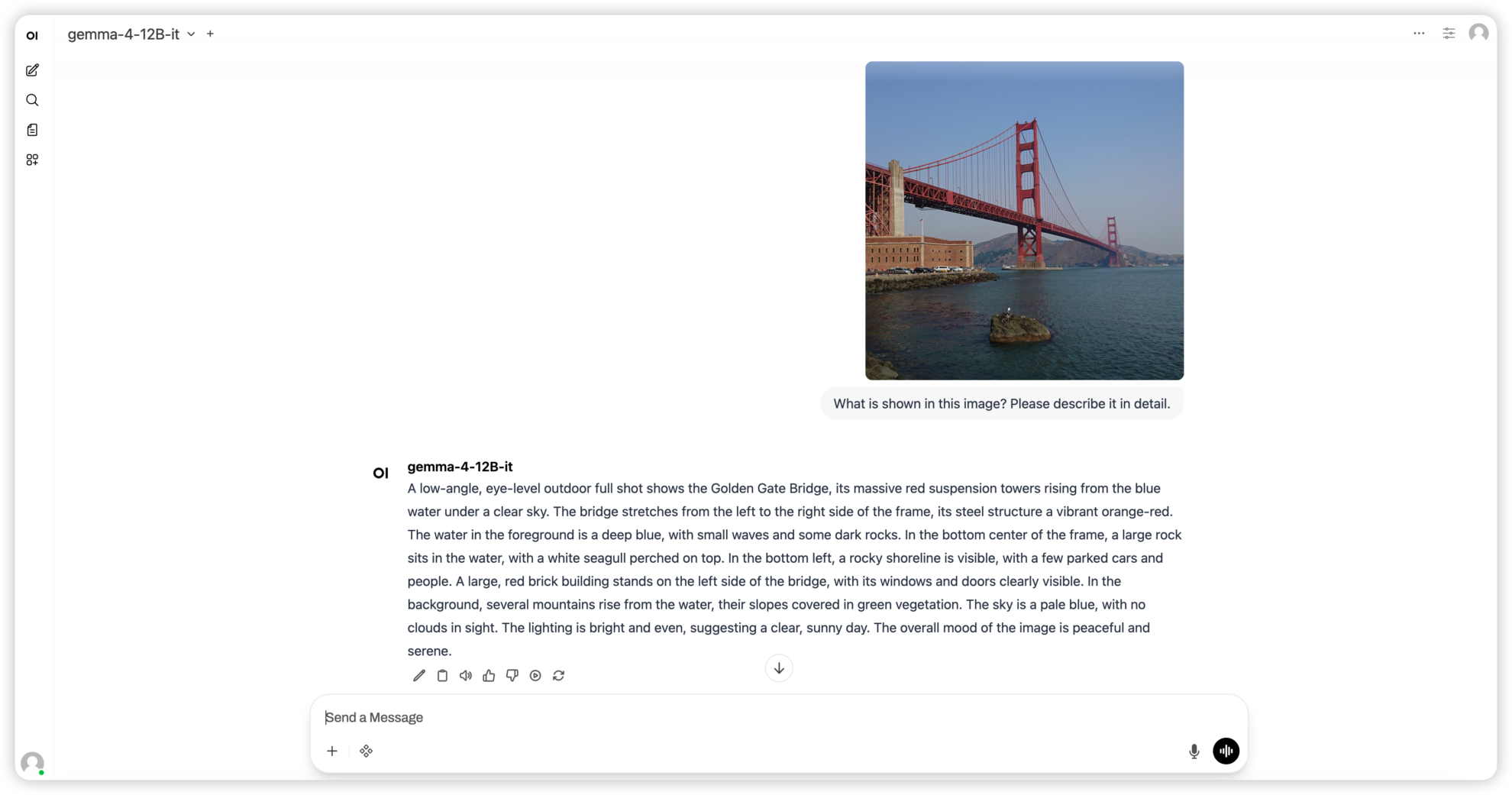
3. Gemma4 12B-it: Ein einheitliches multimodales Modell von Graphen, Texten und Audio.
Gemma 4 12B-it ist ein einheitliches multimodales Modell der Gemma-4-Serie von Google DeepMind. Es verwendet eine encoderfreie Architektur und projiziert Bilder und Audio direkt in den Einbettungsraum des LLM. Es kann Text-, Bild- und Audiomodalitäten ohne separaten Encoder verarbeiten und erzielt leistungsstarke Inferenz-, Kodierungs- und multimodale Verständnisfähigkeiten auf der 12B-Parameterebene.
Online ausführen:https://go.hyper.ai/0713z
Interpretation von Gemeinschaftsartikeln
1. Anhand von 220 marinen Bakterienarten rekonstruierten Wissenschaftler mithilfe eines genomweiten Modells das heterotrophe mikrobielle Klassifizierungssystem und identifizierten dabei acht Typen von Stoffwechselflora.
Ein Team der University of Southern California nutzte eine globale Datenbank mariner Mikroorganismen und genomweite Stoffwechselmodelle, um riesige Mengen mariner Bakteriengenome zu analysieren. Durch die Quantifizierung der Empfindlichkeit der Mikroorganismen gegenüber der Verwertung von elf verschiedenen organischen Substraten identifizierten sie acht differenzierte Stoffwechselgemeinschaften.
Den vollständigen Bericht ansehen:https://go.hyper.ai/dfq8T
2. Die Genauigkeit der Tiefenschätzung erreicht 0,9; Meta schlägt VLM³ vor und zeigt damit, dass visuelle Modelle von Natur aus in der Lage sind, 3D zu lernen, und erreicht eine einheitliche Modellierung für mehrere Aufgaben basierend auf Qwen3-VL-4B.
Meta hat in Zusammenarbeit mit der Princeton University VLM³ vorgeschlagen. Dieses Modell, basierend auf dem Standardmodell der visuellen Sprache, ermöglicht eine einheitliche Modellierung für vier Aufgabentypen: 3D-Objekterkennung, metrische Tiefenschätzung, Pixelabgleich und Kamerapositionsbestimmung. Dies wird durch eine einheitliche Datenorganisationsmethode und ein einheitliches Trainingsparadigma erreicht. Zudem wurden die Leistungsgrenzen des Standard-VLM in der detaillierten 3D-Wahrnehmung systematisch evaluiert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/NihJA
3. Die Universität Cambridge und andere schlugen ein fundamentales Modell auf Pixelebene für Erdbeobachtungsmissionen vor, mit dem in mehreren Missionen eine Genauigkeit auf dem neuesten Stand der Technik (SOTA) erreicht wurde.
Ein gemeinsames Forschungsteam der Universitäten Cambridge, Aalto und Bristol hat ein neuartiges Paradigma zum Lernen zeitlicher Merkmale auf Basis des Barlow-Zwillinge-Algorithmus entwickelt. Dieses Paradigma ermöglicht es Modellen, stabile räumlich-zeitliche Variationen der Erdoberfläche autonom zu erlernen und so Fernerkundungsmerkmale mit zeitlicher Abtastinvarianz zu erzeugen. Darauf aufbauend entwickelte das Team TESSERA, ein pixelgenaues Fernerkundungsmodell für multimodale zeitliche Daten von Sentinel-1/Sentinel-2.
Den vollständigen Bericht ansehen:https://go.hyper.ai/S3KBr
Beliebte Enzyklopädieartikel
1. Weltaktionsmodell (WAM)
2. Erklärbare künstliche Intelligenz (XAI)
3. Visuelles Sprachaktionsmodell (VLA)
4. Regelbasiertes System
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








