Command Palette
Search for a command to run...
Mit Einer Genauigkeit Der Tiefenschätzung Von 0,9 Schlug Meta VLM³ Vor Und Demonstrierte Damit, Dass Visuelle Modelle Von Natur Aus in Der Lage Sind, 3D Zu Lernen Und Eine Einheitliche Modellierung Für Mehrere Aufgaben Auf Basis Von Qwen3-VL-4B Zu erreichen.

Die dreidimensionale räumliche Wahrnehmung ist eine grundlegende Fähigkeit in Bereichen wie autonomes Fahren, Robotik und 3D-Rekonstruktion. Ihr Ziel ist es, die räumliche Struktur, die Maßstabsinformationen und die geometrischen Beziehungen der realen Welt aus zweidimensionalen Bildern zu gewinnen. Im Vergleich zu zweidimensionalen Bildverarbeitungsaufgaben wie Bildklassifizierung und Objekterkennung,Dreidimensionale Wahrnehmung erfordert nicht nur semantisches Verständnis, sondern auch präzises räumliches Denken und geometrische Modellierung.Daher gilt es seit langem als eine der anspruchsvollsten Forschungsrichtungen im Bereich Computer Vision.
In den letzten Jahren haben visuelle Sprachmodelle (VLMs) dank ihrer einheitlichen Architektur und des umfangreichen Vortrainings bedeutende Fortschritte bei 2D-Aufgaben wie Klassifizierung, Objekterkennung und Segmentierung erzielt. Bei feinkörnigen Aufgaben, die präzises räumliches Denken erfordern, wie Tiefenschätzung, Pixelabgleich und Kamerapositionsbestimmung, hinkt die Leistung von Standard-VLMs jedoch weiterhin der von spezialisierten 3D-Modellen hinterher.Im Bereich der 3D-Bildverarbeitung hat sich noch kein universelles Basismodell entwickelt, das dem der 2D-Bildverarbeitung ähnelt. Gängige Methoden basieren weiterhin auf Expertenmodellen, die für spezifische Aufgaben entwickelt wurden.Dies umfasst spezialisierte Netzwerkstrukturen, Verlustfunktionen und Trainingsstrategien.
Jüngste Forschungsergebnisse zeigen, dass das Standard-Visual Language Model (VLM) ohne spezifische 3D-Modifikationen bereits eine gewisse Tiefenwahrnehmung auf Pixelebene ermöglicht. Dieses Phänomen legt nahe, dass universelle Visual Language Models über stärkere 3D-Repräsentationsfähigkeiten verfügen könnten als bisher angenommen. Es wirft zudem eine Frage auf, die weiterer Untersuchung bedarf: Kann das Standard-VLM ein breiteres Spektrum an detaillierten 3D-Wahrnehmungsaufgaben bewältigen, ohne zusätzliche Encoder, visuelle Hinweise oder aufgabenspezifische Module einzuführen?
Um dieses Problem zu beheben,Meta hat in Zusammenarbeit mit der Princeton University das VLM³ (VLM Cubed)-Framework vorgeschlagen.Aufbauend auf dem Standardmodell der visuellen Sprache (VLM) erreicht diese Studie eine einheitliche Modellierung für vier Aufgabentypen – 3D-Objektverständnis, metrische Tiefenschätzung, Pixelabgleich und Kamerapositionsbestimmung – durch eine einheitliche Datenorganisationsmethode und ein einheitliches Trainingsparadigma. Darüber hinaus werden die Leistungsgrenzen des Standard-VLM in der detaillierten 3D-Wahrnehmung systematisch evaluiert.
Die zugehörigen Forschungsergebnisse mit dem Titel „VLM3: Vision Language Models Are Native 3D Learners“ wurden auf der Preprint-Plattform arXiv veröffentlicht.
Forschungshighlights:
* Beim SpatialRGPT-Benchmark übertrifft der VLM³-4B den größeren SpatialRGPT-8B mit einer schlankeren Architektur, die keinen zusätzlichen Encoder erfordert.
* Im Vergleich zum bisherigen besten visuellen Sprachmodell, DepthLM-7B, verbessert VLM³-4B die durchschnittliche Genauigkeit δ₁ von 0,84 auf 0,90 und erreicht damit eine Leistung, die mit dem professionellen Tiefenschätzungsmodell UnidepthV2 vergleichbar ist.
* VLM³ reduziert den Endpunktfehler (EPE) von visuellen Basismodellen um eine Größenordnung und übertrifft damit klassische Expertenmodelle wie DKM und RoMa.
* VLM³ verbessert die AUC₃₀°-Metrik signifikant von einem nahezu zufälligen Niveau von 5% auf 94%, übertrifft damit VGGT und erreicht ein Niveau, das mit DA3-Giant vergleichbar ist.
Lesen Sie das Dokument:
https://hyper.ai/papers/2605.30561
Hybride Datensätze für die 3D-Wahrnehmung mit mehreren Aufgaben
Aufgaben zur 3D-Wahrnehmung umfassen verschiedene Faktoren wie Szenenmaßstab, Blickwinkeländerungen, Kameraparameter und geometrische Beziehungen, was hohe Anforderungen an die Qualität und den Umfang der Trainingsdaten stellt. Um das Erlernen einheitlicher 3D-Darstellungsfähigkeiten zu unterstützen,Diese Studie entwickelt ein hybrides Datensystem, das sowohl Einzel- als auch Mehransichtsszenen abdeckt und drei Aufgabentypen umfasst: metrische Tiefenschätzung, 3D-Verständnis auf Objektebene sowie Pixelabgleich und Kameraposenschätzung.
Bei der Aufgabe der metrischen TiefenschätzungDie Forscher nutzten einen umfangreichen, hybriden Datensatz mit verschiedenen Szenen. Die Basisdaten stammen von DepthLM und umfassen gängige 3D-Szenendaten wie Argoverse2, Waymo, NuScenes, ScanNet++, Taskonomy, HM3D und Matterport3D. Zusätzlich wurden 10 Millionen selbst erstellte Bilder von Straßenszenen im Freien hinzugefügt, wodurch der Trainingsumfang von 16 Millionen auf 26 Millionen Bilder erweitert wurde.Für das finale Modelltraining wurden ungefähr 32 Millionen Bilder und 320 Millionen Tiefenannotationen verwendet.Es deckt eine Vielzahl von Szenarien ab, darunter Innenräume, Außenbereiche, Straßenszenen und komplexe offene Umgebungen.
Im Gegensatz zu bisherigen Ansätzen verwendet VLM³ keine einheitliche Stichprobenstrategie. Stattdessen werden die Trainingsgewichte differenziert, basierend auf Datensatzgröße, Lernschwierigkeit und Generalisierungswert. Experimente zeigen, dass kleine Datensätze bei gemischtem Training anfälliger für Überanpassung sind und eine einfache Erhöhung der Datenquellenanzahl nicht zwangsläufig zu Leistungsverbesserungen führt. Daher hat das Forschungsteam die Trainingsgewichte einiger kleiner Datensätze entsprechend reduziert, um die Generalisierungsfähigkeit insgesamt zu verbessern.
Die Aufgabe zum Verständnis des dreidimensionalen Objektraums verwendet denselben Standarddatensatz wie SpatialRGPT.Es umfasst rund eine Million Trainingsbilder sowie zugehörige qualitative und quantitative Frage-Antwort-Beispiele. Dieser Datensatz hat sich zu einem wichtigen Benchmark für aktuelle Aufgaben im Bereich des 3D-Verstehens auf Objektebene entwickelt. Da viele Bilder keine kamerainternen Informationen enthalten, ist er realitätsnäher und spiegelt somit die räumlichen Denkfähigkeiten des Modells realistischer wider.
Für die Aufgaben des Pixel-Matchings und der Kamera-Pose-Schätzung erstellte das Forschungsteam einen einheitlichen Trainingsdatensatz mit mehreren Ansichten.Dieser Datensatz integriert 14 gängige Datenquellen, darunter BlendedMVS, DynamicReplica, SailVOS3D und ScanNet++, und umfasst ca. 9,9 Millionen Bildpaare. Um die Trainingsqualität zu gewährleisten, wurden nur Bilder mit einer visuellen Überlappung von mehr als 251 TP3T beibehalten. Zudem wurden 30 unabhängige Szenen aus ScanNet++ als separater Testdatensatz reserviert, um Datenlecks zwischen Trainings- und Testdatensatz zu vermeiden. Die Gewichtung des Datensatzes basiert auf der ursprünglichen Anzahl der Bildpaare jeder Datenquelle, was die Stabilität und Anpassungsfähigkeit des Trainingsprozesses weiter verbessert.
VLM³-Modell: Einheitliches 3D-Lernen nach dem Prinzip der minimalen Modifikation
Das Designziel von VLM³ ist nicht der Aufbau einer neuen 3D-Vision-Architektur, sondern die Evaluierung ihrer potenziellen Fähigkeiten bei detaillierten 3D-Aufgaben unter Beibehaltung der ursprünglichen Struktur gängiger visueller Sprachmodelle. Daher folgt das gesamte Framework dem Prinzip der minimalen Modifikation und verzichtet auf die Einführung zusätzlicher Encoder, proprietärer Verlustfunktionen oder aufgabenspezifischer Module.Der Fokus liegt stattdessen auf der Optimierung von drei Aspekten: der Eingabedarstellung, den Methoden zur räumlichen Positionierung und den Strategien zur Datenorganisation.
Die Studie verwendet Qwen3-VL-4B als Basismodell und setzt während des gesamten Trainingsprozesses das Standardparadigma des überwachten Feinabstimmens (SFT) ein, um die Konsistenz mit dem Vortrainings- und Feinabstimmungs-Workflow bestehender visueller Sprachmodelle zu gewährleisten. Dieses Design stellt sicher, dass das Framework direkt mit gängigen VLM-Systemen kompatibel ist, ohne dass eine zusätzliche, dedizierte Trainingspipeline entwickelt werden muss.
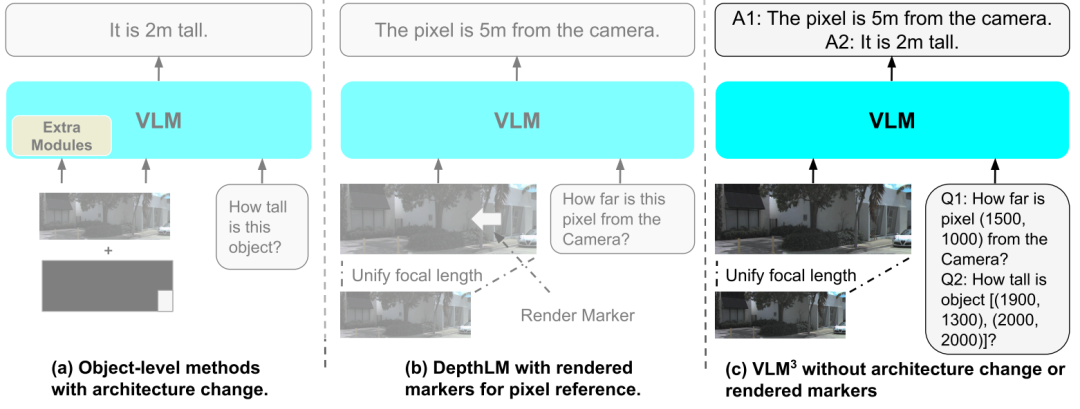
Erstens zum Problem der inkonsistenten Kameraparameter zwischen verschiedenen Datenquellen,VLM³ schlägt eine einheitliche Strategie zur Bildstandardisierung vor.Untersuchungen haben gezeigt, dass zwischen 3D-Datensätzen aus verschiedenen Quellen häufig erhebliche Unterschiede in den kameraspezifischen Parametern bestehen, wobei einigen Netzwerkbildern sogar Kameraparameterinformationen fehlen. Dies beeinträchtigt direkt die Fähigkeit des Modells, räumliche geometrische Beziehungen zu erlernen. DaherDas Framework bildet alle Eingangsbilder auf einen standardisierten Brennweitenraum ab und schätzt die fehlenden intrinsischen Parameter mithilfe bestehender Einzelbildkalibrierungsmodelle.Dadurch wird die durch Unterschiede in den Abbildungsbedingungen verursachte Verteilungsverschiebung verringert.
Zweitens,VLM³ verwendet ein einheitliches Paradigma zur räumlichen Positionierung von Texten.Herkömmliche 3D-Vision-Modelle nutzen typischerweise zusätzliche visuelle Hinweise, gerenderte Marker oder speziell entwickelte Positionskodierungsmodule, um eine pixelgenaue Lokalisierung zu erreichen. VLM³ hingegen normalisiert Bildkoordinaten in einen einheitlichen Koordinatenraum und drückt Positionsbeziehungen in Textform aus. Dadurch kann das Modell die nativen Sprachmodellierungsfunktionen nutzen, um pixelgenaue Lokalisierung, Regionslokalisierung und das Lernen von Korrespondenzen zwischen verschiedenen Ansichten durchzuführen, ohne zusätzliche visuelle Module einzuführen. Gleichzeitig kann ein einzelnes Bild mehrere Beispiele für die Beantwortung von Lokalisierungsfragen enthalten, was die Trainingseffizienz deutlich verbessert. Bei Tiefenschätzungsaufgaben,Die Menge an Überwachungssignal, die eine einzelne Probe liefern kann, ist etwa 10 Mal höher als bei herkömmlichen Verfahren, während der Rechenaufwand nahezu unverändert bleibt.
Das dritte Kerndesign ist eine ausgeklügelte Datenmischungsstrategie.Im Gegensatz zu vielen Methoden, die komplexe Netzwerkstrukturen zur Leistungssteigerung nutzen, konzentriert sich VLM³ bei der Optimierung auf die Datenorganisation. Umfangreiche Experimente zeigten, dass eine unreflektierte Erweiterung des Datenumfangs oder die Verwendung gleichgewichteter gemischter Trainingsdaten häufig zu Leistungssättigung oder sogar -verschlechterung führt. Differenzierte Sampling-Strategien, die auf Datenumfang und Aufgabencharakteristika basieren, verbessern hingegen die dreidimensionalen Repräsentationsfähigkeiten des Modells deutlich effektiver. Daher wird die Datenallokation als entscheidende Komponente des gesamten Frameworks betrachtet und nicht nur als Hilfsfaktor im Trainingsprozess.
Basierend auf dem obigen EntwurfDarüber hinaus ermöglicht VLM³ die einheitliche Modellierung für vier Arten von 3D-Aufgaben.Die Tiefenschätzung erzeugt überwachte Stichproben durch textbasierte Pixellokalisierung; das 3D-Verständnis auf Objektebene nutzt Textkoordinatenfelder anstelle dedizierter Maskencodierer; Pixelabgleich transformiert Korrespondenzen zwischen verschiedenen Ansichten in Koordinatenvorhersageprobleme; und die Kameraposenschätzung zerlegt komplexe geometrische Parameter in textbasierte Frage-Antwort-Formate wie Translationsdistanz, Translationsrichtung und Rotationswinkel. Aufgaben, die ursprünglich auf unterschiedlichen Verarbeitungsmodellen beruhten, werden schließlich im autoregressiven generativen Rahmen des Standard-VLM zusammengeführt.
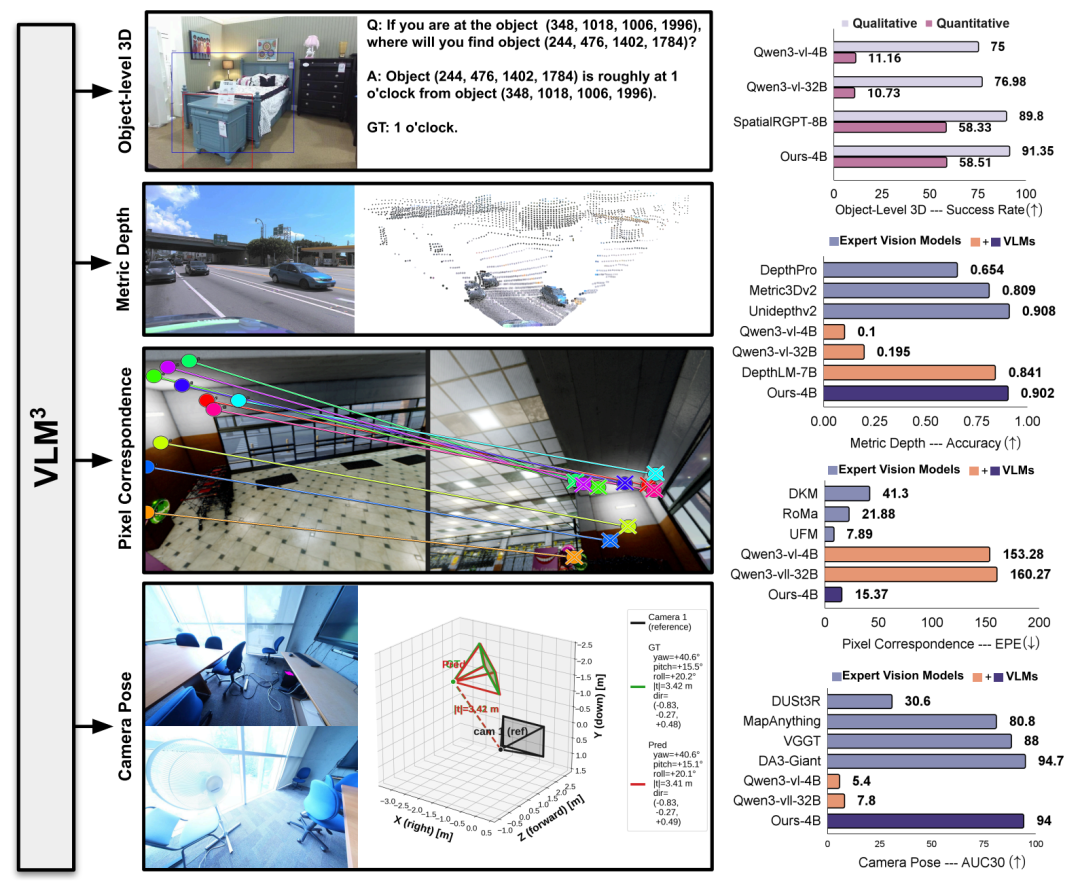
Zum ersten Mal hat das Standardmodell für visuelle Sprache ein hochpräzises 3D-Verständnis bei mehreren fein abgestuften 3D-Aufgaben erreicht.
Um die Effektivität von VLM³ systematisch zu bewerten,Das Forschungsteam führte Experimente zu vier Aufgabentypen durch: metrische Tiefenschätzung, 3D-Objektverständnis, Pixelabgleich und Kameraposenschätzung.Es wird mit allgemeinen visuellen Sprachmodellen und aktuellen gängigen Expertenmodellen verglichen.
Bei der metrischen TiefenschätzungsaufgabeDie Studie wählt neun öffentliche Datensätze zum Vergleich mit einem allgemeinen VLM aus und vergleicht dieses mit dem aktuellen Stand der Technik eines Expertenmodells anhand von fünf repräsentativen Benchmarks.Die Ergebnisse, die anhand von δ₁ als primärem Bewertungskriterium ermittelt wurden, sind in der folgenden Tabelle dargestellt. VLM³-4B übertrifft die bisherige repräsentative Methode DepthLM-7B deutlich.Die durchschnittliche Genauigkeit verbesserte sich von 0,84 auf 0,90 und stellte damit bei mehreren Datensätzen einen neuen Rekord auf.Gleichzeitig hat seine Gesamtleistung das Niveau professioneller Tiefenschätzungsmodelle wie UnidepthV2 und MoGe-2 erreicht.
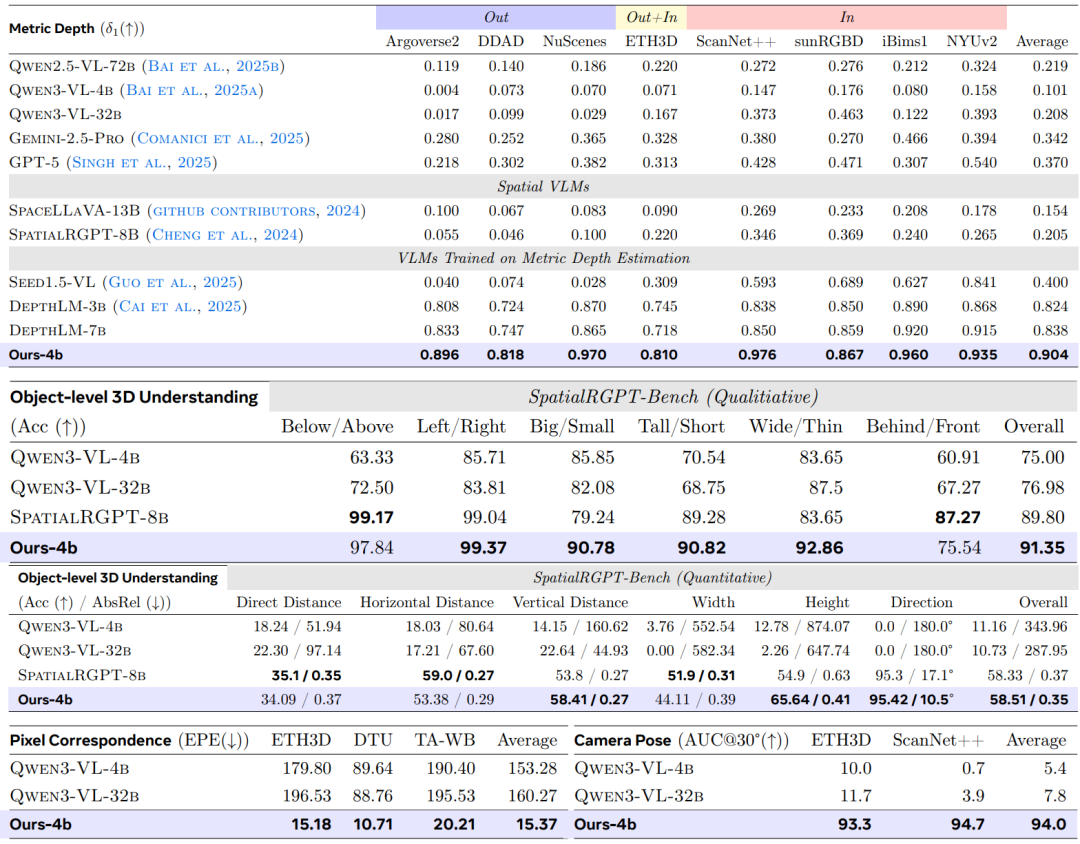
Im Rahmen der Aufgabe zum objektbezogenen 3D-Verständnis wurde das Bewertungsmodell von SpatialRGPT vollständig wiederverwendet. Die Ergebnisse zeigen, dass…Der VLM³, mit einer Parametergröße von nur 4B, übertrifft den SpatialRGPT, der eine Größe von 8B aufweist, sowohl in qualitativen als auch in quantitativen Auswertungen.Letztere Methode verwendet einen zusätzlichen Masken-Encoder zur Vervollständigung der räumlichen Lokalisierung, während VLM³ bessere Ergebnisse erzielt, indem es sich ausschließlich auf den einheitlichen Textlokalisierungsmechanismus stützt. Dies deutet darauf hin, dass die einheitliche Textmodellierung eine hohe Effektivität bei räumlichen Denkaufgaben aufweist.
Die Pixelzuordnungsaufgabe verwendet das UFM-Evaluierungssystem mit dem Endpunktfehler (EPE) als Kernmetrik. Experimentelle Ergebnisse zeigen, dass VLM³ den Fehler im Vergleich zum Basis-VLM um eine Größenordnung reduziert, klassische Expertenmodelle wie DKM und RoMa übertrifft und nur geringfügig hinter dem aktuellen Stand der Technik, UFM, zurückbleibt. Dies deutet darauf hin, dass…Der einheitliche textbasierte Modellierungsansatz ist nicht nur auf Szenen mit einer einzigen Ansicht anwendbar, sondern kann auch geometrische Korrespondenzen zwischen verschiedenen Ansichten effektiv erlernen.
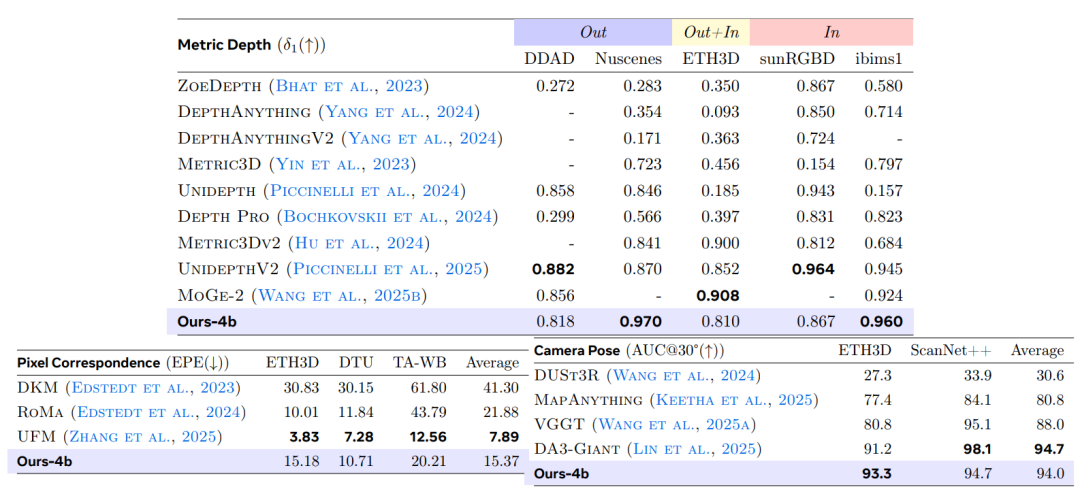
Im Rahmen der Schätzung der Kameraposition verwendet die Studie die AUC₃₀°-Metrik zur Evaluierung auf den Datensätzen ETH3D bzw. ScanNet++. Die Ergebnisse zeigen, dass…VLM³ verbessert die Leistung des Basis-VLM von nahezu zufälligen Vorhersageniveaus auf einen AUC₃₀° von 94%.Es übertrifft gängige Methoden wie VGGT und MapAnything und nähert sich dem Leistungsniveau des derzeit besten Modells, DA3-Giant.
Letzte Worte
Lange Zeit verfolgte die Forschung im Bereich 3D-Vision hauptsächlich einen aufgabenorientierten Ansatz: Es wurden dedizierte Modelle für verschiedene Aufgaben wie Tiefenschätzung, Pixelabgleich oder Pose-Bestimmung entwickelt. VLM³ zeigt jedoch eine andere Möglichkeit auf: Ohne zusätzliche Encoder, proprietäre Verlustfunktionen oder komplexe visuelle Hinweismechanismen kann ein Standardmodell visueller Sprache durch standardisierte Bildverarbeitung, textuelle räumliche Modellierung und optimierte Datenstrategien bei mehreren detaillierten 3D-Aufgaben eine mit Expertenmodellen vergleichbare oder sogar bessere Leistung erzielen. Dieses Forschungsergebnis legt nahe, dass die 3D-Repräsentationsfähigkeiten eines allgemeinen Modells visueller Sprache bisherige Erwartungen weit übertreffen können und liefert neue empirische Belege für den Wandel in der 3D-Vision von der aufgabenspezifischen Optimierung hin zu einem einheitlichen Basismodell.