Command Palette
Search for a command to run...
Die Universität Cambridge Und Andere Haben Ein Fundamentales Modell Auf Pixelebene Für Erdbeobachtungsmissionen Vorgeschlagen, Mit Dem in Mehreren Missionen Eine Genauigkeit Auf Dem Neuesten Stand Der Technik (SOTA) Erreicht wurde.

Erdbeobachtungssatelliten, die die Erde über große Gebiete und lange Zeiträume überwachen können, sind zu unverzichtbaren Werkzeugen in Bereichen wie Landwirtschaft, Forstwirtschaft, Ökosystemüberwachung und Landnutzungsplanung geworden. Mithilfe von Langzeit-Fernerkundungsdaten, die von Satelliten erfasst werden, können Forscher dynamische Veränderungen der Erdoberfläche verfolgen. Allerdings sind reale Satellitenbeobachtungsdaten alles andere als perfekt: Wolkenbedeckung, unregelmäßige Umlaufbahnen, unterschiedliche Sensorauflösungen und Geräteaussetzer gehören zu den Störfaktoren.Dies führt zu unvollständigen, heterogenen und ungeordneten Rohdaten, wodurch deren direkte Verwendung für hochpräzise intelligente Analysen erschwert wird.Insbesondere bei detaillierten Szenarien wie der landwirtschaftlichen Phänologie und kurzfristigen ökologischen Störungen können Wolken wichtige Veränderungsprozesse direkt verdecken.
Aktuell nutzt die Branche häufig Bildkompositionstechnologien, um Wolken zu entfernen und Rauschen zu reduzieren, wodurch standardisierte, wolkenfreie Bilder entstehen. Dies verbessert zwar die Datenqualität und -nutzbarkeit, führt aber auch zu einem erheblichen Informationsverlust.Feine zeitliche Merkmale wie phänologische Dynamiken und kurzfristige abrupte Veränderungen werden während des Syntheseprozesses oft abgeschwächt oder sogar ausgelöscht, was zum Verlust einiger wichtiger Informationen führt.
In den letzten Jahren wurden grundlegende Fernerkundungsmodelle durch umfangreiches Vortraining deutlich verbessert. Die meisten Modelle basieren jedoch weiterhin auf idealisierten Daten, die einer starken Filterung und Normalisierung unterzogen wurden. Beim Training werden ausschließlich wolkenfreie synthetische Bilder oder Mittelwerte aus Zeitreihen verwendet. Dieser Ansatz verwirft effektiv einen Großteil der Beobachtungsdaten, die zwar durch Wolkenbedeckung beeinflusst sind, aber dennoch reale Veränderungsmuster enthalten. Daher stoßen die Modelle bei der Verarbeitung von spärlichen, unvollständigen und komplexen, wolkenbedeckten Zeitreihendaten in realen Anwendungsszenarien an ihre Grenzen.Eine instabile Merkmalsextraktion verringert die Generalisierungsfähigkeit erheblich.
Um diesen Engpass zu überwinden, entwickelte ein gemeinsames Forschungsteam der Universitäten Cambridge, Aalto und Bristol ein neues Paradigma zum Lernen zeitlicher Merkmale auf Basis des Barlow-Twins-Algorithmus. Anstatt Daten mit Wolkenanteil herauszufiltern, beschränkt dieses Paradigma die Merkmalskonsistenz zwischen verschiedenen Beobachtungs-Teilmengen am selben Ort. Dadurch kann das Modell selbstständig stabile räumlich-zeitliche Variationen der Erdoberfläche erlernen und Fernerkundungsmerkmale mit zeitlicher Abtastinvarianz darstellen. Darauf aufbauend…Das Forschungsteam schlug außerdem TESSERA vor, ein Fernerkundungsgrundlagenmodell auf Pixelebene für multimodale Zeitreihendaten von Sentinel-1/Sentinel-2.
Die zugehörigen Forschungsergebnisse mit dem Titel „TESSERA: Temporal Embeddings of Surface Spectra for Earth Representation and Analysis“ wurden auf der Preprint-Plattform arXiv veröffentlicht.
Forschungshighlights:
* Konstruktion globaler, pixelgenauer Feature-Einbettungen mit hoher Label-Nutzung, Entwicklung einer neuartigen selbstüberwachten Architektur und Training eines pixelgenauen Fernerkundungs-Basismodells, das multimodale Sentinel-1/Sentinel-2-Daten integriert.
* Einführung einer Daten-als-eingebetteten Lösung, die den FAIR-Richtlinien entspricht, und Veröffentlichung eines globalen jährlichen Datensatzes von 10-Meter-Auflösung pixelgenauen 8-Bit-Integer-Feature-Embeddings, wodurch konforme Fernerkundungsressourcen bereitgestellt werden, die direkt eingesetzt werden können.
* Experimente haben gezeigt, dass TESSERA bei verschiedenen Klassifizierungs-, Segmentierungs- und Regressionsaufgaben eine hochmoderne Genauigkeit bei extrem hoher Labeling-Effizienz erreichen kann, wobei typischerweise nur ein leichter Aufgabenheader und minimaler Rechenaufwand erforderlich sind.

Lesen Sie das Dokument:
https://hyper.ai/papers/2506.20380
Datensatz: Aufbau eines mehrdimensionalen Bewertungssystems von globalen bis zu lokalen Ebenen
In dieser Studie wurde ein umfangreiches, globales Fernerkundungsdatensystem mit Zeitreihendaten erstellt, das sowohl für das Vortraining des Modells als auch für die Evaluierung seiner Generalisierungsfähigkeit verwendet wird. Das gesamte Datensystem besteht aus einem Datensatz für das Vortraining und einem Datensatz für die nachfolgende Evaluierung.Alle Daten basieren auf Sentinel-1-Radardaten und Sentinel-2-optischen Daten.Die sich ergänzenden Vorteile von Radar- und optischer Beobachtung sollten voll ausgeschöpft werden.

Während der Vorbereitungsphase erstellte das Forschungsteam einen umfangreichen Zeitreihendatensatz auf globaler Ebene, der den Zeitraum von 2017 bis 2024 abdeckt und räumlich über dreitausend Rasterkacheln weltweit umfasst.Insgesamt etwa 800 Millionen d-Pixel-Abtastwerte.Im Gegensatz zu vielen sorgfältig ausgewählten und standardisierten Datensätzen bewahrt dieser Datensatz so viele ursprüngliche Merkmale realer Beobachtungen wie möglich, darunter fehlende Daten, unregelmäßige Stichproben und Wolkenbedeckung. Darüber hinaus ist jedem Zeitschritt eine binäre Maske beigefügt, die die gültigen Zustände der Beobachtungen markiert und es dem Modell ermöglicht, fehlende Daten und Unterschiede in der Beobachtungsqualität explizit zu erkennen.
Nachgelagerte EvaluierungsphaseDas Forschungsteam wählte sechs öffentlich verfügbare Benchmark-Datensätze aus, die drei Hauptaufgaben abdecken: Klassifizierung, Segmentierung und Regression.Das Evaluierungsgebiet umfasst mehrere Länder und Regionen, darunter Deutschland, Frankreich, Österreich, Finnland und Malaysia, und schließt typische Anwendungsszenarien wie Land- und Forstwirtschaft ein. Jede Aufgabe beinhaltet sowohl großflächige regionale Datensätze als auch verfeinerte lokale Datensätze, um die regionsübergreifende Übertragbarkeit des Modells bzw. seine Fähigkeiten zur detaillierten Merkmalsmodellierung zu bewerten.
Darüber hinaus, als Reaktion auf die derzeitige Knappheit an hochauflösenden, multitemporalen Sentinel-1/2-Multimodal-Annotationsdaten,Das Forschungsteam entwickelte außerdem unabhängig zwei neue Bewertungsmaßstäbe:Bei dem ersten handelt es sich um den österreichischen Datensatz zur Kartierung von Nutzpflanzen auf Parzellenebene, der zur Bewertung der Klassifizierungs- und Segmentierungsfähigkeiten in Szenarien der Präzisionslandwirtschaft verwendet wird; beim zweiten um den südostasiatischen Datensatz zur Kronenhöhe von Wäldern, der auf der Grundlage einer Lidar-Korrektur erstellt wurde und zur Überprüfung der Leistungsfähigkeit bei Aufgaben zur Inversion von Waldstrukturparametern verwendet wird.
Ein pixelbasiertes Basismodell für Erdbeobachtungsmissionen
TESSERA ist so konzipiert, dass Modelle stabile Repräsentationen direkt aus komplexen und unvollständigen Zeitreihendaten lernen können, wobei so viele ursprüngliche Beobachtungsinformationen wie möglich erhalten bleiben. Dadurch wird die Abhängigkeit von Datenaufbereitungs-, Vervollständigungs- und Reparaturprozessen reduziert.
zu diesem Zweck,In dieser Studie wurde erstmals eine neue Methode zur Organisation von Zeitreihendaten vorgeschlagen – d-Pixel.Bei der traditionellen Analyse werden typischerweise Einzelszenenbilder oder feste Zeitreihen als Eingabe verwendet, während sich d-pixel auf einen einzelnen räumlichen Ort konzentriert und Beobachtungen desselben Pixels aus verschiedenen Quellen, die zu unterschiedlichen Zeitpunkten erfasst wurden, in einer Beobachtungssequenz in chronologischer Reihenfolge organisiert.Jedes d-Pixel enthält nicht nur optische Informationen von Sentinel-2 und Radarinformationen von Sentinel-1, sondern identifiziert mithilfe von Maskenvektoren auch die Zeitpunkte, an denen Wolken die Sicht versperren oder Daten fehlen.Diese Darstellungsmethode erhält die zeitlichen Merkmale von Oberflächenveränderungen vollständig. Ob es sich um langsame Veränderungen durch Pflanzenwachstum oder kurzfristige, abrupte Veränderungen durch Katastrophen, Störungen usw. handelt – sie alle bleiben erhalten, wodurch Informationsverluste im herkömmlichen Regularisierungsprozess grundsätzlich vermieden werden.
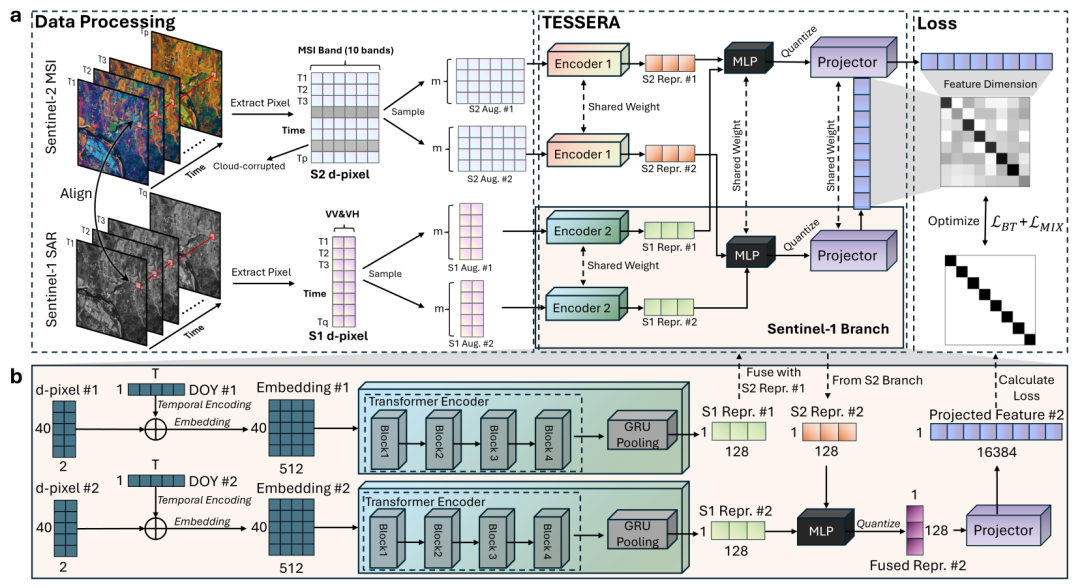
Im Hinblick auf die Modellarchitektur,TESSERA verwendet einen Dual-Branch-Encoder zur separaten Verarbeitung optischer und Radardaten.Die beiden Datentypen weisen deutlich unterschiedliche Bildgebungsmechanismen und physikalische Eigenschaften auf. Durch unabhängige Kodierung lassen sich ihre jeweiligen Merkmale vollständig erfassen, und die anschließende Fusion ermöglicht multimodale Komplementarität. Für jede Modalität bettet das Modell zunächst die relevanten Beobachtungen ein und fügt eine lernbare, intra-annuelle, tägliche Positionskodierung hinzu, um zeitliche Informationen einzuführen. Anschließend werden mithilfe eines Transformer-Encoders langfristige zeitliche Abhängigkeiten modelliert. Abschließend aggregiert eine Gated Recurrent Unit (GRU) die gesamte Zeitreihe, um eine unimodale Repräsentation fester Dimension zu erzeugen. Nach der Fusion optischer und Radar-Merkmale entsteht eine 128-dimensionale multimodale Oberflächenrepräsentation. Die Studie führt außerdem ein quantisiertes Wahrnehmungstraining ein, bei dem die finalen Merkmale in 8-Bit-Ganzzahlen komprimiert werden.Der Speicherplatzbedarf wurde um etwa 75% reduziert, und zwar nahezu ohne Genauigkeitsverlust.
Die Vortrainingsstrategie ist eine Kerninnovation von TESSERA. Basierend auf dem Barlow-Twin-Framework für selbstüberwachtes Lernen extrahiert das System für dasselbe d-Pixel zufällig zwei Teilmengen von Beobachtungen aus seiner gesamten Zeitreihe, um zwei unterschiedliche „Ansichten“ zu konstruieren. Obwohl die beiden Beobachtungsmengen unterschiedliche Zeitpunkte enthalten und sogar einige Zeitschritte fehlen, beschreiben sie dasselbe Oberflächenobjekt.
Während des Trainings muss das Modell die beiden Beobachtungssätze auf einen möglichst konsistenten Merkmalsraum abbilden. Auf diese WeiseDas Modell lernt nicht mehr die momentanen Merkmale einer bestimmten Beobachtung, sondern vielmehr die stabilen Oberflächenmuster, die hinter verschiedenen Beobachtungen verborgen sind.Dies führt zu Merkmalsdarstellungen, die gegenüber zeitlichen Abtastmethoden robust sind. Darüber hinaus stellt die Studie eine hybride Regularisierungs- und globale Shuffling-Strategie vor, um die Robustheit des Modells gegenüber Beobachtungsstörungen und räumlicher Autokorrelation weiter zu verbessern.
TESSERA zeigt seine Vorteile bei Daten mit wenigen Labels und spärlichen Datensätzen.
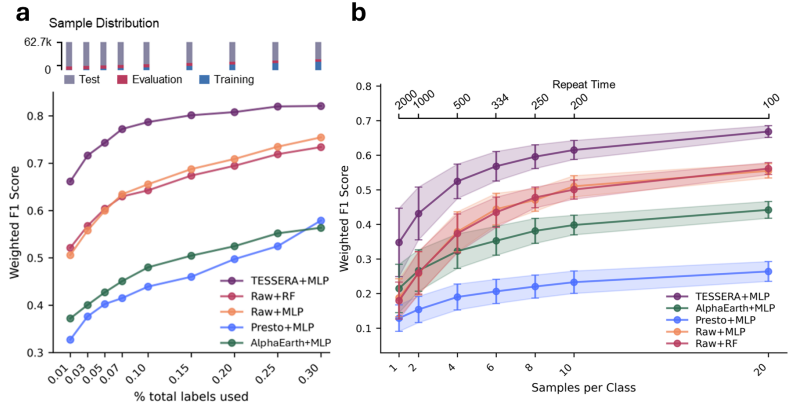
Um die Leistungsfähigkeit von TESSERA umfassend zu evaluieren, wurde in dieser Studie ein systematisches Experiment auf Basis typischer Anwendungsszenarien der Fernerkundung konzipiert. Ausgehend von drei Aufgaben – Klassifizierung, Segmentierung und Regression – wurde die Leistungsfähigkeit des Modells unter verschiedenen Datenskalen, Annotationsbedingungen und regionalen Szenen überprüft. Mehrere gängige Fernerkundungsmodelle und klassische visuelle Modelle dienten als Vergleichsbasis, und es wurden drei einheitliche Annotationsverhältnisse von 1%, 30% und 100% festgelegt.Im Fokus steht die Beurteilung der Lernfähigkeit in Szenarien, in denen nur wenige Tags verfügbar sind.Um Fairness zu gewährleisten, werden für nachgelagerte Inferenzprozesse über verschiedene Aufgaben hinweg Lightweight-Adapter verwendet.
Bei Klassifizierungsaufgaben zeigt TESSERA einen deutlichen Vorteil beim Erlernen zeitlicher Merkmale. Das Modell erzielt führende Ergebnisse sowohl bei der Klassifizierung von Baumarten auf nationaler Ebene als auch bei der verfeinerten Klassifizierung von Nutzpflanzen.Insbesondere in Szenarien mit extrem niedrigen Stichprobenumfängen, in denen nur 1%-gelabelte Daten verwendet werden, behält TESSERA eine stabile Leistung bei.Die Klassifizierungsgenauigkeit wurde im Vergleich zum optimalen Ausgangswert um etwa 8 Prozentpunkte verbessert. Dieser Vorteil beruht hauptsächlich auf der effektiven Modellierung langfristiger Oberflächenveränderungen. Durch die Nutzung vollständiger zeitlicher Beobachtungen zur Erfassung von Vegetationswachstumszyklen und phänologischen Merkmalen lassen sich selbst mit minimalen Annotationen hochgradig differenzierende Kategorien erstellen.
Bei Segmentierungsaufgaben demonstrierte TESSERA ebenfalls exzellente räumliche Detailwiedergabe. Bei der Segmentierung großflächiger Ackerflächen erzielte das Modell unter vollständig annotierten Bedingungen branchenführende Ergebnisse; in Szenarien mit wenigen Annotationen übertraf es sogar alle Vergleichsmodelle. Es ist erwähnenswert, dass…TESSERA kann räumliche Kontextinformationen effektiv mit nur einem ressourcenschonenden Decoder erlernen und dabei die Genauigkeit beibehalten sowie gleichzeitig eine effiziente Bereitstellung gewährleisten.Auf dem österreichischen Datensatz zur semantischen Segmentierung von Nutzpflanzen erzeugt das Modell klarere Parzellengrenzen, reduziert die Verwechslungsgefahr zwischen verschiedenen Nutzpflanzen deutlich und weist eine stärkere semantische Gesamtkonsistenz auf.
Die Regressionsanalyse untersucht primär die Fähigkeit des Modells, kontinuierliche Oberflächenparameter abzubilden. Bei der Schätzung der oberirdischen Biomasse erzielte TESSERA über verschiedene Segmentierungsmaßstäbe hinweg die besten Ergebnisse mit geringeren Vorhersagefehlern und einer kontinuierlicheren räumlichen Verteilung. Bei der Inversion der Kronenhöhe demonstrierte das Modell zudem seine Fähigkeit, dreidimensionale Informationen zur Waldstruktur zu erfassen. Die Schätzergebnisse zeigten die höchste Übereinstimmung mit den Lidar-Messdaten und rekonstruierten effektiv die vertikalen Strukturmerkmale des Waldes.
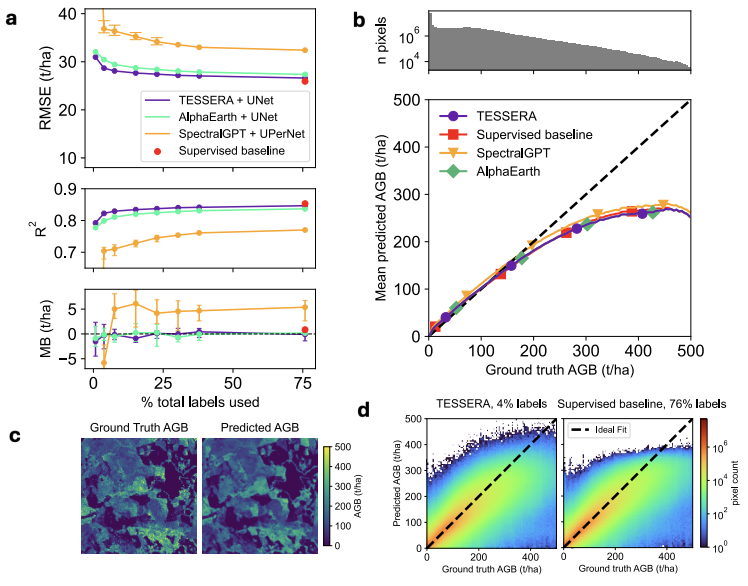
Basierend auf allen experimentellen Ergebnissen,TESSERA behält bei allen drei Aufgabentypen – Klassifizierung, Segmentierung und Regression – einen stabilen Vorsprung, der unter komplexen Bedingungen wie geringer Annotation, spärlichen Daten und fehlenden Beobachtungen noch deutlicher wird.Im Vergleich zu vielen Modellen, die auf qualitativ hochwertigen Trainingsdaten basieren, zeigt TESSERA in realen Fernerkundungsszenarien einen allmählicheren Leistungsabfall und beweist damit eine stärkere Robustheit und Generalisierungsfähigkeit.
Letzte Worte
Benötigen grundlegende Fernerkundungsmodelle tatsächlich „ideale Daten“? Der Ansatz von TESSERA liefert eine andere Antwort: Er ermöglicht es Modellen, direkt mit unvollständigen, unregelmäßigen und häufig durch Wolken beeinträchtigten Beobachtungssequenzen aus der realen Welt zu arbeiten und Merkmalsdarstellungen mit zeitreihenunabhängiger Abtastung innerhalb eines selbstüberwachten Rahmens zu erlernen. Dies bedeutet nicht, dass die Datenbereinigung unwichtig geworden ist, sondern legt vielmehr nahe, dass Forschende ihren Fokus von der „Datenbereinigung“ auf das „Lernen von Modellen, mit unvollkommenen Daten umzugehen“ verlagern könnten. Schließlich ist jedes Satellitenbild mit Wolken Teil einer realen Beobachtung. Anstatt ständig nach „perfekteren“ Daten zu streben, könnte die Befähigung von Modellen, die Komplexität der realen Welt zu verstehen, ein entscheidender Weg für die Generalisierung grundlegender Fernerkundungsmodelle sein.








