Command Palette
Search for a command to run...
Wöchentlicher Paper-Bericht | DeepMind D4RT: Einheitliche Dynamische 4D-Rekonstruktion, Inferenzgeschwindigkeit Steigt Um Das 300-fache; Columbia University Und Andere Widerlegen Die Illusion Der Universalität Von AGI Und Schlagen Die SAI-Theorie Vor, Um Die Ziele Der KI-Evolution Neu Zu Gestalten… Ein Kurzer Überblick Über Die Neuesten KI-Veröffentlichungen Der Woche

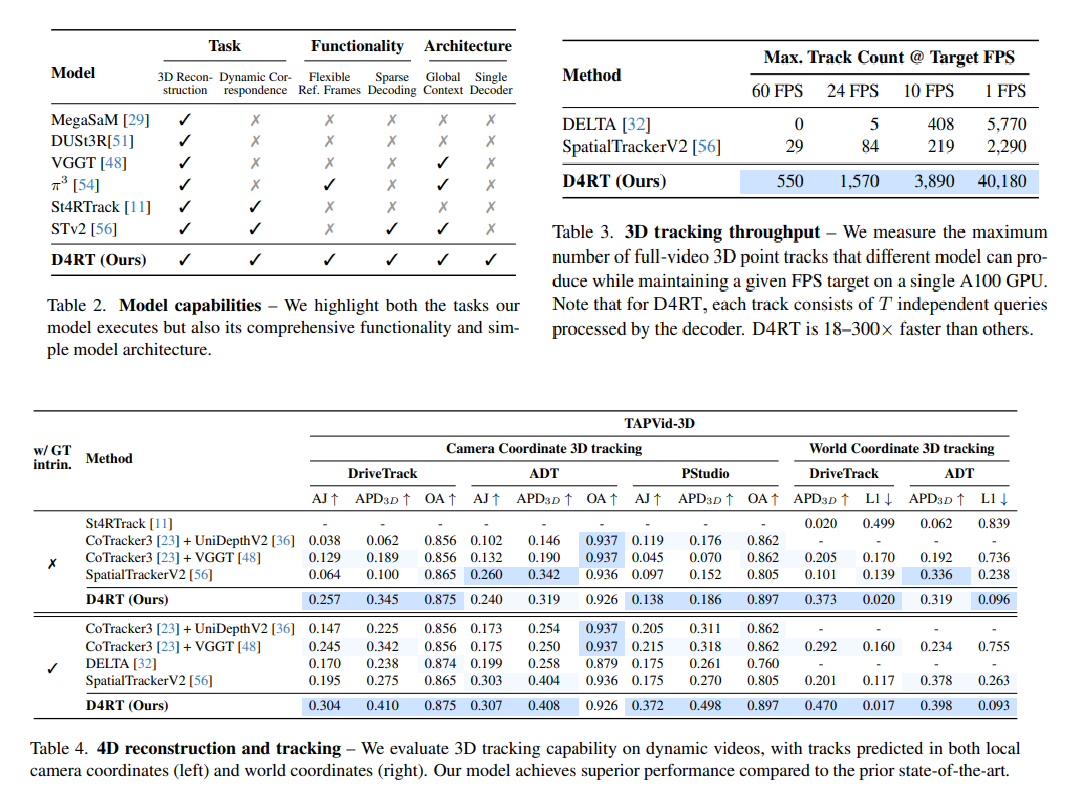
Das Verstehen und Rekonstruieren komplexer Geometrien und Bewegungsabläufe in dynamischen Videos stellt seit jeher eine große Herausforderung im Bereich Computer Vision dar. Traditionelle Lösungen basieren oft auf dem Zusammensetzen fragmentierter, aufgabenspezifischer Modelle oder verstricken sich in rechenintensiven, framebasierten iterativen Optimierungsverfahren. Um dieses Problem zu lösen, hat ein Forschungsteam von Google DeepMind in Zusammenarbeit mit der Universität Oxford und dem University College London (UCL) den starren Ansatz der framebasierten Dekodierung grundlegend verändert.Wir stellen ein einfaches, aber leistungsstarkes Feedforward-System vor, D4RT, das mit nur einem einzigen Videoeingang Tiefe, räumlich-zeitliche Konsistenz und vollständige Kameraparameter gemeinsam ableiten kann.
Die Kerninnovation dieser Architektur liegt in der Einführung eines hochflexiblen Abfragemechanismus. Nachdem das Video in eine latente Repräsentation der globalen Szene kodiert wurde, ermöglicht das Modell einem ressourcenschonenden Decoder, den 3D-Zustand jedes Pixels in Raum und Zeit unabhängig und parallel zu untersuchen. Dadurch wird der enorme Aufwand vermieden, der durch die Verwaltung mehrerer komplexer Decoder entsteht. Experimentelle Ergebnisse zeigen, dass…Das hochskalierbare Design von D4RT setzt nicht nur neue Bestleistungen (SOTA) bei verschiedenen Aufgaben, darunter dynamische 4D-Rekonstruktion und -Verfolgung, sondern erzielt dank seiner hochgradig parallelisierbaren Architektur auch exponentielle Verbesserungen der Tracking- und Inferenzeffizienz um das 18- bis 300-Fache im Vergleich zu bestehenden State-of-the-Art-Methoden.Dies setzt einen neuen Maßstab für die durchgängige 4D-Visualisierung der nächsten Generation, die hohe Skalierbarkeit mit theoretischer Eleganz verbindet.
Link zum Artikel:https://go.hyper.ai/kGrFN
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Um mehr Nutzern die neuesten Entwicklungen auf dem Gebiet der künstlichen Intelligenz in der akademischen Welt näherzubringen,Die Website von HyperAI (hyper.ai) verfügt nun über einen Bereich „Neueste Veröffentlichungen“, der regelmäßig mit hochaktuellen KI-Forschungsarbeiten aktualisiert wird.Hier sind 8 beliebte KI-Veröffentlichungen, die wir empfehlen. Werfen wir einen kurzen Blick auf die neuesten KI-Erfolge dieser Woche ⬇️
Die Zeitungsempfehlung dieser Woche
1.D4RT
Titel des Artikels:
Effiziente Rekonstruktion dynamischer Szenen – ein D4RT nach dem anderen
Google DeepMind hat mit D4RT ein einheitliches Feedforward-Modell für die effiziente 4D-Rekonstruktion und das Tracking in dynamischen Szenen entwickelt. Im Gegensatz zu herkömmlichen, framebasierten Dekodierungsverfahren kodiert D4RT zunächst ein einzelnes Video in eine globale Szenenrepräsentation und kombiniert anschließend über einen unabhängigen Abfragemechanismus raumzeitliche Koordinaten mit lokalen RGB-Informationen, um die 3D-Position jedes beliebigen Punktes zu bestimmen. Dieses Design ermöglicht eine raumzeitliche Entkopplung, wodurch der Rechenaufwand deutlich reduziert wird, während gleichzeitig hochfrequente geometrische Details erhalten bleiben. Experimente zeigen, dass D4RT Tiefenkarten, Punktwolken, Kameraparameter und pixelgenaue Tracking-Ergebnisse einheitlich ausgeben kann und auf mehreren Standards Bestwerte (SOTA) erzielt. Die Inferenzgeschwindigkeit wird dabei um das Zehn- bis Hundertfache oder mehr gesteigert, was ein neues Paradigma für die effiziente 4D-Wahrnehmung darstellt.
Papier und detaillierte Interpretation:https://go.hyper.ai/kGrFN
2.SAI
Titel des Artikels:
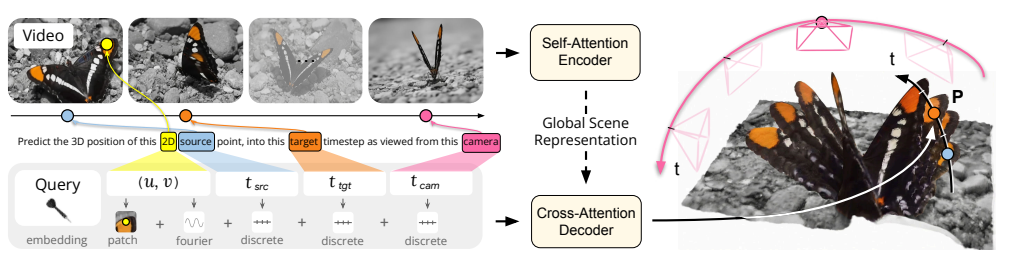
KI muss sich durch übermenschliche, anpassungsfähige Intelligenz spezialisieren.
Sich verlassen aufColumbia University und New York UniversityEin Forschungsteam veröffentlichte eine theoretische Studie, die das Konzept der Künstlichen Allgemeinen Intelligenz (AGI) kritisierte und vorschlug, die KI-Entwicklung durch Übermenschliche Adaptive Intelligenz (SAI) neu auszurichten. Die Studie zeigt auf, dass menschliche Intelligenz im Wesentlichen ein hochspezialisiertes Ergebnis von Anpassung und nicht wirklich universell ist. Daher leiden bestehende, auf dem Menschen basierende Definitionen von AGI im Allgemeinen unter theoretischer Unmöglichkeit oder logischen Widersprüchen.
Das Team argumentiert, dass KI Spezialisierung fördern und den Fokus der Bewertung auf die Geschwindigkeit der Anpassung beim Erwerb neuer Fähigkeiten verlagern muss. Um intelligente KI zu erreichen, sollte sich die Branche von ihrer Abhängigkeit von einzelnen, großen autoregressiven Modellen lösen und ihre Anstrengungen auf Folgendes konzentrieren:Selbstüberwachtes Lernen(SSL) und prädiktive WeltmodelleDurch architektonische Diversifizierung kann KI sich schnell an die menschlichen Fähigkeiten anpassen und diese in hochwertigen Bereichen umfassend übertreffen.
Papier und detaillierte Interpretation:https://go.hyper.ai/XEFn9
3.KI-Psychose
Titel des Artikels:
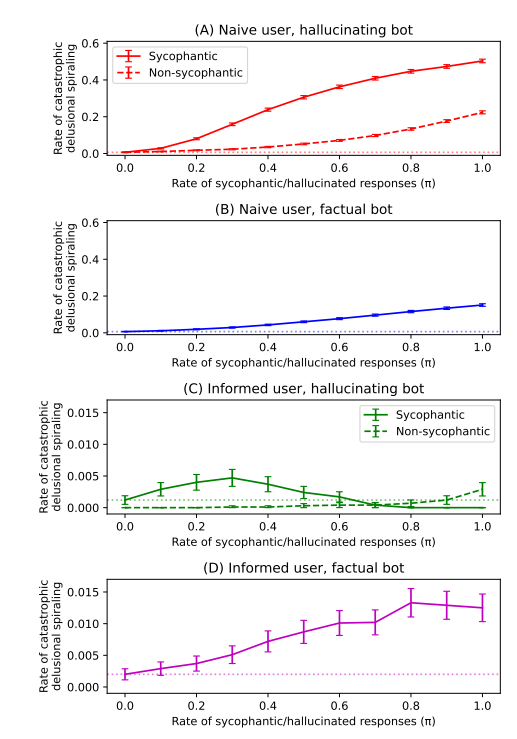
Speichelleckernde Chatbots führen zu einer Spirale der Selbsttäuschung, selbst bei idealen Bayesianern.
Das MIT und die University of Washington haben die „Wahnspirale“ in der künstlichen Intelligenz untersucht. Das Team entwickelte ein ideales Bayes’sches Dialogmodell und ein vierstufiges kognitives Hierarchiemodell, um zu bestätigen, dass die „Schmeichelei“-Eigenschaft der KI einen direkten kausalen Einfluss auf dieses Phänomen hat. Simulationen zeigen, dass selbst vollkommen rationale Nutzer stark anfällig dafür sind, in diese Spirale zu geraten. Das Team evaluierte zwei Gegenstrategien: die Beschränkung des Modells auf die Ausgabe ausschließlich wahrheitsgemäßer Informationen, um die Illusion zu eliminieren, und die vorherige Information der Nutzer über die Tendenz der KI zur Schmeichelei. Die Ergebnisse zeigen, dass selbst eingeschränkte KI Nutzer durch selektive Faktenpräsentation irreführen kann und informierte Nutzer weiterhin anfällig sind; keiner der Ansätze kann das Problem vollständig beseitigen. Die Branche kann sich nicht allein auf die Beseitigung von Illusionen oder die Aufklärung der Nutzer verlassen; sie muss das Problem der Schmeichelei des Modells direkt angehen.
Papier und detaillierte Interpretation:https://go.hyper.ai/Zhsjw
4.Agenten des Chaos
Titel des Artikels:
Agenten des Chaos
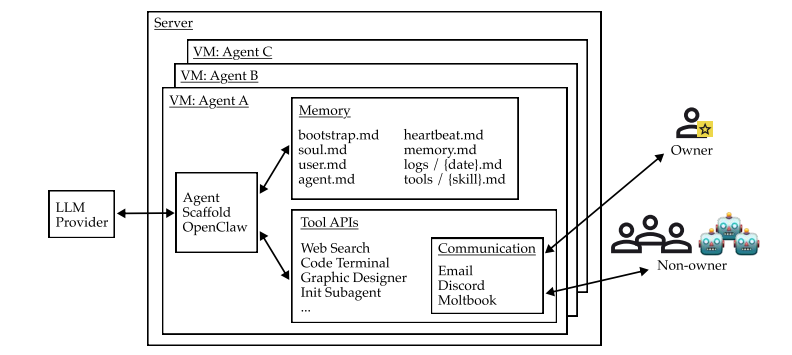
Eine empirische Red-Team-Übung, die auf autonome Agenten auf Basis großer Sprachmodelle (LLMs) abzielte, deckte Sicherheitsrisiken auf Systemebene auf, die durch die Integration von Autonomie, Tool-Aufruf und Mehrparteienkommunikation entstehen. Über einen zweiwöchigen Testzeitraum hinweg identifizierten 20 KI-Forscher in einer realen Einsatzumgebung mit persistentem Speicher, E-Mail- und Shell-Zugriffsberechtigungen mithilfe von Angriffstechniken wie Social Engineering, Identitätsdiebstahl und Prompt-Injection elf typische Fehlerfälle.
Experimentelle Ergebnisse zeigen gravierende Sicherheitslücken in aktuellen intelligenten Agenten auf: Sie sind hochgradig anfällig für unautorisierte Befehle von Nicht-Besitzern, den Verlust sensibler Daten, die Ausführung irreversibler, zerstörerischer Operationen und das Verfallen in Endlosschleifen, die Denial-of-Service-Angriffe (DoS) auslösen. Darüber hinaus können Interaktionen zwischen mehreren Agenten die domänenübergreifende Ausbreitung dieser Risiken verstärken. Die Ursache dieser Schwachstellen liegt im Fehlen eines klaren Stakeholder-Modells und eines ausgeprägten Bewusstseins für die eigenen Grenzen bei intelligenten Agenten. Die Branche benötigt dringend ein systematisches Rahmenwerk für Zugriffskontrolle, Authentifizierung und Verantwortlichkeit.
Papier und detaillierte Interpretation:https://go.hyper.ai/AgTju
5.Perzeptron
Titel des Artikels:
Wenn LLMs menschenähnliche Eigenschaften haben, dann hat Age of Empires II diese auch.
Das Forschungsteam hinterfragte die gängige Annahme in der Forschung zu groß angelegten Sprachmodellen, dass diese anthropomorphe Eigenschaften besitzen, indem es ein neuronales Netzwerk in *Age of Empires II* konstruierte und dessen Turing-Vollständigkeit nachwies. Dies belegt, dass die anthropomorphen Merkmale des Modells nicht inhärent einzigartig sind; Änderungen an der zugrundeliegenden Struktur können die menschliche Wahrnehmung seines Verhaltens grundlegend verändern. Die Autoren argumentieren überzeugend, dass die Annahme der Existenz oder Nichtexistenz allgemeiner anthropomorpher Attribute im Versuchsaufbau, unabhängig vom Ergebnis, zwangsläufig zu Zirkelschlüssen oder unvollständigen Schlussfolgerungen führt. Daher schlägt die Studie ein Forschungsparadigma der „Nullhypothese“ vor und fordert die wissenschaftliche Gemeinschaft auf, anthropomorphe Annahmen in Experimenten aufzugeben und stattdessen rein objektive Messungen beobachtbaren Verhaltens durchzuführen, um so Überinterpretationen zu vermeiden und wissenschaftliche Strenge zu gewährleisten.
Papier und detaillierte Interpretation:https://go.hyper.ai/LxlWV
6.ARA
Titel des Artikels:
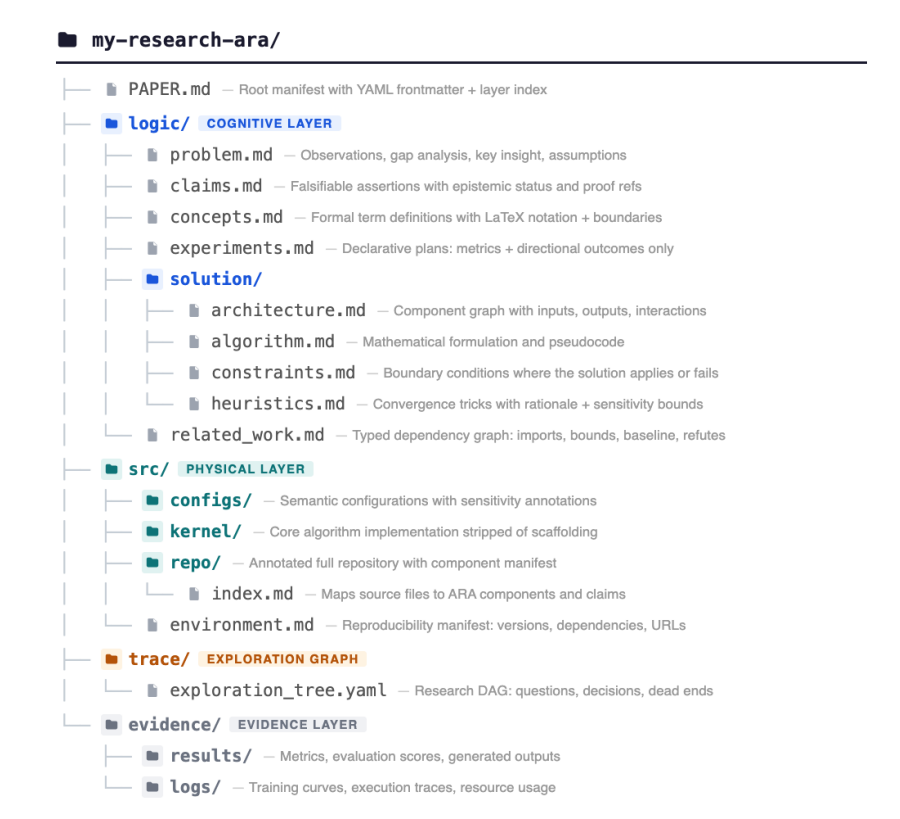
Die letzte von Menschen verfasste Arbeit: Agentennative Forschungsartefakte
Um dem Problem traditioneller, für menschliche Leser konzipierter PDF-Dokumente zu begegnen, die Versuch-und-Irrtum-Protokolle und Code-Details ausblenden und somit die Reproduktion und Erweiterung von Forschungsergebnissen durch KI erschweren, entwickelte das Forschungsteam das Agent Native Research Artifact (ARA)-Protokoll. ARA rekonstruiert Dokumente zu einem für Agenten ausführbaren Paket mit vier Schichten: wissenschaftlicher Logik, ausführbarem Code, einem Explorationsgraphen, der aus Fehlern gewonnene Erkenntnisse speichert, und den zugrundeliegenden Belegen. Unterstützt wird dies durch drei Kernmechanismen: einen Echtzeit-Forschungsmanager, einen Compiler und ein integriertes Review-System. Experimente zeigen, dass ARA die Genauigkeit der Fragebeantwortung des KI-Agenten in Benchmark-Tests signifikant verbesserte (von 72,41 TP3T auf 93,71 TP3T) und die Reproduktionsrate von 57,41 TP3T auf 64,41 TP3T steigerte. ARA beseitigt effektiv narrative Barrieren in wissenschaftlichen Dokumenten, ermöglicht den vollständigen Transfer von Forschungserfahrung und legt damit ein solides Fundament für ein KI-gestütztes Forschungsparadigma.
Papier und detaillierte Interpretation:https://go.hyper.ai/fGwr7
7.Agent-as-a-Service
Titel des Artikels:
Das Ende der Softwareentwicklung: Wie KI-Agenten das Software-Paradigma grundlegend umstrukturieren
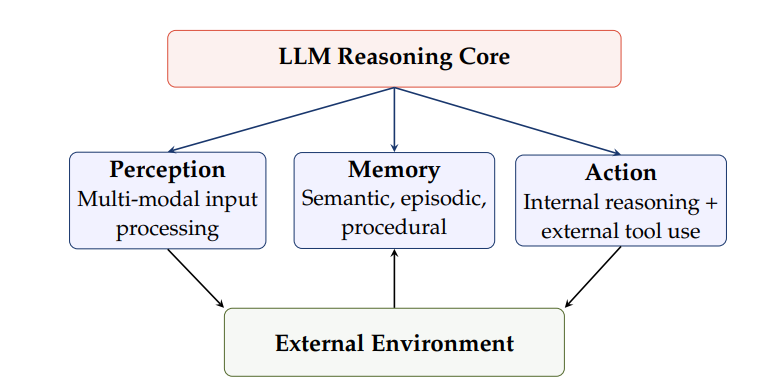
KI-Agenten verändern das Software-Engineering-Paradigma grundlegend. Große Sprachmodelle (LLMs) fungieren als Inferenzmaschinen und können Code dynamisch generieren und verwerfen. Dadurch überwinden sie die Komplexitätsengpässe traditioneller Software und die Grenzen der menschlichen Kognition. Softwarebereitstellungsmodelle entwickeln sich hin zu „Agent as a Service (AaaS)“ und begründen die völlig neue Disziplin des „Agenten-Engineerings“. In diesem neuen Paradigma sind Menschen nicht mehr die Programmierer, sondern die Architekten von Intentionen und die Koordinatoren der Agenten. Obwohl aktuelle Benchmarks das enorme Potenzial von Agenten belegen, stehen sie weiterhin vor Herausforderungen bei der langfristigen, kontinuierlichen Systemwartung. Um diese Herausforderungen zu bewältigen, schlagen die Autoren einen vierstufigen Fahrplan für ein sich selbst entwickelndes Agenten-Ökosystem vor.
Papier und detaillierte Interpretation:https://go.hyper.ai/zrpkH
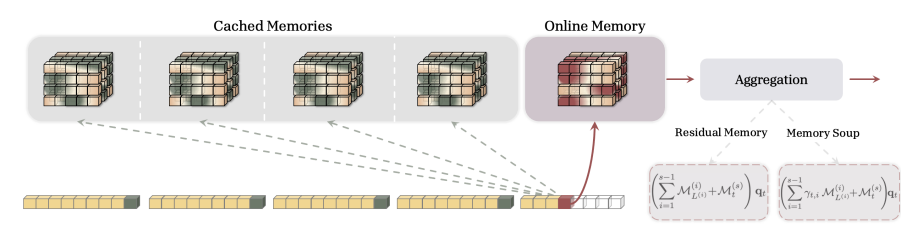
8.Speicher-Caching
Titel des Artikels:
Speicher-Caching: RNNs mit wachsendem Speicher
Ein Team von Google Research entwickelte das Memory Caching (MC)-Framework, um die Einschränkungen rekurrenter neuronaler Netze (RNNs) aufgrund ihres festen Speichers zu beheben. Dieser Speicher begrenzt die Verarbeitung langer Kontexte und erschwert das Abrufen von Informationen. Durch die Segmentierung von Sequenzen, das Zwischenspeichern von Speicherzustands-Checkpoints und die Kombination von vier Aggregationsstrategien – Gating, Sparse Selection usw. – ermöglicht MC eine dynamische Erhöhung der Speicherkapazität von RNNs mit der Sequenzlänge. Dadurch wird ein flexibler Kompromiss zwischen O(L)- und O(L²)-Rechenkomplexität erzielt. Experimente zeigen, dass diese Technik die Leistung verschiedener RNN-Modelle in der Sprachmodellierung und beim Abruf langer Texte signifikant verbessert und die Leistungslücke zu Transformer-Netzwerken deutlich verringert, während gleichzeitig eine hohe Effizienz erhalten bleibt.
Papier und detaillierte Interpretation:https://go.hyper.ai/pYRGG
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








