Command Palette
Search for a command to run...
Online-Tutorial | Team Der Hong Kong University of Science and Technology Veröffentlicht Erste DVD Eines Deterministischen Video-Tiefen-Frameworks Als Open Source Und Erzielt Damit Modernste Ergebnisse Mit Zero-Shot-Technologie

Die Tiefenschätzung zählt zu den grundlegendsten und wichtigsten Aufgaben im Bereich der 3D-Bildverarbeitung. Von autonomem Fahren und Roboternavigation über AR/VR und digitale Zwillinge bis hin zur Videogenerierung müssen Systeme die räumlichen Beziehungen zwischen Objekten und der Kamera in einer Szene präzise erfassen. Die Tiefenschätzung in Videos steht jedoch seit Langem vor einem unauflöslichen Widerspruch: Generative Methoden, wie beispielsweise Diffusionsmodelle, verfügen zwar über ein starkes semantisches Verständnis und können mithilfe großer Mengen vortrainierter Daten komplexe Szenenstrukturen ableiten, ihre Vorhersageergebnisse werden jedoch häufig durch zufällige Stichprobenverfahren beeinflusst, wodurch sie anfällig für geometrische Illusionen, Skalierungsdrift und zeitliche Instabilität sind. Traditionelle diskriminative Methoden hingegen, obwohl sie eine höhere Deterministik aufweisen, sind stark von umfangreichen annotierten Daten abhängig, was zu hohen Trainingskosten und einer begrenzten Generalisierungsfähigkeit in komplexen Szenen führt.
Um diesem Problem der Branche zu begegnen, schlug das Team der Hong Kong University of Science and Technology (Guangzhou) DVD (Deterministic Video Depth Estimation) vor.Zum ersten Mal wurde ein vortrainiertes Videodiffusionsmodell deterministisch in einen einzigen Vorwärtspropagations-Videotiefenschätzer transformiert.Im Gegensatz zu herkömmlichen Diffusionsmodellen, die mehrere Iterationen zur Ergebnisgenerierung benötigen, kann DVD die Tiefenvorhersage mit einer einzigen Vorwärtsberechnung durchführen. Dies verbessert nicht nur die Effizienz der Inferenz erheblich, sondern beseitigt auch vollständig das durch zufälliges Abtasten verursachte Problem geometrischer Illusionen und gewährleistet so die zeitliche Konsistenz und strukturelle Stabilität von Videosequenzen.
Und was noch wichtiger ist:DVD hat erfolgreich eine große Menge an geometrischem und semantischem Vorwissen bewahrt, das im grundlegenden Videomodell enthalten war.Durch innovative strukturelle Verankerungsmechanismen und die Latent Manifold Correction (LMR)-Technologie kann das Modell Objektkanten, hochfrequente Texturen und Bewegungsdetails präzise wiederherstellen und gleichzeitig die globale Szenenstabilität beibehalten, wodurch die strukturelle Genauigkeit von Tiefenkarten deutlich verbessert wird.
In mehreren öffentlich verfügbaren Benchmark-Tests erreicht die Zero-Sample-Performance von DVD ein State-of-the-Art-Niveau (SOTA).Darüber hinaus erreichte es mit nur 367.000 Trainingsbildern ein führendes Niveau – eine Reduzierung um den Faktor 163 im Vergleich zu den 60 Millionen Bildern, die gängige diskriminative Verfahren benötigen. Dies bestätigt nicht nur das enorme Potenzial generativer Basismodelle für das geometrische Verständnis, sondern eröffnet auch einen völlig neuen technischen Weg für die kostengünstige und hochpräzise 3D-Videowahrnehmung der Zukunft.
Um Entwicklern einen schnellen Einstieg in die DVD-Welt zu ermöglichen, hat HyperAI ein benutzerfreundliches Notebook auf den Markt gebracht, das die Einstiegshürde senkt und mit nur einem Klick Zugriff auf modernste Modelle (SOTA) bietet. ⬇️
Online ausführen:https://go.hyper.ai/w8kUO
Open-Source-Adresse:https://github.com/EnVision-Research/DVD
Weitere Online-Tutorials:
Demolauf
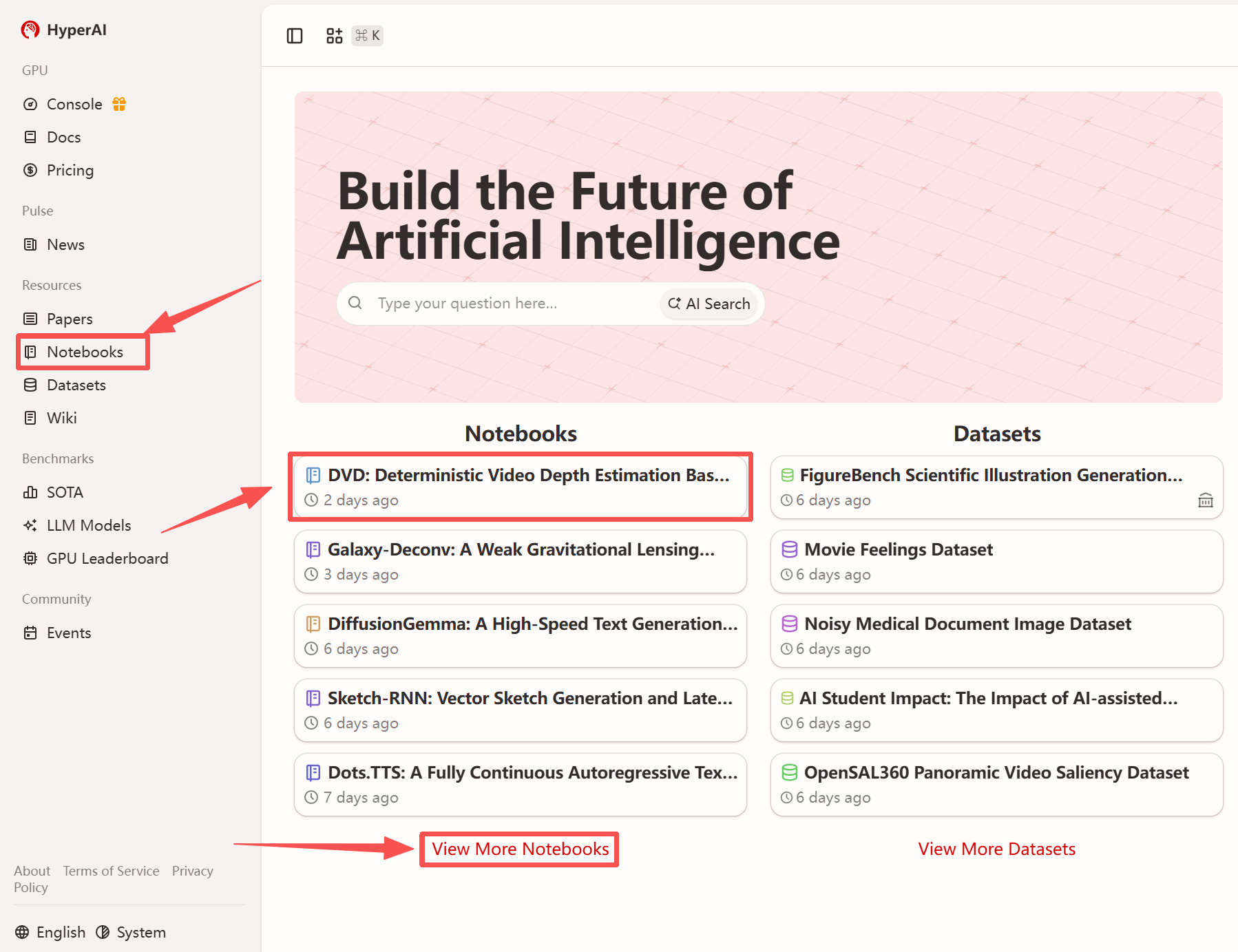
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „DVD: Deterministische Videotiefenschätzung basierend auf generativen Priors“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
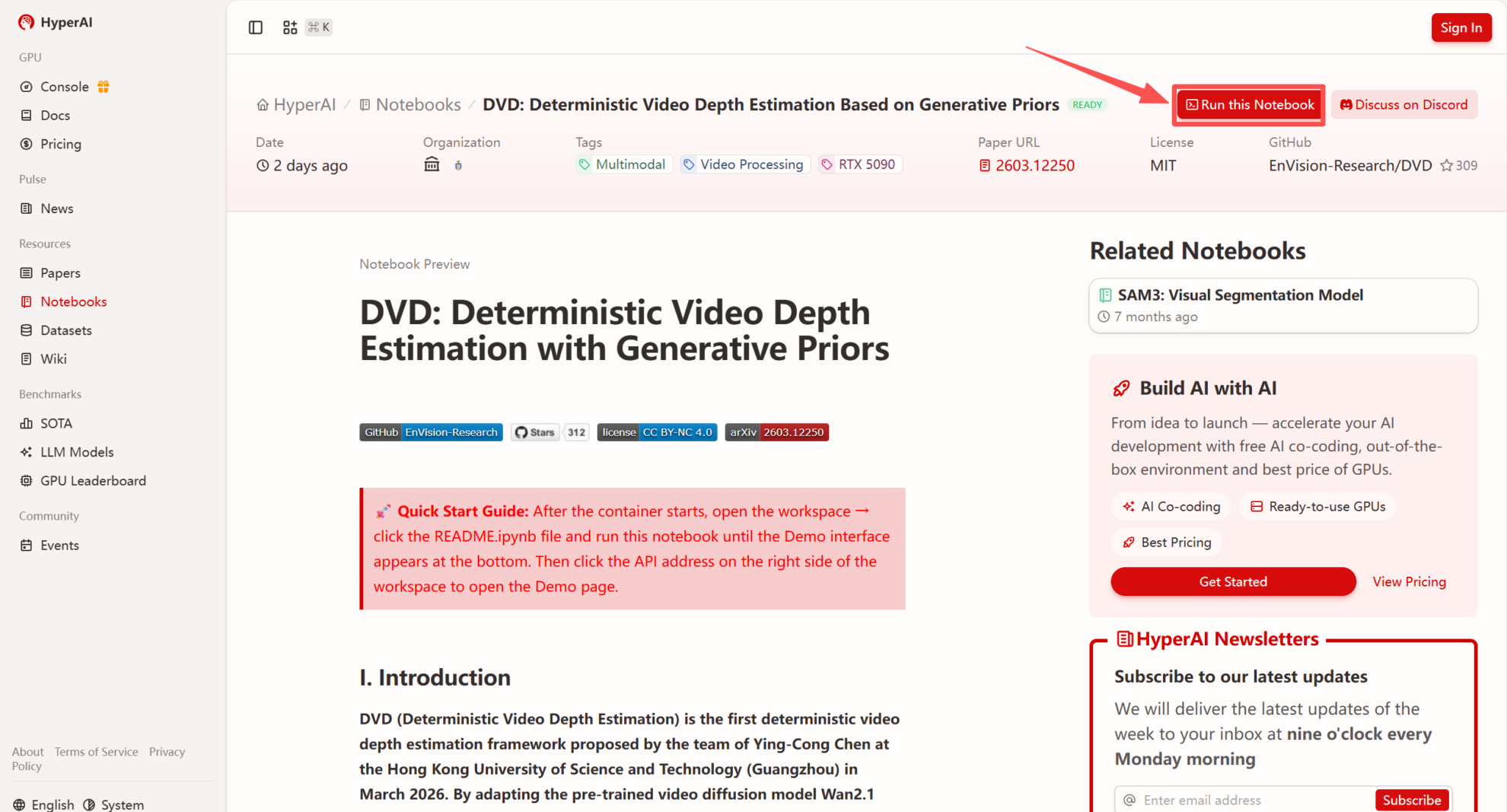
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
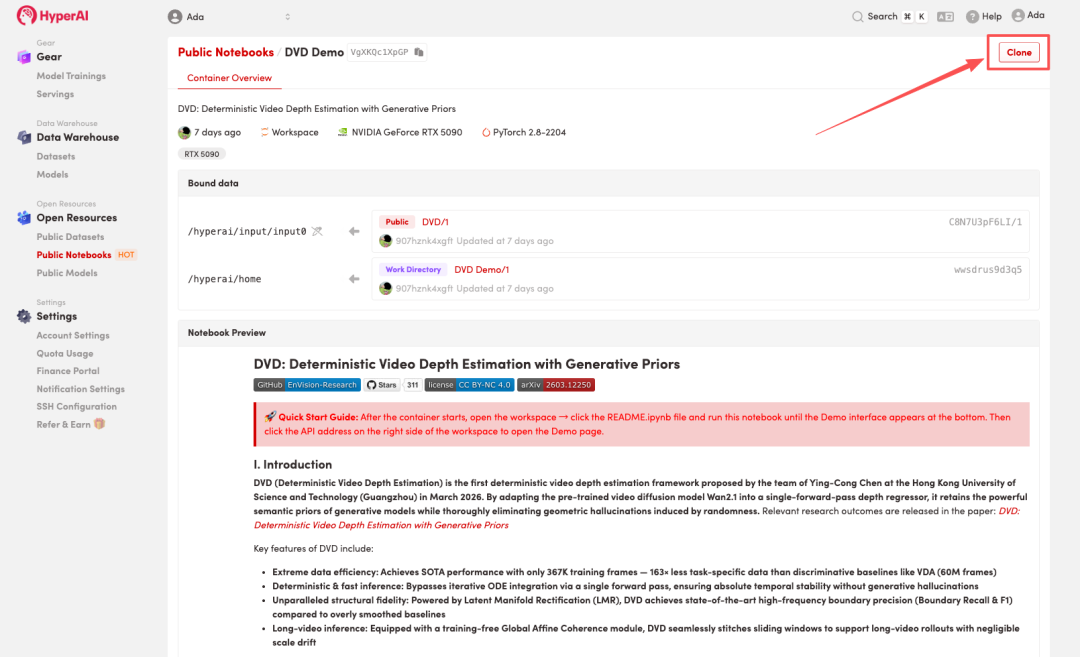
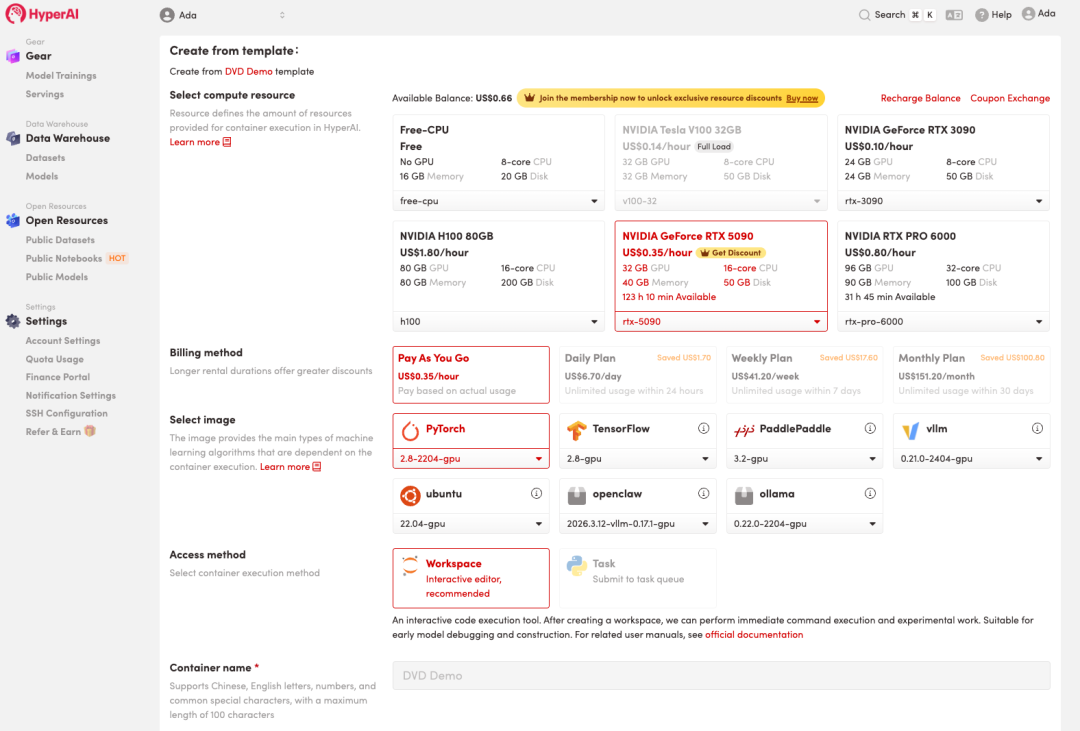
3. Wählen Sie die Images „NVIDIA RTX 5090“ und „PyTorch“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
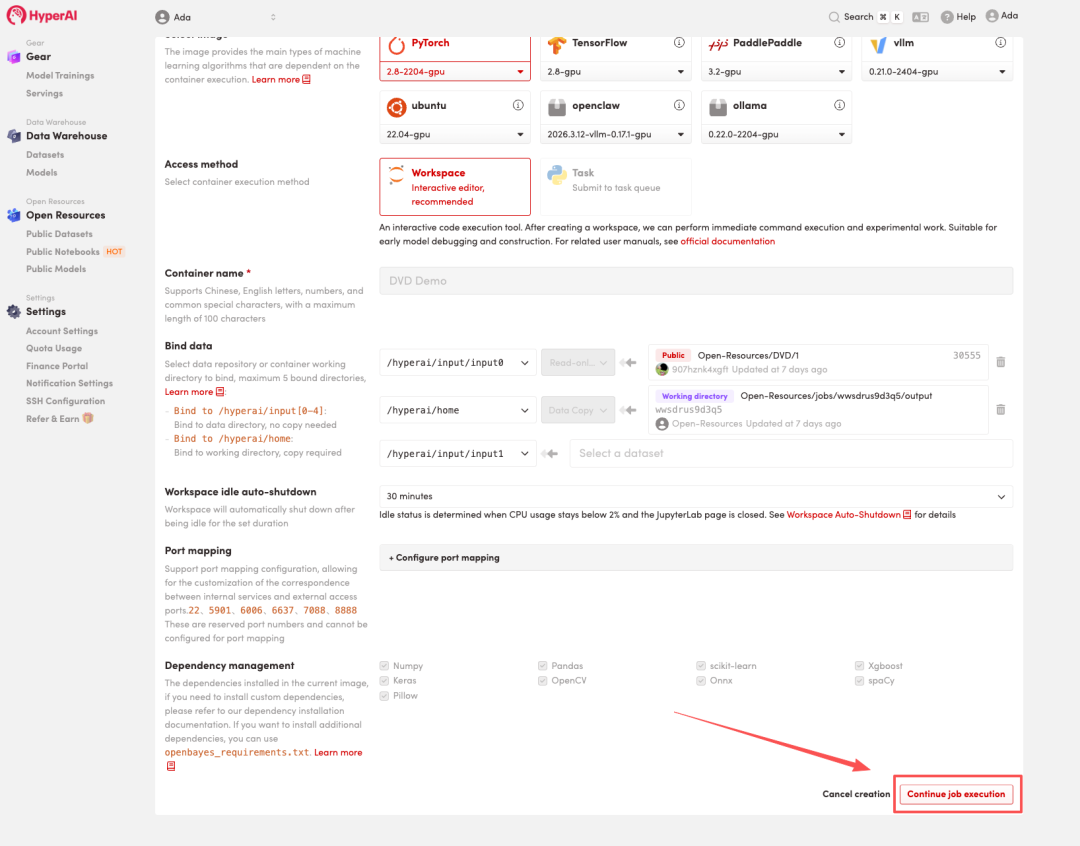
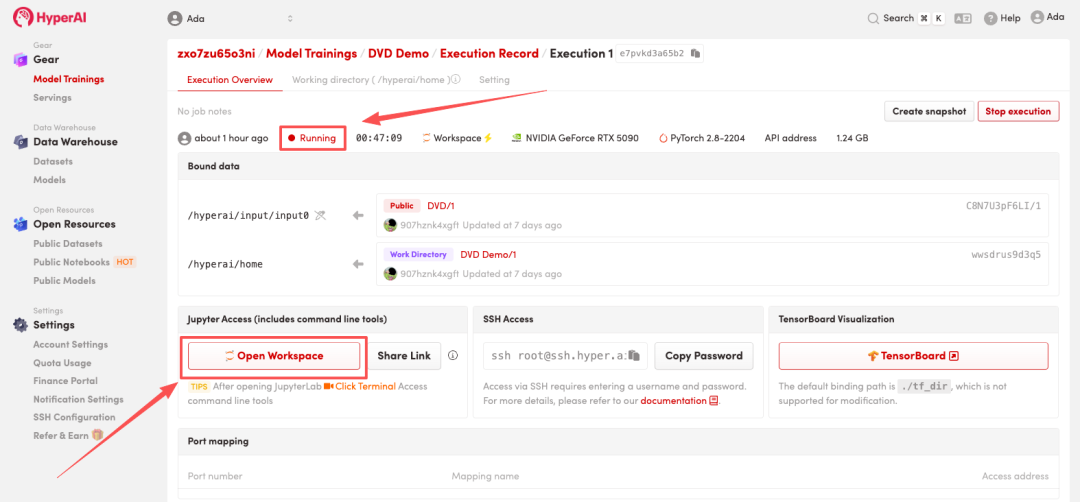
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
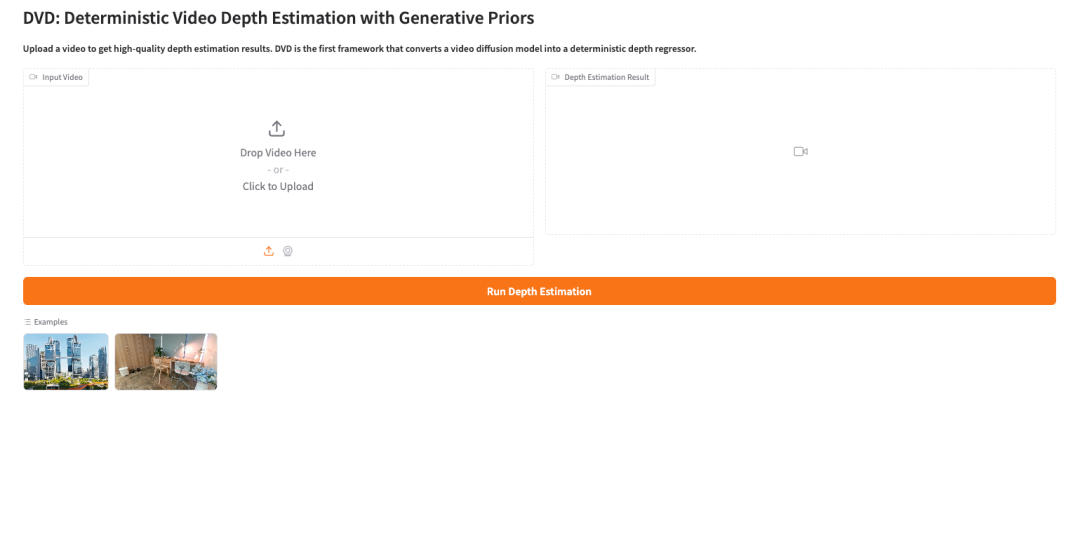
Effektanzeige
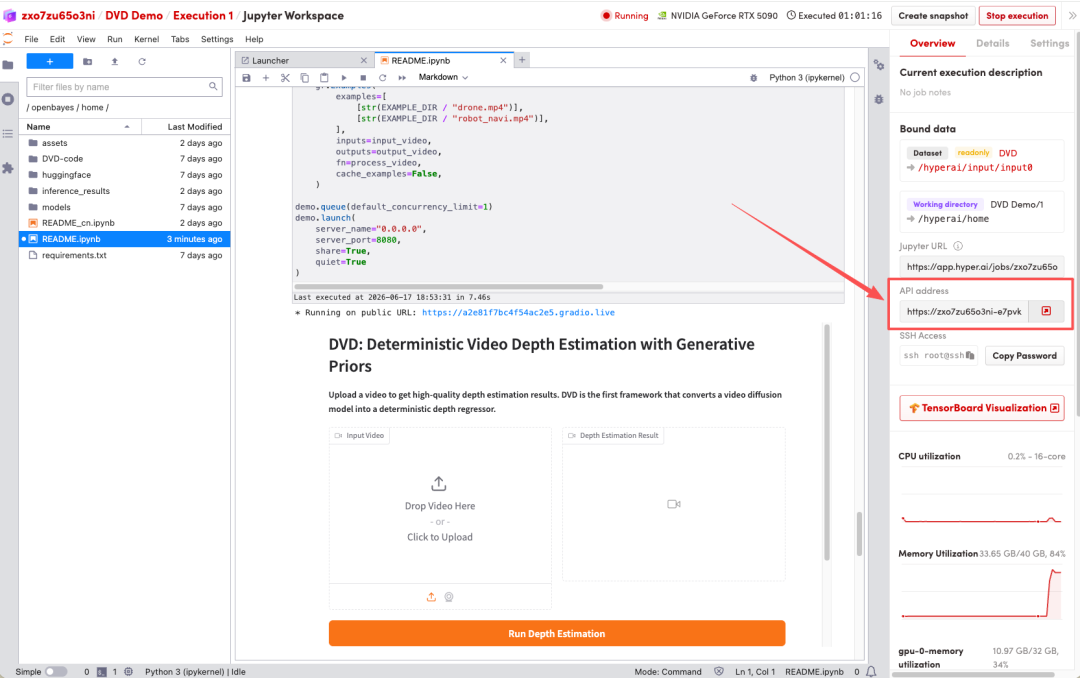
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
2. Nach Abschluss des Vorgangs klicken Sie auf die API-Adresse auf der rechten Seite, um die Demo-Oberfläche zu öffnen.