Command Palette
Search for a command to run...
Online-Tutorial | Laptop Mit 16 GB RAM Erreicht Fast 26 BPM Leistung: Gemma 4 12B – Basierend Auf Innovativer Architektur Für Die Einheitliche Verarbeitung Von Text-, Bild- Und Tondaten

Während der Wettbewerb um große Modelle immer noch auf die Parametergröße fokussiert ist, hat Google DeepMind einmal mehr bewiesen, dass Leistungsverbesserungen nicht unbedingt allein von größeren Modellen abhängen.
Google DeepMind hat kürzlich offiziell das neueste Mitglied der Gemma-4-Familie veröffentlicht: Gemma 4-12B. Dieses einheitliche multimodale Modell verfügt über lediglich 12 Milliarden Parameter und erzielt in mehreren Benchmark-Tests eine Leistung, die nahezu der eines hybriden Expertenmodells (MoE) mit 26 Milliarden Parametern entspricht. Offizielle Daten belegen, dass Gemma 4-12B in Aufgaben wie Inferenz, Codegenerierung und multimodaler Datenanalyse die Leistung von Gemma 4-26B erreicht.Gleichzeitig erreicht es in einigen Aufgaben des visuellen Verständnisses und der Agentenentwicklung den Stand der Technik (SOTA) unter den aktuellen Open-Source-Modellen der gleichen Stufe.Noch wichtiger ist jedoch, dass das Modell nur 16 GB Videospeicher oder einheitlichen Speicher benötigt, um nativ auf Laptops für Endverbraucher zu laufen, wodurch ein seltenes Gleichgewicht zwischen Leistung und Bereitstellungskosten erreicht wird.
Als erstes mittelgroßes Modell der Gemma-Serie mit nativer Audio-Eingabe liegt der größte Durchbruch des Gemma 4 12B nicht in seiner Parametergröße, sondern in seiner architektonischen Innovation. Lange Zeit verfolgten multimodale Modelle im Allgemeinen den Ansatz „Encoder + Sprachmodell“: Bilder werden von einem visuellen Encoder, Audio von einem Sprach-Encoder verarbeitet, und die Ergebnisse werden anschließend einem großen Sprachmodell zur Inferenz übergeben. Obwohl diese Architektur ausgereift ist,Dies bringt jedoch zusätzlichen Rechenaufwand, Speicherbedarf und Verzögerungen bei der Inferenz mit sich.
Um dieses Problem zu lösen, hat Google DeepMind für Gemma 4 12B eine völlig neue Encoder-freie Architektur entwickelt. Bilder werden nach Durchlaufen eines leichtgewichtigen Einbettungsmoduls direkt in das LLM-Backbone eingespeist, während Audio direkt in denselben Darstellungsraum wie Texttoken projiziert wird.Derselbe Decoder-Only-Transformator verarbeitet Text-, Bild- und Tonmodalitäten einheitlich.Die offizielle Stellungnahme weist darauf hin, dass dieses Design die Latenz multimodaler Inferenz deutlich verringert und gleichzeitig die Systemkomplexität und den Speicherbedarf reduziert.
Zusätzlich zu seiner einheitlichen multimodalen Architektur unterstützt der Gemma 4 12B ein ultralanges Kontextfenster von 256 KB, einen umschaltbaren Thinking-Deep-Inferenzmodus, native Funktionsaufrufe und Agent-Workflow-Funktionen. In Standard-BenchmarksSeine Gesamtleistung ist nahezu identisch mit der des Modells Gemma 4 26B MoE, das mehr als doppelt so groß ist.Die Betriebskosten sind weniger als halb so hoch wie die des letztgenannten Modells. Für Entwickler, die fortschrittliche KI-Funktionen lokal einsetzen möchten, bedeutet dies, dass sie eine Inferenz- und Agentenleistung erzielen können, die der aktueller multimodaler Spitzenmodelle sehr nahe kommt, ohne auf teure GPUs angewiesen zu sein.
Aktuell bietet der Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) das Projekt „One-click deployment of Gemma 4 12B-it“ an, das die Bereitstellungshürde in Form eines Notebooks senkt und es Entwicklern erleichtert, Modelle schnell zu überprüfen.
Online ausführen:https://go.hyper.ai/1Jrdl
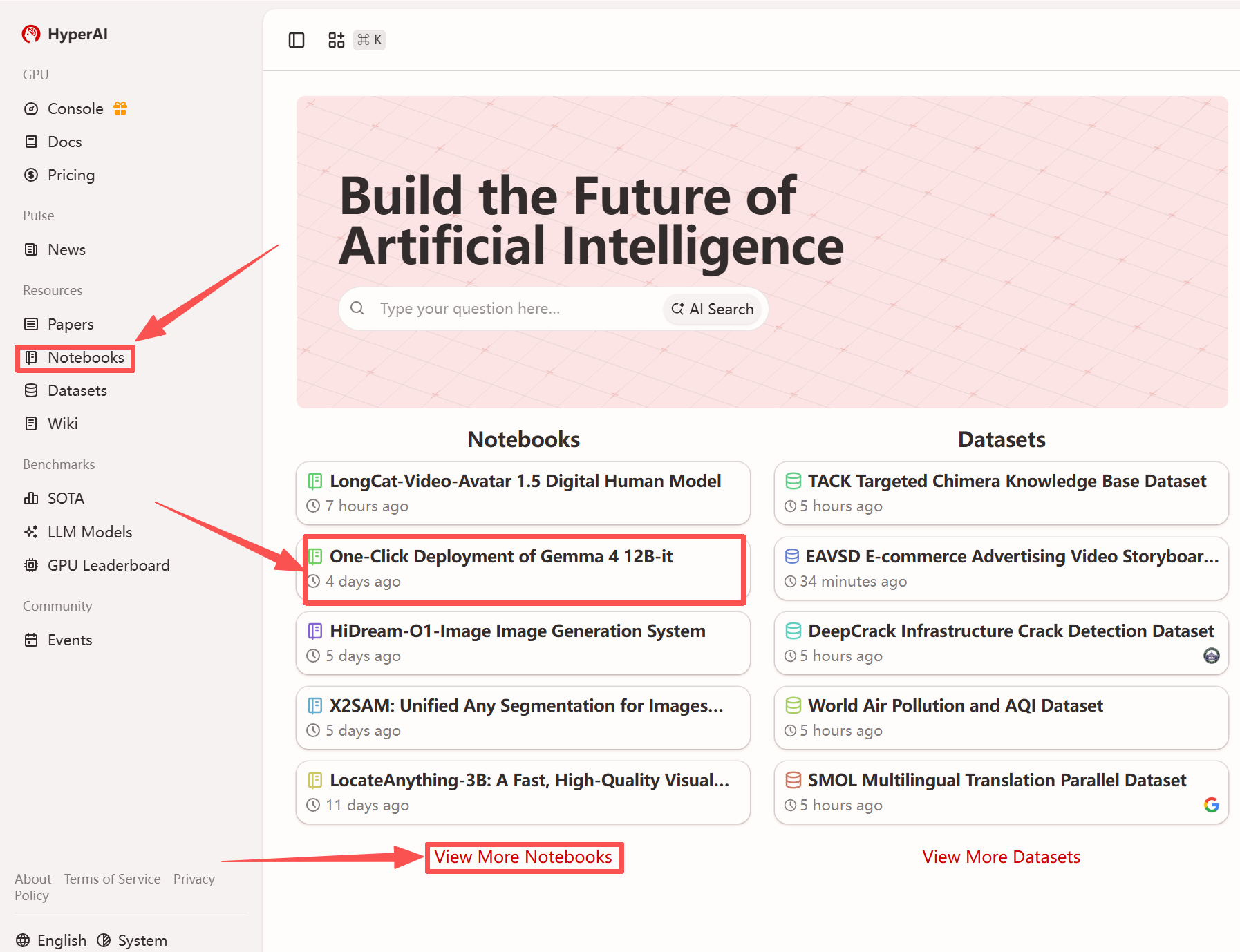
Weitere Online-Tutorials:
Demolauf
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „Ein-Klick-Bereitstellung von Gemma 4 12B-it“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
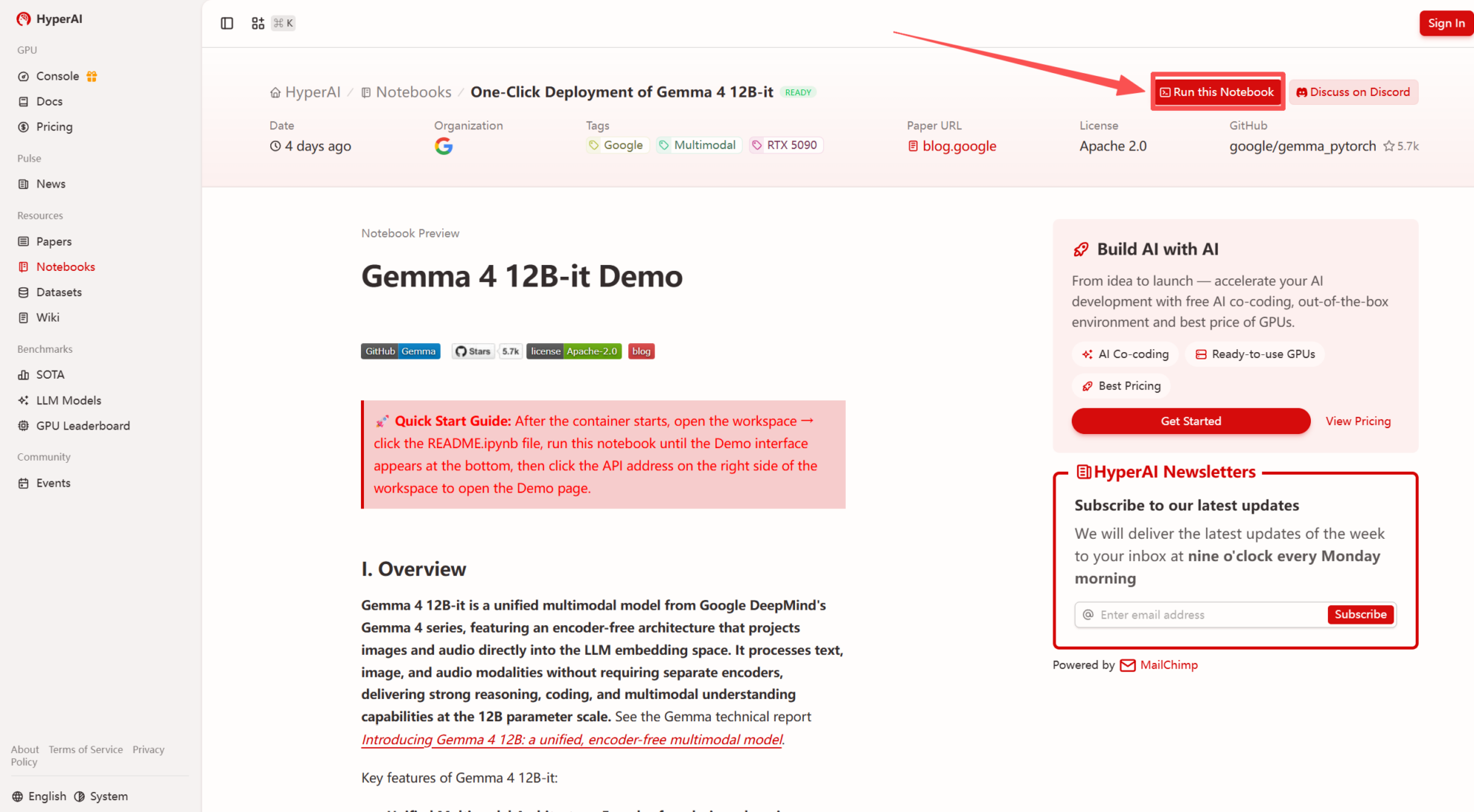
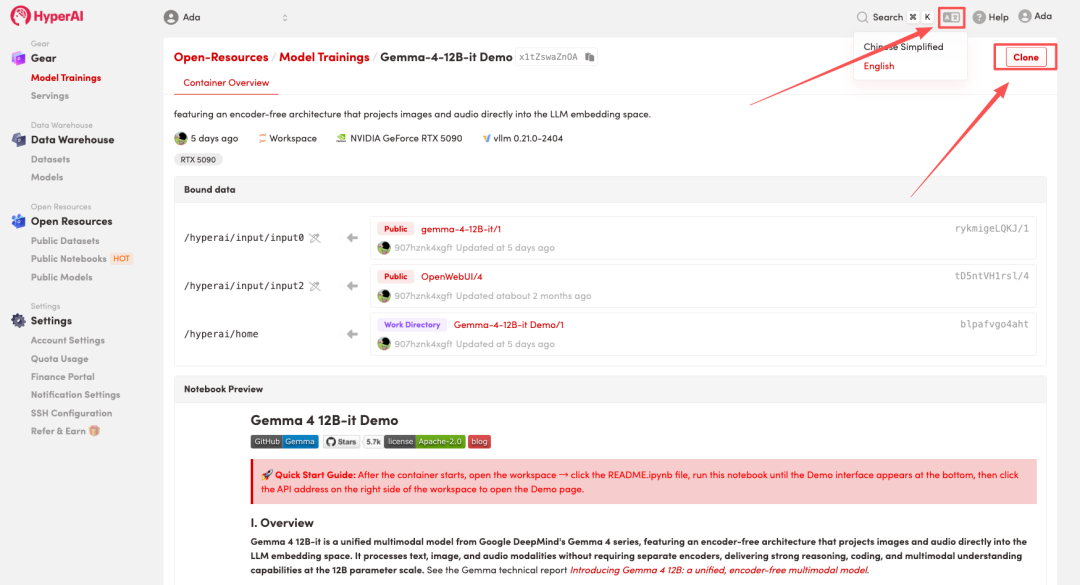
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
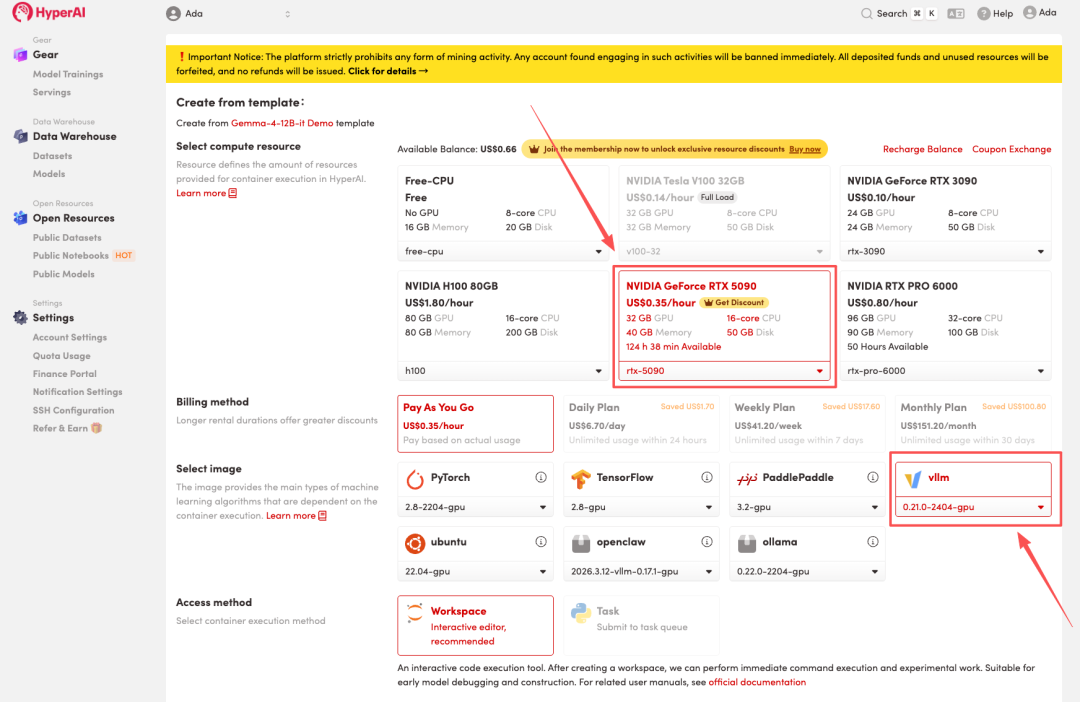
3. Wählen Sie die Images „NVIDIA RTX 5090“ und „vLLM“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
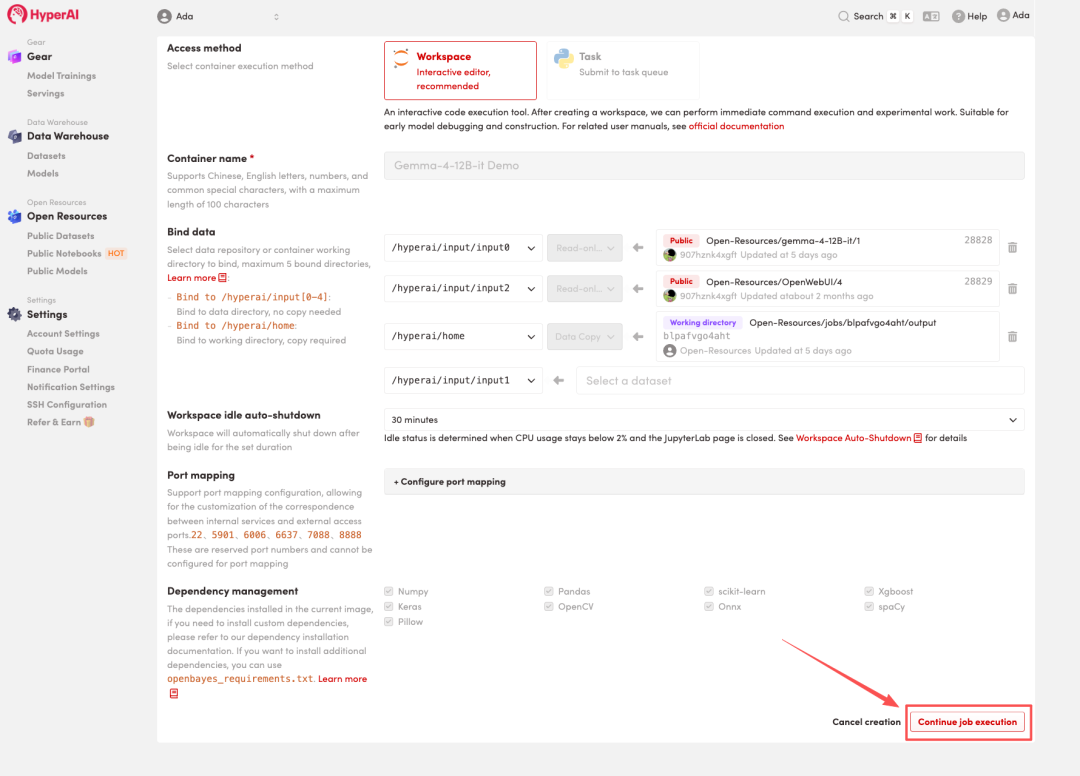
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
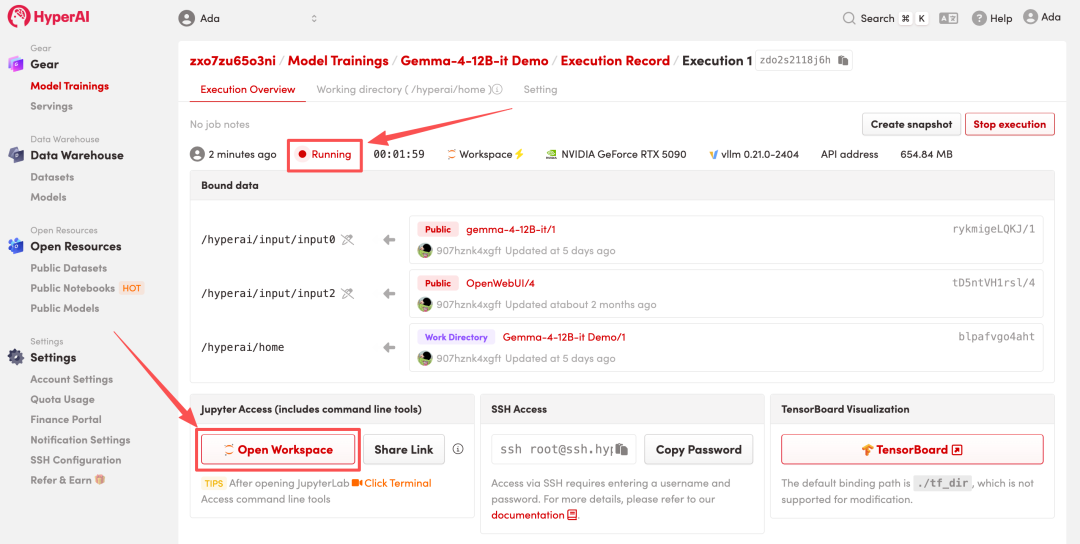
Effektanzeige
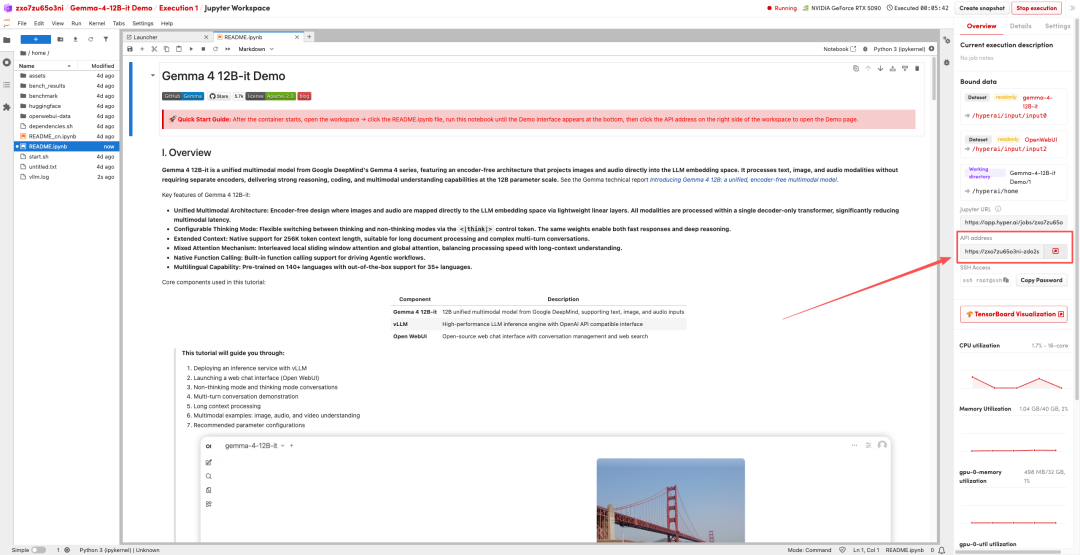
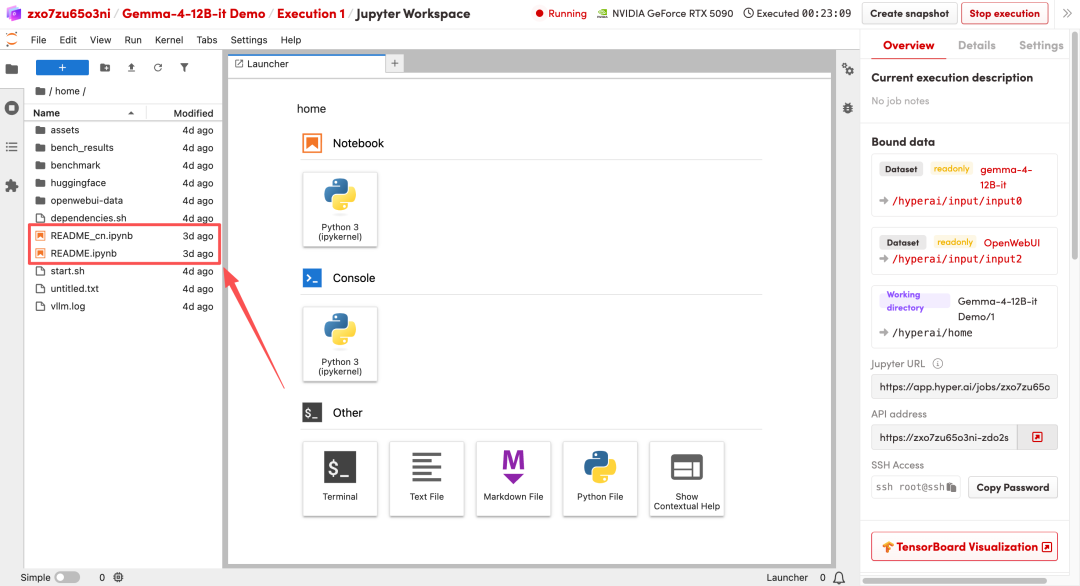
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
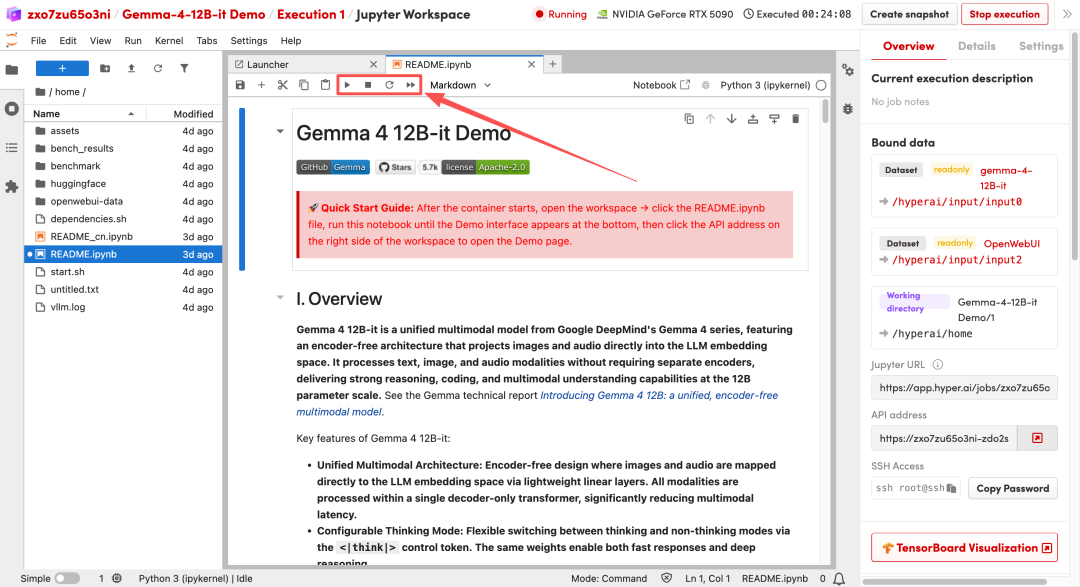
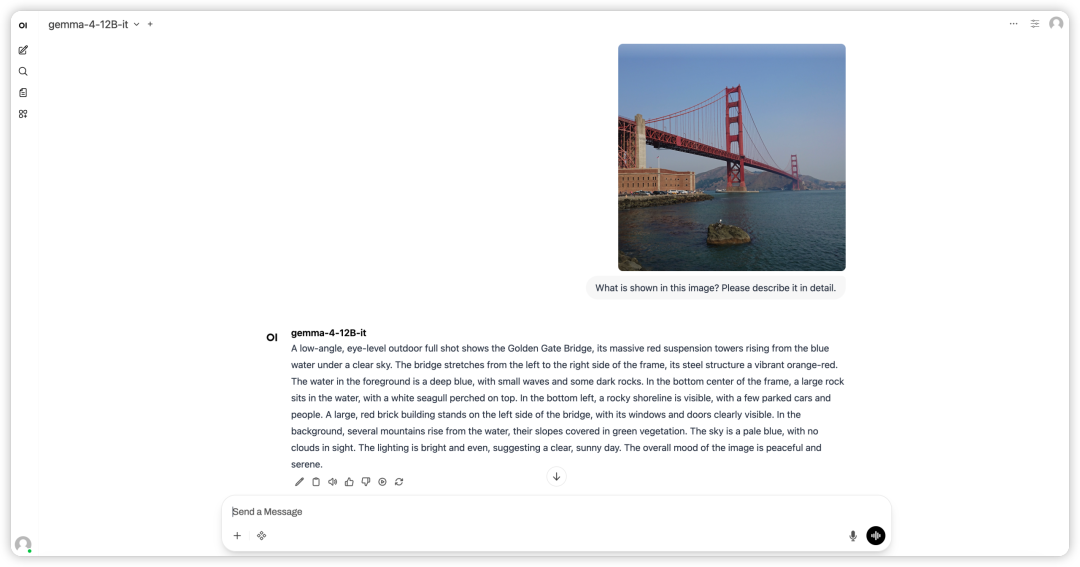
2. Nach Abschluss des Vorgangs klicken Sie auf die API-Adresse auf der rechten Seite, um die Demo-Oberfläche zu öffnen.