Command Palette
Search for a command to run...
Können Emojis Die Sprachgenerierung Steuern? Irodori-TTS Ist Ein Japanisches TTS, Das Auf Der RF-DiT-Architektur Basiert; Datensätze Zu Ekzemen Und Tinea-Hauterkrankungen: Unterstützung Der Medizinischen Bildklassifizierung Und Des Transferlernens.

Irodori-TTS, ein Open-Source-Projekt, das 2026 vom Entwickler Aratako veröffentlicht wurde, ist eine neue Generation japanischer Sprachsynthese und Zero-Shot-Klonmodelle, die hohe Audioqualität mit starker Bedienbarkeit kombiniert.Das Kernmodell, der Irodori-TTS-500M-v3, mit 500 Millionen Parametern, basiert auf dem kontinuierlichen DACVAE-Latentraum und der RF-DiT-Architektur, die eine stabile Ausgabe von professionellem Audio mit 48 kHz bei gleichzeitiger Gewährleistung der Recheneffizienz ermöglicht.In der Praxis hat das Modell zwei große Durchbrüche erzielt: Erstens ermöglicht es extrem schnelles "Null-Sample-Stimmklonen", bei dem Benutzer nur 3-10 Sekunden Referenzaudio bereitstellen müssen, um die Zielklangfarbe ohne Feinabstimmung genau zu reproduzieren; zweitens ermöglicht es "mehrdimensionale Stilsteuerung", die innovative Emoji-Annotationen mit automatischer Dauervorhersage kombiniert, um eine Feinabstimmung von Emotionen, Tonfall und subtilen nonverbalen Ausdrücken zu erreichen.
Die HyperAI-Website präsentiert jetzt „Irodori-TTS-500M-v3: Japanische Sprachsynthese und Emoji-Stilsteuerung“. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/pFPM5
Ein kurzer Überblick über die Aktualisierungen der hyper.ai-Website vom 27. Juni bis zum 3. Juli:
* Hochwertige öffentliche Datensätze: 4
* Eine Auswahl hochwertiger Tutorials: 12
* Analyse von Community-Artikeln: 1 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz zu Ekzemen und Tinea-Hautkrankheiten
Der Datensatz „Ekzeme und Tinea“ ist ein medizinischer Bilddatensatz für Hauterkrankungen wie Ekzeme und Tinea. Er dient der Bereitstellung prägnanter und praxisorientierter Daten für die Klassifizierung binärer Bilder und findet breite Anwendung in der Bildklassifizierung von Hauterkrankungen, im Training und der Evaluierung von Deep-Learning-Modellen, in der Forschung zu Few-Shot- und Transferlernverfahren sowie in Lehre und Experimenten zur medizinischen Bildanalyse. Der Datensatz umfasst 2.147 Bilder von Hauterkrankungen.
Online-Nutzung:https://go.hyper.ai/nheob
2. SASH-VPV-Datensatz zur Erkennung subkutaner Handvenen
SASH-VPV ist ein Benchmark-Datensatz für biometrische Handvenen im Nahinfrarotbereich, der für die biometrische Erkennung und die Forschung im Bereich Computer Vision eingesetzt wird. Er dient der Untersuchung der Identitätsauthentifizierung anhand subkutaner Venenstrukturen in der Handfläche und findet breite Anwendung in der Entwicklung biometrischer Systeme, im Training von Deep-Learning-Modellen und in der Forschung zur sitzungsübergreifenden Robustheit.
Online-Nutzung:https://go.hyper.ai/B9xrr

3. Ultimativer Datensatz zur Anime-Bewertungsklassifizierung
Ultimate Anime, veröffentlicht 2026, ist ein Datensatz zur Bewertung und Klassifizierung von Animes. Er dient der Entwicklung von Anime-Empfehlungssystemen, der Visualisierung explorativer Datenanalysen (EDA) und der Analyse langfristiger Trends und der Qualität von Anime-Produktionen. Der Datensatz umfasst Daten von 3.994 Anime-Werken aus den Anime-Datenbanken AniList und MyAnimeList und beinhaltet multidimensionale Informationen wie Titel, Genre, AniList-Community-Bewertung, Gesamtanzahl der Episoden, Ausstrahlungsstatus, Jahr, Inhaltsangabe, Produktionsfirma, Originalquelle, Popularität und Ranking, Coverbild und Ausstrahlungszeit.
Online-Nutzung:https://go.hyper.ai/tXtT5
4. Datensatz zu Rosenblattkrankheiten
Der Datensatz „Rosenblattkrankheiten“ dient der Bereitstellung hochwertiger Bilddaten für die Entwicklung und das Benchmarking von Modellen zur Erkennung von Rosenblattkrankheiten und wird häufig beim Aufbau von Pflanzenüberwachungssystemen eingesetzt. Die Originalversion dieses Datensatzes enthält 2.458 Rosenblattbilder aus Bangladesch, kategorisiert in fünf Typen: Sternrußtau, Falscher Mehltau, Blattfleckenkrankheit, gesunde Blätter und Insektenfraß.
Online-Nutzung:https://go.hyper.ai/IuPUO

Ausgewählte öffentliche Tutorials
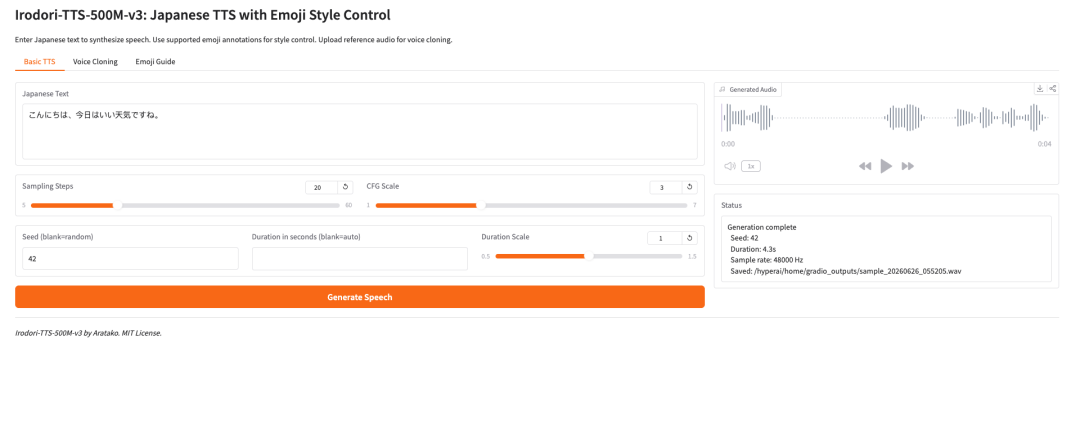
1. Irodori-TTS-500M-v3: Japanische Sprachsynthese und Emoji-Stilsteuerung
Das im Mai 2026 vom Entwickler Aratako veröffentlichte Projekt Irodori-TTS dient der japanischen Text-to-Speech-Technologie, dem Zero-Sample-Voice-Cloning und der Emoji-gesteuerten Sprachstilsteuerung. Die Innovation besteht in der Verwendung eines Gleichrichter-Diffusionstransformators (RF-DiT) zur Erzeugung von 48-kHz-Sprache in einem kontinuierlichen DACVAE-Latentraum. In Kombination mit Referenz-Audiobedingungen, automatischer Dauervorhersage und den subtilen Emoji-Eigenschaften ermöglicht es die Steuerung von Klangfarbe, Emotionen und nonverbaler Ausdrucksweise.
Online ausführen:https://go.hyper.ai/pFPM5
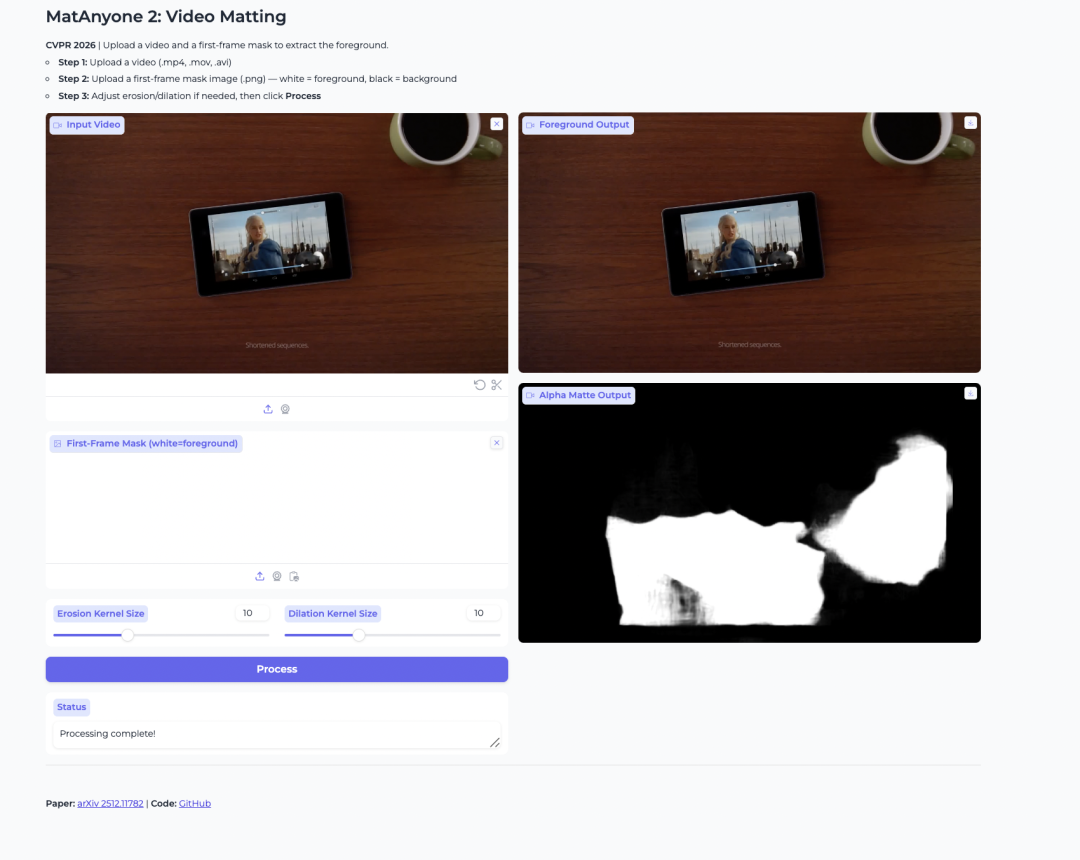
2. MatAnyone 2 Video-Keying-Modell
Das 2026 vom S-Lab der Nanyang Technological University und SenseTime veröffentlichte Projekt MatAnyone 2 dient der Hintergrundentfernung, Vordergrundextraktion und Alpha-Maskierung von Personen in Videos. Seine Innovation basiert auf einem eigens entwickelten Qualitätsbewertungsalgorithmus, der eine stabile Hintergrundentfernung, die Beseitigung von Artefakten an Bildrändern, die präzise Erhaltung von Haardetails und die Unterstützung der spezifischen Hintergrundentfernung für mehrere Personen ermöglicht.
Online ausführen:https://go.hyper.ai/yNeFK
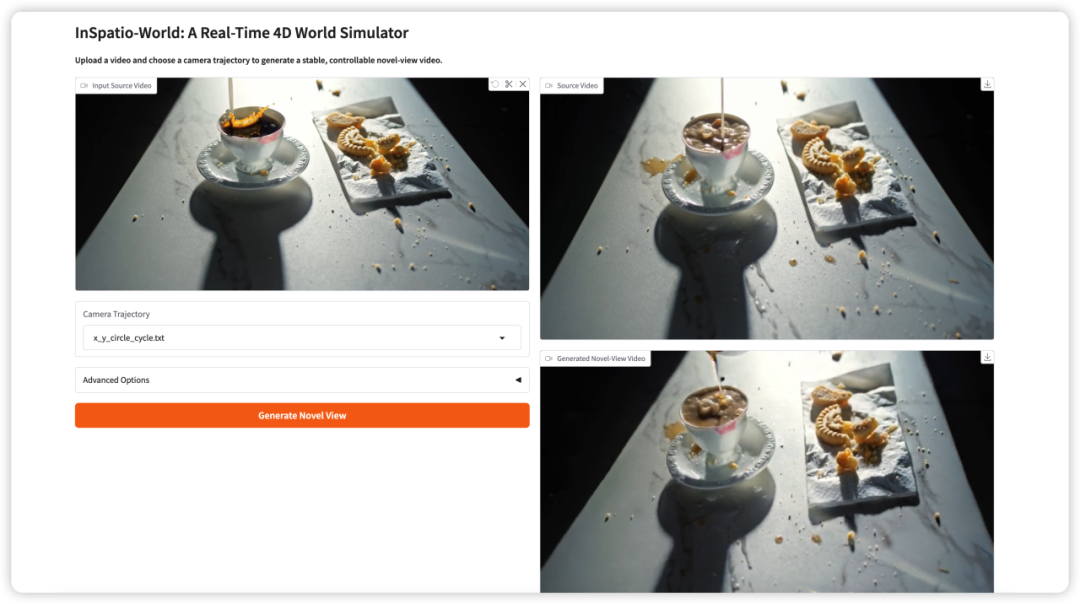
3. InSpatio-World: Ein Echtzeit-4D-Weltsimulator
InSpatio-World ist ein Echtzeit-4D-Weltsimulator, der auf spatiotemporaler autoregressiver Modellierung basiert und vom InSpatio-Team am 19. März 2026 veröffentlicht wurde. Er kann stabile und kontrollierbare neue Perspektivenvideos auf Basis von Eingabevideos und festgelegten Kameratrajektorien generieren und ermöglicht so die freie Kontrolle der Kamerapfade und eine zeitlich konsistente Weltentwicklung.
Online ausführen:https://go.hyper.ai/8FRRy
4. DiaMoE-TTS: Ein Tutorial zur mehrsprachigen Sprachsynthese auf IPA-Basis.
Das von Giant AI Lab im September 2025 gestartete Projekt DiaMoE-TTS dient der mehrsprachigen Sprachsynthese unter Verwendung des Internationalen Phonetischen Alphabets (IPA) als einheitliches Frontend. Die Innovation besteht darin, dialektspezifisches Wissen bis in das Mixture-of-Experts (MoE)-Expertenrouting zu integrieren und durch effiziente Parametermethoden wie LoRa/Conditioning Adapter eine schnelle Anpassung an neue Dialekte ohne vorheriges Testen zu erreichen.
Online ausführen:https://go.hyper.ai/wn9i5
5. SAM-Audio: Trennt beliebige Geräusche aus Audiodateien mithilfe von natürlicher Sprachverarbeitung.
SAM-Audio ist ein grundlegendes Audioquellentrennungsmodell, das von Meta im Dezember 2025 veröffentlicht wurde. Dieses Modell ist in der Lage, spezifische Klänge aus komplexen Audiomischungen mithilfe von Methoden wie natürlichsprachlichen Beschreibungen, visuellen Videohinweisen oder Zeitsegmenten zu trennen.
Online ausführen:https://go.hyper.ai/svjXe
6. PrismAudio: V2A basierend auf CoT-Zerlegung und mehrdimensionalen Belohnungen
PrismAudio ist ein Video-zu-Audio-Generierungsmodell (V2A), das von Tongyi Labs im November 2025 veröffentlicht wurde. Es ist das erste Framework, das Reinforcement Learning in die V2A-Generierung integriert und auf ThinkSounds Chain of Thought (CoT)-Planungsmechanismus basiert. Das Modell unterteilt einen einzelnen Denkprozess in vier spezialisierte CoT-Module: semantisch, temporal, ästhetisch und räumlich. Jedes Modul verfügt über eine zielgerichtete Belohnungsfunktion, wodurch eine mehrdimensionale Optimierung durch Reinforcement Learning erreicht und die Qualität der Denkprozesse über alle Wahrnehmungsdimensionen hinweg umfassend verbessert wird.
Online ausführen:https://go.hyper.ai/BRGSk
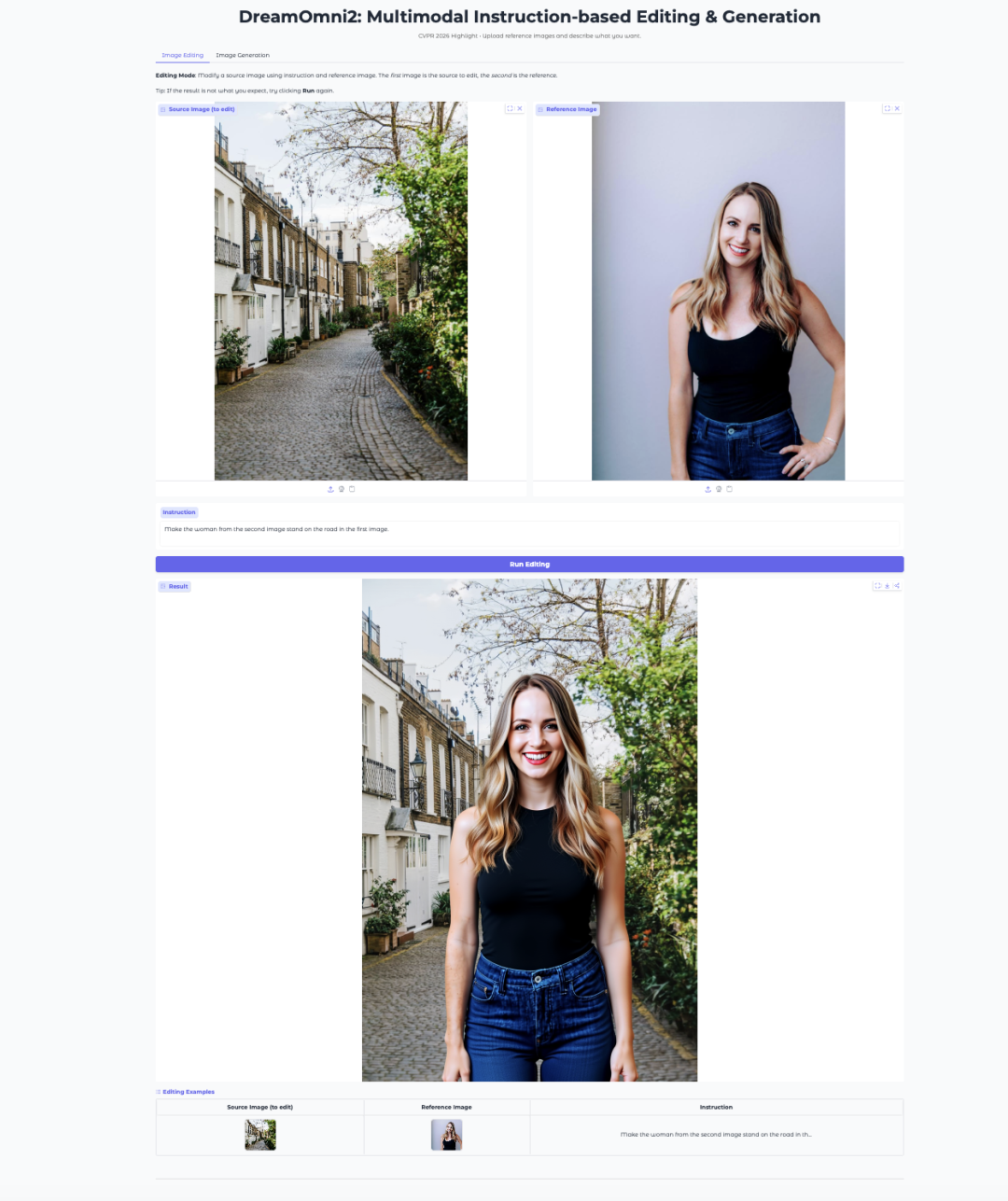
7. DreamOmni2: Multimodale, anweisungsgesteuerte Bildbearbeitung und -generierung
DreamOmni2 ist ein multimodales, anweisungsgesteuertes Bildbearbeitungs- und -generierungsmodell, das im Oktober 2025 vom JIA Lab der Chinesischen Universität Hongkong veröffentlicht wurde. Die zugehörige Publikation wurde als Highlight-Beitrag für die CVPR 2026 angenommen. Das Modell basiert auf dem FLUX.1-Kontext-dev-Basismodell und kombiniert dieses mit einem feinabgestimmten visuellen Sprachmodell Qwen2.5-VL-7B. Es unterstützt die Bildbearbeitung und -generierung durch natürlichsprachliche Anweisungen in Kombination mit Referenzbildern.
Online ausführen:https://go.hyper.ai/1iqNO
8. PixelRefer: Ein einheitliches Framework für das detaillierte Objektverständnis von Bildern und Videos.
PixelRefer, im Oktober 2025 von der Alibaba DAMO Academy veröffentlicht, ermöglicht die präzise Objekterkennung, Bildunterschriftengenerierung und Fragebeantwortung in Bildern und Videos. Die Innovation liegt in der Verwendung eines einheitlichen, regionenbasierten, mehrstufigen linearen Modells (MLLM) in Kombination mit einem skalierungsadaptiven Objektsegmentierer (SAOT) und dem effizienten, objektspezifischen Framework PixelRefer-Lite zur Erstellung kompakter Objektdarstellungen.
Online ausführen:https://go.hyper.ai/ETjjw
9. Unbegrenzte OCR: Bereitstellung von OCR und Layout-Parsing für lange Dokumente mit nur einem Klick
Das Unlimited-OCR-Projekt wurde im Juni 2026 vom Baidu-Team veröffentlicht. Es zielt auf die Texterkennung und das Layout-Parsing langer Dokumente ab und hat zum Ziel, eine gleichbleibende Parsing-Effizienz auch bei längeren Texten zu gewährleisten und ein umfassendes Parsing in einem einzigen Durchlauf zu ermöglichen. Das Modell kann Bilder einzelner Dokumente, mehrseitiger Bilder und aus PDFs konvertierte Seitenbilder verarbeiten und eignet sich daher für die Texterkennung und das strukturierte Parsing von Papieren, Berichten, gescannten Dokumenten, langen Tabellen und mehrseitigen Dokumenten.
Online ausführen:https://go.hyper.ai/Bp69q
10. EdgeTAM: Ein cue-fähiges Bild- und Videosegmentierungsmodell für Edge-Geräte.
Das EdgeTAM-Projekt, das im Januar 2025 von Meta Reality Labs und dem S-Lab der Nanyang Technological University gemeinsam ins Leben gerufen wurde, ist für die hinweisbasierte Bildsegmentierung und Video-Objektverfolgung auf ressourcenbeschränkten Geräten konzipiert. Die Kerninnovation besteht in der Verwendung eines zweidimensionalen räumlichen Perzeptrons in Kombination mit einem Destillationsprozess. Dieser reduziert den Speicherengpass von SAM 2 bei gleichbleibender Segmentierungsqualität und ermöglicht so eine effiziente „Track Anything“-Interaktion direkt auf dem Gerät.
Online ausführen:https://go.hyper.ai/yZoqO
11. Step-Audio-EditX: Zero-Shot-Sprachklonierung und ausdrucksbasierte Audiobearbeitung basierend auf 3B LLM
Das von StepFun im November 2025 veröffentlichte Projekt Step-Audio-EditX zielt auf Zero-Shot-Sprachklonierung und iterative, ausdrucksstarke Audiobearbeitung ab. Die Innovation besteht in der Kombination eines großen Sprachmodells mit 3 Milliarden Parametern mit Reinforcement Learning, wodurch Emotionen, Sprechstil und paralinguistische Ereignisse zu diskreten Steuerungstermen zusammengesetzt werden können. Das Modell unterstützt Mandarin, Englisch, Sichuanesisch, Kantonesisch, Japanisch und Koreanisch.
Online ausführen:https://go.hyper.ai/UL7Hg
12. Nemotron 3.5 ASR Streaming 0.6B: Ein leichtgewichtiges ASR-Modell für Streaming-Spracherkennung
Nemotron 3.5 ASR Streaming 0.6B ist ein automatisches Spracherkennungs- und Streaming-Transkriptionsmodell mit geringer Latenz und 60 Millionen Parametern, das von NVIDIA im Juni 2026 veröffentlicht wurde. Dieses Modell nutzt eine cache-fähige FastConformer-RNNT-Architektur, die den Encoder-Kontext während der Streaming-Inferenz wiederverwendet und so redundante Berechnungen reduziert. Es unterstützt außerdem Sprach-ID-Cueing-Bedingungen und ermöglicht so die Transkription über mehrere Sprachregionen hinweg.
Online ausführen:https://go.hyper.ai/mFejg
Interpretation von Gemeinschaftsartikeln
1. Meta stellt KI-Datenwissenschaftler bereit, und Autodata erstellt hochwertige Trainings-/Evaluierungsdatensätze.
Das Forschungsteam für Künstliche Intelligenz Meta Basic hat eine allgemeine Methode namens Autodata entwickelt. Dabei ist ein intelligenter Agent, der als „Data Scientist“ agiert, für die Erstellung und Organisation von Daten verantwortlich. Sein Verhalten ahmt den Prozess eines menschlichen Data Scientists nach, um qualitativ hochwertige Daten zu generieren. Dieser Prozess umfasst nicht nur die anfängliche Datengenerierung, sondern auch die Datenanalyse, die Bewertung der Ergebnisse, die Zusammenfassung der gewonnenen Erkenntnisse und die iterative Entwicklung besserer Datenlösungen auf Basis dieser Erkenntnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/UThkc
Beliebte Enzyklopädieartikel
1. Großes Sprachmodell (LLM)
2. Weltaktionsmodell (WAM)
3. Harmonisches Mittel
4. Virtuelles Screening
5. Reinforcement Learning Based on AI Feedback (RLAIF)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








