Command Palette
Search for a command to run...
Online-Tutorial | Bis Zu 4x Schnellere Generierungsgeschwindigkeit: DiffusionGemma Kann Ganze Textblöcke Gleichzeitig Generieren, Mit Kontinuierlicher Optimierung Auf Basis Von Mehrstufigem Parallelem Denoising.

Am 11. Juni veröffentlichte Google offiziell DiffusionGemma als Open Source. Das Textgenerierungsmodell basiert auf der Technologie der diskreten Diffusion. Es nutzt die branchenführende Intelligenz der Gemma-4-Serie und die wegweisende Gemini-Diffusionsforschung und integriert einen neuen Diffusionskopf, um die Generierungsgeschwindigkeit zu maximieren. Im Gegensatz zu herkömmlichen großen Modellen, die Text Token für Token ausgeben, kann DiffusionGemma ganze Textblöcke gleichzeitig generieren und die Ergebnisse durch mehrere Runden paralleler Rauschunterdrückung kontinuierlich optimieren.Dies führt zu einer bis zu vierfachen Steigerung der Erzeugungsgeschwindigkeit.
Offizielle Daten zeigen, dass DiffusionGemma auf einer einzelnen NVIDIA H100 GPU eine Generierungsgeschwindigkeit von über 1100 Tokens/s und auf einer GeForce RTX 5090 über 700 Tokens/s erreichen kann und damit autoregressive Modelle der gleichen Leistungsklasse deutlich übertrifft.
Aus der Perspektive der ArchitekturDiffusionGemma verwendet ein hybrides Expertenmodell (MoE) mit 26 Milliarden Parametern.Die Gesamtzahl der Parameter beträgt ca. 25,2 Milliarden, jedoch werden während der Inferenz nur 3,8 Milliarden Parameter aktiviert. Dies reduziert den Rechenaufwand erheblich und erhält gleichzeitig die hohe Leistungsfähigkeit des Modells. Es basiert auf einer Encoder-Decoder-Architektur und verfügt über einen bidirektionalen Aufmerksamkeitsmechanismus, der die parallele Verarbeitung von 256 Token ermöglicht. Darüber hinaus unterstützt es Aufgaben, die stark vom globalen Kontext abhängen, wie z. B. Inline-Textbearbeitung, Codevervollständigung und die Generierung mathematischer Strukturen.
Darüber hinaus unterstützt DiffusionGemma lange Kontexte von bis zu 256.000 Token, multimodale Graph- und Texteingabe sowie durch <|think|> aktivierte Inferenzmodi und bietet Entwicklern damit neue technologische Optionen zur Erforschung hocheffizienter KI-Anwendungen der nächsten Generation.
Obwohl Google weiterhin betont, dass das Standardmodell Gemma 4 hinsichtlich der generierten Qualität besser für Produktionsumgebungen geeignet ist, könnten die von DiffusionGemma demonstrierten Fähigkeiten zur diffusionsbasierten Textgenerierung einen weiteren bemerkenswerten neuen Weg für die Entwicklung großer Sprachmodelle eröffnen.
Um es Entwicklern zu ermöglichen, DiffusionGemma mit minimalem Aufwand zu erleben, hat HyperAI kurz nach der Veröffentlichung des Modells als Open Source ein einfach einzusetzendes Notebook auf den Markt gebracht, mit dem sich die leistungsstarken Fähigkeiten des Modells mit nur einer einzigen NVIDIA RTX Pro 6000 Grafikkarte überprüfen lassen.
Online ausführen:https://go.hyper.ai/879dB
Weitere Online-Tutorials:
Demolauf
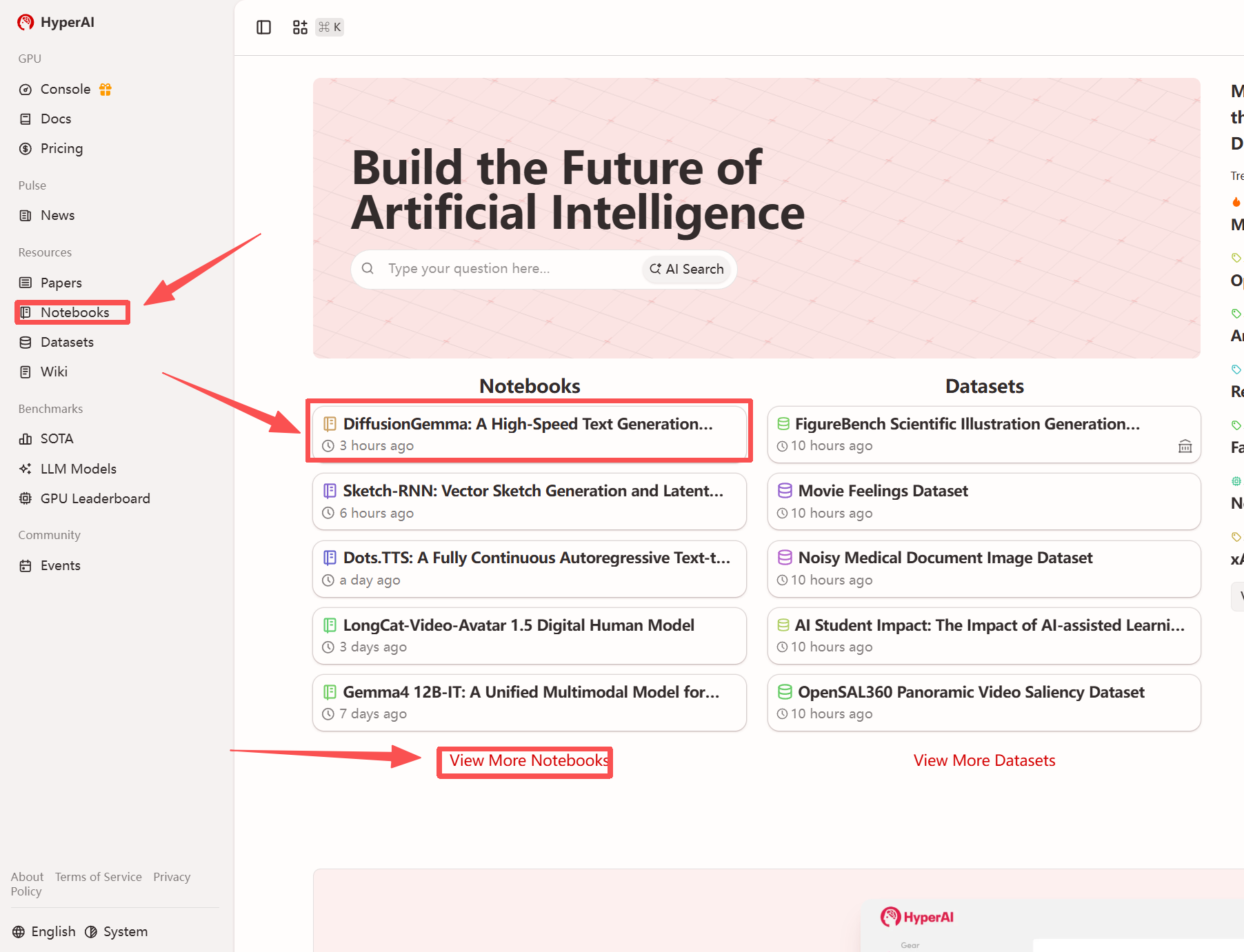
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „DiffusionGemma: Hochgeschwindigkeits-Textgenerierungsmodell basierend auf diskreter Diffusion“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
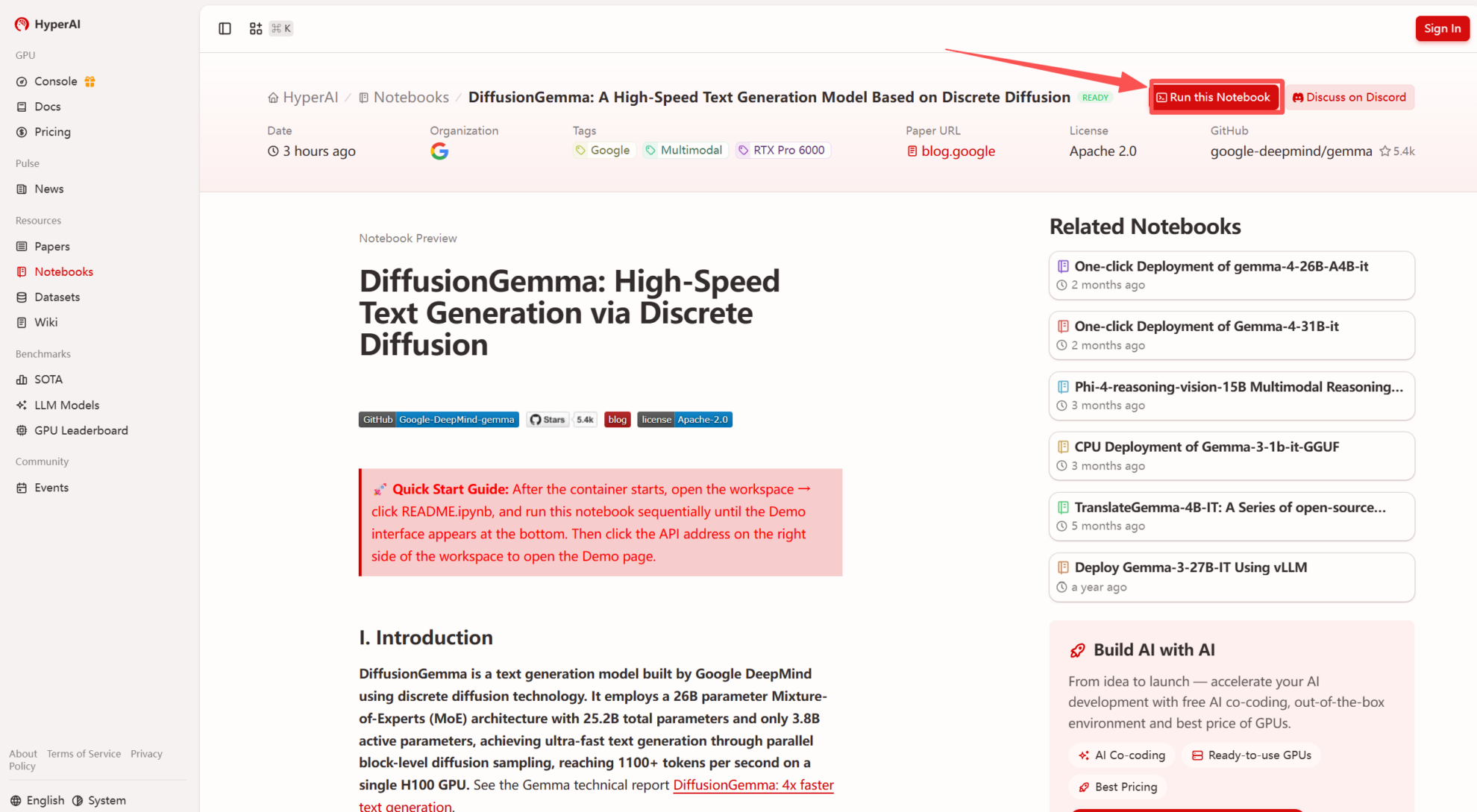
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
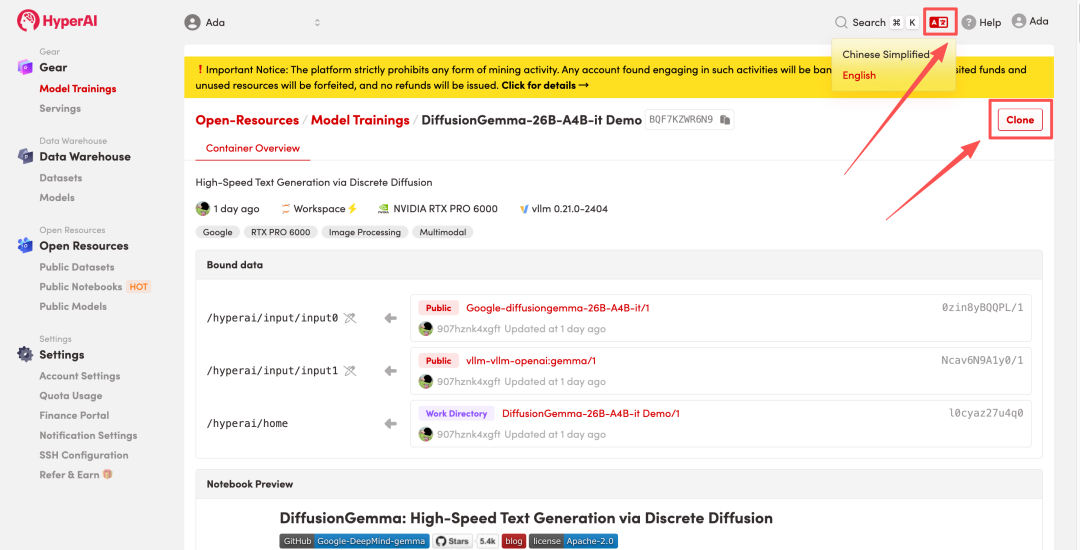
3. Wählen Sie die Images „NVIDIA RTX Pro 6000“ und „vLLM“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
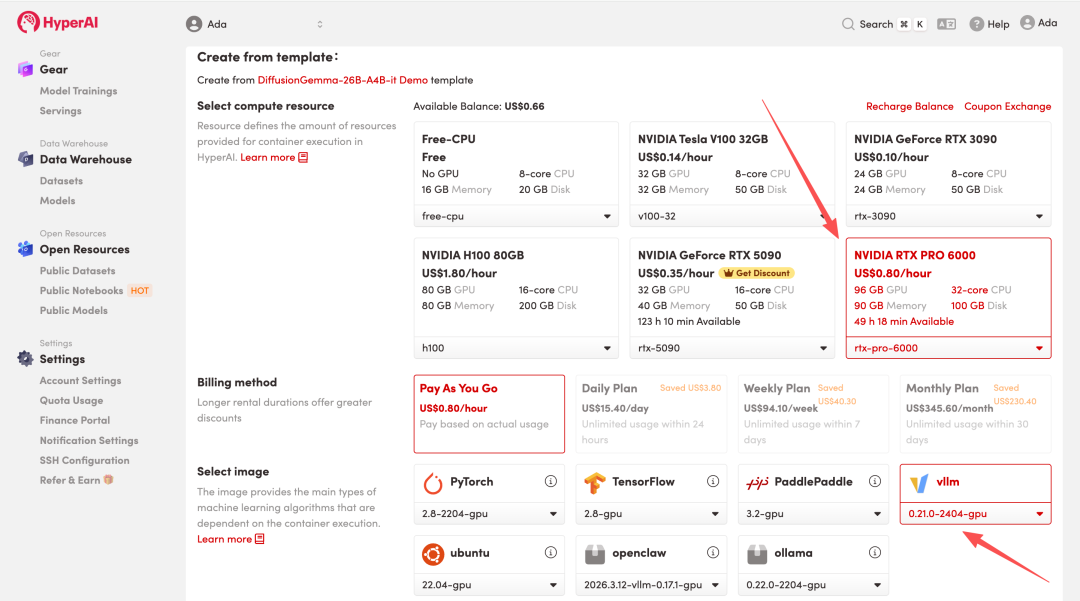
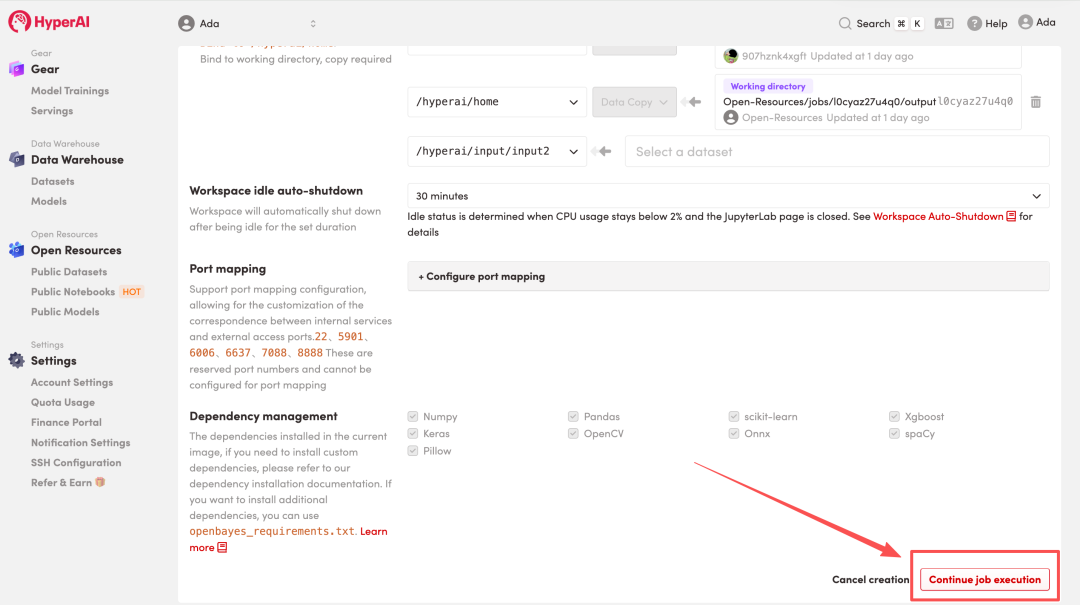
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
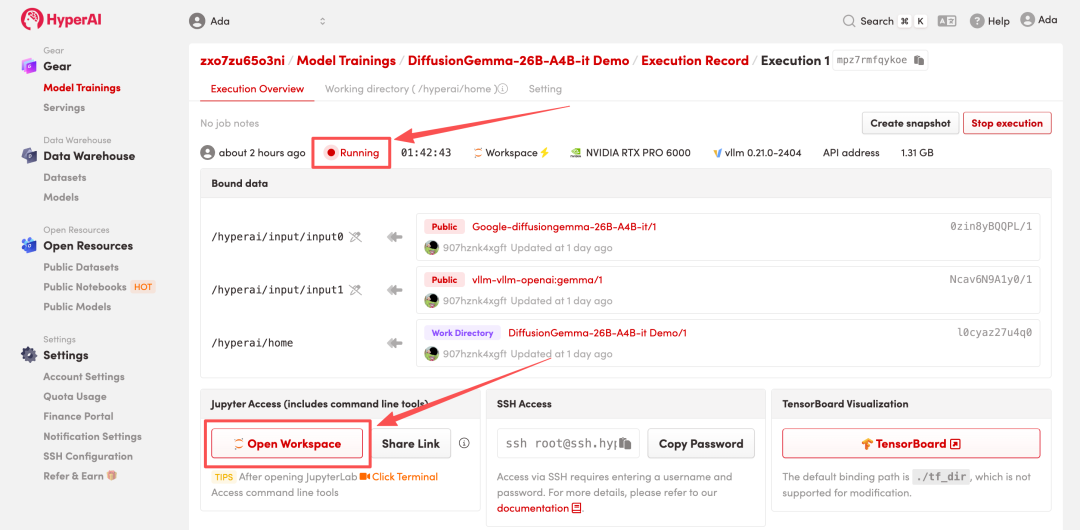
Effektanzeige
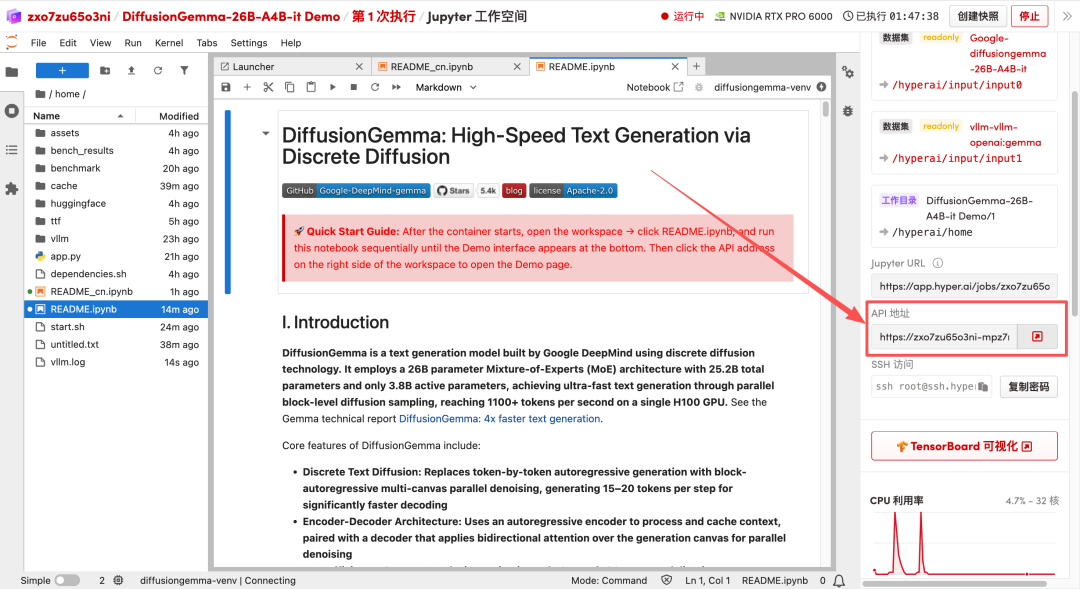
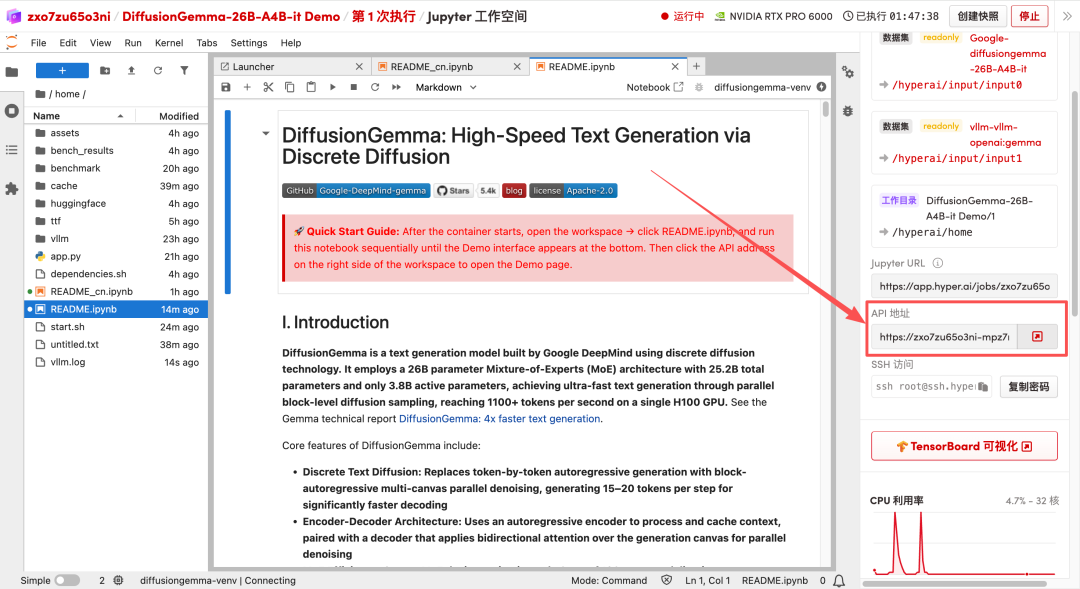
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
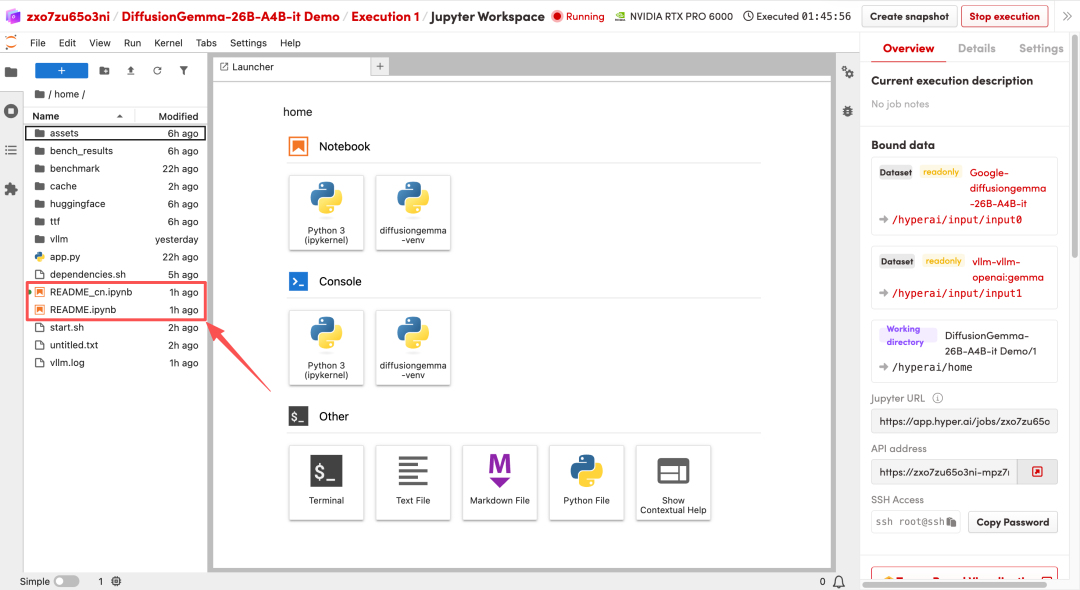
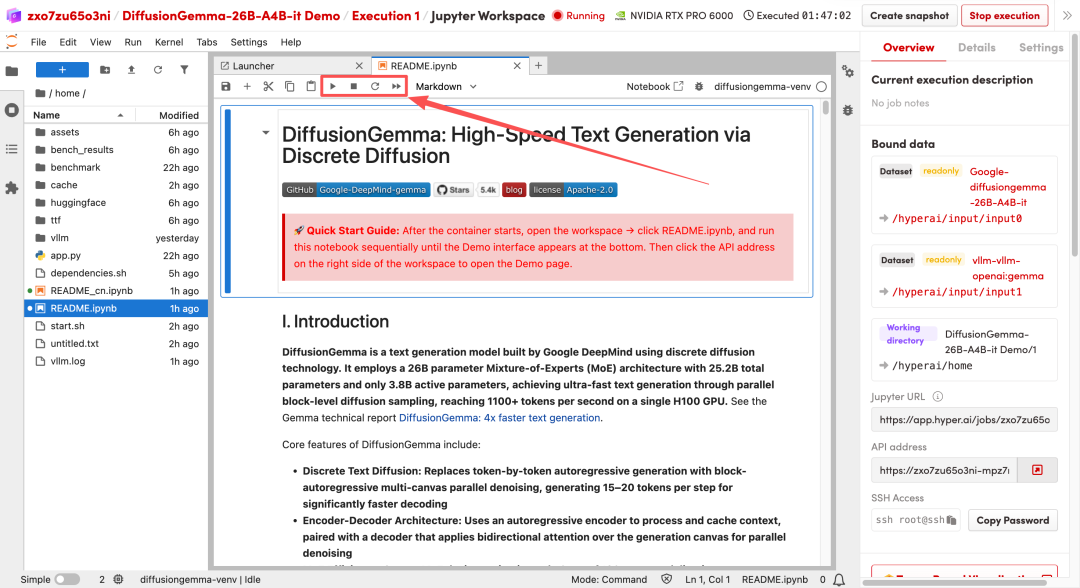
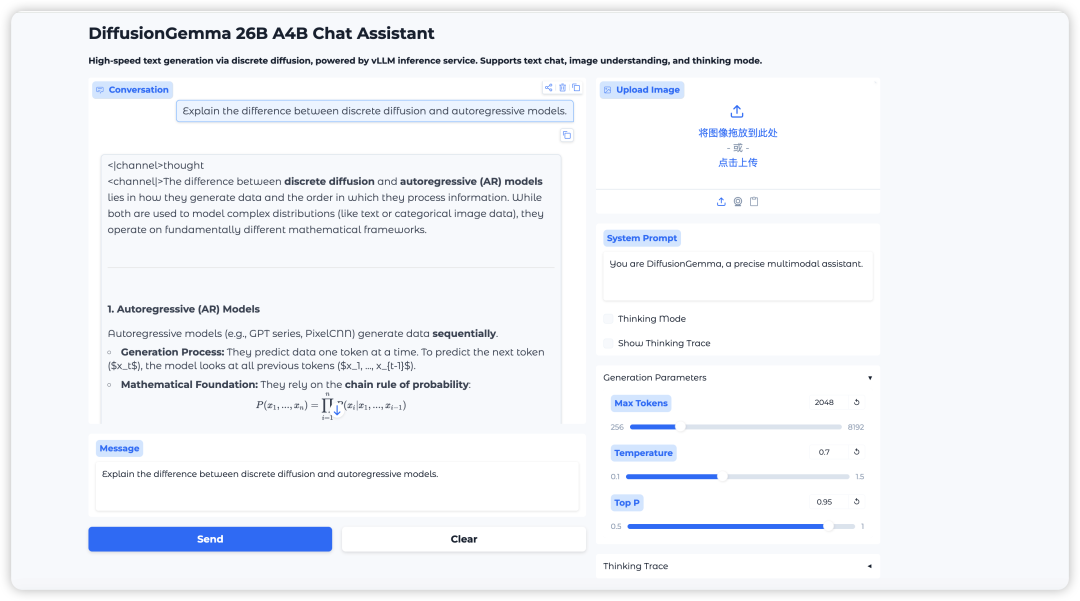
2. Nach Abschluss des Vorgangs klicken Sie auf die API-Adresse auf der rechten Seite, um die Demo-Oberfläche zu öffnen.