Command Palette
Search for a command to run...
Paper-Übersicht | Neueste Fortschritte Im Großskaligen Reinforcement Learning: Microsoft, Google, Stanford, Renmin-Universität, Xiaohongshu Und Andere Veröffentlichen Bedeutende Errungenschaften in Den Bereichen Kreditvergabe, Komplexes Schließen Und Agenten-Reinforcement-Learning

Betrachtet man die aktuelle Entwicklung des Reinforcement Learning, sei es die Verbesserung der Kreditverteilungsfähigkeiten bei Long-Chain-Inferenz, die Erweiterung der autonomen Exploration des Modells in komplexen Umgebungen oder der Aufbau intelligenter Agentensysteme mit langfristigen Planungs- und Feedback-Lernfähigkeiten, so weisen deren Kernziele alle in die gleiche Richtung –Die Grenzen spärlicher Belohnungen und statischer Überwachung überwinden,Es versetzt das Modell in die Lage, durch Interaktion kontinuierlich zu lernen und sich weiterzuentwickeln.
Reinforcement Learning ist im Wesentlichen eine Methode, die es einem intelligenten Agenten ermöglicht, seine Verhaltensstrategien durch einen geschlossenen Kreislauf aus Wahrnehmung, Entscheidung, Ausführung und Feedback kontinuierlich zu optimieren. Im Gegensatz zum traditionellen überwachten Lernen, das auf einer festen Datenverteilung beruht, betont Reinforcement Learning die Fähigkeit des Modells, durch Versuch und Irrtum in Interaktionen mit der Umwelt zu lernen. Dadurch kann es schrittweise einen Entscheidungsmechanismus entwickeln, der den langfristigen Nutzen in dynamischen Aufgaben maximiert.Kurz gesagt, treibt Reinforcement Learning die künstliche Intelligenz von der Fähigkeit, „Fragen zu beantworten“, hin zur Fähigkeit, „autonom zu handeln“, voran und vollzieht damit einen bedeutenden Sprung von der „passiven Generierung“ zur „aktiven Intelligenz“.
Diese Woche,HyperAI hat für Sie 6 der neuesten Forschungsarbeiten auf dem Gebiet des Reinforcement Learning mit großen Modellen ausgewählt.Das Team dahinter besteht aus renommierten Universitäten wie Stanford und der Renmin-Universität Chinas sowie Technologiekonzernen wie Microsoft, Google, Kuaishou und Xiaohongshu. Ihre zugehörigen Veröffentlichungen bieten hochinspirierende neue Lösungsansätze für die Entwicklung von groß angelegten Modellen der nächsten Generation mit leistungsstarken Argumentations- und Selbstlernfähigkeiten. Lasst uns gemeinsam lernen! ⬇️
Um außerdem mehr Nutzern die neuesten Entwicklungen auf dem Gebiet der künstlichen Intelligenz in der akademischen Welt näherzubringen,Auf der offiziellen Website von HyperAI gibt es jetzt eine Rubrik „Neueste Veröffentlichungen“, in der sich die Nutzer über die neuesten Entwicklungen in der KI-Forschung informieren können.
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Die Zeitungsempfehlung dieser Woche
1 ECHO
Titel des Artikels:
ECHO: Terminalagenten lernen kostenlos Weltmodelle
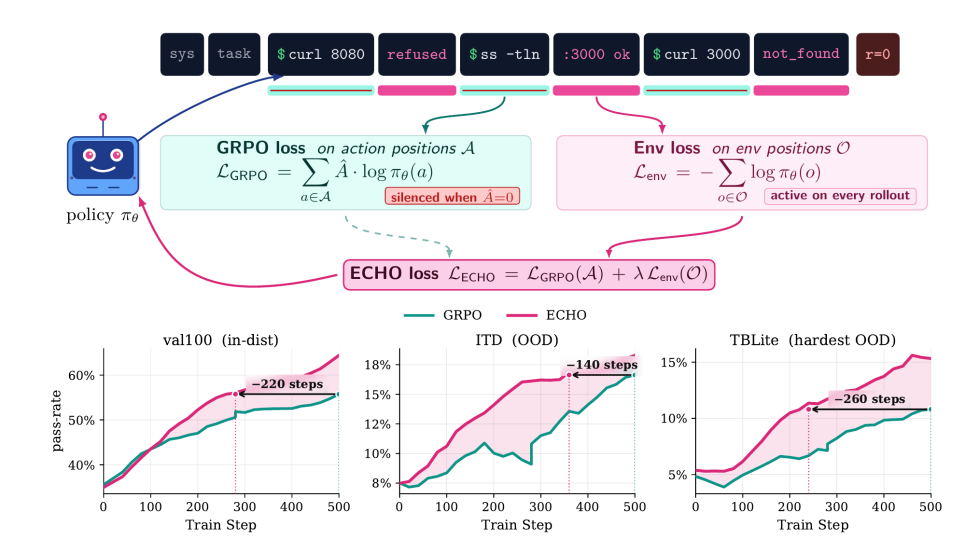
Die Interaktionen von Terminalagenten erzeugen große Mengen an Umweltrückmeldungen. Herkömmliches Reinforcement Learning nutzt jedoch nur wenige Belohnungen zur Aktualisierung von Aktionsbezeichnungen, wodurch Beobachtungsdaten stark verschwendet werden. Diese Arbeit schlägt die ECHO-Methode vor, die neben dem Aktionsverlust zusätzlich den Kreuzentropie-Vorhersageverlust für Umweltrückmeldungen berechnet. Dieser Mechanismus erhöht den Aufwand der Vorwärtsausbreitung nicht und ermöglicht es der Strategie, die Reaktionen des Terminals auf Anweisungen während des Trainings synchron vorherzusagen und so das Weltmodell quasi kostenlos zu erlernen.
Experimentelle Ergebnisse zeigen, dass die Methode die Genauigkeit der ersten Reaktion beim Terminal-Control-Benchmark verdoppelt, die Fähigkeit zur Vorhersage unbekannter Terminaldynamiken deutlich verbessert, die Abhängigkeit von Expertenvorführungen stark reduziert und sogar eine Selbstentwicklung ohne externe Verifizierung erreichen kann.
Papier und detaillierte Interpretation:https://go.hyper.ai/qma4O
2 Delta
Titel des Artikels:
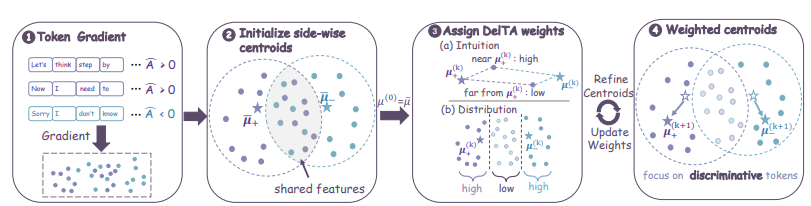
DelTA: Diskriminative Token-Gutschriftzuweisung für Reinforcement Learning mit verifizierbaren Belohnungen
Reinforcement Learning mit verifizierbaren Belohnungen steht oft vor dem Problem einer zu groben Granularität der Kreditvergabe. Regelmäßige Aktualisierungen werden leicht von häufig auftretenden, gemeinsamen Mustern wie dem Typsetting dominiert, wodurch die entscheidenden Inferenzmarker, die tatsächlich hohe Erträge generieren, nicht effektiv identifiziert werden können. Um dieses Problem zu lösen, schlägt diese Arbeit DelTA vor, das die selbstnormalisierte Zielfunktion durch die Berechnung einzigartiger Koeffizienten neu gewichtet. Dieser Mechanismus verstärkt präzise die Gradientenrichtungen von Markern, die sowohl für positive als auch für negative Belohnungen spezifisch sind, unterdrückt gemeinsam auftretende, schwach diskriminative Richtungen stark und verbessert den Kontrast der Gradientenaktualisierungen signifikant. In Evaluierungen mathematischer Inferenz und Codegenerierung übertrifft diese Methode die besten Vergleichsmethoden ihrer Größenordnung umfassend und zeigt eine ausgezeichnete Generalisierungsfähigkeit über verschiedene Architekturen hinweg.
Papier und detaillierte Interpretation:https://go.hyper.ai/IdI42
3 GoLongRL
Titel des Artikels:
GoLongRL: Fähigkeitsorientiertes Reinforcement Learning mit langem Kontext und Multitask-Ausrichtung
Das Reinforcement Learning mit langem Kontext stößt häufig an die Grenzen homogener Trainingsdaten für den Abruf von Daten. Herkömmliche Algorithmen neigen zudem zu verzerrten Vorteilsschätzungen aufgrund von Skalen- und Schwierigkeitsunterschieden bei der Verarbeitung gemischter Belohnungen über mehrere Aufgaben hinweg. Diese Arbeit schlägt das fähigkeitsorientierte GoLongRL-Schema vor und stellt einen Open-Source-Datensatz mit neun Kernfähigkeiten und benutzerdefinierten Belohnungen bereit. Zur Bewältigung von Optimierungsherausforderungen wird ein TMN-Reweight-Mechanismus entwickelt, der die Normalisierung auf Aufgabenebene nutzt, um unterschiedliche Belohnungsskalen anzugleichen, und schwierigkeitsadaptive Gewichte kombiniert, um sich auf wertvolle, schwierige Beispiele zu konzentrieren. Evaluierungen zeigen, dass dieses Schema bestehende führende Modelle in mehreren Benchmarks für lange Texte umfassend übertrifft und den Rückgang der allgemeinen Denk- und Gedächtnisleistung effektiv verhindert.
Papier und detaillierte Interpretation:https://go.hyper.ai/omy5E
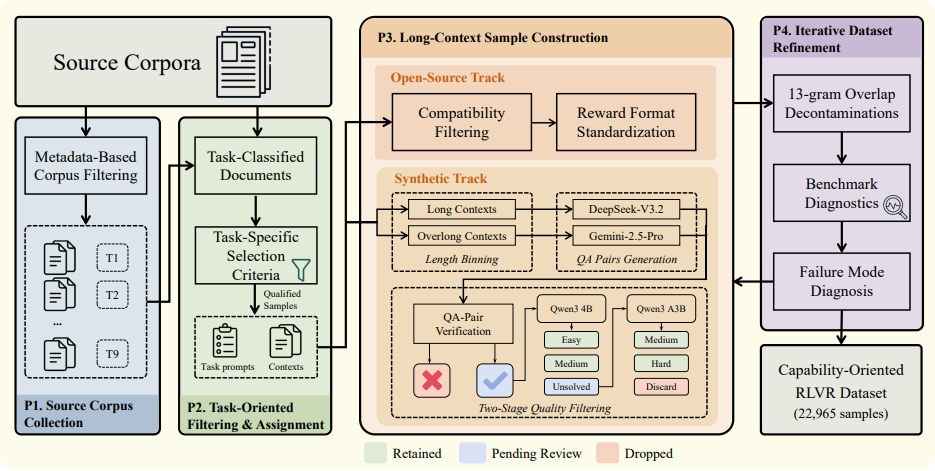
Die Autoren erstellten einen Datensatz mit 22.965 Beispielen, der neun fähigkeitsorientierte Aufgaben mit Kontextlängen von 0,1K bis 256K Token abdeckt.
4 AntiSD
Titel des Artikels:
Anti-Selbstdestillation für Reasoning RL mittels punktweiser gegenseitiger Information
Konventionelle Selbstdestillation in Aufgaben zum mathematischen Denken führt leicht dazu, dass Modelle „Abkürzungen“ nehmen, sich zu sehr auf bekannte Antworten verlassen und den Denkprozess unterdrücken, der mehrstufige Suchvorgänge eigentlich antreibt. Um diesem Problem zu begegnen, schlägt diese Arbeit die Anti-Selbstdestillation (AntiSD)-Methode vor. Anstatt die Lücke zwischen Lehrer- und Schülermodell passiv zu verringern, maximiert sie die JS-Divergenz, um das Gradientensignal umzukehren und insbesondere explorative Denkmuster zu belohnen. Ergänzend dazu sorgt ein entropiebasierter Gating-Mechanismus für die Stabilität des Trainings. Tests an mehreren großen Modellen mit unterschiedlichen Parameterskalen zeigen, dass diese Methode nur ein Fünftel bis die Hälfte der Trainingsschritte des Basismodells benötigt, um das Ziel zu erreichen, und gleichzeitig die Genauigkeit in verschiedenen Benchmarks für mathematisches Denken um bis zu 11,5 Prozentpunkte verbessert.
Papier und detaillierte Interpretation:https://go.hyper.ai/Vax3f
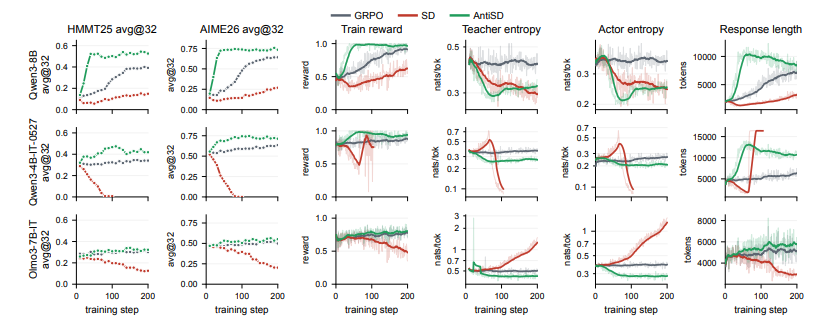
5 RubrikEM
Titel des Artikels:
RubricEM: Meta-RL mit Rubric-gesteuerter Policy-Dekomposition jenseits verifizierbarer Belohnungen
Langfristige, tiefgehende Forschungsaufgaben bieten oft keine objektiven Belohnungen, und herkömmliches Reinforcement Learning liefert nur grobes Feedback, das keine effektive Erfahrungssammlung ermöglicht. Diese Arbeit schlägt das RubricEM-Framework vor, das innovativ eine „Bewertungsskala“ als zentrale Schnittstelle nutzt. Das Modell unterteilt lange Prozesse anhand einer eigens entwickelten Skala in Planungs-, Abruf-, Überprüfungs- und Reaktionsphasen und erreicht so eine fein abgestufte Punktevergabe. Gleichzeitig trainiert das Framework asynchron Meta-Policies und extrahiert historische Interaktionen in wiederverwendbare, reflektierende Erinnerungen. In mehreren Langzeitstudien übertrifft dieses 8B-Modell zahlreiche Open-Source-Lösungen und erreicht nahezu die Leistung führender proprietärer Systeme. Es erzielt effizientes Lernen über lange Kontexte hinweg und eine exzellente Generalisierung über verschiedene Aufgaben hinweg mit minimalem Trainingsaufwand.
Papier und detaillierte Interpretation:https://go.hyper.ai/xSVTh
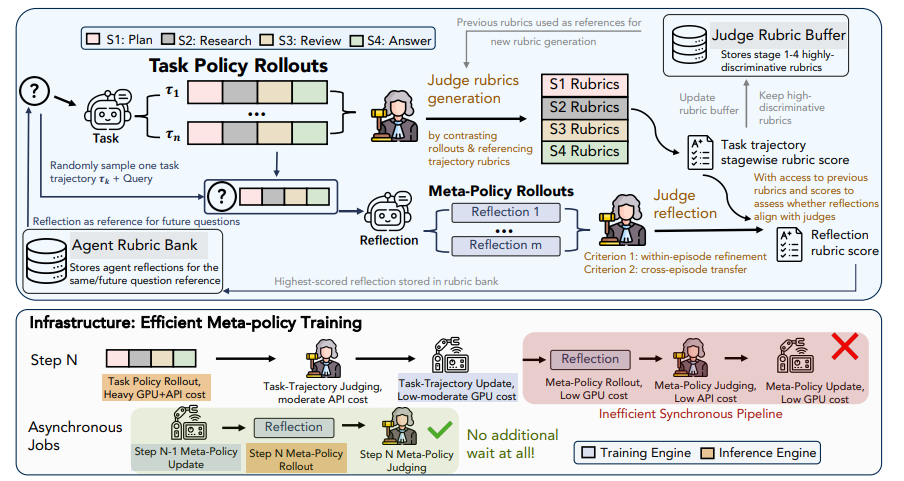
Zusammensetzung und Quelle des Datensatzes: Das Forschungsteam erstellte einen Datensatz für überwachtes Feintuning mit ca. 11.000 Beispielen. Die Datenquelle sind Agententrajektorien, die vom Gemini-Lehrermodell generiert und für Qwen3 angepasst wurden.

6 Poly-EPO
Titel des Artikels:
Poly-EPO: Training explorativer Denkmodelle
Das Nachtrainieren von groß angelegten Reinforcement-Learning-Modellen führt häufig zu einem Verlust an generativer Diversität, was die Erkundung neuer Inferenzpfade und die Erweiterung der Rechenleistung während des Testens behindert. Um die kollaborative Erkundung und Nutzung zu verbessern, schlägt diese Studie den Poly-EPO-Algorithmus vor, der auf Ensemble-Reinforcement-Learning basiert. Diese Methode bricht mit dem traditionellen Ansatz, einzelne Antworten isoliert zu bewerten, indem sie die durchschnittliche Belohnung einer Menge von Antworten mit dem Diversitätswert der Inferenzstrategie als gemeinsames Optimierungsziel multipliziert. Dadurch werden Signale, die eine vielfältige Erkundung fördern, nativ in die Vorteilsfunktion eingebettet. Bei der Bewertung mathematischer Argumentation vermeidet dieser Algorithmus erfolgreich eine Homogenisierung der Strategie, erzielt eine Verbesserung der Pass@k-Abdeckung um bis zu 20% und zeigt ein stärkeres Erweiterungspotenzial unter Mehrheitsentscheidungsmechanismen.
Papier und detaillierte Interpretation:https://go.hyper.ai/j9Z3C
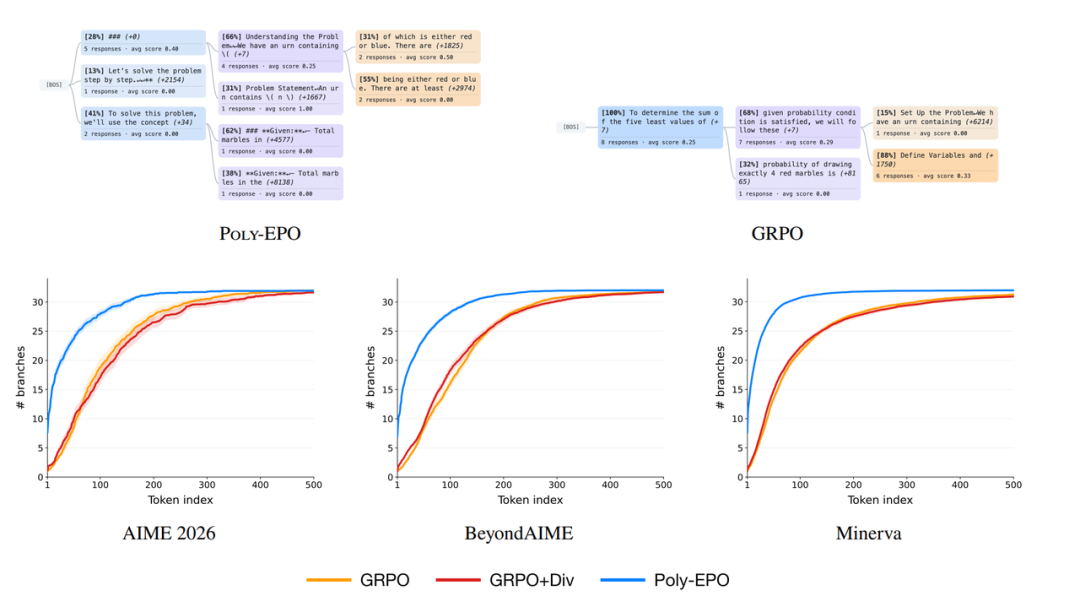
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Bis nächste Woche!








