Command Palette
Search for a command to run...
Das Argonne National Laboratory in Den Vereinigten Staaten Hat CVEvolve Vorgeschlagen, Einen Zero-Code-Algorithmus Zur Selbstentdeckung Für Die Wissenschaftliche Bildverarbeitung, Der Über Umfassende Funktionen Verfügt, Darunter Codierung, Ergebnisselbstprüfung Und Strategieoptimierung.

Zu einer objektiven und strengen wissenschaftlichen Schlussfolgerung zu gelangen, ist so schwierig wie die Goldsuche in einer riesigen Wüste. Dies gilt insbesondere heute, da hochentwickelte wissenschaftliche Instrumente und Simulationstechnologien weit verbreitet sind.Die von der wissenschaftlichen Forschung erzeugten Daten sind von enormem Umfang, lose strukturiert und höchst unstrukturiert.Die Aufbereitung wissenschaftlicher Forschungsdaten gleicht der Suche nach Gold im Sand; sie ist zum entscheidendsten und wichtigsten Schritt geworden, um den Wert der Daten zu erschließen und die Wahrheit der wissenschaftlichen Forschung ans Licht zu bringen.
Das Dilemma liegt jedoch genau hier: Domänenwissenschaftlern fehlen oft die für die Datenverarbeitung erforderlichen Fachkenntnisse, wie etwa Computer Vision, Bildverarbeitung und Softwareentwicklung; technische Experten hingegen, die gut in der Datenverarbeitung sind, können den disziplinären Hintergrund nicht tiefgehend verstehen und haben Schwierigkeiten, adaptive Verarbeitungsabläufe zu entwerfen, die zu realen wissenschaftlichen Forschungsszenarien passen.
Die Schließung der fachlichen Wissenslücke, die bei der wissenschaftlichen Datenverarbeitung entsteht,Ein Forschungsteam des Argonne National Laboratory (ANL) in den Vereinigten Staaten hat nach systematischer Analyse bisheriger KI-basierter Automatisierungsarbeiten ein Zero-Code-Framework für autonome Agenten namens CVEvolve entwickelt.Dieses Framework dient der Gewinnung von Algorithmen für die Datenverarbeitung in der wissenschaftlichen Forschung. Es zeichnet sich durch hohe Flexibilität aus und benötigt weder eine vordefinierte Problemarchitektur noch feste Prozessvorlagen. Es ermöglicht die nahtlose Verknüpfung verschiedener Elemente wie Code, Daten, Bewertungsmetriken, Abfrageergebnisse und Visualisierungsergebnisse. Es unterstützt die Entwicklung ausführbarer Algorithmen für Computer Vision, Bildverarbeitung und weitere Bereiche. Es ist nicht auf eine einzelne Modellierungsmethode beschränkt und bietet umfassende Funktionen, darunter Codeerstellung (Ausführung), Effektbewertung, Verlaufsanalyse, Ergebnisprüfung und strategische iterative Optimierung.
Kurz gesagt, CVEvolve ist in der Lage, eigene, spezialisierte Algorithmen zu entwickeln, die an verschiedene wissenschaftliche Datenverarbeitungsszenarien in realen Situationen angepasst sind. Dadurch können Wissenschaftler auch ohne Programmierkenntnisse oder Erfahrung in der Bildverarbeitung schnell mit intelligenten Analysemethoden beginnen, ohne eine einzige Zeile Code schreiben zu müssen. Die Ergebnisse sind umfassender, zuverlässiger und effizienter als bei bisherigen Methoden.
Die zugehörigen Ergebnisse mit dem Titel „CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing“ wurden auf der Preprint-Plattform arXiv veröffentlicht.
Forschungshighlights:* CVEvolve schlägt ein allgemeines Proxy-Framework zur Entdeckung von Algorithmen für die autonome wissenschaftliche Datenverarbeitung vor, das speziell für unstrukturierte Probleme entwickelt wurde und die Notwendigkeit vordefinierter Problemframeworks und fester Prozessvorlagen eliminiert. * CVEvolve führt eine Architektur für die Weitfeldsuche ein, die Generierungs-, Optimierungs- und Entwicklungsmechanismen mit quellenbasierter Zustandsverwaltung und agentengesteuerten Retentionstests kombiniert. Dies gewährleistet die Flexibilität, Autonomie, Reife und Benutzerfreundlichkeit des Frameworks. * CVEvolve wurde anhand verschiedener Aufgaben validiert, darunter die Bildregistrierung in der Röntgenfluoreszenzmikroskopie, die Bragg-Peak-Detektion und die Bildsegmentierung in der Hochenergie-Diffraktionsmikroskopie. Die Validierung demonstriert die Fähigkeit von CVEvolve, praktische Algorithmen zu entdecken und wissenschaftliche Erkenntnisse zu beschleunigen.

Lesen Sie das Dokument:
https://hyper.ai/papers/2605.11359
Für die drei Aufgabentypen wurden spezielle Validierungsdatensätze erstellt.
In dieser Studie wurden alle Datensätze speziell für das Kontrollexperiment zusammengestellt.
Datensatz zur Registrierung von Fluoreszenzmikroskopiebildern
Basierend auf realen Röntgenfluoreszenzbildern wurden Verschiebung, Poisson-Rauschen, Scanjitter und Unschärfe künstlich angewendet, um Bildunterschiede unter realer Fokusdrift zu simulieren. Die Bilder wurden logarithmisch skaliert und hatten eine Größe von nur 10–30 Pixeln. Der Datensatz umfasste 809 Test-/Referenzbildpaare, wobei 101 TP3T-Bilder zufällig als Validierungssatz ausgewählt und die verbleibenden 901 TP3T-Bilder für die Algorithmeniteration und -entwicklung verwendet wurden.
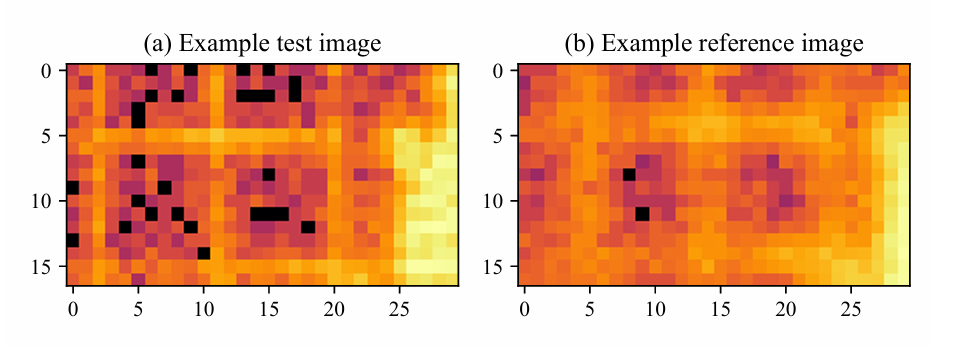
Bragg-Peak-Erkennungsdatensatz
Die Beugungsbilder wurden von allen Abtastpunkten aufgenommen und anschließend in zwei Gruppen unterteilt. Die Bilder jeder Gruppe wurden pixelweise übereinandergelegt, um zwei Bilder zu erzeugen. Ein Bild diente der Leistungsbewertung während der Algorithmenentwicklung, das andere als Validierungsdatensatz. Die Bragg-Peaks in beiden Bildern wurden manuell markiert.
Datensatz zur Segmentierung von Hochenergie-Diffraktionsmikroskopiebildern: Der Entwicklungsdatensatz enthält 5 Bilder und deren manuell erstellte Beschriftungen, wobei 2 Beispiele für den Testdatensatz reserviert sind.
Drei Hauptprozesse und fünf Schlüsselwerkzeuge für den Aufbau eines LLM-basierten intelligenten Agenten.
In Bezug auf die Gesamtarchitektur,CVEvolve ist ein autonomer Suchcontroller, der auf einem großen Sprachmodellagenten basiert. Der Agent kann mithilfe von Werkzeugen Kandidatenlösungen generieren, ausführen und bewerten, während der Controller die Richtung der weiteren Suche anhand historischer Daten bestimmt.Die Iterationsstrategie basiert auf dem Pty-Chi-Evolve-Framework und umfasst drei Arten von Operationsschritten: Generieren, Optimieren und Weiterentwickeln. Durch ein erweitertes Toolset und ein verbessertes Zustandsmanagement ist sie für mehr Aufgaben geeignet.
Um die Kontextlänge zu steuern und den Rechenaufwand zu reduzieren, wird in jeder Iteration ein komplett neuer Kontext verwendet. Lediglich die System- und Aufgabenaufforderungen, die den in dieser Runde durchgeführten Aktionen entsprechen, werden beibehalten; frühere Dialogprotokolle werden nicht gespeichert. Innerhalb derselben Runde können die Prozesse „Generieren“ und „Anpassen“ gleichzeitig von mehreren parallelen Prozessen ausgeführt werden. Dadurch kann das System mehrere neue Lösungen erkunden oder mehrere Optimierungs- und Anpassungsrunden für unterschiedliche Originalinhalte durchführen, bevor die Dialogprotokolle aktualisiert werden.
Nach jeder Runde werden die vom Agenten eingereichten Kandidatenalgorithmen gemäß ihrer evolutionären Abstammung gruppiert, wobei Eltern-Kind-Vererbungsbeziehungen erfasst und bewährte Designmuster erhalten bleiben. Die Architektur der Kandidatenauswahl ist dem MAP-Elites-Algorithmus entlehnt und erfolgt zufällig. Für die Optimierungs- und Entwicklungsschritte verwendet CVEvolve eine zufällige Kandidatenauswahl, anstatt stets den aktuell besten Kandidaten auszuwählen.
Dreistufiger Arbeitsablauf
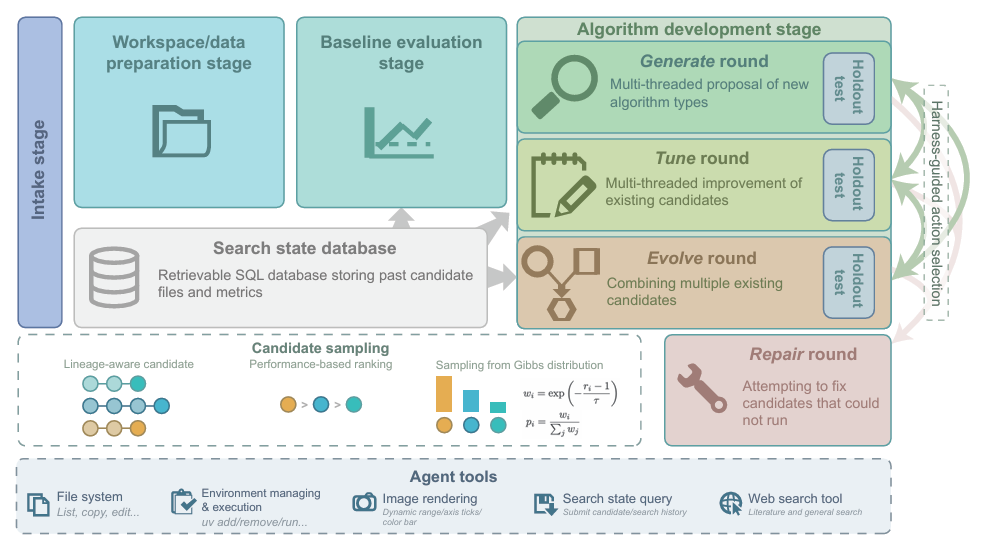
* Phase der Arbeitsplatzvorbereitung:Ausgehend von der Vorbereitung des Arbeitsbereichs wird die Laufzeitumgebung eingerichtet und die Bewertungsmetriken aus Aufgabenbeschreibungen oder Benutzereingaben werden automatisch in ausführbaren Bewertungscode geschrieben.
* Phase der Ausgangsbewertung:Bestehende Benchmark-Algorithmen ausführen und auswerten, um eine Grundlage für nachfolgende Vergleichsarbeiten zu schaffen.
* Algorithmen-Iterations- und Entwicklungsphase:Der Algorithmus folgt den Strategien Generieren, Optimieren und Weiterentwickeln, um mehrere iterative Suchrunden durchzuführen. Die Generierungsstrategie dient der umfassenden Exploration und dem Entwurf neuer Algorithmen mithilfe mehrerer Threads. Die Optimierungsstrategie ist für die grundlegende Optimierung zuständig, indem sie zufällig die besten Kandidatenalgorithmen auswählt und deren Parameter optimiert. Die Weiterentwicklungsstrategie ist für die iterative Evolution verantwortlich, indem sie die Vorteile mehrerer Algorithmen kombiniert, um einen neuen Algorithmus zu generieren.
Um die Strenge und Rationalität der Forschung zu gewährleisten, umfasst der Gesamtprozess außerdem optionale Reparaturrunden zur Behebung von Fehlern in Kandidatenalgorithmen, die nicht ausgeführt werden können, unabhängige Tests nach jeder Runde, eine SQL-Suche in der Statusdatenbank sowie die Aufzeichnung von Kandidaten, Indikatoren, Iterationsrunden und evolutionären Linien während des gesamten Prozesses.
Fünf zentrale unterstützende Werkzeuge
* Dateisystemtools:Unterstützt das Auflisten, Lesen, Schreiben, Bearbeiten, Kopieren, Verschieben und Löschen von Dateien im Arbeitsbereich und ermöglicht es Agenten, Kandidatencodes, Hilfsskripte und Bewertungstools in einer Sitzungssandbox zu schreiben.
* Tools für Umgebungsmanagement und Codeausführung:Installieren oder Entfernen von Abhängigkeiten im Support-Workspace und Ausführen von Python-Skripten.
* Bildanzeigewerkzeuge:Es unterstützt Gleitkomma-Bildverarbeitung, logarithmische Skalierung von Bildern mit hohem Dynamikumfang, Konvertierung von TIFF in PNG und andere Anpassungsfunktionen, wodurch der Agent in der Lage ist, subtile Strukturen, Helligkeitsvariationen und Anomalien zu erkennen, die bei gewöhnlichem linearem Rendering schwer zu erkennen sind.
* Suchstatus-Tool:Es unterstützt Agenten bei der Festlegung von Kernmetriken, der Aufzeichnung von Bewertungsergebnissen, der Überprüfung historischer Daten, der Analyse von Kandidatenergebnissen und der Übermittlung neuer Kandidaten an die Suchdatensätze in der strukturierten Abfragesprache.
* Web-Suchwerkzeuge:Durch den Zugang zu arXiv, Semantic Scholar und Tavily wird die Entwicklung iterativer Algorithmen erleichtert, indem externe technische Referenzinformationen genutzt werden.
Zusätzlich wurde dem Design eine Middleware zur multimodalen Bildnachverfolgung hinzugefügt, um die Einschränkung großer Sprachmodellschnittstellen, Bilder nicht direkt übertragen zu können, auszugleichen. Konkret fügt das Tool, sobald es den Bildpfad zurückgibt, das gerenderte Bild automatisch als Folgenachricht in den Dialog ein.
Kernarchitektur der zugrundeliegenden Ausführung
CVEvolve ist eine auf LangGraph basierende Agentenanwendung. Sie verwendet zur Laufzeit einen vereinfachten Knotengraphen und verarbeitet Daten in vier Kernprozessen: Nachrichtenempfang, Modellinferenz, Werkzeugaufruf und Bildnachbearbeitung. Nachdem das Werkzeug den Bildpfad zurückgegeben hat, wandelt der Bildverarbeitungsknoten diesen in multimodale Beobachtungsdaten um und sendet sie zur Verwendung in der nächsten Inferenzrunde an das Modell zurück (siehe Abbildung unten).
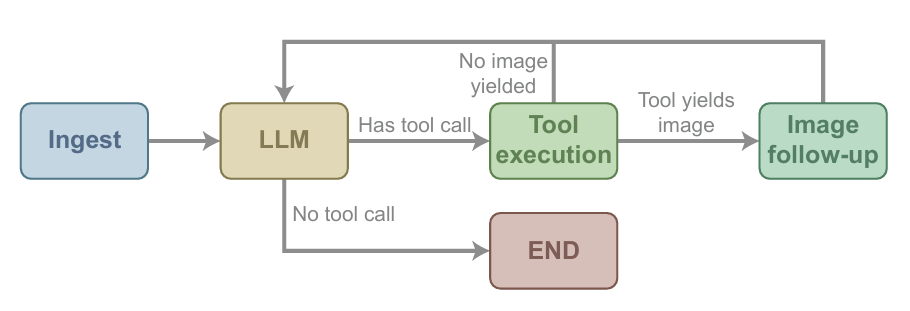
Überprüfung der Praktikabilität von CVEvolve in drei Arten von wissenschaftlichen Bildverarbeitungsszenarien
Um die praktische Effektivität und Generalisierungsfähigkeit von CVEvolve zu demonstrieren, hat das Forschungsteam speziell drei Sätze von realen wissenschaftlichen Bildverarbeitungsexperimenten zur Validierung entworfen.Alle Experimente wurden mit Claude Opus 4.6 durchgeführt.
Registrierung von Fluoreszenzmikroskopie-Bildern
Die Forscher demonstrierten zunächst die Aufgabe von CVEvolve bei der Suche nach einem robusten Algorithmus für die translatorische Registrierung von Röntgenfluoreszenzmikroskopie-Bildern (XRF), der das Problem der Bildversatzkalibrierung nach der Fokussierung des Mikroskops angeht.
Zu den Basisalgorithmen gehören zwei Typen: Phasenkorrelation mit einem Hanning-Fenster-Vorprozessor und Brute-Force-Fehlerminimierung; als Leistungsvergleichsmetrik dient die durchschnittliche euklidische Distanz zwischen berechneten und tatsächlichen Verschiebungen.
Die Studie zeigt nach 20 Suchrunden die Fehleränderungen und Leistungsmerkmale. In den ersten Basisrunden betrug der durchschnittliche euklidische Fehler der Brute-Force-Fehlerminimierung 1,25, während der Fehler der Phasenkorrelationsmethode nach Hanning-Fenster-Vorverarbeitung bis zu 5,8 erreichte. Nach den darauffolgenden Generierungs- und Entwicklungsrunden sank der Registrierungsfehler kontinuierlich auf 0,8 bzw. 0,43, und die Leistung stabilisierte sich nach der 9. Runde. Dies wird in der folgenden Abbildung veranschaulicht.
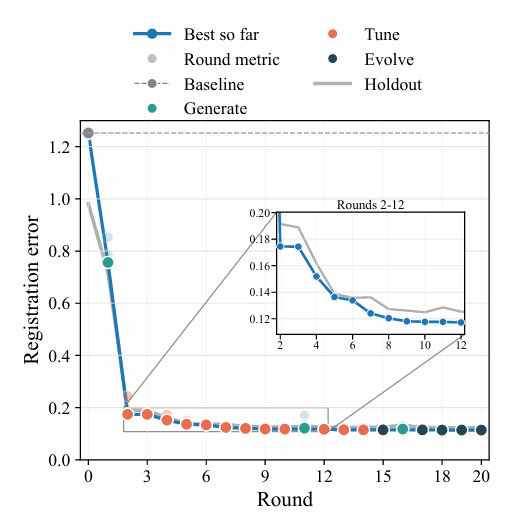
Zur Auswahl des optimalen Registrierungsalgorithmus verwendet dieser Algorithmus ein schrittweises Bildregistrierungsverfahren. Im ersten Schritt erfolgt die Ausrichtung und Positionierung auf Pixelebene mittels normalisierter Kreuzkorrelation in verschiedenen Skalen. Im zweiten Schritt werden verschiedene Vorverarbeitungsmethoden, darunter Spline-Funktionen und Optimierungsalgorithmen, kombiniert, um die Genauigkeit bis auf Subpixel-Ebene zu verbessern. Im dritten Schritt werden mehrere Schätzergebnisse anhand der Koordinaten adaptiv gewichtet und integriert, um einen stabilen und zuverlässigen finalen Offset zu ermitteln.
Tests an einem Validierungsdatensatz und Vergleiche mit verschiedenen Basisalgorithmen zeigten, dass der optimale Registrierungsalgorithmus einen Fehler von 0,12 aufwies, fast achtmal niedriger als der des leistungsstärkeren Brute-Force-Fehlerminimierungsalgorithmus.Die Forscher verglichen die von CVEvolve gefundenen Kandidaten mit denen von OpenEvolve. Nach 500 Iterationen stabilisierte sich der Fehler bei 0,23, was deutlich höher war als der des von CVEvolve gefundenen Kandidatenalgorithmus.Wie in der folgenden Tabelle gezeigt:

Bragg-Peak-Detektion
Ziel dieses Experiments ist die Entwicklung eines Algorithmus zur Erkennung von Bragg-Peaks in Röntgenbeugungsbildern. Es soll ein Verfahren entwickelt werden, das Bragg-Peaks innerhalb und um entsprechende ringförmige Bereiche einer gegebenen Gitterebene identifiziert und lokalisiert. Zu den Bewertungskriterien gehören der F1-Score, die Präzision und die Trefferquote.
Da der Entwicklungsdatensatz nur ein Bild enthält, ist der Algorithmus stark anfällig für Überanpassung. Daher muss ein Holdout-Datensatz verwendet werden, um die Generalisierungsleistung zu überwachen. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Der F1-Score für das Bild im Entwicklungsdatensatz steigt kontinuierlich an und nähert sich schließlich dem Idealwert von 1, während der F1-Score für den reservierten Testdatensatz um die 5. Runde seinen Höchstwert erreicht und nach der 9. Runde stark abfällt.
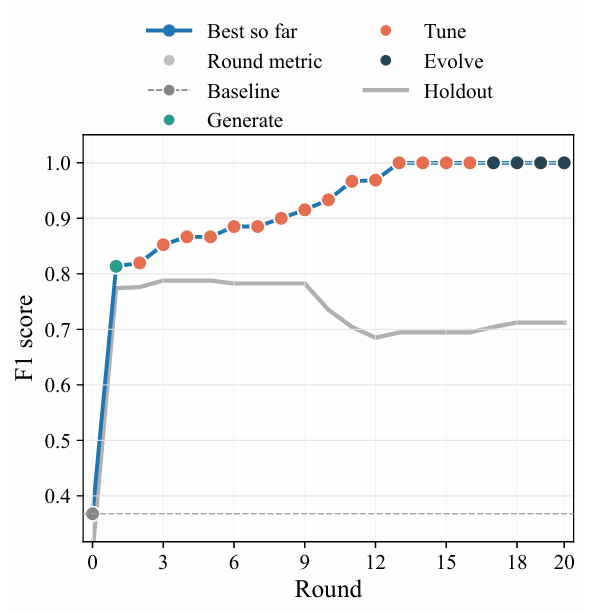
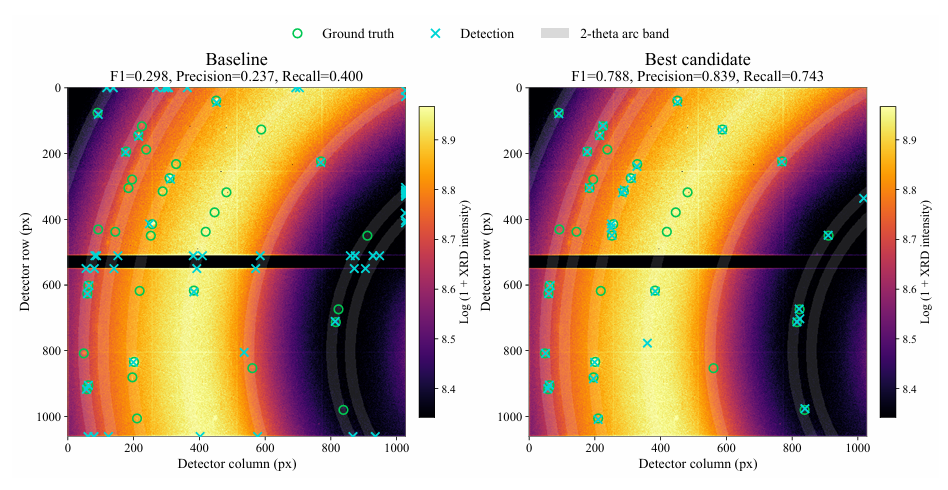
Anschließend wählen wir im fünften Durchgang den optimalen Kandidaten aus. Zuerst maskieren wir den ungültigen Bereich und erstellen dann eine Signal-Rausch-Verhältnis-Karte, indem wir den Hintergrund mithilfe bogenförmiger Polarkoordinaten subtrahieren und das lokale Rauschen normalisieren. Danach verwenden wir einen mehrstufigen komplementären Algorithmus, um den Spitzenwert zu ermitteln. Abschließend führen wir die Ergebnisse zusammen, überprüfen und optimieren den Mittelpunkt, um die endgültigen Spitzenkoordinaten auszugeben.
Die Ergebnisse zeigen, dassDie optimale Kandidatenlösung kann Fehlalarme wirksam verringern, gleichzeitig die Anzahl verpasster Detektionen reduzieren und mehr markierte Peaks identifizieren.Der beste Kandidat erzielte im Vergleich zur Basislinie in allen Metriken Leistungsverbesserungen: Der F1-Score stieg von 0,298 auf 0,788, der Präzisionswert von 0,237 auf 0,839 und der Recall-Wert von 0,400 auf 0,743 (entsprechend der Anzahl übersehener Fälle). Siehe Abbildung unten.
Diffraktionsbildsegmentierung
Die Aufgabe dieser Studie war die Segmentierung von polykristallinen Beugungsbildern. Die Herausforderung bestand darin, Beugungsringe und Bragg-Reflexe präzise zu unterscheiden. Im Experiment wurde der gewichtete Intersection-to-Union-Index (IoU) verwendet und 40 Beobachtungsrunden durchgeführt. Die Ergebnisse zeigten…Die vom Agenten mittels Hintergrundsubtraktion und Schwellenwertsegmentierung zur Identifizierung von Merkmalen erstellten ersten Basiskandidaten wiesen letztendlich ein Schnittmengen-Vereinigungs-Verhältnis von nur 0,37 auf, was eine geringe Genauigkeit darstellt.Wie in der Abbildung unten gezeigt.
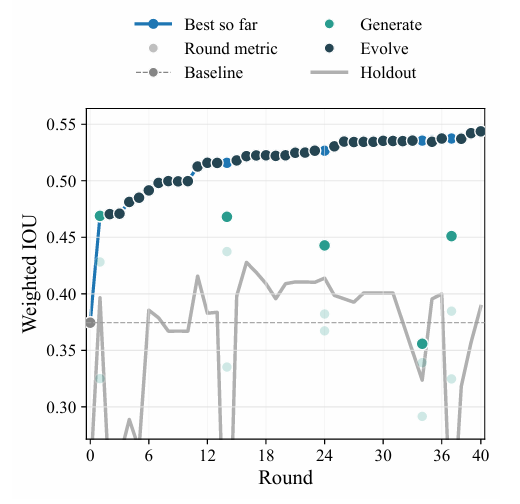
Anschließend wurde in der 16. Runde anhand der Kennzahlen des Retentionstests der optimale Kandidatenalgorithmus ausgewählt. Dieser wurde in ein logarithmisches Beugungsbild transformiert, die Parameter für Strahlzentrum und radialen Hintergrund berechnet und die ringförmigen Ergebnisse durch radiale und azimutale Konsistenzprüfungen identifiziert und verifiziert. Die Pixel wurden anhand des Hintergrundschwellenwerts segmentiert, die Beugungspeaks herausgefiltert und eine Segmentierungsmaske erstellt.
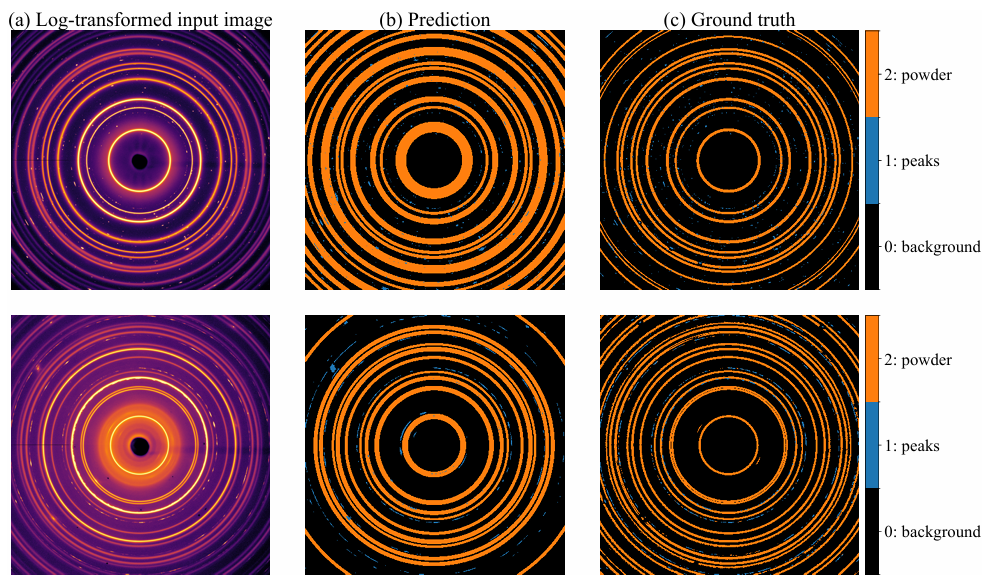
Die Ergebnisse zeigten, dass die vorhergesagte ringförmige Maske in der ersten Demonstration breiter und dicker als die tatsächliche Basislinienkontur war. Nach sorgfältiger Überprüfung konnte jedoch bestätigt werden, dass die meisten ringförmigen Strukturen erfolgreich detektiert und verschiedene Bragg-Peaks gut segmentiert wurden. Die vorhergesagte Maske wies eine hohe Übereinstimmung mit der tatsächlichen Basislinienkontur auf. In der zweiten Demonstration konnten einige wenige ringförmige Strukturen im äußeren Bereich nicht identifiziert und detektiert werden.
Letzte Worte
Zusammenfassend lässt sich sagen, dass die codefreie Entwicklung von CVEvolve den Einstieg in die computergestützte Bildgebungstechnologie deutlich erleichtert und Wissenschaftlern einen direkten Weg zur individuellen wissenschaftlichen Datenverarbeitung eröffnet. Zukünftig wird CVEvolve seine Fähigkeiten, wie im Artikel beschrieben, durch die Erweiterung auf fortgeschrittene Datenverarbeitung und Echtzeit-Workflow-Optimierung weiter ausbauen. Dies wird autonome wissenschaftliche Entdeckungsprozesse in ein Zeitalter führen, das von Intelligenz und Technologie geprägt ist.








