Command Palette
Search for a command to run...
Tencent Veröffentlicht Hy-MT1.5 Als Open Source: Das 440 MB Große Übersetzungsmodell Bietet Erstklassige Übersetzungsfähigkeiten; MIT Veröffentlicht Gemeinsam MathNet: Einen Multimodalen Benchmark Für Mathematische Inferenz, Der 27.000 Reale Mathematikaufgaben Der Olympiade abdeckt.

Hy-MT1.5-1.8B-1.25bit ist ein von Tencent entwickeltes, ressourcenschonendes maschinelles Übersetzungsmodell. Es basiert auf Hy-MT1.5-1.8B und wurde durch mehrstufiges Training optimiert, einschließlich MT-Vortraining, überwachtem Feintuning, Destillation und Reinforcement Learning.Das Modell unterstützt 33 Sprachen, 5 Dialekte und Minderheitensprachen sowie 1.056 Übersetzungsrichtungen.Mit nur 1,8 Milliarden Parametern übertrifft seine Übersetzungsleistung die einiger größer angelegter Open-Source-Modelle und gängiger kommerzieller Übersetzungs-APIs.
Die HyperAI-Website präsentiert jetzt „Hy-MT1.5-1.8B-1.25bit: Ein leichtgewichtiges, mehrsprachiges Übersetzungsmodell“. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/PCK8X
Besuchen Sie unsere offizielle Website für weitere Informationen:
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 6. bis 15. Mai:
* Hochwertige öffentliche Datensätze: 12
* Eine Auswahl hochwertiger Tutorials: 7
* Interpretation von Community-Artikeln: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. QCalEval Quantenkalibrierungsdiagramm – Verständnis des Datensatzes
QCalEval, 2026 von NVIDIA veröffentlicht, ist ein Datensatz für visuelle Sprachmodelle zur Graphenanalyse in Quantencomputer-Experimenten. Er dient der Evaluierung der Fähigkeit visueller Sprachmodelle (VLMs), die Ergebnisse von Kalibrierungsexperimenten im Quantencomputing zu interpretieren, zu klassifizieren und zu analysieren. QCalEval findet breite Anwendung in der Forschung zu visuellen Sprachmodellen und wissenschaftlicher Bildanalyse. Der Datensatz umfasst 309 zweidimensionale wissenschaftliche Bilder im PNG-Format, 243 Benchmark-Einträge und 236 Few-Shot-Benchmark-Einträge aus 22 Versuchsreihen und 87 Szenentypen.
Online-Nutzung:https://go.hyper.ai/Ke7cu
2. Claw-Eval Real-World Benchmark Dataset
Claw-Eval, 2026 von der Peking-Universität und der Universität Hongkong veröffentlicht, ist ein durchgängig transparenter Benchmark-Datensatz zur Evaluierung von KI-Agenten in realen Aufgaben. Er dient der Bewertung der Fähigkeiten autonomer Agenten in den Bereichen Aufgabenausführung, Werkzeugaufruf, multimodales Verständnis und mehrstufige Interaktion in realen Umgebungen. Der Datensatz unterstützt Englisch und Chinesisch und umfasst drei Kernaufgabengruppen: Allgemein, Multimodal und Mehrstufige Interaktion. Er deckt 24 Aufgabenkategorien ab, darunter Kommunikation, Finanzen, Büroarbeit und Produktivitätstools.
Online-Nutzung:https://go.hyper.ai/Tznpa
3. MathNet Multimodaler mathematischer Benchmark-Inferenzdatensatz
MathNet ist ein umfangreicher, mehrsprachiger und multimodaler Datensatz für mathematisches Denken, der 2026 vom MIT-Team in Zusammenarbeit mit der King Abdullah University of Science and Technology und anderen Institutionen veröffentlicht wurde. Er dient der Evaluierung und Verbesserung der Leistungsfähigkeit großer Modelle in mathematischen Denk- und strukturierten Suchaufgaben auf Olympiade-Niveau und findet breite Anwendung in der Evaluierung mathematischen Denkens, der Forschung zu Random Access Tools (RAG) und dem Training multimodaler KI.
Online-Nutzung:https://go.hyper.ai/HLxNw
4. RSRCC-Fernerkundungsflächenänderungs-Basisdatensatz
Der 2026 von Google Research veröffentlichte Datensatz RSRCC dient als Benchmark für das Verständnis semantischer Veränderungen in der Fernerkundung. Er ermöglicht ein tieferes Verständnis zeitlicher Veränderungen in Fernerkundungsszenen, indem er multitemporale Bilddaten mit natürlichsprachlichen Frage-Antwort-Systemen kombiniert und die traditionelle binäre Veränderungserkennung um eine semantische Veränderungsbeschreibung erweitert. Der Datensatz umfasst 126.000 Frage-Antwort-Beispiele zur Veränderungserkennung in der Fernerkundung und deckt Szenarien wie Neubau, Abriss, Straßenbau, Vegetationsveränderungen und Wohnbebauung ab.
Online-Nutzung:https://go.hyper.ai/jtCaK
5. Datensatz zur Erkennung medizinischer Abfälle
Medical Waste ist ein hochauflösender Bilddatensatz, der für die intelligente Identifizierung und gezielte Erkennung von medizinischen Abfällen entwickelt wurde. Er soll Computer-Vision-Modellen helfen, medizinische Abfälle in komplexen medizinischen Umgebungen automatisch zu erkennen und zu klassifizieren, und findet breite Anwendung in Forschungsbereichen wie intelligenter Gesundheitsversorgung, öffentlicher Gesundheit, automatisierter Abfallsortierung und Robotervision.
Online-Nutzung:https://go.hyper.ai/PrUKd
6. Datensatz zu Weinblattkrankheiten
GRAPE Leaf Diseases ist ein Bilddatensatz für Weinblätter, der speziell für die Erkennung von Krankheiten in der Präzisionslandwirtschaft entwickelt wurde. Ziel ist es, die Fähigkeit von Computer-Vision-Modellen zur Erkennung, Klassifizierung und Lokalisierung von Krankheiten in realen landwirtschaftlichen Szenarien zu verbessern. Der Datensatz umfasst 4.195 Bilder von Weinblättern in vier Kategorien: gesunde Weinblätter und drei häufige Krankheiten: Schwarzfäule, Escafé fulva und Blattfleckenkrankheit.
Online-Nutzung:https://go.hyper.ai/tJrkm
7. Atlas der aquatischen Tierwelt: Ein globaler Datensatz über das Leben im Wasser.
Der „Aquatic Wildlife Atlas: Global Species Records“ ist ein umfangreicher Datensatz zur Beobachtung von Wassertieren, der für die aquatische Ökologieforschung und Biodiversitätsanalyse entwickelt wurde. Er soll Forschern, Studierenden und Datenwissenschaftlern hochwertige Datenressourcen zur aquatischen Ökologie bereitstellen. Der Datensatz umfasst 200.000 Beobachtungsdatensätze von über 100 Wassertierarten und deckt wichtige aquatische Ökosysteme weltweit ab, darunter Korallenriffe, tropische Flüsse, den Arktischen Ozean und Tiefseegebiete bis zu 7.000 Metern Tiefe.
Online-Nutzung:https://go.hyper.ai/calNa
8. Global Earthquake-M4.5: Ein globaler Datensatz von Erdbeben der Magnitude 4,5 und höher.
Globale Erdbebenereignisse – M4.5+ ist ein globaler Datensatz zu Erdbebenereignissen, der für die Analyse seismischer Aktivitäten und die Geodatenforschung entwickelt wurde. Er soll Forschern helfen, die Häufigkeit, Verteilung und Magnitudenvariationen langfristiger seismischer Aktivitäten zu analysieren. Der Datensatz umfasst 230.608 Erdbebenaufzeichnungen, die weltweit Erdbeben mit einer Magnitude von 4,5 und höher im Zeitraum von 1900 bis 2026 abdecken.
Online-Nutzung:https://go.hyper.ai/D7j95
9. Datensatz zur Wirksamkeit synthetischer Arzneimittel
Die Datenbank „Synthetic Drug Effectiveness“ ist ein generierter Datensatz synthetischer Arzneimittel, der die Arzneimittelsicherheitsanalyse und die klinische Risikobewertung unterstützt und sich für Datenanalyse, Modellentwicklung und experimentelle Forschung eignet. Dieser Datensatz enthält strukturierte medizinische Informationen zur Arzneimittelanwendung und zur Überwachung von Nebenwirkungen. Jeder Datensatz ist durch eine eindeutige Berichtsnummer indexiert und enthält grundlegende Informationen wie Alter und Geschlecht des Patienten sowie Behandlungsdetails wie Arzneimittelname, Dosierung, Anwendungsdauer und Begleitmedikation.
Online-Nutzung:https://go.hyper.ai/1ZaA0
10. Datensatz zur Klassifizierung von Augenkrankheiten des Augenhintergrunds
Der Datensatz „Eye Disease Classification Fundus“ ist ein medizinischer Bilddatensatz, der speziell für die Klassifizierung von Fundusbildern entwickelt wurde. Ziel ist die Verbesserung der Klassifizierungsfähigkeiten von Computer-Vision-Modellen bei der Erkennung von Augenkrankheiten und der Unterstützung der Diagnose. Der Datensatz umfasst 6.086 Bilder aus vier Kategorien von Fundusbildern: Katarakt, diabetische Retinopathie, Glaukom und normaler Augenhintergrund.
Online-Nutzung:https://go.hyper.ai/FFFE7
11. Brustkrebs: Multimodaler Fusionsdatensatz
Brustkrebs: Multimodale Fusion ist ein vorverarbeiteter multimodaler Datensatz für Patientinnen mit invasivem Brustkrebs (BRCA). Er dient als sofort einsatzbereite Grundlage für den Aufbau multimodaler Fusionsnetzwerke. Dieser Datensatz verknüpft präzise Daten aus verschiedenen Quellen von 122 BRCA-Patientinnen. Alle Proben wurden mithilfe von TCGA-Fall-IDs modalitätsübergreifend zugeordnet, wodurch eine eindeutige Korrespondenz zwischen makroskopischer medizinischer Bildgebung (MRT), mikroskopischer digitaler Pathologie (Histopathologie), molekularen Omics-Daten (Multi-Omics) und klinischen Behandlungsinformationen erreicht wird.
Online-Nutzung:https://go.hyper.ai/199WV
12. Datensatz zur Erkennung von Waldbränden und Rauch über große Entfernungen
Das Datensatzmodell „Long-Distance Wildfire & Smoke Detection“ ist ein computergestütztes Bildverarbeitungssystem, das für die Frühwarnung und Umweltüberwachung von Waldbränden entwickelt wurde. Es dient der Verbesserung der Fähigkeit des Modells, Rauch und Waldbrände in Szenarien der Waldüberwachung über große Entfernungen zu erkennen. Der Datensatz wurde mithilfe eines vollständig synthetischen Ansatzes generiert, der Überwachungsszenarien mit hohem Winkel und großer Entfernung simuliert, wie beispielsweise Waldbrandtürme und Überwachungskameras auf Bergrücken. Der Fokus liegt dabei auf der Erkennung von Waldbrandrauchwolken, die in den frühen Phasen eines Brandes leichter zu beobachten sind.
Online-Nutzung:https://go.hyper.ai/LnuXC
Ausgewählte öffentliche Tutorials
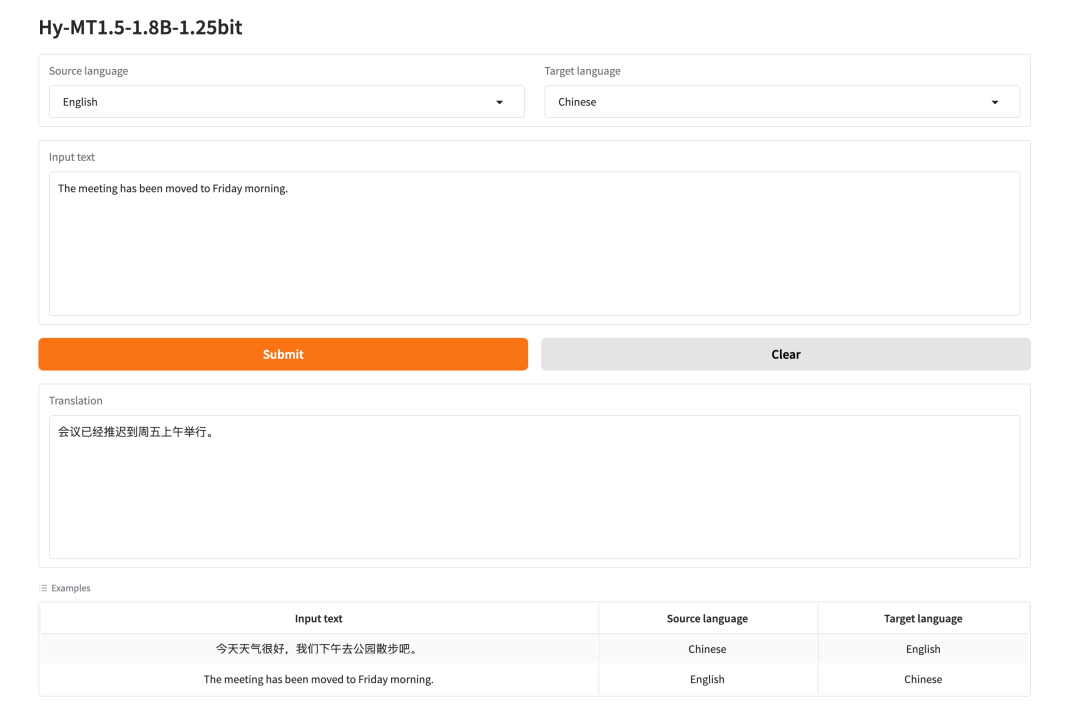
1. Hy-MT1.5-1.8B-1.25bit: Leichtgewichtiges mehrsprachiges Übersetzungsmodell
Hy-MT1.5-1.8B-1.25bit, das von Tencent im April 2026 veröffentlicht wurde, ist ein auf Hy-MT1.5-1.8B basierendes, quantisiertes 1,25-Bit-Übersetzungsmodell für mehrsprachige Anwendungen. Der Hauptvorteil dieses Modells liegt in der Komprimierung hochwertiger mehrsprachiger Übersetzungsfunktionen in eine ressourcenschonendere Bereitstellungsform.
Online ausführen:https://go.hyper.ai/PCK8X
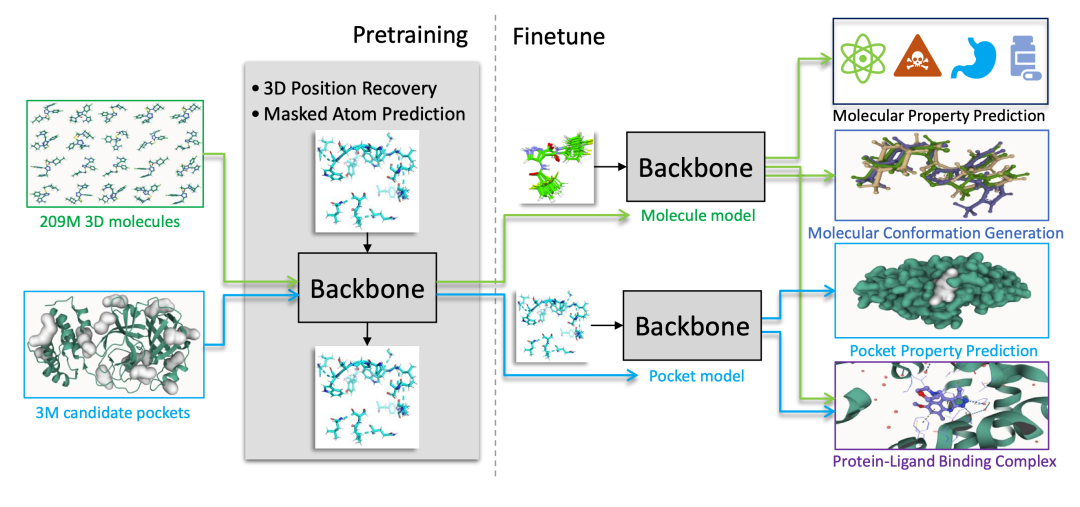
2. Uni-Mol: Ein allgemeines Lernframework zur dreidimensionalen Moleküldarstellung
Uni-Mol ist ein universelles 3D-Molekül-Pre-Training-Framework, das 2022 von DP Technology veröffentlicht wurde. Uni-Mol erweitert die Möglichkeiten der Moleküldarstellung durch groß angelegtes 3D-Molekülstruktur-Pre-Training und kann für Aufgaben wie Wirkstoffdesign, Vorhersage molekularer Eigenschaften und Modellierung von Protein-Ligand-Interaktionen eingesetzt werden.
Online ausführen:https://go.hyper.ai/RukIx
3. Bereitstellung von Mistral-Medium-3.5-128B mit einem Klick
Mistral Medium 3.5, veröffentlicht von Mistral AI im Jahr 2025, ist ein Flaggschiff-Fusionsmodell mit 128 Milliarden (128 B) Parametern und 256.000 Kontextfenstern. Es vereint Befehlsausführung, Inferenz und Programmierfunktionen in einem einzigen Gewichtungssatz. Dieses Modell ersetzte die Vorgängermodelle Mistral Medium 3.1 und Magistral sowie Devstral 2 im Programmieragenten Vibe.
Online ausführen:https://go.hyper.ai/PXiHc
4. OmniVoice: Unterstützt hochwertige TTS in über 600 Sprachen.
OmniVoice ist ein mehrsprachiges Text-to-Speech-Modell (TTS), das vom Next-Gen Kaldi-Team des Xiaomi AI Lab entwickelt wurde und hochwertige Sprachsynthese in über 600 Sprachen unterstützt. Basierend auf einer iterativen, unmaskierten Dekodierungsarchitektur implementiert das Projekt drei Kernfunktionen: Stimmklonierung, Stimmgestaltung und automatische Sprachausgabe.
Online ausführen:https://go.hyper.ai/7F7IR
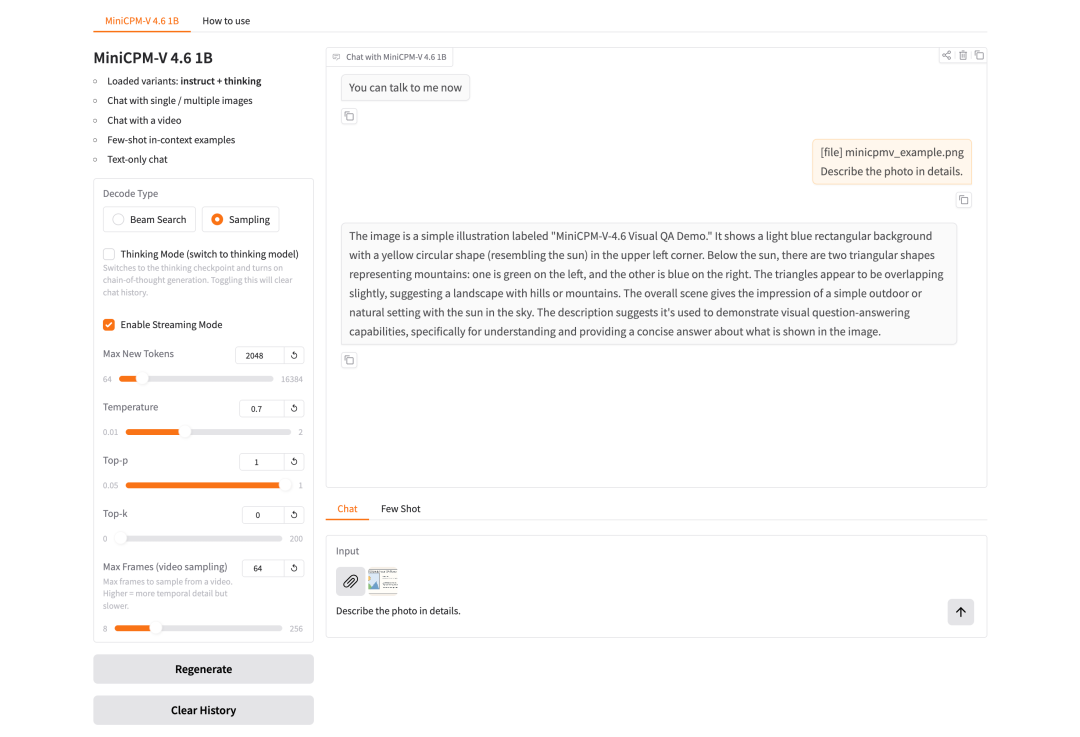
5. MiniCPM-V-4.6: Hocheffizientes multimodales visuelles Sprachmodell für Edge-Geräte
MiniCPM-V-4.6, veröffentlicht im Mai 2026 vom OpenBMB-Team und dem Natural Language Processing Laboratory der Tsinghua-Universität, ist ein effizientes, gerätebasiertes multimodales visuelles Sprachmodell für Bild- und Videoanalyse, visuelle Fragebeantwortung, OCR und mehrstufige multimodale Dialogszenarien. Sein Hauptvorteil liegt in der Abdeckung gängiger multimodaler Analyseaufgaben mit relativ geringer Modellgröße. Dadurch eignet es sich besonders für die Beantwortung von Bildfragen, die Zusammenfassung kurzer Videos, die Screenshot-Analyse, die Dokumentenbild-OCR und die Validierung mehrstufiger multimodaler Dialoge in ressourcenbeschränkten Umgebungen.
Online ausführen:https://go.hyper.ai/azdHU
6. LingBot-Map: Geometrischer Kontexttransformator für Streaming-3D-Rekonstruktion
LingBot-Map ist ein Streaming-3D-Rekonstruktionsprojekt, das vom Robbyant-Team im April 2026 veröffentlicht wurde. Das Projekt verarbeitet Bildsequenzen oder Videoframes und kann online 3D-Szenen rekonstruieren. Punktwolken, Kameratrajektorien und Einzelbildergebnisse lassen sich über einen 3D-Viewer im Browser betrachten.
Online ausführen:https://go.hyper.ai/BR4me

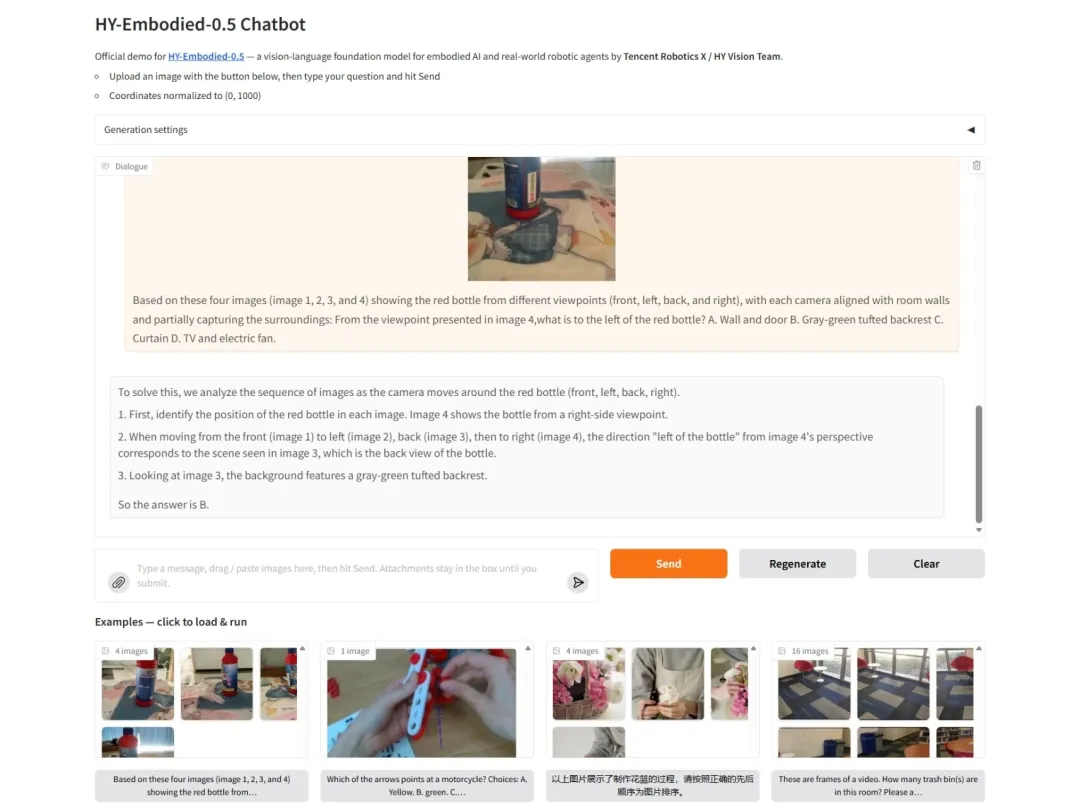
7. HY-Embodied-0.5: Ein verkörpertes Grundlagenmodell für intelligente Agenten in der realen Welt
HY-Embodied-0.5 ist ein speziell für verkörperte Intelligenz entwickeltes Basismodell, das im April 2026 vom Hunyuan-Team von Tencent und dem Tencent Robotics X Lab gemeinsam als Open Source veröffentlicht wurde. Diese Modellreihe stellt keine einfache Anpassung eines Standardmodells dar, sondern eine vollständige Neuentwicklung von der Architektur bis zum Trainingsparadigma. Das Team veröffentlichte gleichzeitig zwei Hauptmodelle: MoT-2B (4 Milliarden Parameter, 2 Milliarden Aktivierungen) mit Fokus auf Echtzeit-Reaktionen am Rand und MoE-32B (407 Milliarden Parameter, 32 Milliarden Aktivierungen) für maximale Inferenzleistung.
Online ausführen:https://go.hyper.ai/u8lJk
Interpretation von Gemeinschaftsartikeln
1. EnergAIzer, ein von MIT und anderen entwickeltes Framework zur GPU-Leistungsschätzung, führt Vorhersagen im Durchschnitt in 1,8 Sekunden mit einem Fehler von ungefähr 81 TP3T durch.
Forscher des MIT und des MIT-IBM Watson AI Lab haben EnergAIzer entwickelt, ein schnelles Framework zur GPU-Leistungsschätzung für KI-Workloads. Es liefert Hardware-Auslastungsinformationen direkt an die Leistungsmodelle, ohne dass aufwändige Simulationen oder Leistungsanalysen erforderlich sind. Das neue Framework führt die vollständige Leistungsschätzung in durchschnittlich nur 1,8 Sekunden durch. Auf NVIDIA Ampere GPUs erreicht EnergAIzer einen Leistungsfehler von etwa 81 TP3T, was mit herkömmlichen Modellen vergleichbar ist, die auf komplexen, zyklischen Simulationen oder Hardware-Leistungsanalysen basieren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/1PeMV
2. Der Tokenverbrauch sank um 30%. Eywa, ein heterogenes intelligentes Agenten-Framework, das von "Avatar" inspiriert wurde, kombiniert auf effiziente Weise Sprachmodelle mit domänenspezifischen Basismodellen.
Ein Forschungsteam der University of Illinois at Urbana-Champaign (UIUC) hat Eywa vorgestellt, ein Framework für heterogene Agenten, das Sprachagenten mit domänenspezifischen Basismodellen verbindet. Durch die Kombination domänenspezifischer Basismodelle mit Sprachmodellen entwickelten die Forscher den neuartigen EywaAgent. Dieser ermöglicht es dem Sprachagenten, die Denk-, Planungs- und Entscheidungsprozesse des Basismodells bei dessen spezialisierten Aufgaben zu steuern.
Den vollständigen Bericht ansehen:https://go.hyper.ai/CzRL4
3. Hundert Universitäten haben die weltweit größte Multikohorten-Proteogenomikstudie gestartet, um krankheitsverursachende Gene zu entschlüsseln und bestehende Medikamente auf der Grundlage von Daten von fast 80.000 Teilnehmern neu zu positionieren.
Ein Team aus über hundert Universitäten und Forschungseinrichtungen, darunter die Queen Mary University of London und die University of Cambridge, hat die bisher weltweit größte proteogenomische Studie mit mehreren Kohorten veröffentlicht. Basierend auf einer umfassenden Metaanalyse von Proteoglyphen aus 38 unabhängigen Forschungskohorten mit insgesamt 78.664 Teilnehmenden identifizierte die Studie systematisch 24.738 quantitative Merkmalsloci von Proteinen und ordnete diese 1.116 zirkulierenden Proteinen zu. Dadurch wurden die vielfältigen genetischen regulatorischen Merkmale der Nähe und Distanz auf Proteinebene umfassend aufgezeigt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/lGD68
Beliebte Enzyklopädieartikel
1. Weltmodelle
2. Kalibrierkurve
3. Gesteuerte Aufmerksamkeit
4. Der Mensch im Regelkreis
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








