Command Palette
Search for a command to run...
Mit DRiffusion Wird Eine 1,4- Bis 3,7-fache Beschleunigung Der Inferenz Erreicht, Um Den Engpass Der Abtastlatenz in Diffusionsmodellen Zu überwinden.

Im Bereich der generativen KI überwinden Diffusionsmodelle mit ihrem einzigartigen iterativen Entrauschungsmechanismus effektiv die Einschränkungen traditioneller Modelle hinsichtlich Generierungsqualität und -diversität und finden breite Anwendung in zukunftsweisenden Bereichen wie Bild-, Video- und Audioverarbeitung sowie Moleküldesign. Dieser zeitabhängige Verfeinerungsprozess erfordert jedoch typischerweise Dutzende oder sogar Hunderte von Iterationen, um hochpräzise Ergebnisse zu erzielen.Dies führt zu extrem langsamen Abtastgeschwindigkeiten und hohen Inferenzkosten.Dies hat sich zu einem zentralen Engpass für die Weiterentwicklung von Diffusionsmodellen hin zu Echtzeitanwendungen und großflächigem Einsatz entwickelt.
Um die Herausforderung des langsamen Samplings zu bewältigen, haben Forscher Beschleunigungsmethoden wie Rectified Flow und Distillation vorgeschlagen: Ersteres reduziert ungültige Iterationen durch Optimierung des Entrauschungspfads, während letzteres Wissensdestillation nutzt, um das Modell zu vereinfachen. Wenn jedoch die Anzahl der Sampling-Schritte drastisch reduziert wird, um eine hohe Beschleunigung zu erzielen,Beide Methoden beeinträchtigen die Qualität des Ergebnisses erheblich (z. B. durch Detailverlust und Unschärfe von Texturen), und die Destillation kann sogar die Vielfalt der Ergebnisse stark reduzieren.
Parallelisierungstechniken bieten zwar einen komplementären Ansatz ohne Qualitätseinbußen, doch sind bestehende Systemmethoden durch Modellarchitekturen (wie U-Net und Transformer) eingeschränkt, was ihre Vielseitigkeit mindert. Mathematische Methoden, die den Diffusionsprozess als Differentialgleichungen modellieren und effiziente Löser entwickeln, weisen oft eine geringe Kompatibilität mit gängigen Frameworks auf und neigen dazu, von der ursprünglichen Stichprobenverteilung abzuweichen. Keine dieser Lösungen überwindet die inhärente serielle Abhängigkeit von Diffusionsmodellen grundlegend – jeder Entrauschungsschritt hängt vom Ergebnis des vorherigen ab.
Um dieser Herausforderung zu begegnen, haben Forscher am MIT kürzlich das grundlegende Problem angegangen und mithilfe einer prägnanten mathematischen Entdeckung und eines innovativen Ablaufplanungsmodells erstmals den bisher ungenutzten intrinsischen Parallelismus innerhalb des Diffusionsrahmens aufgezeigt. Darauf aufbauendForscher haben das DRiffusion-Diffusionsmodell mit Entwurf und Verfeinerung vorgeschlagen.Durch die Kombination der Vorteile von Systemmethoden und mathematischen Methoden wird eine signifikante Beschleunigung erreicht, ohne die Generierungsqualität zu beeinträchtigen. Dies bietet eine neuartige Lösung für den Ausgleich zwischen hoher Wiedergabetreue und Abtasteffizienz in Diffusionsmodellen.
Die zugehörigen Forschungsergebnisse mit dem Titel „DRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
* Pionierarbeit am DRiffusion-Parallelframework „Entwurf-Verfeinerung“, das den inhärenten Parallelismus von Diffusionsmodellen aufzeigt.
* Bietet sowohl aggressive als auch konservative Beschleunigungsmodi und ermöglicht so einen flexiblen Kompromiss zwischen Qualität und Geschwindigkeit.
* Erreicht in Feldtests mit verschiedenen Modellen eine reale Beschleunigung um das 1,4- bis 3,7-Fache bei nahezu verlustfreier Erzeugungsqualität und umfassender Überlegenheit gegenüber bestehenden Methoden.

Papieradresse:
https://arxiv.org/abs/2603.25872
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „DRiffusion“, um das vollständige PDF zu erhalten.
MS-COCO-Datensatz: enthält 5.000 Bilder und 25.000 Beschreibungen.
Im Experiment wurde der MS-COCO 2017 Validierungsdatensatz als Benchmark-Datensatz verwendet, der 5.000 Bilder enthält.Jedem Bild sind fünf beschreibende Textzeilen beigefügt. Gemäß gängiger Praxis wird für die Auswertung der Bild-Text-Übereinstimmung nur die erste Beschreibungszeile jedes Bildes verwendet, um eine eindeutige Entsprechung zwischen dem generierten Bild und dem Referenztext zu gewährleisten und somit die Genauigkeit der Auswertung sicherzustellen.
Da herkömmliche Metriken die feinen visuellen Präferenzen nur unzureichend erfassen, werden in dieser Studie PickScore und Human Preference Score v2.1 (HPSv2.1) als ergänzende Bewertungsmethoden eingeführt. Zur Effizienzbewertung wurden bis zu vier NVIDIA V100 GPUs eingesetzt und die durchschnittliche Abtastlatenz in mehreren stationären Durchläufen gemessen. Die relative Beschleunigung gegenüber dem Diffusionsmodell mit einer einzelnen GPU sowie der durch die Methode verursachte zusätzliche Speicherbedarf werden angegeben.
Zum Vergleich mit der Baseline wurden zwei repräsentative Beschleunigungsmethoden für Diffusionsmodelle ausgewählt: Direct Skipping (d. h. Reduzierung der Anzahl der Abtastschritte) und AsyncDiff (Parallelisierung der Rauschunterdrückung durch Verteilung von Teilnetzwerken auf verschiedene Geräte und asynchrone Abtastung). Um die Konsistenz der Auswertung zu gewährleisten, reproduzierten die Forscher die experimentellen Ergebnisse anhand der offiziellen Implementierung von AsyncDiff unter denselben Messbedingungen.
DRiffusion: Diffusionsmodelle durch einen Entwurfs- und Verfeinerungsprozess einfach parallelisieren
Das Design von DRiffusion basiert auf einer grundlegenden Frage: Kann ein Diffusionsmodell gleichzeitig Rauschvorhersagen für mehrere Zeitschritte berechnen? Im ursprünglichen Diffusionsmodell ist dieses Ziel direkt schwer zu erreichen, da jeder Entrauschungsschritt vom Ausgabezustand des vorherigen Schritts abhängt.Überspringbare Übergänge bieten eine neue Perspektive zur Überwindung dieser Einschränkung:Wenn die Skip-Operation als unabhängig aufrufbarer lokaler Operator betrachtet werden kann, dann können Zwischenzustände direkt konstruiert werden, ohne die gesamte Trajektorie zu durchlaufen, wodurch eine parallele Berechnung über die Zeitschritte hinweg erreicht wird.
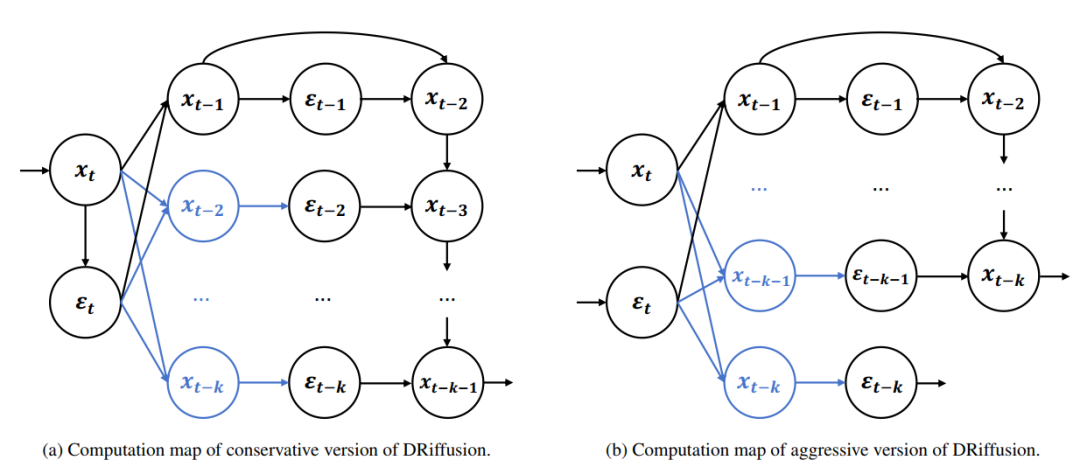
Das Konzept der Sprungübergänge ist nicht neu. Wie die Abbildung unten zeigt, lässt sich die Systemdynamik aus der Perspektive einer kontinuierlichen Zeit über ein längeres Zeitintervall integrieren, und das Überspringen von Zwischenschritten ist eine natürliche Vorgehensweise. Aktuell jedoch…Diffusionsmodell-Frameworks nutzen diesen Freiheitsgrad typischerweise nur auf globaler Ebene (z. B. durch Neuwahl der Zeitschrittsequenz).Es fehlt ein schrittweiser Mechanismus, der lokal aufgerufen und bei Bedarf eingesetzt werden kann.

zu diesem Zweck,DRiffusion wandelt zunächst den Sprungübergang in einen Operator um.Insbesondere für gängige Diffusionsmodelle wie DDPM, DDIM und Löser, die auf gewöhnlichen Differentialgleichungen (ODE) basieren, wird eine einheitliche Sprungübergangsformel abgeleitet, die eine direkte Verbindung zwischen beliebigen zwei Diffusionszuständen ermöglicht, ohne dass der globale Zeitschrittplan neu definiert werden muss.
Am Beispiel von DDPM lässt sich zeigen, dass der Übergang vom aktuellen Zustand x_t zum zukünftigen Zustand x_t-k eine geschlossene Lösung besitzt; DDIM kann ebenfalls auf Basis der Konsistenz der Randverteilung verallgemeinert werden; und bei der Modellierung gewöhnlicher Differentialgleichungen entspricht das Überspringen von Zwischenschritten der direkten Verwendung einer größeren numerischen Integrationsschrittweite. Die Einführung dieses Operators verbessert die Flexibilität der Abtastmustergestaltung erheblich und legt den Grundstein für die spätere Parallelisierung.
Basierend auf dem SprungübergangsoperatorDer Kern-Workflow von DRiffusion lässt sich in zwei Phasen zusammenfassen: Entwurfserstellung und Verfeinerung.Ausgehend vom Zustand x_t zum Ankerzeitschritt t werden die Zustände für die folgenden k Zeitschritte parallel mittels Sprungübergängen generiert, um Entwurfsschätzungen zu erhalten. Aufgrund der erhöhten Schrittweite ist die Genauigkeit dieser Entwürfe etwas geringer als die der nachfolgenden Iterationen, die Gesamtergebnisse stimmen jedoch weiterhin mit der ursprünglichen, entrauschten Trajektorie überein.
Anschließend werden diese Entwürfe parallel in den Rauschprädiktor eingespeist, um die entsprechenden Rauschschätzungen zu erhalten. Danach werden standardmäßige Entrauschungsaktualisierungen durchgeführt, um jeden Entwurf zu verfeinern. Schließlich werden der verfeinerte Zustand und sein zugehöriges Rauschen ermittelt, die als Ankerpunkt für die nächste Iteration dienen.
Dieses Design birgt ein potenzielles Problem: Eine große Sprungschrittweite kann aufgrund von Ungenauigkeiten in der Rauschvorhersage zu einer verminderten Generierungsqualität führen. Bisherige Forschungsergebnisse haben dieses Risiko zwar bereits aufgezeigt, unsere experimentellen Beobachtungen zeigen jedoch zwei mildernde Faktoren.Erste,Eine leichte Verschlechterung der wahrgenommenen Qualität bedeutet nicht zwangsläufig eine signifikante Verringerung der Darstellungsfähigkeit; die generierten Bilder oder latenten Vektoren behalten typischerweise den größten Teil der zugrunde liegenden semantischen und strukturellen Informationen.zweite,Obwohl der Rauschprädiktor nicht perfekt genau ist, reicht seine Generalisierungsfähigkeit aus, um plausiblen Stichprobenumgebungen plausible Ergebnisse zuzuordnen. Aus diesen beiden Gründen liefert DRiffusion auch bei großer Schrittweite noch ausreichend hochwertige Bilder.
Hinsichtlich der Implementierung umfasst DRiffusion zwei Versionen: eine radikale und eine konservative.
Wie in der Abbildung unten dargestellt, parallelisiert die radikale Version mehrere Rauschvorhersagen vollständig in einer Iteration. Unter der Annahme, dass geringfügiger Overhead wie die Kommunikation vernachlässigt wird, kann die ideale Beschleunigung den Faktor k erreichen, d. h. die Laufzeit reduziert sich auf 1/k der ursprünglichen Laufzeit.
Die konservative Version berechnet zunächst unabhängig ein hochpräzises Stromrauschen (generiert aus dem verfeinerten Zustand) und nutzt dieses anschließend als Grundlage, um den Prozess der aggressiven Version zu reproduzieren. Dabei wird ein zusätzlicher Zeitschritt hinzugefügt, wodurch eine ideale Beschleunigung um den Faktor 2k+1 erreicht wird. Der Kerngedanke beider Versionen ist derselbe: Ein Entwurf wird gegen parallele Rechenleistung eingetauscht, und die Verfeinerung dient der Sicherstellung der Ausgabequalität.
Auf 3 GPUs wurde eine nahezu dreifache Beschleunigung in der Praxis erzielt.
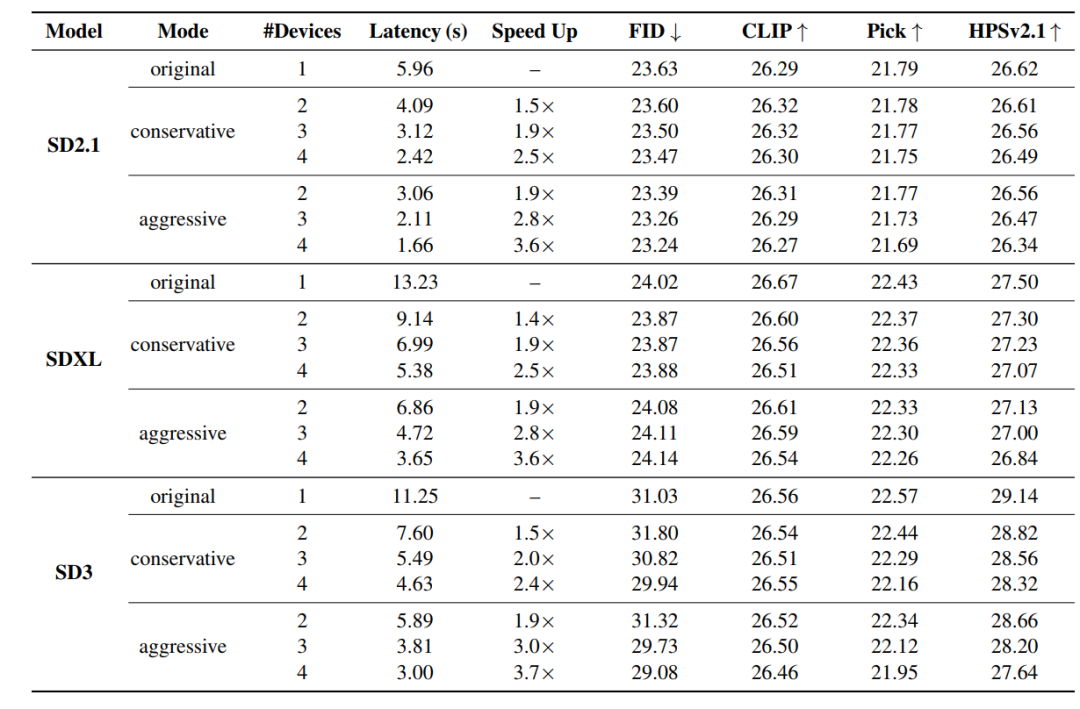
Um die Leistungsfähigkeit von DRiffusion zu überprüfen, wurden Experimente mit Diffusionsmodellen verschiedener Architekturen und Skalen durchgeführt, darunter Stable Diffusion 2.1 (SD2.1) basierend auf U-Net, Stable Diffusion XL (SDXL) basierend auf U-Net und Stable Diffusion 3 (SD3) basierend auf Transformer für Flow Matching. Diese breite Modellauswahl ermöglicht nicht nur einen fairen Vergleich mit bestehenden Methoden, sondern testet auch umfassend die Allgemeingültigkeit des Verfahrens.
Die qualitativen Ergebnisse sind in der folgenden Abbildung dargestellt. Bei hohen BeschleunigungsverhältnissenWährend DRiffusion Schwierigkeiten hat, die pixelgenaue Ausgabe des Ausgangsmaterials vollständig zu reproduzieren, wird die semantische Konsistenz konsequent aufrechterhalten und feine Details (wie die Holzstruktur und Glanzlichter auf der Brust einer Katze) effektiv bewahrt.Durch das moderate Überspringen einiger Rauschabtastschritte kann die beschleunigte Version mitunter Bilder mit stärkerem Kontrast und schärferen Details (wie z. B. Katzenaugenreflexionen) erzeugen. Eine aggressive Beschleunigung (nahezu 4x) kann zu geringfügigen Qualitätseinbußen wie Farbübersättigung oder kleineren Artefakten führen, die hohe Übereinstimmung mit dem Ausgangsbild bleibt jedoch insgesamt erhalten.

Die quantitativen Ergebnisse sind in der folgenden Tabelle dargestellt.Bei allen Konfigurationen liegt der FID-Wert sehr nahe am Ausgangswert, und die maximale Abnahme des CLIP-Scores überschreitet nicht 0,16.In einigen Szenarien verbesserte sich die FID leicht, hauptsächlich aufgrund statistischer Schwankungen und weniger aufgrund methodischer Verbesserungen. Ergänzende Auswertungen von PickScore und HPSv2.1 zeigen durchschnittliche Rückgänge von 0,17 bzw. 0,43. Die einzige Ausnahme bildet SD3 im aggressiven 4-Geräte-Modus, wo HPSv2.1 um 1,50 sank. Dies liegt daran, dass SD3 standardmäßig nur 28 Abtastschritte durchführt und die extreme Schrittweite den Approximationsfehler verstärkt. Angesichts der Stabilität der vier Metriken und der signifikanten Geschwindigkeitssteigerungen ist diese Qualitätsminderung akzeptabel.
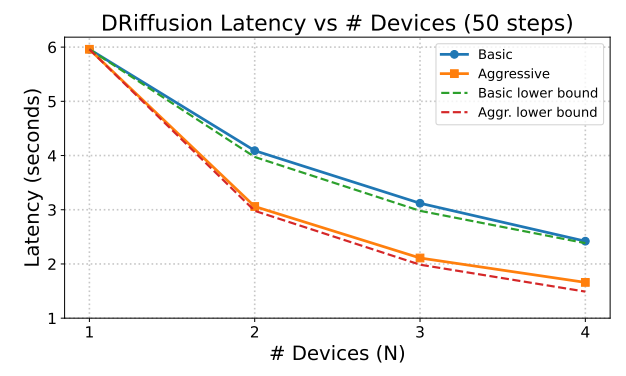
Hinsichtlich der Beschleunigungsleistung,Die tatsächliche Beschleunigung liegt zwischen dem 1,4- und 3,7-Fachen, und der gesamte Rechenaufwand pro Stichprobe ist nahezu derselbe wie beim ursprünglichen Modell.Experimentelle Daten zeigen, dass die Verzögerungsskalierung des aggressiven Modus nahe an der theoretischen unteren Grenze O(1/N) liegt, während der konservative Modus sehr gut mit O(2/(N+1)) übereinstimmt. Dies beweist, dass DRiffusion eine effiziente und skalierbare Parallelisierung erreicht.
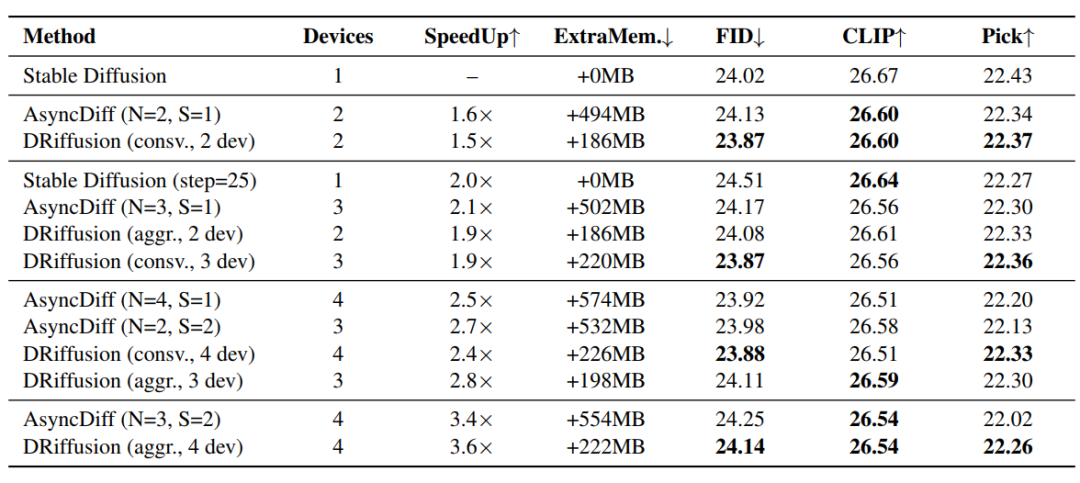
Die Ergebnisse des Methodenvergleichs sind in der folgenden Tabelle dargestellt.In allen Speedup-Gruppen übertraf DRiffusion AsyncDiff und die einfache Skip-Baseline hinsichtlich der Generierungsqualität.Durch die Verwendung von PickScore als zentralem Messwert, das empfindlicher auf Beschleunigung reagiert, konnte DRiffusion die Leistungseinbußen im Durchschnitt um 48,61 TP3T reduzieren, mit einer maximalen Reduzierung von 58,51 TP3T bei vier Geräten. Der Beschleunigungseffekt korreliert nahezu linear mit der Anzahl der Geräte, und das Beschleunigungsverhältnis ist vergleichbar mit oder sogar etwas besser als das von AsyncDiff bei einer ähnlichen Anzahl von Geräten.
Der Vorteil hinsichtlich der Speichereffizienz ist deutlicher: AsyncDiff benötigt bis zu 574 MB zusätzlichen Speicher, wobei der Bedarf mit der Anzahl der Geräte steigt, während DRiffusion lediglich einen stabilen Overhead von 186–226 MB verursacht. Verglichen mit dem SDXL-Basisspeicherbedarf von ca. 13 GB ist dieser Overhead vernachlässigbar. Bei einer Batchgröße von 5 traten bei AsyncDiff auf einem 32-GB-Knoten Speicherengpässe auf, während DRiffusion normal funktionierte.Der Grund dafür ist, dass DRiffusion lediglich den Sampling-Iterationsprozess modifiziert und ihn somit von der Modellstruktur und der Kernberechnung entkoppelt.
Zusammenfassend:DRiffusion erzielt auf 3 GPUs eine nahezu dreifache Beschleunigung bei gleichbleibender Generierungsqualität und feinkörnigen Details, wodurch die Inferenzgeschwindigkeit deutlich verbessert wird.Durch die Kombination prägnanter theoretischer Merkmale mit praktischer paralleler Implementierung wurden qualitativ hochwertige und stabile experimentelle Ergebnisse erzielt.
Die Parallelisierung von Diffusionsmodellen beschleunigt den Prozess
Die Parallelisierung von Diffusionsmodellen hat sich weltweit zu einem zentralen Forschungsschwerpunkt in Wissenschaft und Industrie entwickelt. Zahlreiche führende Institutionen haben in diesem Bereich bahnbrechende Fortschritte erzielt. Das gemeinsam vom MIT und der Universität Hongkong entwickelte Fast-dLLM erreicht eine 27,6-fache Beschleunigung der gesamten Laufzeit von groß angelegten Diffusionssprachmodellen (z. B. für die Generierung langer Texte) ohne erneutes Training des Modells und hält den Genauigkeitsverlust innerhalb von 21 TP3T.
Titel des Papers: FAST-DLLM V2: Effizientes Block-Diffusions-LLM
Link zum Artikel:https://arxiv.org/pdf/2509.26328
Das von der UC Berkeley entwickelte Streaming-System StreamDiffusionV2 integriert einen SLO-fähigen Batch-Scheduler und einen bewegungsabhängigen Rauschregler für Videodiffusionsmodelle. Dadurch wird die Bildrate der Videogenerierung in einer Multi-GPU-Umgebung auf 58 FPS erhöht und der Engpass der Rechenleistung bei der Echtzeitgenerierung überwunden.
Titel des Papers: StreamDiffusionV2: Ein Streaming-System zur dynamischen und interaktiven Videogenerierung
Link zum Artikel:https://arxiv.org/abs/2511.07399
Im Unternehmensbereich hat NVIDIA Parallelisierungstechnologie tief in sein Hardware- und Software-Ökosystem integriert. Durch die Optimierung von Rechenpfaden und die Zusammenarbeit mehrerer Geräte wird die Inferenzgeschwindigkeit von Diffusionsmodellen deutlich verbessert und der Rechenaufwand bei der Bild- und Videogenerierung reduziert. Stability AI hingegen erforscht parallele Sampling-Strategien in seiner Stable Diffusion-Modellreihe. Durch die Optimierung von Batch-Verarbeitungsparametern und die Aktivierung von Samplern, die Parallelverarbeitung unterstützen, wie DDIM und PLMS, wird die Effizienz der Bildgenerierung um das Drei- bis Fünffache gesteigert, ohne die Qualität zu beeinträchtigen.
Zusammenfassend lässt sich sagen, dass die gemeinsamen Anstrengungen von Wissenschaft und Industrie die Parallelisierung von Diffusionsmodellen zu einem zentralen Thema für technologische Durchbrüche gemacht haben. DRiffusion hat als typische Lösung die Machbarkeit und Effizienz der Nutzung inhärenter Parallelität unter Beweis gestellt. Zukünftig werden Diffusionsmodelle durch die enge Zusammenarbeit von Hardware und Algorithmen voraussichtlich eine Echtzeitgenerierung bei gleichzeitig hoher Genauigkeit ermöglichen und so Effizienzbarrieren für die breitere Anwendung von KI überwinden.
Referenzlinks:
1.https://mp.weixin.qq.com/s/70OiIuuNP2PWgIV_hiRZBQ








