Command Palette
Search for a command to run...
MOSS-TTS: Ein Entkoppeltes, Produktionsreifes Sprachgenerierungsmodell Basierend Auf Der CAT-Architektur; Überwindung Der Barriere Der Einzelzellanalyse: Erstellung Eines Benchmarks Für Einen Krebsübergreifenden Immunatlas Unter Verwendung Des Pan-Cancer scRNA-Seq-Datensatzes.

Aktuell erweisen sich einzelne Sprachgenerierungsmodelle angesichts komplexer Anforderungen aus der Praxis als unzureichend. In der Praxis muss eine Sprache nicht nur eine bestimmte Klangfarbe originalgetreu wiedergeben, sondern auch den Sprechstil je nach Inhalt natürlich anpassen und über mehrere Minuten hinweg stabil bleiben. Darüber hinaus muss sie verschiedene Formate wie Dialoge, Rollenspiele und Echtzeitinteraktion unterstützen. Diese Anforderungen übersteigen die Möglichkeiten eines einzelnen Modells bei Weitem.
In diesem ZusammenhangMOSI.AI und OpenMOSS haben die MOSS-TTS-Familie von Sprachgenerierungsmodellen veröffentlicht.Anstatt eines einzigen, umfangreichen Modells entkoppelt diese Modellfamilie den Sprachgenerierungs-Workflow in fünf produktionsreife Modelle, darunter das hochauflösende Sprachmodell MOSS-TTS und das Mehrsprecher-Dialogmodell MOSS-TTSD. Die Kerntechnologie basiert auf dem 1,6 Milliarden Parameter umfassenden Audio-Tokenizer MOSS Audio-Tokenizer und nutzt eine reine Transformer-Architektur (CAT, Causal Audio Tokenizer with Transformer) für eine hochpräzise Audiorekonstruktion. Diese Modellreihe löst zahlreiche Anwendungsherausforderungen in komplexen Szenarien und bietet eine Toolchain für die Sprachgenerierung, die sich direkt in den Authoring-Workflow integrieren lässt.
Auf der HyperAI-Website wird jetzt „MOSS-TTS: Ein hochpräzises Sprachgenerierungsmodell für verschiedene Szenen“ vorgestellt. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/AtKvk
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 2. bis 6. März:
* Hochwertige öffentliche Datensätze: 3
* Hochwertige Tutorial-Auswahl: 8
* Interpretation von Community-Artikeln: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im März: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz zur Erkennung von Drohnengeräuschen
Dieser Datensatz enthält Audioaufnahmen zweier Kategorien: unbekannte Geräusche und Drohnengeräusche. Er dient der binären Audioklassifizierung und der Erkennung von Drohnengeräuschen in realen Umgebungen. Die Audiodateien liegen in Standardformaten (z. B. WAV) vor und eignen sich für Vorverarbeitungstechniken wie die Extraktion von Mel-Spektrogrammen, die MFCC-Merkmalsextraktion, die Kurzzeit-Fourier-Transformation (STFT) und Deep-Learning-Modelle der Rohsignalformen.
Direkte Verwendung:https://go.hyper.ai/vKHJC
2. Datensatz zur Simulation unerwünschter Arzneimittelwirkungen
Dieser Datensatz simuliert Pharmakovigilanzberichte über unerwünschte Arzneimittelwirkungen (UAW) und dient der Unterstützung von Forschung, maschinellem Lernen und der Entwicklung von Algorithmen im Bereich der Arzneimittelsicherheitsüberwachung. Die Fallberichte (ICSRs) werden künstlich generiert und sind von realen Pharmakovigilanzsystemen wie FDA FAERS und EMA EudraVigilance inspiriert.
Direkte Verwendung:https://go.hyper.ai/Jex4v
3. Pan-Cancer scRNA-Seq Einzelzell-Transkriptionsatlas-Datensatz
Dieser Datensatz enthält Transkriptom-Expressionsdaten von 7.930 Einzelzellen aus drei verschiedenen biologischen Zuständen: gesunde Immunantwort, flüssiger Tumor (myeloische Leukämie) und solides Tumormikromilieu (Melanom). Ziel ist die Entwicklung eines Benchmarks für die kohortenübergreifende, integrierte Einzelzellanalyse. Dieser Benchmark dient der Bewertung der Algorithmenleistung und dem methodischen Vergleich, der Korrektur von Batch-Effekten in mehreren Kohorten, der Analyse des Immunerschöpfungszustands und der Identifizierung tumorübergreifender Biomarker.
Direkte Verwendung:https://go.hyper.ai/CnZTc
Ausgewählte öffentliche Tutorials
1. ACE-Schritt 1.5: Demo zur Musikgenerierung
ACE-Step 1.5 ist ein Open-Source-Musikgenerierungsmodell, das von ACE Studio und StepFun gemeinsam entwickelt wurde und die Grenzen der Open-Source-Musikgenerierung erweitern soll. Dieses Modell nutzt eine innovative zweistufige Generierungsarchitektur und erzielt durch die Integration eines Diffusion Transformers (DiT) und eines Sprachmodells (LM) die Generierung hochwertiger, lang anhaltender Musikinhalte.
Online ausführen:https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B: Ein Spracherkennungssystem der neuen Generation
Qwen3-ASR ist eine neue Generation von Open-Source-ASR-Modellen (Automatische Spracherkennung), die vom Tongyi-Qianwen-Team von Alibaba Cloud entwickelt wurde. Basierend auf dem multimodalen Basismodell Qwen3-Omni und einem eigens entwickelten AuT-Sprachcodierer (Automatische Spracherkennung) konzentriert sich dieses Modell auf hochpräzise, mehrsprachige und lange Audiodatensätze sowie auf die einheitliche Transkription von Sprache in Text – sowohl im Streaming- als auch im Non-Streaming-Verfahren. Das Modell verarbeitet Rohaudiosignale und wandelt diese mithilfe einer End-to-End-Architektur direkt in strukturierten Text um. Dabei wird die Ausrichtung auf Zeichen-/Wortebene mit Millisekunden-Zeitstempeln unterstützt. Qwen3-ASR eignet sich für zahlreiche Anwendungsfälle wie die Transkription von Besprechungen, intelligente Untertitelung, die Archivierung von Kundenservice-Sprachaufzeichnungen und die dialektbasierte Sprachinteraktion.
Online ausführen:https://go.hyper.ai/zb0Vi

3.Bereitstellung von vLLM+Open WebUI mit Qwen3-Coder-Next
Qwen3-Coder-Next ist ein schlankes, von Tongyi Qianwen (Alibaba Cloud) als Open Source entwickeltes Code-Generierungsmodell, das sich auf die Unterstützung von Programmieraufgaben in allen Szenarien und die Code-Generierung konzentriert. Seine Kernvorteile sind hohe Leistung, geringer Einstieg und einfache Implementierung. Basierend auf der optimierten Architektur des Qwen3-Sprachmodells integriert es vortrainierte, domänenspezifische Daten (über 80 gängige Programmiersprachen und mehr als eine Milliarde Code-Snippets) sowie RLHF-Code-Alignment-Optimierung (Human Feedback Reinforcement Learning). Es erzielte Spitzenleistungen unter den Open-Source-Modellen in den drei maßgeblichen Code-Benchmarks HumanEval+, MBPP und MultiPL-E und erreichte eine Performance, die der von CodeLlama-70B nahekommt. Es eignet sich für verschiedene Programmierszenarien, darunter Algorithmenentwicklung, Geschäftscode-Generierung, Code-Kommentierung, sprachübergreifende Code-Konvertierung und Fehlerbehebung.
Online ausführen:https://go.hyper.ai/ukxPt
4. VibeVoice-ASR: Multifunktionale End-to-End-Spracherkennungsdemo
VibeVoice-ASR ist ein leistungsstarkes, multifunktionales End-to-End-Spracherkennungsmodell (ASR) von Microsoft, das als Open Source entwickelt wurde und strukturierte, kontextbezogene Spracherkennungsdienste für lange Audiodateien bietet. Das Modell verwendet eine fortschrittliche, einheitliche Audiomodellierungsarchitektur und kann Audiodateien mit einer Länge von bis zu 60 Minuten verarbeiten. Es generiert strukturierte Ausgaben mit Sprecheridentität (Wer), Zeitstempeln (Wann) und transkribiertem Inhalt (Was) und ermöglicht es Nutzern, Kontextinformationen zur Verbesserung der Erkennungsgenauigkeit bereitzustellen. Die technologischen Innovationen liegen in der effizienten Modellierung langer Sequenzen und dem sprachübergreifenden Multitasking-Lernmechanismus. Dadurch werden die Probleme der zeitlichen Ausrichtung und der semantischen Kohärenz herkömmlicher ASR-Modelle bei der Verarbeitung langer Audiodateien vollständig gelöst.
Online ausführen:https://go.hyper.ai/8eMFX
5. MOSS-TTS: Ein hochpräzises Sprachgenerierungsmodell für mehrere Szenen
Die MOSS-TTS-Serie ist eine Open-Source-Sprachgenerierungsmodellreihe, die von MOSI.AI und dem OpenMOSS-Team entwickelt wurde. Wenn ein einzelnes Audiosegment natürlich klingen soll – mit präziser Aussprache jedes Wortes, wechselndem Sprechstil je nach Inhalt, stabiler Wiedergabe über mehrere Minuten und Unterstützung von Dialogen, Rollenspielen und Echtzeitinteraktion –, stößt ein einzelnes TTS-Modell oft an seine Grenzen. Daher entkoppelt dieses Projekt den Sprachgenerierungs-Workflow in fünf produktionsreife Modelle, die unabhängig voneinander oder kombiniert verwendet werden können: das MOSS-TTS-Basismodell, das mehrsprachige Dialogmodell MOSS-TTSD, das Sprachdesignmodell MOSS-VoiceGenerator, das Modell zur Generierung von Soundeffekten MOSS-SoundEffect und das Echtzeitinteraktionsmodell MOSS-TTS-Realtime. Diese Serie unterstützt 20 Sprachen und befasst sich in erster Linie mit Herausforderungen realer Anwendungen wie der hochpräzisen Zero-Sample-Sprachklonierung, der stabilen Synthese langer Texte von bis zu einer Stunde Länge, der mehrsprachigen und gemischten chinesisch-englischen Generierung sowie der fein abgestuften Dauer- und Phonem-Aussprachesteuerung in komplexen Szenarien.
Online ausführen:https://go.hyper.ai/AtKvk
6.Z-Image: Alibabas Open-Source-Textbildmodell mit 6 Milliarden Parametern
Z-Image ist ein hocheffizientes Bildgenerierungsmodell der neuen Generation, entwickelt vom Tongyi Qianwen Team von Alibaba Cloud. Nachdem die optimierte Version Z-Image-Turbo zum führenden Open-Source-Modell in der Liste der künstlichen Bildanalysen avancierte, veröffentlichte das Z-Image-Team die Standardversion offiziell als Open Source. Als zentrales Basismodell der Z-Image-Serie bietet die Standardversion ein vollständiges, unverändertes Modell, das sich durch hohe Generierungsqualität, vielfältige Stile und umfassende Unterstützung für die Weiterentwicklung auszeichnet. Ziel ist es, Entwicklern eine leistungsstarke und flexible Grundlage für die Bildgenerierung zu bieten und so mehr Möglichkeiten für individuelle Anpassungen und Feinabstimmungen zu eröffnen.
Online ausführen:https://go.hyper.ai/SsDMv
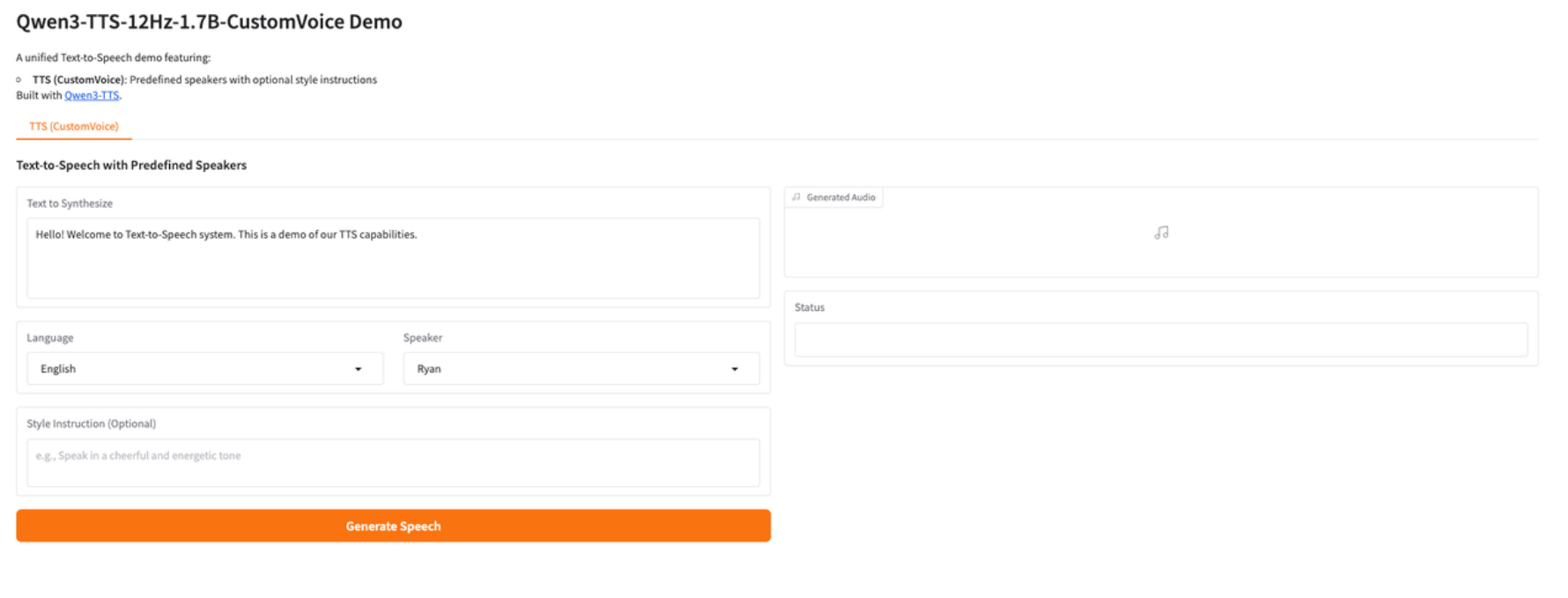
7. Qwen3-TTS: Hochwertige, steuerbare mehrsprachige Sprachsynthese-Demo
Qwen3-TTS-12Hz-1.7B-CustomVoice ist ein neues, hochwertiges Text-to-Speech-Modell (TTS), entwickelt vom Alibaba Tongyi Team. Dieses Modell konzentriert sich auf mehrsprachige Sprachsynthese, die Steuerung mehrerer Sprecher (Custom Voice), textbasierte Stil- und Emotionsanpassung sowie die Generierung von natürlicher Sprache mit geringer Latenz in einem einzigen, einheitlichen Framework. Basierend auf einem 12-Hz-Akustikmodell mit 1,7 Milliarden Parametern erzielt das Modell hervorragende Ergebnisse in Bezug auf Sprachverständlichkeit, prosodische Konsistenz und sprachübergreifende Stabilität. Durch die Einführung des CustomVoice-Mechanismus kann das Modell während der Inferenzphase ohne zusätzliches Training direkt zwischen voreingestellten Sprechern wechseln und in Kombination mit Anweisungen zum natürlichen Sprachstil eine differenziertere Ausdruckskontrolle erreichen.
Online ausführen:https://go.hyper.ai/xWsQ6
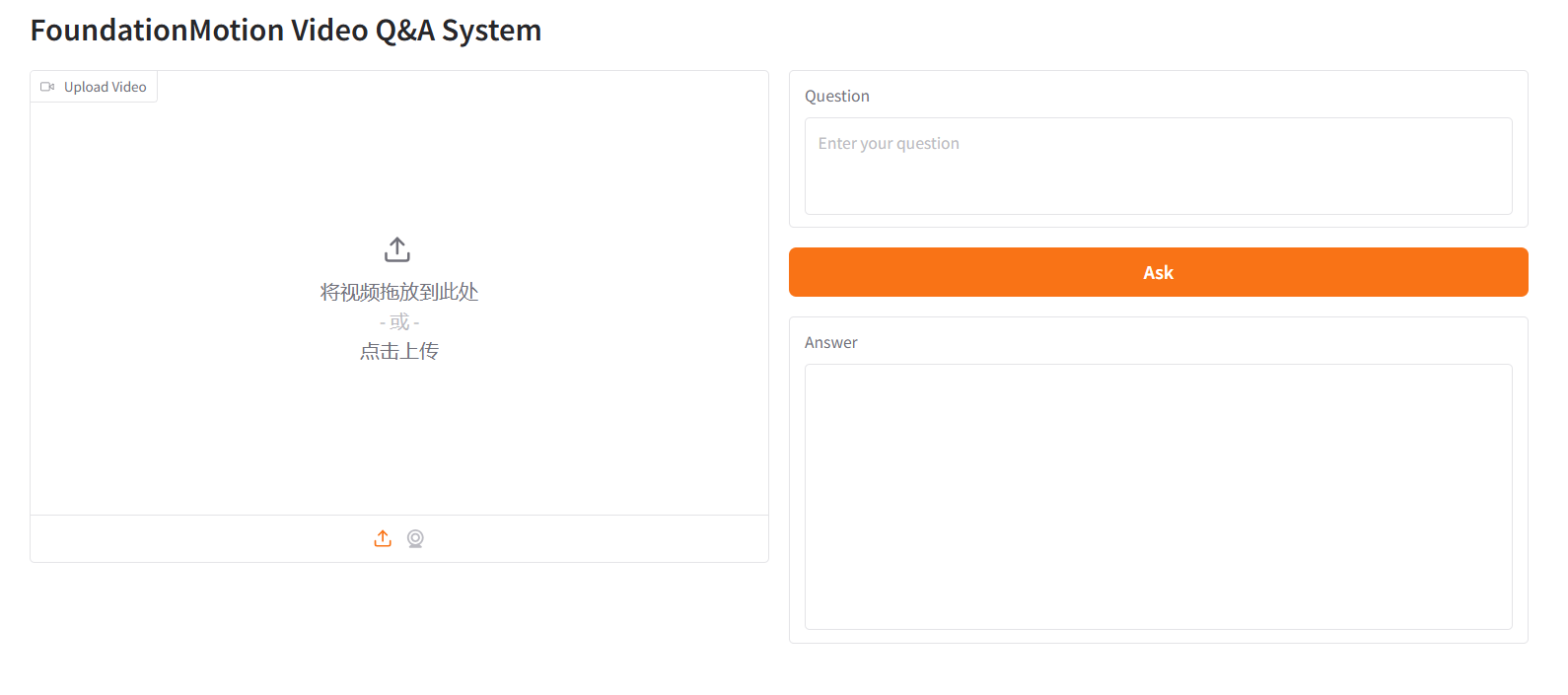
8. FoundationMotion Video-Frage-und-Antwort-System
FoundationMotion ist ein von NVIDIA und dem MIT gemeinsam entwickeltes System zur Videoanalyse und Fragebeantwortung, das auf dem feinabgestimmten Modell Qwen2.5-VL basiert. Es dient dem Verständnis und der Interpretation räumlicher Bewegungen in Videos. Durch die Integration von Vortrainingstechnologien für visuelle Sprache kann das Modell hochgeladene Videoinhalte intelligent analysieren und entsprechende Fragen beantworten.
Online ausführen:https://go.hyper.ai/JlGZk
Interpretation von Gemeinschaftsartikeln
1. Die Grenzen der traditionellen multimodalen Integration werden durchbrochen! Das MIT präsentiert das APOLLO-Framework, das eine klare Trennung von zellübergreifenden und zellspezifischen Informationen ermöglicht.
Angesichts der kontinuierlichen Weiterentwicklung der Einzelzelltechnologie und des rasanten Datenwachstums ist die effiziente und automatische Integration multimodaler Daten bei gleichzeitiger klarer Trennung von gemeinsamen und modalitätsspezifischen Informationen zu einer zentralen Herausforderung der Einzelzellbiologie geworden. Um dieser Herausforderung zu begegnen, hat ein gemeinsames Forschungsteam des MIT und der ETH Zürich mit APOLLO (Autoencoder with a Partially Overlapping Latent Space Learned through Latent Optimization) ein allgemeines Deep-Learning-Framework entwickelt. Dieses Framework bietet einen praktikablen technischen Weg für eine umfassendere und präzisere Analyse von Zellzuständen und ihrer Regulationslogik durch die explizite Modellierung gemeinsamer und modalitätsspezifischer Informationen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/jaCKf
2. Online-Tutorial | Basierend auf 5 Millionen Stunden Sprachdaten erreicht Qwen3-TTS eine 3-Sekunden-Stimmklonierung und -Feinabstimmung.
Wenn generative KI nicht mehr nur „Text generiert“, sondern tatsächlich „Klang erzeugt“, wandelt sich Sprache von einem reinen Informationskanal zu einem programmierbaren und formbaren Ausdrucksmittel. Auf diesem technologischen Entwicklungspfad versucht die neue Generation von Modellen, die Grenzen traditioneller Sprachausgabesysteme (TTS) zu überwinden – nicht nur durch höhere Wiedergabetreue, sondern auch durch mehrsprachige Generalisierung und präzise Steuerung. Qwen3-TTS, kürzlich vom Qwen-Team als Open Source veröffentlicht, basiert auf einer zweigleisigen Sprachmodellarchitektur (LM), die eine präzise Steuerung der Sprachausgabe bei gleichzeitiger Echtzeitsynthese ermöglicht.
Den vollständigen Bericht ansehen:https://go.hyper.ai/eKr7T
3. Das MIT entwickelt ein Pichia-CLM-Modell, um die "Sprache" der Hefe-DNA zu erlernen und so möglicherweise die Produktion exogener Proteine um das Dreifache zu steigern.
Aktuell werden in der Industrie verschiedene Codon-Optimierungswerkzeuge und -methoden auf Basis von Wirts-CUBs entwickelt. Diese Methoden führen jedoch nicht immer zu hoch exprimierten Konstrukten. In den letzten Jahren haben Forscher mit der Entwicklung künstlicher Intelligenz, insbesondere der Sequenzmodellierungstechnologie, begonnen, Gensequenzen als eine Art „Sprache“ zu betrachten und versuchen, die darin enthaltenen impliziten Regeln mithilfe von Methoden ähnlich der natürlichen Sprachverarbeitung zu erlernen. Vor diesem Hintergrund hat ein Forschungsteam des MIT das auf Deep Learning basierende Sprachmodell Pichia-CLM zur Codon-Optimierung im industriellen Wirt Pichia pastoris vorgeschlagen, um die Ausbeute rekombinanter Proteine zu verbessern.
Den vollständigen Bericht ansehen:https://go.hyper.ai/a4H2G
Beliebte Enzyklopädieartikel
1. Visuelles Sprachmodell (VLM)
2. Hypernetzwerke
3. Gesteuerte Aufmerksamkeit
4. Menschliche Interaktion (Human-in-the-Loop, HITL)
5. Neuronales Strahlungsfeld (NeRF)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
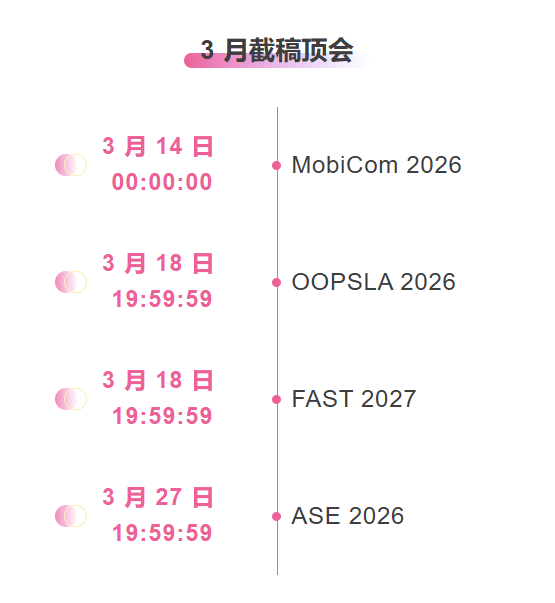
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








