Command Palette
Search for a command to run...
Künstliche Intelligenz Hat 118 Neue Exoplaneten Entdeckt! Ein Team Der Universität Warwick Hat RAVEN Entwickelt, Das Einen Direkten Vergleich Von Planetenszenarien Mit Jedem falsch-positiven Szenario ermöglicht.

Dank des stetigen Fortschritts in der astronomischen Forschung hat die Entdeckung von Exoplaneten eine Phase rasanter Entwicklung erreicht. Insbesondere die Lichtkurvendaten der NASA-Mission TESS (Transiting Exoplanet Survey Satellite) ermöglichen es Wissenschaftlern, täglich eine große Anzahl potenzieller Transitsignale zu erfassen.
Die Bestätigung oder Widerlegung der planetaren Eigenschaften von Kandidaten ist jedoch ein langwieriger und anspruchsvoller Prozess. Das Exoplanet Archive listet derzeit 7.658 TESS-Objekte (Teleplanetary Objects of Interest, TOIs) auf, von denen 5.152 noch als Kandidaten gelten.Nur 666 wurden als echte Exoplaneten bestätigt, weitere 558 wurden von TESS entdeckt, waren aber bereits zuvor als solche bestätigt worden.Inzwischen wurden 1.185 TESS-Kandidaten als „falsch positive Ergebnisse (FPs)“ identifiziert und weitere 97 als „falsche Alarme (FAs)“ klassifiziert – eine so hohe Zahl unterstreicht die Schwierigkeit, Exoplanetenkandidaten zu bestätigen.
Einen Schritt weiter als die Kandidatenauswahl gehen die sogenannten „Validierungspipelines“, die mithilfe statistischer Methoden bestätigen sollen, dass es sich bei den Kandidaten tatsächlich um Planeten handelt.Bei den traditionellen Verifizierungsmethoden kommt es vor allem auf die manuelle Analyse und anschließende Beobachtungen an, einschließlich Radialgeschwindigkeitsmessungen (RV) und der Nachführung durch bodengebundene Teleskope.Diese Methoden sind zwar zuverlässig, aber zeitaufwändig und kostspielig.
Als Reaktion darauf entwickelte ein Forschungsteam der Universität Warwick, aufbauend auf dem von David J. Armstrong et al. vorgeschlagenen Kepler-Prozess,Ein neues Screening- und Validierungsverfahren für TESS-Kandidaten wurde weiterentwickelt – RAVEN (RAnking and Validation of ExoplaNets).Die wichtigste Änderung im neuen Verfahren ist die Einführung synthetischer Trainingsdatensätze, die nicht mehr ausschließlich auf Schwellenwertüberschreitungsdaten (TCE-Daten) basieren, die von der Aufgabe selbst generiert werden. Diese Verbesserung erweitert und optimiert den Parameterraum der vom Machine-Learning-Modell abgedeckten planetaren und falsch-positiven Szenarien erheblich.
Die Ergebnisse zeigen, dassDas Verfahren erreichte in allen falsch-positiven Szenarien einen AUC-Wert von über 971 TP3T, mit Ausnahme eines Szenarios, in dem er 991 TP3T überstieg.Anhand eines unabhängigen externen Testdatensatzes mit 1.361 vorklassifizierten TESS-Kandidaten erreichte der Workflow eine Gesamtgenauigkeit von 91% und demonstrierte damit seine Effektivität bei der automatischen Rangfolge der TESS-Kandidaten.
Mithilfe des Verfahrens konnten die Forscher außerdem 118 neue Exoplaneten bestätigen und über 2.000 hochwertige Planetenkandidaten identifizieren, von denen fast 1.000 noch nie zuvor entdeckt worden waren.
Die zugehörigen Forschungsergebnisse mit dem Titel „RAVEN: Ranking and Validation of ExoplaNets“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
Durch die Nutzung synthetischer Datensätze ermöglicht RAVEN einen direkten Vergleich zwischen planetaren Szenarien und jedem einzelnen falsch-positiven Szenario – eine Fähigkeit, die bisher typischerweise nur in Validierungsrahmen zu finden war, die auf Modellanpassung basieren.
Das neue Verfahren verwendet synthetische Trainingsdatensätze und stützt sich nicht mehr ausschließlich auf TCE-Daten, die von der Aufgabe selbst generiert werden.
Das neue Verfahren zeichnet sich durch hohe operative Effizienz aus: Die Bearbeitung eines typischen Kandidaten dauert nur etwa eine Minute, und es bietet dank der Unterstützung mehrerer Prozesse eine gute Skalierbarkeit.
Papieradresse:https://arxiv.org/abs/2509.17645*
Folgen Sie unserem offiziellen WeChat-Account und antworten Sie im Hintergrund mit „TESS“, um das vollständige PDF zu erhalten.
Datensatz: Der vollständige Konstruktionspfad von den Eingabedaten zu den Trainingsbeispielen
Eingangsdaten: Fusion von Informationen aus verschiedenen Quellen mit Lichtkurven als Kern.
Der RAVEN-Workflow verwendet derzeit Lichtprofile, die aus TESS-Vollbildaufnahmen (FFI) generiert werden, welche vom TESS Science Processing Operations Center veröffentlicht werden. Diese Lichtprofile werden mithilfe von Aperturphotometrie aus den FFI-Daten jedes Beobachtungssektors extrahiert, mit einer Abtastrate von 30 Minuten für die Sektoren 1–27 und 10 Minuten für die Sektoren 28–55. Die von der TESS Second Extension Mission (beginnend mit Sektor 56) veröffentlichten FFI-Daten weisen eine Abtastrate von 200 Sekunden auf. Die in dieser Studie verwendeten Lichtprofile enden mit Sektor 55.
Trainingsdaten: Systematische Modellierung von Planeten und falsch positiven Ergebnissen
Das RAVEN-Verfahren verwendet synthetische Lichtkurvendaten zum Trainieren von Modellen des maschinellen Lernens, anstatt sich bei dieser Aufgabe auf bereits vorhandene klassifizierte Lichtkurvendaten zu stützen.
Der ursprüngliche Datensatz kombinierte Ereignisse nutzte simulierte Transits oder Bedeckungen und integrierte diese in die SPOC-Lichtkurven. Die simulierten Ereignisse wurden mit einer modifizierten Version der PASTIS-Software der Forscher generiert und umfassten zunächst Szenarien wie transitierende Planeten (Planet), Bedeckungsveränderliche (EB), geschichtete Bedeckungsveränderliche (HEB), geschichtete transitierende Planeten (HTP), Hintergrund-Bedeckungsveränderliche (BEB) und Hintergrund-transitierende Planeten (BTP). Um sicherzustellen, dass die kombinierten Daten die tatsächliche TESS-Beobachtungspopulation möglichst genau abbilden, wurde der Hauptstern in jedem Szenario zufällig aus einer vollständig charakterisierten Stichprobe des TESS Input Catalog (TIC) ausgewählt. Die Zielstichprobe enthielt schließlich 1.200.520 SPOC-FFI-Sterne.
Darauf aufbauend wird die Konstruktion von Daten zu falsch positiven Ergebnissen komplexer und wichtiger. Für nahegelegene falsch positive Ergebnisse (NFPs) betrachten Forscher die folgenden NFP-Szenarien: Nahegelegener Transitplanet (NTP): Der Planet zieht vor dem Wirtsstern vorbei und verdünnt dessen Helligkeit; Nahegelegener Bedeckungsveränderlicher (NEB): Die nahegelegene Quelle der Helligkeitsverdünnung ist ein Bedeckungsveränderlicher; Nahegelegener geschichteter Bedeckungsveränderlicher (NHEB): Die nahegelegene Quelle der Helligkeitsverdünnung ist ein geschichteter Bedeckungsveränderlicher.
Testdaten: Anwendungsszenarien aus der Praxis mit Schwerpunkt auf TOI
Die Leistungsfähigkeit dieses Verfahrens wurde schließlich an einer Reihe von TOIs (d. h. TESS-Zielen von Interesse) mit bereits bestehenden Vorklassifizierungen getestet.Die Liste und die Klassifizierungsinformationen der im Test verwendeten TOIs stammen aus dem NASA Exoplanet Archive vom 3. Februar 2025. Zu diesem Zeitpunkt gab es 2.134 vorklassifizierte TOIs, von denen 548 als bekannte Planeten (KP), 485 als TESS-bestätigte Planeten (CP), 1.113 als FP und 96 als FA klassifiziert waren. Allerdings lagen nur für 1.918 TOIs veröffentlichte SPOC-FFI-Lichtkurven vor.Nach Anwendung von Tiefen- und Periodizitätsbeschränkungen auf die verbleibenden Proben beträgt die Gesamtzahl der zu verarbeitenden TOIs 1.589.
Alle TOIs durchliefen die vollständigen Verarbeitungsschritte, mit Ausnahme eines FP-TOI, dessen Zielstern in TIC als „DUPLIKAT“ markiert war. In den Endergebnissen wurden 68 TOIs ausgeschlossen, da dem Zielstern in TIC der Sternradius fehlte; weitere 87 wurden ausgeschlossen, da ihre TESS-Helligkeit 13,5 überschritt, und 22 wurden ausgeschlossen, da ihre Gaia-Helligkeit 14 überschritt.
Der in dieser Studie verwendete Trainingsdatensatz enthielt keine Ereignisse mit Zielsternen größer als 13,5 Tmag oder 14 Gmag. Darüber hinaus wurden 28 Ereignisse ausgeschlossen, da ihr berechneter MES-Wert während der Merkmalsgenerierung unter 0,8 lag, und 2 weitere Ereignisse wurden aufgrund eines Fehlers bei der Merkmalsgenerierung verworfen. Schließlich wurden 21 Ereignisse von der weiteren Analyse ausgeschlossen, da ihre Schwerpunktdaten die Generierung von Positionswahrscheinlichkeiten verhinderten und daher keine A-posteriori-Wahrscheinlichkeiten angegeben werden konnten.
daher,Die endgültige Anzahl der vorklassifizierten TOIs in diesem Test betrug 1.361, davon waren 705 bekannte oder bestätigte Planeten, 630 FPs und 26 FAs.
Kombination zweier Modelle des maschinellen Lernens – GBDT+GP
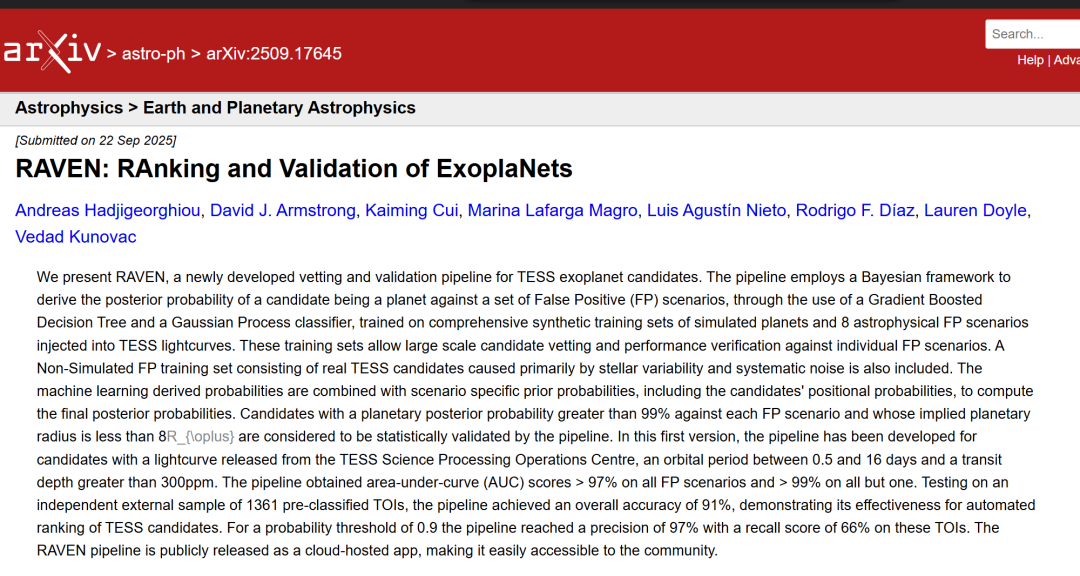
Der RAVEN-Workflow basiert auf dem statistischen Validierungsrahmen (im Folgenden A21 genannt), der 2021 von David J. Armstrong et al. für Kepler-Missionskandidaten vorgeschlagen wurde. Dieser Rahmen wurde an die Daten des Transiting Exoplanet Survey Satellite (TES) angepasst und zudem erweitert und verbessert. Die Implementierung und der Betrieb des gesamten Workflows sind relativ komplex und umfassen mehrere Schritte. Ein vereinfachtes Flussdiagramm ist in der folgenden Abbildung dargestellt:
Schulung im maschinellen Lernen
Im Kern kombiniert RAVEN zwei Modelle des maschinellen Lernens: Gradient Boosted Decision Tree (GBDT) und Gaussian Process (GP).Der Prozess generiert für jeden Kandidatenplaneten acht falsch positive Szenarien A-posteriori-Wahrscheinlichkeiten und ermittelt die RAVEN-Wahrscheinlichkeit, die das geringste Vertrauen in die Echtheit des Kandidaten darstellt, indem der Minimalwert genommen wird.
① Gradient Boosting Decision Tree (GBDT)
Entscheidungsbäume sind ein einfacher, aber leistungsstarker Typ von Modellen des maschinellen Lernens. Ein wesentlicher Vorteil ist ihre gute Interpretierbarkeit. Einzelne Entscheidungsbäume weisen jedoch Einschränkungen hinsichtlich ihrer Robustheit auf und neigen bei zu großer Baumtiefe zu Überanpassung. Um diese Probleme zu beheben, werden typischerweise Ensemble-Methoden eingesetzt, die aus mehreren „schwachen“ Bäumen bestehen. Gradient Boosting Decision Trees (GBDT) ist eine solche Ensemble-Methode, die sequenziell mehrere Entscheidungsbäume erstellt, um ein robusteres Endmodell zu erzeugen.
Die Kernfunktionen von GBDT sind:Jeder neu generierte Baum wird nicht direkt anhand der ursprünglichen Labels trainiert, sondern lernt aus dem Restfehler, der durch die Modellvorhersage in der vorherigen Runde entstanden ist.Anders ausgedrückt: Ziel jedes neuen Modells ist es, die Verlustfunktion des Gesamtmodells zu minimieren – ein Prozess, der dem Gradientenabstieg im Wesentlichen ähnelt. Während der Ensemble-Verarbeitung werden die Ausgaben jedes Teilmodells mit der Lernrate skaliert und anschließend summiert, um die endgültige Vorhersage zu erhalten.
Der Modellverlust wird mithilfe einer vordefinierten Verlustfunktion berechnet, und die Residuen werden durch den Gradienten dieser Verlustfunktion bestimmt. In dieser Studie wird der GBDT-Klassifikator mit XGBoost implementiert, wie von Chen und Guestrin vorgeschlagen.
② Gaußprozess-Klassifikator
Ein Gaußprozess (GP) ist ein stochastischer Prozess, der die Gaußsche Wahrscheinlichkeitsverteilung von einer „Verteilung von Zufallsvariablen“ auf eine „Verteilung von Funktionen“ verallgemeinert. Bei der GP-Klassifizierung besteht das Ziel darin, diskrete Klassenbezeichnungen oder Klassenwahrscheinlichkeiten zwischen 0 und 1 auszugeben. Um dies zu erreichen, wird eine Zielfunktion auf die GP-Ausgabe angewendet, die das Ergebnis auf das Intervall von 0 bis 1 abbildet. Diese wird dann mit einer Wahrscheinlichkeitsfunktion (wie z. B. der Bernoulli-Wahrscheinlichkeitsfunktion) kombiniert.
In dieser Studie wird die von James Hensman et al. vorgeschlagene Variationsapproximationsmethode verwendet. Diese Methode basiert auf einer Menge von „induzierenden Punkten“, die repräsentative Teilmengen der Daten darstellen, um die Skalierbarkeit des Modells zu verbessern und gleichzeitig die Rechenkomplexität zu reduzieren.
Schulung und Kalibrierung
Zur Schulung und Optimierung der beiden Klassifikatoren wurde ein iterativer Ansatz gewählt. Dabei wurde der synthetische Trainingsdatensatz mit verschiedenen Hyperparameterkombinationen trainiert und die Leistung anhand des Validierungsdatensatzes evaluiert, um die optimalen Parameter auszuwählen. Die Parameteroptimierung konzentrierte sich primär auf drei wichtige Szenarien falsch positiver Ergebnisse: EB, NEB und NSFP, da diese am häufigsten auftreten. Um eine Überoptimierung einzelner Szenarien und die daraus resultierende Überanpassung zu vermeiden, wurde gleichzeitig eine möglichst hohe Parameterkonsistenz über alle Szenarien hinweg angestrebt.
Alle Modelle verfügen über den „Early Stopping“-Mechanismus: Das Training wird beendet und das Modell kehrt zum Zustand zum Zeitpunkt der letzten Verbesserung der Verlustfunktion auf dem Validierungsdatensatz zurück, wenn die Verlustfunktion auf dem Validierungsdatensatz in 20 aufeinanderfolgenden Iterationen nicht um mindestens 0,0001 abnimmt.
Statistische Validierung
Der letzte Schritt des Prozesses besteht darin, die A-posteriori-Wahrscheinlichkeit der Planetenhypothese zu ermitteln. Dazu wird die Wahrscheinlichkeit jeder Planeten-FP-Kategorie, die mittels maschinellen Lernens bestimmt wurde, mit ihrer jeweiligen szenariospezifischen A-priori-Wahrscheinlichkeit kombiniert. Diese A-posteriori-Wahrscheinlichkeit gibt lediglich die Wahrscheinlichkeit an, dass es sich bei dem Kandidaten um einen Planeten oder ein bestimmtes FP-Szenario handelt. Daher erfordert die statistische Validierungsmethode der Forscher, dass die A-posteriori-Wahrscheinlichkeit des Kandidaten für jede der acht Planeten-FP-Kategorien 0,99 übersteigt, damit er als validiert gilt.
RAVEN erzielt gute Ergebnisse bei der Vorauswahl, Rangfolge und Validierung realer Planetenkandidaten.
Um die Leistungsfähigkeit von RAVEN zu bewerten, führten die Forscher die folgenden Validierungen sowohl am Trainings- als auch am Testdatensatz durch:
Die Forscher testeten die Leistung des Modells zunächst anhand unbekannter Teilmengen des Trainingsdatensatzes. Diese Teilmengen bestanden aus 10%-Ereignissen, die zufällig aus jeder Szene ausgewählt und vor dem Training unabhängig voneinander isoliert wurden. Die Modellleistung wurde anhand von vier Schlüsselmetriken bewertet: Genauigkeit, Fläche unter der ROC-Kurve (AUC), Präzision und Trefferquote. Die Ergebnisse des Leistungstests sind in der folgenden Tabelle dargestellt:
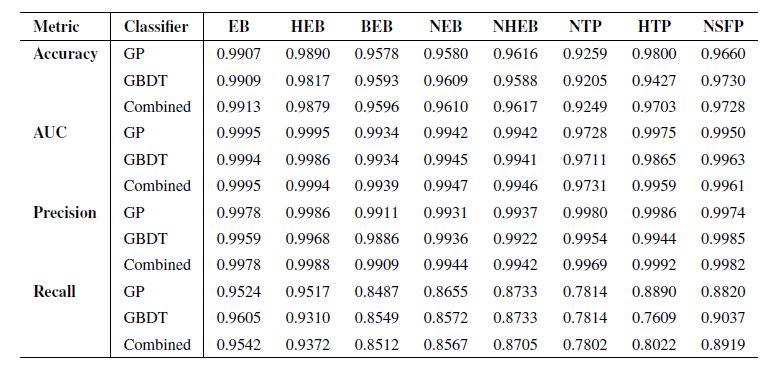
Die Ergebnisse zeigen, dass beide Klassifikatoren in allen FP-Szenarien hervorragend abschneiden, insbesondere hinsichtlich der Genauigkeit. Da das Hauptziel der RAVEN-Pipeline die Überprüfung und Validierung realer Planetenkandidaten ist, stellt die Genauigkeit die wichtigste Kennzahl dar, die die Fähigkeit der Pipeline widerspiegelt, FPs korrekt und ohne Fehlklassifizierung zu identifizieren.Durch die Kombination der Ergebnisse beider Klassifikatoren wird in allen Szenarien eine Genauigkeit von nahezu 99% erreicht.
Die Leistungsfähigkeit des RAVEN-Verfahrens wurde schließlich anhand eines Satzes von TOIs mit vorheriger Klassifizierung getestet. Die RAVEN-Wahrscheinlichkeiten für alle 1361 TOIs in der Stichprobe sind in der folgenden Abbildung dargestellt:
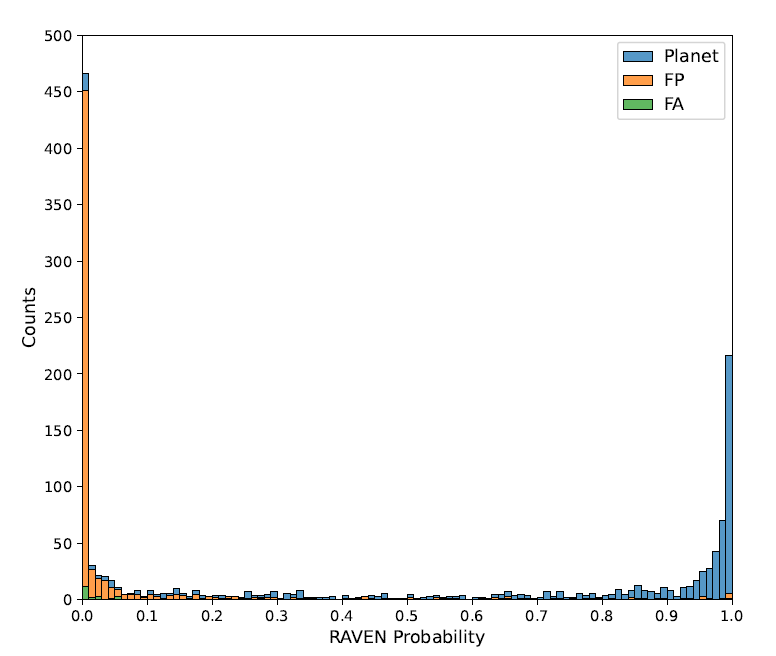
Das Histogramm zeigt, dass die Wahrscheinlichkeitsunterschiede zwischen den drei Klassen signifikant sind, die Verteilung gut ist und die Extremwerte deutlich erkennbar sind.Dies beweist die Effektivität von RAVEN bei der Identifizierung von FP-Ereignissen und der Zuweisung niedriger planetarischer A-posteriori-Wahrscheinlichkeiten an diese.Die minimale A-posteriori-Wahrscheinlichkeit für falsch-positive Ereignisse liegt bei 93,8% unter 0,5 und bei 69,7% unter 0,01. Die mittlere Wahrscheinlichkeit für falsch-positive Ereignisse beträgt 0,076, der Median 0,00022.
Bei den 26 FA-TOIs wiesen 23 eine Wahrscheinlichkeit unter 0,5 auf, mit einem Median von 0,016 für die gesamte Kategorie. Insgesamt bestätigen die Ergebnisse für FP und FA-TOI die Effizienz des Verfahrens beim Screening von TESS-Kandidaten und können zur Eliminierung der meisten FP-Ereignisse genutzt werden.
Anschließend überprüften die Forscher die Fähigkeit von RAVEN, falsch positive Ergebnisse (FPs) zu identifizieren. Die folgende Tabelle listet 12 FP-Ereignisse mit einer Wahrscheinlichkeit von mehr als 0,9 auf:
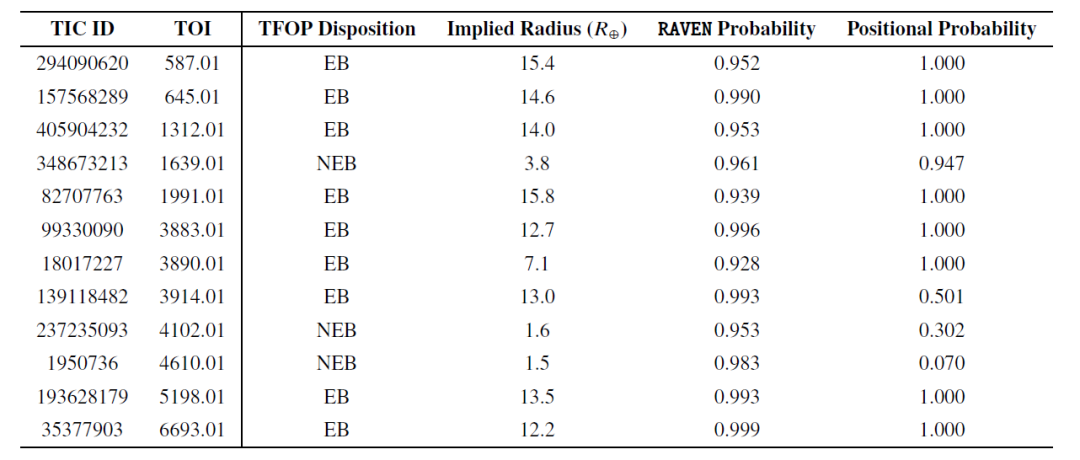
Von diesen Ereignissen mit hoher Wahrscheinlichkeit für eine Fehlinterpretation (FP) handelte es sich meist um Bedeckungsveränderliche (EB), nur drei waren benachbarte Bedeckungsveränderliche (NEB). Obwohl NEB der häufigste FP-Typ in der Stichprobe war, deutet dies darauf hin, dass RAVEN NEB effektiv identifiziert hat. Tatsächlich ermittelte das RAVEN-Verfahren für zwei NEB-Ereignisse (TOI-4102.01 und TOI-4610.01) eine geringe Wahrscheinlichkeit für Positionsinformationen und ordnete die höchste Wahrscheinlichkeit korrekt dem durch Nachbeobachtungen bestätigten Wirtsstern zu.
Darüber hinaus wurde TOI-4102.01 ebenfalls als problematisches Ereignis markiert. Diese beiden TOIs weisen darauf hin, dass bei der Bewertung von Kandidaten, insbesondere während der Validierung, die vollständige Ausgabe des RAVEN-Prozesses zusammen mit den Standortwahrscheinlichkeiten berücksichtigt werden sollte, um Situationen zu identifizieren, in denen die A-posteriori-Wahrscheinlichkeiten ungültig sein könnten.
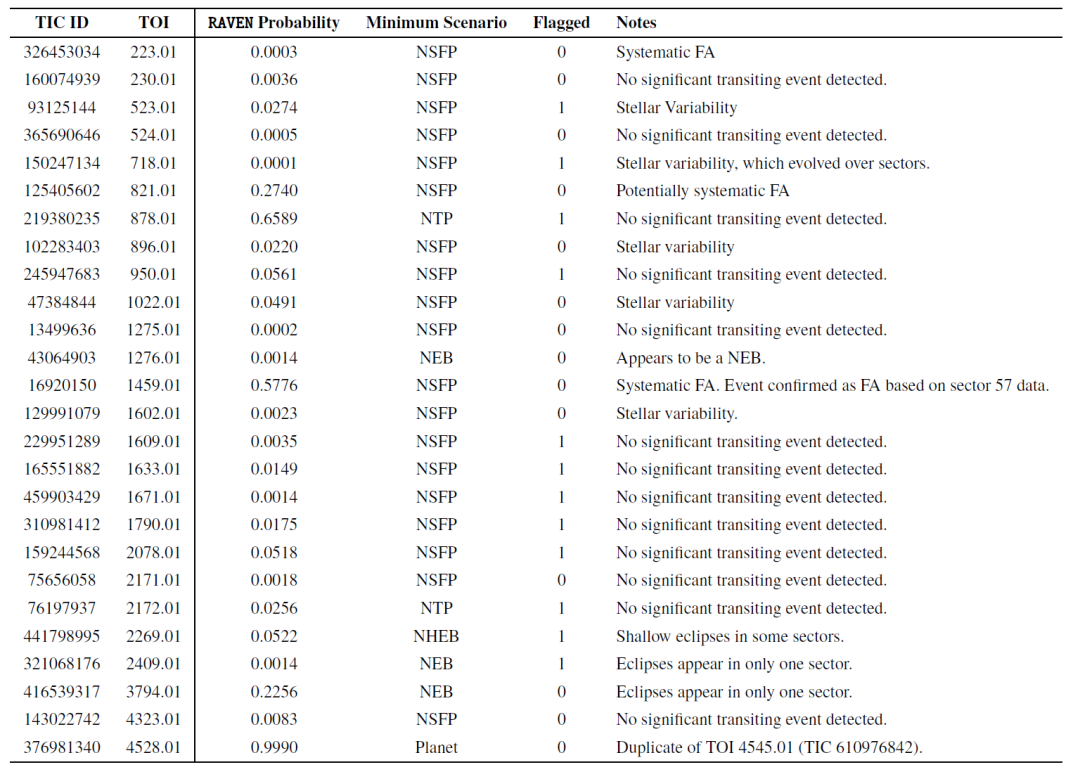
Die Forscher evaluierten auch die Leistung des RAVEN-Verfahrens bei Fehlalarmen (FA-TOIs). Die folgende Tabelle zeigt die niedrigsten A-posteriori-Wahrscheinlichkeiten für 26 FA-TOIs in der Stichprobe sowie die entsprechenden FP-Szenarien. Die Wahrscheinlichkeiten fast aller FA-TOIs stimmten nicht mit den Planetenszenarien überein, was belegt, dass RAVEN diese effektiv identifizierte.
Nach der Sichtung der ersten TOI-Stichprobe behielten die Forscher schließlich 397 bekannte und 308 bestätigte Planeten bei, insgesamt also 705 Planeten. Die Ergebnisse zeigen, dass…Die meisten Planet TOIs weisen hohe posteriore Planetenwahrscheinlichkeiten auf, wobei 81% den Schwellenwert von 0,5 überschreitet.
Insbesondere weisen 420 Planeten eine Wahrscheinlichkeit von über 0,9 auf und fallen somit in den Bereich „Wahrscheinlicher Planet“. Darüber hinaus haben 210 Planeten einen TOI-Wert, der den statistischen Validierungsschwellenwert von 0,99 überschreitet; dies entspricht etwa 30% der gesamten Planetenstichprobe.Diese Ergebnisse zeigen, dass RAVEN bei der Vorauswahl, Rangfolge und Validierung realer Planetenkandidaten gute Ergebnisse liefert.
Künstliche Intelligenz entwickelt sich zunehmend zu einer wichtigen Infrastruktur für die astronomische Forschung.
Aus einer breiteren Perspektive der technologischen Entwicklung wird künstliche Intelligenz zunehmend zu einer entscheidenden Infrastruktur für die astronomische Forschung. Ihre Bedeutung geht weit über die bloße „Verbesserung der Datenverarbeitungseffizienz“ hinaus; sie beginnt, das gesamte Paradigma der wissenschaftlichen Entdeckung neu zu gestalten. Lange Zeit stützte sich die Astronomie auf Analysemethoden, die auf physikalischen Modellen und künstlichen Regeln basierten. Mit der Verbesserung der Beobachtungsmöglichkeiten haben jedoch Umfang und Komplexität der Daten stetig zugenommen. Von Lichtkurven über hochauflösende Bilder bis hin zu mehrdimensionalen Spektren und Sternkataloginformationen stoßen traditionelle Methoden bei der Verarbeitung hochdimensionaler, nichtlinearer und stark verrauschter Daten zunehmend an ihre Grenzen. Vor diesem Hintergrund …KI-Technologien, deren Kern maschinelles Lernen und Deep Learning bilden, entwickeln sich zu einer wichtigen Brücke zwischen „massiven Beobachtungsdaten“ und „effektivem wissenschaftlichem Verständnis“.
Mit dem Fortschritt der Beobachtungsmethoden sind astronomische Daten nicht mehr auf eine einzige Modalität beschränkt. Mehrere Datenquellen, wie Bilder, Spektren, Lichtkurven-Zeitreihen und Sternkatalogparameter, existieren nebeneinander, und traditionelle Deep-Learning-Modelle stoßen in diesem Stadium an ihre Grenzen. Tatsächlich haben einige Studien versucht, multimodale astronomische Modelle zu entwickeln, doch diese Ansätze weisen noch erhebliche Einschränkungen auf.Die meisten Studien konzentrieren sich auf einzelne Phänomene wie Supernova-Explosionen und nutzen „kontrastive Zielsetzungen“ als Kerntechnologie. Dadurch können die Modelle nur schwer flexibel mit beliebigen Modalkombinationen umgehen und wichtige wissenschaftliche Informationen zwischen den Modalitäten jenseits oberflächlicher Korrelationen erfassen.
Um diesen Engpass zu überwinden,Teams aus mehr als zehn Forschungseinrichtungen weltweit, darunter die University of California, Berkeley, die University of Cambridge und die University of Oxford, haben zusammengearbeitet, um AION-1 (Astronomical Omni-modal Network) zu starten, die erste groß angelegte multimodale Basismodellfamilie für die Astronomie.Durch die Integration und Modellierung heterogener Beobachtungsinformationen wie Bilder, Spektren und Sternkatalogdaten mittels eines einheitlichen frühen Fusions-Backbone-Netzwerks erzielt es nicht nur gute Ergebnisse in Zero-Shot-Szenarien, sondern seine lineare Detektionsgenauigkeit ist auch mit Modellen vergleichbar, die speziell für bestimmte Aufgaben trainiert wurden.
Titel des Beitrags: AION-1: Omnimodales Grundlagenmodell für die astronomischen Wissenschaften
Papieradresse:https://openreview.net/forum?id=6gJ2ZykQ5W
Gleichzeitig erweitert die KI auf der Ebene konkreter wissenschaftlicher Fragestellungen die Grenzen traditioneller Beobachtungsmethoden. In der modernen Astronomie beispielsweise ist die starke Gravitationslinse ein wichtiges Instrument zur Untersuchung der großräumigen Struktur des Universums und der gemeinsamen Entwicklung von Schwarzen Löchern und Galaxien. Quasare, die als starke Gravitationslinsen wirken, bieten äußerst seltene Beobachtungsmöglichkeiten, um die Entwicklung der Skalierungsbeziehung (insbesondere die Beziehung zwischen supermassereichen Schwarzen Löchern und ihren Wirtsgalaxien) in Abhängigkeit von der Rotverschiebung zu untersuchen.
Allerdings sind Quasare extrem selten, und ihre Identifizierung war für Astronomen schon immer eine große Herausforderung – unter den fast 300.000 im Sloan Digital Sky Survey (SDSS) katalogisierten Quasaren wurden nur 12 Kandidaten gefunden, und nur 3 wurden letztendlich bestätigt.Vor diesem Hintergrund entwickelte ein Team aus zahlreichen Forschungseinrichtungen, darunter die Stanford University, das SLAC National Accelerator Laboratory, die Peking University, das Brera-Observatorium des Italienischen Nationalen Instituts für Astrophysik, das University College London und die University of California, Berkeley, einen datengesteuerten Arbeitsablauf zur Identifizierung von Quasaren, die in den Spektraldaten von DESI DR1 als starke Gravitationslinsen wirken. Mithilfe dieses Arbeitsablaufs identifizierten die Forscher sieben hochwertige (Klasse A) Quasar-Linsenkandidaten.
Titel der Veröffentlichung: Quasare, die als starke Linsen wirken, wurden in DESI DR1 entdeckt
Papieradresse:https://arxiv.org/abs/2511.02009
Es ist absehbar, dass die Astronomie mit dem Fortschritt zukünftiger Beobachtungsmissionen (wie großflächigeren Himmelsdurchmusterungen) in eine Phase weiterer Datenexplosionen eintreten wird und die Rolle der KI entsprechend an Bedeutung gewinnen wird. Von der Unterstützung der Analyse bis hin zur Förderung von Entdeckungen, von Modellen für einzelne Aufgaben bis hin zu grundlegenden Modellen – KI verändert unser Verständnis des Universums grundlegend. Sie verändert nicht nur, „wie wir sehen“, sondern auch, „was wir entdecken können“.
Quellen:
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W








