Command Palette
Search for a command to run...
Gemeinsames Training Ist Auch Ohne Datenaustausch Möglich! Das UCL-Team Revolutioniert Die Untersuchung Der Blutmorphologie Mithilfe Von Föderiertem Lernen.

Die Untersuchung der Blutmorphologie ist ein entscheidender Schritt in der klinischen Diagnostik von Blutkrankheiten. Durch die Beobachtung der Zellmorphologie in peripheren Blutausstrichen (PBS) oder Knochenmarkaspiraten (BMA) können Ärzte die Art von Leukämie, Anämie, Infektionen und erblichen Blutkrankheiten bestimmen. Dieses Verfahren ist jedoch nicht nur arbeitsintensiv, sondern auch stark von erfahrenen Fachkräften abhängig. Insbesondere in Ländern mit niedrigem und mittlerem Einkommen (LMICs) herrscht Mangel an qualifizierten Spezialisten, wodurch eine schnelle, zuverlässige und skalierbare hämatologische Diagnostik zu einem dringenden Anliegen wird.
Die Entwicklung künstlicher Intelligenz und des Deep Learning hat in den letzten Jahren neue Lösungen für die Blutmorphologieanalyse hervorgebracht. KI-Modelle können verschiedene Arten von weißen Blutkörperchen automatisch identifizieren und Ärzte bei der schnellen Diagnosestellung unterstützen.Forschungsergebnisse deuten darauf hin, dass Deep Learning ein erhebliches Potenzial in der automatisierten hämatologischen Diagnostik besitzt.In der Praxis bestehen jedoch weiterhin erhebliche Herausforderungen: Das Modelltraining ist stark datenabhängig, während klinische Daten typischerweise auf verschiedene Krankenhäuser verteilt sind und durch Variationen in Färbemethoden, Bildgebungsgeräten und einigen seltenen Zelltypen beeinträchtigt werden. Diese Datenheterogenität kann die Generalisierbarkeit des Modells auf neue Einrichtungen oder Patientenpopulationen verringern.
Wichtiger noch: Medizinische Daten berühren die Privatsphäre der Patienten, und der institutionsübergreifende Datenaustausch ist stark eingeschränkt. Traditionelle, zentralisierte Trainingsmethoden erfordern typischerweise die Zusammenführung großer Mengen sensibler medizinischer Daten und sind auf Hochleistungsrechner angewiesen, was in vielen Einrichtungen schwer umzusetzen ist. Wie sich institutionsübergreifendes, kollaboratives Training unter Wahrung der Privatsphäre realisieren lässt, ist daher zu einer zentralen Frage geworden, die im Bereich der medizinischen KI dringend gelöst werden muss.
In diesem ZusammenhangEin Forschungsteam des Fachbereichs Informatik am University College London (UCL) hat ein föderiertes Lernframework für die Analyse der Morphologie weißer Blutkörperchen vorgeschlagen.Dies ermöglicht es Institutionen, gemeinsame Schulungen durchzuführen, ohne Trainingsdaten auszutauschen. Mithilfe von Blutausstrichen aus verschiedenen klinischen Einrichtungen lernt das föderierte Modell robuste und domäneninvariante Merkmalsdarstellungen unter vollständiger Wahrung des Datenschutzes. Evaluierungen auf Convolutional Neural Networks und Transformer-basierten Architekturen zeigen, dass föderiertes Training zentralisiertes Training hinsichtlich standortübergreifender Leistung und Generalisierung auf unbekannte Institutionen übertrifft.
Die zugehörigen Forschungsergebnisse mit dem Titel „MORPHFED: Federated Learning for Cross-institutional Blood Morphology Analysis“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
* Im Vergleich zu zentralisierter Ausbildung zeigt föderierte Ausbildung eine überlegene Leistung an allen Standorten und die Fähigkeit, auf unbekannte Institutionen zu generalisieren.
Diese Methode ermöglicht das kollaborative Modelltraining über verschiedene Institutionen hinweg, ohne dass Rohdaten ausgetauscht werden müssen, und bietet somit eine praktikable Lösung für ressourcenbeschränkte Gesundheitseinrichtungen.

Papieradresse:
https://arxiv.org/abs/2601.04121
Folgen Sie unserem offiziellen WeChat-Account und antworten Sie im Hintergrund mit „MORPHFED“, um das vollständige PDF zu erhalten.
Datensatz: Spiegelt die Heterogenität in realen klinischen Umgebungen wider
In dieser Studie wurden Blutausstrichdaten aus mehreren medizinischen Einrichtungen verwendet, um sicherzustellen, dass die Trainingsdaten nicht nur verschiedene Zelltypen abdeckten, sondern auch die Heterogenität in realen klinischen Umgebungen widerspiegelten.
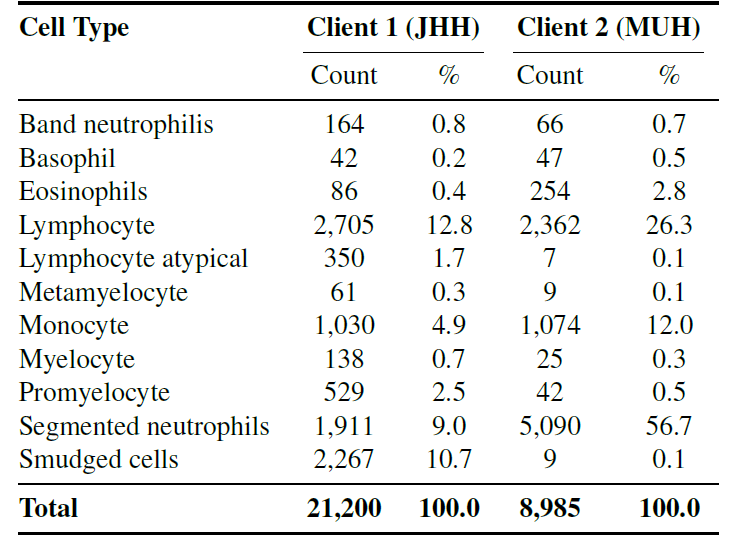
Konkret wurden in der Studie unabhängige Datensätze aus zwei Zentren verwendet.Diese beiden Datensätze enthalten 11 häufig vorkommende Zelltypen (wie z. B. Neutrophile, Eosinophile, Basophile, Promyelozyten usw.).Es gewährleistet Konsistenz bei den Klassifizierungszielen unter Beibehaltung von Unterschieden in der Färbung und Bildgebung und wird verwendet, um die Generalisierungsfähigkeit des föderierten Lernens in realen heterogenen Umgebungen zu testen.
Die folgende Abbildung zeigt die Verteilung der verschiedenen Kundenkategorien.
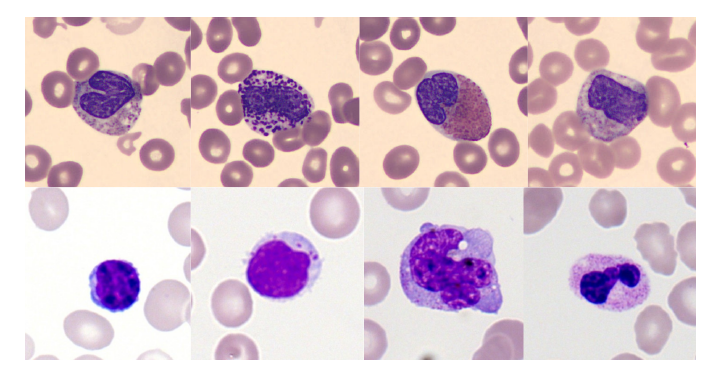
Die Abbildung unten zeigt Beispiele einiger Zelltypen aus zwei Trainingsdatensätzen.Der Unterschied im Farbstil ist deutlich erkennbar, und genau diese Datenverzerrung muss das Modell überwinden.
Um die Leistungsfähigkeit des Modells anhand völlig unbekannter institutioneller Daten unabhängig zu bewerten,Die Studie sicherte 12.992 Bilder aus dem Klinikum Barcelona (Klient 3).Dieser Datensatz dient als externer Validierungssatz. Er umfasst verschiedene Bildgebungsgeräte, Färbemethoden und Patientenpopulationen und wird verwendet, um die Generalisierungsfähigkeit des Modells in realen, institutionsübergreifenden Szenarien zu testen.
Zwei Arten von Deep-Learning-Architekturen und vier föderierte Aggregationsstrategien
Diese Studie verwendet zwei Arten von Deep-Learning-Architekturen:
* ResNet-34: Eine klassische Architektur, die auf Convolutional Neural Networks (CNNs) basiert und vortrainierte Gewichte von ImageNet verwendet.
* DINOv2-Small: Basierend auf dem selbstüberwachten Vision Transformer (ViT) erfasst es globale Bildmerkmale durch selbstüberwachtes Lernen.
Das Training folgt einem einheitlichen Protokoll: Das föderierte Modell führt 5 Runden globaler Kommunikation durch, wobei jeder Client pro Runde 5 lokale Trainingszyklen durchführt, insgesamt also 25 Trainingszyklen; das zentralisierte Basismodell verwendet 25 Trainingszyklen und führt eine 4-fache Kreuzvalidierung durch, wie in der folgenden Abbildung dargestellt.Die Daten wurden in einen 60%-Trainingsdatensatz, einen 13.33%-Validierungsdatensatz, einen 13.33%-lokalen Testdatensatz und einen 13.33%-globalen Testdatensatz unterteilt.Alle Bilder wurden auf 224×224 Pixel verkleinert und eine konservative Datenaugmentationsstrategie (Translation ±10%, Rotation ±5°) wurde angewendet, um diagnostische morphologische Informationen zu erhalten.
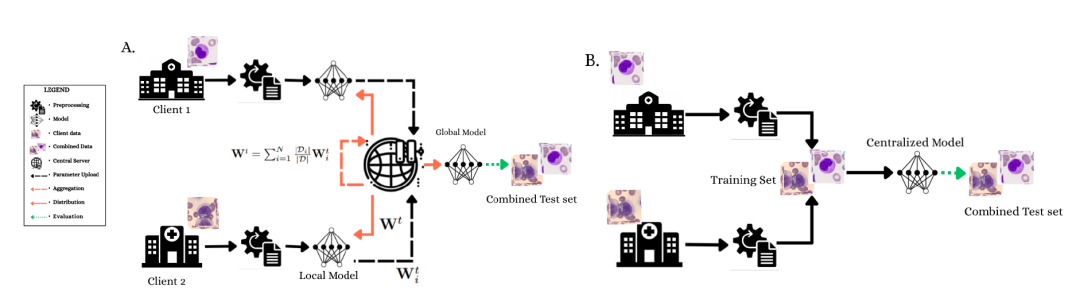
(A) Das föderierte Lernframework demonstriert einen datenschutzfreundlichen kollaborativen Trainingsprozess, bei dem Client 1 und Client 2 das Modell lokal trainieren und die Parameter auf einem zentralen Server aggregiert werden.
(B) Zentralisiertes Trainingsparadigma mit vollem Zugriff auf zusammengeführte Datensätze und 4-facher Kreuzvalidierung.
Beide Architekturen nutzten selektives Feintuning: ResNet-34 fror die frühen Schichten ein und trainierte nur die letzten drei Residualblöcke (ca. 11 Millionen Parameter); DINOv2-Small fror die ersten acht Transformer-Blöcke (0–7) ein und trainierte die Blöcke 8 bis 11 (ca. 9 Millionen Parameter). Die Daten von Klient 3 wurden während des gesamten Trainingsprozesses isoliert gehalten und ausschließlich zur Bewertung der Generalisierungsfähigkeit des finalen Modells auf neue institutionelle Daten verwendet.
Im Rahmen des föderierten Lernens ist der zentrale Server für die Koordination des Trainings und die Verteilung globaler Parameter zuständig, greift aber nicht auf die Originaldaten zu; der Client trainiert lokal und gibt lediglich Parameteraktualisierungen zurück.
Die Studie nutzte vier föderierte Aggregationsstrategien:
* FedAvg: Berechnet einen gewichteten Durchschnitt der Clientparameter, der empfindlich auf extreme Klassenverteilungen reagiert.
* FedMedian: Berechnet den Medianwert für jede Koordinate. Es ist robust gegenüber Ausreißern und byzantinischen Fehlern, kann aber Signale von Minderheitsklassen unterdrücken.
* FedProx: Fügt proximale Nebenbedingungen zur lokalen Zielfunktion hinzu, um die Konvergenzstabilität bei nicht-iid-Daten zu verbessern.
* FedOpt: Nutzt adaptive Optimierung (Adam) auf aggregierten Gradienten, um die Lernrate dynamisch anzupassen, um mit der Heterogenität der Clients umzugehen und die Konvergenz zu beschleunigen.
Um das gravierende Problem der Klassenungleichgewichte zu beheben, kombiniert die Studie Focal Loss, gewichtetes Zufallssampling und Gradientenakkumulation, um sicherzustellen, dass Trainingssignale von Minderheitsklassen nicht vernachlässigt werden. Gradientenbeschneidung (Maximum-Norm 1,0) gewährleistet eine stabile Konvergenz während des Trainings.
Die Leistungsfähigkeit des Modells wurde anhand der ausgewogenen Genauigkeit bewertet, wobei der Schwerpunkt auf der institutionsübergreifenden Generalisierungsfähigkeit lag, um die Robustheit des Modells bei der Konfrontation mit Daten aus verschiedenen Bildgebungsprotokollen und Patientenpopulationen zu testen.
Das föderierte Training zeigt hervorragende Ergebnisse an allen Standorten und lässt sich auf unbekannte Institutionen übertragen.
Um die Effektivität des föderierten Lernmodells zu überprüfen, führten die Forscher eine gemeinsame Evaluierung des Testdatensatzes und eine externe, verteilte Datengeneralisierungsevaluierung durch.
① Gemeinsame Testdatensatzauswertung
Das Modell wurde anhand eines gemeinsamen Datensatzes mit Daten zweier Kunden evaluiert; die Ergebnisse sind in der folgenden Tabelle dargestellt. Unterschiedliche Aggregationsmethoden zeigen signifikante Leistungsunterschiede über verschiedene Architekturen hinweg.
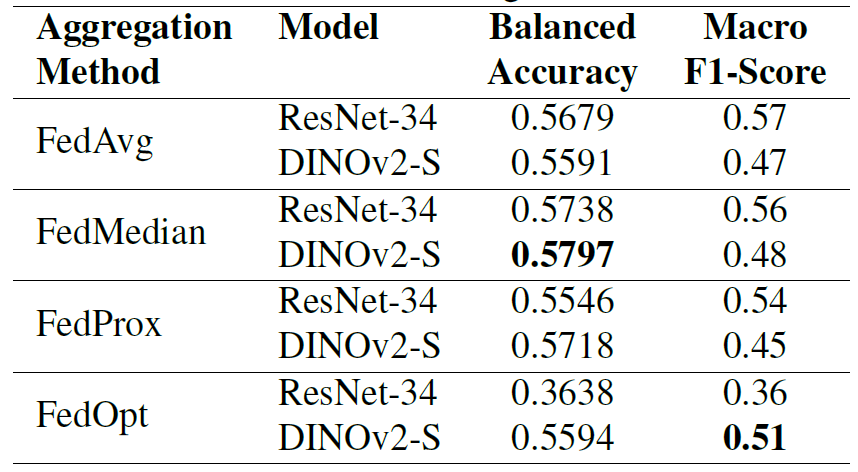
Es ist bemerkenswert, dass FedOpt extreme Volatilität aufweist: Auf ResNet-34 schneidet es sehr schlecht ab (ausgewogene Genauigkeit von 0,3638), während es auf DINOv2-S eine wettbewerbsfähige Leistung erbringt (ausgewogene Genauigkeit von 0,5594).Im Vergleich dazu zeigten FedAvg und FedProx auf beiden Modellen eine relativ stabile Leistung.FedMedian erzielte über beide Architekturen hinweg die konsistentesten Ergebnisse und erreichte eine ausgewogene Genauigkeit von 0,5738 für ResNet-34 und 0,5797 für DINOv2-S.
Die Ergebnisse zeigen, dass föderiertes Lernen die Leistung deutlich verbessert und die Vorteile des kollaborativen Trainings ohne Datenaustausch im Vergleich zu Modellen, die ausschließlich mit Daten einer einzelnen Institution trainiert wurden (58% vs. 52%, ausgeglichene Genauigkeit), verdeutlicht. Obwohl die föderierten Modelle etwas schlechter abschneiden als jene, die zentral mit allen Daten trainiert wurden, erreichen sie dennoch eine vergleichbare Genauigkeit bei gleichzeitig vollständiger Wahrung des Datenschutzes.
② Generalisierungsbewertung extern verteilter Daten
Evaluierungen anhand des externen Validierungsdatensatzes von Client 3 aus Barcelona zeigen, dass beide föderierten Methoden (FedMedian und FedOpt) das zentralisierte Training auf völlig unbekannten institutionellen Daten übertreffen (ausgewogene Genauigkeit 67% vs. 64%), wie in der folgenden Tabelle dargestellt. Dies deutet darauf hin, dass…Die Auseinandersetzung mit heterogenen institutionellen Gegebenheiten (wie Bildgebungsgeräten, Patientenpopulationen und Färbemethoden) während des föderierten Trainings hilft dem Modell, allgemeinere morphologische Merkmale zu erlernen.
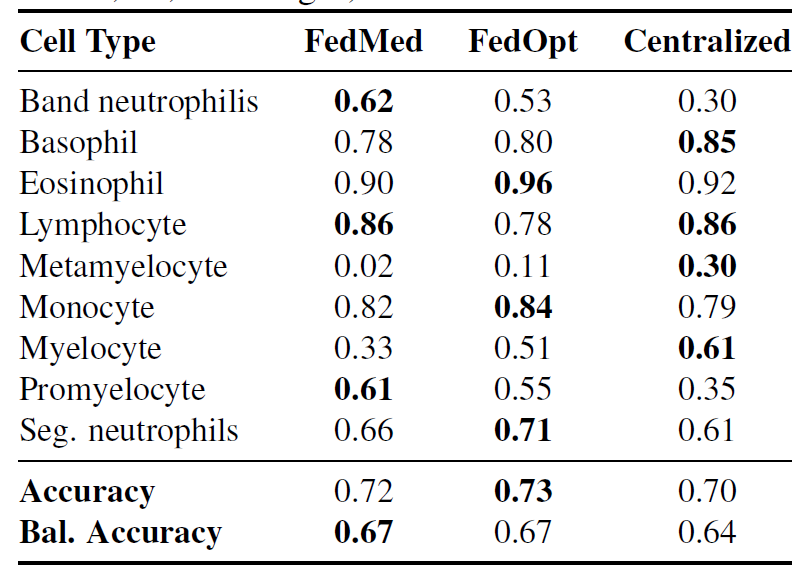
FedMedian zeigte besonders signifikante Verbesserungen bei einer Minderheit der Zelltypen: stabkernige Neutrophile F1: 0,62 vs. zentrale Neutrophile 0,30 (eine Steigerung um 1071 TP3T) und Promyelozyten F1: 0,61 vs. zentrale Neutrophile 0,35 (eine Steigerung um 741 TP3T).Die Ergebnisse zeigen, dass die diagnostischen Merkmale unter verschiedenen institutionellen Protokollen effektiv erhalten blieben.Die Identifizierung von Metamyelozyten bleibt jedoch für alle Methoden eine Herausforderung (F1: 0,02–0,30), was die grundsätzliche Schwierigkeit widerspiegelt, robuste Repräsentationen aus extrem seltenen Klassen zu lernen.
③ Das Wechselwirkungsgesetz zwischen Architektur und Aggregationsstrategie
Die Forscher identifizierten zudem wichtige Wechselwirkungen zwischen Architektur und Aggregationsstrategie: FedMedian bietet architekturübergreifende Robustheit, ist aber für seltene Klassen nachteilig; FedOpt erhält die Signalqualität von Zellen in Minderheitsklassen besser, reagiert aber architekturabhängig. Die vortrainierte Transformer-Architektur von DINOv2-S zeigt eine höhere Robustheit gegenüber nicht-iid-Datenverteilungen, während ResNet-34 empfindlicher auf Gradientenkonflikte reagiert.
Insgesamt positionieren diese Ergebnisse das föderierte Lernen als einen robusten, datenschutzfreundlichen und generalisierbaren Rahmen für die hämatologische Bildanalyse.
Föderiertes Lernen wird zum Schlüssel für den Abbau von „Datensilos“ im Gesundheitswesen.
Föderiertes Lernen ist ein kollaboratives Paradigma des maschinellen Lernens für verteilte Datenumgebungen. Sein Kernkonzept besteht darin, Modelle gemeinsam zu trainieren, ohne die Originaldaten zentral zu speichern. In einem föderierten Lernframework trainieren die teilnehmenden Institutionen (wie Krankenhäuser, Labore oder Forschungszentren) ihre Modelle lokal und laden lediglich Modellparameter oder Gradientenaktualisierungen auf einen zentralen Server hoch. Der Server aggregiert diese Aktualisierungen, generiert ein globales Modell und verteilt es zur weiteren iterativen Trainingsdurchführung an jeden Knoten. Durch diesen Mechanismus, bei dem „Daten in ihrem jeweiligen Bereich bleiben und Modelle zusammenarbeiten“,Föderiertes Lernen ermöglicht den institutionsübergreifenden Wissensaustausch und schützt gleichzeitig wirksam die Datenprivatsphäre und erfüllt strenge Datenschutzbestimmungen.
In den letzten Jahren haben viele Organisationen daran gearbeitet, wie das Gesundheitswesen durch föderiertes Lernen gestärkt werden kann. Ein typisches Beispiel ist Owkin, ein KI-Biotechnologieunternehmen, das umfassende Lösungen anbietet und zu den 20 bemerkenswertesten KI-Startups in Frankreich, einem der bemerkenswertesten Medizin- und Technologie-Startups 2023, dem Best Medical Technology Award und den Forbes AI 50 zählt.
Owkin arbeitet daran, KI-Technologien so einzusetzen, dass sie verschiedene Biomarker in multimodalen Patientendaten identifizieren, Patienten in Untergruppen einteilen, jeden Patienten dem besten Behandlungsziel zuordnen, die Entwicklung gezielter Medikamente fördern, Diagnoseinstrumente für Krankheiten optimieren und eine wirklich personalisierte Medizin erreichen können.Der Schlüssel zum Erreichen der oben genannten Ziele liegt darin, wie Daten weitergegeben und gleichzeitig der Datenschutz der Patienten gewährleistet werden kann.Um dieses Problem zu lösen, setzt Owkin auf föderiertes Lernen. Um die Verbreitung dieser Technologie zu fördern, hat Owkin seine Software für föderiertes Lernen, Substra, als Open Source veröffentlicht. Diese kann in der klinischen Forschung, der Arzneimittelentwicklung und anderen Anwendungsbereichen eingesetzt werden.
Open-Source-Adresse:
Im Bereich der medizinischen Bildgebung gilt föderiertes Lernen als Schlüsseltechnologie, um die Herausforderungen von Datensilos und Datenschutzbestimmungen zu bewältigen. Medizinische Bilddaten sind hochsensibel und berühren den Patientendatenschutz sowie strenge Vorschriften (wie DSGVO und HIPAA). Traditionelles, zentralisiertes Training stößt häufig auf praktische Hindernisse wie Ethikgenehmigungen, rechtliche Risiken und Beschränkungen des grenzüberschreitenden Datentransfers. Föderiertes Lernen ermöglicht es verschiedenen Krankenhäusern, Modelle gemeinsam zu trainieren, ohne Rohdaten auszutauschen. Dadurch wird die Generalisierungsfähigkeit des Modells über verschiedene Geräte, Färbeprotokolle und Patientenpopulationen hinweg verbessert.Bisherige Forschungsergebnisse haben gezeigt, dass föderiertes Lernen eine institutionsübergreifende Generalisierungsleistung erzielen kann, die der zentralisierten Ausbildung in Bereichen wie radiologischer Bildgebung, digitaler Pathologie und Ultraschallbildgebung nahe kommt oder diese sogar übertrifft.Es zeigt eine höhere Robustheit, insbesondere bei externen Datentests.
Aus einer umfassenderen Perspektive betrachtet, entwickelt sich das durch föderiertes Lernen repräsentierte Modell der „verteilten kollaborativen Intelligenz“ zu einer entscheidenden Infrastruktur für den großflächigen Einsatz medizinischer KI in der Zukunft. Es bietet nicht nur einen praktikablen Weg zum Training datenschutzkonformer, umfangreicher medizinischer Modelle, sondern legt auch den technologischen Grundstein für institutionsübergreifende klinische Entscheidungshilfesysteme und globale kollaborative medizinische Forschungsplattformen. In spezifischen Bereichen wie der Blutmorphologieanalyse wird erwartet, dass föderiertes Lernen die KI von Anwendungen in einzelnen Laboren hin zu regions- und systemübergreifenden intelligenten Diagnosediensten in klinischer Qualität vorantreibt und damit einen wichtigen Beitrag zur Präzisionsmedizin und zur digitalen Gesundheitsversorgung leistet.
Quellen:
1.https://arxiv.org/abs/2601.04121
2.https://mp.weixin.qq.com/s/Lf6N7EUHlhibLNc9YXWjTQ








