Command Palette
Search for a command to run...
NeurIPS 2025 | Das MIT Stellt AutoSciDACT Vor, Ein Automatisiertes Wissenschaftliches Entdeckungswerkzeug, Das Hochsensibel Auf Anomale Daten in Astronomie, Physik Und Biomedizin reagiert.

Im Laufe der Geschichte spielten Zufall und Zufall bei wissenschaftlichen Entdeckungen oft eine Rolle. So wurde beispielsweise Penicillin zufällig in einer verschimmelten Petrischale entdeckt, und die kosmische Mikrowellenhintergrundstrahlung entstand durch „abnormales Rauschen“, das von einer Antenne aufgefangen wurde. Diese unbeabsichtigten Beobachtungen erwiesen sich letztendlich als entscheidende Triebkräfte für den Fortschritt der menschlichen Zivilisation. In der heutigen datenintensiven Forschungswelt enthalten riesige Mengen interdisziplinärer Daten noch mehr ungewöhnliche und unerklärliche Beobachtungen, wodurch sich die Wahrscheinlichkeit zufälliger wissenschaftlicher Entdeckungen theoretisch vervielfacht. Paradoxerweise ist es jedoch weitaus schwieriger, aus komplexen und riesigen Forschungsdatenmengen präzise „neue Erkenntnisse“ zu gewinnen, als die Nadel im Heuhaufen zu finden.
Traditionelle wissenschaftliche Erkenntnismethoden stützen sich stark auf die Intuition und Expertise von Wissenschaftlern und erfordern einen komplexen Prozess aus Beobachtung, Forschung, Hypothesenbildung, Experimenten und Verifizierung, um den wahren wissenschaftlichen Wert einer „neuen Entdeckung“ zu bestimmen. Angesichts des exponentiellen Wachstums und der zunehmenden Komplexität wissenschaftlicher Daten ist es jedoch heute praktisch unmöglich, „neue Entdeckungen“ allein durch genaue Beobachtung zu identifizieren. Automatisierte wissenschaftliche Untersuchungsmethoden auf Basis künstlicher Intelligenz und großer Sprachmodelle haben sich in letzter Zeit zwar als vielversprechend erwiesen,Aufgrund des Fehlens eines integrierten Rahmens, der rigorose und automatisierte Hypothesentests und -verifizierungen ermöglicht,Selbst mit solchen Methoden bleibt es unvermeidlich, dass „der Wille zwar da ist, aber die Fähigkeit nicht ausreicht“.
Um den Herausforderungen der wissenschaftlichen Entdeckung zu begegnen, hat ein Team des MIT, der UW-Madison und des Instituts für Künstliche Intelligenz und Fundamentale Interaktionen (IAIFI) der National Science Foundation eine Methode namens AutoSciDACT (Automatisierte Wissenschaftliche Entdeckung mit anomalem Kontrasttest) vorgeschlagen.Es kann zur automatisierten Erkennung von „neuen Entdeckungen“ in wissenschaftlichen Daten verwendet werden und vereinfacht dadurch die wissenschaftliche Untersuchung.Die Forscher validierten die Methode anhand realer Datensätze aus den Bereichen Astronomie, Physik, Biomedizin und Bildgebung sowie anhand eines synthetischen Datensatzes und zeigten, dass die Methode in allen Bereichen hochsensibel auf geringe Mengen eingestreuter anomaler Daten reagiert.
Die zugehörigen Forschungsergebnisse mit dem Titel „AutoSciDACT: Automated Scientific Discovery through Contrastive Embedding and Hypothesis Testing“ wurden auf der NeurIPS 2025 veröffentlicht.
Forschungshighlights:
* AutoSciDACT ist ein durchgängiges, allgemeines Framework zur Erkennung der Neuartigkeit wissenschaftlicher Daten mit domänenübergreifender Übertragbarkeit;
* Es wurde ein systematischer Prozess entwickelt, indem wissenschaftliche Simulationsdaten, manuell gekennzeichnete Daten und Expertenwissen in einen vergleichenden Arbeitsablauf zur Dimensionsreduktion integriert wurden;
* Es wurde ein statistisch strenges Rahmenwerk entwickelt, um die Signifikanz der beobachteten Anomalien zu quantifizieren und festzustellen, ob die Anomalien aus statistischer Sicht wissenschaftliche Signifikanz besitzen;
* Die Ergebnisse wurden anhand realer Daten in vier deutlich unterschiedlichen wissenschaftlichen Bereichen validiert, was ihre signifikante Wirksamkeit, Überzeugungskraft und ihren Werbewert belegt.

Papieradresse:
https://openreview.net/forum?id=vKyiv67VWa
Folgen Sie dem öffentlichen Konto und antworten Sie auf „ AutoSciDACT Vollständiges PDF herunterladen
Weitere Artikel zu den Grenzen der KI:
https://hyper.ai/papers
Datensätze: Diverse, interdisziplinäre Datensätze bestätigen die überlegene Leistung von AutoSciDACT.
Um die überlegene Leistung von AutoSciDACT rigoros zu überprüfen,Die Forscher testeten es an fünf Datensätzen aus völlig unterschiedlichen Bereichen.Diese Datensätze umfassen Daten aus vier verschiedenen Bereichen: Astronomie, Physik, Biomedizin und Bildgebung sowie einen synthetisch erstellten Datensatz.
Bezüglich astronomischer Datensätze,Das Team wählte Gravitationswellendaten des Laser-Interferometer-Gravitationswellen-Observatoriums (LIGO) in Hanford, Washington, und Livingston, Louisiana, als astronomischen Referenzwert. Diese Daten umfassen den dritten Beobachtungslauf von April 2019 bis März 2020. Sie bestehen aus 50 Millisekunden langen Zeitreihensignalen von zwei Kanälen (ein Kanal pro Interferometer), abgetastet mit einer Frequenz von 4096 Hz (200 Messungen pro Kanal). Verschiedene Datenkategorien wurden berücksichtigt, darunter „reines Rauschen“, „Instrumenteninterferenzen“, „bekannte astrophysikalische Signale“ und ein verborgenes Signal namens „Weißrauschen-Burst (WNB)“ (als Anomalie). WNB-Signale wurden während des Vortrainings ausgeschlossen und anschließend in die Daten eingefügt, um zu testen, ob das Modell dieses unsichtbare Signal von den Gravitationswellensignalen unterscheiden kann.
PhysikdatensätzeDas Team wählte den JETCLASS-Datensatz als Benchmark für die Teilchenphysik. Dieser umfangreiche Datensatz enthält simulierte Jets aus Proton-Proton-Kollisionen am Large Hadron Collider (LHC). Die Studie nutzte eine Teilmenge dieses Datensatzes, die Jets aus Prozessen der Quantenchromodynamik (QCD) (Quark/Gluon), dem Zerfall des Top-Quarks (t → bqq′) und dem Zerfall des W/Z-Vektorbosons (V → qq′) umfasste. Signal-Jets aus dem Zerfall des verstärkten Higgs-Bosons in das Bottom-Quark (H → bb¯) wurden ebenfalls berücksichtigt. Als kontrastiven Encoder verwendete das Team den Particle Transformer (ParT), eine für die Teilchenphysik geeignete Variante der Transformer-Architektur.
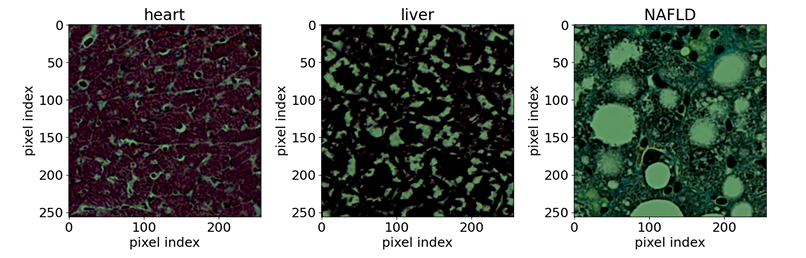
Im Bereich der Biomedizin,Das Team nutzte öffentlich zugängliche optische Mikroskopaufnahmen gefärbter Gewebeproben. Als Referenzproben dienten sieben verschiedene Mausgewebe (Gehirn, Herz, Niere, Leber, Lunge, Pankreas und Milz) sowie eine Art normales Rattenlebergewebe. Ziel der Studie war der Nachweis von durch nichtalkoholische Fettlebererkrankung (NAFLD) verursachten Anomalien im Mauslebergewebe. Die Eingangsproben bestanden aus Gewebeschnitten mit einer Auflösung von 256 × 256 Pixeln, die aus Ganzschnittbildern extrahiert und mit Masson-Trichrom gefärbt wurden. Als neuronales Netzwerk wurde EfficientNet-B0 verwendet.
Im Bereich der Bildwissenschaft,Das Team nutzte den CIFAR-10-Bilddatensatz (insgesamt 50.000 Bilder), wählte die erste Klasse zufällig als Anomalieklasse aus und trainierte das Modell mit den verbleibenden neun Klassen vor. In der Entdeckungsphase ergänzte das Team den CIFAR-10-Testdatensatz um 100.000 Bilder aus CIFAR-5m, wodurch die Anzahl der für Hypothesentests verfügbaren Datenpunkte erhöht wurde. Das Encoder-Backbone basierte auf einem ResNet-50 mit vortrainierten Gewichten. Lediglich die letzte vollständig verbundene Schicht wurde durch ein etwas größeres MLP ersetzt und dieses anhand der kontrastiven Einbettungsaufgabe von CIFAR feinabgestimmt.
Bezüglich synthetischer DatensätzeDas Hauptziel ist die Demonstration der Kernfunktionen von AutoSciDACT und der Nachweis, dass es von spezifischen Details realer wissenschaftlicher Datensätze unbeeinflusst bleibt. Der synthetische Datensatz besteht aus X⊂R^D+M und enthält D sinnvolle und M verrauschte Dimensionen. Die verrauschten Dimensionen werden gleichverteilt zwischen 0 und 1 generiert, während die sinnvollen Dimensionen aus N Gaußschen Clustern mit einem Mittelwert zwischen 0 und 1 und zufällig generierten Kovarianzen (gleichverteilt zwischen 0 und 0,5) bestehen. Anschließend werden alle Dimensionen zufällig rotiert, um die ursprünglichen, effektiven Diskriminierungsvariablen zu verbergen. Das Training erfolgt mittels eines kontrastiven Einbettungsverfahrens, wobei nur N-1 Cluster als Trainingsdaten verwendet werden und ein Cluster als zu detektierendes „Signal“ reserviert wird. Als Basismodell für das Training dient ein einfaches mehrschichtiges Perzeptron (MLP).
Zusätzlich wurden weitere Datensätze zur Validierung herangezogen, darunter Genomdaten zur Identifizierung von Schmetterlingshybriden und reale Daten zum Zerfall von Tetraleptonen im LHC-Higgs-Boson, um die domänenübergreifende Generalisierungsfähigkeit des Modells weiter zu überprüfen. Zusammenfassend lässt sich sagen, dass diese verschiedenen Datensätze alle aus Hintergrunddaten und Daten mit abnormalen Signalen erstellt wurden und sowohl für das Vortraining des Modells als auch für die Überprüfung seiner Fähigkeit, Neuheiten zu erkennen, verwendet wurden. Die Validierungsergebnisse belegen die Effektivität von AutoSciDACT als allgemeines Verfahren zur Erkennung von Neuheiten in wissenschaftlichen Daten sowie seine domänenübergreifende Generalisierungsfähigkeit.
Modellarchitektur: Ein zweistufiger Prozess aus „Vortraining“ und „Entdeckung“ schafft neue Methoden für wissenschaftliche Erkenntnisse
Der Kern von AutoSciDACT besteht aus zwei Schritten: „Vortraining – Entdeckung“.Durch die Kombination von niedrigdimensionaler Merkmalseinbettung mit statistischen Tests können wir statistisch signifikante „neue Signale“ aus hochdimensionalen wissenschaftlichen Daten extrahieren.
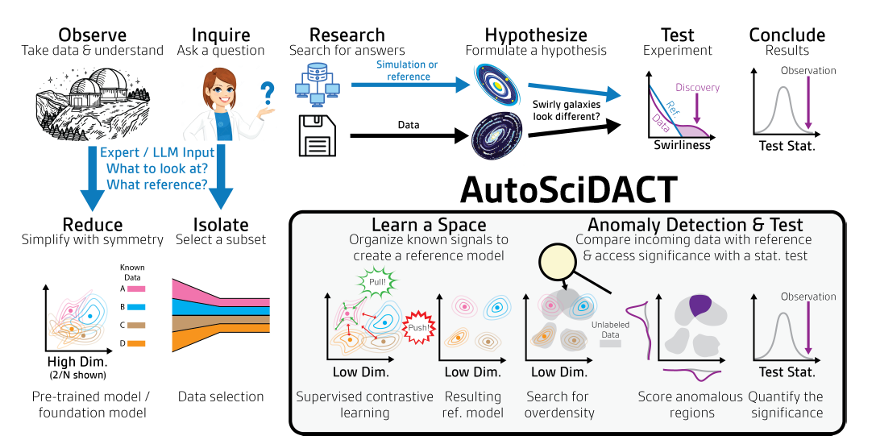
Die Vortrainingsphase befasst sich insbesondere mit dem Problem der Redundanz hochdimensionaler Daten. Sie komprimiert die Hunderte oder Tausende von Dimensionen der Eingabemerkmale, die in den ursprünglichen wissenschaftlichen Daten enthalten sein können, in niedrigdimensionale Vektoren, wobei die wichtigsten semantischen Merkmale der Daten – also die Kerninformationen im wissenschaftlichen Sinne – erhalten bleiben und somit die Grundlage für die nachfolgende Analyse geschaffen wird.
Die vortrainierte Pipeline basiert auf einem Encoder fθ : X → Rᵈ, der mittels kontrastiven Lernens trainiert wird und die Rohdaten aus dem hochdimensionalen Eingaberaum X auf eine niedrigdimensionale Repräsentation in Rᵈ abbildet. Das kontrastive Ziel ist darauf ausgelegt, die Übereinstimmung zwischen ähnlichen Eingaben (positiven Paaren) zu maximieren und gleichzeitig unähnliche Eingaben (negative Paare) im Lernraum zu trennen. Das zugrundeliegende Framework verwendet SimCLR, welches den Encoder fθ und den Projektionskopf gϕ trainiert.Nach dem Training wird nur der Encoder fθ beibehalten, um das endgültige niedrigdimensionale Embedding auszugeben.In der Praxis wird überwachtes kontrastives Lernen (SupCon) eingesetzt. Dabei werden gelabelte Trainingsdaten verwendet, um positive Paare derselben Klasse und negative Paare verschiedener Klassen zu erstellen. Die Verlustfunktion ist der SupCon-Verlust. Strategien zur Datenerweiterung können entwickelt werden, indem Domänenwissen einbezogen wird, um die Erstellung positiver Paare zu ergänzen. Zusätzlich kann optional der überwachte Kreuzentropie-Verlust (LCE) hinzugefügt werden, was zu einem Gesamtverlust von L = LSupCon + λCELCE führt (wobei λCE zwischen 0,1 und 0,5 liegt, um sicherzustellen, dass die Klassifizierung nicht dominiert).
In der Entdeckungsphase werden die im vorherigen Schritt erhaltenen niedrigdimensionalen Einbettungen innerhalb des NPLM-Frameworks (New Physics Learning Machine) zur Anomalieerkennung und zum Hypothesentest verwendet.Suchen Sie in den Daten nach potenziellen „neuen Signalen“ und quantifizieren Sie deren Signifikanz durch statistische Tests.
In dieser Phase verwenden die Forschenden Einbettungsvektoren fθ, um unbekannte Datensätze zu verarbeiten und nach anomalen Clustern, Dichteverzerrungen oder Ausreißern zu suchen, die von der Hintergrundverteilung im niedrigdimensionalen Raum abweichen. Der Suchprozess verwendet einen klassischen wissenschaftlichen Hypothesentest, indem er einen Referenzdatensatz R mit bekanntem Hintergrund mit einem beobachteten Datensatz D unbekannter Zusammensetzung vergleicht. Dabei wird versucht, die Nullhypothese, dass R und D die gleiche Verteilung aufweisen, anzunehmen oder zu verwerfen. Die Hypothese wird mithilfe des NPLM-Algorithmus (basierend auf dem klassischen Likelihood-Ratio-Test von Neyman et al.) getestet.In Kombination mit ausdrucksstarken, gelernten Einbettungsvektoren reagiert dieses Modell äußerst empfindlich auf neuartige Signale.
Es ist wichtig zu beachten, dass die Dimensionsreduktion während des Vortrainings entscheidend ist, da die Effektivität statistischer Testverfahren, einschließlich NPLM, mit zunehmender Datendimensionalität deutlich abnimmt. Anders ausgedrückt: Höhere Dimensionalität erfordert eine größere Stichprobe, um statistisch signifikante kleine Signale zu erkennen. In der praktischen Forschung reicht die Stichprobengröße jedoch häufig nicht aus, um diese Anforderungen zu erfüllen. Daher können Verfahren wie NPLM nur durch die Komprimierung hochdimensionaler Daten effektiv funktionieren, statistisch signifikante Anomalien aufdecken und somit ihren wissenschaftlichen Wert steigern.
Experimentelle Ergebnisse: Multidimensionale und domänenübergreifende Vergleiche unterstreichen die Übertragbarkeit und die domänenübergreifenden Fähigkeiten von AutoSciDACT.
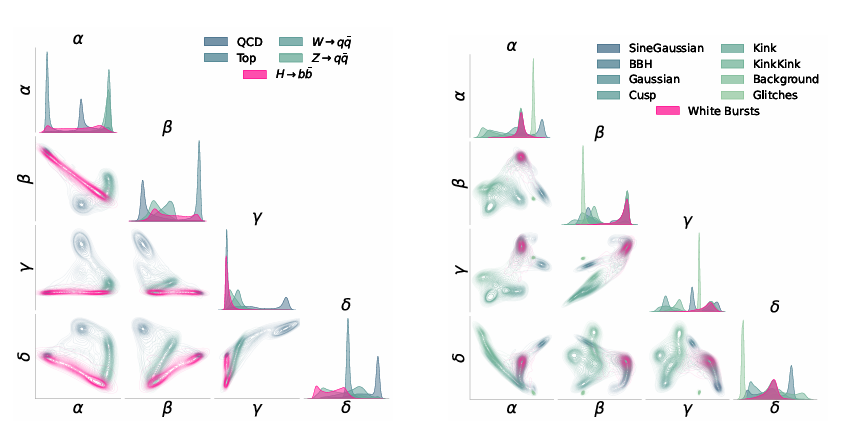
Die Forscher trainierten und evaluierten AutoSciDACT auf jedem Datensatz mit der gleichen Methode und nahmen während der Vortrainingsphase nur geringfügige Anpassungen vor, um den spezifischen Anforderungen jedes Datensatzes gerecht zu werden.
Alle Encoder haben eine Einbettungsdimension von d=4. Die Einbettungsergebnisse werden wie in der folgenden Abbildung dargestellt visualisiert.Darüber hinaus wurden im Rahmen des Experiments drei Arten von Vergleichs-Benchmarks eingerichtet: ein überwachtes Benchmark, ein ideales überwachtes Benchmark und die Mahalanobis-Baseline.
Wie die Abbildung unten zeigt, belegen die Ergebnisse, dass NPLM hochsignifikante Verzerrungen (Z≳3 oder p≲10⁻³) mit Signalanteilen bis hinunter zu 11TP³T erkennen kann. Zwei überwachte Baselines, die die Signalverteilung im Einbettungsraum vollständig verstehen, liefern eine sinnvolle Obergrenze für die Signalempfindlichkeit, und in einigen Fällen nähert sich die Leistung von NPLM dieser Grenze an. Oberhalb von etwa 5σ verlieren einige Trends ihre Gültigkeit, aber auf diesem Signifikanzniveau (p∼10⁻⁷) sind die Ergebnisse maschinell definiert.
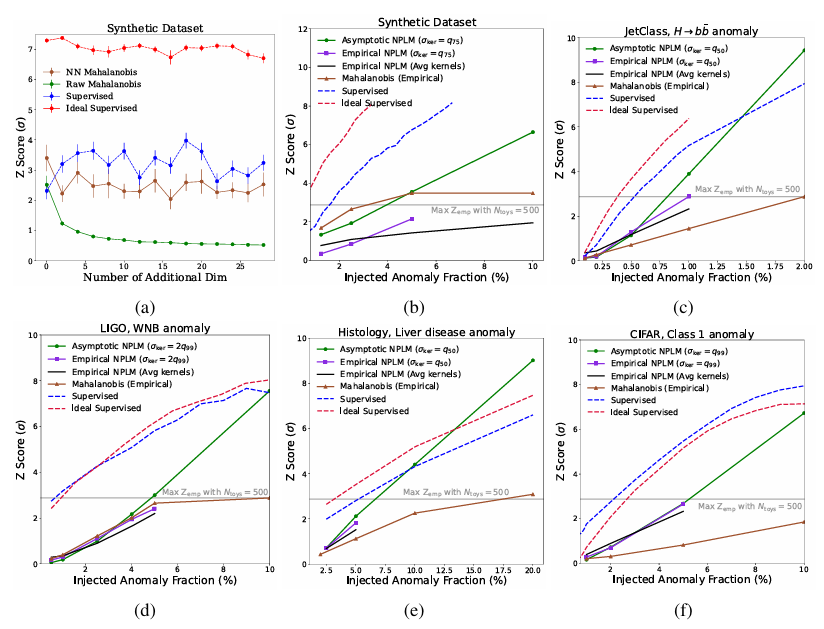
Zusätzlich zu synthetischen DatenIn allen anderen Datensätzen ist NPLM dem Mahalanobis-Distanz-Baseline deutlich überlegen.Dies liegt daran, dass es in der Lage ist, verschiedene Verzerrungen im Eingangsraum zu modellieren.
Für die LIGO- und JETClass-Datensätze nähert sich die vorgeschlagene Methode mit einem Z-Score von 3 der oberen Grenze des überwachten Lernens an. Dies ist vergleichbar mit oder übertrifft sogar alle Anomalieerkennungsalgorithmen in ihren jeweiligen Fachgebieten. Während in der Astronomie und Teilchenphysik statistisch entwickelte Anomalieerkennungstechniken schon lange Anwendung finden, demonstriert deren Anwendung in der Histologie die methodische Übertragbarkeit zwischen verschiedenen wissenschaftlichen Disziplinen.
In histologischer Hinsicht,Experimente zeigen, dass der mithilfe von Labelinformationen konstruierte Einbettungsraum dem ausschließlich auf Datenerweiterung basierenden Einbettungsraum überlegen ist.Mithilfe von AutoSciDACT haben Forscher eine neue Methode entwickelt, die lokalisierte Anomalien erkennen kann, die möglicherweise nur in kleinen Gewebebereichen auftreten. Diese Fähigkeit ist entscheidend für die Früherkennung von Krankheiten und unterstützt Pathologen bei der Identifizierung toxischer Substanzen.
Im Zeitalter des explosionsartigen Datenwachstums sind „KI-Wissenschaftler“ Realität geworden.
Die KI-Welle rollt unaufhaltsam voran und droht, alles zu verändern. Die wissenschaftliche Forschung, die Speerspitze der Wissenschaftsentwicklung, erfährt unter dem Einfluss der KI beispiellose Veränderungen und wird zu einem Kernbereich, der von der KI-Welle grundlegend umgestaltet wird.
Zusätzlich zu AutoSciDACT, das in der oben genannten Arbeit erwähnt wurde.Im selben Forschungsfeld haben Teams von Google, der Stanford University und anderen Institutionen auch KI-gestützte Co-Wissenschaftler vorgeschlagen, die menschliche Wissenschaftler imitieren können.Es kann Ideen generieren, diskutieren, hinterfragen, optimieren und verbessern – genau wie ein Mensch. Konkret handelt es sich um ein Multiagentensystem, das auf Gemini 2.0 basiert und Wissenschaftlern dabei helfen kann, neue und originelle Erkenntnisse zu gewinnen und, auf Grundlage vorhandener Daten und in Verbindung mit den Forschungszielen und -vorgaben des Science Journals, nachweislich innovative Forschungshypothesen und Lösungen zu entwickeln.
Titel des Artikels:Auf dem Weg zu einem KI-Co-Wissenschaftler
Papieradresse:https://arxiv.org/abs/2502.18864
Darüber hinaus erweitert sich die Fähigkeit der KI, wissenschaftliche Forschung zu betreiben, stetig und geht sogar von „automatischem Denken über die Erforschung von Elektronen“ bis hin zum „Verfassen vollständiger wissenschaftlicher Arbeiten“. Ein Team der Universitäten Oxford und Columbia hat einen solchen KI-Wissenschaftler vorgeschlagen.Dies ist das erste umfassende Rahmenwerk für die vollautomatische wissenschaftliche Forschung.Dies ermöglicht es hochentwickelten, großen Sprachmodellen, selbstständig Forschung zu betreiben und ihre Ergebnisse zu verbreiten. Vereinfacht gesagt: Dieser KI-Wissenschaftler kann neue Forschungsideen generieren, Code schreiben, Experimente durchführen, Ergebnisse visualisieren, seine Erkenntnisse in vollständigen wissenschaftlichen Artikeln beschreiben und anschließend ein simuliertes Peer-Review-Verfahren zur Bewertung durchführen.
Titel des Artikels:Der KI-Wissenschaftler: Auf dem Weg zu vollautomatisierter, ergebnisoffener wissenschaftlicher Entdeckung
Papieradresse:https://arxiv.org/abs/2408.06292
Im ersten Halbjahr dieses Jahres wurde AI Scientist einem wichtigen Upgrade unterzogen und zu AI Scientist-v2 weiterentwickelt. Im Vergleich zum Vorgänger,AI Scientist-v2 ist nicht mehr auf für Menschen portierbare Codevorlagen angewiesen; es kann effektiv über verschiedene Bereiche des maschinellen Lernens generalisieren.Es verwendet eine neuartige, progressive Agentenbaum-Suchmethode, die von einem dedizierten Prozessmanagement-Agenten gesteuert wird, und integriert eine Feedbackschleife eines visuellen Sprachmodells (VLM), um die KI-Review-Komponente zu verbessern und Inhalt und Ästhetik der Grafiken iterativ zu optimieren. Die Forscher evaluierten AI Scientist-v2, indem sie drei vollständig selbstverfasste Manuskripte bei einem Peer-Review-Workshop der ICLR einreichten – mit äußerst positiven Ergebnissen. Ein Manuskript erreichte eine Punktzahl, die die durchschnittliche menschliche Bewertungsschwelle übertraf. Dies ist das erste Mal, dass ein vollständig KI-generiertes Paper das Peer-Review-Verfahren erfolgreich bestanden hat.
Titel des Artikels:Der KI-Wissenschaftler-v2: Automatisierte wissenschaftliche Entdeckung auf Workshop-Niveau mittels agentenbasierter Baumsuche
Papieradresse:https://arxiv.org/abs/2504.08066
Es ist offensichtlich, dass KI und wissenschaftliche Forschung sich zunehmend integrieren und weiterentwickeln – von der Unterstützung bei der Hypothesenformulierung bis hin zur vollständig autonomen wissenschaftlichen Forschung und von der domänenspezifischen Verifizierung bis hin zu breiten interdisziplinären Anwendungen. Diese Systeme überwinden nicht nur die Effizienzgrenzen traditioneller wissenschaftlicher Forschung, sondern treiben auch den Wandel von erfahrungsbasierter zu datenbasierter Forschung voran. Mit der zukünftigen Realisierung des Mensch-Maschine-Kollaborationsmodells wird KI ein neues Kapitel effizienter Forschung für die Wissenschaftsgemeinschaft aufschlagen und gleichzeitig der globalen Zivilisation neue Impulse verleihen.








