Command Palette
Search for a command to run...
Speicherverbrauch Um Bis Zu 751 TP3T Reduziert: Wissenschaftler Des US-Energieministeriums Haben Die D-CHAG-Methode Vorgeschlagen, Eine Kanalübergreifende Hierarchische Aggregationsmethode, Um Die Ausführung Extrem Großer Modell-Mehrkanal-Datensätze Zu ermöglichen.

Bildbasierte wissenschaftliche Grundlagenmodelle bergen ein immenses Potenzial für wissenschaftliche Entdeckungen und Innovationen, vor allem aufgrund ihrer Fähigkeit, Bilddaten aus verschiedenen Quellen (z. B. unterschiedlichen physikalischen Beobachtungsszenarien) zu aggregieren und mithilfe der Transformer-Architektur raumzeitliche Korrelationen zu lernen. Die Tokenisierung und Aggregation von Bildern ist jedoch rechenintensiv, und bestehende verteilte Verfahren wie Tensorparallelität (TP), Sequenzparallelität (SP) oder Datenparallelität (DP) haben diese Herausforderung bisher nicht ausreichend bewältigt.
In diesem ZusammenhangForscher des Oak Ridge National Laboratory des US-Energieministeriums haben eine verteilte, kanalübergreifende hierarchische Aggregationsmethode (D-CHAG) für Basismodelle vorgeschlagen.Dieses Verfahren verteilt den Tokenisierungsprozess und nutzt eine hierarchische Strategie zur Kanalaggregation, wodurch extrem große Modelle auf Mehrkanal-Datensätzen ausgeführt werden können. Forscher evaluierten D-CHAG anhand von Aufgaben in der Hyperspektralbildgebung und Wettervorhersage und stellten fest, dass die Kombination dieses Verfahrens mit Tensorparallelität und Modellsharding den Speicherbedarf auf dem Supercomputer Frontier um bis zu 751 TP3T reduzierte und auf bis zu 1.024 AMD-GPUs eine nachhaltige Durchsatzsteigerung von mehr als dem Doppelten erzielte.
Die entsprechenden Forschungsergebnisse mit dem Titel „Verteilte kanalübergreifende hierarchische Aggregation für Foundation-Modelle“ wurden in SC25 veröffentlicht.
Forschungshighlights:
* D-CHAG löst die Probleme des Speicherengpasses und der Recheneffizienz beim Training von Mehrkanal-Basismodellen.
* Im Vergleich zur alleinigen Verwendung von TP kann D-CHAG eine Reduzierung des Speicherbedarfs um bis zu 70% erreichen und unterstützt somit ein effizienteres Training von Modellen im großen Maßstab.
* Die Leistungsfähigkeit von D-CHAG wurde anhand zweier wissenschaftlicher Arbeitslasten validiert: Wettervorhersage und Vorhersage der Maskierung hyperspektraler Pflanzenbilder.
Papieradresse:
https://dl.acm.org/doi/10.1145/3712285.3759870
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „cross-channel“, um das vollständige PDF zu erhalten.
Verwendung zweier typischer Mehrkanal-Datensätze
In dieser Studie wurden zwei typische Mehrkanal-Datensätze verwendet, um die Effektivität der D-CHAG-Methode zu validieren:Hyperspektrale Bilder von Pflanzen und der meteorologische Datensatz ERA5.
Die für die selbstüberwachte Maskenvorhersage verwendeten hyperspektralen Bilddaten der Pflanzen wurden vom Advanced Plant Phenotyping Laboratory (APPL) des Oak Ridge National Laboratory (ORNL) erhoben.Der Datensatz umfasst 494 hyperspektrale Bilder von Pappeln, die jeweils 500 Spektralkanäle im Wellenlängenbereich von 400 nm bis 900 nm enthalten.
Dieser Datensatz wird primär in der Biomasseforschung eingesetzt und ist eine wichtige Ressource für die Pflanzenphänotypisierung und Bioenergieforschung. Die Bilder dienen dem maskierten, selbstüberwachten Training, wobei Bildausschnitte als Token für die Maskierung verwendet werden. Das Modell soll fehlende Inhalte vorhersagen und so die zugrundeliegende Datenverteilung der Bilder erlernen. Bemerkenswert ist, dass dieser Datensatz keine vortrainierten Gewichte verwendet und vollständig durch selbstüberwachtes Lernen trainiert wird. Dies unterstreicht die Anwendbarkeit von D-CHAG bei selbstüberwachten Aufgaben mit vielen Kanälen.
Auch,Im Rahmen des Wettervorhersageexperiments nutzte das Forschungsteam den hochauflösenden Reanalysedatensatz ERA5.Die Studie wählte fünf atmosphärische Variablen (geopotentielle Höhe, Temperatur, u-Komponente der Windgeschwindigkeit, v-Komponente der Windgeschwindigkeit und spezifische Feuchte) sowie drei Oberflächenvariablen (Temperatur in 2 m Höhe, u-Komponente der Windgeschwindigkeit in 10 m Höhe und v-Komponente der Windgeschwindigkeit in 10 m Höhe) aus, die mehr als zehn Druckschichten abdecken und insgesamt 80 Eingangskanäle generieren. Zur Anpassung an das Modelltraining wurden die ursprünglichen Daten mit einer Auflösung von 0,25° (770 × 1440) mithilfe des xESMF-Toolkits und eines bilinearen Interpolationsalgorithmus auf 5,625° (32 × 64) hochskaliert.
Die Aufgabe des Modells besteht darin, meteorologische Variablen für zukünftige Zeitpunkte vorherzusagen, wie zum Beispiel die geopotentielle Höhe in 500 hPa (Z500), die Temperatur in 850 hPa (T850) und die Windgeschwindigkeit in 10 m Höhe (U10), und damit die Leistungsfähigkeit der D-CHAG-Methode bei der Vorhersage von Zeitreihen zu überprüfen.
D-CHAG: Kombination hierarchischer Aggregation mit verteilter Tokenisierung
Kurz gesagt, die D-CHAG-Methode ist eine Fusion zweier unabhängiger Methoden:
Verteiltes Tokenisierungsverfahren
Während des Vorwärtsausbreitungsprozesses tokenisiert jeder TP-Rang nur eine Teilmenge der Eingangskanäle.Vor der Kanalaggregation muss eine AllGather-Operation ausgeführt werden, um Cross-Attention über alle Kanäle hinweg zu erreichen. Theoretisch kann diese Methode den Rechenaufwand für die Tokenisierung pro GPU reduzieren.
Hierarchische kanalübergreifende Aggregation
Der Hauptvorteil dieses Ansatzes liegt im geringeren Speicherbedarf pro Cross-Channel-Attention-Layer, da pro Layer weniger Kanäle verarbeitet werden.Eine Erhöhung der Anzahl der Schichten führt jedoch zu einer größeren Gesamtmodellgröße und einem höheren Speicherbedarf. Dieser Kompromiss ist bei Datensätzen mit vielen Kanälen vorteilhafter, da die standardmäßige kanalübergreifende Aufmerksamkeit einen höheren zusätzlichen Speicherbedarf verursacht.
Obwohl beide Methoden ihre Vorteile haben, weisen sie auch Nachteile auf. Beispielsweise verursacht die verteilte Tokenisierungsmethode einen hohen Kommunikationsaufwand zwischen den TP-Rängen und löst nicht das Problem des hohen Speicherverbrauchs auf Kanalebene; die hierarchische kanalübergreifende Aggregationsmethode hingegen erhöht die Anzahl der Modellparameter pro GPU. Die D-CHAG-Methode kombiniert beide Methoden verteilt, und die Gesamtarchitektur ist in der folgenden Abbildung dargestellt:
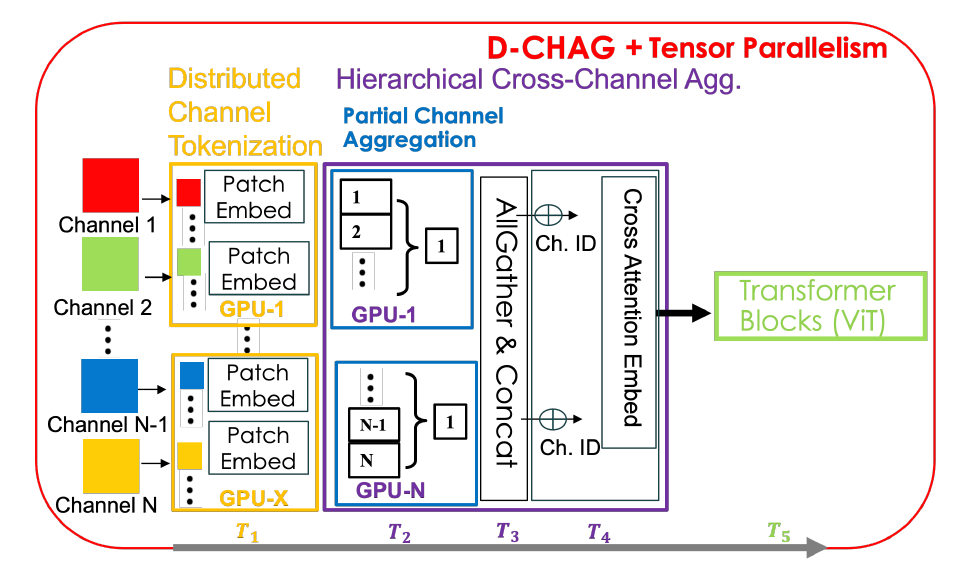
Speziell,Jeder TP-Rang tokenisiert die zweidimensionalen Bilder in der gesamten Kanal-Teilmenge.Da jede GPU nur eine Teilmenge aller Kanäle verarbeitet, erfolgt die Kanalaggregation lokal auf diesen Kanälen – dieses Modul wird als Modul für partielle Kanalaggregation bezeichnet. Nach Abschluss der Kanalaggregation innerhalb jedes TP-Rangs werden die Ausgaben gesammelt und die finale Aggregation mittels kanalübergreifender Aufmerksamkeit durchgeführt. Während der Vorwärtsausbreitung wird nur eine AllGather-Operation ausgeführt; während der Rückwärtsausbreitung werden nur die relevanten Gradienten für jede GPU gesammelt, wodurch zusätzliche Kommunikation vermieden wird.
Die D-CHAG-Methode kann die Vorteile der verteilten Tokenisierung und der hierarchischen Kanalaggregation voll ausschöpfen und gleichzeitig deren Nachteile abmildern.Durch die Verteilung der hierarchischen Kanalaggregation über die TP-Ränge hinweg reduzierten die Forscher die AllGather-Kommunikation auf die Verarbeitung nur eines einzigen Kanals pro TP-Rang. Dadurch entfiel jegliche Kommunikation während der Rückpropagation. Durch die Erhöhung der Modelltiefe behielten sie zudem den Vorteil der reduzierten Kanalverarbeitung pro Schicht bei und verteilten gleichzeitig zusätzliche Modellparameter über partielle Kanalaggregationsmodule auf die TP-Ränge.
Die Studie verglich zwei Implementierungsstrategien:
* D-CHAG-L (Lineare Schicht): Das hierarchische Aggregationsmodul verwendet eine lineare Schicht, die einen geringen Speicherbedarf aufweist und sich für Situationen mit einer großen Anzahl von Kanälen eignet.
* D-CHAG-C (Cross-Attention Layer): Verwendet eine Cross-Attention-Schicht, die einen höheren Rechenaufwand verursacht, aber die Leistung bei sehr großen Modellen oder extrem hohen Kanalzahlen deutlich verbessert.
Ergebnisse: D-CHAG unterstützt das Training größerer Modelle auf Datensätzen mit vielen Kanälen.
Nach der Konstruktion von D-CHAG validierten die Forscher die Leistungsfähigkeit des Modells und evaluierten anschließend dessen Leistungsfähigkeit bei Aufgaben der hyperspektralen Bildgebung und Wettervorhersage:
Modellleistungsanalyse
Die folgende Abbildung zeigt die Leistung von D-CHAG unter verschiedenen Konfigurationen des Moduls zur partiellen Kanalaggregation:
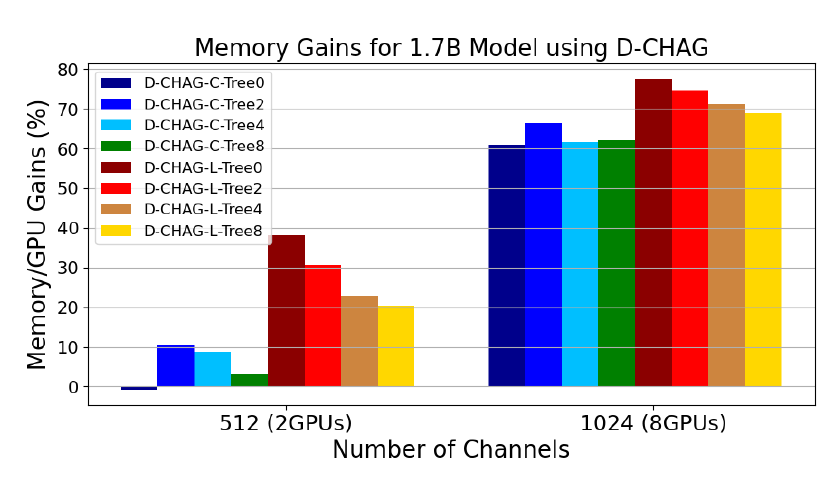
* Tree0 bedeutet, dass es in einigen Aggregationsmodulen nur eine Aggregationsebene gibt, Tree2 bedeutet zwei Ebenen usw.;
* Die Suffixe -C und -L geben die Art der verwendeten Schichten an: -C bedeutet, dass alle Schichten Cross-Attention sind, und -L bedeutet, dass alle Schichten linear sind.
Die Ergebnisse zeigen:
Bei 512-Kanal-Daten ist die Leistung bei Verwendung einer einschichtigen Cross-Attention-Schicht etwas geringer als die des Basismodells, kann aber bei 1024-Kanal-Daten um etwa 60% verbessert werden.
Mit zunehmender Tiefe der hierarchischen Struktur können selbst 512-Kanal-Daten deutliche Leistungsverbesserungen erzielen, während die Leistung von 1024-Kanal-Daten relativ stabil bleibt.
Die Verwendung linearer Schichten, selbst bei flacher Hierarchie, kann die Leistung bei Bildern mit 512 und 1024 Kanälen verbessern. Die beste Leistung erzielt D-CHAG-L-Tree0, das nur eine Kanalaggregationsschicht enthält. Zusätzliche Aggregationsschichten erhöhen die Anzahl der Modellparameter und den Speicherbedarf. Obwohl eine Erhöhung der Schichtanzahl bei 512 Kanälen vorteilhaft erscheint, ist die Verwendung einer einzigen linearen Schicht bei beiden Kanalgrößen überlegen.
Der D-CHAG-C-Tree0 hat bei zwei GPUs einen geringfügig negativen Einfluss auf die Leistung, kann aber bei einer Skalierung auf acht GPUs eine Leistungssteigerung von 60% erzielen.
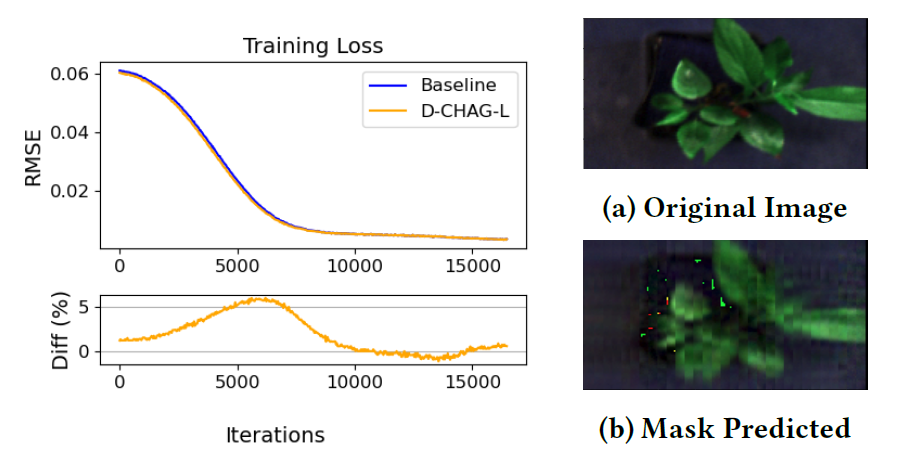
Selbstüberwachte Maskenvorhersage von hyperspektralen Pflanzenbildern
Die folgende Abbildung vergleicht den Trainingsverlust der Basismethode und der D-CHAG-Methode bei der Anwendung von Autoencodern für hyperspektrale Pflanzenbildmasken. Die Ergebnisse zeigen:Während des Trainings stimmt die Trainingsverlustleistung der Einzel-GPU-Implementierung weitgehend mit der des D-CHAG-Verfahrens (das auf zwei GPUs ausgeführt wird) überein.
Larry York, ein leitender Forscher in der Molekular- und Zellbildgebungsgruppe am Oak Ridge National Laboratory, sagte, dass D-CHAG Pflanzenwissenschaftlern helfen kann, Aufgaben wie die Messung der photosynthetischen Aktivität von Pflanzen direkt aus Bildern schnell zu erledigen und so zeitaufwändige und mühsame manuelle Messungen zu ersetzen.
Wettervorhersage
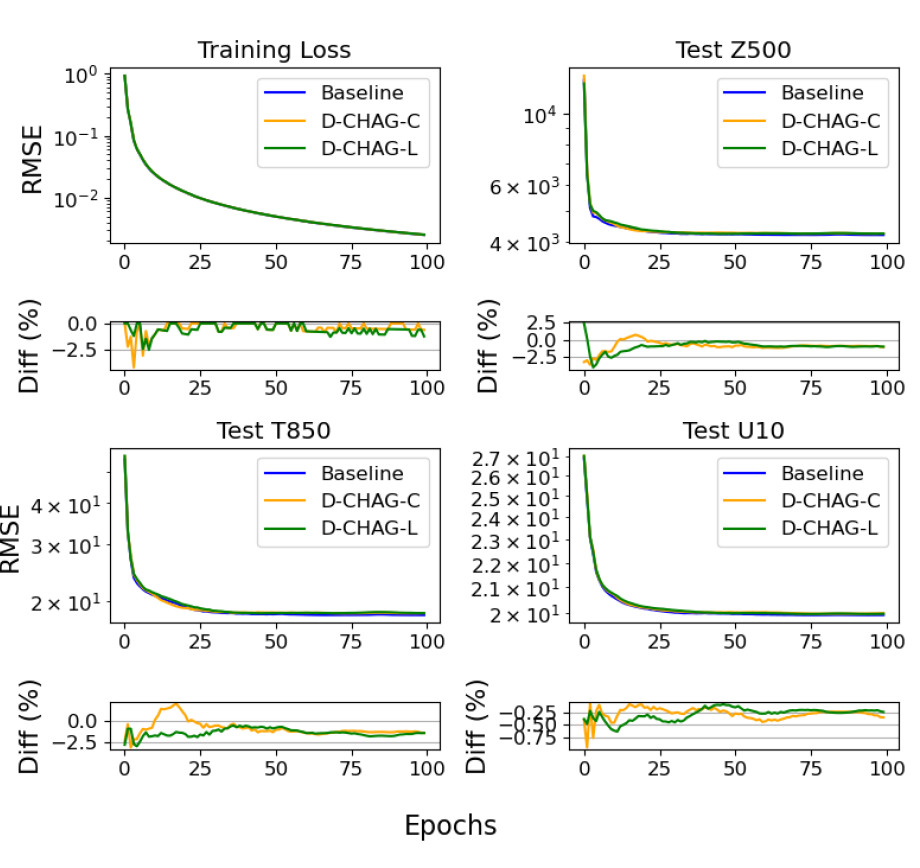
Forscher führten ein 30-tägiges Wettervorhersageexperiment mit dem ERA5-Datensatz durch. Die folgende Abbildung vergleicht den Trainingsverlust und den RMSE der drei Testvariablen der Basismethode und der D-CHAG-Methode in Wettervorhersageanwendungen:
Die Tabelle unten zeigt den abschließenden Vergleich des Modells bei Vorhersageaufgaben für 7, 14 und 30 Tage, einschließlich RMSE, MSE und Pearson-Korrelationskoeffizient (wACC).
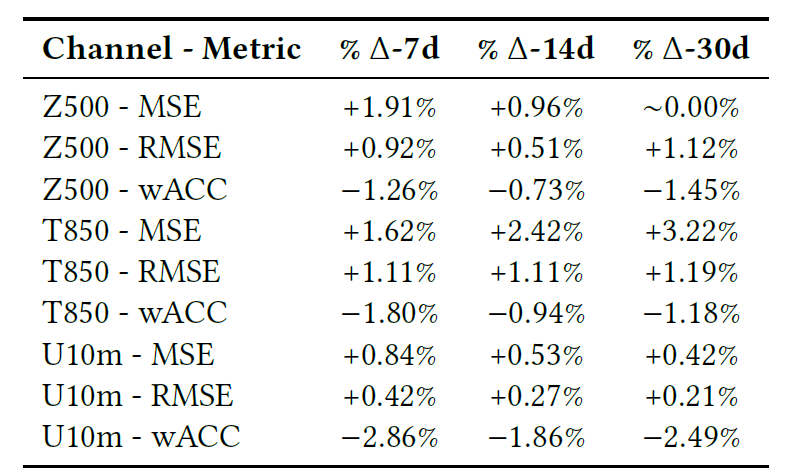
Insgesamt lässt sich anhand der Grafiken und Tabellen feststellen, dass der Trainingsverlust weitgehend mit dem Basismodell übereinstimmt und die Abweichungen der verschiedenen Indikatoren minimal sind.
Leistungsskalierung mit der Modellgröße
Die folgende Abbildung zeigt die Leistungsverbesserung der D-CHAG-Methode im Vergleich zur alleinigen Verwendung von TP für drei Modellgrößen mit Kanalkonfigurationen, die TP erfordern:
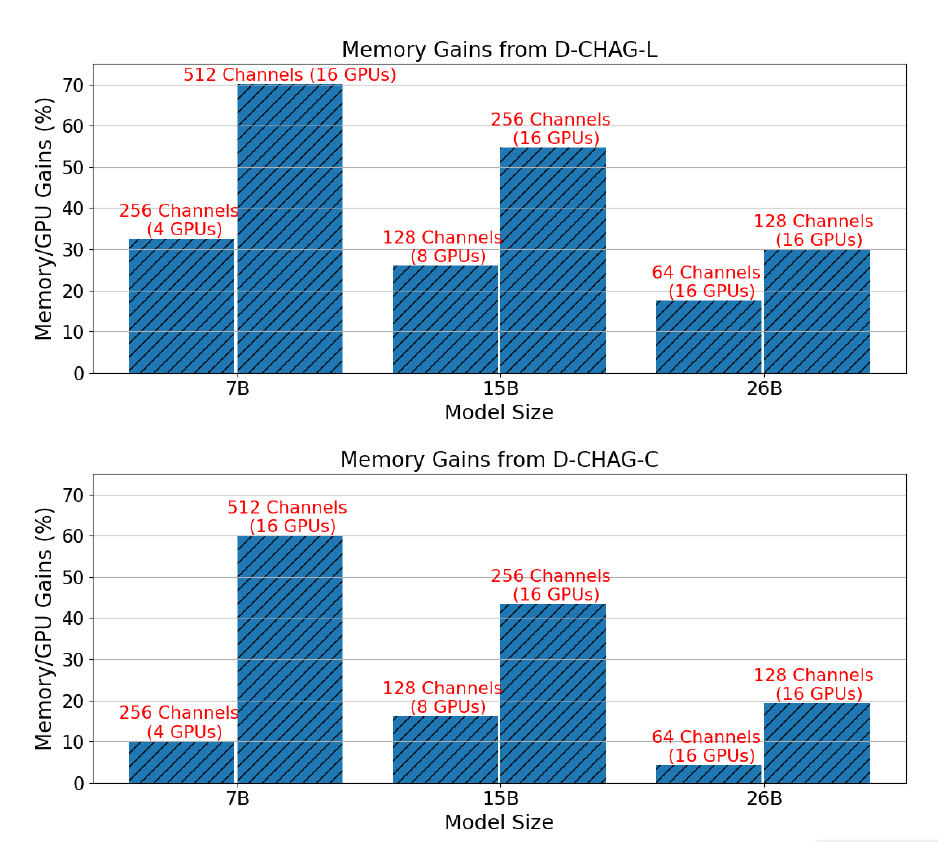
Die Ergebnisse zeigen, dassFür das 7B-Parametermodell,Durch den Einsatz linearer Schichten im Modul zur partiellen Kanalaggregation kann eine Leistungsverbesserung von 30% auf 70% erzielt werden, während durch den Einsatz von Cross-Attention-Schichten eine Verbesserung von 10% auf 60% erzielt werden kann.Für das 15B-Parametermodell,Die Leistungsverbesserungen übersteigen 20% bis 50%;Die Leistungsverbesserung des 26B-Parametermodells liegt zwischen 10% und 30%.
Darüber hinaus wird die Leistungsverbesserung bei gleichbleibender Modellgröße mit zunehmender Kanalanzahl deutlicher. Dies liegt daran, dass bei gegebener Architektur die Erhöhung der Kanalanzahl zwar nicht den Rechenaufwand des Transformer-Blocks erhöht, jedoch die Arbeitslast der Tokenisierungs- und Kanalaggregationsmodule.
Andererseits kann TP allein keine Bilder mit 26 Parametern und 256 Kanälen trainieren, aber die D-CHAG-Methode kann ein Modell mit 26 Parametern und 512 Kanälen mit weniger als 80% verfügbarem Speicher trainieren - dies zeigt, dass die Methode das Training größerer Modelle auf Datensätzen mit vielen Kanälen unterstützen kann.
ViT: Visuelle KI – Von Wahrnehmungsmodellen zu allgemeinen visuellen Grundlagenmodellen
Im letzten Jahrzehnt konzentrierten sich Computer-Vision-Modelle primär auf die Optimierung einzelner Aufgaben – Klassifizierung, Detektion, Segmentierung und Rekonstruktion entwickelten sich unabhängig voneinander. Da die Transformer-Architektur jedoch grundlegende Modelle wie GPT und BERT im Bereich der natürlichen Sprachverarbeitung hervorgebracht hat, vollzieht sich im Bereich der Bildverarbeitung ein ähnlicher Paradigmenwechsel: von aufgabenspezifischen Modellen hin zu universellen, grundlegenden Modellen. In diesem Zusammenhang gilt der Vision Transformer (ViT) als ein zentraler technologischer Eckpfeiler grundlegender Bildverarbeitungsmodelle.
Vision Transformer (ViT) führte als erstes die Transformer-Architektur vollständig in Aufgaben der Computer Vision ein. Die Kernidee besteht darin, ein Bild als Sequenz von Patch-Tokens zu behandeln und die lokale rezeptive Feldmodellierung von Convolutional Neural Networks durch einen Selbstaufmerksamkeitsmechanismus zu ersetzen. Konkret teilt ViT das Eingabebild in Patches fester Größe auf, ordnet jedem Patch ein Embedding-Token zu und modelliert anschließend die globalen Beziehungen zwischen den Patches mithilfe eines Transformer-Encoders.
Im Vergleich zu herkömmlichen CNNs bietet ViT besondere Vorteile für wissenschaftliche Daten: Es eignet sich für hochdimensionale Mehrkanaldaten (wie Fernerkundungsdaten, medizinische Bilder und Spektraldaten), kann nicht-euklidische räumliche Strukturen (wie Klimagitter und physikalische Felder) verarbeiten und eignet sich für die kanalübergreifende Modellierung (Kopplungsbeziehungen zwischen verschiedenen physikalischen Variablen), was auch das Kernthema des D-CHAG-Papiers ist.
Über die oben genannten Anwendungsfälle hinaus beweist ViT seinen Kernnutzen in noch mehr Bereichen. Im März 2025 entwickelte Dr. Han Gangwen, Chefarzt der Dermatologischen Abteilung des Peking University International Hospital, mit seinem Team den Deep-Learning-Algorithmus AcneDGNet. Dieser Algorithmus integriert visuelle Transformer und Convolutional Neural Networks (CNNs), um eine effizientere hierarchische Merkmalsmatrix zu erstellen und so eine präzisere Klassifizierung zu ermöglichen. Prospektive Studien zeigen, dass der Deep-Learning-Algorithmus von AcneDGNet nicht nur genauer ist als der von Assistenzärzten, sondern auch mit dem von erfahrenen Dermatologen vergleichbar. Er kann Akne-Läsionen präzise erkennen und ihren Schweregrad in verschiedenen medizinischen Szenarien bestimmen. So unterstützt er Dermatologen und Patienten effektiv bei der Diagnose und Behandlung von Akne – sowohl in Online-Sprechstunden als auch in Arztbesuchen.
Titel des Papiers:
Evaluierung eines Modells zur Erkennung und Schweregradeinteilung von Akne-Läsionen für die chinesische Bevölkerung in Online- und Offline-Gesundheitsversorgungsszenarien
Papieradresse:
https://www.nature.com/articles/s41598-024-84670-z
Aus Branchensicht markiert Vision Transformer einen entscheidenden Wendepunkt in der Entwicklung visueller KI – von Wahrnehmungsmodellen hin zu universellen visuellen Basismodellen. Seine einheitliche Transformer-Architektur bietet eine universelle Grundlage für multimodale Fusion, skalierbare Erweiterung und Systemoptimierung und macht visuelle Modelle damit zu einer Kerninfrastruktur für KI in der Wissenschaft. Zukünftig werden Parallelisierung, Speicheroptimierung und die Mehrkanal-Modellierungsfunktionen von ViT entscheidende Wettbewerbsfaktoren für die Geschwindigkeit und den Umfang des industriellen Einsatzes visueller Basismodelle sein.
Quellen:
1.https://phys.org/news/2026-01-empowering-ai-foundation.html
2.https://dl.acm.org/doi/10.1145/3712285.3759870
3.https://mp.weixin.qq.com/s/JvKQPbBQFhofqlVX4jLgSA








