Command Palette
Search for a command to run...
AI Paper Weekly Report | Ein Sonderbericht Über Spitzenforschung Im Bereich Transformer, Der Die Neuesten Fortschritte in Den Bereichen Strukturelle Sparsität, Speichermechanismen Und Organisation Des Denkens analysiert.

In den vergangenen acht Jahren hat Transformer die gesamte Landschaft der KI-Forschung grundlegend verändert. Seit Google diese Architektur 2017 in „Attention Is All You Need“ vorstellte, hat sich der „Aufmerksamkeitsmechanismus“ schrittweise von einer technischen Methode zu einem allgemeinen Paradigma für Deep Learning entwickelt – von der Verarbeitung natürlicher Sprache über Computer Vision und Sprach- und multimodales Rechnen bis hin zum wissenschaftlichen Rechnen. Transformer etabliert sich als de facto grundlegendes Modellframework.
Branchenakteure wie Google, OpenAI, Meta und Microsoft erweitern kontinuierlich die Grenzen von Skalierbarkeit und technischer Leistungsfähigkeit, während Universitäten wie Stanford, MIT und Berkeley stetig wichtige Ergebnisse in der theoretischen Analyse, strukturellen Verbesserungen und der Erforschung neuer Paradigmen erzielen. Angesichts der stetig wachsenden Modellgröße, der Trainingsparadigmen und Anwendungsbereiche zeigt die Forschung im Bereich der Transformer-Modelle eine hohe Differenzierung und rasante Entwicklung – eine systematische Überprüfung und Auswahl repräsentativer Publikationen ist daher besonders wichtig.
Um mehr Benutzer über die neuesten Entwicklungen im Bereich der künstlichen Intelligenz in der Wissenschaft zu informieren, wurde auf der offiziellen Website von HyperAI (hyper.ai) jetzt der Bereich „Neueste Artikel“ eingerichtet, in dem täglich hochmoderne KI-Forschungsartikel aktualisiert werden.
* Neueste KI-Veröffentlichungen:https://go.hyper.ai/hzChCDiese Woche haben wir für Sie sorgfältig 5 beliebte Artikel über Transformers ausgewählt.Teams der Peking-Universität, von DeepSeek, ByteDance Seed, Meta AI und anderen sind dabei. Lasst uns gemeinsam lernen! ⬇️
Die Zeitungsempfehlung dieser Woche
- Bedingtes Speichern durch skalierbares Nachschlagen: Eine neue Achse der Sparsität für große Sprachmodelle
Forscher der Peking-Universität und von DeepSeek-AI haben Engram entwickelt, ein skalierbares Modul für bedingten Speicher mit einer Suchkomplexität von O(1). Durch die Extraktion aus den frühen Schichten des statischen Wissensabruf-Transformers und dessen Ergänzung mit MoE werden diese Schichten für tiefergehende Inferenzberechnungen frei. Deutliche Verbesserungen wurden bei Inferenzaufgaben (BBH +5,0, ARC-Challenge +3,7), Code- und Mathematikaufgaben (HumanEval +3,0, MATH +2,4) sowie Aufgaben mit langem Kontext (Multi-Query NIAH: 84,2 → 97,0) erzielt, während die Anzahl der Parameter und die Anzahl der FLOPs gleich blieben.
Papier und detaillierte Interpretation:https://go.hyper.ai/SlcId
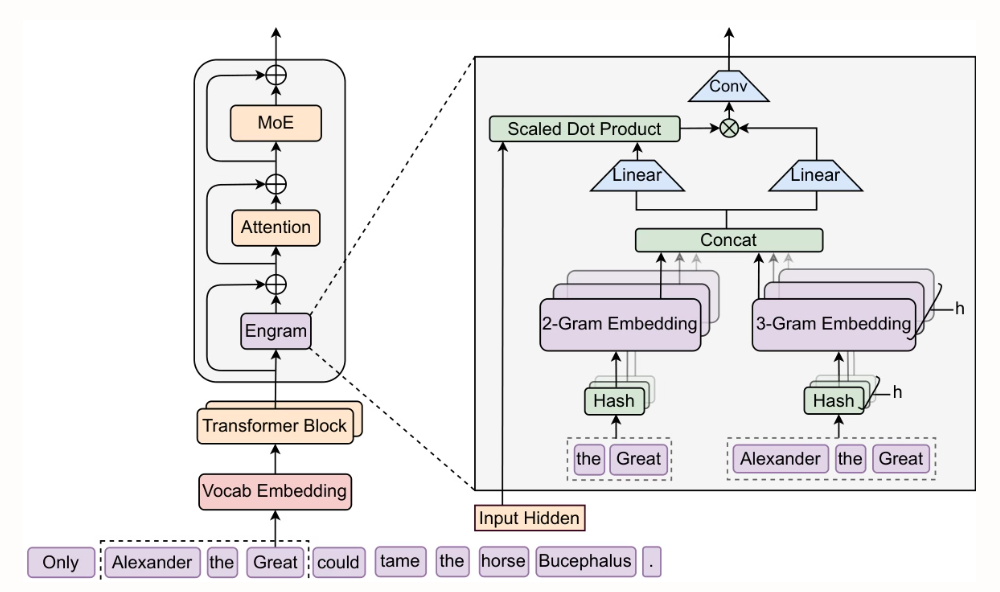
2. STEM: Skalierung von Transformatoren durch Einbettungsmodule
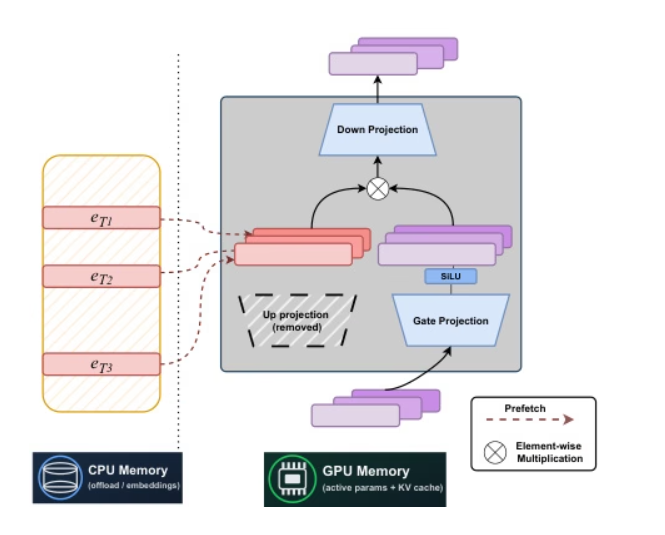
Forscher der Carnegie Mellon University und von Meta AI haben gemeinsam STEM, eine statische, labelindexbasierte Sparse-Architektur, entwickelt. Durch den Ersatz der Upprojektion von FFN durch Intra-Layer-Embedding-Lookup wird ein stabiles Training erreicht, wodurch die FLOPs pro Label und die Parameterzugriffe um etwa ein Drittel reduziert werden. Zudem wird die Performance bei längeren Kontexten durch skalierbare Parameteraktivierung verbessert. Durch die Entkopplung von Speicherkapazität, Berechnung und Kommunikation unterstützt STEM asynchrones Prefetching zur CPU-Entlastung, nutzt Embeddings mit großen Winkelverteilungen für eine höhere Wissensspeicherkapazität und ermöglicht die Einspeisung von interpretierbarem und editierbarem Wissen, ohne den Eingabetext zu verändern. In Benchmarks für Wissen und Schlussfolgerung erzielt STEM Leistungsverbesserungen von bis zu etwa 3–41 TP3T im Vergleich zu dichten Baselines.
Papier und detaillierte Interpretation:https://go.hyper.ai/NPuoj
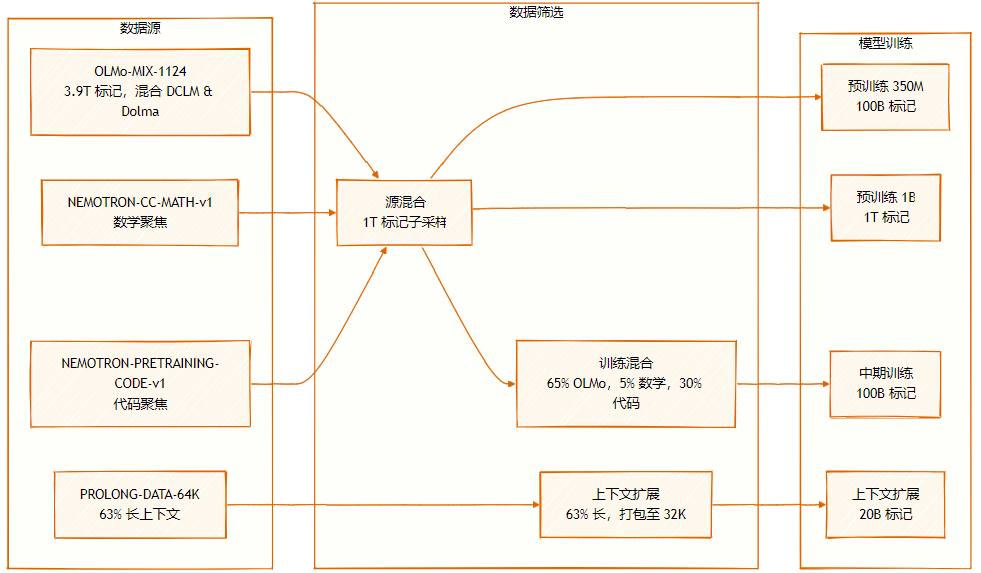
Der Datensatz besteht aus mehreren Quellen: OLMo-MIX-1124 (3.9T gelabelt), eine Mischung aus DCLM und Dolma1.7; NEMOTRON-CC-MATH-v1 (mathematisch orientiert); und NEMOTRON-PRETRAINING-CODE-v1 (codeorientiert).
3. SeedFold: Skalierung der Vorhersage biomolekularer Strukturen
Das Seed-Team von ByteDance hat SeedFold entwickelt, ein skalierbares Modell zur Vorhersage biomolekularer Strukturen. Es erhöht die Modellkapazität durch die Erweiterung des Pairformers, reduziert die Rechenkomplexität durch einen linearen Dreiecks-Aufmerksamkeitsmechanismus und erzielt auf FoldBench mit einem Destillationsdatensatz von 26,5 Millionen Proben Bestleistungen. Zudem übertrifft es AlphaFold3 bei Aufgaben im Zusammenhang mit Proteinen.
Papier und detaillierte Interpretation:https://go.hyper.ai/9zAID
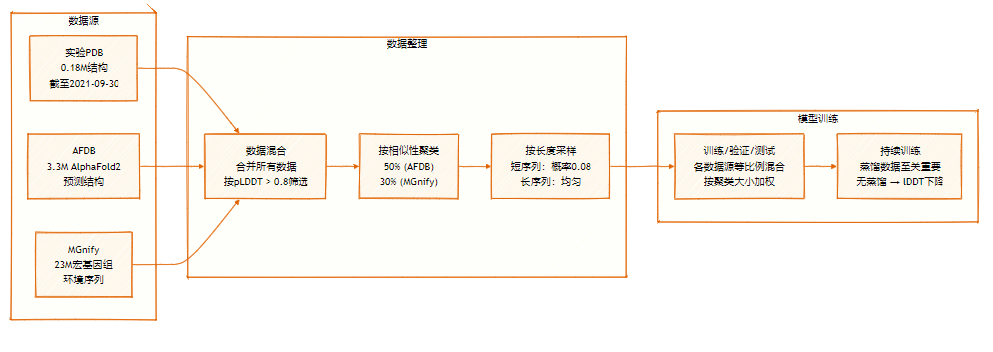
Der SeedFold-Datensatz enthält 26,5 Millionen Samples, die durch eine groß angelegte Datendestillation aus zwei Hauptquellen erweitert wurden: dem experimentellen Datensatz (0,18 Mio.) und dem destillierten Datensatz aus AFDB und MGnify.
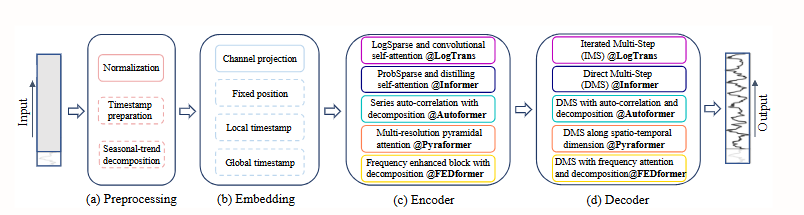
4. Sind Transformatoren für die Zeitreihenprognose effektiv?
Diese Arbeit zeigt, dass trotz der rasant steigenden Popularität von Transformer-Algorithmen in der Zeitreihenvorhersage die Permutationsinvarianz ihres Selbstaufmerksamkeitsmechanismus zum Verlust wichtiger zeitlicher Informationen führt. Vergleichsexperimente belegen, dass einfache, einschichtige lineare Modelle komplexe Transformer-Modelle auf mehreren realen Datensätzen deutlich übertreffen. Dieses Ergebnis stellt bestehende Forschungsansätze in Frage und erfordert eine Neubewertung der Effektivität von Transformer-Algorithmen in Zeitreihenaufgaben.
Papier und detaillierte Interpretation:https://go.hyper.ai/Hk05h
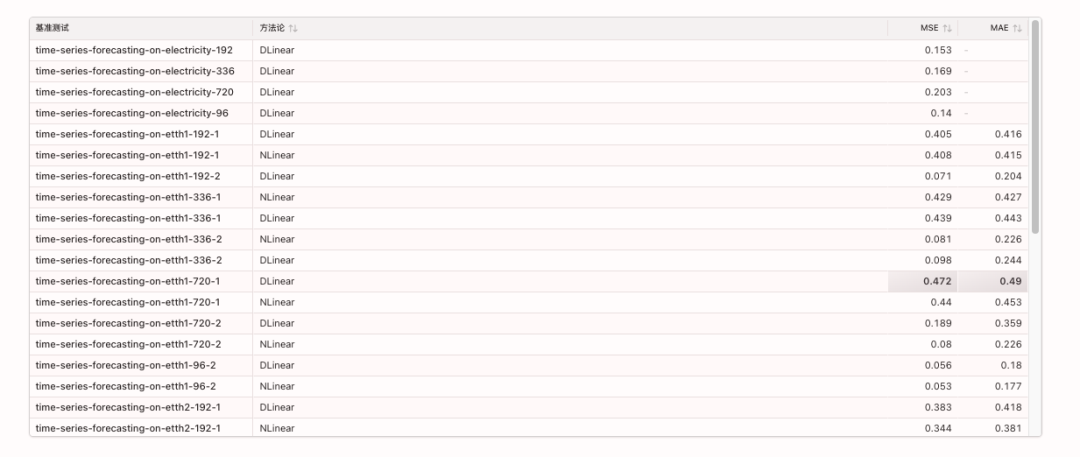
Die relevanten Benchmarks lauten wie folgt:
5. Denkmodelle erzeugen Denkgesellschaften
Forscher von Google, der Universität Chicago und dem Santa Fe Institute argumentieren, dass die überlegene Leistung fortschrittlicher Denkmodelle wie DeepSeek-R1 und QwQ-32B nicht allein auf längeren Gedankenketten beruht, sondern vielmehr auf der impliziten Simulation einer „Gedankengesellschaft“ – eines Multiagenten-ähnlichen Dialogs zwischen verschiedenen Perspektiven mit unterschiedlichen Persönlichkeiten und Fachkenntnissen innerhalb des Modells. Mithilfe mechanistischer Interpretierbarkeit und kontrolliertem Reinforcement Learning demonstrieren sie präzise einen kausalen Zusammenhang zwischen Gesprächsverhalten (wie Fragen, Konflikt und Versöhnung) und Perspektivenvielfalt. Die gezielte Steuerung des Äußerungsmarkers „Überraschung“ kann die Denkleistung verdoppeln. Diese soziale Organisation von Gedanken ermöglicht die systematische Erkundung des Lösungsraums und legt nahe, dass die Prinzipien kollektiver Intelligenz – Diversität, Debatte und Rollenkoordination – eine zentrale Grundlage für effektives künstliches Denken bilden.
Papier und detaillierte Interpretation:https://go.hyper.ai/0oXCC
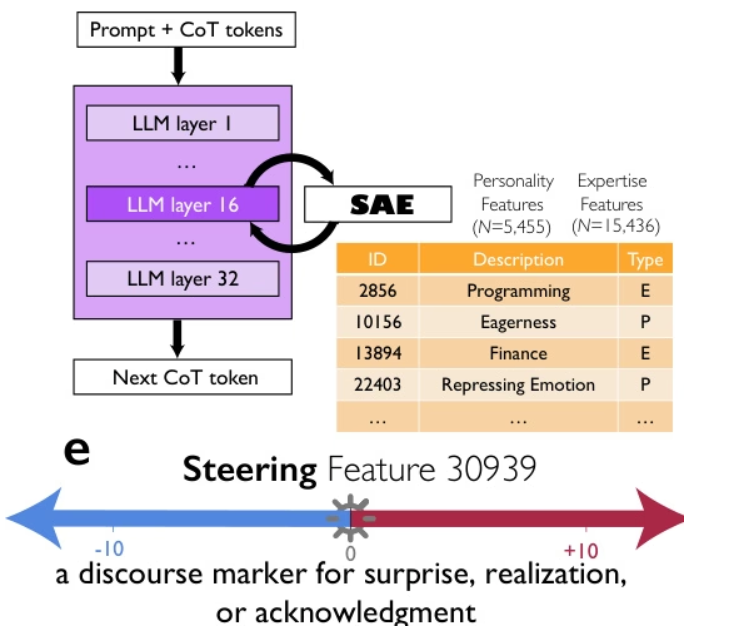
Der Datensatz umfasst 8.262 Denkaufgaben aus verschiedenen Bereichen, darunter symbolische Logik, mathematisches Lösen, wissenschaftliches Denken, Befolgen von Anweisungen und Multiagenten-Logik. Er unterstützt multiperspektivisches Denken und dient dem Training und der Evaluierung von Modellen.
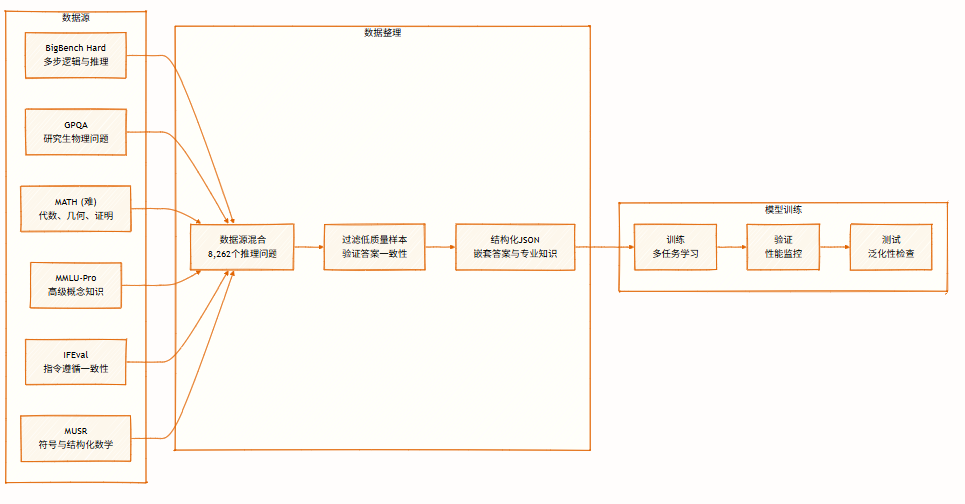
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








