Command Palette
Search for a command to run...
Online-Tutorial | Das WeChat-KI-Team Stellt WeDLM Vor, Ein Diffusions-Sprachmodell, Das Im Vergleich Zu vLLM Eine Dreifach Höhere Inferenzgeschwindigkeit Für Die Bereitstellung Von AR-Modellen erreicht.

Bei großflächigen Implementierungen und kommerziellen Anwendungen gewinnt die Inferenzgeschwindigkeit zunehmend an Bedeutung und übertrifft in vielen Fällen sogar die reine Anzahl der Modellparameter. Sie wird somit zu einem Schlüsselfaktor für den technischen Nutzen. Obwohl das autoregressive (AR) Generierungsparadigma aufgrund seiner Stabilität und seines ausgereiften Ökosystems weiterhin die gängigste Dekodierungsmethode darstellt,Aufgrund des dem Modell innewohnenden Mechanismus der Token-für-Token-Generierung ist es jedoch nahezu unmöglich, die parallelen Rechenressourcen während der Inferenzphase voll auszuschöpfen.Diese Einschränkung macht sich besonders deutlich in Szenarien, die die Generierung langer Texte, komplexe Schlussfolgerungen und Dienste mit hoher Parallelität beinhalten, und erhöht direkt die Latenz der Inferenz und die Rechenkosten.
Um diesen Engpass zu überwinden, erforscht die Forschungsgemeinschaft seit einigen Jahren kontinuierlich parallele Dekodierungswege.Unter ihnen gelten Diffusion Language Models (DLMs) aufgrund ihrer Eigenschaft, „mehrere Token pro Schritt zu generieren“, als eine der vielversprechendsten Alternativen.Zwischen Ideal und Realität besteht jedoch weiterhin eine erhebliche Diskrepanz: In realen Einsatzumgebungen konnten viele DLLMs den erwarteten Geschwindigkeitsvorteil nicht nachweisen und haben sogar Schwierigkeiten, hochoptimierte AR-Inferenz-Engines (wie vLLMs) zu übertreffen. Das Problem liegt nicht im Parallelismus selbst, sondern in einem tieferliegenden Konflikt, der in der Modellstruktur und auf Systemebene verborgen ist.Viele bestehende Diffusionsmethoden basieren auf bidirektionalen Aufmerksamkeitsmechanismen, was den Effizienz-Eckpfeiler moderner Inferenzsysteme – das Präfix-Schlüssel-Wert-Caching – untergräbt und das Modell zwingt, den Kontext wiederholt neu zu berechnen, wodurch die potenziellen Vorteile der Parallelverarbeitung zunichte gemacht werden.
In diesem ZusammenhangDas WeChat-KI-Team von Tencent hat WeDLM (WeChat Diffusion Language Model) vorgeschlagen.Dies ist das erste Diffusions-Sprachmodell, das vergleichbare AR-Modelle hinsichtlich der Inferenzgeschwindigkeit unter industrieller Inferenzmaschinenoptimierung (vLLM) übertrifft. Die Kernidee besteht darin, jede maskierte Position mit allen aktuell beobachteten Token zu verknüpfen und dabei die strikte kausale Maskierung beizubehalten. Zu diesem Zweck führten die Forscher eine topologische Neuordnungsmethode ein, die beobachtete Token in physische Präfixregionen verschiebt, ohne ihre logischen Positionen zu verändern.
Experimentelle Ergebnisse zeigen, dass WeDLM eine signifikante Beschleunigung der Inferenz ermöglicht und gleichzeitig die Qualität der Generierung starker autoregressiver Modelle beibehält. Konkret erreicht es eine mehr als dreifache Beschleunigung der von vLLM eingesetzten AR-Modelle bei Aufgaben wie mathematischem Schließen, und die Inferenzeffizienz in Szenarien mit niedriger Entropie ist mehr als zehnmal höher.
Das „WeDLM High-Efficiency Large Language Model Decoding Framework“ ist aktuell im Bereich „Tutorials“ der HyperAI-Website verfügbar. Sie können die Online-Tutorials über den unten stehenden Link aufrufen ⬇️
Online-Tutorials:
Open-Source-Adresse:
https://github.com/tencent/WeDLM
Um allen ein besseres Nutzungserlebnis der Online-Tutorials zu ermöglichen, bietet HyperAI auch Vorteile in Bezug auf Rechenleistung an.Neukunden erhalten nach der Registrierung mit dem Einlösecode „WeDLM“ 2 Stunden Nutzungsdauer für die NVIDIA GeForce RTX 5090 (das Angebot ist 1 Monat lang gültig).Nur begrenzte Stückzahl verfügbar, sichern Sie sich Ihres jetzt!
Demolauf
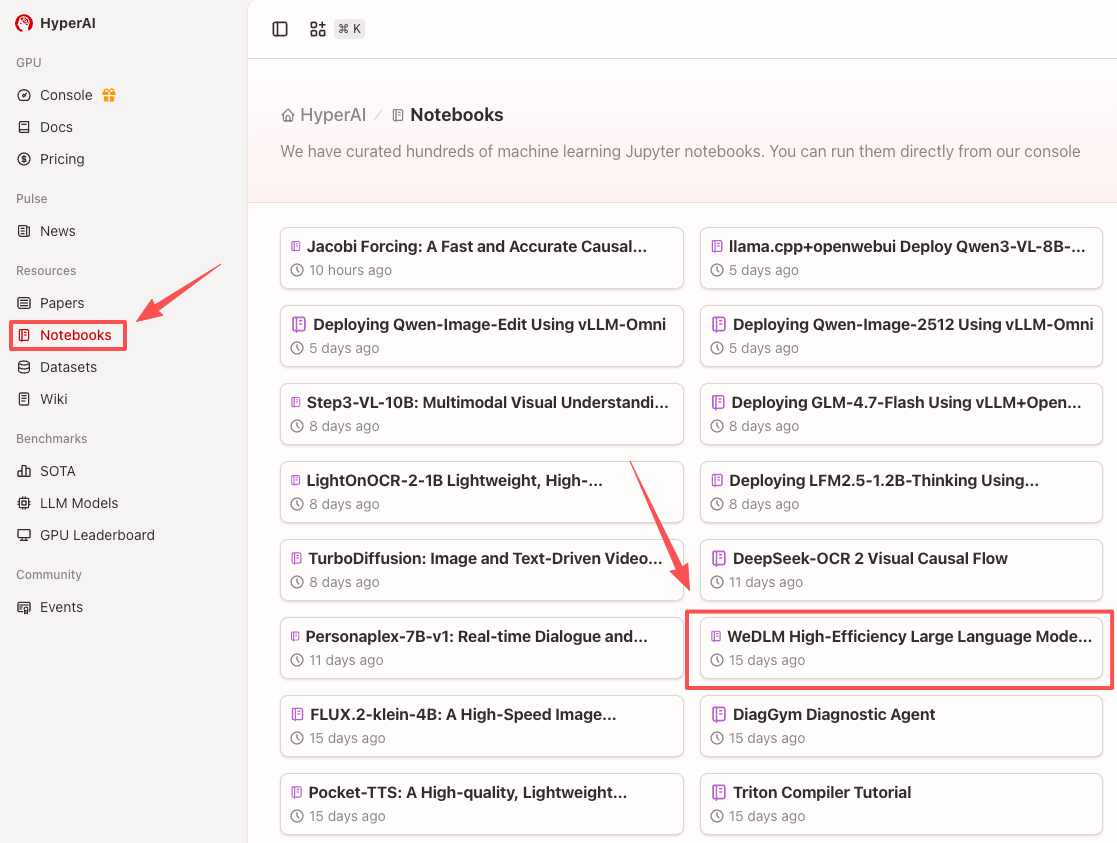
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „WeDLM High-Efficiency Large Language Model Decoding Framework“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.
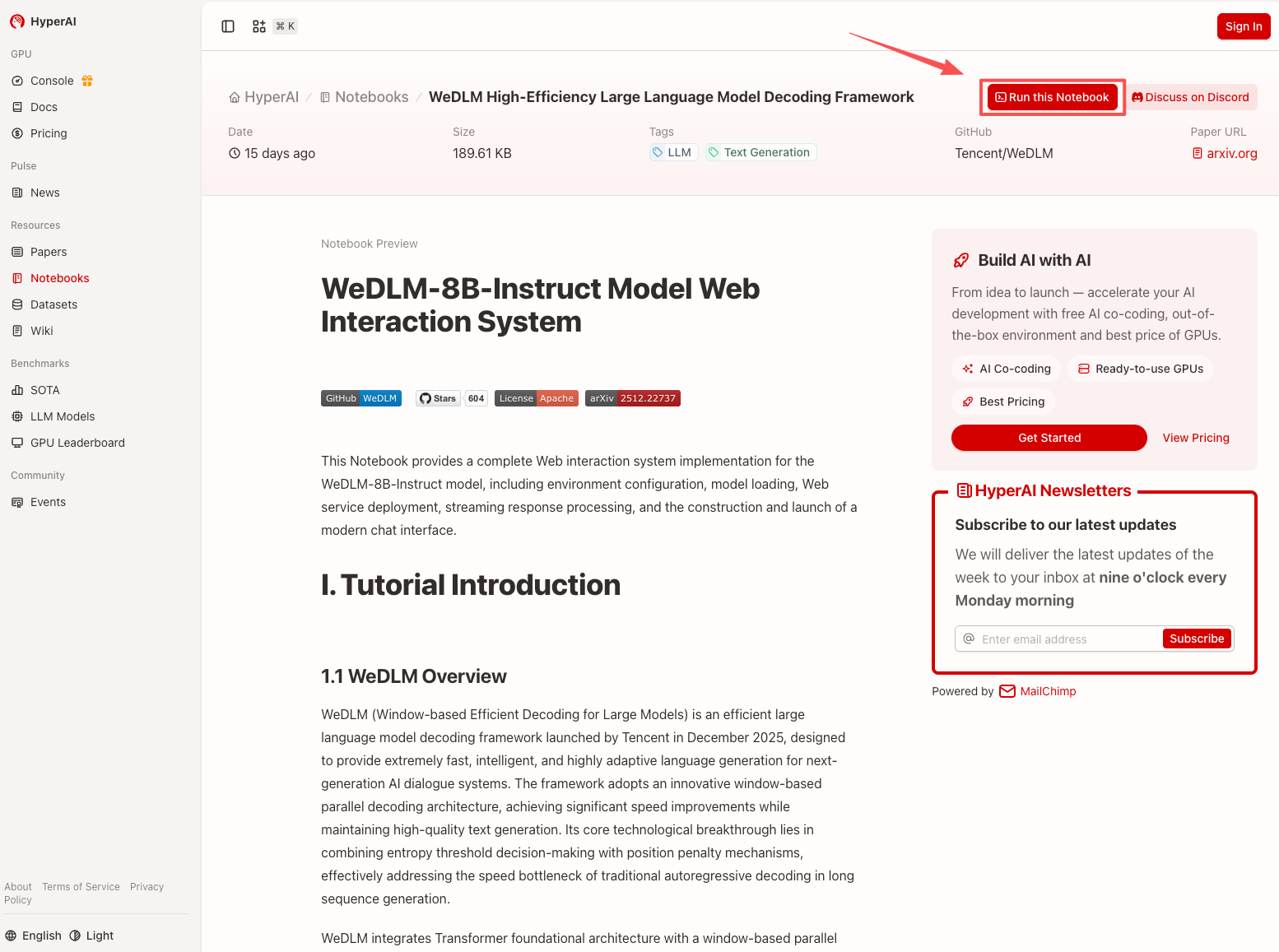
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
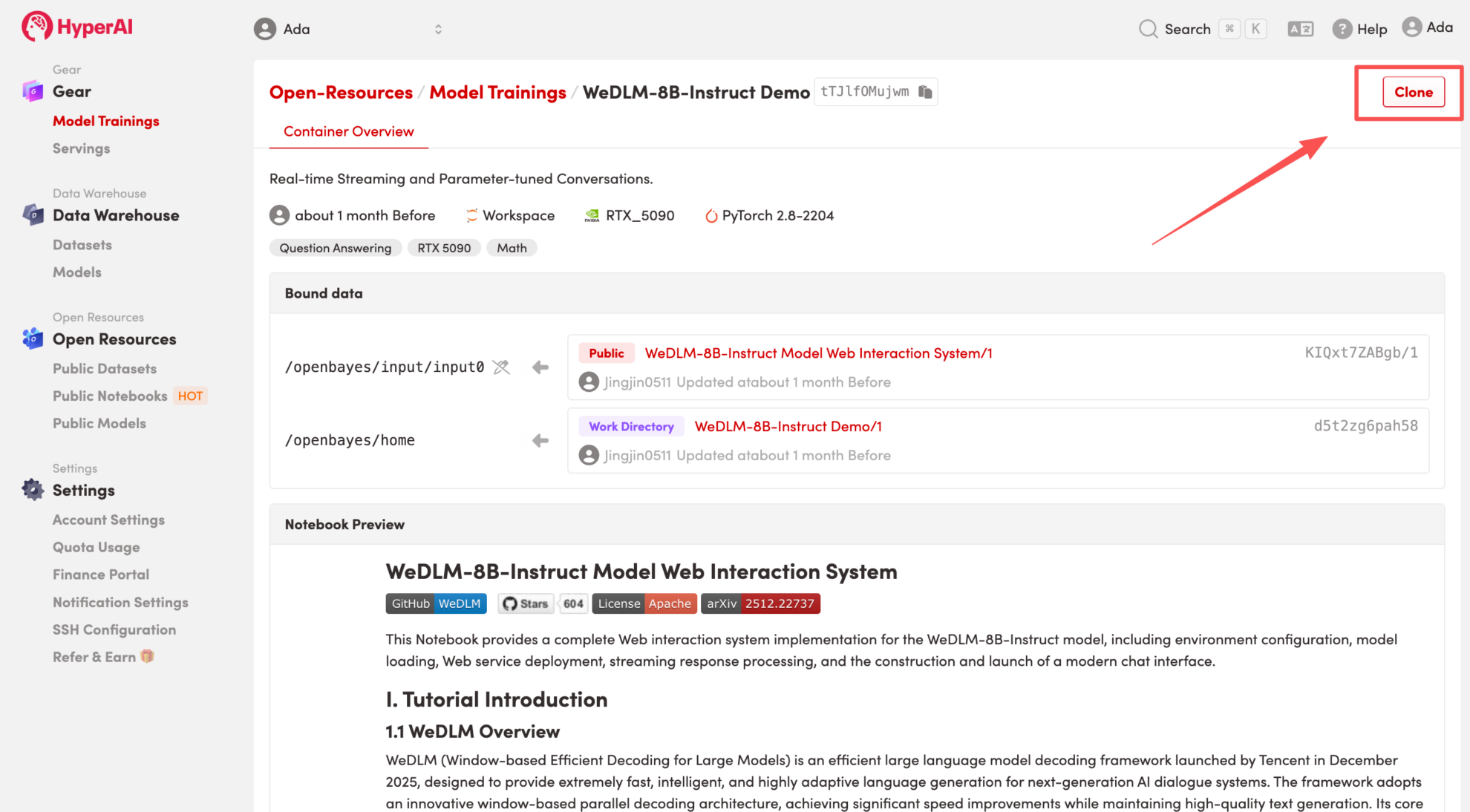
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden Registrierungsvorteile.Für nur $1 erhalten Sie 20 Stunden Rechenleistung einer RTX 5090 (ursprünglicher Preis $7).Die Ressource ist dauerhaft gültig.
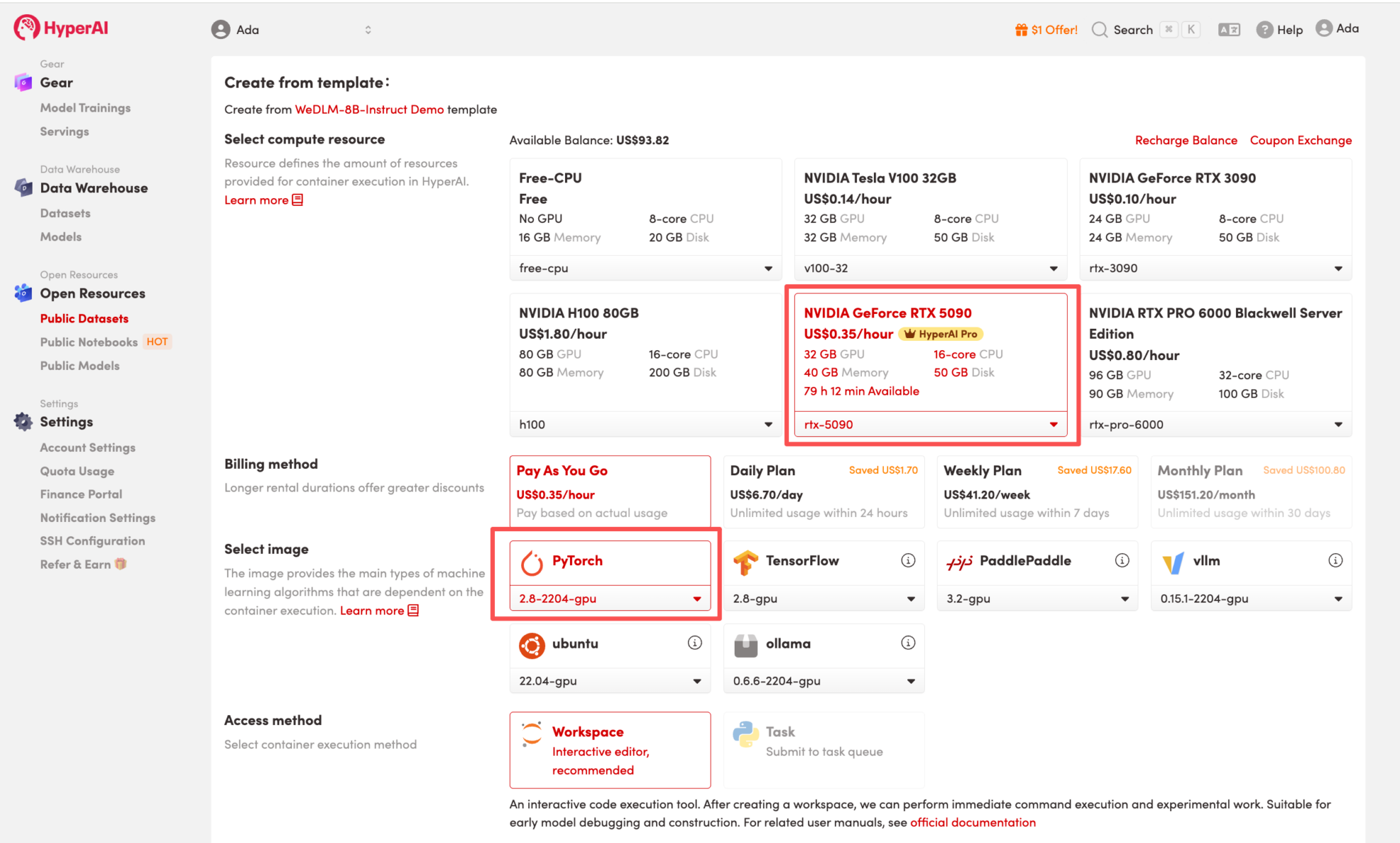
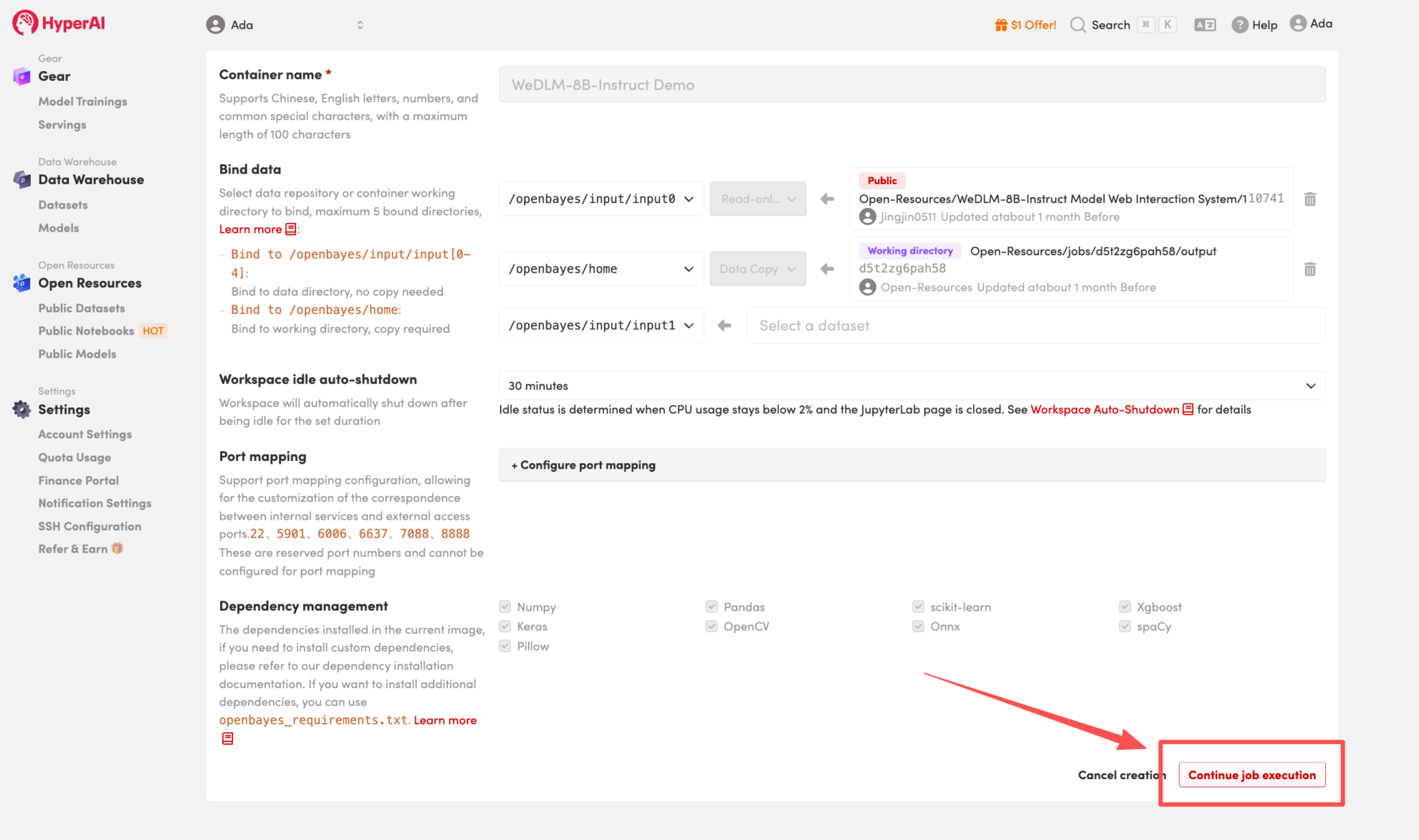
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
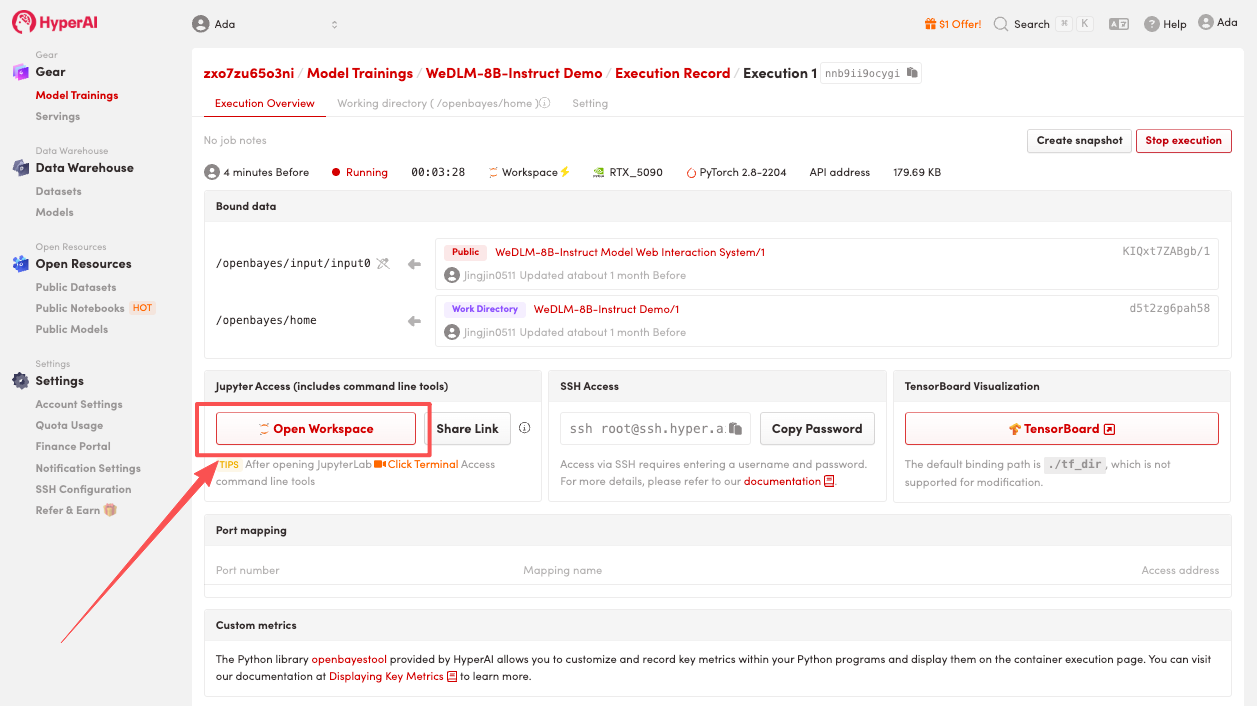
Effektdemonstration
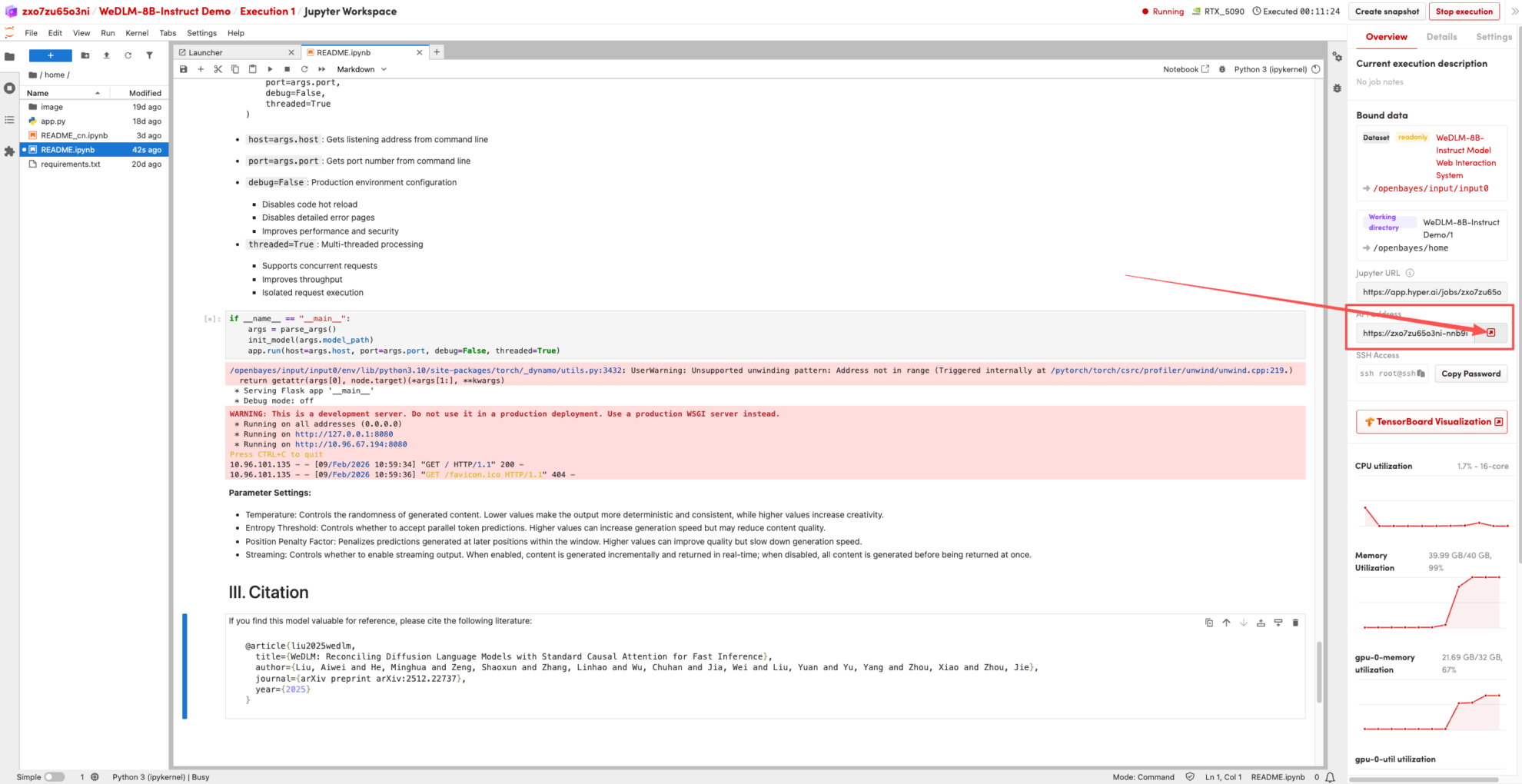
1. Nachdem die Seite weitergeleitet wurde, klicken Sie links auf die README-Seite und anschließend oben auf Ausführen.
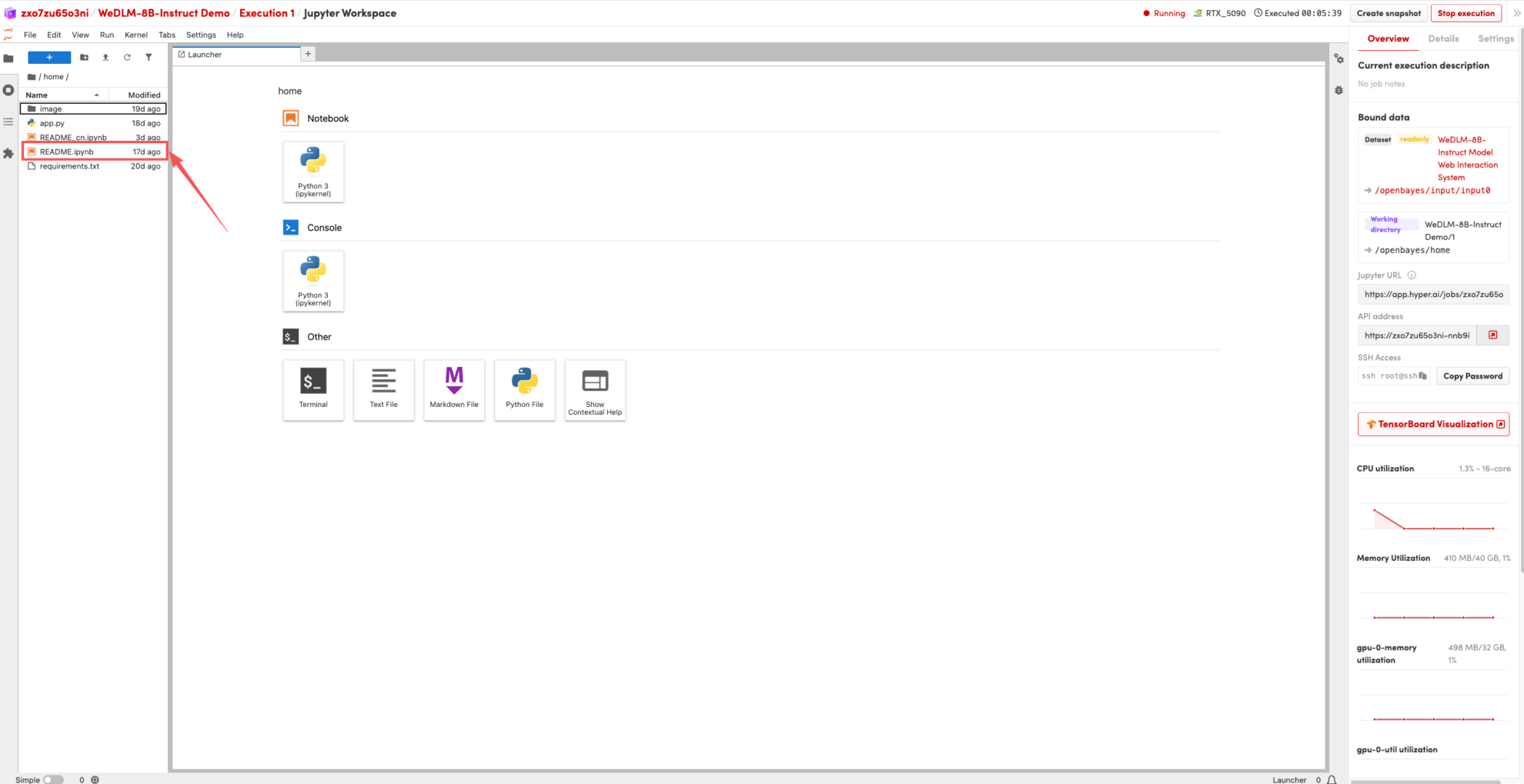
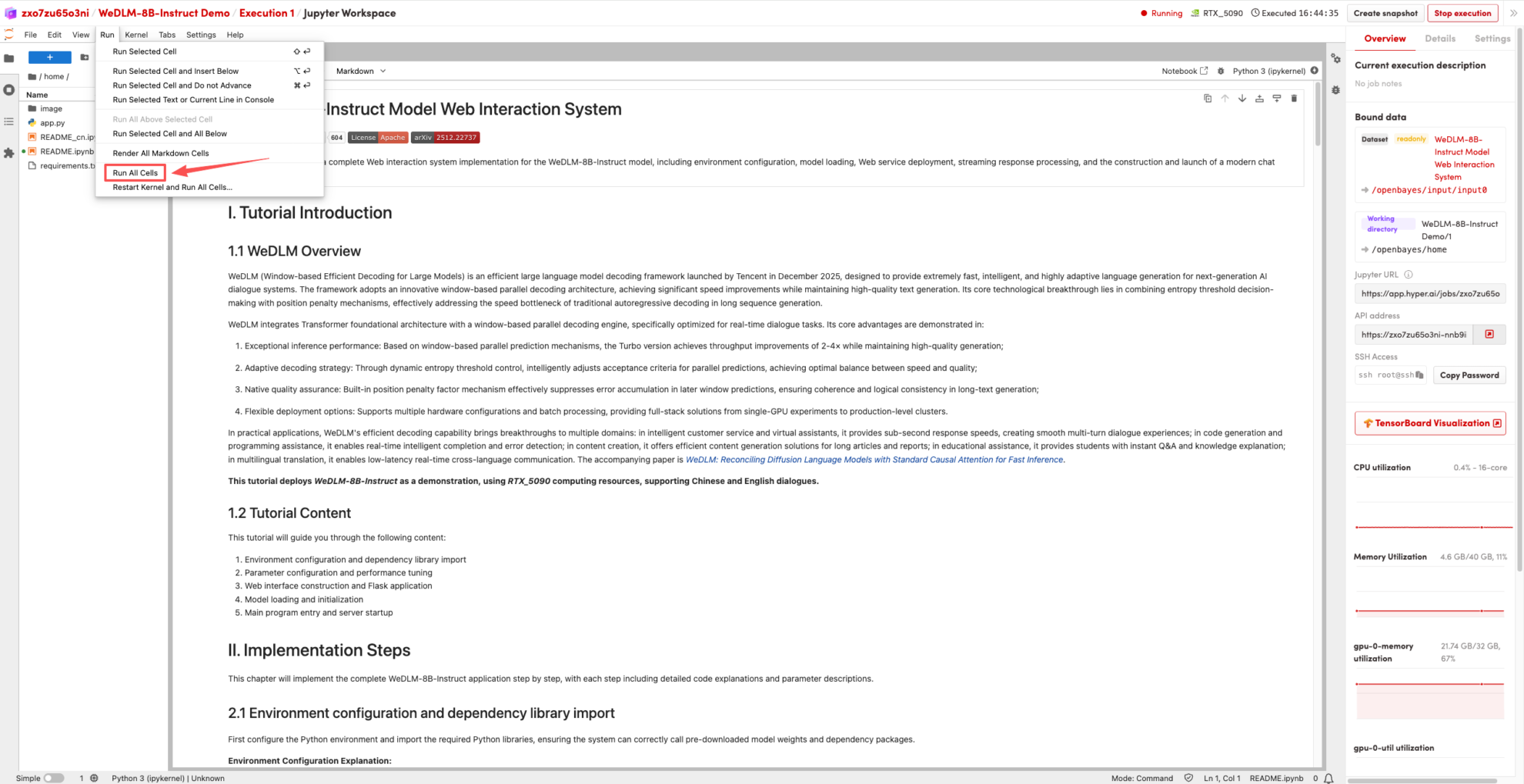
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:https://go.hyper.ai/qf0Y6








