Command Palette
Search for a command to run...
Jensen Huangs Jüngster Vortrag: 5 Innovationen, Erstmals Veröffentlichte Leistungsdaten Von Rubin; Vielfältige Open-Source-Lösungen Für Agenten, Roboter, Autonomes Fahren Und KI4S

Zu Beginn des neuen Jahres startete in Las Vegas, USA, die CES 2026 (Consumer Electronics Show), oft auch als „Frühlingsfest der Technologie“ bezeichnet. Neben der anhaltenden Präsenz von Bionik, humanoiden Robotern und Technologien für autonomes Fahren im Zentrum der Ausstellung war der intensive Wettbewerb zwischen Herstellern wie Intel, AMD, Qualcomm und Nvidia – eine wichtige Plattform für neue Chips – ein weiteres Highlight der CES.
Laut verschiedenen Quellen plant Intel, seine Panther-Lake-Prozessoren, die dritte Generation der Core-Ultra-Prozessoren, auf der CES offiziell vorzustellen. Qualcomm präsentiert die neuesten Entwicklungen seiner Snapdragon-X2-Elite- und Snapdragon-X2-Elite-Extreme-Plattformen für PCs. AMD-CEO Lisa Su kündigt an, im Rahmen ihrer Keynote am Abend des 5. Januar neue Ryzen-Chips zu präsentieren, darunter den kürzlich geleakten Ryzen 7 9850X3D und die auf der Zen-5-Architektur basierende Ryzen-9000G-Serie.
Obwohl Jensen Huang nicht auf der offiziellen CES-Keynote-Liste stand, war er dennoch auf verschiedenen Veranstaltungen präsent. Besonders hervorzuheben war seine Solo-Präsentation bei NVIDIA LIVE, die für den 5. Januar um 5:00 Uhr Pekinger Zeit angesetzt war. Es wird vermutet, dass Huang die neuesten Fortschritte der Rubin-Plattform sowie verwandte Entwicklungen in den Bereichen Physikalische KI und autonomes Fahren vorstellen wird.
Jensen Huang hat die Branche nicht enttäuscht; in seiner kürzlich gehaltenen RedeIn seiner charakteristischen schwarzen Lederjacke stellte Lao Huang außerdem die Rubin-Plattform vor, die fünf Innovationen beinhaltet, und veröffentlichte mehrere Open-Source-Errungenschaften.Speziell:
* NVIDIA Nemotron-Serie für Agentic AI
* NVIDIA Cosmos-Plattform für physikalische KI
* NVIDIA Alpamayo-Serie für autonome Fahrforschung und -entwicklung
* NVIDIA Isaac GR00T für den Robotikbereich
* NVIDIA Clara im biomedizinischen Bereich
Mit fünf innovativen Funktionen kam Rubin genau zum richtigen Zeitpunkt.
„Der Rechenaufwand für KI-Training und -Inferenz steigt derzeit dramatisch an, und Rubins Veröffentlichung kommt zum perfekten Zeitpunkt.“Jensen Huang hegt große Hoffnungen in die Rubin-Plattform und erklärt, dass Rubin sich nun in der vollen Produktionsphase befinde und voraussichtlich in der zweiten Jahreshälfte 2026 an die ersten Nutzer ausgeliefert werden werde.
Mit Fokus auf Plattformleistung erreicht die Rubin-Plattform ein „extremes Codesign“ über sechs Chips hinweg, darunter die NVIDIA Vera CPU, die NVIDIA Rubin GPU, der NVIDIA NVLink 6 Switch, die NVIDIA ConnectX-9 SuperNIC, die NVIDIA BlueField-4 DPU und der NVIDIA Spectrum-6 Ethernet-Switch. Im Vergleich zur NVIDIA Blackwell-Plattform bietet sie daher folgende Vorteile:Dadurch können die Kosten pro Token in der Inferenzphase um bis zu das Zehnfache und die Anzahl der für das Training des MoE-Modells (Hybrid Expert) benötigten GPUs um das Vierfache reduziert werden.
NVIDIA Spectrum-6 Ethernet ist die nächste Generation von Ethernet für KI-Netzwerke. Es nutzt 200G SerDes, integrierte Optiken und eine KI-optimierte Netzwerkarchitektur, um Rubins KI-Fabrik höhere Effizienz und größere Ausfallsicherheit zu bieten. Das auf der Spectrum-6-Architektur basierende photonische Ethernet-Switching-System Spectrum-X erzielt eine fünffach höhere Energieeffizienz bei gleichzeitig zehnfacher Zuverlässigkeit und fünffach längerer Verfügbarkeit.

Laut offizieller Einführung bietet die Rubin-Plattform fünf Neuerungen:
NVIDIA NVLink der 6. Generation
Bietet nahtlose GPU-zu-GPU-Kommunikation in Höchstgeschwindigkeit für großflächige MoE-Modelle. Die Bandbreite einer einzelnen GPU erreicht 3,6 TB/s, und die Gesamtbandbreite eines Vera Rubin NVL72-Racks beträgt 260 TB/s und übertrifft damit die Bandbreite des gesamten Internets. Der NVLink 6-Switch-Chip integriert Netzwerk-Computing-Funktionen, beschleunigt die aggregierte Kommunikation und bietet neue Funktionen in Bezug auf Wartbarkeit und Ausfallsicherheit. Dies ermöglicht ein schnelleres und effizienteres Training und Inferenz von KI-Systemen in großem Umfang.
* NVIDIA Vera CPU
Speziell für die Agenteninferenz entwickelt, ist sie die energieeffizienteste CPU in großen KI-Fabriken. Sie nutzt 88 NVIDIA Olympus-Kerne, ist vollständig kompatibel mit Armv9.2 und unterstützt die ultraschnelle NVLink-C2C-Verbindung. Dadurch bietet sie überragende Leistung, Bandbreite und branchenführende Energieeffizienz für moderne Rechenzentrums-Workloads.

* NVIDIA Rubin GPU
Ausgestattet mit einer Transformer Engine der dritten Generation und unterstützt hardwarebeschleunigte adaptive Komprimierung, liefert sie eine NVFP4-Rechenleistung von 50 PFLOPS bei KI-Inferenz.
* Vertrauliche Datenverarbeitung der dritten Generation von NVIDIA
Die Vera Rubin NVL72 ist die erste Plattform, die NVIDIA Confidential Computing auf Rack-Ebene implementiert und so die Datensicherheit über die Bereiche CPU, GPU und NVLink hinweg gewährleistet. Dadurch wird das weltweit größte proprietäre Modell sowie dessen Trainings- und Inferenzaufgaben geschützt.
* RAS-Motor der zweiten Generation
Echtzeit-Gesundheitsüberwachung, Fehlertoleranz und vorausschauende Wartungsmechanismen für GPU, CPU und NVLink maximieren die Systemproduktivität; das modulare, kabellose Tray-Design ermöglicht Montage- und Wartungsgeschwindigkeiten, die bis zu 18 Mal schneller sind als bei Blackwell.

Die Rubin-Plattform führt die NVIDIA Inference Context Memory Storage Platform ein, eine neue KI-native Speicherinfrastruktur, die die Skalierung von Inferenzkontexten im Gigabit-Bereich ermöglicht. Basierend auf NVIDIA BlueField-4 ermöglicht diese Plattform die effiziente gemeinsame Nutzung und Wiederverwendung von Key-Value-Cache-Daten innerhalb der KI-Infrastruktur. Dies verbessert Reaktionsfähigkeit und Durchsatz und ermöglicht gleichzeitig eine vorhersehbare und energieeffiziente Skalierung der Agenten-KI.
Obwohl die Rubin-Plattform noch nicht offiziell auf dem Markt ist, hat sie bereits die Unterstützung zahlreicher Branchenführer erhalten. In einem offiziellen Blogbeitrag von NVIDIA lobten OpenAI-CEO Sam Altman, Anthropic-CEO Dario Amodei, Meta-CEO Mark Zuckerberg, Elon Musk (der als CEO von xAI auftrat) sowie die Chefs großer Technologieunternehmen wie Microsoft, Google, AWS und Dell die Plattform in höchsten Tönen – Musk erklärte direkt:„Rubin wird der Welt einmal mehr beweisen, dass NVIDIA der Goldstandard in der Branche ist.“

Diverse Open-Source-Technologien: Agenten, AI4S, autonomes Fahren und Robotik.
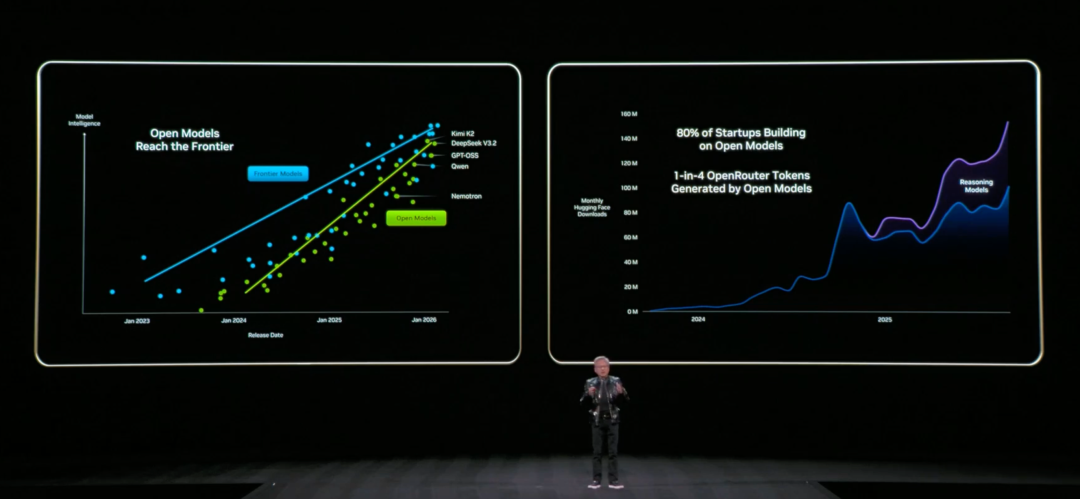
Neben der viel diskutierten Rubin-Plattform war „Open Source“ ein weiteres wichtiges Schlagwort in Jensen Huangs Rede.
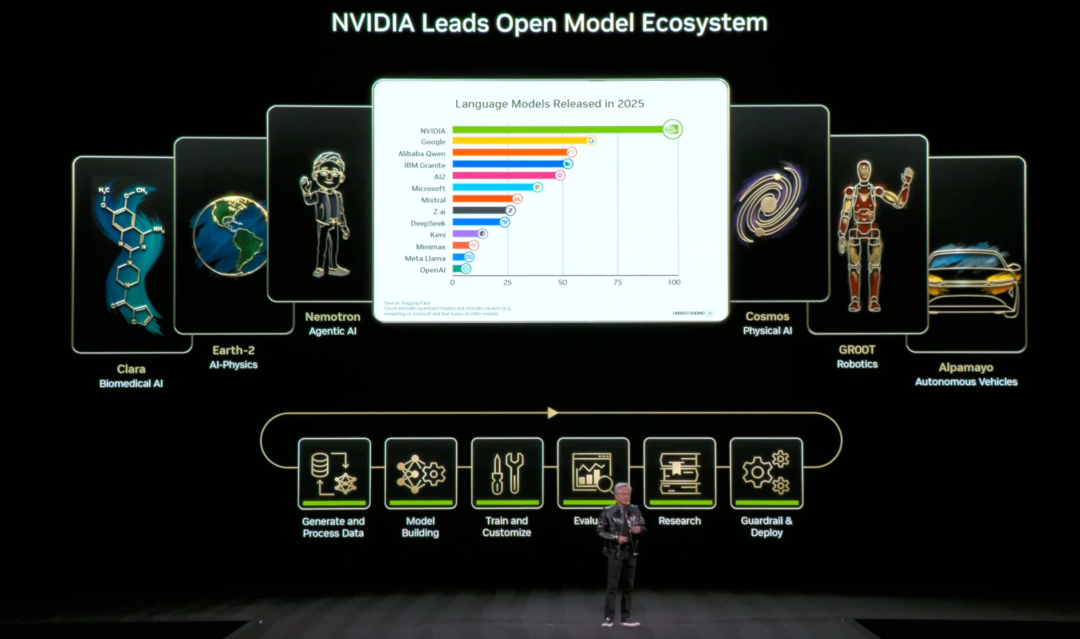
Zunächst gibt es NVIDIA Nemotron für KI-Agenten. Aufbauend auf dem zuvor veröffentlichten offenen Modell und den Daten von NVIDIA Nemotron 3 hat NVIDIA weitere Nemotron-Modelle für Sprache, multimodale erweiterte Informationsgewinnung (RAG) und Sicherheit eingeführt.
* Nemotron-Sprache
Es besteht aus mehreren führenden Open-Source-Modellen, darunter einem brandneuen ASR-Modell (Automatische Spracherkennung), und bietet latenzarme Echtzeit-Spracherkennung für Echtzeit-Untertitelung und KI-Sprachverarbeitungsanwendungen. Tägliche und modale Benchmarks zeigen, dass es zehnmal schneller ist als vergleichbare Modelle.
* Nemotron RAG
Es beinhaltet ein brandneues Einbettungsmodell und ein neu geordnetes visuelles Sprachmodell (VLM), das hochpräzise mehrsprachige und multimodale Dateneinblicke ermöglicht und die Dokumentensuche sowie die Informationsabfrage deutlich verbessert.
* Nemotron-Sicherheit
Das Modellsystem, das die Sicherheit und Vertrauenswürdigkeit von KI-Anwendungen verbessern soll, umfasst nun das Llama Nemotron Content Security Model (das mehr Sprachen unterstützt) und Nemotron PII, das sensible Daten mit hoher Genauigkeit identifizieren kann.
Zweitens hat NVIDIA seine Cosmos-Serienmodelle für die Bereiche physikalische KI und Robotik aktualisiert:
* Kosmischer Grund 2
Das neue, hochrangige, auf Inferenz basierende VLM hilft Robotern und KI-Agenten, eine höhere Präzision bei Wahrnehmung, Verständnis und Interaktion in der physischen Welt zu erreichen.
* Cosmos Transfer 2.5 und Cosmos Predict 2.5
Es kann unter verschiedensten Umgebungen und Bedingungen groß angelegte synthetische Videos erzeugen.
Aufbauend auf Cosmos hat NVIDIA auch Open-Source-Modelle für verschiedene physikalische KI-Paradigmen veröffentlicht:
* Isaac GR00T N1.6
Ein offenes Vision-Sprache-Aktions-Modell (VLA) für humanoide Roboter, das die Ganzkörpersteuerung ermöglicht und mit Hilfe von Cosmos Reason die Fähigkeiten zum logischen Denken und zum Kontextverständnis verbessert.
* Videosuche und Zusammenfassung NVIDIA Blueprint
Als Teil der NVIDIA Metropolis-Plattform bietet es einen Referenz-Workflow für die Entwicklung visueller KI-Agenten, die große Mengen an aufgezeichnetem und Echtzeit-Video analysieren können, um die betriebliche Effizienz und die öffentliche Sicherheit zu verbessern.

Drittens hat das Unternehmen für die Branche des autonomen Fahrens NVIDIA Alpamayo neu als Open Source veröffentlicht – dazu gehören Open-Source-Modelle, Simulationswerkzeuge und umfangreiche Datensätze.
* Alpamayo 1
Das erste Open-Source-VLA-Modell für autonome Fahrzeuge (AVs) mit groß angelegter Inferenz ermöglicht es den Fahrzeugen, nicht nur ihre Umgebung zu verstehen, sondern auch ihr eigenes Verhalten zu erklären.
* AlpaSim
Ein Open-Source-Simulationsframework, das das Training und die Evaluierung von inferenzbasierten Modellen für autonomes Fahren in verschiedenen Umgebungen und komplexen Randszenarien unterstützt.
Darüber hinaus veröffentlichte NVIDIA das Physical AI Open Dataset, das mehr als 1.700 Stunden realer Fahrdaten aus einem breiten Spektrum geografischer Regionen und Umweltbedingungen weltweit enthält und eine große Anzahl seltener und komplexer realer Edge-Szenarien abdeckt, was für die Weiterentwicklung von Inferenzarchitekturen von entscheidender Bedeutung ist.

Schließlich hat NVIDIA für den AI4S-Bereich das KI-Modell Clara auf den Markt gebracht, das Folgendes umfasst:
* La-Proteina
Es unterstützt die Entwicklung großskaliger Proteine auf atomarer Ebene für die wissenschaftliche Forschung und die Entwicklung von Arzneimittelkandidaten und bietet neue Werkzeuge zur Erforschung von Krankheiten, die bisher als „unbehandelbar“ galten.
* ReaSyn v2
Die Einbeziehung von Herstellungsplänen in den Wirkstoffforschungsprozess gewährleistet, dass KI-entwickelte Medikamente synthetisch herstellbar sind.
* KERMT
Durch die Vorhersage von Wechselwirkungen zwischen Arzneimitteln und Menschen ermöglicht es hochpräzise computergestützte Sicherheitstests in einem frühen Stadium.
* RNAPro
Das Potenzial der personalisierten Medizin erschließen, indem die komplexe dreidimensionale Struktur von RNA-Molekülen vorhergesagt wird.
Darüber hinaus veröffentlichte NVIDIA einen Datensatz mit 455.000 synthetischen Proteinstrukturen, um Forschern beim Aufbau präziserer KI-Modelle zu helfen.
Abschluss
Während sich das Rampenlicht in Las Vegas wieder einmal auf KI und die dazugehörige Hardware richtet, sei es Jensen Huangs eloquente Diskussion über die Rubin-Plattform oder Lisa Sus große Produktvorstellung heute Abend, geht es nicht nur um die Veröffentlichung einer neuen Chipgeneration oder einen Leistungssprung; es geht vielmehr darum, die Grenzen für die nächste Stufe der KI-Entwicklung zu setzen: wie Rechenleistung organisiert werden kann, wie Kosten gesenkt werden können, wie Modelle wirklich in Richtung Inferenz gehen können und wie Agenten eng mit der realen Welt verknüpft werden können.
Die CES 2026 ist längst kein reiner Wettbewerb der Hersteller um die besten Spezifikationen mehr, sondern eine gemeinsame Entscheidung über die Gestaltung der KI-Infrastruktur. Der Fokus des Wettbewerbs verlagert sich eindeutig von den Modellen selbst hin zu der Frage, wer den großflächigen Einsatz von künstlicher Intelligenz effizienter und stabiler unterstützen kann.
Referenzen
1.https://nvidianews.nvidia.com/news/rubin-platform-ai-supercomputer
2.https://blogs.nvidia.com/blog/open-models-data-tools-accelerate-ai/








