Command Palette
Search for a command to run...
Die Ursprünglichen Teammitglieder Von CUDA Kritisierten cuTile Scharf Dafür, Dass Es „speziell“ Auf Triton Abziele; Kann Das Tile-Paradigma Die Wettbewerbslandschaft Des GPU-Programmierökosystems Neu Gestalten?

Im Dezember 2025, fast zwanzig Jahre nach der Veröffentlichung von CUDA, brachte NVIDIA die neueste Version, CUDA 13.1, auf den Markt. Die wichtigste Änderung liegt im neuen CUDA Tile (cuTile) Programmiermodell.Die GPU-Kernelstruktur wurde durch ein „Tile-basiertes“ Programmiermodell reorganisiert, das es Entwicklern ermöglicht, leistungsstarke Kernel zu schreiben, ohne direkt in das zugrunde liegende CUDA C++ einzugreifen.Dies ist zweifellos ein bemerkenswerter Meilenstein für das GPU-Programmier-Ökosystem: Es könnte sich um eine neue Produktstufe handeln, die von NVIDIA eingeführt wurde, um der wachsenden Nachfrage nach benutzerdefinierten Operatoren im KI-Zeitalter gerecht zu werden und die Bindung des Software-Ökosystems weiter zu stärken.
Nach der Veröffentlichung löste cuTile in der Entwicklergemeinschaft schnell breite Diskussionen über den Entwicklungszyklus benutzerdefinierter Operatoren, die direkte Konkurrenz zu Triton und die Frage aus, ob es sich zum Standardeinstiegspunkt für Python entwickeln könnte. Obwohl sich cuTile noch in einem sehr frühen Stadium befindet, deuten die bisherigen Rückmeldungen der Entwickler darauf hin, dass es bereits das Potenzial besitzt, ein neues Paradigma zu werden.
Mit der zunehmenden Entwicklung des entsprechenden Ökosystems werden die Positionierung und das Potenzial von cuTile immer deutlicher. Auf GitHub, in Foren und in internen Projekten bestätigen zahlreiche Entwickler die Verbesserungen von cuTile hinsichtlich Codeorganisation und Lesbarkeit, während einige Community-Nutzer bereits versucht haben, bestehenden CUDA-Code nach cuTile zu migrieren. Wird cuTile mit der Unterstützung des Python-Ökosystems zum Standardeinstiegspunkt für die GPU-Programmierung oder entsteht eine neue technische Arbeitsteilung zwischen CUDA und Triton? Mit zunehmender Verbreitung realer Anwendungsfälle werden diese Fragen in den kommenden Jahren wohl beantwortet werden.
cuTile: Einläutung einer Ära der „codeorientierten“ GPU-Programmierung
Seit langer Zeit bietet CUDA Entwicklern ein Hardware- und Programmiermodell für Single Instruction Multithreading (SIMT), das es ihnen ermöglicht, die parallele Rechenlogik der GPU auf der Granularität von "Threads" zu beschreiben: Ein Kernel wird in Tausende von Threads unterteilt, jeder Thread führt ein kleines Segment der Berechnung durch, Gruppen von Threads bilden Blöcke, und dann ordnet die Hardware diese dem Streaming Multiprocessor (SM) zur Ausführung zu.
Angesichts des exponentiellen Wachstums des Rechenbedarfs, insbesondere des Umfangs des KI-Trainings, in den letzten 3-5 Jahren, ist diese Thread-zentrierte Programmierung jedoch immer häufiger an ihre Grenzen gestoßen.Forscher und Ingenieure müssen nicht nur die Thread-Planung verstehen, sondern auch Speicherzusammenführung, Warp-Divergenz und sogar das Ausführungsformat von Tensor-Kernen eingehend berücksichtigen. Anders ausgedrückt: Die Entwicklung eines leistungsstarken CUDA-Kernels erfordert ein umfassendes Verständnis aller Aspekte der Grafikkartenarchitektur; andernfalls lassen sich die Hardware-Leistungsmerkmale nur schwer voll ausschöpfen.
Mit dem Aufkommen von cuTile reagiert NVIDIA auf diesen Trend – es ermöglicht Entwicklern, sich wieder auf Algorithmen zu konzentrieren, während die Leistungssteigerung der Hardware dem Framework überlassen wird.
Speziell,cuTile ist ein paralleles Programmiermodell für NVIDIA-GPUs und gleichzeitig eine auf Python basierende domänenspezifische Sprache (DSL). Es kann erweiterte Hardwarefunktionen automatisch nutzen.Beispielsweise Tensor-Kerne und Tensor-Speicherbeschleuniger, und eine gute Portabilität über verschiedene NVIDIA-GPU-Architekturen hinweg gewährleisten.

Aus technischer Sicht,Die Grundlage von CUDA Tile bildet CUDA Tile IR (Intermediate Representation). Diese stellt eine Reihe virtueller Befehle bereit, die es ermöglichen, Hardware nativ im Tile-basierten Stil zu programmieren. Entwickler können so Code auf höherer Ebene schreiben, der mit minimalen Anpassungen effizient auf verschiedenen GPU-Generationen ausgeführt werden kann.
Obwohl NVIDIAs Parallel Thread Execution (PTX) die Portabilität von SIMT-Programmen gewährleistet,CUDA Tile IR erweitert die CUDA-Plattform jedoch um die native Unterstützung von kachelbasierten Anwendungen.Entwickler können sich darauf konzentrieren, datenparallele Programme in Kacheln und Kachelblöcke zu unterteilen. CUDA Tile IR übernimmt dabei die Zuordnung dieser Kacheln zu Hardware-Ressourcen wie Threads, Speicherhierarchien und Tensor-Kernen. Mit anderen Worten: Kachelbasierte Programmierung ermöglicht es Entwicklern, Algorithmen zu schreiben, indem sie Kacheln spezifizieren und die auf diesen Kacheln ausgeführten Rechenoperationen definieren, ohne die Ausführungsmethode für jedes Element des Algorithmus einzeln konfigurieren zu müssen – diese Details übernimmt der Compiler.
Warum hat NVIDIA sich nach 20 Jahren CUDA-Implementierung für eine Aktualisierung seines Programmierparadigmas entschieden?
Die Veröffentlichung von cuTile erfolgt fast zwanzig Jahre nach der ersten Veröffentlichung von CUDA.Seit seiner Veröffentlichung im Jahr 2006 hat sich CUDA schrittweise von einer GPU-Programmierschnittstelle zu einem umfassenden Ökosystem entwickelt, das Frameworks, Compiler, Bibliotheken und Toolchains umfasst und bis heute als Kerninfrastruktur des Softwaresystems von NVIDIA dient. NVIDIAs Entscheidung, 2025 ein neues Programmierparadigma zur Weiterentwicklung von CUDA einzuführen, ist nicht nur eine technologische Evolution, sondern eine direkte Reaktion auf Veränderungen im Branchenumfeld.
Einerseits hat der Wandel der KI-Workloads zu einer extrem hohen Nachfrage nach benutzerdefinierten Operatoren geführt, andererseits stellen die Entwicklungsgeschwindigkeit, die Debugging-Kosten und der Fachkräftemangel im traditionellen CUDA C++ Einschränkungen dar. Viele Teams können zwar schnell Algorithmen entwerfen, haben aber Schwierigkeiten, in kurzer Zeit leistungsstarke und wartungsfreundliche CUDA-Kernel zu entwickeln. cuTile soll genau diesen Widerspruch lösen: Ohne Leistungseinbußen bietet es einen Python-freundlichen Einstiegspunkt, der es mehr Entwicklern ermöglicht, benutzerdefinierte Operatoren zu überschaubaren Kosten zu erstellen. Dadurch wird die Einstiegshürde für die GPU-Programmierung gesenkt und der Iterationszyklus verkürzt.
Mit anderen Worten:cuTile ist NVIDIAs strategischer Vorstoß, um die Kontrolle über das Programmierparadigma zurückzugewinnen, bevor die umfassenden DSL-Kriege der Betreiber beginnen.
Andererseits verschärft sich der Wettbewerb im GPU-Software-Ökosystem im Zuge der „Ent-Nvidiaisierung“: AMD hat die Open-Source-Plattform ROCm für beschleunigtes Rechnen eingeführt und zieht durch ihre offene Architektur und die erweiterte Ökosystemabdeckung mehr Drittanbieterbibliotheken und -tools an. Intel hat OneAPI gestartet, um ein einheitliches Programmiermodell für verschiedene Architekturen zu entwickeln und Sprachunterstützung wie DPC++ bereitzustellen, um die Komplexität der Entwicklung heterogener Systeme zu reduzieren. All dies schwächt die Exklusivität von CUDA.
Darüber hinaus wetteifern Unternehmen, die KI-Modelle im großen Maßstab entwickeln, und Chiphersteller um die Entwicklung eigener Operator-DSLs. Bereits im Oktober 2022 veröffentlichte OpenAI Triton. Dieser Open-Source-Compiler für Deep-Learning-Programmiersprachen für GPUs ermöglicht es Entwicklern, leistungsstarke GPU-Kernel in prägnantem Python-ähnlichem Code zu schreiben, ohne sich mit den Low-Level-Details von CUDA C++ auseinandersetzen zu müssen. Dadurch erlangte Triton schnell Aufmerksamkeit in der Community. Viele Forscher und Ingenieure sind der Ansicht, dass Triton die Einstiegshürde für die GPU-Operatorentwicklung senkt. Gleichzeitig bieten die Meta/FAIR-bezogenen TC/Tensor-Sprachen sowie die von der Community um TVM/Relay/DeepSpeed entwickelten Frameworks zur Operatorkompilierung und -optimierung vielfältige Wettbewerbsmöglichkeiten in spezifischen Bereichen des Software-Ökosystems.
Dies führte direkt zur Entstehung von cuTile – um seine Marktstellung zu festigen, musste NVIDIA die Verpackung und Benutzererfahrung seines Softwaresystems weiter verbessern, damit mehr Entwickler im CUDA-Ökosystem bleiben würden. SemiAnalysis veröffentlichte einen Artikel, in dem festgestellt wird, dass die Einführung von cuTile ein wichtiger Schritt von NVIDIA ist, um seinen CUDA-Vorteil weiter auszubauen.„Der PyTorch-Compiler unterstützt nun neben Triton auch NVIDIA Python CuTeDSL, wodurch FlexAttention doppelt so schnell ist wie die Triton-Implementierung. NVIDIA hat sein proprietäres Python CuTeDSL-, cuTile- und TileIR-Ökosystem stets stark unterstützt. Dank Python CuTeDSL/cuTile/TileIR hat NVIDIA wieder Zugriff auf die Optimierungen des proprietären Compilers.“
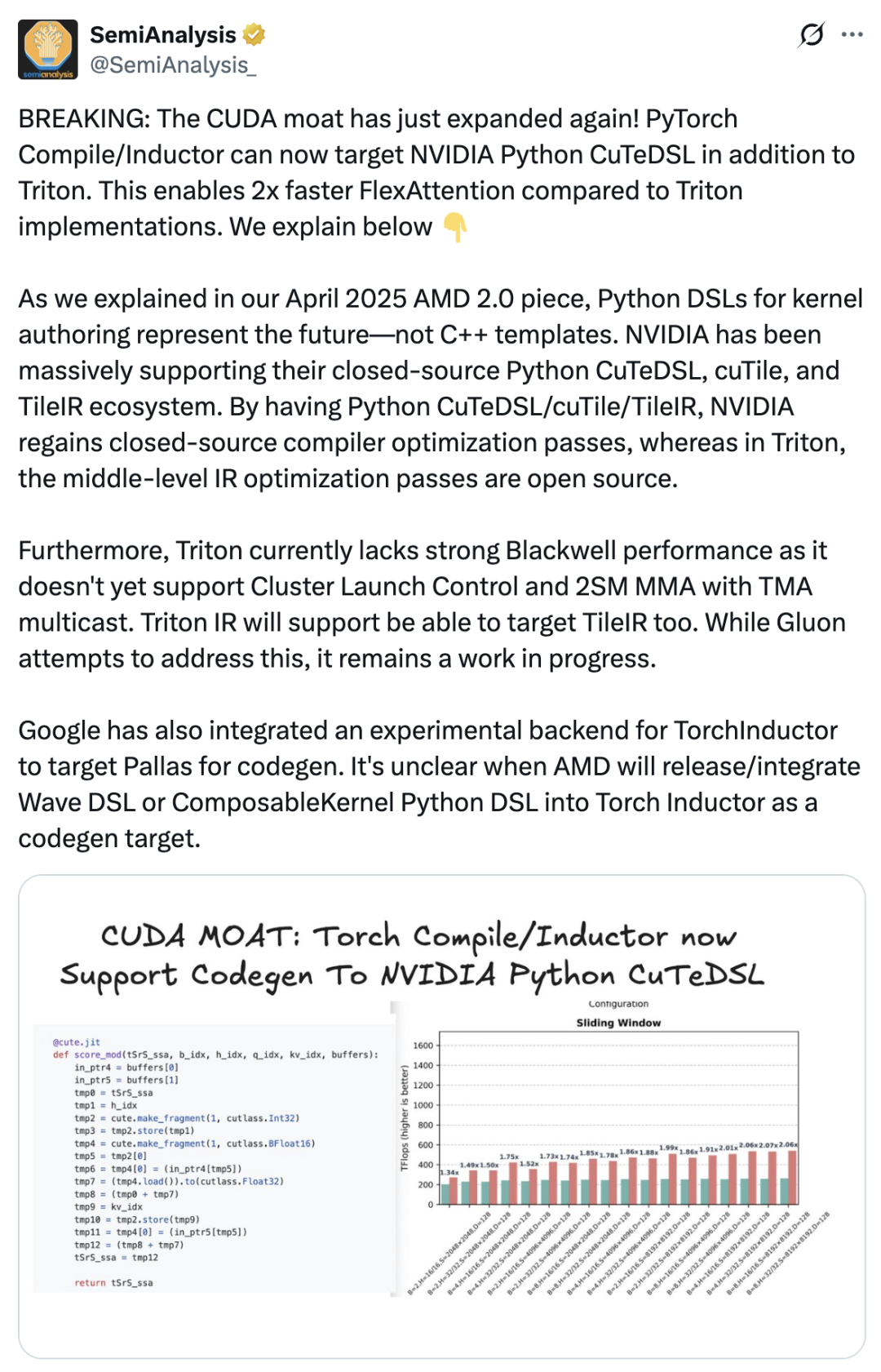
Kopiert man Triton? cuTiles „Tile Mindset“: Das sagen die Entwickler dazu.
Tatsächlich,Die Marktreaktion auf cuTile war gemischt und von Kontroversen begleitet.Einige Entwickler, die es nutzten, berichteten, dass die Tile-Optimierung zwar eine sinnvolle Verbesserung darstellte, die Vielzahl an domänenspezifischen Sprachen (DSLs) jedoch auch neue Lernkurven mit sich brachte. Der Reddit-Nutzer Previous-Raisin1434 kommentierte, dass er sich während der Übergangsphase von den neuen DSLs in cuTile überfordert fühlte.
„Warum gibt es plötzlich Tausende von verschiedenen Dingen? Ich habe vorher Triton benutzt, und jetzt hat NVIDIA mehr als ein Dutzend neue DSLs herausgebracht“, beschwerte er sich.
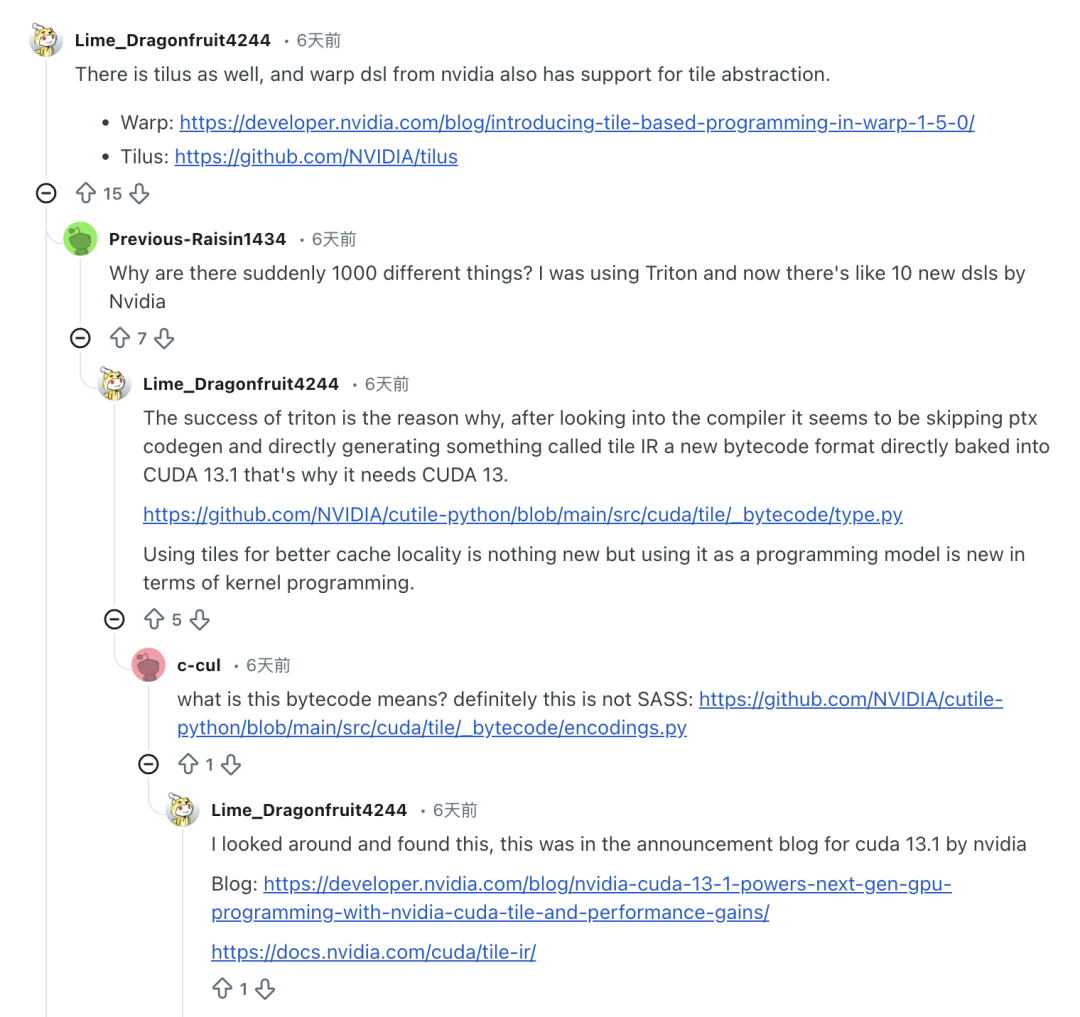
Unterdessen haben einige Branchenexperten die mangelnde Differenzierung und Originalität von cuTile in Frage gestellt und gesagt: „cuTile fühlt sich an wie NVIDIAs Antwort auf Triton, Mojo und ThunderKittens, als wären sie alle miteinander integriert worden.“

In diesem ZusammenhangNicholas Wilt, ein Mitglied des ursprünglichen CUDA-Teams, postete sogar Folgendes:„Man kann sich des Verdachts kaum erwehren, dass cuTile direkt als Gegenstück zu Triton entwickelt wurde. cuTile ist eine neue eDSL zum Schreiben von Kerneln, genau wie Triton oder Helion.“
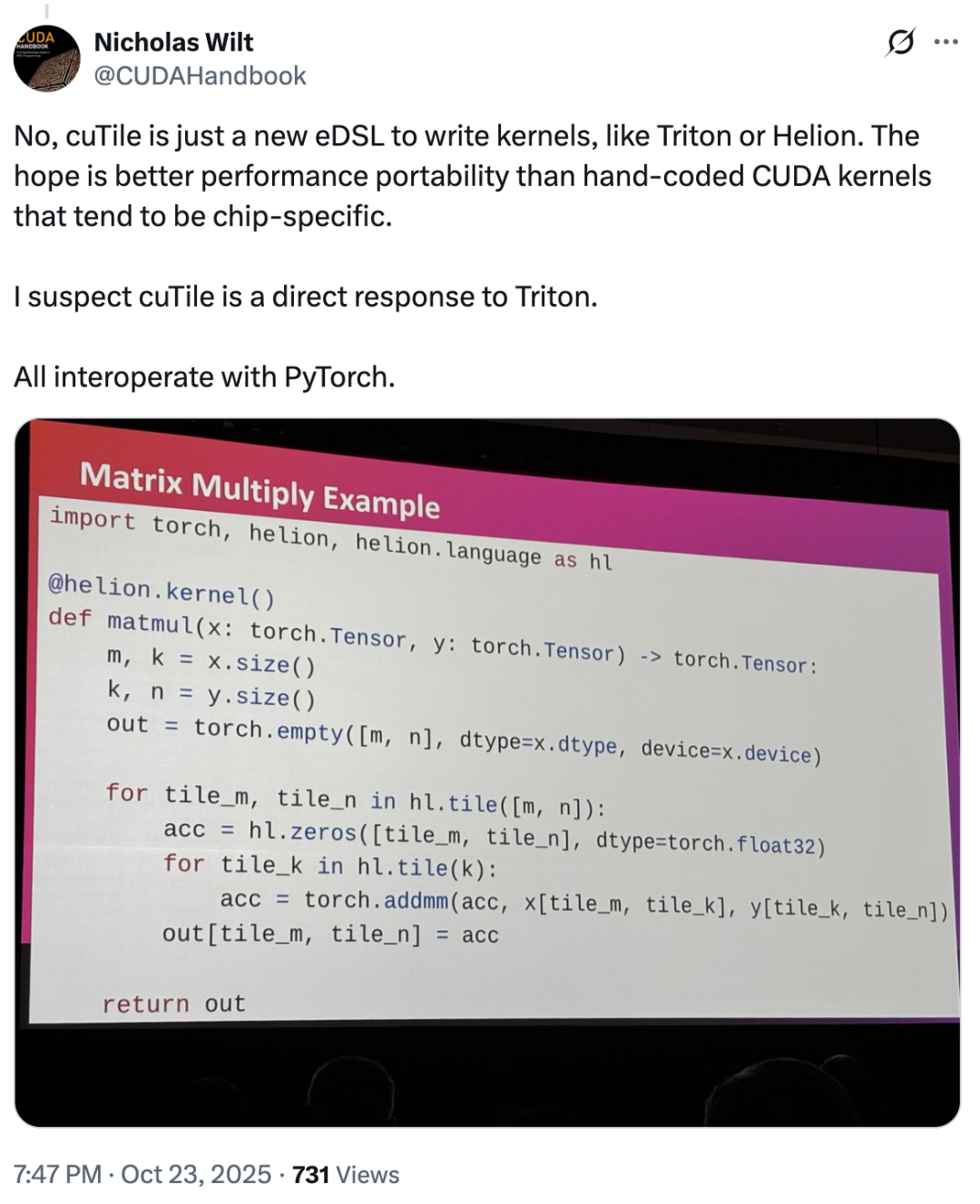
Hat cuTile also Triton kopiert? Die meisten Nutzer verneinten dies – tatsächlich fiel die Marktreaktion auf cuTile im Allgemeinen optimistisch aus, es gab nur wenige abweichende Meinungen.Die meisten Nutzer äußerten sich nicht unzufrieden über dieses Update; einige lobten cuTile sogar als ein „revolutionäres Produkt“.„cuTile beseitigt die Notwendigkeit für Benutzer, sich Gedanken über Speicherauslagerung, Warp-SPCLZ, Speicherzusammenführung und über hundert andere Probleme zu machen.“
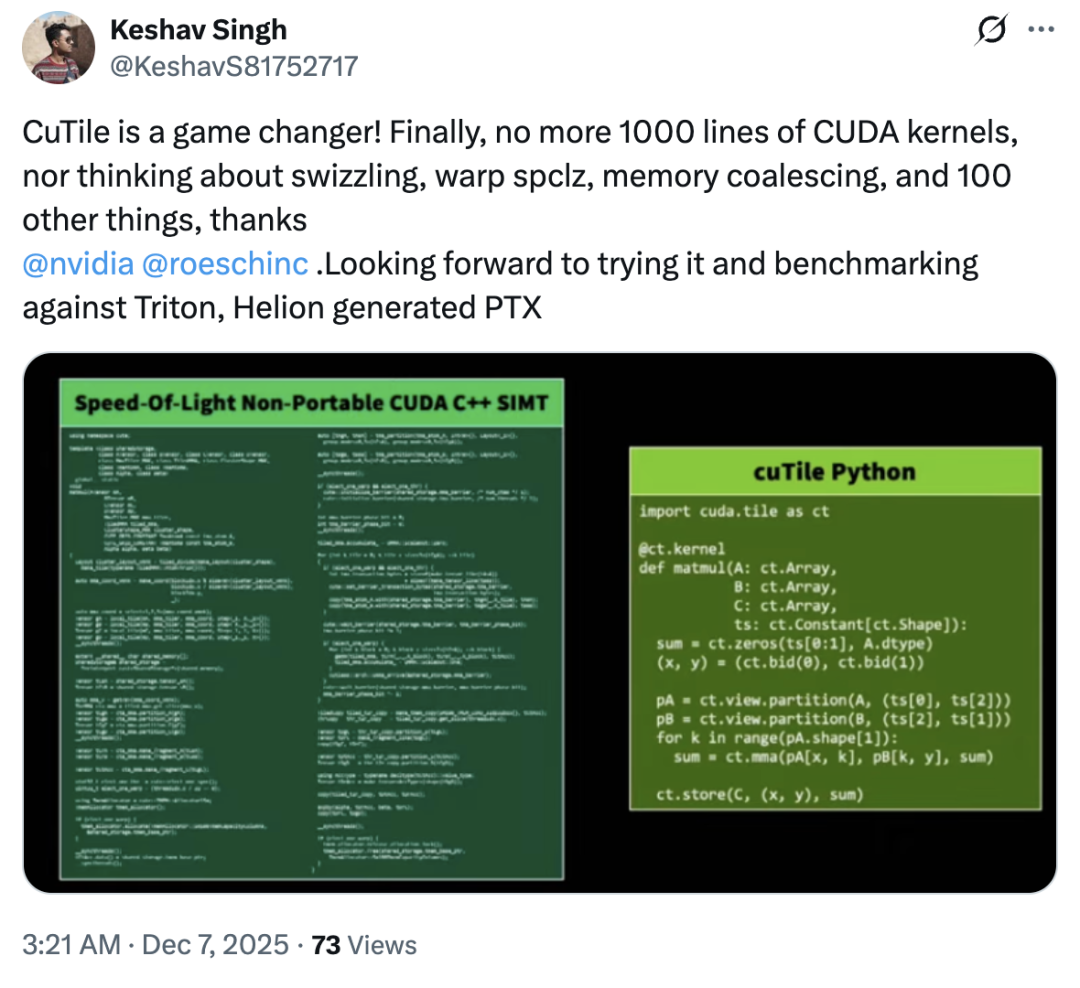
Laut einem Tech-Blog liegt der Hauptreiz von cuTile bei der Gewinnung von Nutzern in seinem „Tile“-Konzept, das GPU-Computing auf eine höhere Abstraktionsebene hebt.
„Ich dachte zunächst, es handele sich lediglich um eine weitere Python-Anbindung oder einen vereinfachten Wrapper für CUDA, aber nach eingehender Betrachtung der Dokumentation und der Beispiele stellte ich fest, dass es viel größere Ambitionen hat.“ Die Kernidee von cuTile ist Tile, was für paralleles Rechnen und Hardwarebeschleunigung relevant ist.Tiling ist eine klassische Optimierungstechnik, die große Datensätze in kleinere Teile zerlegt, um Caches oder gemeinsam genutzten Speicher besser auszunutzen. cuTile hebt dieses Konzept auf die Ebene eines Programmiermodells. Im Blog heißt es: „Entwickler können Berechnungen direkt in Form von Tiles denken und beschreiben. Sie müssen nicht mehr explizit verwalten, wie die einzelnen Threads in einem Thread-Block zusammenarbeiten, wie Daten vom globalen Speicher in den gemeinsam genutzten Speicher geladen werden oder wie die Synchronisierung erfolgt. Stattdessen definieren Sie die Tiles Ihrer Daten, die auf diesen Tiles ausgeführten Operationen, und der cuTile-Compiler generiert automatisch effizienten Kernel-Code, der sich um diese mühsamen Details auf niedriger Ebene kümmert.“
Obwohl sich cuTile noch in der Anfangsphase befindet, gab es bereits Fälle, in denen proaktiv Migrationswege innerhalb der Branche erkundet wurden.Einige Algorithmenexperten haben damit begonnen, automatisierte Konvertierungswerkzeuge von CUDA C++ zu cuTile zu entwickeln.Ziel ist es, eine tragfähige Brücke zwischen bestehendem Entwicklungscode und dem neuen Paradigma zu schlagen. Im Rahmen dieser Bemühungen haben Entwickler der Reddit-Community ein Open-Source-Projekt ins Leben gerufen, das Teile des CUDA-Kernels in ein kachelbasiertes Format übersetzen kann, um den potenziellen Migrationsbedarf der Community zu decken.
Wie weit kann NVIDIAs „Tile“-Paradigma jedoch reichen? Als neues Produkt befindet sich cuTile erst in der Validierungsphase. Sollte die Migrations-Toolchain von CUDA zu cuTile weiter ausgereift sein und die Community bereit sein, neue Experimentier- und Diskussionskreise rund um cuTile zu bilden, könnte cuTile eine beispiellose Stellung im zukünftigen GPU-Software-Ökosystem einnehmen.Das Ergebnis, wenn diese Schwellenwerte nicht überschritten werden, ist jedoch ziemlich eindeutig – cuTile könnte sich in der langen Geschichte von CUDA als ein kurzes Experiment erweisen.Zusammenfassend lässt sich sagen, dass die anhaltende Attraktivität von cuTile im aktuellen Wettbewerbsumfeld von seiner Fähigkeit abhängen wird, das Entwicklungserlebnis kontinuierlich zu optimieren, die Migrationskosten zu senken und komplexen Betreibern unersetzliche Leistungsvorteile zu bieten.
Referenzlinks:
1.https://byteiota.com/nvidia-cutile-python-gpu-kernel-programming-without-cuda-complexity/
2.https://veyvin.com/archives/github-trending-2025-12-08-nvidia-cutile-python
3.https://cloud.tencent.com/developer/article/2512674
4.https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware








