Command Palette
Search for a command to run...
Das Team Von David Baker Hat Ein Wichtiges Update Angekündigt: RFantibody Ermöglicht Die Entwicklung Maßgeschneiderter Antikörper Für Bestimmte Ziele; VisualOverload Erweitert Die Grenzen Des Visuellen Verständnisses Und Ermöglicht Neue Durchbrüche Bei Der Komplexen Szenenbetrachtung.

Antikörper sind die Hauptstütze der aktuellen Proteintherapie. Weltweit sind über 160 Antikörpermedikamente zur Vermarktung zugelassen, und es wird erwartet, dass das Marktvolumen in den nächsten fünf Jahren 445 Milliarden US-Dollar erreichen wird.Die Entwicklung therapeutischer Antikörper beruht jedoch noch immer hauptsächlich auf der Immunisierung von Tieren oder dem Screening von Kandidatenmolekülen aus großen Antikörperbibliotheken.Diese Methoden sind nicht nur zeit- und arbeitsintensiv, sondern erschweren oft auch die präzise Entwicklung neuer Antikörper, die zu den spezifischen Epitopen auf dem Ziel passen.
Auf dieser GrundlageDas Team von David Baker hat eine neue Generation von Antikörper- und Nanoantikörper-Designtools namens RFantibody herausgebracht, die auf Basis von RFdiffusion fein optimiert wurde.Das Tool wurde entwickelt, um Forschern und Biotechnologieingenieuren eine effiziente De-novo-Designmethode bereitzustellen. Es nutzt Deep Learning, um Antikörperstrukturen (insbesondere CDR-Regionen) zu generieren, verwendet dann ProteinMPNN, um Sequenzen zu entwerfen und verwendet anschließend RF2 (RoseTTAFold2), um zu überprüfen, ob sie sich in die erwartete Struktur falten.
Als effizientes Proteindesign-Tool wird RFantibody häufig in der biomedizinischen Forschung, der Arzneimittelentwicklung, der Impfstoffentwicklung und anderen Bereichen eingesetzt und stellt ein neues Werkzeug für die biomedizinische Forschung dar.
Auf der offiziellen Website von HyperAI wurde das „RFantibody: Antibody and Nanobody Design Tool“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/sO07A
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 15. bis 19. September:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 7
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im September: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. ConstructionSite Baustellen-Bilddatensatz
ConstructionSite ist ein multimodaler Benchmark-Datensatz für Baustellenszenarien, der entwickelt wurde, um das Bildverständnis und die Argumentationsfähigkeiten von Vision-Language-Modellen in Baustellensicherheitsumgebungen zu bewerten und zu verbessern. Dieser Datensatz enthält komplexe Szenen, vielfältige Anmerkungen und kommt tatsächlichen Baustellensicherheitsinspektionen sehr nahe. Er eignet sich für Aufgaben wie Bildbeschriftung, visuelle Fragenbeantwortung, Objekterkennung, visuelle Lokalisierung und multimodales Denken.
Direkte Nutzung: https://go.hyper.ai/ZRy12
2. HTSC-2025-Benchmark-Datensatz für Hochtemperatur-Supraleiter bei atmosphärischem Druck
HTSC-2025 ist ein Benchmark-Datensatz zur Vorhersage der kritischen Temperatur von Hochtemperatur-Supraleitern bei Umgebungsdruck. Ziel ist es, standardisierte und vergleichbare Testproben für Modelle bereitzustellen und so die Weiterentwicklung und Validierung von Supraleitervorhersagen zu fördern. Der Datensatz enthält rund 140 Materialien und ist zur einfachen Verarbeitung im JSON/Parquet-Format gespeichert.
Direkte Nutzung: https://go.hyper.ai/G2bJB
3. VisualOverload-Datensatz zum Verständnis von Szenenbildern
VisualOverload ist ein Datensatz zur Bewertung des Szenenbildverständnisses. Er wurde entwickelt, um die Fähigkeit eines Modells zu testen, Details in komplexen Szenen visuell zu verstehen und zu beurteilen, ohne auf externes Wissen zurückzugreifen. Der Datensatz enthält 2.720 Frage-Antwort-Paare, bestehend aus hochauflösenden, gemeinfreien Gemälden, die oft mehrere Charaktere, Aktionen, Nebenhandlungen und komplexe Hintergründe zeigen.
Direkte Nutzung: https://go.hyper.ai/Acce1

4. WebExplorer-QA-Datensatz zur Informationsabfrage und Beantwortung von Fragen
WebExplorer-QA ist ein Datensatz für Informationsabruf und Webbrowsing. Ziel ist es, die Modellleistung bei komplexen mehrstufigen Schlussfolgerungen und der weitreichenden Webnavigation durch die systematische Generierung anspruchsvoller Abfrage-Antwort-Paare zu verbessern. Er eignet sich für das Training und die Evaluierung von Netzwerkagenten oder großen Sprachmodellen für die Informationssuche, Multi-Hop-/komplexe kontextuelle Schlussfolgerungen, die Verarbeitung von Eingabeaufforderungen im langen Kontext, den Tool-Aufruf und die Webnavigation.
Direkte Verwendung:https://go.hyper.ai/I58Ry
5. AnonyRAG Classic Novel Fragen-Antwort-Datensatz
AnonyRAG ist ein Frage-Antwort-Datensatz für Aufgaben zur Entitätsanonymisierung, der vom Tencent Youtu Lab, der Monash University und der Hong Kong Polytechnic University veröffentlicht wurde. Ziel ist es zu bewerten, ob das Retrieval Augmented Generation (RAG)-System auf das Abrufen angewiesen ist, um Beweise zu erhalten, wenn die Entität anonymisiert ist.
Direkte Nutzung: https://go.hyper.ai/jzqD9
6. RxnBench-Datensatz zur Beantwortung von Fragen zur organischen Chemie
RxnBench ist ein visueller Frage-Antwort-Datensatz zum Verständnis multimodaler chemischer Reaktionsbilder. Ziel ist es, die Fähigkeiten visueller Sprachmodelle für Aufgaben wie das Verständnis chemischer Reaktionsbilder, multimodales Denken und die Beantwortung wissenschaftlicher Fragen zu bewerten. Der Datensatz enthält 1.525 Multiple-Choice-Fragen zum Verständnis organischer chemischer Reaktionen, verfügbar auf Chinesisch und Englisch.
Direkte Nutzung: https://go.hyper.ai/Utkdo
7. SceneSplat-7K-3D-Rendering-Datensatz für Innenszenen
SceneSplat-7 ist der größte und hochwertigste 3D-Gaussian-Splats-Datensatz (3DGS) für Innenaufnahmen. Ziel ist es, das Verständnis und die semantischen Denkfähigkeiten vortrainierter Vision-Language-Modelle für reale 3D-Innenaufnahmen zu verbessern.
Direktzugriff: https://go.hyper.ai/HISAa
8. SSTQA – halbstrukturierter tabellarischer Datensatz zur Beantwortung von Fragen
SSTQA ist ein Benchmark-Datensatz für halbstrukturierte Tabellenfragen-Antwortaufgaben, der von der Shanghai Jiao Tong University in Zusammenarbeit mit der Simon Fraser University, der Tsinghua University und anderen Institutionen veröffentlicht wurde. Ziel ist es, das Verständnis und die Antwortfähigkeiten großer Sprachmodelle und Tabellenfragen-Antwortsysteme bei komplexen Layouts in echten Tabellen (wie zusammengeführten Zellen, hierarchischen Überschriften, mehrstufiger Verschachtelung usw.) zu testen.
Direkte Nutzung: https://go.hyper.ai/JoZyB
9. OmniSpatial Panoramic Spatial Reasoning Benchmark-Datensatz
OmniSpatial ist ein umfassender und anspruchsvoller standardisierter Benchmark-Datensatz für panoramisches räumliches Denken, der eine Lücke in der Bewertung des räumlichen Verständnisses in Vision-Language-Modellen schließen soll. Er eignet sich für das Training und die Bewertung der räumlichen Denkfähigkeiten großer multimodaler Modelle, insbesondere in Anwendungen wie intelligenter Navigation, erweiterter/virtueller Realität und dem Verständnis komplexer Szenen.
Direkte Nutzung: https://go.hyper.ai/a6ep8
10. Urban Issues Urban Issues Bilddatensatz
„Urban Issues“ ist ein öffentlicher Bildklassifizierungsdatensatz, der automatisierten und maschinellen Bildverarbeitungssystemen dabei helfen soll, öffentliche Infrastruktur und Umweltprobleme in städtischen Umgebungen zu identifizieren. Die Bilder in diesem Datensatz sind nach Kategorien geordnet, wobei jedes Bild einer Klasse zugeordnet und unter verschiedenen Hintergrund-, Beleuchtungs- und Blickwinkelbedingungen präsentiert wird.
Direkte Nutzung: https://go.hyper.ai/2id2J

Ausgewählte öffentliche Tutorials
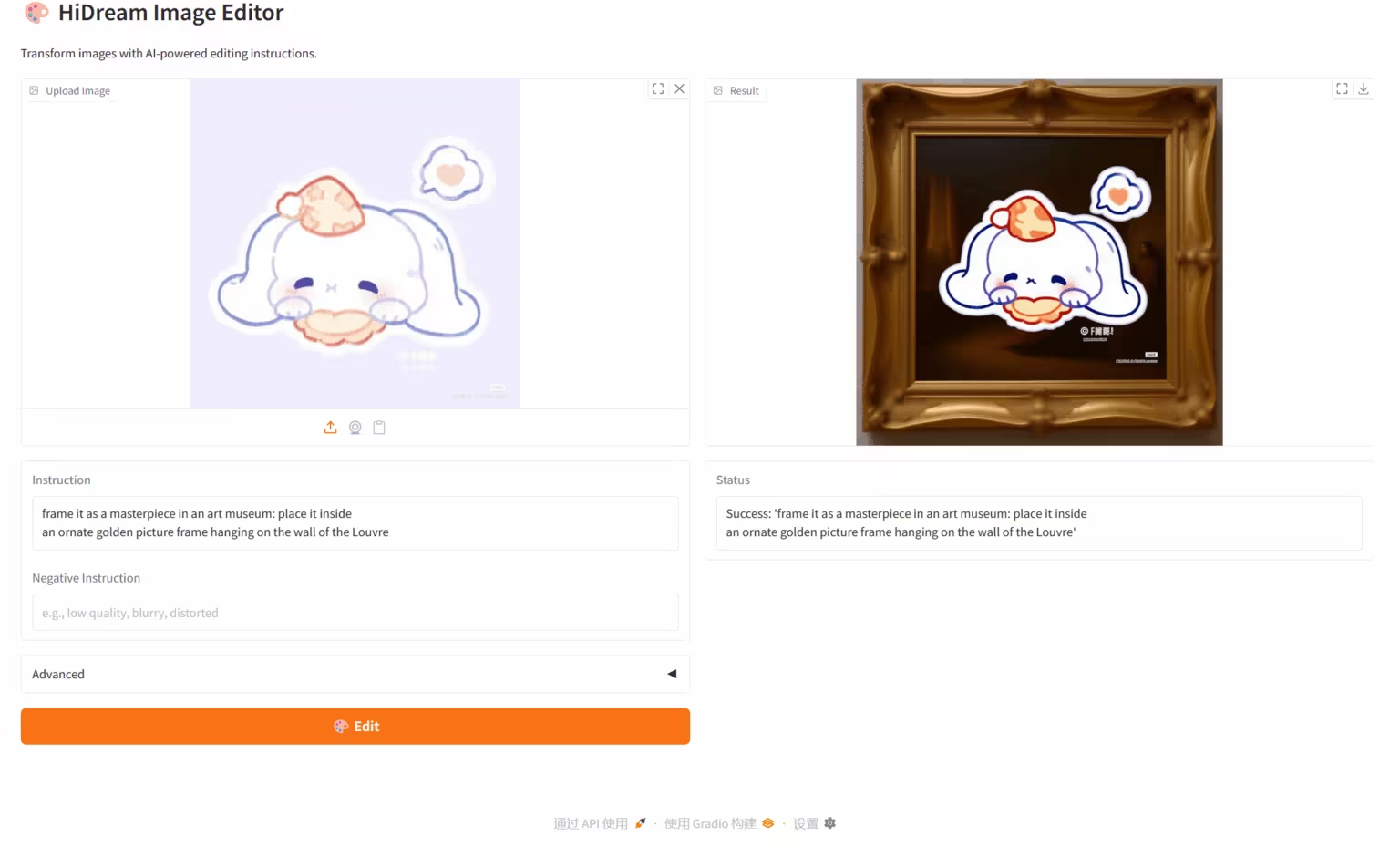
1. HiDream-E1.1: Befehlsbasierter Bildeditor
Das Modell HiDream-E1.1 ist ein Open-Source-Bildbearbeitungsmodell von Zhixiang Future. Es basiert auf der proprietären Sparse Diffusion Transformer-Architektur, unterstützt Megapixel-Auflösung und ist unter der MIT Open Source-Lizenz lizenziert. Das Modell implementiert die Funktion „Sprechen, Ändern“ zur Bildbearbeitung in natürlicher Sprache. Anwender können komplexe Aufgaben wie Farbkorrektur, Stilübertragung sowie das Hinzufügen und Entfernen von Elementen mit einfachen Sprachbefehlen ausführen, ohne dass spezielle Softwarekenntnisse erforderlich sind.
Online ausführen: https://go.hyper.ai/P9C3R
2. RFantibody: Antikörper- und Nanobody-Design-Tool
RFdiffusion2 ist ein von David Bakers Team entwickeltes Tool für das Design von Antikörpern und Nanokörpern. Es soll Forschern und Biotechnologie-Ingenieuren einen effizienten De-novo-Designansatz bieten. Im Kern nutzt das Tool Deep-Learning-Techniken, um die dreidimensionale Struktur und Aminosäuresequenz von Antikörpern anhand struktureller Informationen vorherzusagen und zu entwerfen. Dies ermöglicht die Entwicklung maßgeschneiderter Antikörper für spezifische Ziele.
Online ausführen: https://go.hyper.ai/sO07A
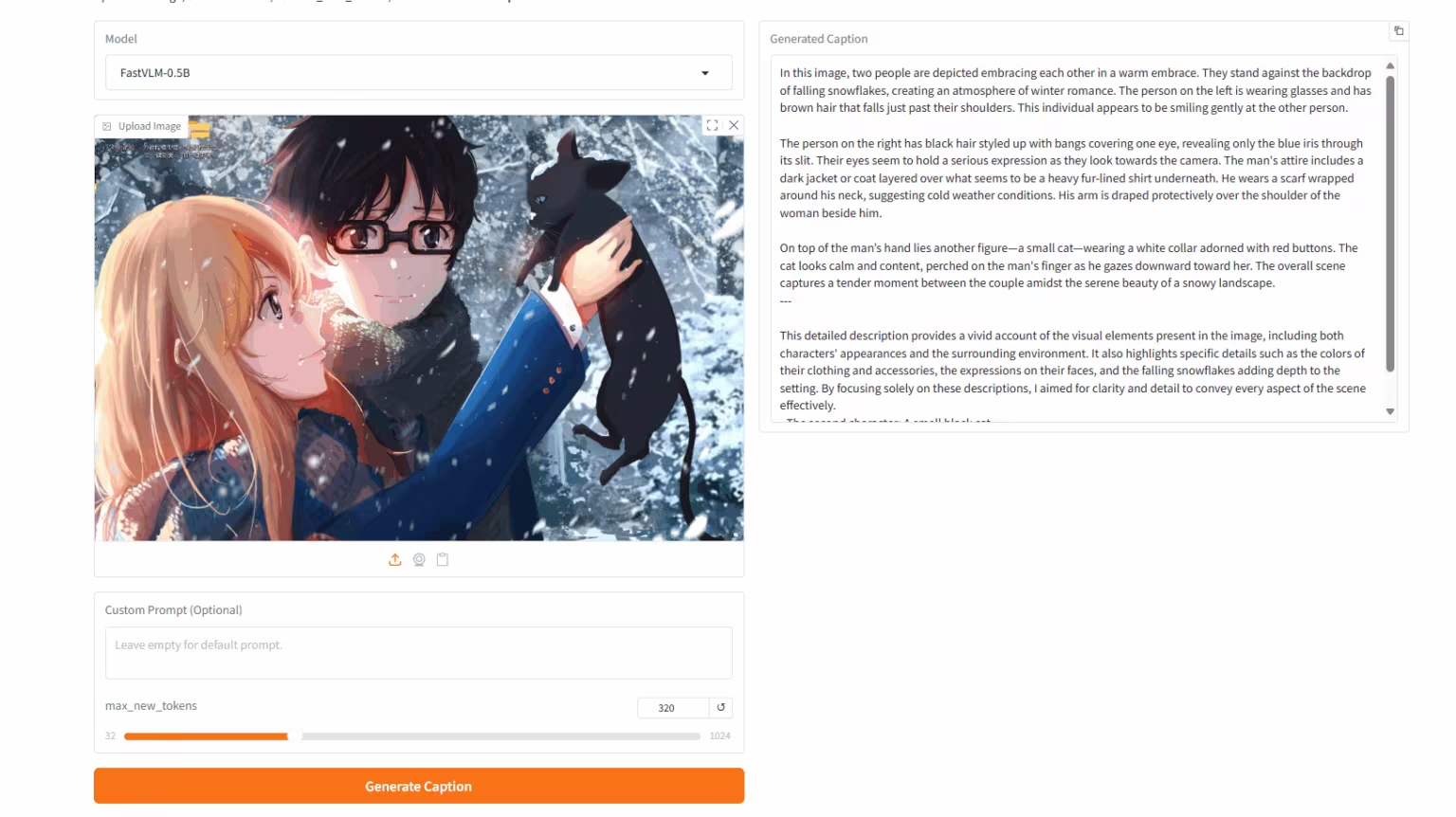
3. FastVLM: Extrem schnelles visuelles Sprachmodell
FastVLM ist ein hocheffizientes visuelles Sprachmodell (VLM), das vom Apple-Team entwickelt wurde. Es verbessert die Effizienz und Leistung der hochauflösenden Bildverarbeitung. Das Modell enthält den neuen Hybrid-Vision-Encoder FastViTHD, der die Anzahl der visuellen Token effektiv reduziert und die Kodierzeit deutlich verkürzt.
Online ausführen: https://go.hyper.ai/xg8wa
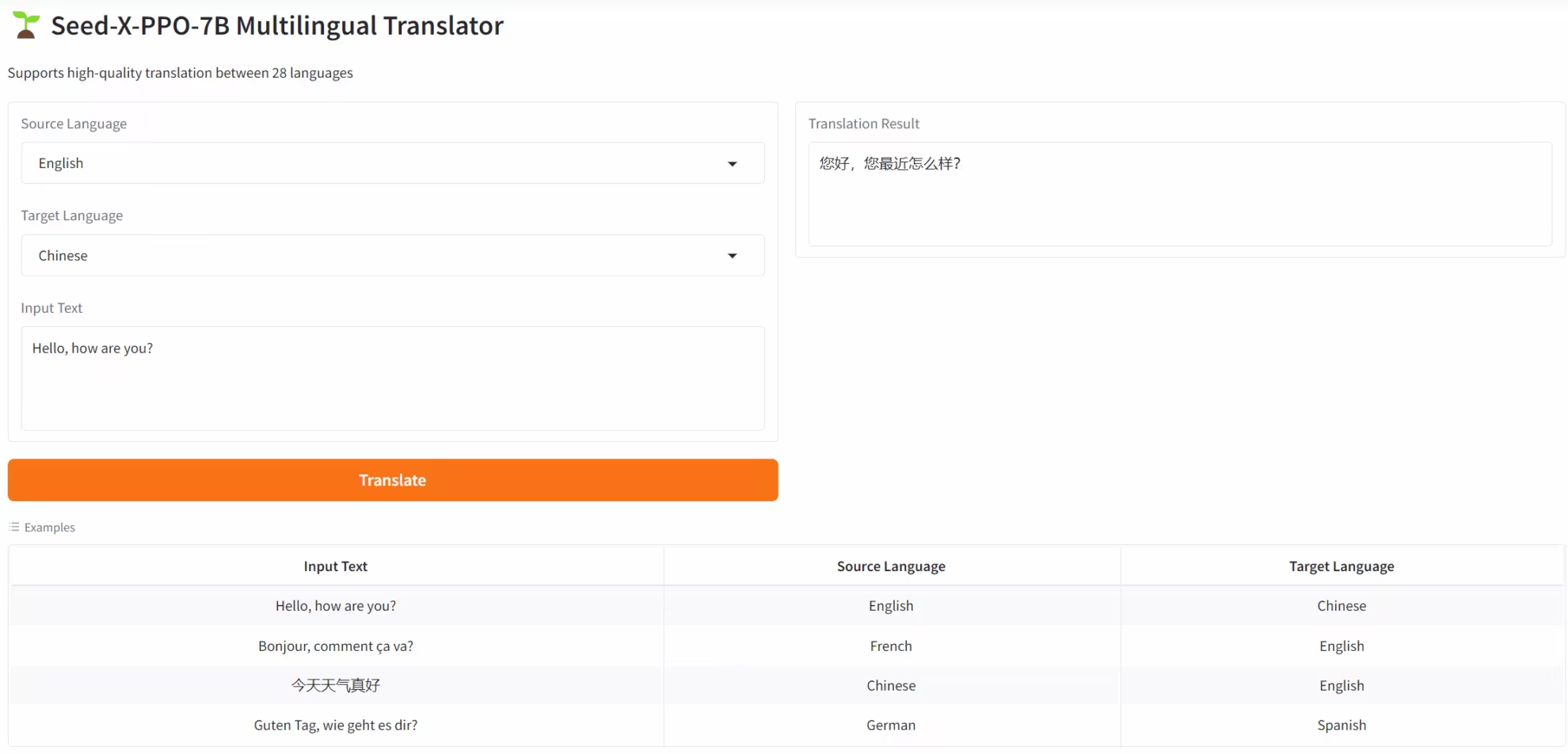
4. SEED-X-PPO-7B: Mehrsprachiges Übersetzungsmodell, optimiert durch Reinforcement Learning
SEED-X-PPO-7B ist ein mehrsprachiges Übersetzungsmodell der nächsten Generation, das vom ByteDance Seed-Team veröffentlicht wurde. Es basiert auf iterativer Optimierung mit dem Reinforcement-Learning-Algorithmus Proximal Policy Optimization (PPO) und zielt vor allem darauf ab, den Bedarf an hochpräziser semantischer Übertragung in sprachübergreifenden Szenarien zu erfüllen. Dieses Modell überwindet die Einschränkungen traditioneller Übersetzungsmodelle bei der Anpassung an Minderheitensprachen, der Wiederherstellung des kulturellen Kontexts und der Gewährleistung der Kohärenz in langen Texten und unterstützt die Übersetzung zwischen 28 gängigen Sprachen, darunter Chinesisch, Englisch und Deutsch.
Online ausführen: https://go.hyper.ai/aw5oS
5. SRPO: Verabschieden Sie sich von der Bildgenerierung im KI-Stil!
SRPO ist ein Modell zur Generierung von Text in Bilder, das gemeinsam vom Tencent Hunyuan-Team, der School of Science der Chinese University of Hong Kong, Shenzhen, und der Shenzhen International Graduate School der Tsinghua University entwickelt wurde. Durch die Gestaltung des Belohnungssignals als textbedingtes Signal ermöglicht es eine Online-Anpassung der Belohnung und reduziert die Abhängigkeit von einer Offline-Feinabstimmung der Belohnung.
Online ausführen: https://go.hyper.ai/8OQxS

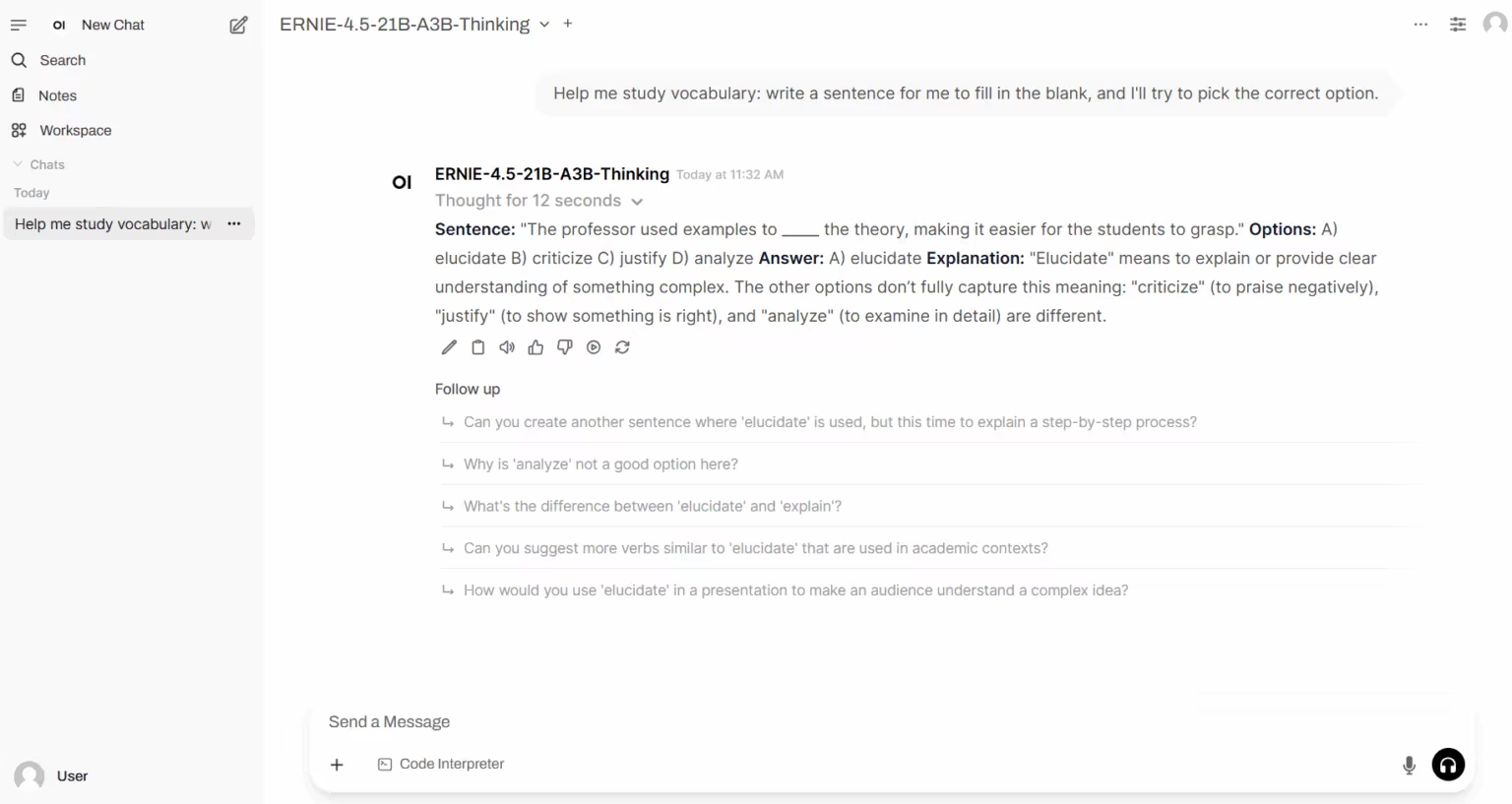
6. ERNIE-4.5-21B-A3B-Thinking: Verbesserte Fähigkeiten zur leichten Modellbegründung
ERNIE-4.5-21B-A3B-Thinking ist eine leichtgewichtige „Denkversion“ des Inferenzmodells des Baidu Wenxin Yiyan-Teams. Dieses Modell verwendet eine Mischung aus Experten (MoE)-Architektur, hat eine Gesamtparametergröße von 21B und jedes Token aktiviert 3B Parameter. Es wird durch Feinabstimmung der Anweisungen und bestärkendes Lernen trainiert.
Online ausführen: https://go.hyper.ai/bQmlo
7. RFdiffusion2: Protein-Design-Tool
RFdiffusion2 ist ein Deep-Learning-Proteindesignmodell des Institute for Protein Design der University of Washington. Dieses Modell generiert nicht nur Enzymgerüste mit maßgeschneiderten aktiven Zentren auf der Grundlage einfacher chemischer Reaktionsbeschreibungen, sondern überwindet auch bisherige technische Engpässe im Katalysatordesign erheblich und bietet so umfassende technische Unterstützung für wichtige Anwendungen wie den Kunststoffabbau.
Online ausführen: https://go.hyper.ai/9YInD
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. OmniWorld: Ein Multi-Domain- und Multi-Modal-Datensatz für die 4D-Weltmodellierung
Dieses Dokument stellt OmniWorld vor, einen umfangreichen, multidomänen und multimodalen Datensatz zur Modellierung vierdimensionaler Welten. Dieser Datensatz besteht aus dem neu gesammelten OmniWorld-Game-Datensatz und mehreren ausgewählten öffentlichen Datensätzen und deckt eine Vielzahl von Anwendungsszenarien ab.
Link zum Artikel: https://go.hyper.ai/SbW2Y
2. WebWeaver: Strukturierung von Beweisen im Web-Maßstab mit dynamischen Gliederungen für offene, tiefgehende Forschung
Dieses Papier stellt ein neuartiges Dual-Agent-Framework namens WebWeaver vor, das den menschlichen Forschungsprozess nachbilden soll. Der Planungsagent arbeitet in einer dynamischen Schleife und verknüpft iterativ Beweismittelbeschaffung und Gliederungsverfeinerung, um eine umfassende, quellenbasierte, strukturierte Gliederung zu erstellen, die mit einem Beweismittelspeicher verknüpft ist. Anschließend führt der Schreibagent einen hierarchischen Abruf- und Schreibprozess durch und vervollständigt die Berichtserstellung Abschnitt für Abschnitt.
Link zum Artikel: https://go.hyper.ai/lqMvM
3. Skalierung von Agenten durch kontinuierliches Vortraining
In diesem Artikel wird erstmals die Integration von agentenkontinuierlichem Vortraining (Agentic CPT) in den Trainingsprozess von Deep-Learning-Agenten vorgeschlagen, um ein robustes agentenbasiertes Modell zu erstellen. Basierend auf diesem Ansatz entwickelten Forscher ein Deep-Learning-Agentenmodell namens AgentFounder.
Link zum Artikel: https://go.hyper.ai/6lyWG
4. WebSailor-V2: Überbrückung der Kluft zu proprietären Agenten durch synthetische Daten und skalierbares Verstärkungslernen
Dieses Dokument stellt eine umfassende Post-Training-Methodik namens WebSailor vor, die durch strukturiertes Sampling und Informationsunschärfe neuartige Aufgaben mit hoher Unsicherheit generiert. Es verwendet eine RFT-Kaltstartstrategie und kombiniert diese mit einem hocheffizienten agentenbasierten Reinforcement-Learning-Trainingsalgorithmus, Repeated Sampling Policy Optimization (DUPO). Durch diesen integrierten Prozess übertrifft WebSailor alle bestehenden Open-Source-Agenten bei komplexen Informationsabrufaufgaben deutlich, nähert sich der Leistung proprietärer Agenten an und verringert die Leistungslücke effektiv.
Link zum Artikel: https://go.hyper.ai/biWLb
5. Technischer Bericht von Hala: Entwicklung arabischzentrierter Unterrichts- und Übersetzungsmodelle im großen Maßstab
Dieses Dokument stellt Hala vor, eine Familie von Unterrichts- und Übersetzungsmodellen mit Schwerpunkt auf Arabisch. Hala basiert auf einer proprietären Übersetzungs-Feinabstimmungs-Pipeline und erreicht sowohl in der Kategorie „Nano“ (≤ 2 Milliarden Parameter) als auch in der Kategorie „Klein“ (7–9 Milliarden Parameter) bei zentralen arabischen Benchmarks Spitzenleistungen und übertrifft damit sein Basismodell deutlich.
Link zum Artikel: https://go.hyper.ai/KI73S
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Forschungsteams der Chinesischen Akademie der Wissenschaften, der Northeast Agricultural University, der Universität Macau und der Jilin University haben gemeinsam ein neues Twin-Clustering-Framework namens scSiameseClu zur Interpretation von Einzelzell-RNA-Sequenzdaten vorgeschlagen. Es kann das Problem des Repräsentationskollapses wirksam lindern, eine klarere Klassifizierung der Zellpopulation ermöglichen und ein leistungsstarkes Werkzeug für die Analyse von scRNA-Sequenzdaten bereitstellen.
Den vollständigen Bericht ansehen: https://go.hyper.ai/hyDFA
Im September 2025 veröffentlichte das Tencent Hunyuan-Team das leichtgewichtige Übersetzungsmodell Hunyuan-MT-7B, das Übersetzungen zwischen 33 Sprachen und fünf ethnischen chinesischen Sprachen/Dialekten unterstützt. Mit nur 7 Milliarden Parametern ermöglicht es eine effiziente und präzise Übersetzung. Beim WMT2025-Wettbewerb der Association for Computational Linguistics (ACL) belegte dieses Modell in 30 von 31 Sprachkategorien den ersten Platz und erzielte damit eine beeindruckende Leistung.
Den vollständigen Bericht ansehen: https://go.hyper.ai/y2X2L
In den letzten Jahren haben Häufigkeit und Intensität extremer Regenfälle in Mumbai deutlich zugenommen. Herkömmliche globale Vorhersagesysteme können lokale Wettermuster aufgrund unzureichender Auflösung nur schwer erfassen. Um diesem Problem zu begegnen, entwickelte das Indian Institute of Technology (IIT) Bombay in Zusammenarbeit mit der University of Maryland ein Vorhersagemodell auf Basis von Convolutional Neural Networks und Transfer Learning, das eine frühzeitige Vorhersage extremer Regenfälle ermöglicht.
Den vollständigen Bericht ansehen: https://go.hyper.ai/wYsSk
Die Forschungsergebnisse von DeepSeek-R1 erschienen auf dem Titelblatt von Nature und lösten in der weltweiten akademischen Gemeinschaft hitzige Diskussionen aus. Die Bedeutung dieser Veröffentlichung in Nature liegt in der Begutachtung durch dieses renommierte Journal.
Den vollständigen Bericht ansehen: https://go.hyper.ai/B12hL
Google DeepMind hat in Zusammenarbeit mit Forschern der New York University, der Stanford University, der Brown University und anderer Institutionen auf der Grundlage eines maschinellen Lernrahmens und eines hochpräzisen Gauss-Newton-Optimierers erstmals systematisch neue instabile Singularitäten in drei verschiedenen Flüssigkeitsgleichungen entdeckt und eine einfache empirische asymptotische Formel enthüllt, die die Explosionsrate mit der Instabilitätsordnung verknüpft.
Den vollständigen Bericht ansehen: https://go.hyper.ai/hq5og
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








