Command Palette
Search for a command to run...
Erreichen Sie Eine Detaillierte Charakterisierung Von TCR-Sequenzen! Das Deep-Learning-Framework DeepTCR Erweitert Die Immunologischen Forschungsmethoden; Unterstützt Durch Die Daten Von 50.000 Lungenkrebspatienten! Lung Cancer Risk Beschreibt Detailliert Die Risikofaktoren Für Lungenkrebs.

Die T-Zell-Rezeptor-Sequenzierung (TCR-Seq) ist eine wichtige Anwendung der Next-Generation-Sequencing-Technologie (NGS), die es Forschern ermöglicht, die Vielfalt adaptiver Immunantworten systematisch zu charakterisieren. Bei der Analyse von T-Zell-Rezeptor-Sequenzierungsdaten haben traditionelle Methoden (wie Motivsuche oder Sequenzalignment) zwar Ergebnisse erzielt, sind aber auch allmählich an ihre Grenzen gestoßen.Bei der Identifizierung niederfrequenter antigenspezifischer T-Zell-Reaktionen im Körper werden deren Signale häufig durch eine große Anzahl unspezifischer T-Zell-Hintergründe überlagert.Dies spiegelt die Herausforderungen wider, denen herkömmliche Methoden bei der Unterscheidung von Signalen und Rauschen gegenüberstehen.
Da die Nachfrage nach einer verfeinerten Charakterisierung von TCR-Sequenzen weiter wächst, haben Forscher ihre Aufmerksamkeit auf Deep-Learning-Technologien gerichtet, die durch Convolutional Neural Networks (CNNs) repräsentiert werden.DeepTCR entwickelte sich zu einem auf Deep Learning basierenden Framework zur Sequenzanalyse von Immunrezeptoren.Das Framework kann CDR3-Sequenzen, V/D/J-Gennutzung und MHC-Molekültypeigenschaften aus TCR-Sequenzierungsdaten des Immunrepertoires lernen und eine gemeinsame Darstellung erstellen, um hochkomplexe TCR-Sequenzierungsdaten zu modellieren.
DeepTCR wendet das Deep-Learning-Framework systematisch auf die TCR-Sequenzanalyse an, was nicht nur die Analysemethoden der immunologischen Forschung erweitert, sondern auch die breite Anwendung der Deep-Learning-Technologie in verschiedenen Bereichen demonstriert.
Auf der offiziellen Website von HyperAI wurde „DeepTCR: Vorhersage der TCR-Peptid-Affinität mithilfe von Deep Learning“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/gKmgi
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 8. bis 12. September:
* Hochwertige öffentliche Datensätze: 10
* Ausgewählte hochwertige Tutorials: 2
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im September: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Neuer Bilddatensatz zu Pflanzenkrankheiten
„New Plant Diseases“ ist ein Bilddatensatz zur Identifizierung von Pflanzenkrankheiten und zur Blattklassifizierungsforschung. Er deckt gesunde Blätter und verschiedene Krankheitstypen ab. Er eignet sich hervorragend für die Entwicklung und Evaluierung von Modellen für maschinelles Lernen und Deep Learning, insbesondere für die Überwachung der Pflanzengesundheit, die Krankheitserkennung, Präzisionslandwirtschaftsmodelle und die akademische Forschung, und hat einen wichtigen Benchmark-Wert.
Direkte Nutzung: https://go.hyper.ai/RKYtW

2. Intel Image Classification Natural Scene Image Classification Dataset
Intel Image Classification ist ein von Intel veröffentlichter Bildklassifizierungsdatensatz zur Klassifizierung von Bildern natürlicher und künstlicher Szenen. Der Datensatz enthält rund 25.000 Farbbilder, die in sechs Kategorien, darunter Gebäude und Wälder, unterteilt sind.
Direkte Nutzung: https://go.hyper.ai/qgbeX

3. LongPage-Datensatz für neuartiges Denken
LongPage ist der erste umfassende Datensatz für das Training künstlicher Intelligenzmodelle zum Schreiben kompletter Romane mit komplexen Denkfähigkeiten. Er unterstützt die überwachte Feinabstimmung von Trainingsprozessen mit bestärkendem Lernen und eignet sich für das Training umfangreicher Sprachmodelle mit hierarchischen Denkfähigkeiten sowie zur Verbesserung der Kohärenz und Planung längerer Texte.
Direkte Nutzung: https://go.hyper.ai/odoKA
4. Datensatz zum Lungenkrebsrisiko
„Lung Cancer Risk“ ist ein tabellarischer Datensatz zur Vorhersage des Lungenkrebsrisikos und zur Analyse von Gesundheitsfaktoren. Ziel ist es, den Zusammenhang zwischen Rauchgewohnheiten, Lebensstil und Lungenkrebsrisiko anhand multidimensionaler Merkmale zu untersuchen. Er eignet sich für die Modellierung des Lungenkrebsrisikos, die medizinische maschinelle Lernforschung, die Entwicklung von Gesundheitsprognosesystemen und Lehrexperimente. Besonders wertvoll ist er für Klassifizierungsmodellierungen und Risikobewertungsszenarien.
Direkte Verwendung:https://go.hyper.ai/YGFzG
5. IFEval – Inverse Reverse Instruction Evaluation Dataset
IFEval-Inverse ist ein Datensatz zur Bewertung von gegnerischen Anweisungen für große Sprachmodelle, der von ByteDance Seed in Zusammenarbeit mit der Universität Nanjing, der Universität Tsinghua und anderen Institutionen veröffentlicht wurde. Ziel ist es zu testen, ob das Modell die Trainingsträgheit durchbrechen und bei umgekehrten oder abnormalen Anweisungen echte Anweisungskonformität erreichen kann.
Direkte Nutzung: https://go.hyper.ai/IcTqj
6. FinReflectKG Financial Knowledge Graph-Datensatz
FinReflectKG ist ein umfangreicher Wissensgraphen-Datensatz für den Finanzsektor. Ziel ist es, strukturierte semantische Beziehungen aus regulatorischen Unternehmensdokumenten zu extrahieren und die Entwicklung der Wissensgraphenforschung im Finanzbereich zu fördern. Es eignet sich für die Entitätserkennung, Beziehungsextraktion, Wissensgraphenkonstruktion, Zeitreihenanalyse, die groß angelegte, sprachmodellbasierte Informationsextraktionsbewertung und die nachgelagerte Entwicklung intelligenter Finanzanwendungen im Finanzbereich.
Direkte Nutzung: https://go.hyper.ai/EB5em
7. WenetSpeech Yue Kantonesischer Korpus-Datensatz
WenetSpeech Yue ist ein umfangreiches, mehrdimensional annotiertes Sprachkorpus für die kantonesische Spracherkennung (ASR) und Text-to-Speech-Synthese (TTS). Ziel ist es, die Ressourcenlücke im kantonesischen Bereich zu schließen und die Schulung und Evaluation hochwertiger kantonesischer Modelle zu fördern.
Direktzugriff: https://go.hyper.ai/cICOv
8. UCIT-Datensatz zur kontinuierlichen Befehlsoptimierung
UCIT ist ein Benchmark-Datensatz für die kontinuierliche Anweisungsoptimierung multimodaler Sprachmodelle im großen Maßstab. Jedes Beispiel in diesem Datensatz besteht aus einer Aufgabenbeschreibung (Eingabeaufforderung/Anweisung) und der entsprechenden korrekten Ausführungserwartung (Ground-Truth-Antwort), die zur Messung der Leistung des Modells unter Zero-Shot-Bedingungen verwendet wird.
Direkte Nutzung: https://go.hyper.ai/TZPwY
9. LoongBench Multi-Domain Reasoning Benchmark-Datensatz
LoongBench ist ein Datensatz zur Bewertung des schlussfolgernden Denkens in mehreren Domänen, der LLM eine überprüfbare Trainings- und Bewertungsressource für mehrere Domänen bietet. Der Datensatz enthält 8.729 Fragen zur natürlichen Sprache aus 12 schlussfolgerungsintensiven Domänen, darunter höhere Mathematik und fortgeschrittene Physik.
Direkte Nutzung: https://go.hyper.ai/AcFOZ
10. CA‑1-Datensatz zur Ausrichtung menschlicher Präferenzen
CA-1 konzentriert sich auf menschliche Werturteile und Präferenzen für das Standardverhalten von KI-Modellen. Es handelt sich um einen Datensatz zum menschlichen Feedbackverhalten, der modellgenerierte Inhalte und Bewertungen von Kommentatoren kombiniert. Er eignet sich für die Untersuchung von Gruppenausrichtungsunterschieden, die Steuerung von Modellverhaltensnormen und die Entwicklung wertsensitiver Belohnungsmechanismen.
Direkte Nutzung: https://go.hyper.ai/mXznO
Ausgewählte öffentliche Tutorials
1. Wan2.2-S2V-14B: Audiogesteuerte Videogenerierung in Filmqualität
Wan2.2-S2V-14B ist ein Open-Source-Modell zur audiogesteuerten Videogenerierung, das vom Alibaba Tongyi Wanxiang-Team entwickelt wurde. Mit nur einem einzigen Standbild und Audio kann es digitale Menschenvideos in Kinoqualität mit einer Länge von bis zu mehreren Minuten generieren und unterstützt dabei eine Vielzahl von Bildtypen und -größen. Das Modell integriert mehrere innovative Technologien, um die audiogesteuerte Videogenerierung für komplexe Szenen zu ermöglichen und unterstützt die Generierung langer Videos sowie Training und Inferenz mit mehreren Auflösungen.
Online ausführen: https://go.hyper.ai/TlSai
2. DeepTCR: Deep Learning zur Vorhersage der TCR-Peptid-Affinität
DeepTCR ist ein Deep-Learning-basiertes Framework zur Analyse der Immunrezeptor-Sequenzierung. Es kann Affinitäten aus TCR-Sequenzierungsdaten des Immunrepertoires vorhersagen, TCR-CDR3-Sequenzen, die V/D/J-Gennutzung oder MHC-Molekültypmerkmale extrahieren und erlernen und TCRs gemeinsam darstellen, um hochkomplexe TCR-Sequenzierungsdaten zu modellieren. Es kann antigenspezifische TCRs aus Einzelzell-RNA-Sequenzierung mit Hintergrundrauschen und T-Zellkultur-basierten Assays extrahieren.
Online ausführen: https://go.hyper.ai/gKmgi
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Teilen ist Fürsorge: Effizientes LM-Nachtraining mit kollektivem RL-Erfahrungsaustausch
Dieses Dokument stellt Swarm SAmpling Policy Optimization (SAPO) vor, einen vollständig dezentralen und asynchronen Post-Training-Algorithmus für Reinforcement Learning. SAPO ist für dezentrale Netzwerke heterogener Rechenknoten konzipiert. Jeder Knoten verwaltet autonom sein eigenes Richtlinienmodell und teilt seine Trajektorie mit anderen Knoten. Der Algorithmus basiert nicht auf expliziten Annahmen über Latenz, Modellhomogenität oder Hardwarekonfiguration, und Knoten können bei Bedarf unabhängig voneinander arbeiten.
Link zum Artikel: https://go.hyper.ai/MWeWF
2. Warum Sprachmodelle halluzinieren
Dieser Artikel geht davon aus, dass der grundlegende Grund für Halluzinationen bei Sprachmodellen darin liegt, dass ihre Trainings- und Evaluierungsmechanismen eher Raten belohnen als Unsicherheiten berücksichtigen. Darüber hinaus werden die statistischen Ursachen von Halluzinationen in modernen Trainingsprozessen analysiert. Die systematische Bestrafung unsicherer Antworten durch große Modelle legt nahe, dass die gängigen, aber verzerrten Benchmark-Bewertungsmethoden überarbeitet werden sollten, anstatt zusätzliche Messgrößen zur Bewertung von Halluzinationen einzuführen.
Link zum Artikel: https://go.hyper.ai/eXoOR
3. Reverse-Engineering-Argumentation für die offene Generierung
Dieses Papier schlägt ein neues Paradigma vor – Reverse-Engineered Reasoning (REER) –, das die Art und Weise, wie logisches Denken aufgebaut wird, grundlegend verändert. Im Gegensatz zu herkömmlichen Methoden, die Denkprozesse von Grund auf durch Versuch und Irrtum oder Nachahmung konstruieren, verfolgt REER eine „umgekehrte“ Strategie. Ausgehend von bekannten, qualitativ hochwertigen Lösungen entdeckt REER rechnerisch schrittweise die zugrunde liegenden, tiefen Denkpfade, die diese Lösungen generieren können.
Link zum Artikel: https://go.hyper.ai/xFygJ
4. Parallel-R1: Auf dem Weg zum parallelen Denken durch bestärkendes Lernen
Dieses Dokument stellt Parallel-R1 vor, das erste Framework für Reinforcement Learning (RL) für komplexe reale Denkaufgaben, das paralleles Denken ermöglicht. Dieses Framework verwendet ein progressives Curriculum-Design, um das Kaltstartproblem beim Training parallelen Denkens in RL explizit zu lösen.
Link zum Artikel: https://go.hyper.ai/s2OlH
5. WebExplorer: Erkunden und weiterentwickeln für die Schulung von Web-Agenten mit langem Horizont
Mithilfe eines sorgfältig erstellten, hochwertigen Datensatzes wurde in dieser Arbeit erfolgreich ein hochmodernes Web-Proxy-Modell, WebExplorer-8B, durch überwachtes Feintuning in Kombination mit Reinforcement Learning trainiert. Dieses Modell unterstützt Kontextlängen von bis zu 128 KB und kann bis zu 100 Tool-Aufrufe ausführen, was eine langfristige Problemlösung ermöglicht. In mehreren Benchmarks zur Informationsabfrage erreichte WebExplorer-8B die höchste Leistung unter Modellen ähnlicher Größe.
Link zum Artikel: https://go.hyper.ai/NusbG
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Forscher der Chinesischen Universität Hongkong, der Mohamed bin Zayed Universität für Künstliche Intelligenz und anderer Institutionen haben ein skalierbares, transkriptomgesteuertes Diffusionsmodell namens MorphDiff vorgeschlagen, das speziell dafür entwickelt wurde, die Reaktion der Zellmorphologie auf Störungen mit hoher Genauigkeit zu simulieren. Dieses Modell basiert auf der Architektur des Latent Diffusion Model (LDM) und verwendet L1000-Genexpressionsprofile als bedingte Eingabe für das Denoising-Training.
Den vollständigen Bericht ansehen: https://go.hyper.ai/f7WeP
Ein gemeinsames Forschungsteam der China University of Petroleum und der Yonsei University hat mehrere fortschrittliche Technologien integriert, um ein neues Framework namens AlphaPPIMI zu entwickeln. Durch die Kombination eines groß angelegten, vortrainierten Modells mit einem adaptiven Lernmechanismus zielt dieses Tool darauf ab, die zentrale Herausforderung der Entdeckung von Modulatoren zu bewältigen, die speziell auf die PPI-Schnittstelle abzielen, und so die zukünftige Entwicklung von PPI-gerichteten Medikamenten nachhaltig zu unterstützen.
Den vollständigen Bericht ansehen: https://go.hyper.ai/4tp0M
Am 10. September um 1:00 Uhr Pekinger Zeit konzentrierte sich Apples Herbstkonferenz 2025 ganz auf KI und kündigte KI-Upgrades für drei Kernprodukte an: das iPhone 17, die Apple Watch Series 11 und die AirPods Pro 3. Apple Intelligence hat sich von einer Konzeptpräsentation im letzten Jahr zu einer umfassenden Implementierung entwickelt und deckt Szenarien wie Echtzeitübersetzung, Gesundheitsüberwachung und visuelle Intelligenz ab. Die Chips der nächsten Generation A19 und M19 Pro bilden den Grundstein für die Rechenleistung.
Den vollständigen Bericht ansehen: https://go.hyper.ai/IimjS
Forschungsteams der Universität Wuhan und der Technischen Universität Nanyang haben gemeinsam einen Gesundheitsagenten entwickelt, der aus drei Komponenten besteht: Dialog, Gedächtnis und Verarbeitung. Er kann die medizinischen Zwecke von Patienten erkennen und automatisch medizinethische und sicherheitsrelevante Probleme aufdecken.
Den vollständigen Bericht ansehen: https://go.hyper.ai/AdG2j
Anfang September war Apple Berichten zufolge an der Übernahme des französischen Startups Mistral AI interessiert. Der Halbleiterriese ASML folgte diesem Beispiel und führte seine Finanzierungsrunde der Serie C mit 1,3 Milliarden Euro an. Die Bewertung des Unternehmens ist inzwischen auf 14 Milliarden Dollar gestiegen und macht es zu einer führenden Kraft im europäischen KI-Bereich.
Den vollständigen Bericht ansehen: https://go.hyper.ai/zsQBu
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
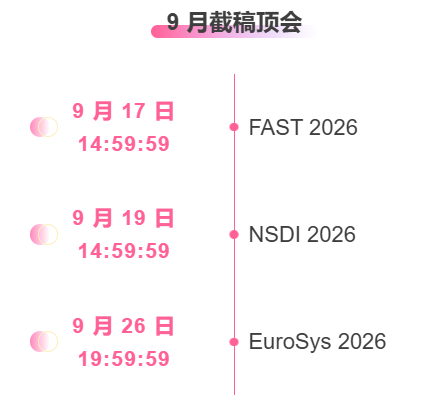
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








