Command Palette
Search for a command to run...
MiniCPM-V 4.0 Übertrifft GPT-4.1-mini in Der Leistung Und Erreicht Neue Höhen Bei Der Bildmodellierung Auf Dem Gerät; HelpSteer3 Bringt KI-Reaktionen Näher an Das Menschliche Denken heran.

Die technologische Entwicklung multimodaler Large Language Models (MLLMs) treibt die Entwicklung des KI-Ökosystems voran. Die Nachfrage der Nutzer nach Echtzeitinteraktion auf mobilen Geräten wie Smartphones und Tablets steigt deutlich. Traditionelle Large Models bieten zwar eine hervorragende Leistung, sind jedoch mit einer Vielzahl von Parametern belastet, was ihre Bereitstellung und Bedienung auf Geräten in mobilen und Offline-Szenarien erschwert.Große Modelle am Rand erfordern bei der Einbindung in einige komplexe Aufgaben immer noch Cloud-seitige Unterstützung und Optimierung, und es besteht noch Raum für Verbesserungen bei der Edge-Leistung und den multimodalen Fähigkeiten.
In diesem ZusammenhangDas Natural Language Processing Laboratory der Tsinghua-Universität und Mianbi Intelligence haben gemeinsam das effiziente End-to-End-Modell MiniCPM-V 4.0 im großen Maßstab auf den Markt gebracht.Dieses Modell übernimmt nicht nur die leistungsstarke Einzelbild-, Mehrbild- und Videoverarbeitungsleistung seines Vorgängers MiniCPM-V 2.6, sondern übertrifft in der OpenCompass-Evaluierung auch gängige Modelle wie GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct und InternVL2.5-8B in der Bildverarbeitungsleistung. Es erreicht außerdem eine Parameterreduzierung um die Hälfte auf 4,1B, wodurch die Bereitstellungsschwelle deutlich gesenkt wird.Das Forschungsteam hat außerdem gleichzeitig iOS-Anwendungen für iPhone und iPad als Open Source veröffentlicht, sodass Benutzer auf ihren Telefonen „Funktionen auf Cloud-Ebene und Effizienz auf Edge-Ebene“ erleben können.
Als wichtige Erforschung des End-Side-MLLM fördert MiniCPM-V 4.0 die leichte Bereitstellung von Terminals, um einen breiteren Entwicklungsraum zu eröffnen, und bietet ein gutes Beispiel für die Ausweitung anderer Modalitäten wie Sprache und Video auf Edge-Geräte.
Aktuell wurde auf der offiziellen HyperAI-Website „MiniCPM-V4.0: Extrem effizientes groß angelegtes On-Device-Modell“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/pZ5aZ
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 11. bis 15. August:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 6
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. NuminaMath-LEAN-Datensatz für mathematische Probleme
NuminaMath-LEAN ist ein gemeinsam von Numina und dem Kimi-Team veröffentlichter Datensatz für mathematische Probleme. Ziel ist es, manuell annotierte formale Aussagen und Beweise für das Training und die Evaluation automatisierter Theorembeweismodelle bereitzustellen. Der Datensatz enthält 100.000 mathematische Wettbewerbsprobleme, darunter auch solche aus renommierten Wettbewerben wie der Internationalen Mathematik-Olympiade (IMO) und der US-amerikanischen Mathematik-Olympiade (USAMO).
Direkte Verwendung:https://go.hyper.ai/YSJM2
2. Trendyol-Datensatz zur Sicherheitsanweisungsoptimierung
Trendyol ist ein Datensatz zur Optimierung von Sicherheitsanweisungen, der für die Schulung fortgeschrittener KI-Assistenten für defensive Cybersicherheit entwickelt wurde. Dieser Datensatz enthält 53.202 Beispiele für die Optimierung von Anweisungen aus über 200 Cybersicherheitsbereichen, darunter Cloud-native Bedrohungen, KI/ML-Sicherheit und andere moderne Sicherheitsherausforderungen. Er bietet ein hochwertiges Korpus für das Training defensiver Sicherheits-KI-Modelle.
Direkte Verwendung:https://go.hyper.ai/hfxLQ
3. InteriorGS 3D-Innenraum-Szenendatensatz
InteriorGS ist ein 3D-Datensatz für Innenraumszenen, der die Einschränkungen bestehender Datensätze hinsichtlich geometrischer Vollständigkeit, semantischer Annotation und räumlicher Interaktionsmöglichkeiten überwindet. Der Datensatz bietet hochwertige 3D-Gauß-Streuungsdarstellungen sowie semantische Begrenzungsrahmen und Belegungskarten auf Instanzebene, die die zugänglichen Bereiche der Agenten anzeigen.
Direkte Verwendung:https://go.hyper.ai/8pxTq
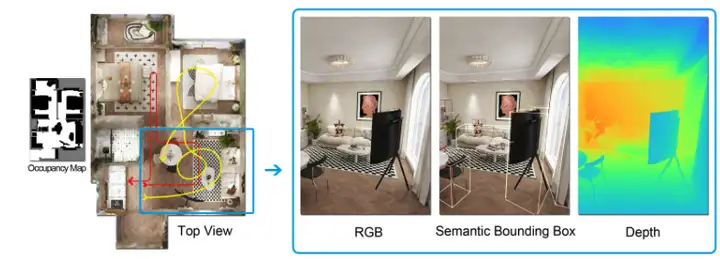
4. Benchmark-Datensatz zur Textgenerierung von CognitiveKernel-Pro-Query
CognitiveKernel-Pro-Query ist ein von Tencent veröffentlichter Benchmark-Datensatz zur Textgenerierung, der die Leistung von Modellen bei der Verarbeitung langer Texte bewerten soll. Der Datensatz enthält über 10.000 lange Texte und deckt Anwendungsszenarien wie Nachrichtenartikel, technische Dokumente und Bücher ab.
Direkte Verwendung:https://go.hyper.ai/onijU
5. Satelliteneinbettung des Erdbeobachtungsdatensatzes
Satellite Embedding ist ein von Google veröffentlichter Datensatz zur Erdbeobachtung. Ziel ist es, eine äußerst vielseitige georäumliche Darstellung bereitzustellen, die räumliche, zeitliche und messtechnische Kontexte aus mehreren Quellen integriert, um präzise und effizient Karten und Überwachungssysteme vom lokalen bis zum globalen Maßstab zu erstellen.
Direkte Verwendung:https://go.hyper.ai/Yfw8K

6. LongText-Bench Text Understanding Benchmark Dataset
LongText-Bench ist ein Benchmark-Datensatz zum Textverständnis, der die Fähigkeit von Modellen bewertet, lange Passagen chinesischer und englischer Texte genau zu verstehen. Der Datensatz enthält 160 Eingabeaufforderungen zur Bewertung von Aufgaben zur Wiedergabe langer Texte und deckt acht verschiedene Szenarien ab (Verkehrsschilder, beschriftete Objekte, Drucksachen, Webseiten, Folien, Poster, Überschriften und Dialoge).
Direkte Verwendung:https://go.hyper.ai/k6Kj8
7. nuPlan-Datensatz zum autonomen Fahren
nuPlan ist ein von Motional veröffentlichter Datensatz zum autonomen Fahren. Er bietet ein auf maschinellem Lernen basierendes Entwicklungs- und Trainingsframework für Planer, einen leichtgewichtigen Closed-Loop-Simulator, spezielle Bewegungsplanungsmetriken und interaktive Tools zur Ergebnisvisualisierung. Der Datensatz enthält 1.200 Stunden menschlicher Fahrdaten aus vier Städten in den USA und Asien: Boston, Pittsburgh, Las Vegas und Singapur.
Direkte Verwendung:https://go.hyper.ai/BcEC8

8. HelpSteer3-Datensatz zu menschlichen Präferenzen
HelpSteer3 ist ein von NVIDIA veröffentlichter Datensatz zu menschlichen Präferenzen. Ziel ist es, die Reaktionsfähigkeit von Modellen auf Benutzereingaben durch menschliches Feedback und Techniken des bestärkenden Lernens zu verbessern. Der Datensatz enthält 40.476 Präferenzbeispiele, die jeweils eine Domäne, eine Sprache, einen Kontext, zwei Antworten, eine Gesamtpräferenzbewertung zwischen den beiden Antworten und individuelle Präferenzbewertungen von bis zu drei Kommentatoren umfassen.
Direkte Verwendung:https://go.hyper.ai/hByqe
9. NHR-Edit Bildbearbeitungsdatensatz
NHR-Edit ist ein Bildbearbeitungsdatensatz, der das Training allgemeiner Bildbearbeitungsmodelle unterstützt, die verschiedenen natürlichen Bearbeitungsanweisungen folgen können. Der Datensatz enthält 286.608 einzigartige Quellbilder und 358.463 Bildbearbeitungstripletts. Jedes Beispiel enthält außerdem zusätzliche Metadaten wie Bearbeitungstyp, Stil und Bildauflösung und eignet sich daher für das Training feinkörniger, steuerbarer Bildbearbeitungsmodelle.
Direkte Verwendung:https://go.hyper.ai/LZtkd

10. A-WetDri-Datensatz zum Fahren bei Unwettern
A-WetDri ist ein Datensatz zum Fahren bei Unwettern, der die Robustheit und Generalisierung autonomer Fahrwahrnehmungsmodelle bei widrigen Wetterbedingungen verbessern soll. Der Datensatz enthält 42.390 Beispiele aus vier Umweltszenarien (Regen, Nebel, Nacht, Schnee und klares Wetter) und verschiedenen Objektkategorien (Autos, LKWs, Fahrräder, Motorräder, Fußgänger sowie Verkehrszeichen und -ampeln).
Direkte Verwendung:https://go.hyper.ai/W2XE7

Ausgewählte öffentliche Tutorials
1. MiniCPM-V4.0: Extrem effizientes End-to-End-Modell im großen Maßstab
MiniCPM-V 4.0 ist ein äußerst effizientes, groß angelegtes, gerätebasiertes Modell, das vom Natural Language Processing Laboratory der Tsinghua-Universität und Mianbi Intelligence als Open Source entwickelt wurde. Im OpenCompass-Test übertraf MiniCPM-V 4.0 GPT-4.1-mini-20250414, Qwen2.5-VL-3B-Instruct und InternVL2.5-8B in Bezug auf die Bildverarbeitungsfähigkeiten.
Online ausführen:https://go.hyper.ai/pZ5aZ

2. Explorative Datenanalyse | Erläuterung der SHAP-Werte von XGBoost
Dieses Tutorial befasst sich mit dem Multiklassifizierungsproblem der „Vorhersage des optimalen Düngers“ und stellt den gesamten Prozess von der Datenexploration über das Modelltraining bis hin zur interpretierbaren Analyse vollständig dar.
Online ausführen:https://go.hyper.ai/41z6K
3. dots.ocr: Mehrsprachiges Dokument-Parsing-Modell
dots.ocr ist ein mehrsprachiges Dokumentlayout-Parsing-Modell, das vom hi-Labor von Xiaohongshu entwickelt wurde. Basierend auf einem visuellen Sprachmodell (VLM) mit 1,7 Milliarden Parametern integriert es Layout- und Inhaltserkennung und sorgt so für eine korrekte Lesereihenfolge. Dieses Modell bietet eine einfache und effiziente Architektur, die zum Wechseln zwischen Aufgaben lediglich eine Änderung der Eingabeaufforderung erfordert. Dank seiner hohen Inferenzgeschwindigkeit eignet es sich für eine Vielzahl von Dokumentparsing-Szenarien.
Online ausführen:https://go.hyper.ai/JewLR

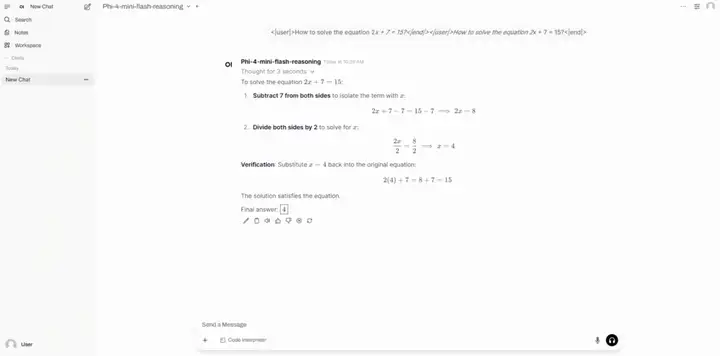
4. Stellen Sie Phi-4-Mini-Flash-Argumentation mit vLLM+Open-WebUI bereit
Phi-4-mini-flash-reasoning ist ein leichtgewichtiges Open-Source-Modell des Microsoft-Teams. Es basiert auf synthetischen Daten, konzentriert sich auf hochwertige, dichte Inferenzdaten und wurde weiter optimiert, um erweiterte mathematische Denkfähigkeiten zu erreichen. Dieses Modell, Teil der Phi-4-Modellfamilie, unterstützt 64K-Token-Kontextlängen und nutzt eine Decoder-Hybrid-Decoder-Architektur, kombiniert mit einem Aufmerksamkeitsmechanismus und einem State-Space-Modell (SSM), wodurch eine hervorragende Inferenzeffizienz erreicht wird.
Online ausführen:https://go.hyper.ai/ENYcL
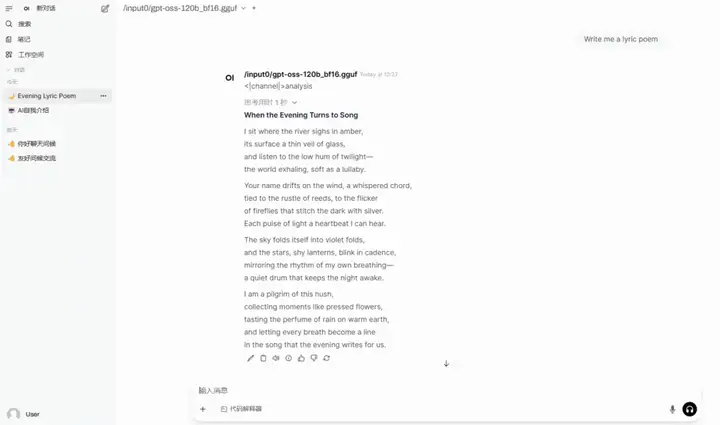
5. llama.cpp+Open-WebUI stellt gpt-oss-120b bereit
gpt-oss-120b ist ein Open-Source-Argumentationsmodell von OpenAI, das für starkes Reasoning, agentenbasierte Aufgaben und vielfältige Entwicklungsszenarien entwickelt wurde. Basierend auf der MoE-Architektur unterstützt dieses Modell eine Kontextlänge von 128 KB und zeichnet sich durch Tool-Aufrufe, wenige Funktionsaufrufe, verkettetes Reasoning und die Beantwortung von Gesundheitsfragen aus.
Online ausführen:https://go.hyper.ai/3BnDy
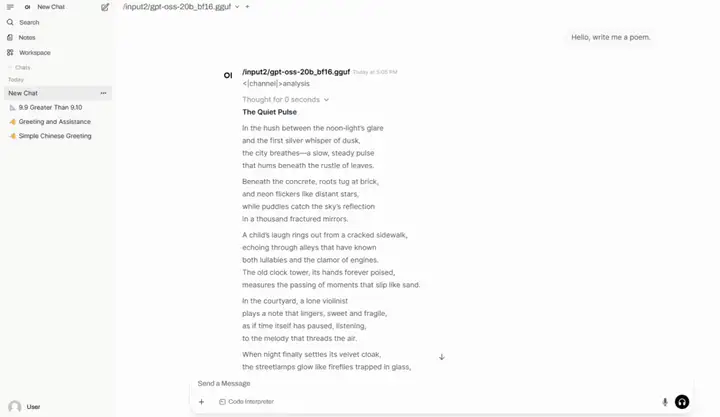
6. llama.cpp+Open-WebUI stellt gpt-oss-20b bereit
gpt-oss-20b ist ein Open-Source-Inferenzmodell von OpenAI. Es eignet sich für Anwendungen mit geringer Latenz, lokale Anwendungen oder spezialisierte vertikale Anwendungen. Es läuft reibungslos auf Consumer-Hardware (wie Laptops und Edge-Geräten) und bietet eine Leistung, die mit der des o3-mini vergleichbar ist.
Online ausführen:https://go.hyper.ai/28FXJ
Die Zeitungsempfehlung dieser Woche
1. ReasonRank: Verbesserung der Passagenbewertung durch starke Argumentationsfähigkeit
Aufgrund des Mangels an hochinferenzintensiven Trainingsdaten schneiden bestehende Reranker in vielen komplexen Ranking-Szenarien schlecht ab, und ihre Ranking-Fähigkeiten befinden sich noch in der frühen Entwicklungsphase. Dieses Papier schlägt erstmals ein automatisiertes Framework zur Synthese hochinferenzintensiver Trainingsdaten vor. Dieses Framework extrahiert Trainingsabfragen und -abschnitte aus mehreren Domänen und nutzt das DeepSeek-R1-Modell zur Generierung hochwertiger Trainingslabels. Darüber hinaus wird ein selbstkonsistenter Datenfiltermechanismus entwickelt, um die Datenqualität sicherzustellen.
Link zum Artikel:https://go.hyper.ai/nmaou
2. WideSearch: Benchmarking der agentenbasierten, umfassenden Informationssuche
Dieses Dokument stellt einen neuen Benchmark namens WideSearch vor, der die Zuverlässigkeit von Agenten bei umfangreichen Datenerfassungsaufgaben bewerten soll. Er besteht aus 200 sorgfältig zusammengestellten Fragen aus über 15 verschiedenen Bereichen, die auf realen Benutzeranfragen basieren. Für jede Aufgabe muss der Agent große Mengen atomarer Informationen sammeln und diese in einer klar strukturierten Ausgabe organisieren.
Link zum Artikel:https://go.hyper.ai/87pbh
3. WebWatcher: Neue Grenzen für Deep-Research-Agenten für Vision-Language
Dieses Dokument stellt WebWatcher vor, einen multimodalen Deep Research-Agenten mit erweiterten Fähigkeiten zum visuell-sprachlichen Schlussfolgern. Dieser Agent ermöglicht effizientes Kaltstarttraining durch hochwertige synthetische multimodale Trajektorien, kombiniert mehrere Tools für Deep Reasoning und verbessert die Generalisierung durch bestärkendes Lernen.
Link zum Artikel:https://go.hyper.ai/n9IKZ
4. Matrix-3D: Omnidirektionale erforschbare 3D-Weltgenerierung
Dieses Papier stellt das Matrix-3D-Framework vor, das mithilfe einer Panoramadarstellung großflächige, vollständig erforschbare 3D-Welten generiert. Es kombiniert bedingte Videogenerierung mit Techniken zur Panorama-3D-Rekonstruktion. Die Forscher trainierten zunächst ein trajektoriengeführtes Panorama-Videodiffusionsmodell, das auf einem Szenennetz-Rendering basiert, um eine qualitativ hochwertige, geometrisch konsistente Szenenvideogenerierung zu erreichen.
Link zum Artikel:https://go.hyper.ai/ojvKE
Ziel der virtuellen Anprobe ist die Erzeugung realistischer Bilder einer Person in einem bestimmten Kleidungsstück. Die genaue Modellierung der Übereinstimmung zwischen Kleidungsstück und menschlichem Körper bleibt jedoch eine anhaltende Herausforderung, insbesondere bei Variationen in Körperhaltung und Aussehen. In diesem Artikel schlagen wir ein einheitliches und skalierbares Framework namens Voost vor, das die virtuellen An- und Ausprobierungsaufgaben über einen einzigen Diffusionstransformator gemeinsam lernt.
Link zum Artikel:https://go.hyper.ai/qCCaH
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Google DeepMind und Google Research haben gemeinsam Perch 2.0 veröffentlicht und damit die Bioakustikforschung auf ein neues Niveau gehoben. Im Vergleich zum Vorgänger konzentriert sich Perch 2.0 auf die Artenklassifizierung als zentrale Trainingsaufgabe. Es integriert nicht nur mehr Trainingsdaten von Nicht-Vogel-Gruppen, sondern setzt auch neue Strategien zur Datenerweiterung und Trainingsziele ein. Dies führte zu hochmodernen Ergebnissen sowohl bei den Bioakustik-Benchmarks BirdSET als auch BEANS.
Den vollständigen Bericht ansehen:https://go.hyper.ai/B7ZUk
Ein Forschungsteam der Peking-Universität hat MediCLIP entwickelt, eine effiziente Lösung zur Erkennung von Anomalien in medizinischen Bildern mit wenigen Aufnahmen. Diese Methode benötigt nur eine minimale Anzahl normaler medizinischer Bilder und erzielt hervorragende Ergebnisse bei der Erkennung und Lokalisierung von Anomalien. Sie erkennt effektiv verschiedene Krankheiten in einer Vielzahl medizinischer Bildtypen und zeigt beeindruckende Zero-Shot-Generalisierungsfähigkeiten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/VAhFb
Paper With Code hat seinen Betrieb offiziell eingestellt, und Deep-User aus aller Welt haben sich dazu geäußert. Einerseits lobten sie den Wert der Website für die Machine-Learning-Forschung, andererseits äußerten sie echte Bedürfnisse – neben der Korrespondenz zwischen Papers und Open-Source-Codes sind Funktionen wie SOTA und Bestenlisten ebenso wichtig.
Den vollständigen Bericht ansehen:https://go.hyper.ai/poRWa
Um das Problem der histochemischen Färbung bei der bildgebenden Massenspektrometrie zu lösen, schlug das Forschungsteam der UCLA eine virtuelle histologische Färbemethode auf Basis eines Diffusionsmodells vor, die die räumliche Auflösung verbessern und einen zellmorphologischen Kontrast digital in Massenspektrometriebilder von markierungsfreiem menschlichen Gewebe einführen kann, wodurch die Vorhersage der pathologischen Struktur von Zellgewebe mit hoher Auflösung auf Grundlage von IMS-Daten mit niedriger Auflösung möglich wird.
Den vollständigen Bericht ansehen:https://go.hyper.ai/gcZ5U
Ainnova Tech, ein Unternehmen im Bereich Gesundheitstechnologie, hat seine Vision AI-Plattform entwickelt, die intelligente Diagnosetechnologie auf Basis von Fundusbildern nutzt. Diese Plattform kann diabetische Retinopathie (mit einer Genauigkeit von über 90,1 % TP3T), kardiovaskuläre Risiken und andere Multisystemerkrankungen in Sekundenschnelle erkennen. Ainnova Tech ist in über 20 Ländern tätig, hat im Juli 2025 sein Pre-Submission-Meeting mit der FDA erfolgreich abgeschlossen und nun ein kostenloses Screening-Modell in Lateinamerika eingeführt, um Innovationen in der Frühdiagnose chronischer Krankheiten voranzutreiben.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Ete2g
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
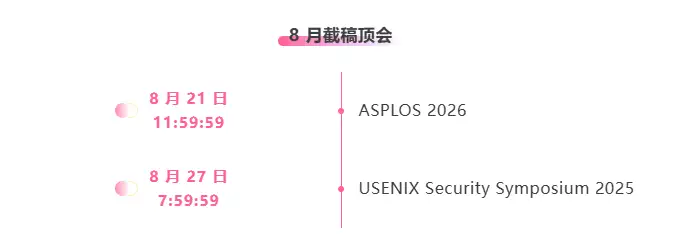
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








