Command Palette
Search for a command to run...
Vom „Assistenten“ Zum „Benutzer“: Microsoft UserLM-8B Simuliert Echte Menschliche Gespräche Und Treibt so Eine Neue Welle Der LLM-Optimierung voran. Extract-0 Wurde Für Geringe Leistung Entwickelt Und Unterstützt Modelle Mit Kleinen Parametern Bei Der Präzisen Informationsextraktion.

Mit der rasanten Entwicklung großer Sprachmodelle (LLMs) sind leistungsstarke Modelle entstanden, die als „Assistenten“ fungieren und detaillierte und strukturierte Antworten liefern, um die expliziten Bedürfnisse des Benutzers zu erfüllen.existierenIn realen Gesprächsszenarien drücken Benutzer ihre Absichten häufig nicht auf einmal vollständig aus, sondern geben Informationen nach und nach in mehreren Gesprächsrunden preis. Ihr Sprachstil weist zudem im Allgemeinen Merkmale der Fragmentierung, Personalisierung und sofortigen Anpassung auf.Im Gegensatz dazu sind traditionelle „Assistenten“-Modelle nicht besonders gut darin, Benutzer zu simulieren. Je besser der LLM-Assistent, desto verzerrter ist zudem seine „Benutzer“-Imitation. Diese Einschränkung offenbart auch einen zentralen Schwachpunkt des aktuellen LLM-Evaluierungssystems: Aufgrund des Mangels an hochwertigen „Benutzer“-Personas, die menschliche Gespräche präzise simulieren können, sind bestehende Evaluierungsumgebungen oft übermäßig idealisiert und den komplexen Kontexten realer Anwendungen deutlich unterlegen.
In diesem ZusammenhangMicrosoft hat das neueste Benutzersprachenmodell UserLM-8B herausgebracht,Im Gegensatz zu typischen LLMs, die typischerweise als Assistenten fungieren, kann dieses auf dem WildChat-Konversationskorpus trainierte Modell verwendet werden, um die Rolle des „Benutzers“ in Konversationen zu simulieren, mehrere Dialogrunden zu führen und als nützliches Werkzeug zur Bewertung der Fähigkeiten groß angelegter Modelle zu dienen. Bei der Verwendung von UserLM zur Simulation von Programmier- und Mathematikgesprächen sank der GPT-4o-Score von 74,61 TP3T auf 57,41 TP3T. Dies bestätigt, dass realistischere Simulationsumgebungen zu Leistungseinbußen für den „Assistenten“ führen können, da dieser Schwierigkeiten hat, auf die Nuancen der Benutzeräußerung zu reagieren.
Die Einführung von UserLM-8B bietet eine realistischere und robustere Testumgebung für die Evaluierung großer Modelle. Durch die Simulation von Benutzergesprächen kann die Leistung selbst modernster Assistenzmodelle erheblich nachlassen. Forscher und Entwickler können Modellschwächen in realen Interaktionen genauer identifizieren.Dadurch wird die Kompetenzbewertung im LLM weiter vorangetrieben und geht über einen einzelnen, statischen Benchmarktest und Punktevergleich hinaus. Der Schwerpunkt liegt zunehmend auf „tatsächlichen Kampfübungen“, die näher an der Realität liegen.Lassen Sie LLM die wahren Absichten des Benutzers besser verstehen und die menschliche Benutzererfahrung kontinuierlich optimieren.
Das „UserLM-8b: User Conversation Simulation Model“ ist jetzt auf der offiziellen Website von HyperAI verfügbar. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/EHcdQ
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 20. bis 24. Oktober:
* Hochwertige öffentliche Datensätze: 8
* Auswahl an hochwertigen Tutorials: 7
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenz mit Deadline im Oktober: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. CP2K_Benchmark-Leistungsbenchmark-Datensatz
Der CP2K-Benchmark-Datensatz ist eine Reihe von Leistungstest- und Validierungseingaben, die speziell für High-Performance-Computing-Umgebungen (HPC) entwickelt wurden. Dieser Datensatz, der aus der Open-Source-First-Principles-Simulationssoftware CP2K stammt, wird verwendet, um die Leistung von Quantenchemie- und Molekulardynamikberechnungen unter verschiedenen Hardwareplattformen, Parallelisierungsstrategien (MPI/OpenMP) und Kompilierungsoptimierungseinstellungen zu bewerten.
Direkte Verwendung:https://go.hyper.ai/BGnLb
2. Smilei_Benchmark-Benchmark-Datensatz zur Plasmadynamiksimulation
Smilei, die Abkürzung für Simulation of Matter Irradiated by Light at Extreme Intensities, ist ein Open-Source-Code für elektromagnetische Partikel in Zellen (PIC), der einfach zu verwenden ist und eine hochpräzise, leistungsstarke und skalierbare Plasmadynamik-Simulationsplattform für Bereiche wie Laser-Plasma-Wechselwirkung, Teilchenbeschleunigung, Starkfeld-QED und Weltraumphysik bieten soll.
Direkte Verwendung:https://go.hyper.ai/6VCxB
3. Beispieldatensatz für die Genomanalyse von Gatk_benchmark
GATK (Genome Analysis Toolkit) ist ein Open-Source-Bioinformatik-Toolkit, das vom Broad Institute, einem Joint Venture des MIT und der Harvard University, entwickelt wurde. Ziel des Projekts ist die Bereitstellung einer standardisierten Analyse-Pipeline für Hochdurchsatzsequenzierungsdaten (NGS).
Direkte Verwendung:https://go.hyper.ai/0VAuf
4. LAMMPS-Bench Molekulardynamik-Benchmark-Datensatz
LAMMPS-Bench-Datensätze dienen zum Testen und Vergleichen der Leistung von LAMMPS (Software zur Molekulardynamik-Simulation) auf unterschiedlicher Hardware und Konfiguration. Diese Datensätze sind keine wissenschaftlichen Versuchsdaten, sondern dienen der Bewertung der Rechenleistung (Geschwindigkeit, Skalierung und Effizienz). Sie enthalten spezifische Architekturen, Kraftfelddateien, Eingabeskripte, anfängliche Atomkoordinaten und mehr. LAMMPS stellt diese Datensätze im Ordner „bench/“ bereit.
Direkte Verwendung:https://go.hyper.ai/L4gye
5. PromptCoT-2.0-SFT-4.8M überwachter Feinabstimmungs-Prompt-SFT-Datensatz
PromptCoT-2.0-SFT-4.8M ist ein umfangreicher synthetischer Prompt-Datensatz, der hochwertige Argumentationsanregungen für große Sprachmodelle bereitstellt, entweder zur Feinabstimmung oder zum Selbsttraining. Dieser Datensatz enthält rund 4,8 Millionen vollständig synthetische Prompts mit Argumentationsspuren und deckt zwei wichtige Argumentationsbereiche ab: Mathematik und Programmierung.
Direkte Verwendung:https://go.hyper.ai/f188j
6. Extract-0-Dokumentinformationen extrahieren Daten
Extract-0 ist ein hochwertiger Trainings- und Evaluierungsdatensatz, der speziell für die Extraktion von Dokumentinformationen entwickelt wurde. Er soll die Forschung zur Leistungsoptimierung von kleinskaligen Parametermodellen bei komplexen Extraktionsaufgaben unterstützen.
Direkte Verwendung:https://go.hyper.ai/z9BQO
7. EmoBench-M-Benchmark-Datensatz zur Emotionswahrnehmung
EmoBench-M ist ein Benchmark-Datensatz, der von der Universität Shenzhen, dem Guangming Laboratory, der Universität Macau und anderen Institutionen vorgeschlagen wurde, um die Fähigkeiten multimodaler Large Language Models (MLLMs) zum Emotionsverständnis zu bewerten. Ziel ist es, die Lücken in bestehenden unimodalen oder statischen Emotionsdatensätzen in dynamischen und multimodalen Interaktionsszenarien zu schließen und der Komplexität des menschlichen Emotionsausdrucks und der Emotionswahrnehmung in realen Umgebungen näher zu kommen.
Direkte Verwendung:https://go.hyper.ai/WafXo
8. GeoReasoning-10K-Datensatz zum geometrischen multimodalen Denken
GeoReasoning-10K ist ein multimodaler Datensatz für Geometrie, der die Lücke zwischen visuellen und sprachlichen Modalitäten in der Geometrie schließt. Der Datensatz enthält 10.000 geometrische Bild-Text-Paare mit detaillierten Anmerkungen zum geometrischen Denken. Jedes Paar weist eine einheitliche geometrische Struktur, einen einheitlichen semantischen Ausdruck und eine einheitliche visuelle Darstellung auf, was zu einer hochpräzisen modalübergreifenden semantischen Ausrichtung führt.
Direkte Verwendung:https://go.hyper.ai/7qisY

Ausgewählte öffentliche Tutorials
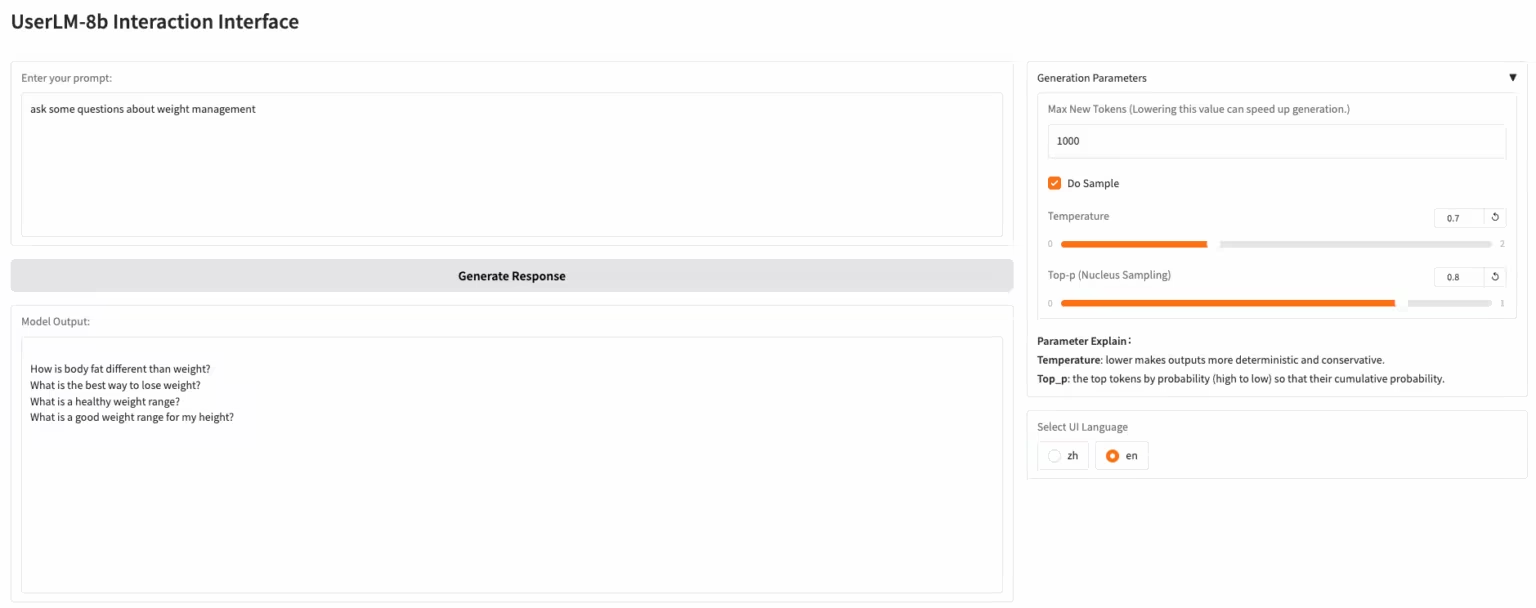
1. UserLM-8b: Benutzerdialog-Simulationsmodell
UserLM-8b ist ein von Microsoft veröffentlichtes Simulationsmodell für Benutzerverhalten. Im Gegensatz zu typischen LLMs, die in Gesprächen die Rolle eines „Assistenten“ übernehmen, simuliert UserLM-8b die Rolle des „Benutzers“ in Gesprächen (trainiert mit dem WildChat-Konversationskorpus) und kann zur Bewertung der Fähigkeiten umfangreicher Assistenten verwendet werden. Dieses Modell ist kein typischer umfangreicher Assistent und kann keine realistischeren Gespräche simulieren oder Probleme lösen, kann aber zur Entwicklung leistungsfähigerer Assistenten beitragen.
Online ausführen:https://go.hyper.ai/EHcdQ
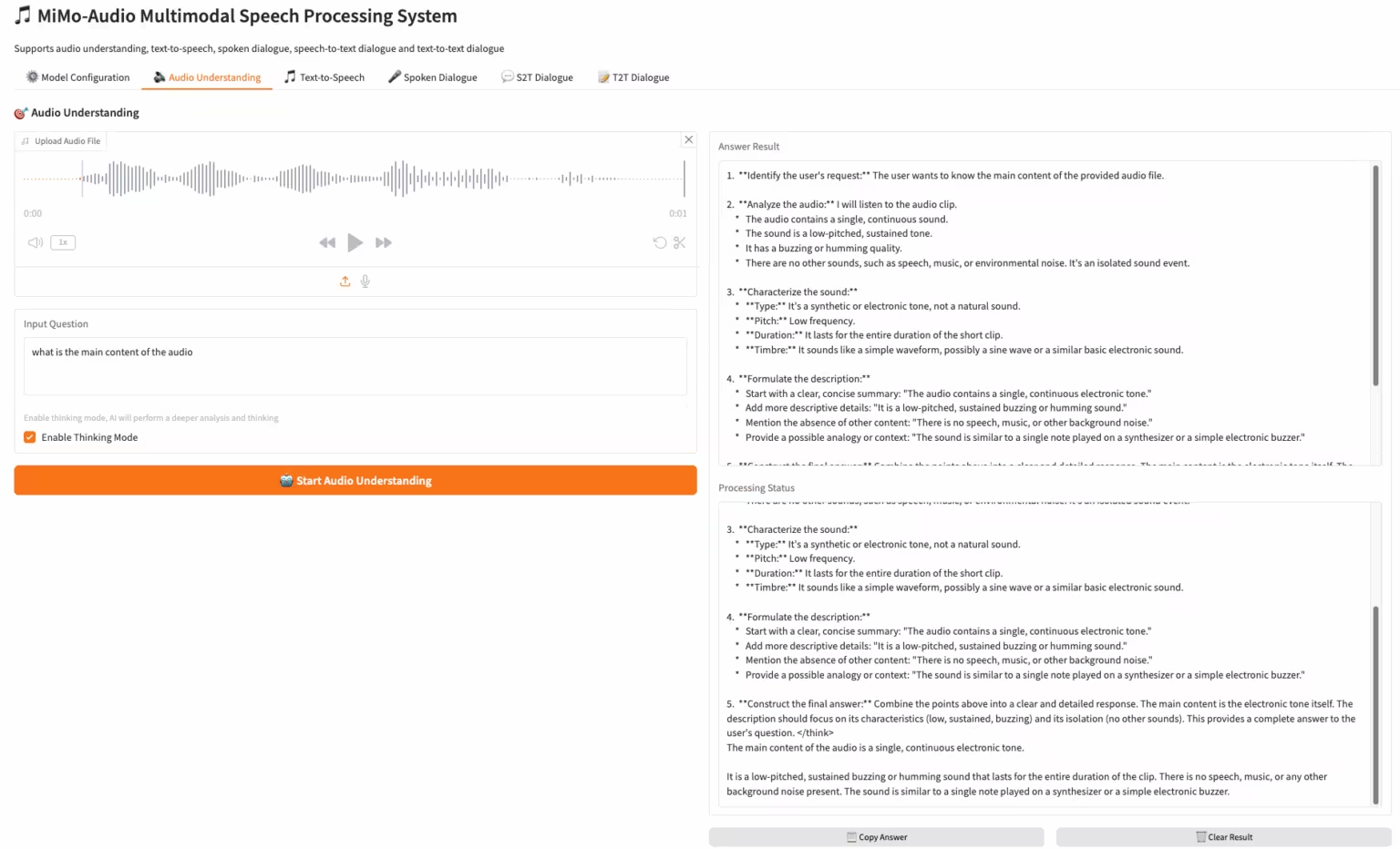
2. MiMo-Audio-7B-Instruct: Xiaomis Open-Source-End-to-End-Sprachmodell
MiMo-Audio ist ein durchgängiges Sprachmodell von Xiaomi. Die vorab trainierten Daten wurden auf über 100 Millionen Stunden erweitert, und Forscher haben beobachtet, dass es bei einer Vielzahl von Audioaufgaben über Few-Shot-Learning-Fähigkeiten verfügt. Das Team evaluierte diese Fähigkeiten systematisch und stellte fest, dass MiMo-Audio-7B-Base sowohl bei Sprachintelligenz- als auch bei Audioverständnis-Benchmarks für Open-Source-Modelle die höchste Leistung (SOTA) erreichte.
Online ausführen:https://go.hyper.ai/3DWbb
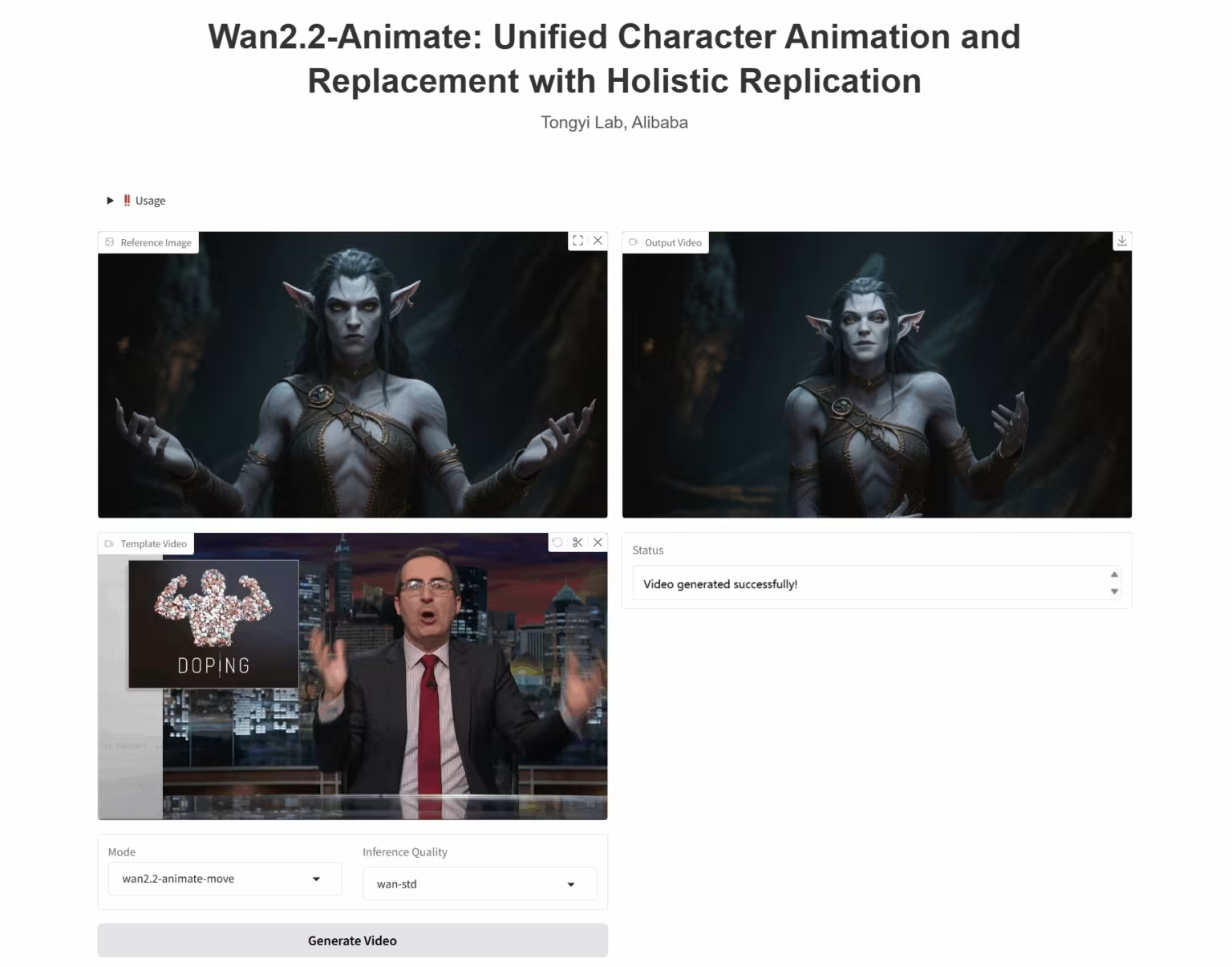
3. Wan2.2-Animate-14B: Offenes erweitertes Modell zur Videogenerierung im großen Maßstab
Wan2.2-Animate-14B ist ein Open-Source-Modell zur Bewegungsgenerierung, das vom Alibaba Tongyi Wanxiang-Team entwickelt wurde. Das Modell unterstützt sowohl Bewegungsimitation als auch Rollenspielmodi. Basierend auf Darstellervideos kann es Gesichtsausdrücke und Bewegungen präzise nachbilden und so hochrealistische Charakteranimationsvideos generieren.
Online ausführen: https://go.hyper.ai/UbtSO
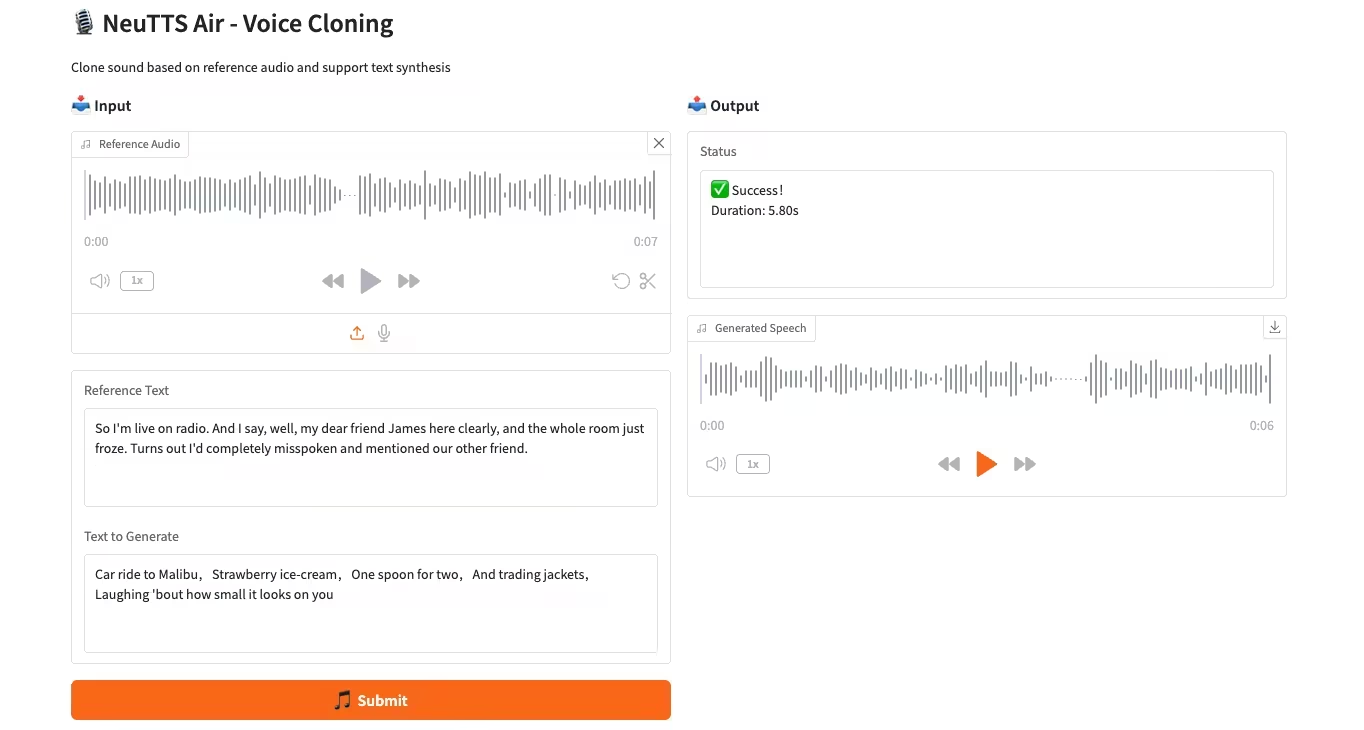
4. CPU-Bereitstellung des NeuTTS-Air-Sprachklonmodells
NeuTTS-Air ist ein durchgängiges Text-to-Speech-Modell (TTS) von Neuphonic. Basierend auf dem 0,5B Qwen LLM-Backbone und dem NeuCodec-Audiocodec demonstriert das Modell Few-Shot-Learning-Fähigkeiten bei der On-Device-Bereitstellung und sofortigem Voice-Cloning. Systembewertungen zeigen, dass NeuTTS Air unter Open-Source-Modellen Spitzenleistungen erzielt, insbesondere bei Benchmarks für hyperrealistische Synthese und Echtzeit-Inferenz.
Online ausführen:https://go.hyper.ai/KMMG1
5. HuMo-1.7B: Framework zur multimodalen Videogenerierung
HuMo ist ein multimodales Videogenerierungs-Framework, das von der Tsinghua-Universität und dem Intelligent Creation Lab von ByteDance entwickelt wurde und sich auf die menschenzentrierte Videogenerierung konzentriert. Es generiert hochwertige, detaillierte und steuerbare, menschenähnliche Videos aus multimodalen Eingaben, darunter Text, Bilder und Audio. Das Modell unterstützt die zuverlässige Verfolgung von Texthinweisen, die konsistente Beibehaltung des Motivs und die audiogesteuerte Bewegungssynchronisierung.
Online ausführen:https://go.hyper.ai/tnyQU
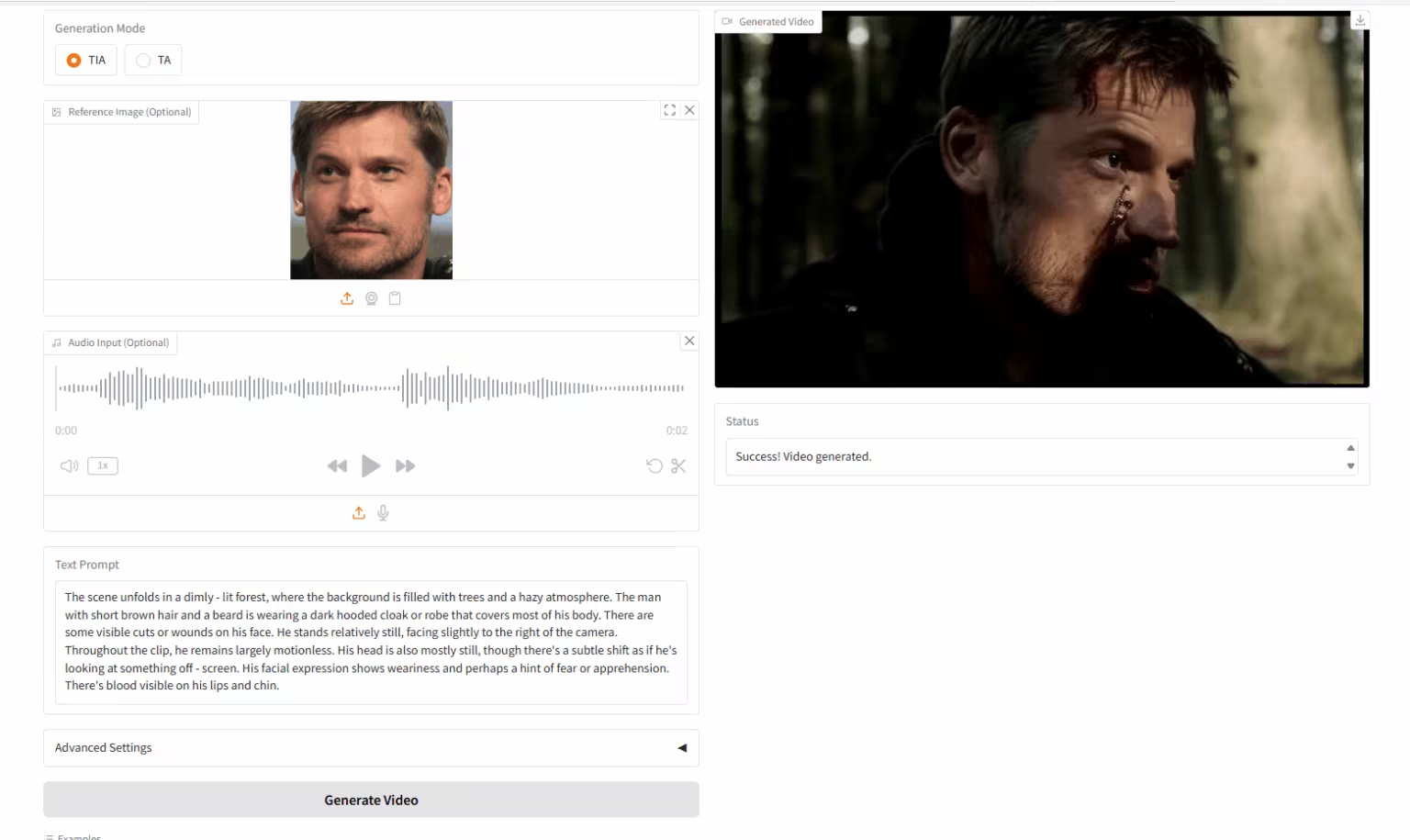
6. HuMo-17B: Trimodale kollaborative Kreation
HuMo ist ein multimodales Framework zur Videogenerierung, das von der Tsinghua-Universität und dem ByteDance Intelligent Creation Lab veröffentlicht wurde. Es unterstützt die Generierung von Videos aus Text-Bild (VideoGen aus Text-Bild), Text-Audio (VideoGen aus Text-Audio) und Text-Bild-Audio (VideoGen aus Text-Bild-Audio).
Online ausführen:https://go.hyper.ai/liAti
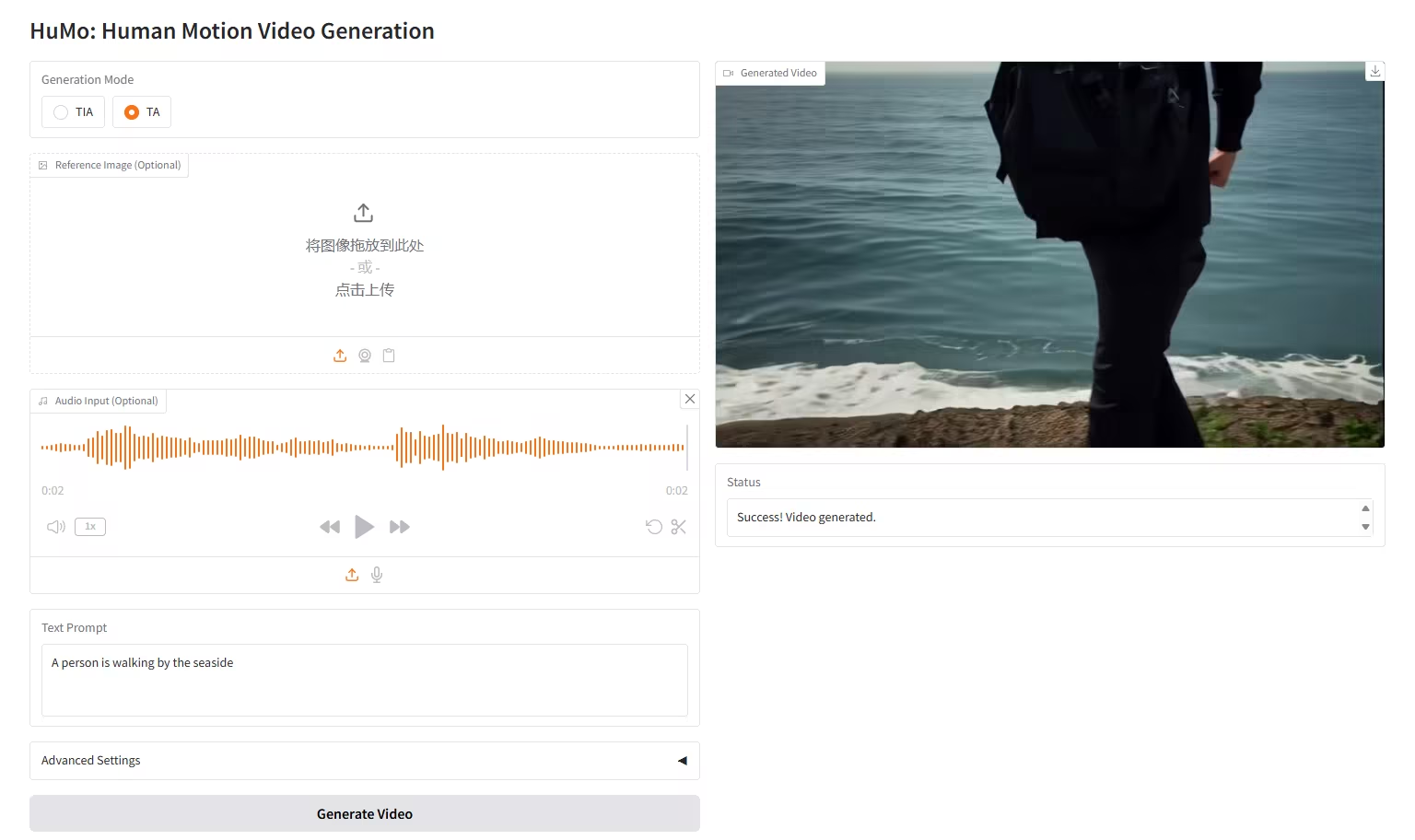
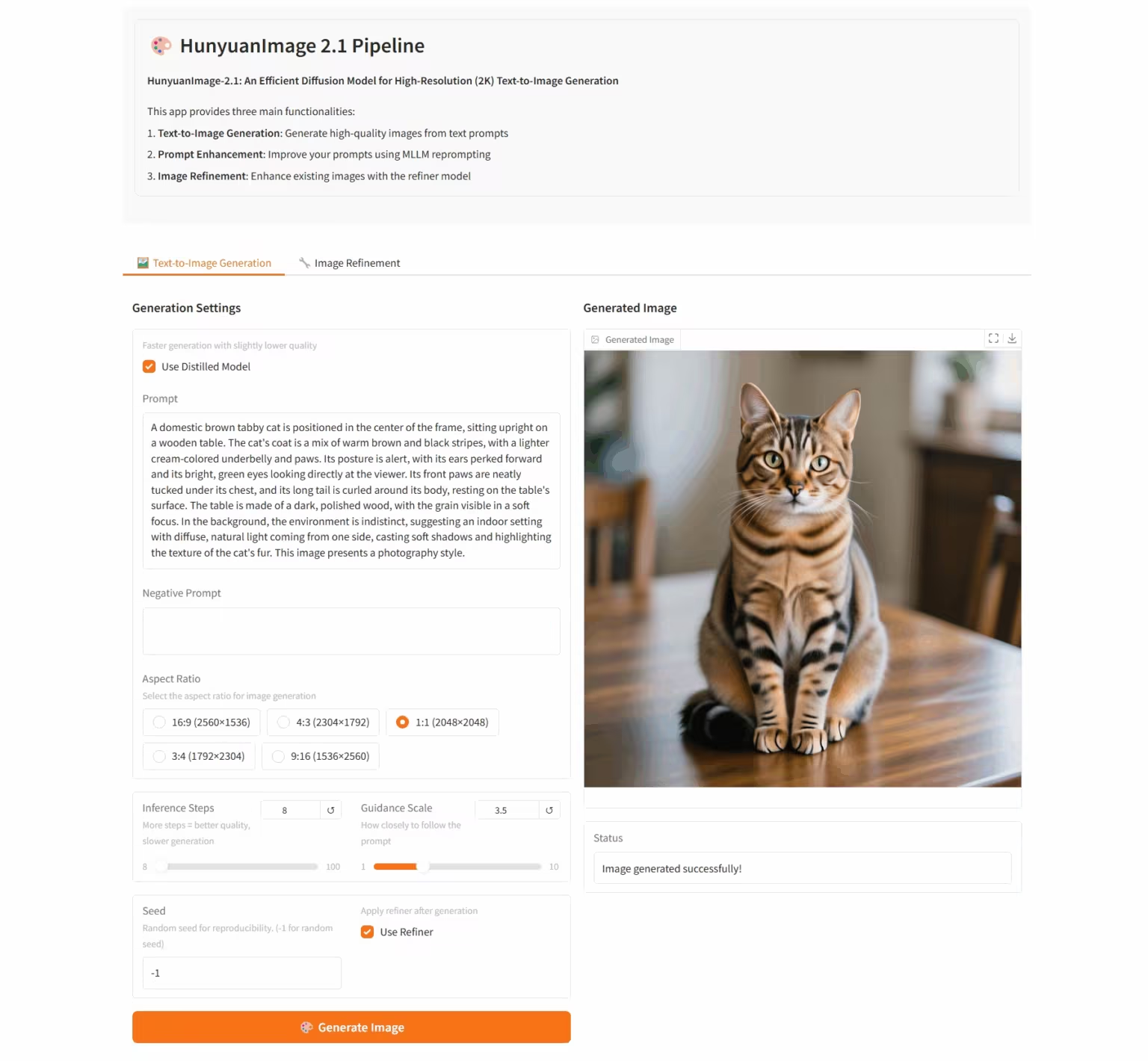
7. HunyuanImage-2.1: Diffusionsmodell für hochauflösende (2K) Wensheng-Bilder
HunyuanImage-2.1 ist ein textbasiertes Open-Source-Bildmodell, das vom Tencent Hunyuan-Team entwickelt wurde. Es unterstützt native 2K-Auflösung und verfügt über leistungsstarke Funktionen zum komplexen semantischen Verständnis, die die präzise Generierung von Szenendetails, Charakterausdrücken und Aktionen ermöglichen. Das Modell unterstützt sowohl chinesische als auch englische Eingaben und kann Bilder in verschiedenen Stilen, wie Comics und Actionfiguren, generieren und gleichzeitig die Kontrolle über Text und Details in den Bildern behalten.
Online ausführen:https://go.hyper.ai/hpWNA
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Eine theoretische Studie zur Überbrückung von interner Wahrscheinlichkeit und Selbstkonsistenz für LLM-Argumentation
Dieses Papier schlägt RPC (Perplexity-Consistency and Reasoning Pruning) vor, einen hybriden Ansatz, der theoretische Erkenntnisse integriert und aus zwei Kernkomponenten besteht: Perplexity-Consistency und Reasoning Pruning. Sowohl theoretische Analysen als auch empirische Ergebnisse anhand von sieben Benchmark-Datensätzen belegen das erhebliche Potenzial von RPC zur Reduzierung von Reasoning-Fehlern. Insbesondere erreicht RPC eine mit Selbstkonsistenz vergleichbare Reasoning-Leistung, verbessert die Zuverlässigkeit deutlich und reduziert die Sampling-Kosten um 50%.
Link zum Artikel:https://go.hyper.ai/V3reH
2. Jede Aufmerksamkeit zählt: Eine effiziente Hybridarchitektur für Long-Context-Argumentation
Dieser technische Bericht schlägt eine Reihe von Ring-linearen Modellen vor, darunter Ring-mini-linear-2.0 und Ring-flash-linear-2.0. Beide Modelle verwenden eine Hybridarchitektur, die lineare Aufmerksamkeit und Softmax-Aufmerksamkeit effektiv integriert und so den E/A-Overhead und die Rechenlast in Szenarien mit langem Kontext-Argumentationsaufwand erheblich reduziert.
Link zum Artikel:https://go.hyper.ai/xLhP3
3. BAPO: Stabilisierung des Off-Policy-Reinforcement-Learning für LLMs durch Balanced Policy Optimization mit adaptivem Clipping
In diesem Artikel wird eine einfache und effiziente Methode vorgeschlagen: Balanced Policy Optimization with Adaptive Clipping (BAPO), die die Clipping-Grenzen dynamisch anpasst, positive und negative Beiträge adaptiv neu ausgleicht, die Policy-Entropie effektiv aufrechterhält und die Stabilität der RL-Optimierung erheblich verbessert.
Link zum Artikel:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: Agentische große Sprachmodelle für autonome Datenwissenschaft
Dieses Dokument stellt DeepAnalyze-8B vor, das erste groß angelegte Sprachmodell, das speziell für autonome Datenwissenschaft entwickelt wurde. Es automatisiert den gesamten Prozess von der Datenquelle bis hin zu detaillierten Forschungsberichten auf Analystenniveau. Experimentelle Ergebnisse zeigen, dass dieses Modell mit nur 8 Milliarden Parametern frühere Workflow-Agenten übertrifft, die auf den meisten modernen proprietären groß angelegten Sprachmodellen basieren.
Link zum Artikel:https://go.hyper.ai/UTdwP
5. OmniVinci: Verbesserung von Architektur und Daten für omnimodales Verständnis LLM
Dieses Dokument stellt das OmniVinci-Projekt vor, dessen Ziel die Entwicklung eines leistungsstarken und quelloffenen omnimodalen Large Language Model (LLM) ist. Die Forscher führten umfassende Untersuchungen zum Entwurf der Modellarchitektur und zu Strategien für die Datenkonstruktion durch, entwarfen und implementierten einen Prozess für die Datenkonstruktion und -synthese und generierten einen Datensatz mit 24 Millionen unimodalen und omnimodalen Konversationen.
Link zum Artikel:https://go.hyper.ai/c3yQW
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. NVIDIA wurde für NeurIPS 2025 ausgewählt und schlug das ERDM-Modell zur Lösung langfristiger Prognoseprobleme vor. Seine mittel- und langfristigen Prognosen sind weiterhin führend im EDM-Benchmark.
Auf der Grundlage des Elucidated Diffusion Model (EDM)-Frameworks hat ein Forschungsteam von NVIDIA und der University of California, San Diego, die Rauschplanung, die Parametrisierung des Rauschunterdrückungsnetzwerks, Vorverarbeitungsverfahren, Verlustgewichtungsstrategien und Sampling-Algorithmen systematisch verbessert, um den Anforderungen der Sequenzmodellierung gerecht zu werden, und ein verbessertes Sequenzdiffusionsmodell (ERDM) erstellt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/QZBBl
2. Inklusives Tutorial | MIT et al. starten BindCraft, das AF2 direkt aufruft, um ein intelligentes Design von Proteinkomplexen zu erreichen
Ein Team der Eidgenössischen Technischen Hochschule Lausanne (EPFL) und des Massachusetts Institute of Technology (MIT) hat mit BindCraft einen Open-Source-Automatisierungsprozess für die Entwicklung von Proteinbindern von Grund auf vorgeschlagen. Die Kernidee besteht darin, die halluzinierte Bindersequenz durch die AlphaFold2-Gewichte zurückzupropagieren und den Fehlergradienten zu berechnen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/LqNeb
3. Drei Nobelpreise in zwei Jahren: Alphabets langfristige wissenschaftliche Forschungsansammlung, KI+Quantencomputing führen zu technologischer Stärke und Ambition
Bei der Bekanntgabe der Nobelpreise 2025 haben erneut Wissenschaftler von Googles Mutterkonzern Alphabet gewonnen. Als Technologieriese, der zwei Jahre in Folge Nobelpreise gewonnen hat, ist sein Erfolg von „drei Auszeichnungen und fünf Gewinnern in zwei Jahren“ kein Zufall. Vom Gewinn der Chemie- und Physikpreise für KI-Technologie im Jahr 2024 bis zum Durchbruch in der Quantenforschung, der diesmal den Physikpreis einbrachte, haben über ein Jahrzehnt ehrgeiziger Planungs- und Forschungsstrategien seine starken wissenschaftlichen Forschungskapazitäten gefördert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/mY9Z3
Das MIT erstellt ein generatives KI-Modell auf der Grundlage physikalischer Vordaten, das nur einen einzigen spektralen Modalitäts-Input erfordert, um eine kreuzmodale Spektralgenerierung mit experimentellen Korrelationen von bis zu 99% zu erreichen.
Ein Forschungsteam des MIT hat SpectroGen vorgeschlagen, ein generatives KI-Modell auf Basis physikalischer Vorhersagen. Mit nur einer einzigen spektralen Modalität als Eingabe kann es modalübergreifende Spektren mit einer Korrelation von 99% mit experimentellen Ergebnissen generieren. Dieses Modell führt zwei wesentliche Neuerungen ein: Erstens die Darstellung spektraler Daten als mathematische Verteilungskurven; zweitens die Konstruktion eines generativen Algorithmus für einen variationellen Autoencoder auf Basis physikalischer Vorhersagen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/OsYY2
5. Google-Teams arbeiten gemeinsam an Earth AI, wobei sie sich auf drei zentrale Datenpunkte konzentrieren und die Fähigkeiten zum georäumlichen Denken bis 64% verbessern.
Mehrere Teams bei Google haben gemeinsam „Earth AI“ entwickelt, ein georäumliches KI-Modell und intelligentes Schlussfolgerungssystem. Dieses System bildet eine interoperable Familie von GeoAI-Modellen und ermöglicht die kollaborative Analyse multimodaler Daten durch maßgeschneiderte Inferenzagenten. Das System konzentriert sich auf drei Kerndatentypen: Bilddaten, Bevölkerung und Umwelt und verbindet diese drei Modelle mithilfe von Gemini-basierten Agenten. Das System überwindet die Grenzen von Einzelpunktmodellen und ermöglicht selbst Laien domänenübergreifende Echtzeitanalysen. Es fördert die Erdsystemforschung hin zu umsetzbaren, globalen Erkenntnissen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/djq48
Beliebte Enzyklopädieartikel
1. DALL-E
2. Hypernetzwerke
3. Pareto-Front
4. Bidirektionales Langzeit-Kurzzeitgedächtnis (Bi-LSTM)
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Anmeldeschluss für die Konferenz im Oktober

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








