Command Palette
Search for a command to run...
Eine Neue Hochmoderne Plattform Zur Dokumentenanalyse! Die Neue Version Von MinerU Bietet Eine Innovative Zweistufige Analysestrategie Von „grob Bis Fein“; Der S2S-Domänen-Benchmark Wird Vorgestellt! Der Neueste Benchmark-Datensatz Von Tencent Bewertet Die Fähigkeiten Von Sprachmodellen.

Im Zuge der Digitalisierung haben sich in allen Lebensbereichen enorme Mengen unstrukturierter Dokumentdaten angesammelt, insbesondere wissenschaftliche Arbeiten, Berichte, Formulare usw., hauptsächlich im PDF-Format.Die effiziente und präzise Konvertierung dieser Dokumente in maschinenlesbare strukturierte Daten ist eine wichtige Voraussetzung für die automatisierte Informationsextraktion, Dokumentenverwaltung und intelligente Analyse und zugleich ein entscheidender Schritt zur Erschließung des Datenwerts.
Aufgrund der kontinuierlich wachsenden Nachfrage nach OCR,OpenDataLab und Shanghai AI Lab haben gemeinsam das visuelle Sprachmodell MinerU2.5-2509-1.2B auf den Markt gebracht.Der Schwerpunkt liegt auf der Konvertierung komplexer Formatdokumente wie PDF in strukturierte maschinenlesbare Daten (wie Markdown, JSON usw.) und ist für hochpräzise und hocheffiziente Dokumentanalyseaufgaben konzipiert.Die neue Version des Modells erreicht eine effiziente Analyse durch eine zweistufige Strategie „vom Groben zum Feinen“:Im ersten Schritt werden durch eine effiziente Layoutanalyse Strukturelemente identifiziert und der Dokumentrahmen skizziert; im zweiten Schritt erfolgt eine Feinerkennung innerhalb des zugeschnittenen Bereichs in der Originalauflösung, um sicherzustellen, dass Details wie Text, Formeln und Tabellen wiederhergestellt werden.
MinerU2.5-2509-1.2B entkoppelt die globale Layoutanalyse von der lokalen Inhaltserkennung und demonstriert leistungsstarke Funktionen zur Dokumentanalyse.Es übertrifft allgemeine und vertikale Feldmodelle bei mehreren Erkennungsaufgaben.Gleichzeitig weist es erhebliche Vorteile hinsichtlich des Rechenaufwands auf. Es handelt sich nicht nur um ein technisch überlegenes Modell, sondern auch um ein Tool, das die technische Effizienz effektiv verbessert und nachgelagerte Benutzeranforderungen wie Datenanalyse, Informationsabruf und Korpusaufbau umfassend unterstützt.
Auf der offiziellen HyperAI-Website wurde „MinerU2.5-2509-1.2B: Document Parsing Demo“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/emEKs
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 13. bis 17. Oktober:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 11
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenz mit Deadline im Oktober: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. FDAbench – Vollständiger Benchmark-Datensatz für die heterogene Datenanalyse
FDAbench-Full ist der erste Benchmark für heterogene Datenanalyseaufgaben für Datenagenten, der von der Nanyang Technological University, der National University of Singapore und Huawei Technologies Co., Ltd. veröffentlicht wurde. Ziel ist es, die Fähigkeiten des Modells bei der Generierung von Datenbankabfragen, dem SQL-Verständnis und der Finanzdatenanalyse zu bewerten.
Direkte Verwendung:https://go.hyper.ai/AUjv5
2. PubMedVision Medical Multimodal Evaluation Dataset
PubMedVision ist ein Datensatz zur Bewertung multimodaler medizinischer Fähigkeiten, der eine Vielzahl medizinischer Bildgebungsverfahren und anatomischer Regionen abdeckt. Ziel ist es, standardisierte Testressourcen für multimodale große Sprachmodelle (MLLMs) in medizinischen Aufgaben zum visuellen Textverstehen bereitzustellen, um ihre visuelle Wissensfusion und ihre Argumentationsleistung im medizinischen Bereich zu testen.
Direkte Verwendung:https://go.hyper.ai/qdvVe
3. Verse-Bench-Datensatz zur gemeinsamen audiovisuellen Generierung
Verse-Bench ist ein Benchmark-Datensatz zur Bewertung der gemeinsamen Generierung von Audio und Video, der von StepFun in Zusammenarbeit mit der Hong Kong University of Science and Technology, der Hong Kong University of Science and Technology (Guangzhou) und anderen Institutionen veröffentlicht wurde. Ziel ist es, generative Modelle nicht nur in die Lage zu versetzen, Videos zu generieren, sondern auch eine strikte zeitliche Ausrichtung mit Audioinhalten (einschließlich Umgebungsgeräuschen und Sprache) beizubehalten.
Direkte Verwendung:https://go.hyper.ai/mvau0

4. MMMC-Benchmark-Datensatz zur Erstellung von Lehrvideos
MMMC ist ein umfangreicher, multidisziplinärer Benchmark-Datensatz für die Erstellung von Lehrvideos, der vom Show Lab der National University of Singapore veröffentlicht wurde. Ziel ist es, hochwertige Trainings- und Evaluierungsressourcen für pädagogische KI-Modelle bereitzustellen und die Forschung zur automatischen Generierung professioneller Lehrvideos aus strukturiertem Code und Lehrinhalten zu unterstützen.
Direkte Verwendung:https://go.hyper.ai/AELav
5. T2I-CoReBench Benchmark-Datensatz zur multimodalen Bildgenerierung
T2I-CoReBench ist ein umfassender Bewertungsmaßstab für textbasierte Bildgenerierungsmodelle, der von der University of Science and Technology of China, dem Kling-Team von Kuaishou Technology und der Universität Hongkong vorgeschlagen wurde. Ziel ist es, die Kombinations- und Argumentationsfähigkeiten von Bildgenerierungsmodellen gleichzeitig zu messen.
Direkte Verwendung:https://go.hyper.ai/SLyED
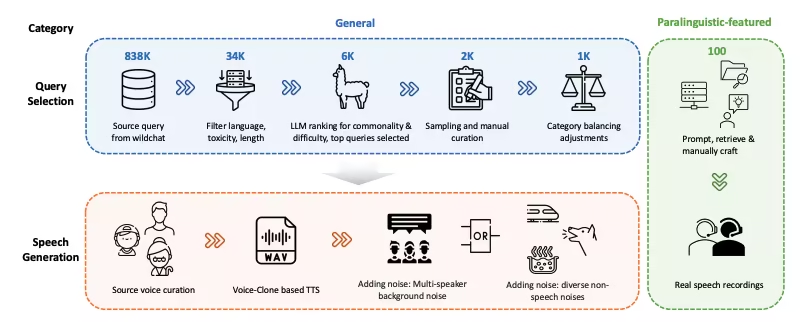
6. WildSpeech-Bench Benchmark-Datensatz für Sprachverständnis und -generierung
WildSpeech-Bench ist der erste von Tencent veröffentlichte Benchmark zur Bewertung der Sprach-zu-Sprache-Fähigkeiten von SpeechLLM. Ziel ist es, die Fähigkeit des Modells zu messen, in realen Sprachinteraktionsszenarien vollständige Spracheingaben und Sprachausgaben (S2S) zu verstehen und zu generieren.
Direkte Verwendung:https://go.hyper.ai/Cy63e
7. OmniRetarget-Datensatz zur globalen Neuzuordnung von Roboterbewegungen
OmniRetarget ist ein hochwertiger Trajektorien-Datensatz für die Neuzuordnung der Ganzkörperbewegung humanoider Roboter, der von Amazon in Zusammenarbeit mit dem MIT, der University of California, Berkeley und anderen Institutionen veröffentlicht wurde. Er enthält die Bewegungstrajektorien des humanoiden Roboters G1 bei der Interaktion mit Objekten und komplexem Gelände und deckt drei Szenarien ab: Roboter trägt Objekte, läuft auf Gelände und gemischte Objekt-Gelände-Interaktion.
Direkte Verwendung:https://go.hyper.ai/xfZY4

8. Paper2Video Paper-Video-Benchmark-Daten
Paper2Video ist der erste Benchmark-Datensatz mit Paper- und Videopaaren, der von der National University of Singapore veröffentlicht wurde. Ziel ist es, eine standardisierte Benchmark- und Bewertungsressource für die automatische Generierung von Präsentationsvideos (einschließlich Folien, Untertiteln, Audio und Sprecherporträts) aus wissenschaftlichen Arbeiten bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/NeRuV
9. FoMER Bench Multimodal Evaluation Dataset
FoMER Bench ist ein Foundational Model Embodied Reasoning (FoMER)-Benchmark, der drei verschiedene Robotertypen und mehrere Robotermodi abdeckt und zur Bewertung der Denkfähigkeit von LMMs in komplexen verkörperten Entscheidungsfindungsszenarien entwickelt wurde.
Direkte Verwendung:https://go.hyper.ai/Tiy5w
10. OCRBench-v2-Benchmark-Datensatz zur Texterkennung
OCRBench-v2 ist ein multimodaler Benchmark für groß angelegte optische Zeichenerkennung (OCR), der von der Huazhong University of Science and Technology in Zusammenarbeit mit der South China University of Technology, ByteDance und anderen Institutionen veröffentlicht wurde. Ziel ist es, die OCR-Fähigkeiten großer multimodaler Modelle (LMMs) in verschiedenen textbezogenen Aufgaben zu bewerten.
Direkte Verwendung:https://go.hyper.ai/hhGFR
Ausgewählte öffentliche Tutorials
Diese Woche haben wir 4 Kategorien hochwertiger öffentlicher Tutorials zusammengefasst:
* OCR-Tutorials: 2
* AI4S-Tutorials: 2
* Großes Modell-Tutorial: 1
* Multimodale Tutorials: 6
OCR-Tutorial
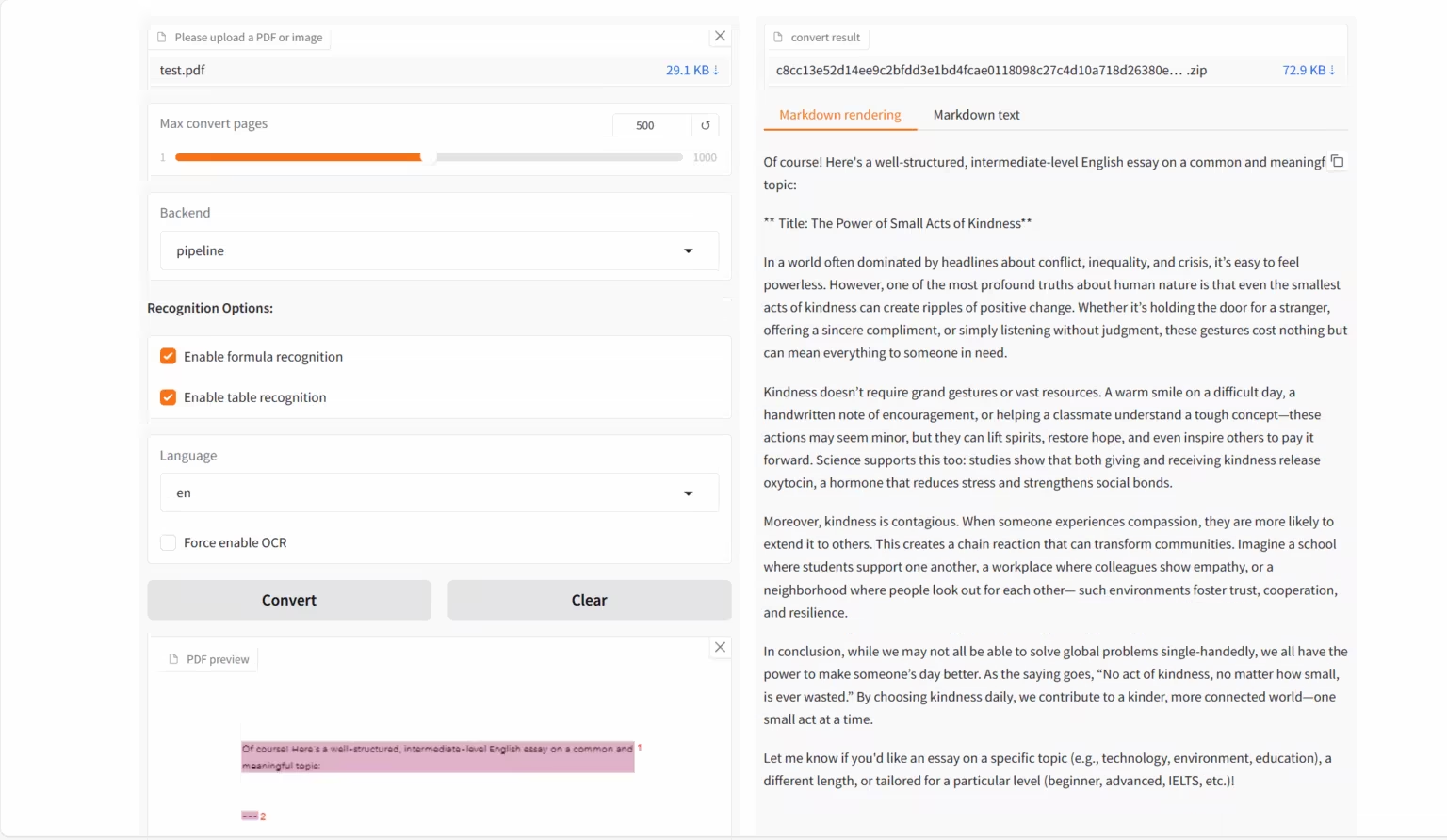
1. MinerU2.5-2509-1.2B: Demo zur Dokumentanalyse
MinerU 2.5-2509-1.2B ist ein von OpenDataLab und Shanghai AI Lab entwickeltes visuelles Sprachmodell, das speziell für hochpräzises und effizientes Dokumenten-Parsing konzipiert ist. Es ist die neueste Version der MinerU-Reihe und konzentriert sich auf die Konvertierung komplexer Dokumentformate wie PDF in strukturierte, maschinenlesbare Daten (z. B. Markdown und JSON).
Online ausführen:https://go.hyper.ai/emEKs
2. Dolphin Multimodales Dokumentbild-Parsing
Dolphin ist ein multimodales Dokumentanalysemodell, das vom ByteDance-Team entwickelt wurde. Dieses Modell verwendet einen zweistufigen Ansatz: Zuerst wird die Struktur analysiert, dann der Inhalt analysiert. Die erste Stufe generiert eine Sequenz von Dokumentlayoutelementen, die zweite nutzt diese Elemente als Anker, um den Inhalt parallel zu analysieren. Dolphin hat bei einer Vielzahl von Dokumentanalyseaufgaben eine hervorragende Leistung bewiesen und übertrifft Modelle wie GPT-4.1 und Mistral-OCR.
Online ausführen: https://go.hyper.ai/lLT6X

AI4S-Tutorial
1. BindCraft: Proteinbinder-Design
BindCraft, eine von Martin Pacesa entwickelte Open-Source-Pipeline zur Entwicklung von Proteinbindern mit nur einem Klick, weist eine experimentelle Erfolgsrate von 10–100% auf. Sie nutzt direkt vortrainierte AlphaFold2-Gewichte, um in silico De-novo-Binder mit nanomolarer Affinität zu generieren. Dadurch entfallen Hochdurchsatz-Screening, experimentelle Iterationen und sogar die Notwendigkeit bekannter Bindungsstellen.
Online ausführen:https://go.hyper.ai/eSoHk
2. Ml-simplefold: Ein leichtes KI-Modell zur Vorhersage der Proteinfaltung
Ml-simplefold ist ein leichtgewichtiges KI-Modell zur Vorhersage der Proteinfaltung, das von Apple eingeführt wurde. Basierend auf der Flow-Matching-Technologie umgeht das Modell komplexe Module wie die Multiple Sequence Alignment (MSA) und generiert die dreidimensionale Struktur von Proteinen direkt aus zufälligem Rauschen, wodurch der Rechenaufwand deutlich reduziert wird.
Online ausführen: https://go.hyper.ai/Y0Us9
Tutorial für große Modelle
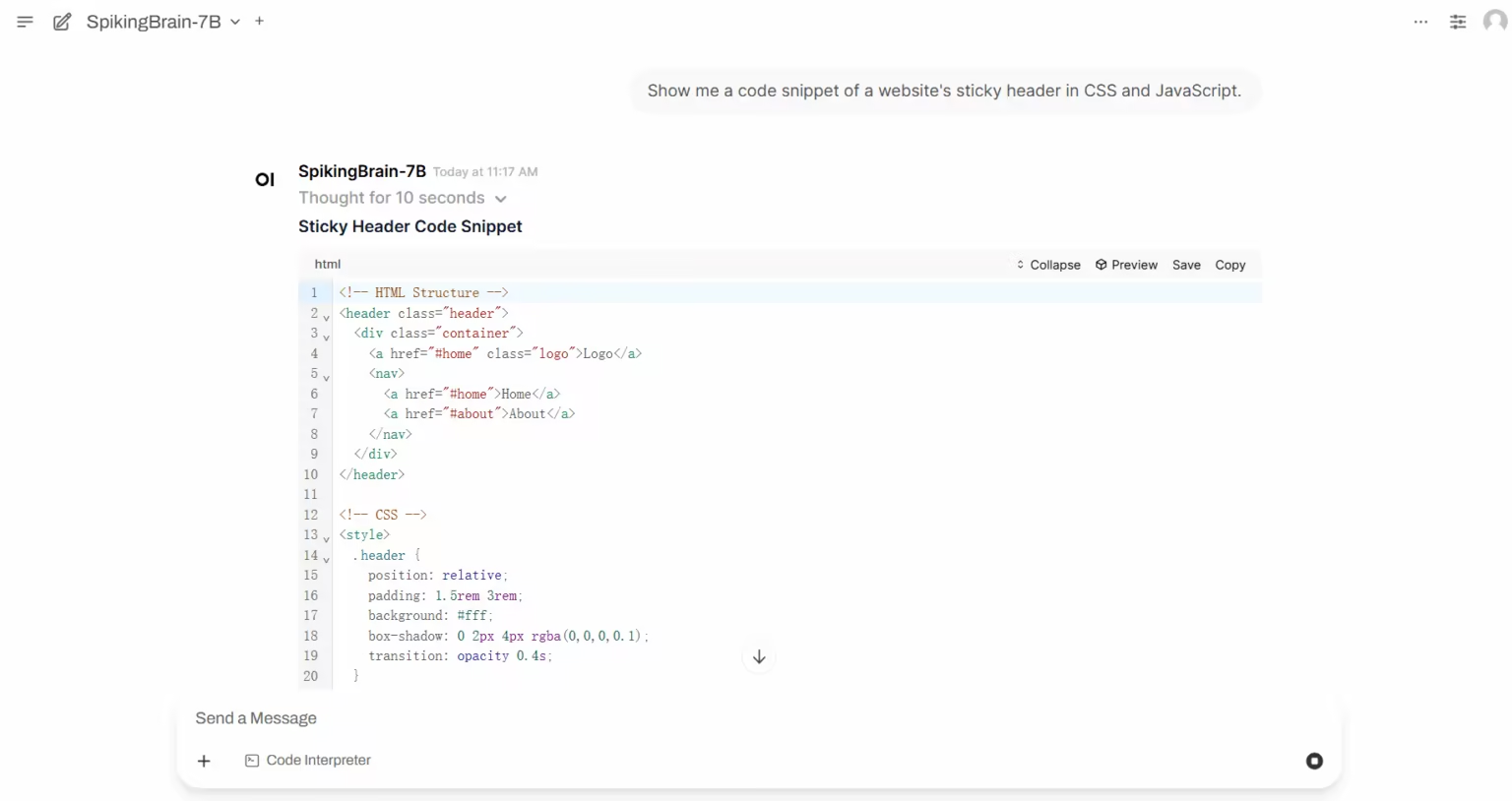
1. SpikingBrain-1.0: Ein groß angelegtes, gehirnähnliches Spike-Modell basierend auf intrinsischer Komplexität
SpikingBrain-1.0 ist ein großes, im Inland entwickeltes, steuerbares, vom Gehirn inspiriertes Spiking-Modell, das vom Institute of Automation der Chinesischen Akademie der Wissenschaften in Zusammenarbeit mit dem National Key Laboratory of Brain Cognition and Brain-Inspired Intelligence, Muxi Integrated Circuit Co., Ltd. und anderen Institutionen veröffentlicht wurde. Inspiriert von Gehirnmechanismen integriert dieses Modell einen hybriden, hocheffizienten Aufmerksamkeitsmechanismus, ein MoE-Modul und Spike-Codierung in seine Architektur, unterstützt durch eine universelle Konvertierungspipeline, die mit dem Open-Source-Modell-Ökosystem kompatibel ist.
Online ausführen:https://go.hyper.ai/i3zHC
Multimodales Tutorial
1. HuMo-1.7B: Framework zur multimodalen Videogenerierung
HuMo ist ein multimodales Framework zur Videogenerierung, das von der Tsinghua-Universität und dem Intelligent Creation Lab von ByteDance entwickelt wurde. Es konzentriert sich auf die menschenzentrierte Videogenerierung und kann aus mehreren modalen Eingaben, darunter Text, Bilder und Audio, hochwertige, detaillierte und steuerbare, menschenähnliche Videos generieren.
Online ausführen:https://go.hyper.ai/Xe4dM
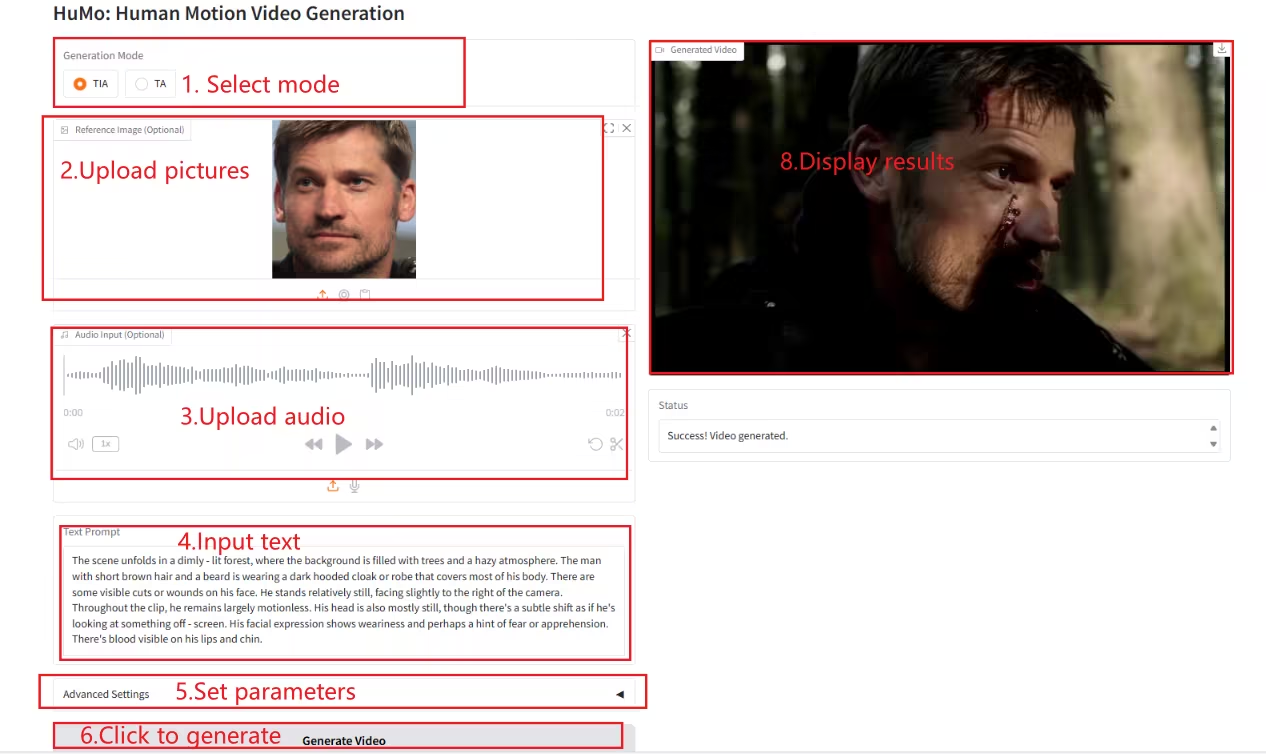
2. NeuTTS-Air: Ein leichtes und effizientes Modell zum Klonen von Stimmen
NeuTTS-Air ist ein durchgängiges Text-to-Speech-Modell (TTS) von Neuphonic. Basierend auf dem 0,5B Qwen LLM-Backbone und dem NeuCodec-Audiocodec demonstriert es Few-Shot-Learning-Fähigkeiten bei der On-Device-Bereitstellung und sofortigem Voice-Cloning. Systembewertungen zeigen, dass NeuTTS Air unter Open-Source-Modellen Spitzenleistungen erzielt, insbesondere bei Benchmarks für hyperrealistische Synthese und Echtzeit-Inferenz.
Online ausführen:https://go.hyper.ai/7ONYq
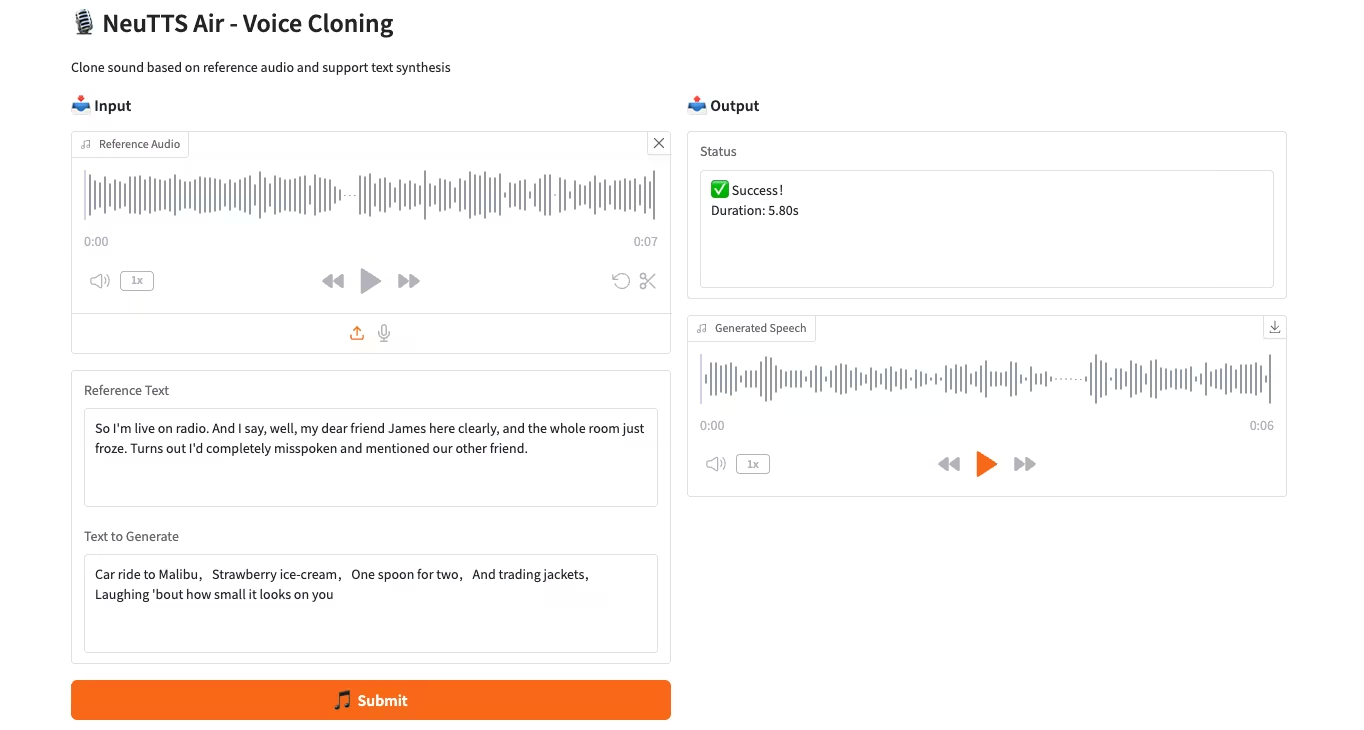
3. Moondream3-Vorschau: Modulares visuelles Sprachverständnismodell
Moondream3, ein visuelles Sprachmodell basierend auf einer vom Moondream-Team vorgeschlagenen hybriden Expertenarchitektur, verfügt über 9 Milliarden Parameter (davon 2 Milliarden Aktivierungsparameter). Dieses Modell bietet modernste visuelle Argumentationsfähigkeiten, unterstützt eine maximale Kontextlänge von 32 KB und kann hochauflösende Bilder effizient verarbeiten.
Online ausführen:https://go.hyper.ai/eKGcP
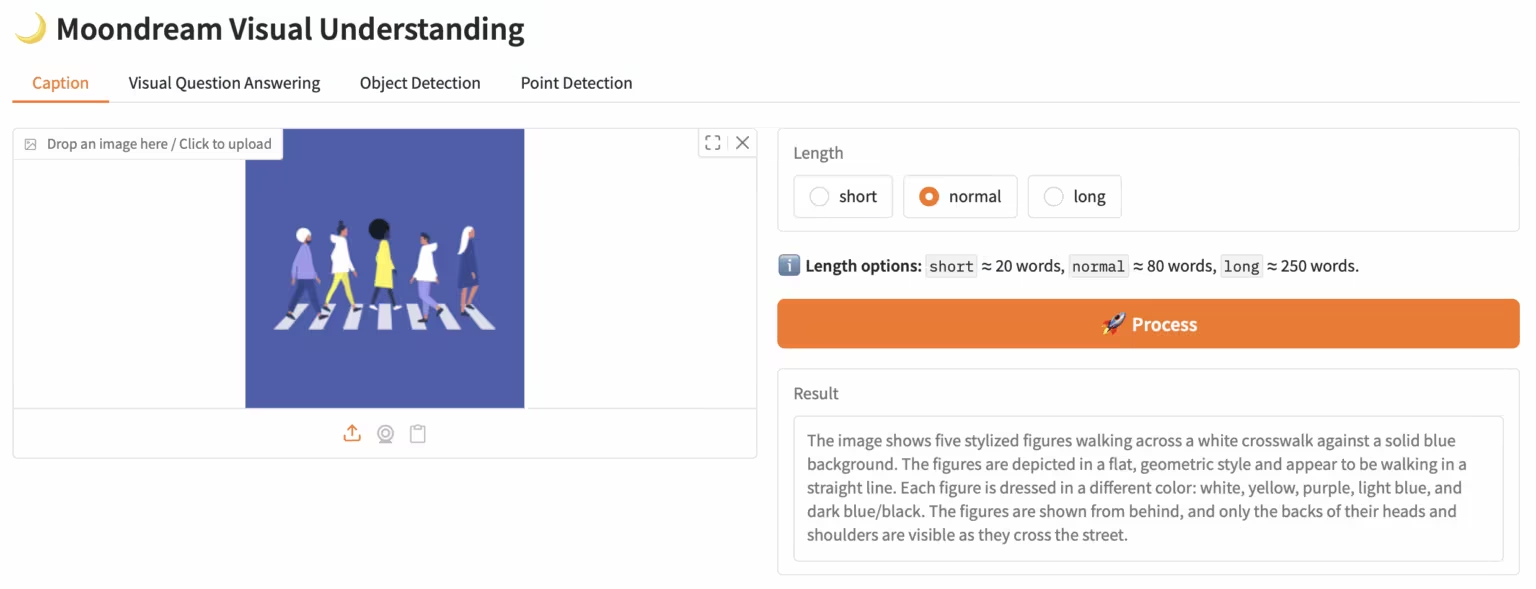
4. LiveCC: Echtzeit-Videokommentar großes Modell
LiveCC ist ein Video-Sprachmodellprojekt, das sich auf die groß angelegte Streaming-Sprachtranskription konzentriert. Ziel des Projekts ist es, das erste Video-Sprachmodell mit Echtzeit-Kommentarfunktionen durch eine innovative Streaming-Methode zur automatischen Video-Spracherkennung (ASR) zu trainieren. Es hat sowohl bei Streaming- als auch bei Offline-Benchmarks den aktuellen Stand der Technik erreicht.
Online ausführen:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part: Komponentenbasiertes 3D-generatives Modell
Hunyuan3D-Part, ein vom Tencent Hunyuan-Team entwickeltes 3D-generatives Modell, besteht aus P3-SAM und X-Part. Es war Vorreiter bei der hochpräzisen, steuerbaren, komponentenbasierten 3D-Modellgenerierung und unterstützt die automatische Generierung von über 50 Komponenten. Es findet breite Anwendung in Bereichen wie Spielemodellierung und 3D-Druck, beispielsweise bei der Zerlegung eines Automodells in Karosserie und Räder, um spielspezifische Scrolllogik oder schrittweisen 3D-Druck zu ermöglichen.
Online ausführen:https://go.hyper.ai/1w1Jq

6. HunyuanImage-2.1: Diffusionsmodell für hochauflösende (2K) Wensheng-Bilder
HunyuanImage-2.1 ist ein textbasiertes Open-Source-Bildmodell, das vom Tencent Hunyuan-Team entwickelt wurde. Es unterstützt native 2K-Auflösung und verfügt über leistungsstarke Funktionen zum komplexen semantischen Verständnis, die die präzise Generierung von Szenendetails, Charakterausdrücken und Aktionen ermöglichen. Das Modell unterstützt sowohl chinesische als auch englische Eingaben und kann Bilder in verschiedenen Stilen, wie Comics und Actionfiguren, generieren und gleichzeitig die Kontrolle über Text und Details in den Bildern behalten.
Online ausführen:https://go.hyper.ai/i96yp
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. QeRL: Mehr als Effizienz – Quantisierungsverstärktes Reinforcement Learning für LLMs
Dieses Dokument stellt QeRL vor, ein quantisierungsverstärktes Reinforcement-Learning-Framework für große Sprachmodelle. Durch die Kombination von NVFP4-Quantisierung mit Low-Rank Adaptation (LoRA) beschleunigt dieses Modell die RL-Sampling-Phase und reduziert gleichzeitig den Speicheraufwand erheblich. QeRL ist das erste Framework, das große Reinforcement-Learning-Modelle mit 32 Milliarden Parametern (32B) auf einer einzigen H100 80GB GPU trainieren und gleichzeitig die allgemeine Trainingsgeschwindigkeit verbessern kann.
Link zum Artikel: https://go.hyper.ai/catLh
2. Diffusionstransformatoren mit Darstellungs-Autoencodern
In diesem Artikel wird der Ersatz von VAEs durch vortrainierte Repräsentations-Encoder (wie DINO, SigLIP und MAE) in Kombination mit vortrainierten Decodern untersucht, um eine neue Architektur zu erstellen, die wir Repräsentations-Autoencoder (RAEs) nennen. Diese Modelle erzielen nicht nur eine hochwertige Rekonstruktion, sondern verfügen auch über einen semantisch reichen latenten Raum und unterstützen ein skalierbares, Transformer-basiertes Architekturdesign.
Link zum Artikel: https://go.hyper.ai/fqVs4
3. D2E: Skalierung des Vision-Action-Pretrainings auf Desktop-Daten für die Übertragung auf verkörperte KI
Dieses Dokument schlägt das D2E-Framework (Desktop to Embodied AI) vor und zeigt, dass Desktop-Interaktion als effektive Grundlage für das Training von Roboter-KI-Aufgaben dienen kann. Im Gegensatz zu früheren Ansätzen, die auf bestimmte Domänen beschränkt oder datengekapselt sind, etabliert D2E eine vollständige technische Kette von der skalierbaren Desktop-Datenerfassung bis hin zur Verifizierung und Migration verkörperter Domänen.
Link zum Artikel: https://go.hyper.ai/aNbE4
4. Denken mit der Kamera: Ein einheitliches multimodales Modell für kamerazentriertes Verständnis und Generierung
In diesem Artikel wird Puffin vorgeschlagen, ein einheitliches, kamerazentriertes multimodales Modell, das die räumliche Wahrnehmung entlang der Kameradimension erweitert, Sprachregression mit diffusionsbasierten Generierungstechniken verbindet und Szenen aus beliebigen Blickwinkeln analysieren und generieren kann.
Link zum Artikel: https://go.hyper.ai/9JBvw
5. DITING: Ein Multi-Agent-Evaluierungsrahmen für das Benchmarking der Web-Romanübersetzung
Dieses Papier stellt DITING vor, das erste umfassende Bewertungsmodell für Online-Romanübersetzungen. Es bewertet systematisch die narrative Konsistenz und kulturelle Treue von Übersetzungen anhand von sechs Dimensionen: Idiomübersetzung, Umgang mit lexikalischer Mehrdeutigkeit, Terminologielokalisierung, Zeitkonsistenz, Nullpronomenauflösung und kulturelle Sicherheit und stützt sich dabei auf über 18.000 von Experten kommentierte chinesisch-englische Satzpaare.
Link zum Artikel:https://go.hyper.ai/KRUmn
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. Die Hong Kong University of Science and Technology und andere haben das inkrementelle Wettervorhersagemodell VA-MoE vorgeschlagen, das 751 vereinfachte Parameter aufweist und dennoch eine Leistung auf dem neuesten Stand der Technik erreicht.
Forschungsteams der Hong Kong University of Science and Technology und der Zhejiang University haben das Modell Variable Adaptive Mixture of Experts (VA-MoE) entwickelt. Dieses Modell nutzt phasenweises Training und die Einbettung variabler Indizes, um verschiedene Expertenmodule auf bestimmte meteorologische Variablen zu konzentrieren. Beim Hinzufügen neuer Variablen oder Stationen kann das Modell ohne vollständiges Neutraining erweitert werden, wodurch der Rechenaufwand bei gleichbleibender Genauigkeit deutlich reduziert wird.
Den vollständigen Bericht ansehen:https://go.hyper.ai/nPWPN
2. NeurIPS 2025 | Die Huazhong University of Science and Technology und andere haben OCRBench v2 veröffentlicht. Gemini gewann das chinesische Ranking, erhielt aber nur eine ausreichende Punktzahl.
Das Team von Bai Xiang von der Huazhong University of Science and Technology hat in Zusammenarbeit mit der South China University of Technology, der University of Adelaide und ByteDance den OCR-Evaluierungsbenchmark der nächsten Generation OCRBench v2 auf den Markt gebracht, der von 2023 bis 2025 58 gängige multimodale Modelle auf der ganzen Welt sowohl auf Chinesisch als auch auf Englisch bewertete.
Den vollständigen Bericht ansehen:https://go.hyper.ai/AL1ZJ
3. Die für NeurIPS 2025 ausgewählte Universität von Toronto und andere schlugen das Ctrl-DNA-Framework vor, um eine „gezielte Kontrolle“ der Genexpression in bestimmten Zellen zu erreichen.
Ein Team der Universität Toronto hat in Zusammenarbeit mit dem Changping Laboratory ein Framework für eingeschränktes bestärkendes Lernen namens Ctrl-DNA entwickelt, das die regulatorische Aktivität von CRE in Zielzellen maximieren und gleichzeitig seine Aktivität in Nicht-Zielzellen streng begrenzen kann.
Den vollständigen Bericht ansehen:https://go.hyper.ai/eVORr
4. KI sagt Plasma-Runaway voraus. MIT und andere nutzen maschinelles Lernen, um hochpräzise Vorhersagen der Plasmadynamik bei kleinen Stichprobengrößen zu erreichen.
Ein vom MIT geleitetes Forschungsteam nutzte wissenschaftliches maschinelles Lernen, um die Gesetze der Physik intelligent mit experimentellen Daten zu verknüpfen. Sie entwickelten ein neuronales Zustandsraummodell, das die Plasmadynamik und potenzielle Instabilitäten während des Herunterfahrens der Tokamak-Konfigurationsvariablen (TCV) mit minimalen Daten vorhersagen kann.
Den vollständigen Bericht ansehen:https://go.hyper.ai/HQgZx
5. MOF-Struktur gewinnt nach 36 Jahren den Nobelpreis: Wenn KI die Chemie versteht, bewegen sich metallorganische Gerüste in Richtung des Zeitalters der generativen Forschung.
Am 8. Oktober 2025 erhielten Susumu Kitagawa, Richard Robson und Omar Yaghi den Nobelpreis für Chemie für ihre Beiträge auf dem Gebiet der Metall-organischen Gerüstverbindungen (MOFs). In den letzten drei Jahrzehnten hat sich das MOF-Gebiet vom Strukturdesign zur Industrialisierung entwickelt und den Grundstein für die computergestützte Chemie gelegt. Heute verändert künstliche Intelligenz die MOF-Forschung mit generativen Modellen und Diffusionsalgorithmen und läutet eine neue Ära des chemischen Designs ein.
Den vollständigen Bericht ansehen:https://go.hyper.ai/U5XgN
Beliebte Enzyklopädieartikel
1. DALL-E
2. Hypernetzwerke
3. Pareto-Front
4. Bidirektionales Langzeit-Kurzzeitgedächtnis (Bi-LSTM)
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Anmeldeschluss für die Konferenz im Oktober

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








