Command Palette
Search for a command to run...
Ein Neues Paradigma Für Die Beurteilung Der Audioästhetik! Audiobox-Aesthetics War Pionier Der Vierdimensionalen Audioquantifizierung; 6,7 Millionen Fälle! Caselaw Gibt Den Compliance-Plan Für Juristische Referenzen Frei

Die traditionelle Audiobewertung basiert in der Regel auf manuellem Hören. Die subjektive Voreingenommenheit erschwert die Vereinheitlichung der Bewertungsstandards. Obwohl bestehende Bewertungsmethoden und -tools bestimmte Ergebnisse liefern können, konzentrieren sich die meisten von ihnen nur auf die allgemeine Audioqualität und es fehlt ihnen an einer gezielten Analyse lokaler Details.
zu diesem Zweck,Meta AI hat Audiobox-Aesthetics eingeführt, ein Tool zur Bewertung der Audioqualität.Realisieren Sie eine mehrdimensionale automatische Analyse von Sprache, Musik und Umgebungsgeräuschen.Bewerten Sie die Audioqualität umfassend anhand von vier Kerndimensionen: Produktionsqualität, Produktionskomplexität, Inhaltsgenuss und Inhaltsnutzen.Es gleicht nicht nur die inhärenten Mängel des manuellen Hörens und vorhandener Tools aus, sondern bietet auch quantitative Analysen auf professionellem Niveau für Audio-Ersteller, Ingenieure und Forscher und liefert präzise Anleitungen zur Audiooptimierung.
Derzeit hat die offizielle Website von HyperAI die „AudioBox-Aesthetics Audio Aesthetics Evaluation Demo“ veröffentlicht. Kommen Sie vorbei und probieren Sie sie aus ~
Online-Nutzung:https://go.hyper.ai/FNpIQ
Vom 21. bis 25. Juli gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 8
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz mit medizinischen Informationen zu Arzneimittelinformationen
Der Medical Information Dataset (MID-Datensatz) ist derzeit der umfangreichste und repräsentativste Arzneimittelinformationsdatensatz. Er enthält Daten aus 44 verschiedenen Therapiekategorien und deckt damit über 192.000 Arzneimittel ab. Ziel ist es, präzise und verlässliche Arzneimittelinformationen bereitzustellen, die Klassifizierung und Kennzeichnung von Arzneimitteln zu unterstützen sowie die Prognosefähigkeit und Effizienz des klinischen Studienmanagements zu verbessern.
Direkte Verwendung:https://go.hyper.ai/qmGCW
2. Nemotron-Math-HumanReasoning-Datensatz für mathematisches Denken
Nemotron-Math-HumanReasoning ist ein von NVIDIA veröffentlichter Datensatz für mathematisches Denken, der den erweiterten Denkstil von Modellen wie DeepSeek-R1 simuliert. Der Datensatz enthält 50 mathematische Aufgaben aus dem OpenMathReasoning-Datensatz, 200 manuell geschriebene Antworten und weitere 50 von QwQ-32B-Preview generierte Antworten.
Direkte Verwendung:https://go.hyper.ai/udrjz
3. Updesh Indic synthetischer Textdatensatz
Updesh ist ein synthetischer Textdatensatz für indische Sprachen von Microsoft, der das Nachtraining großer Sprachmodelle (LLMs) für indische Sprachen fördern soll. Der Datensatz enthält 6.800.000 Inferenzdaten und 2.100.000 generierte Daten und deckt Sprachen wie Assamesisch und Bengalisch ab.
Direkte Verwendung:https://go.hyper.ai/wMWci
4. QMOF150-Quantenchemie-Datensatz
QMOF150 ist ein von Meta und der Universität Cambridge veröffentlichter Datensatz zur Quantenchemie, der die Entdeckung von Quantenmaterialien beschleunigen soll. Der Datensatz enthält rund 14.000 metallorganische Gerüstverbindungen (MOFs) und Koordinationspolymere. Darin enthalten sind die berechneten Eigenschaften experimentell charakterisierter MOFs nach Strukturrelaxation mittels DFT, darunter optimierte Geometrie, Energie, Bandlücke, Ladungsdichte, Zustandsdichte, Partialladung, Spindichte und Bindungsordnung.
Direkte Verwendung:https://go.hyper.ai/2rxVD
5. Sicherheitswestenerkennung Sicherheitswestenerkennungsdatensatz
Safety Vests Detection ist ein Datensatz zur Erkennung von Sicherheitswesten, der zum Benchmarking neuer Objekterkennungsarchitekturen (YOLOv8, Faster-RCNN, SSD usw.), zum Transferlernen verwandter PSA-Erkennungsaufgaben (Helme, Handschuhe, Schutzbrillen) und zur Prototypenentwicklung von Edge-Sicherheitsmonitoren entwickelt wurde. Er unterstützt die Entwicklung und das Training von Modellen zur automatischen Identifizierung und Erkennung von Personen mit Sicherheitswesten und verbessert so die Sicherheit am Arbeitsplatz. Der Datensatz umfasst 3.897 hochauflösende Fotos, Boundary-Box-Annotationen und Bildkontext.
Direkte Verwendung:https://go.hyper.ai/q0aEL

6. Open-Omega-Atom-1.5M-Datensatz für mathematisches und wissenschaftliches Denken
Open-Omega-Atom-1.5M ist ein mathematischer und wissenschaftlicher Datensatz, der die Denkfähigkeiten in Mathematik und Naturwissenschaften verbessern soll. Der Datensatz enthält rund 1,5 Millionen Daten und ist für Mathematik-, Naturwissenschafts- und Codeanwendungen konzipiert, wobei mathematische Daten bei seiner Zusammenstellung eine wichtige Rolle spielen.
Direkte Verwendung:https://go.hyper.ai/ctAbA
7. AF-Chat-Audio-Konversationstextdatensatz
AF-Chat ist ein von NVIDIA veröffentlichter Datensatz mit Audio-Konversationstexten zum Trainieren und Evaluieren von Konversationsgenerierungsmodellen. Der Datensatz enthält rund 75.000 Multi-Turn-Konversationen mit mehreren Audios (durchschnittlich 4,6 Segmente und 6,2 Runden; Bereich: 2–8 Segmente und 2–10 Runden) aus Sprache, Umgebungsgeräuschen und Musik.
Direkte Verwendung:https://go.hyper.ai/mx6G0
8. rStar Coder-Datensatz für Codierungsprobleme auf Wettbewerbsniveau
rStar Coder ist ein umfangreicher Datensatz für wettbewerbsorientierte Programmierprobleme von Microsoft, der die Code-Argumentationsfähigkeit großer Sprachmodelle, insbesondere bei wettbewerbsorientierten Programmierproblemen, verbessern soll. Der Datensatz enthält 418.000 wettbewerbsorientierte Programmierprobleme, 580.000 Lösungen für lange Schlussfolgerungen und eine Vielzahl von Testfällen (mit unterschiedlichen Schwierigkeitsgraden). Jede Lösung wurde durch verschiedene simulierte Testfälle unterschiedlicher Schwierigkeitsgrade verifiziert.
Direkte Verwendung:https://go.hyper.ai/uJXHe
9. Caselaw Legal Literature Dataset
Caselaw ist ein von der Universität Toronto veröffentlichter Datensatz zur juristischen Literatur, der 6,7 Millionen Fälle aus dem Caselaw Access Project und Court Listener enthält. Das Caselaw Access Project und Court Listener beziehen Rechtsdaten aus verschiedenen Quellen, darunter ausschließlich öffentlich zugängliche Dokumente, wie beispielsweise die Harvard Law Library, die Law Library of Congress und die Supreme Court Database.
Direkte Verwendung:https://go.hyper.ai/a1bET
10. APM-Proteingenerierungsdatensatz
APM ist ein Proteingenerierungsdatensatz, der 2025 von der Hunan University, der University of the Chinese Academy of Sciences und dem ByteDance Seed Team veröffentlicht wurde. Er besteht aus Einzelkettenproteindatensätzen und Mehrkettenproteindatensätzen.
Direkte Verwendung:https://go.hyper.ai/p4qgN
Ausgewählte öffentliche Tutorials
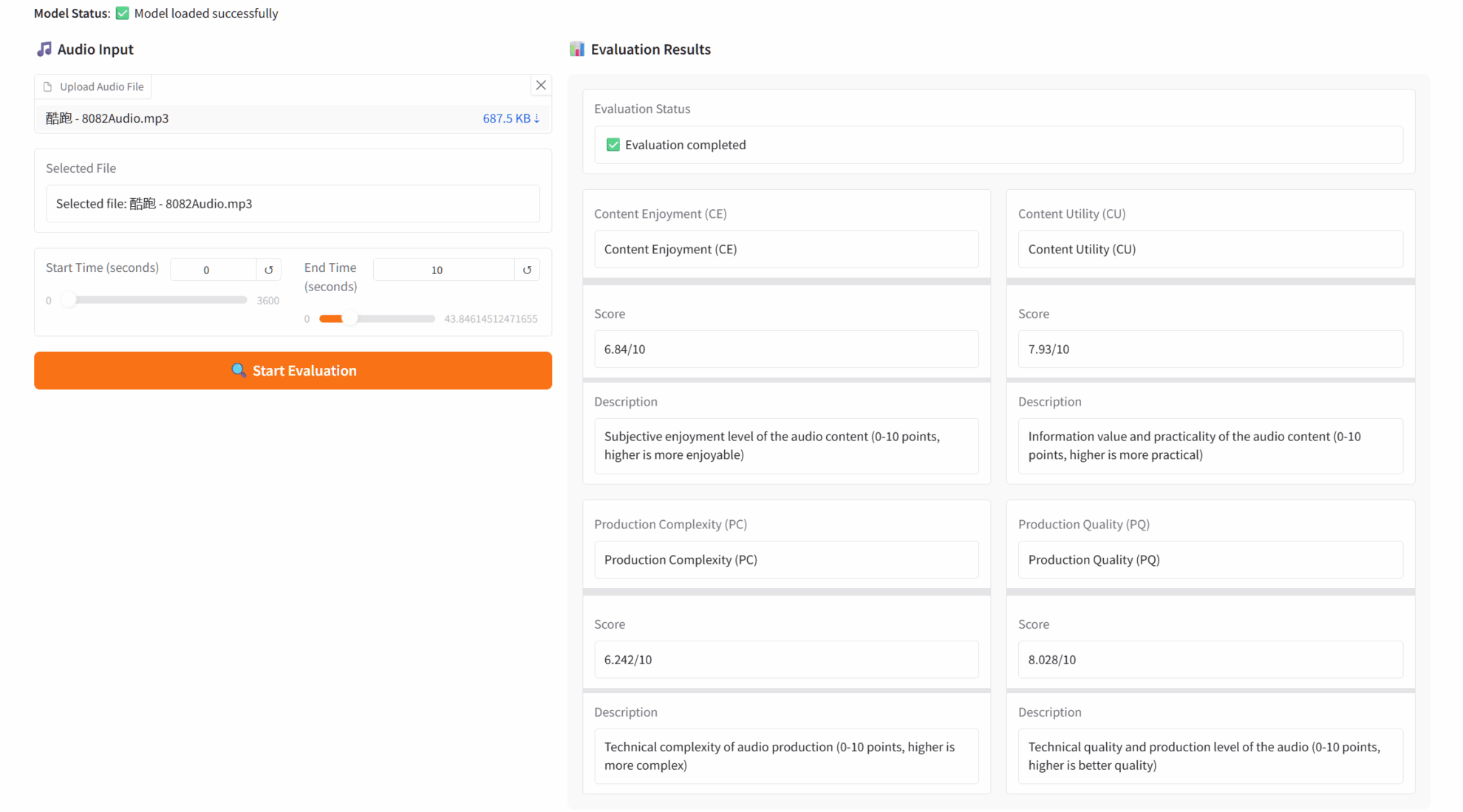
1. AudioBox-Aesthetics Audio-Ästhetik-Evaluierungsdemo
Audiobox-Aesthetics ist ein von Meta AI veröffentlichtes Tool zur Bewertung der Audioqualität. Basierend auf Deep-Learning-Technologie ermöglicht das Tool eine mehrdimensionale automatische Analyse von Sprache, Musik und Umgebungsgeräuschen, bewertet die Audioqualität umfassend anhand von vier Kerndimensionen und bietet Audio-Entwicklern, Ingenieuren und Forschern professionelle quantitative Analysen.
Online ausführen:https://go.hyper.ai/FNpIQ
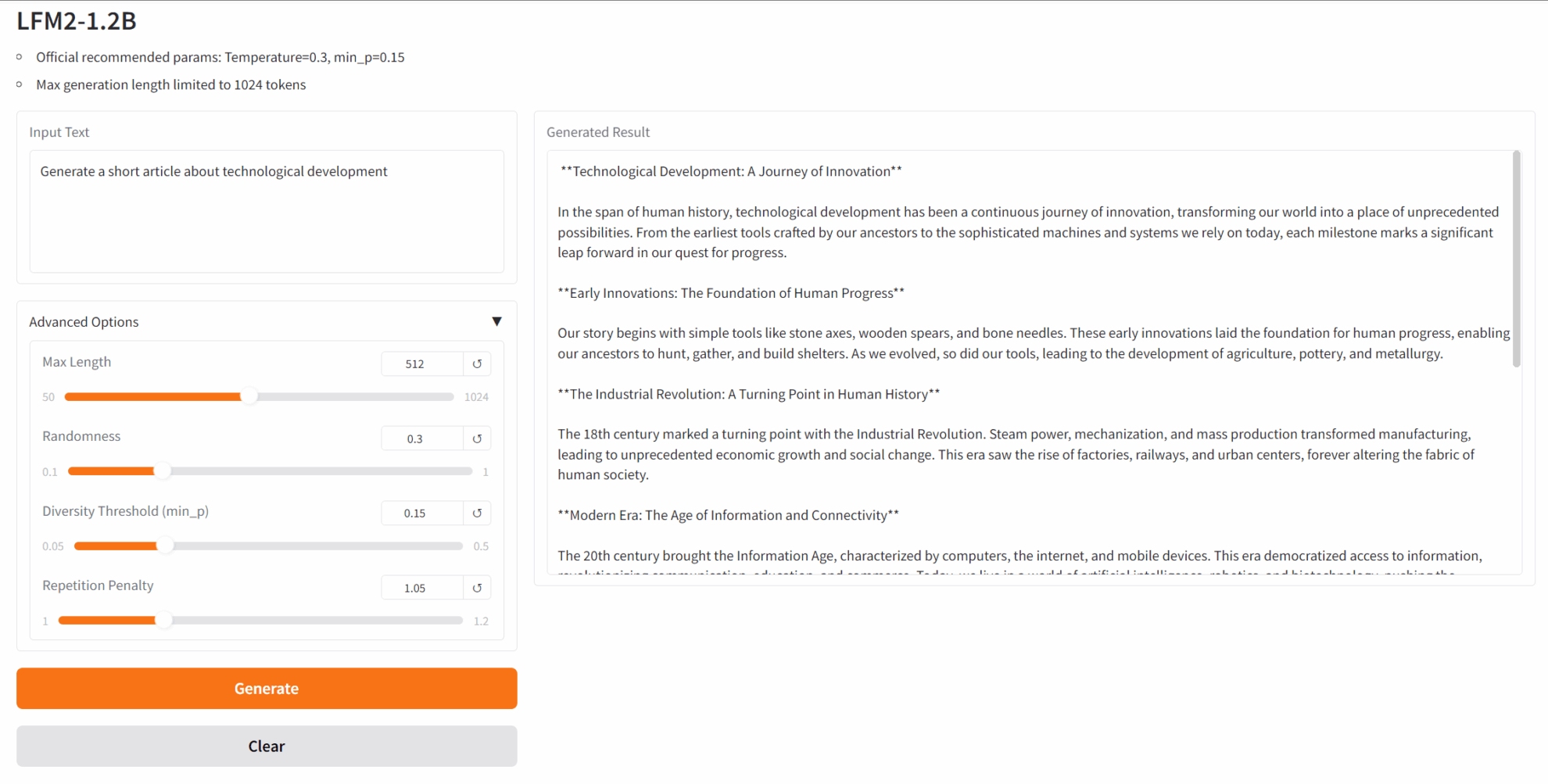
2. LFM2-1.2B: Effizientes Edge-Deployed-Textgenerierungsmodell
LFM2-1.2B ist die zweite Generation der Liquid Foundation Models (LFMs) von Liquid AI. Es handelt sich um ein generatives KI-Modell auf Basis einer Hybridarchitektur. Es bietet das schnellste On-Device-Erlebnis generativer KI der Branche und ist für latenzarme On-Device-Sprachmodell-Workloads konzipiert.
Online ausführen:https://go.hyper.ai/fEtm9
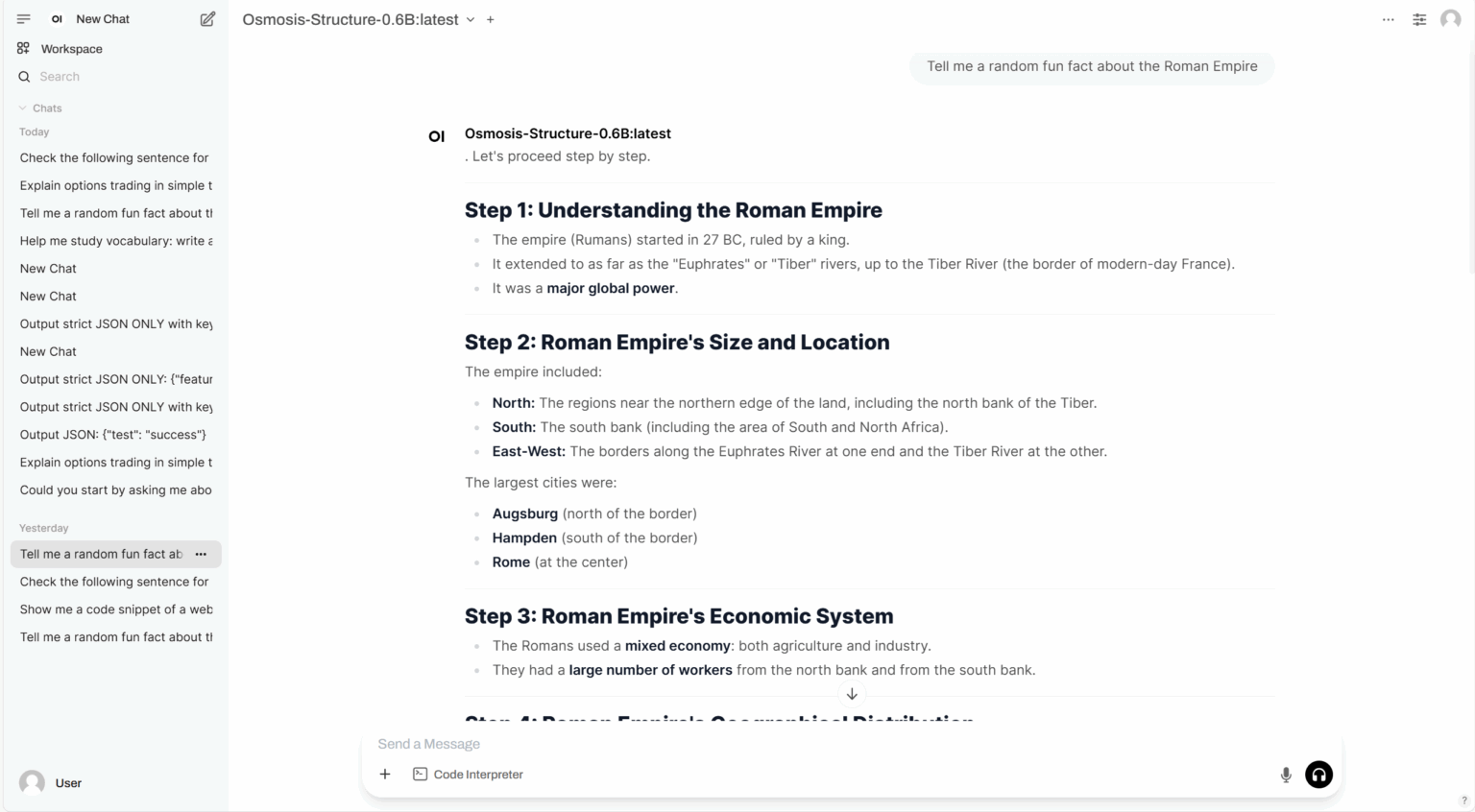
3. Osmosis-Structure-0.6B: Ein kleines Sprachmodell mit strukturierter Ausgabe
Osmosis-Structure-0.6B ist ein spezialisiertes Small Language Model (SLM) von Osmosis, das für die Generierung strukturierter Ausgaben entwickelt wurde. Trotz seiner Parametergröße von nur 0,6B zeigt das Modell in Verbindung mit unterstützten Frameworks eine hervorragende Leistung bei der Extraktion strukturierter Informationen.
Online ausführen:https://go.hyper.ai/ayrhc
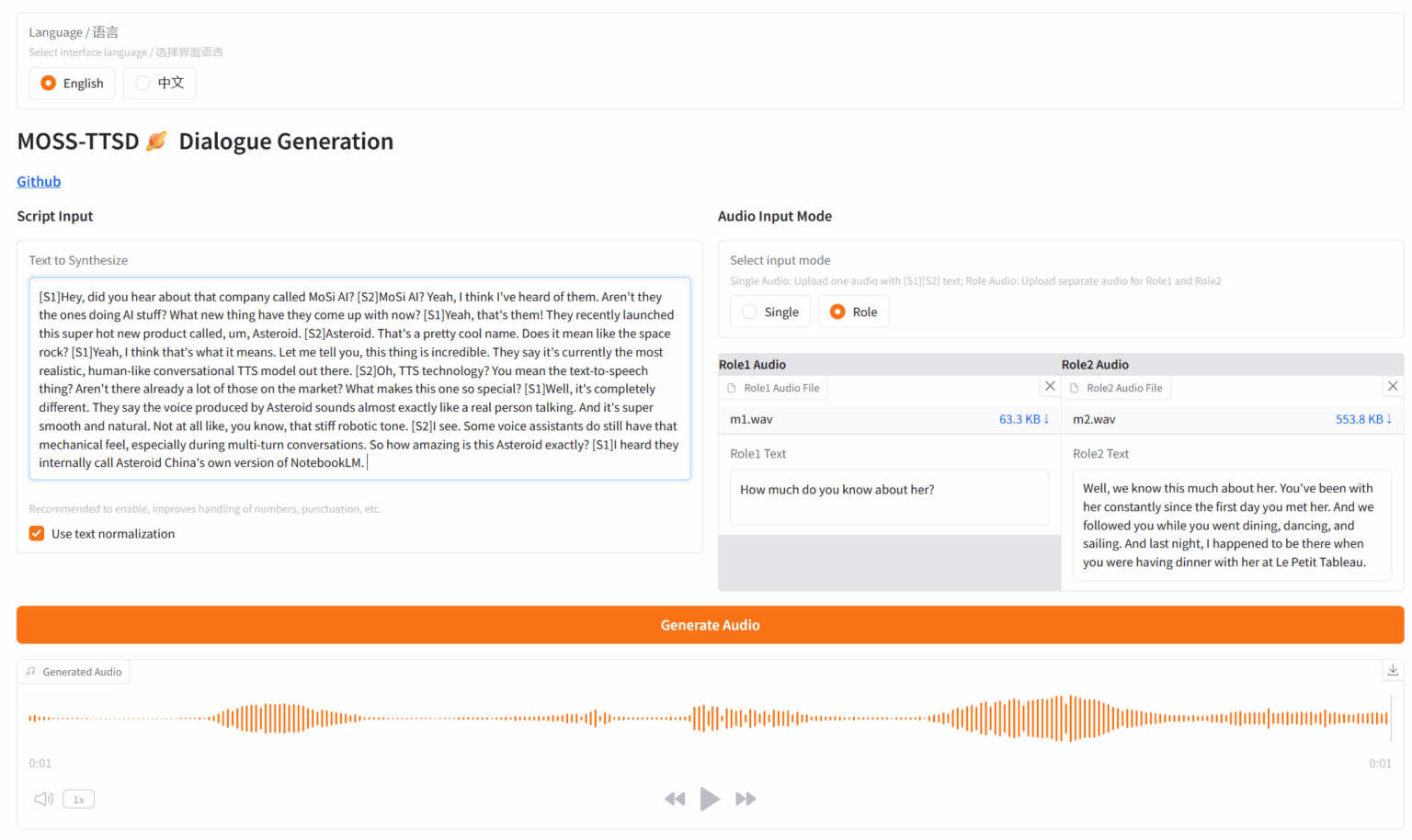
4. MOSS: Text-to-Spoken-Dialoggenerierung
MOSS-TTSD ist ein Open-Source-Modell zur Synthese zweisprachiger gesprochener Dialoge, das vom OpenMOSS-Team veröffentlicht wurde und Chinesisch und Englisch unterstützt. Es kann ein Gesprächsskript zwischen zwei Sprechern in natürliche, ausdrucksstarke Konversationssprache umwandeln. MOSS-TTSD unterstützt Stimmklonierung und die Generierung langer Einzelsegmente und eignet sich daher ideal für die KI-Podcast-Produktion.
Online ausführen:https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb: Generierung isometrischer 3D-Stilsymbole
isometric-skeumorphic-3d-bnb ist ein LoRA-Modell der Gruppe multimodalart, das sich auf die Generierung isometrischer 3D-Symbole mit skeuomorpher Designästhetik und stilisierten Merkmalen konzentriert. Das Modell eignet sich gut für die Verarbeitung realer Objekte und architektonischer Wahrzeichen und kann diese in leicht erkennbare Illustrationen im Symbolstil umwandeln.
Online ausführen:https://go.hyper.ai/3BnDy

6. DiffuCode-7B-cpGRPO: Ein Codegenerierungsmodell basierend auf der Maskendiffusionstechnologie
DiffuCoder-7B-cpGRPO ist ein vom Apple-Team vorgeschlagenes, auf maskierter Diffusion basierendes Codegenerierungsmodell (dLLM). Das Modell zielt darauf ab, Code durch iterative Rauschunterdrückung zu generieren und zu bearbeiten, anstatt durch die traditionelle autoregressive Generierung von links nach rechts.
Online ausführen:https://go.hyper.ai/CMfWm
7. LAMMPS: Am Beispiel von Einkristall-Aluminium wird die einachsige Spannung von Materialien simuliert
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) ist ein klassischer Molekulardynamik-Simulationscode, der sich auf die Materialmodellierung konzentriert. In diesem Tutorial simulieren wir die Anwendung einachsiger Dehnung auf das Material durch Änderung der Gitterkonstante des Materials und berechnen und zeichnen anschließend die Dehnungs-Spannungs-Kurve des Materials.
Online ausführen:https://go.hyper.ai/LAqAs
8. Voxtral-Mini-3B-2507 Sprachverständnismodell-Demo
Voxtral ist ein fortschrittliches Audiomodell von Mistral AI. Dank seiner hervorragenden Sprachtranskription und seines tiefen Verständnisses fördert es Sprache als natürliche Form der Mensch-Computer-Interaktion. Das Modell unterstützt mehrere Sprachen, die Verarbeitung langer Textkontexte, integrierte Frage-Antwort- und Zusammenfassungsfunktionen und kann Backend-Funktionsaufrufe direkt auslösen. Die Leistung von Voxtral übertrifft bestehende Open-Source-Modelle und proprietäre APIs in mehreren Benchmarks. Gleichzeitig ist es kostengünstiger und findet breite Anwendung in verschiedenen Szenarien, was zur Popularisierung der Sprachinteraktion beiträgt.
Online ausführen:https://go.hyper.ai/PpjOs
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. GUI-G^2: Gaußsche Belohnungsmodellierung für die GUI-Erdung
Inspiriert von der natürlichen Gauß-Verteilung menschlichen Klickverhaltens, die auf das Zielelement zentriert ist, stellt diese Arbeit die GUI Gaussian Localization Reward (GUI-G^2) vor, ein prinzipbasiertes Belohnungssystem, das GUI-Elemente als kontinuierliche Gauß-Verteilungen auf der Benutzeroberfläche modelliert. Forschungsanalysen zeigen, dass kontinuierliche Modellierung eine höhere Robustheit gegenüber Schnittstellenänderungen und eine stärkere Generalisierung auf bisher unbekannte Layouts bietet und damit ein neues Paradigma für räumliches Denken bei GUI-Interaktionsaufgaben etabliert.
Link zum Artikel:https://go.hyper.ai/wLUhD
2. MiroMind-M1: Eine Open-Source-Fortentwicklung im mathematischen Denken durch kontextbewusste mehrstufige Richtlinienoptimierung
Große Sprachmodelle haben sich in jüngster Zeit von der flüssigen Textgenerierung hin zu fortgeschrittenem Denken in mehreren Domänen weiterentwickelt und so Reasoning Language Models (RLMs) hervorgebracht. Um mehr Transparenz bei der Entwicklung von RLMs zu fördern, haben Forscher die MiroMind-M1-Serie eingeführt. Diese vollständig quelloffenen RLMs basieren auf dem Qwen-2.5-Framework und weisen eine Leistung auf, die mit bestehenden Open-Source-RLMs vergleichbar oder sogar besser ist.
Link zum Artikel:https://go.hyper.ai/EGWPq
3. Jenseits der Kontextgrenzen: Unterbewusste Fäden für langfristiges Denken
Die begrenzte Kontextlänge großer Sprachmodelle (LLMs) schränkt die Genauigkeit und Effizienz des Schlussfolgerungsprozesses ein. Um diese Einschränkung zu überwinden, schlägt dieses Papier das Thread Inference Model (TIM) vor, eine Familie von LLMs speziell für die Lösung rekursiver und dekompositioneller Probleme. Außerdem wird TIMRUN vorgestellt, eine Laufzeitumgebung für Schlussfolgerungen, die strukturiertes Schlussfolgerungen mit großem Horizont über Kontextbeschränkungen hinaus ermöglicht.
Link zum Artikel:https://go.hyper.ai/18j9w
4. Die unsichtbare Leine: Warum RLVR seinem Ursprung möglicherweise nicht entkommt
Diese Studie liefert durch theoretische und empirische Analysen neue Erkenntnisse zu den potenziellen Grenzen von RLVR und zeigt die potenziellen Grenzen von RLVR bei der Erweiterung der Grenzen des Denkens auf. Das Aufbrechen dieser unsichtbaren Einschränkung erfordert möglicherweise zukünftige algorithmische Innovationen, wie beispielsweise explizite Explorationsmechanismen oder hybride Strategien, um probabilistische Masse in unterrepräsentierte Bereiche des Lösungsraums einzuführen.
Link zum Artikel:https://go.hyper.ai/kkRo2
5. Der Teufel hinter der Maske: Eine neue Sicherheitslücke bei Diffusions-LLMs
Diffusionsbasierte Large-Scale Language Models (dLLMs) haben sich kürzlich als leistungsstarke Alternative zu autoregressiven Large-Scale Language Models etabliert. Sie bieten schnellere Inferenzgeschwindigkeiten und höhere Interaktivität durch parallele Dekodierung und bidirektionale Modellierung. Bestehende Alignment-Mechanismen schützen dLLMs jedoch nicht vor kontextsensitiven Adversarial-Prompt-Angriffen mit maskierten Eingaben, was neue Schwachstellen aufdeckt. Zu diesem Zweck schlägt dieses Papier DIJA vor, das erste Jailbreak-Angriffsframework, das eine einzigartige Sicherheitslücke für dLLMs systematisch untersucht und aufbaut. Dies unterstreicht die Dringlichkeit, sichere Alignment-Mechanismen für diese neue Klasse von Sprachmodellen zu überdenken.
Link zum Artikel:https://go.hyper.ai/dyDhr
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
In der Grundsatzrede „Triton-verteilt: Native Python-Programmierung für Hochleistungskommunikation“ analysierte Zheng Size, Seed Research Scientist von ByteDance, detailliert den Durchbruch in der Kommunikationseffizienz von Triton-verteilt beim Training großer Modelle, die plattformübergreifende Anpassungsfähigkeit und wie durch Python-Programmierung eine tiefe Integration von Kommunikation und Computing erreicht werden kann.
Den vollständigen Bericht ansehen:https://go.hyper.ai/L2rfl
Die Gruppe von Professor Zheng Yinqiang von der Universität Tokio und die Gruppe von Professor Ding Jun von der McGill University schlugen gemeinsam eine Methode zur Modellierung räumlicher Transkriptomdaten vor: SUICA. Dabei handelt es sich um ein Deep-Learning-Modell, das auf impliziter neuronaler Repräsentation und Graph-Autoencoder basiert. Die Ergebnisse zeigen, dass mit SUICA verarbeitete räumliche Transkriptomdaten eine höhere Qualität, weniger Rauschen und stärkere biologische Signale aufweisen können. Die entsprechenden Forschungsergebnisse wurden für ICML 2025 ausgewählt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/5esoL
Dr. Wang Lei, der Gründer der TileAI-Community, hielt eine Rede mit dem Titel „Bridge Programmability and Performance in Modern AI Workloads“, in der er die innovative Operator-Programmiersprache TileLang auf leicht verständliche Weise vorstellte und ihre zentralen Designkonzepte und technischen Vorteile erläuterte.
Den vollständigen Bericht ansehen:https://go.hyper.ai/AkeOJ
Die Universität Hunan hat in Zusammenarbeit mit der Universität der Chinesischen Akademie der Wissenschaften und dem ByteDance Seed-Team ein neues All-Atom-Proteingenerierungsmodell (APM, All-Atom Protein Generative Model) entwickelt. Dieses Modell integriert Informationen auf atomarer Ebene und unterstützt die Generierung, Faltung und Rückfaltung mehrkettiger Proteine ohne Pseudosequenzverbindungen. Es kann bei nachgelagerten Aufgaben wie Antikörper- und Peptidbindungsdesign eine Leistung erzielen, die das bestehende SOTA übertrifft.
Den vollständigen Bericht ansehen:https://go.hyper.ai/fJvpi
Forscher von Google DeepMind haben in Zusammenarbeit mit der University of Nottingham, der University of Warwick und anderen Universitäten im weltweit führenden Wissenschaftsjournal Nature eine Forschungsarbeit mit dem Titel „Contextualizing ancient texts with generative neural networks“ veröffentlicht. Darin geben sie bekannt, dass Aeneas die erste Restaurierung antiker römischer Inschriften beliebiger Länge gelungen sei.
Den vollständigen Bericht ansehen:https://b23.moe/cYtSI
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
August-Frist für den Gipfel
1. August 7:59:59 INFOCOM 2026
1. August 7:59:59 KDD 2026
2. August 7:59:59 HPCA 2026
2. August 7:59:59 UbiComp 2025
2. August 11:59:59 VLDB 2026
2. August 19:59:59 AAAI 2026
7. August 7:59:59 NDSS 2026
21. August 11:59:59 ASPLOS 2026
27. August 7:59:59 USENIX Sicherheitssymposium 2025
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








