Command Palette
Search for a command to run...
Vom Herzmodell Bis Zur LLM-basierten Krankheitsnetzwerkanalyse Analysiert Li Dong Vom Tsinghua Chang Gung Hospital Den Entwicklungstrend Medizinischer Großmodelle Aus Datenperspektive

Mit der Weiterentwicklung der künstlichen Intelligenz hat KI auch im medizinischen Bereich tiefgreifende Veränderungen bewirkt. Durch die Integration von Daten aus verschiedenen Quellen und intelligenten Algorithmen bietet sie neue Lösungen für mehr Effizienz und präzisere Diagnosen in der Medizinbranche. Medizinische Daten spielen als „Treibstoff“ großer Modelle und zentraler Träger medizinischer Entscheidungen eine entscheidende Rolle.Insbesondere im Kontext der beschleunigten digitalen Transformation des chinesischen Gesundheitssystems ist die Analyse medizinischer Modelle aus einer Datenperspektive ein unvermeidlicher Weg zur Innovation.
Kürzlich hielt Professor Li Dong, Direktor des Medical Data Science Center des Tsinghua Chang Gung Hospital, auf der Beijing Zhiyuan Conference 2025 eine Rede im Forum „AI+Science & Medicine“.Das Thema lautet: „Wie medizinische Daten im Zeitalter der intelligenten Gesundheitsversorgung für innovative Forschung genutzt werden können“.Kombiniert mit der praktischen Erfahrung des Tsinghua Chang Gung Memorial Hospital,Aus Datensicht wurden mehrere Dimensionen geteilt, darunter das Implementierungsmodell des großen Modells, technische Einschränkungen, Ressourcenrekonstruktion und Anwendungserkundung.

HyperAI hat die ausführlichen Ausführungen von Professor Li Dong zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Nachfolgend finden Sie die Abschrift der Rede.
Anwendung und Herausforderungen großer Modelle in medizinischen Szenarien
Anwendung im Modus „Lokale Bereitstellung + benutzerdefinierte Entwicklung + Offline-Nutzung“
DeepSeek ist ein großes Modell, das in den letzten Jahren sehr beliebt geworden ist. Es verfügt über drei Hauptnutzungsmodi in medizinischen Szenarien: Leichtgewichtiger Nutzungsmodus auf Mobiltelefonen, Cloud-Zugriffsmodus und „lokale Bereitstellung + benutzerdefinierte Entwicklung + Offline-Nutzung“.
Unter diesen drei Zugriffsmethoden„Lokale Bereitstellung + kundenspezifische Entwicklung + Offline-Nutzung“ hat sich in der Praxis als optimale Lösung erwiesen.Aufgrund der Richtlinienbeschränkung „Daten dürfen das Krankenhaus nicht verlassen“ kann das Cloud-Modell nicht mit realen Daten trainiert werden, was es zu einer „statischen Vorlage“ macht. Die leichtgewichtige mobile Anwendung kann nur einfache Konsultationen durchführen und kann die grundlegenden medizinischen Anforderungen nicht erfüllen. Obwohl „lokale Bereitstellung + kundenspezifische Entwicklung + Offline-Nutzung“ Datenlecks und -verschmutzungsrisiken (wie die Vermischung exogener Halluzinationsdaten) vermeiden kann, bedeutet dies auch, dass das Krankenhaus die hohen Kosten für die Rechenleistung selbst tragen muss.
Herausforderungen großer Modelle im Gesundheitswesen
Bei der Implementierung des Großmodells im Krankenhaus standen uns viele Herausforderungen bevor.Zum Beispiel algorithmische Mängel, Halluzinationsprobleme, Rechenleistungsfallen, KI-Fairness usw.
* Algorithmusfehler:Die Beliebtheit von DeepSeek liegt in seiner Open Source-Architektur und dem niedrigen Preis. Der verwendete „Mixed Expert Mode (MoE)“ senkt die Rechenleistung durch Aufteilung des neuronalen Netzwerks, weist jedoch in medizinischen Szenarien Einschränkungen auf: Erstens unterstützt DeepSeek keine multimodale Beratung, und die Entscheidungsfindung durch einen einzelnen Experten führt bei komplexen Fällen zu Fehldiagnosen. Zweitens werden Daten, um die Rechenleistung aufrechtzuerhalten, willkürlich online veröffentlicht, was zum Verlust wichtiger Informationen (wie Allergie- und Operationsgeschichte) führen und somit Diagnose und Behandlung gefährden kann.
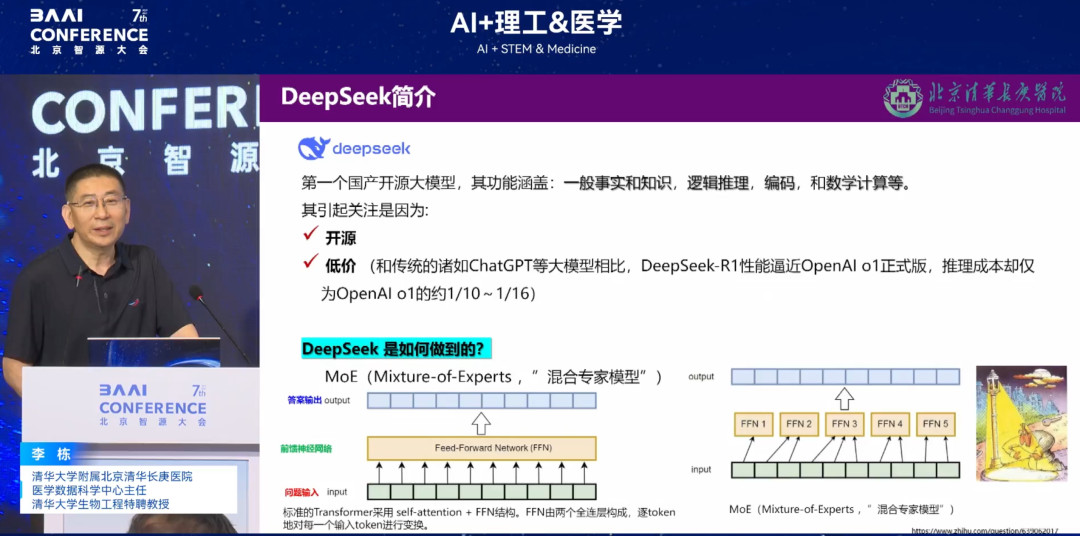
* Halluzinationsprobleme:DeepSeek weist in bestimmten medizinischen Szenarien einen gewissen Prozentsatz an Halluzinationen auf. Wir verwenden einen „dreifachen Verifizierungsmechanismus“ (erste Überprüfung des Algorithmus + Überprüfung durch den Arzt + Vergleich der Wissensdatenbank), um Risiken zu minimieren. Dies erhöht jedoch den Zeitaufwand für Diagnose und Behandlung.
* Hash-Power-Falle:Der Stromverbrauch kleiner Rechenzentren ist bereits enorm und das Training komplexerer großer medizinischer Modelle erfordert kontinuierliche Investitionen.
* KI-Fairness:Führende Krankenhäuser monopolisieren fortschrittliche Modelle, indem sie ihre Ressourcenvorteile ausnutzen, was die „digitale Kluft“ verschärfen kann.
Neukonstruktion medizinischer Bewertungsstandards: Vom „Drei-Stufen-Standard“ zum „Sechs-Faktoren-Wettbewerb“
Der Einsatz großer Modelle im medizinischen Bereich ist weitaus komplizierter als erwartet. Die Nationale Gesundheitskommission hoffte ursprünglich, das Ungleichgewicht der medizinischen Ressourcen durch KI zu verringern. Drei Monate nach der Einführung stellten wir jedoch fest, dass die Ergebnisse kontraproduktiv waren. Weit davon entfernt, das Ungleichgewicht der medizinischen Ressourcen zu verbessern, verändert das große Modell vielmehr die Wettbewerbslandschaft der Tertiärkrankenhäuser.
Die Bewertungskriterien für traditionelle Tertiärkrankenhäuser sind „berühmte Ärzte, Ausstattung und Hardware-Umgebung“, aber im Zeitalter der großen Modelle wurden drei neue Schwellenwerte hinzugefügt:
Das erste ist eine enorme Rechenleistung.Das Chang Gung Memorial Hospital verfügte einst über die zweitgrößte Rechenkapazität aller medizinischen Einrichtungen in Peking, konnte aber dennoch keine langfristige Ausbildung gewährleisten. Als ein kleines Rechenzentrum in Betrieb genommen wurde, kam es sogar zu einem Stromausfall in der Hälfte des Gebäudes.
Der zweite ist ein erstklassiger Data Governance Engineer.Medizinische Daten umfassen elektronische Patientenakten, Bilder, Tests und andere Daten, die bereinigt, beschriftet und strukturiert werden müssen. Wir haben 5 Millionen in eine Datenverwaltungsrunde investiert, aber der Effekt war nicht signifikant;
Endlich ein erstklassiger Algorithmen-Ingenieur.Um das „Black Box“-Problem und die „Halluzinations“-Erkennung zu lösen, müssen Algorithmen an medizinische Szenarien angepasst werden.
Smart Healthcare: datengetriebene Innovation in Gesundheitsmodellen
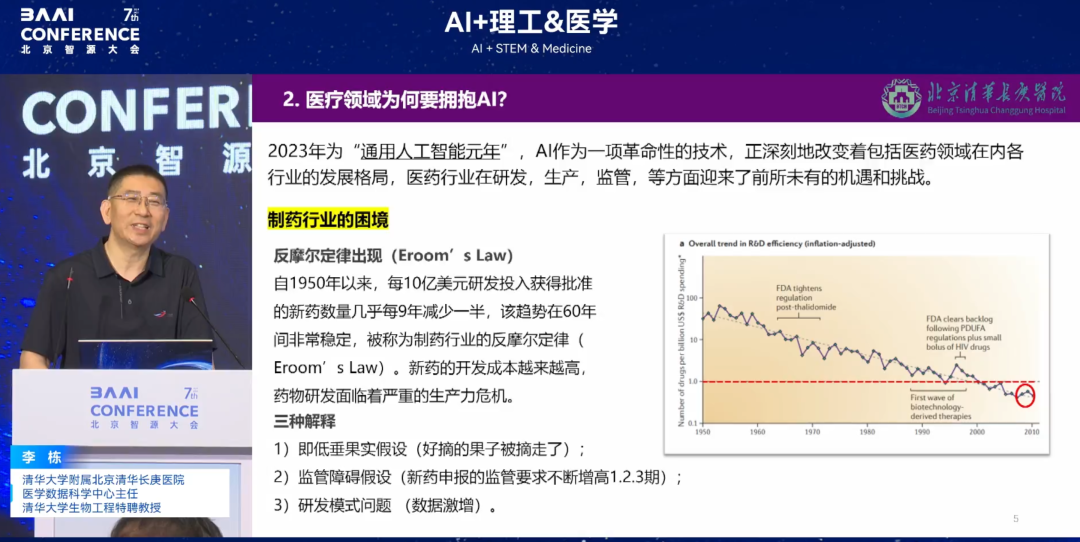
Wie die folgende Abbildung zeigt, hat sich seit 1950 die Zahl der neu zugelassenen Medikamente pro Milliarde US-Dollar an Forschungs- und Entwicklungsinvestitionen fast alle neun Jahre halbiert. Dieser Trend war in den letzten 60 Jahren sehr stabil. Dieses Phänomen ist in der Pharmaindustrie als Anti-Mooresches Gesetz bekannt.Die Kosten für die Entwicklung neuer Medikamente steigen immer weiter und die Arzneimittelforschung und -entwicklung steht vor einer schweren Produktivitätskrise.
Dies gilt nicht nur für die Pharmaindustrie, sondern für die gesamte Medizinbranche. Wie in der folgenden Abbildung dargestellt,Statistiken aus dem Jahr 2018 zufolge betrug die Zahl der Krankenhäuser der Klasse III in China 7,631 TP3T des Landes, sie waren jedoch für 50,971 TP3T des ambulanten Patientenaufkommens des Landes verantwortlich.Es sind eine Reihe von Problemen aufgetreten, darunter die ungleiche Verteilung medizinischer Ressourcen, eine geringe Diagnose- und Behandlungseffizienz sowie der Druck durch Veränderungen im Krankheitsspektrum aufgrund einer alternden Bevölkerung. Daher ist es im Zeitalter der intelligenten Gesundheitsversorgung unerlässlich, dass KI den medizinischen Wandel beschleunigt.
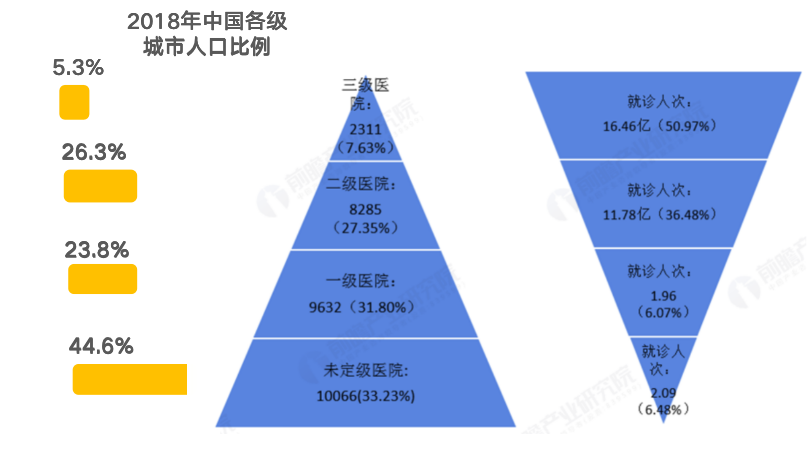
(Einheit: Haushalt, 100 Millionen Menschen, %), Quelle: Nationale Gesundheitskommission (Erstellt vom Prospective Industry Research Institute)
Traditioneller Algorithmus zur Steuerung der logistischen Regression als Benchmark
Da der KI-Trend im klinischen und pharmazeutischen Bereich an Bedeutung gewinnt, kann die traditionelle logistische Regression zwar für die klinische Forschung eingesetzt werden, weist aber erhebliche Mängel auf. Am Beispiel der quantitativen Bewertung des Zusammenhangs zwischen langfristiger Luftverschmutzung und Myokardfibrose erfassen traditionelle Methoden üblicherweise soziodemografische Merkmale, Biomarker und Bildgebungsberichte (nicht-bildgebende Omics-Methoden), integrieren Variablen wie PM2,5 und PM10 in das Modell und analysieren deren Zusammenhang mit Krankheiten (wie Körperfibrose).
Diese Art der Korrelationsanalyse seit den 1970er Jahren weist jedoch grundlegende Mängel auf: Die medizinische Forschung muss die Kausalität untersuchen, doch traditionelle Methoden können nur die Korrelation vordefinierter Variablen aufdecken und keine neuen Risikofaktoren identifizieren, die nicht vorab in das Modell einbezogen wurden. Dadurch verfällt man in das Henne-Ei-Paradoxon. Darüber hinausDie herkömmliche Korrelationsanalyse hat Schwierigkeiten mit der Handhabung von Variableninteraktionen und kann in der Regel nur die Interaktionen von zwei oder drei Faktoren analysieren. Sie kann nicht Hunderte oder Tausende von Variablen berücksichtigen und nicht direkt auf Bilddaten zugreifen.
Im Gegensatz,Die algorithmische Analyse hat erhebliche Vorteile: Sie kann multivariate Interaktionen verarbeiten, riesige Datenmengen (einschließlich Bilder) einbeziehen und durch wiederholtes Training von Token (10.000 oder sogar 100 Millionen Mal)Wenn ein Risikofaktor weiterhin besteht, kann er als „kausal“ betrachtet werden, was dem für die medizinische Forschung erforderlichen Kausalzusammenhang näher kommt.
Rekonstruktion der 4 Elemente der medizinischen KI: Szenario-priorisierte Ressourcenzuweisung
Smart Healthcare ist ein neues medizinisches Modell, das moderne Informationstechnologie nutzt, um medizinische Dienstleistungen und das Management zu verbessern. Ziel ist es, die medizinische Effizienz zu steigern, die Behandlungskosten zu senken und die medizinische Erfahrung der Patienten zu verbessern. Die Kerngrundlage bilden Big Data, Cloud Computing, das Internet der Dinge und künstliche Intelligenz.
In der traditionellen Kognition sind die drei Elemente der künstlichen Intelligenz Algorithmen, Rechenleistung und Daten.Im medizinischen Szenario schlagen wir jedoch die „Vier-Elemente-Theorie“ vor, nämlich Algorithmus, Rechenleistung, Daten und Anwendungsszenarien, wobei ihre jeweiligen Anteile 10%, 30%, 40% und 20% betragen.Da sich die Algorithmen im In- und Ausland kaum unterscheiden und die meisten Open Source sind, machen sie den geringsten Anteil an medizinischen KI-Elementen aus. Rechenleistung kann durch die Anmietung von Cloud-Computing-Leistung entlastet werden. Anwendungsszenarien dienen als Hilfsmittel, um Semantik bereitzustellen und klinische Anforderungen in vom Modell verständliche Aufgaben umzuwandeln. Daraus lässt sich schließen, dass „Daten“ der entscheidende Faktor sind. China ist weltweit führend beim medizinischen Datenvolumen, doch die geringe Digitalisierungsrate macht das Land zu einer unerschlossenen Goldgrube. Schätzungen zufolge wird das Wachstum traditionell strukturierter medizinischer Daten weltweit bis 2028 kaum ausreichen, um den Bedarf großer Modelle zu decken (die Datenerfassung begann 1550). China wird sich aufgrund seiner unvollständigen Informatisierung zur zentralen Datenbank der globalen medizinischen Forschung und Entwicklung entwickeln.
Zwei Ansätze für das Training medizinischer Daten
Viele haben Zweifel am Training großer Modelle, etwa ob Krankenhausdaten direkt für das Training genutzt werden können. Erfahrungsgemäß ist dieser Ansatz jedoch nicht umsetzbar.Es gibt zwei Ansätze zum Trainieren großer Modelle.
Erstens übersteigt der Datenbedarf großer Modelle den der klinischen Forschung bei weitem.Obwohl es für Krankenhäuser schwierig ist, Daten so zu verwalten, dass sie für die klinische Forschung genutzt werden können, stellt das Training großer Modelle höhere Anforderungen an die Daten. Denn obwohl große Modelle über unüberwachtes Lernen verfügen, ist das alleinige Verlassen auf unüberwachtes Lernen vergleichbar mit der Entwicklung eines Arztes zum Chefarzt. Dies ist zu langsam und kann den tatsächlichen Anforderungen nicht gerecht werden. Um das Training zu beschleunigen, muss es mit einem ärztlichen Entscheidungsbaum ausgestattet werden. Die Daten können nicht einfach in das große Modell eingegeben werden, sondern müssen gründlicher verarbeitet und optimiert werden.
Zweitens: Wenn Krankenhäuser große Modelle direkt für Schulungen verwenden möchten, müssen sie das Datenverwaltungsmodell „Bibliothek + Fachbibliothek + Bibliothek für spezielle Krankheiten + Bibliothek für spezielle Projekte“ übernehmen.Dieses Modell wurde nach der Integration praktischer Untersuchungen in mehreren Krankenhäusern, wie beispielsweise dem Tiantan-Krankenhaus, entwickelt und gilt als ein Datenmodell, das sich derzeit besser für das Training großer Modelle eignet. Diese hierarchische Datenverwaltungsstruktur kann gezielter hochwertige und systematische Daten für große Modelle bereitstellen und so die Wirkung und Effizienz des Trainings großer Modelle verbessern.

Herz-Kreislauf- und Diabetesforschung: ein Modell für datengetriebene Innovation
Abschließend möchte ich kurz auf zwei Studien eingehen, die wir zum Thema Smart Healthcare durchgeführt haben.
Kardiovaskuläre KI: Von „tragbaren Geräten“ bis zu „Gesamtherzmodellen“
Laut Statistas Prognose zum globalen Markt für intelligente Gesundheitsversorgung im Jahr 2025 macht der Herz-Kreislauf-Bereich ein Viertel aus und stellt damit das größte Marktsegment dar. Die Digitalisierung erstreckt sich auf die akute und die Genesungsphase von Herz-Kreislauf-Erkrankungen.
Nach der Einführung der ersten Generation der Apple Watch erzielte die Einzelleitung präzisere Vorhersagen als zwölf Leitungen und konnte Vorhofflimmern (AFib) und andere Arrhythmien beim Träger erkennen. Dies führte zu Innovationen in der Primärversorgung. Basierend auf dieser Inspiration,Unser Team stellte die Hypothese auf: „Da die auf tragbaren Geräten basierende Elektrokardiogramm-Wellenform (EKG) Arrhythmien frühzeitig vorhersagen kann, können andere tragbare Geräte ohne EKG-Funktion denselben Effekt nur über die Herzfrequenz erzielen?“Nach einer Reihe von Überprüfungen stellten wir fest, dass andere Geräte den gleichen Effekt mit einer Genauigkeit von bis zu 99,67% erzielen können. Unser Team erfasste die Herzschläge pro Minute gewöhnlicher Sportarmbänder innerhalb von 24 Stunden, um die Dauer der Arrhythmie vorherzusagen.
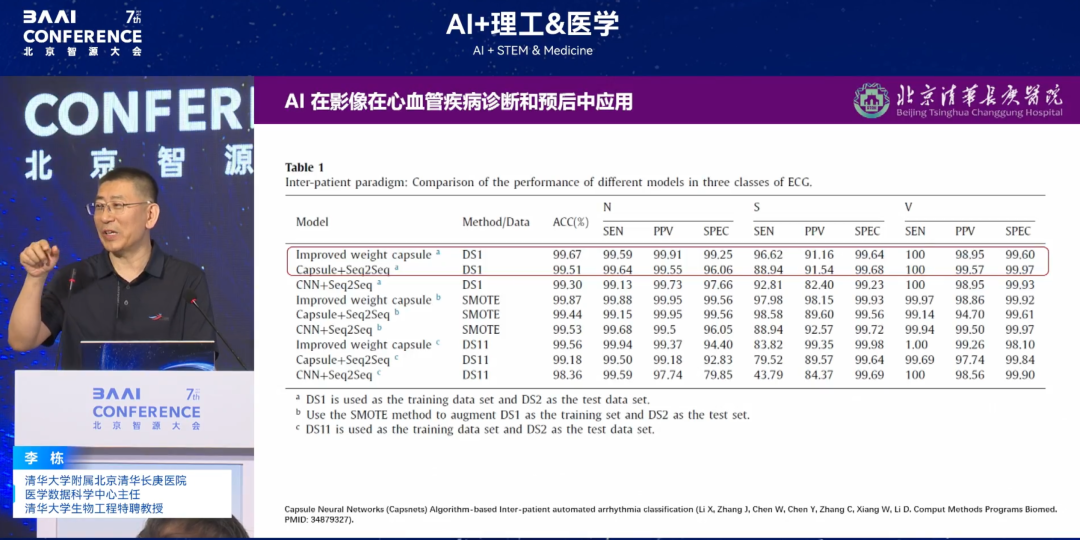
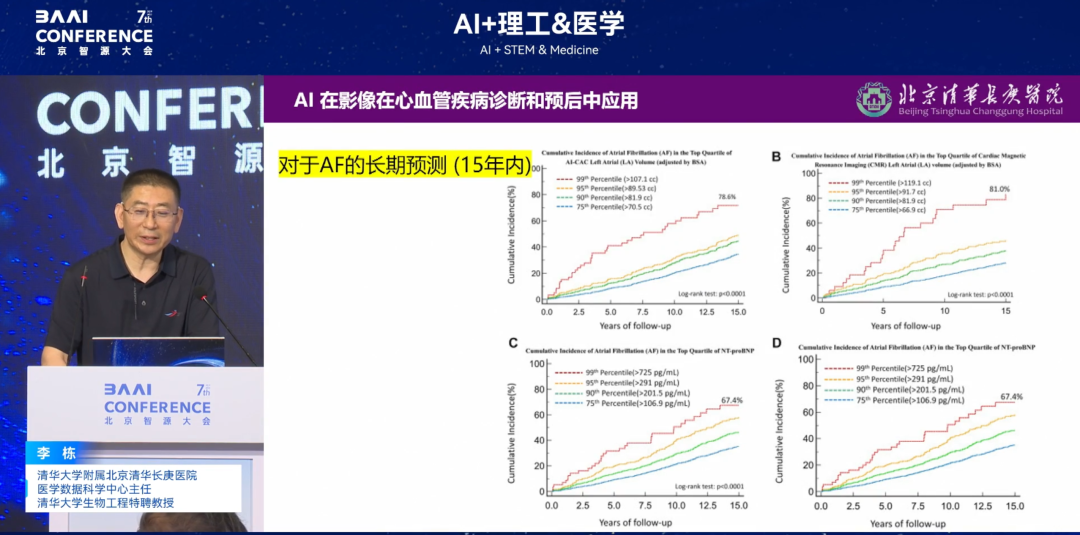
Weiter gehen,Wir haben eine zweite Hypothese vorgeschlagen: „Können Arrhythmien zusätzlich zu EKG-Wellenformen und Herzfrequenz frühzeitig vorhergesagt werden? Ist die Kontraktion/Entspannung der vier Herzkammern an Arrhythmien beteiligt? Wenn ja, kann dies vorhergesagt werden?“Nach weiterer Überprüfung durch uns kann das „Gesamtherzmodell“, das mehrdimensionale Daten wie Herz-Kreislauf-, Nerven- und Muskeldaten integriert, das Herz mithilfe von Algorithmen „verpacken“. Die endgültigen Ergebnisse zeigen, dass die Integration aller Herzfunktionsdaten zur Vorhersage des Arrhythmierisikos eine genaue Vorhersage des Krankheitsrisikos für bis zu 15 Jahre ermöglicht. Die entsprechenden Ergebnisse wurden in einem JACC-Subjournal (Impact Factor 24+) veröffentlicht.
* Titel des Papiers:KI-gestützte CT-Herzkammervolumetrie sagt Vorhofflimmern und Schlaganfall vergleichbar mit MRT voraus
* Papieradresse:https://www.jacc.org/doi/abs/10.1016/j.jacadv.2024.101300
Diabetesforschung: Vom „Komplikationsspektrum“ zum „Ursachenmechanismus“
Eine weitere Studie untersuchte ein Krankheitsnetzwerk anhand eines umfassenden Modells. Früher ging man davon aus, dass Frühdiabetes (vor dem 40. Lebensjahr) milder verläuft als Normaldiabetes. So kann beispielsweise eine Person, die mit 20 Jahren an Diabetes erkrankt, mit 30 Jahren normale Blutdruck- und Blutfettwerte sowie keine Komplikationen aufweisen, während eine Person mit 40 Jahren mit 50 Jahren auffällige Indikatoren und andere Erkrankungen aufweisen kann. Die Untersuchung des gesamten Diabetes-Komplikationsspektrums ergab jedoch, dassDie systemischen Wechselwirkungen der Komplikationen von Frühdiabetes sind intensiver und es bestehen Vektorpfadassoziationen, die sich von der angeborenen Wahrnehmung der Menschen unterscheiden.
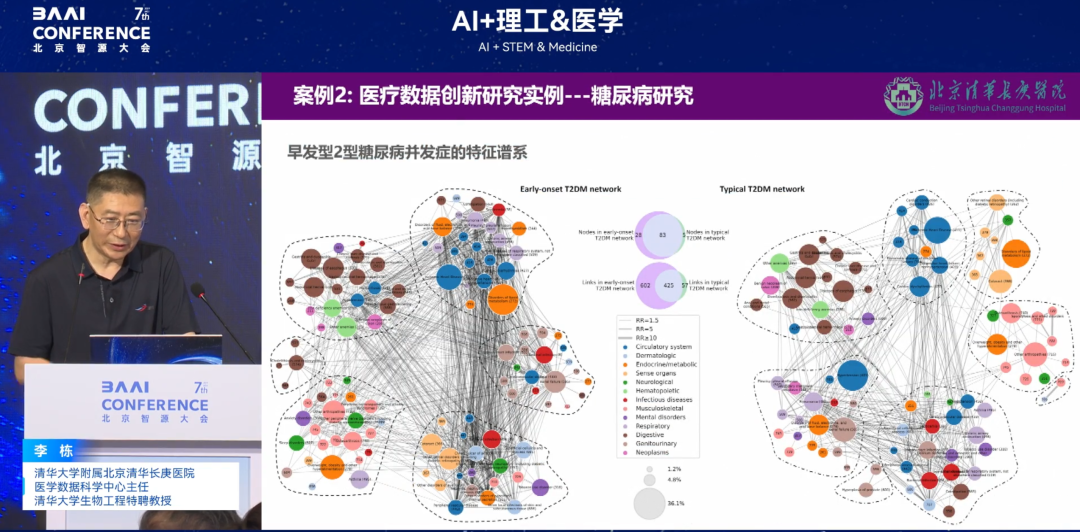
(Links: Früh einsetzender Diabetes; Rechts: Normal diagnostizierter Diabetes; jeder Kreis mit unterschiedlichen Farben stellt ein anderes System dar)
Zukunftsausblick: Ein neues Paradigma für das Gesundheitswesen im Zeitalter der Datenintelligenz
In den letzten Jahren hat sich die medizinische KI in China rasant entwickelt. Wie Akademiemitglied Li Guojie sagte: „Die Menschheit befindet sich nun in der intelligenten Phase des Informationszeitalters und bewegt sich auf das intelligente Zeitalter zu. Das Paradigma der intelligenten wissenschaftlichen Forschung hat sich herausgebildet und kann zum „fünften wissenschaftlichen Forschungsparadigma“ werden. Wir dürfen uns in unserem Verständnis der Zeit nicht irren. Wenn wir die Chance des Wandels der Zeit verpassen, werden wir einen historischen Schlag der Dimensionsreduzierung erleiden.“
In Zukunft müssen wir an folgenden Bereichen arbeiten:
* Doktorgrad:Daten sind ein unvermeidlicher Trend der Zukunft und die interdisziplinäre Zusammenarbeit (Verbindung von Medizin und Ingenieurwesen) ist eine notwendige Voraussetzung für die Durchführung innovativer Forschung mithilfe von Daten.Die Förderung amphibischer Talente im Bereich „Medizin + Daten“ hat höchste Priorität.Ärzte müssen bestimmte KI-Kenntnisse (wie Modellbewertung und Dateninterpretation) beherrschen, um besser mit Algorithmenentwicklern und Datenwissenschaftlern zusammenarbeiten zu können und so die Anwendungseffekte von KI im Gesundheitswesen zu verbessern.
* Algorithmusebene:Datenbasierte Modelle sind heute mit hohen Trainingskosten konfrontiert. Wir hoffen, in Zukunft leichtgewichtige Modelle entwickeln zu können, die besser für medizinische Szenarien geeignet sind.Senken Sie die Rechenleistungsschwelle und verbessern Sie die Interpretierbarkeit und Vertrauenswürdigkeit der klinischen Anwendung des Algorithmus.Insbesondere wird dadurch die Akzeptanz von KI bei Ärzten und Patienten erhöht und KI in die medizinische Versorgung integriert.
* Krankenhausebene:Wenn Ihnen die Forschungsideen fehlen und Ihnen die Innovationskraft fehlt, können Sie genauso gut mit Daten beginnen und die neuesten Methoden der Informationswissenschaft nutzen. Krankenhäuser sollten dies daher fördern und tatkräftig unterstützen. Datenräume für die wissenschaftliche Forschung sollten mit der entsprechenden Rechen-, Speicher-, Netzwerk-, Sicherheits- und anderen Infrastrukturen ausgestattet sein, um wichtige Dienste für medizinische Innovationen auf Datenebene bereitzustellen.
Obwohl das große Modell kein Allheilmittel ist, verändert das dahinterstehende Datendenken das Wesen der Medizin. Wenn wir wirklich lernen, mit Daten Geschichten zu erzählen und mit Algorithmen Antworten zu finden, können wir „Datenintelligenz + medizinische Essenz“ tiefgreifend integrieren, um die Initiative bei medizinischen Innovationen zu ergreifen und intelligente Medizin so zu gestalten, dass sie den Patienten wirklich dient und der Gesellschaft etwas zurückgibt.
Über Professor Li Dong
Professor Li Dong, MD, ist ein international anerkannter Experte für medizinische Datenwissenschaft. Er ist Direktor des Medical Data Science Center des Beijing Tsinghua Chang Gung Hospital der Tsinghua-Universität und angesehener Professor für Bioingenieurwesen an der Tsinghua-Universität. Professor Li Dong war der erste chinesische Direktor des Clinical Research Center am Harbor Medical Center der University of California, Los Angeles, und wurde als angesehener Professor an das West China Hospital der Sichuan-Universität berufen.

Professor Li Dong hat in den letzten fünf Jahren über 100 SCI-Artikel in führenden internationalen Fachzeitschriften veröffentlicht, die fast 4.000 Mal zitiert wurden. Darüber hinaus hat er über 220 Abstracts wissenschaftlicher Konferenzen veröffentlicht. Darüber hinaus wurde er zu über 40 wissenschaftlichen Vorträgen eingeladen, war an der Erstellung von vier wissenschaftlichen Monographien beteiligt und besitzt zwei Erfindungspatente.
Seine Forschung umfasst ein breites Spektrum, darunter klinisches Forschungsdesign, Messung und Auswertung, Modellanalyse, medizinisches Data Mining und die Anwendung künstlicher Intelligenz in der Medizin. Er verfügt über umfangreiche Erfahrung in der Leitung klinischer Forschungsteams zur Durchführung von medizinischem Big Data Mining und der Entwicklung intelligenter medizinischer Entscheidungsanalysesysteme und ist eine anerkannte Autorität auf diesem Gebiet.








