Command Palette
Search for a command to run...
Die Hong Kong University of Science and Technology Und Andere Haben Das Inkrementelle Wettervorhersagemodell VA-MoE Vorgeschlagen, Das Die Parameter Um 75% Vereinfacht Hat Und Dennoch Eine SOTA-Leistung erreicht.

Die Wettervorhersage, ein zentraler Bereich, der gesellschaftliche Abläufe und Entscheidungen zur Katastrophenprävention beeinflusst, steht aufgrund des komplexen und sich ständig verändernden atmosphärischen Systems seit jeher vor enormen Herausforderungen. Jede Verbesserung der Vorhersagemöglichkeiten hat tiefgreifende Auswirkungen auf die menschliche Produktion und das Leben. Die numerische Wettervorhersage (NWP) ist seit langem der gängige Ansatz in diesem Bereich. Basierend auf den Gleichungen der Atmosphärendynamik simuliert sie die Entwicklung wichtiger Variablen wie Temperatur, Luftdruck und Windgeschwindigkeit durch die Lösung partieller Differentialgleichungen und ermöglicht so die numerische Ableitung von Wettersystemen.
In den letzten Jahren hat Deep Learning mit dem Durchbruch der künstlichen Intelligenztechnologie und seiner leistungsstarken Fähigkeit zur räumlich-zeitlichen Mustererkennung großes Potenzial in der meteorologischen Modellierung gezeigt.Dies hat zu dem aufstrebenden interdisziplinären Feld „Künstliche Intelligenz für das Wetter (AI4Weather)“ geführt.Jedoch,Die meisten bestehenden KI-Wettermodelle basieren auf der idealen Annahme, dass alle meteorologischen Variablen während des Trainings und der Vorhersage gleichzeitig erfasst werden können. Dies steht im Widerspruch zur Realität tatsächlicher Beobachtungen, bei denen die Datenquellen vielfältig sind und die Häufigkeit der Datenerfassung variiert.Beispielsweise wird die Temperatur in großen Höhen von Satelliten oder Radiosonden gemessen, deren Aktualisierung langsam erfolgt. Niederschlag und Windgeschwindigkeit an der Erdoberfläche werden hingegen in Echtzeit von dicht besiedelten Stationen überwacht. Diese Datenasynchronität erfordert eine vollständige Neuschulung des Modells, wenn neue Variablen eingeführt werden, was zu extrem hohen Rechenkosten führt.
Um dieser Herausforderung zu begegnen,Forschungsteams der Hong Kong University of Science and Technology, der Zhejiang University und anderer Institutionen haben ein neues Paradigma für die „Incremental Weather Forecasting (IWF)“ entwickelt und die „Variable Adaptive Mixture of Experts (VA-MoE)“ eingeführt.Das Modell nutzt phasenweises Training und Mechanismen zur Einbettung variabler Indizes, um verschiedene Expertenmodule auf bestimmte Arten meteorologischer Variablen zu konzentrieren. Wenn neue Variablen oder Stationen hinzugefügt werden, kann das Modell ohne vollständiges erneutes Training erweitert werden, wodurch der Rechenaufwand erheblich reduziert und gleichzeitig die Genauigkeit gewährleistet wird.
Die entsprechenden Forschungsergebnisse mit dem Titel „VA-MoE: Variables-Adaptive Mixture of Experts for Incremental Weather Forecasting“ wurden von der ICCV25, der wichtigsten internationalen Konferenz im Bereich Computer Vision, angenommen.
Forschungshighlights:
* Die erste systematische Erforschung eines neuen Paradigmas für inkrementelles Lernen in der Wettervorhersage, das einen Maßstab für die quantifizierbare Bewertung der Skalierbarkeit und Generalisierungsfähigkeit von Modellen schafft
* Schlagen Sie VA-MoE vor, das erste Framework, das speziell für die inkrementelle Atmosphärenmodellierung entwickelt wurde und das Expertenspezialisierung durch kontextuelle Variablenaktivierung erreicht, die durch die Einbettung variabler Indizes gesteuert wird
* Groß angelegte Experimente auf der Grundlage des ERA5-Datensatzes zeigen, dass VA-MoE ähnliche Modelle bei der Vorhersage von Höhenvariablen deutlich übertrifft, wenn die Datengröße halbiert und die Anzahl der Parameter auf 25% reduziert wird.

Papieradresse:
https://arxiv.org/abs/2412.02503
Folgen Sie dem offiziellen Konto und antworten Sie mit „VA-MoE“, um das vollständige PDF zu erhalten
Weitere Artikel zu den Grenzen der KI:
Aufteilung der Höhen- und Bodenvariablen im ERA5-Datensatz
Diese Studie verwendet den gängigen atmosphärischen Reanalyse-Datensatz ERA5 des Europäischen Zentrums für mittelfristige Wettervorhersage (ECMWF) als experimentelle Grundlage und umfasst kontinuierliche meteorologische Beobachtungsdaten von 1979 bis heute. Herkömmliche Experimente verwenden eine räumliche Auflösung von 0,25° (entsprechend einer Rastergröße von 721×1440). Nur im Ablationsexperiment wird zur Kontrolle des Rechenaufwands eine Version mit 1,5° Auflösung (Rastergröße 128×256) verwendet, um ein Gleichgewicht zwischen Datenanpassungsfähigkeit und Recheneffizienz in verschiedenen experimentellen Szenarien zu gewährleisten.
Aus der zeitlichen Dimension lässt sich der Datensatz eindeutig verschiedenen Phasen des Experiments zuordnen:
* In der ersten Trainingsphase werden Daten aus 40 Jahren von 1979 bis 2020 verwendet, um die Grundlage für die meteorologische Wissensreserve des Modells zu legen.
* Die inkrementelle Trainingsphase verwendet 20 Jahre Daten von 2000 bis 2020, um sich an die Anforderungen der Parameteroptimierung nach der Einführung neuer Variablen anzupassen.
* Während der Testphase wurden Daten zu meteorologischen Variablen für das gesamte Jahr 2021 ausgewählt, um mithilfe unabhängiger Daten die Generalisierungsfähigkeit des Modells an unbekannten Stichproben zu überprüfen und so die Auswirkungen von Datenlecks auf die Glaubwürdigkeit der Ergebnisse zu vermeiden.
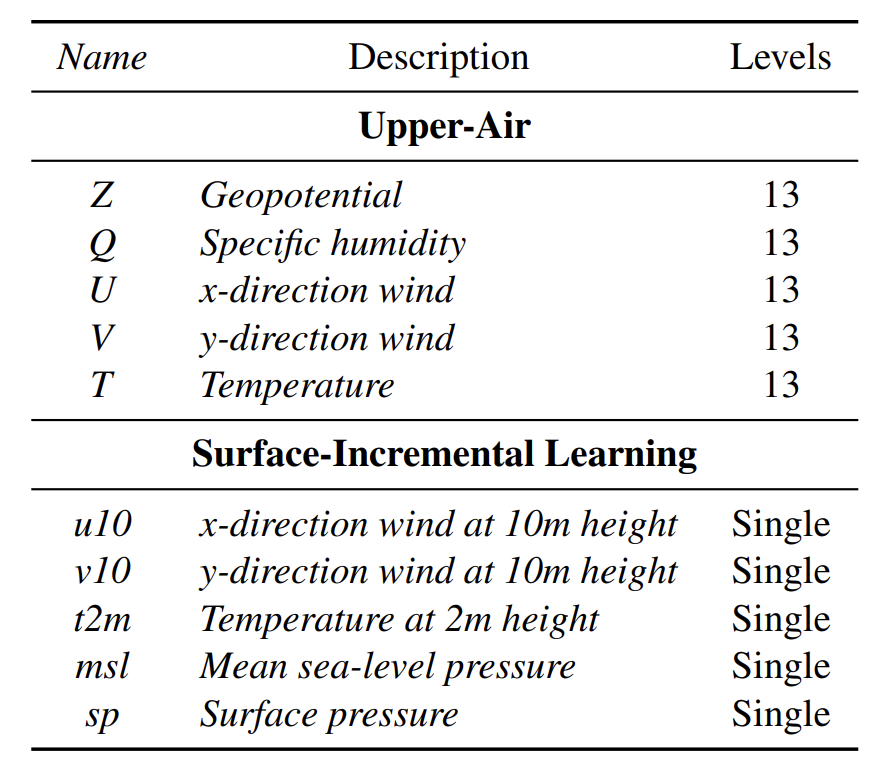
* In Bezug auf die Variablenkonfiguration umfasst das Experiment, wie in der folgenden Abbildung dargestellt, 5 Variablen in der oberen Luftschicht und 5 Oberflächenvariablen:
* Höhenvariablen: Diese umfassen fünf Typen: Z (Geopotentialhöhe), Q (Spezifische Luftfeuchtigkeit), U (Ost-West-Windgeschwindigkeit), V (Nord-Süd-Windgeschwindigkeit) und T (Temperatur). Jeder Typ ist in 13 verschiedenen Druckschichten definiert und wird hauptsächlich in der anfänglichen Modelltrainingsphase verwendet, um grundlegende Fähigkeiten zur Modellierung der Atmosphärendynamik aufzubauen.
* Bodenvariablen: einschließlich 2-Meter-Temperatur T2M, 10-Meter-Ostwindgeschwindigkeit U10, 10-Meter-Südwindgeschwindigkeit V10, mittlerer Meeresspiegeldruck MSL, Oberflächendruck SP usw. werden als inkrementelle Variablen in der zweiten Phase des Modells (inkrementelle Trainingsphase) eingeführt, um das Szenario der dynamischen Erweiterung von Variablen in tatsächlichen Beobachtungen zu simulieren.
VA-MoE: Variable adaptive Wettervorhersagemodellarchitektur für inkrementelles Lernen
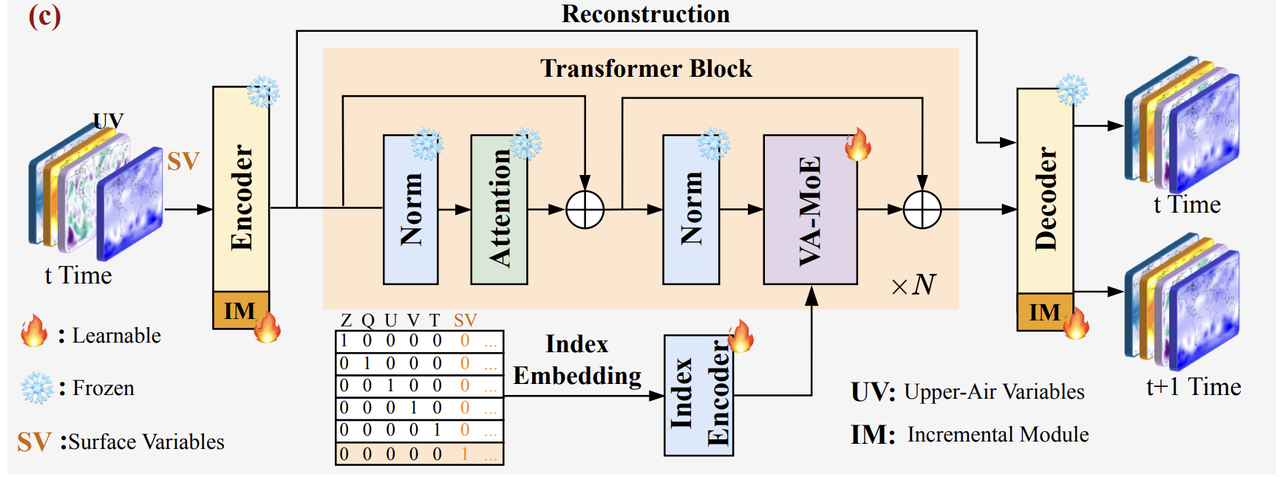
Die Kernbetriebslogik von VA-MoE dreht sich um das „zweistufige Trainingsparadigma“.Wie in der folgenden Abbildung dargestellt, simuliert es das Szenario der „schrittweisen Datenerweiterung“ in tatsächlichen Beobachtungen vollständig: Die erste Phase ist die „Anfangsphase“, in der zum Trainieren des Modells nur Variablen in großer Höhe verwendet werden, sodass das Modell zunächst die zentralen dynamischen Gesetze der oberen Atmosphäre erfassen kann. Die zweite Phase ist die „inkrementelle Phase“, in der bodenbasierte Variablen hinzugefügt werden, während die trainierten Parameter der ersten Phase eingefroren werden. Nur die für die neuen Variablen neu hinzugefügten Module werden trainiert, wodurch letztendlich ein vollständiges Modell entsteht.

Aus Sicht der Architektur, wie in der folgenden Abbildung dargestellt,VA-MoE verwendet Transformer als Kern-Backbone, hat jedoch wichtige Optimierungen für die mehrskaligen und stark korrelierten Eigenschaften meteorologischer Daten vorgenommen.Wenn das Modell Eingabedaten verarbeitet, durchlaufen die vom Encoder extrahierten Eingabemerkmale zunächst eine Normalisierungsschicht und eine Self-Attention-Schicht. Die Ausgabe der Self-Attention-Schicht wird mit einer Residualverbindung verknüpft. Anschließend durchläuft sie eine weitere Normalisierungsschicht, bevor sie zur variablen adaptiven Berechnung in das VA-MoE-Kernmodul eingegeben wird. Um Wissenslücken durch „verschwindende Gradienten“ während des Deep-Network-Trainings zu vermeiden, integriert das Framework außerdem einen „Restverbindungs“-Mechanismus: Nach jedem Berechnungsschritt bleiben einige ursprüngliche Merkmale erhalten. Dadurch wird sichergestellt, dass Netzwerke auf hoher Ebene weiterhin effektiv grundlegende meteorologische Informationen übernehmen können, die von niedrigeren Schichten extrahiert wurden (wie z. B. den Einfluss des Geländes auf die bodennahe Windgeschwindigkeit). Dies verbessert die Modellierungsstabilität langfristiger meteorologischer Reihen erheblich.
Auf der Trainingsoptimierungsebene verwendet VA-MoE einen „Multi-Task Joint Loss“-Mechanismus, um Vorhersagegenauigkeit und physikalische Konsistenz auszugleichen.Dieser Mechanismus besteht aus zwei Kernkomponenten: einem dynamischen Vorhersageverlust, der die Gewichte anhand der physikalischen Eigenschaften der Variablen optimiert. Schnell veränderliche Variablen wie Temperatur und Windgeschwindigkeit erhalten höhere Gewichte, um flüchtige Änderungen besser erfassen zu können. Bei langsam veränderlichen Variablen wie der geopotentiellen Höhe wird eine schrittweise Gewichtungsanpassung vorgenommen, um die langfristige Prognosestabilität zu gewährleisten und so den Verlust wichtiger dynamischer Merkmale zu vermeiden, der oft mit traditionellen Modellen einhergeht. Darüber hinaus führt das Modell einen Rekonstruktionsverlust als Zusatzaufgabe ein. Durch eine Encoder-Decoder-Struktur muss das Modell zunächst das ursprüngliche meteorologische Feld präzise wiederherstellen und dabei wesentliche Eigenschaften wie die atmosphärische Energie- und Massenerhaltung erlernen, bevor es die Vorhersageaufgabe ausführt.
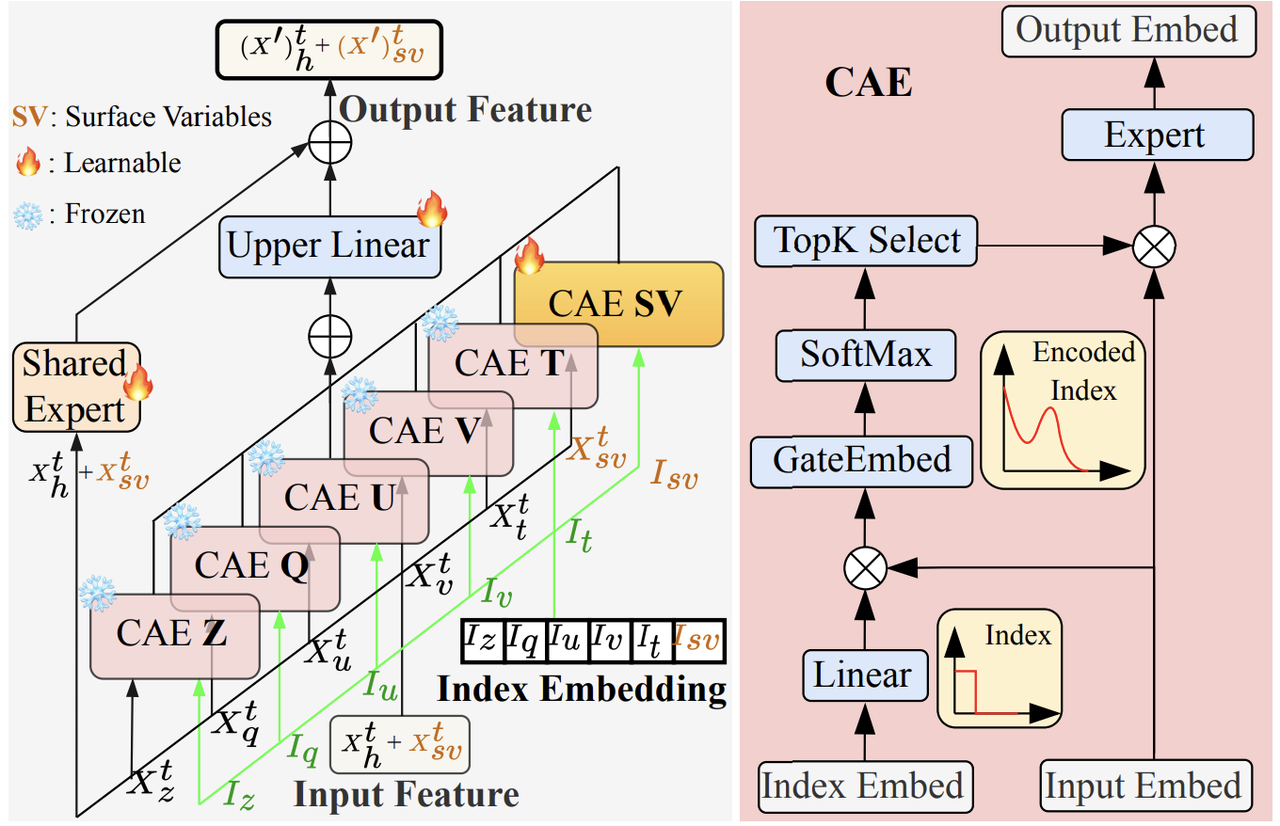
Auf dieser Grundlage, wie in der folgenden Abbildung dargestellt,Das Modell baut ein Expertensystem aus „Spezialisierung + Zusammenarbeit“ auf.Für die fünf Kernvariablen der Trainingsphase (wie Z500, Temperatur und Windgeschwindigkeit) werden für jede Variable unabhängige „Channel-Adaptive Experts (CAEs)“ konfiguriert. Beispielsweise konzentriert sich das Temperatur-CAE ausschließlich auf die räumlich-zeitliche Entwicklung der Temperatur und kombiniert den „Identity Tag“ der Temperatur mit der Überprüfung wichtiger Merkmale (wie der täglichen Temperaturdifferenz und plötzlicher Temperaturänderungen während eines Frontdurchgangs). Dadurch wird die Genauigkeit von Prognosen für einzelne Variablen durch spezialisierte Modellierung verbessert. Darüber hinaus wird ein „Shared Expert“-Modul eingerichtet, um die lokalen Informationsausgaben aller CAEs zu integrieren und systemweite Korrelationen zwischen mehreren Variablen zu erfassen (wie die Kettenreaktion von steigender Temperatur → sinkendem Luftdruck → steigender Windgeschwindigkeit). Dadurch wird vermieden, dass man durch Überspezialisierung den Wald vor lauter Bäumen nicht sieht, und sichergestellt, dass das Modell das dynamische Verhalten des gesamten atmosphärischen Systems wiederherstellen kann.
VA-MoE-Leistungsüberprüfung: Genauigkeit vergleichbar mit Mainstream-Modellen, mit erheblichen inkrementellen Lernvorteilen
Um die tatsächliche Wirksamkeit von VA-MoE bei der Wettervorhersage systematisch zu bewerten, hat das Forschungsteam ein komplettes experimentelles System auf der Grundlage realer meteorologischer Daten erstellt und sich dabei auf die drei Dimensionen „Genauigkeit, Effizienz und Skalierbarkeit“ konzentriert.
Der Kern des Experiments besteht darin, VA-MoE mit neun gängigen meteorologischen KI-Modellen (darunter Pangu-Weather, GraphCast, ClimaX usw.) zu vergleichen, darunter geopotentielle Höhe Z500 bei 500 hPa, östliche Windgeschwindigkeit U10 bei 10 Metern, Temperatur T850 bei 850 hPa, Temperatur T2M bei 2 Metern usw. Der Schwerpunkt liegt auf der Bewertung ihrer Prognoseleistung innerhalb von 5 Tagen. Der Hauptunterschied liegt in der Trainingslogik: Die verglichenen Modelle verwenden meist die traditionelle Methode des „einmaligen gemeinsamen Trainings von Höhen- und Bodenvariablen“.VA-MoE verfolgt eine zweistufige inkrementelle Strategie „zuerst in großer Höhe, dann am Boden“, was seine Vorteile bei der variablen Expansion hervorhebt.
Was die Prognosegenauigkeit betrifft,Wie die Abbildung unten zeigt, schneidet VA-MoE sowohl bei der Boden- als auch bei der Höhenluftvorhersage gut ab. Bei wichtigen Bodenvariablen wie T2M und U10 ist die Vorhersagegenauigkeit von VA-MoE mit der von Stormer und GraphCast vergleichbar und übertrifft Modelle wie ClimaX und FourCastNet deutlich. Dabei bleibt die Stabilität sowohl bei kurz- als auch bei langfristigen Vorhersagen erhalten. Bei der Ausweitung auf Variablen wie V10 und den Luftdruck auf Meereshöhe (MSL) wird der Vorteil von VA-MoE noch deutlicher: Nur bei T2M fällt VA-MoE knapp hinter GraphCast zurück, liegt aber auf Augenhöhe mit Mainstream-Modellen wie FengWu und FuXi.
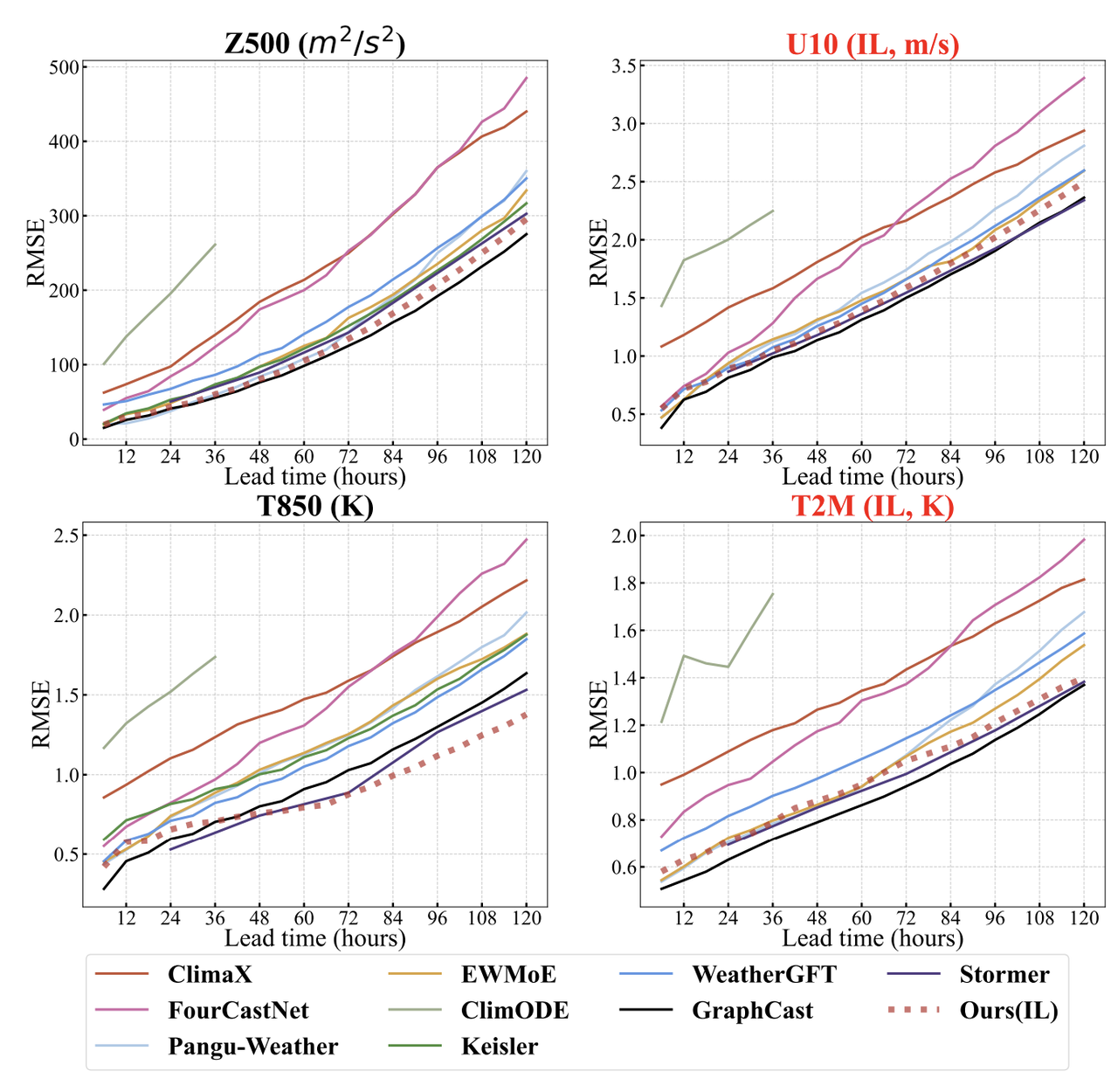
In Bezug auf die TrainingseffizienzVA-MoE, das im inkrementellen Modus auf der Grundlage von 40 Jahren Daten trainiert wird, kann eine ähnliche Genauigkeit mit nur der Hälfte der Standardanzahl von Iterationen erreichen. Selbst wenn die Daten auf 20 Jahre reduziert und die Anzahl der Iterationen auf ein Viertel verringert wird, kann das Modell immer noch eine für Unternehmen nutzbare Genauigkeit beibehalten, wodurch die durch die Variablenerweiterung verursachten Rechenkosten erheblich reduziert werden.
Die Vorhersage der Höhenvariablen bestätigt den inkrementellen Vorteil von VA-MoE zusätzlich.Die Studie verglich drei Trainingsstrategien: VA-MoE, das ausschließlich auf Höhenvariablen trainiert wurde, VA-MoE, das schrittweise Bodenvariablen (IL) einbezog, und ein traditionelles gemeinsames Trainingsmodell. Die Ergebnisse zeigten, dass VA-MoE, das ausschließlich auf Höhenvariablen trainiert wurde, eine mit GraphCast vergleichbare Genauigkeit erreichte und IFS und Pangu-Weather übertraf. Darüber hinaus zeigte das inkrementelle VA-MoE keine Verschlechterung seiner Vorhersageleistung für Höhenvariablen nach der Einbeziehung von Bodenvariablen und verbesserte seine Genauigkeit sogar bei Langzeitprognosen für eine geopotentielle Höhe von 500 hPa (Z500). Dies demonstriert seine Fähigkeit, „Neues zu lernen, ohne Altes zu verlieren“.
Um die Wirksamkeit der Modellstruktur weiter zu validieren, führte das Team Ablationsexperimente durch, bei denen VA-MoE mit dem Visual Transformer (ViT) und seiner expertenbasierten Erweiterung (ViT+MoE) verglichen wurde. Obwohl ViT+MoE fast doppelt so viele Parameter wie VA-MoE aufweist, erreichte VA-MoE in den 6-Stunden-, 3-Tage- und 5-Tage-Prognoseintervallen dennoch eine deutlich höhere Genauigkeit. Dies verdeutlicht die Vorteile des „kanaladaptiven Experten“-Mechanismus auch in parameterbeschränkten Szenarien und macht ihn besonders geeignet für Geschäftsumgebungen mit dynamisch wachsenden Variablen.
KI treibt Innovationen in der Wettervorhersage voran und erweitert die Grenzen traditioneller numerischer Modelle
Im Sinne des Schwerpunkts des VA-MoE auf „effiziente Anpassung an mehrere Variablen, Reduzierung der Aktualisierungskosten und Verbesserung der Prognosegenauigkeit“ arbeiten die akademischen und geschäftlichen Gemeinschaften weltweit zusammen, um kontinuierlich tiefgreifende Innovationen im Paradigma der meteorologischen Modellierung voranzutreiben.
Durch die Konzentration auf zentrale technologische Engpässe hat die akademische Gemeinschaft wichtige Durchbrüche bei der Innovation der Modellarchitektur und der Effizienz der Datennutzung erzielt.Aardvark Weather, gemeinsam entwickelt von der University of Cambridge, dem Alan Turing Institute und Microsoft Research, ist das erste End-to-End-KI-System, das völlig frei von traditionellen numerischen Frameworks ist.Es wurde eine direkte Abbildung von Beobachtungsdaten aus mehreren Quellen auf hochauflösende Prognosen erreicht, wodurch nicht nur die Abhängigkeit von Supercomputer-Ressourcen erheblich reduziert, sondern auch der Entwicklungszyklus spezieller Modelle von mehreren Monaten auf mehrere Wochen verkürzt und die wirtschaftliche Machbarkeit des rein datengesteuerten Pfads vollständig bestätigt wurde.
Titel des Papiers:End-to-End-datengesteuerte Wettervorhersage
Papieradresse:https://www.nature.com/articles/s41586-025-08897-0
Das FuXi-Weather-System wurde von der Fudan-Universität in Zusammenarbeit mit dem Shanghai Institute of Scientific and Intelligent Technology, der China Meteorological Administration und anderen Institutionen entwickelt.Es hat Pionierarbeit bei der Realisierung einer vollständigen End-to-End-Modellierung geleistet, von der Satellitenhelligkeitstemperatur bis hin zu den Prognoseergebnissen, und ist damit nicht mehr vom Ausgangsfeld traditioneller numerischer Modelle abhängig. Selbst in spärlich beobachteten Gebieten wie Afrika übertrifft seine Prognosegenauigkeit immer noch das HRES-System des Europäischen Zentrums für mittelfristige Wettervorhersage.
Titel des Papiers:Ein maschinelles Lernsystem zur Datenprognose für das globale Wetter
Papieradresse:https://www.nature.com/articles/s41467-025-62024-1
Die Geschäftswelt konzentriert sich auf die Implementierung von Technologien und die Anpassung an Szenarien und beweist dabei herausragende technische Fähigkeiten.GraphCast, das von Google DeepMind eingeführt wurde, basiert auf der fortschrittlichen Graph-Neural-Network-Architektur.Nach dem Training mit ERA5-Reanalysedaten kann es globale Wettervorhersagen für die nächsten zehn Tage innerhalb einer Minute erstellen. Seine Indikatorgenauigkeit übersteigt 90% bei 1.380 Testvariablen und ist damit besser als die des HRES-Systems. Es kann außerdem extreme Wettersignale wie Wirbelstürme und atmosphärische Flüsse drei Tage im Voraus effektiv erkennen. Seine Open-Source-Strategie fördert die Verbreitung der Technologie zusätzlich.
Titel des Papiers:UT-GraphCast Hindcast-Datensatz: Ein globales KI-Prognosearchiv der UT Austin für Wetter- und Klimaanwendungen
Papieradresse:https://arxiv.org/abs/2506.17453
Das von Microsoft entwickelte große Aurora-Modell verfolgt eine zweistufige Strategie aus „Vortraining und Feinabstimmung“.Mit einer flexiblen Architektur mit 1,3 Milliarden Parametern erreicht es eine umfassende Genauigkeit von 89% bei verschiedenen Aufgaben wie Wetter-, Luftqualitäts- und Wellenvorhersage. Die Rechengeschwindigkeit ist 5.000-mal schneller als bei herkömmlichen numerischen Modellen und kann durch leichte Feinabstimmung schnell an verschiedene Geschäftsszenarien angepasst werden.
Titel des Papiers:Ein Grundlagenmodell für das Erdsystem
Papieradresse:https://www.nature.com/articles/s41586-025-09005-y
Mit Blick auf die Zukunft wird erwartet, dass meteorologische KI mit der kontinuierlichen Anreicherung von Beobachtungsdaten aus mehreren Quellen und der kontinuierlichen Weiterentwicklung grundlegender Modelle eine größere Rolle bei der Warnung vor extremen Wetterbedingungen, der Bewertung des Klimawandels und professionellen Branchendienstleistungen spielen wird. Ihre Rolle wird sich schrittweise von der „unterstützenden Vorhersage“ zur „treibenden Entscheidungsfindung“ wandeln und der menschlichen Gesellschaft intelligentere technische Unterstützung bei der Bewältigung von Wetter- und Klimaherausforderungen bieten.








