Command Palette
Search for a command to run...
Orpheus TTS Verabschiedet Sich Vom Mechanischen Gefühl, Echtzeitgespräche Sind so Natürlich Wie Freunde; OpenCodeReasoning – Open Source Für Massive Datenmengen, Die Eine Neue Ebene Der Programmierlogik Erschließen

Bei Text-to-Speech-Modellen wurden in den letzten Jahren erhebliche Fortschritte erzielt, doch in der praktischen Anwendung weisen bestehende Modelle noch immer zahlreiche Einschränkungen auf. Die meisten Modelle können Sprache nur mit einer einzigen Klangfarbe erzeugen und sind nicht in der Lage, Sprache mit starken Emotionen zu erzeugen. Um diese Herausforderung zu bewältigen, hat Canopy Labs das Text-to-Speech-Modell Orpheus-TTS als Open Source veröffentlicht.
Orpheus-TTS kann eine natürliche, emotionale und dem menschlichen Sprachniveau nahekommende Sprache erzeugen.Es verfügt über Zero-Sample-Sprachklonfunktionen und kann bestimmte Stimmen ohne vorheriges Training imitieren.Benutzer können Tags verwenden, um den emotionalen Ausdruck der Stimme zu steuern und den Realismus der Stimme zu verbessern. Das Modell weist eine Latenz von nur etwa 200 Millisekunden auf und unterstützt Benutzer bei der Implementierung von Echtzeitanwendungen.
derzeit,HyperAI ist jetzt online「Orpheus TTS: Ein mehrsprachiges Text-to-Speech-Modell",Kommen Sie und probieren Sie es aus~
Online-Nutzung:https://go.hyper.ai/FGexv
Vom 26. bis 29. Mai gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorials: 12
* Community-Artikelauswahl: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juni: 3
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
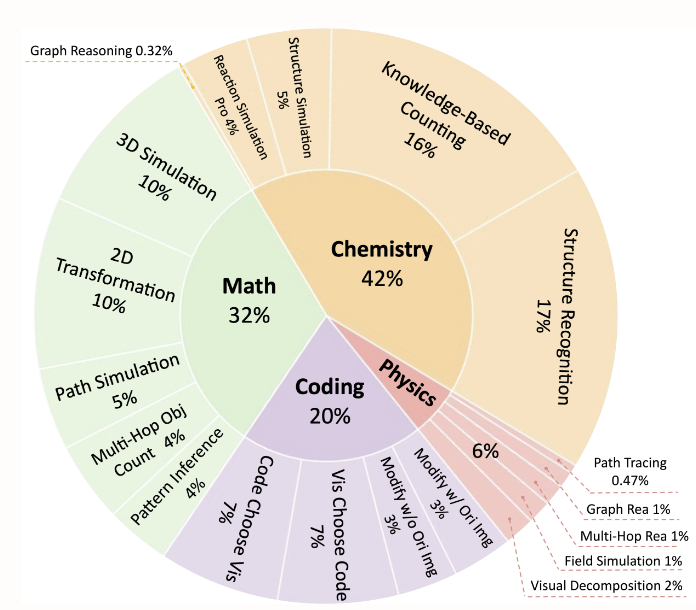
1. EMMA-Benchmark-Datensatz für multimodales Denken
Der Datensatz konzentriert sich auf multimodale Denkaufgaben in den Bereichen organische Chemie (42%), Mathematik (32%), Physik (6%) und Programmierung (20%). Es enthält 2.788 Fragen, von denen 1.796 neu erstellte Stichproben sind. Es unterstützt eine feingranulare Aufgabenteilung und zielt darauf ab, die gemeinsame Verstehensfähigkeit von Bildern und Texten zu fördern. Zu den Datenaufgabentypen gehören die Simulation chemischer Reaktionen, mathematisches Grafik-Argumentieren, physikalische Pfadverfolgung, Programmiervisualisierung usw.
Direkte Verwendung:https://go.hyper.ai/HtL1N
2. Gesichtsausdrücke Gesichtsausdruck YOLO-Format-Erkennungsdatensatz
Dieser Datensatz ist ein Datensatz im YOLO-Format zur Emotionserkennung, der für das Training und die Auswertung von Zielerkennungs- und Klassifizierungsmodellen entwickelt wurde. Der Datensatz enthält insgesamt etwa 70.000 Bilder und deckt 9 Kategorien von Gesichtsausdrücken ab, wobei sowohl grundlegende als auch komplexe Emotionstypen berücksichtigt werden. Es eignet sich für Anwendungsszenarien wie Emotionserkennung in der Computervision, Mensch-Computer-Interaktion, Analyse der psychischen Gesundheit und intelligente Überwachung.
Direkte Verwendung:https://go.hyper.ai/K6iIH

3. GeneralThought-430K-Datensatz zum groß angelegten Denken
Der Datensatz enthält 430.000 Beispiele und deckt Probleme aus den Bereichen Mathematik, Code, Physik, Chemie, Naturwissenschaften, Geistes- und Sozialwissenschaften, Ingenieurtechnik usw. ab, darunter Fragen aus mehreren Argumentationsmodellen, Referenzantworten, Argumentationsverläufe, endgültige Antworten und andere Metadaten.
Direkte Verwendung:https://go.hyper.ai/xdSzd
4. S1k-1.1 Datensatz zum mathematischen Denken
Dieser Datensatz ist ein Datensatz zum mathematischen Problemdenken und enthält 1.000 Beispiele. Der Schwerpunkt liegt auf mathematischen Problemen und Denkpfaden und deckt mehrere mathematische Bereiche wie Algebra, Geometrie, Wahrscheinlichkeit usw. ab. Jedes Beispiel enthält eine Problembeschreibung, Schritte zur Problemlösung, Antworten und Denkpfade, die von DeepSeek r1 generiert wurden.
Direkte Verwendung:https://go.hyper.ai/MtvcV
5. HPA Human Protein Atlas-Datensatz
Dieser Datensatz besteht aus Daten der Human Protein Atlas (HPA)-Datenbank, die eine große Anzahl hochauflösender konfokaler Mikroskopiebilder enthält, die die räumliche Verteilung von Tausenden menschlicher Proteine in verschiedenen Organellen abdecken. Es handelt sich um eine wichtige öffentliche Ressource für die Erforschung der subzellulären Proteinlokalisierung. Faire Bewertung der Modelle.
Direkte Verwendung:https://go.hyper.ai/Dhuwt
6. ZeroSearch-Frage-Antwort-Datensatz
Der Datensatz enthält etwa 170.000 Beispiele und deckt mehrere Bereiche ab, beispielsweise wissenschaftliche Erkenntnisse, historische Ereignisse, Film- und Fernsehunterhaltung, Geographie und Geisteswissenschaften. Es deckt auch Sachfragen, Definitionsfragen, Richtig-Falsch-Fragen usw. ab und eignet sich zum Trainieren kleiner und mittelgroßer Frage-Antwort-Modelle. Ziel ist es, durch sorgfältig gestaltete Frage-Antwort-Paare die Fähigkeiten des Modells zum gesunden Menschenverstand, zum Faktengedächtnis und zur logischen Schlussfolgerung zu bewerten und standardisierte Trainings- und Testressourcen für den Bereich der natürlichen Sprachverarbeitung bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/OkvBx
7. SocialMaze-Benchmark-Datensatz für logisches Denken
Bei diesem Datensatz handelt es sich um einen Benchmark-Datensatz für soziales Denken, der sich auf Aufgaben zum Denken über verborgene Rollen in Szenarien mit der Interaktion mehrerer Agenten konzentriert. Ziel ist es, die Fähigkeiten großer Sprachmodelle (LLMs) zum logischen Denken, zur Täuschungserkennung und zum mehrstufigen Dialogverständnis in komplexen sozialen Umgebungen zu bewerten und eine standardisierte Testplattform für die Untersuchung der Fähigkeiten von LLMs zum sozialen Denken bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/Cch64
8. OpenCodeReasoning-Programmier-Reasoning-Datensatz
Dieser Datensatz soll qualitativ hochwertige Trainingsdaten für das Programmieren von logischen Denkfähigkeiten für große Sprachmodelle (LLMs) bereitstellen und die Verbesserung der Codegenerierung und der logischen Denkfähigkeiten fördern. Der Datensatz enthält 735.255 Beispiele, die 28.319 einzigartige Programmierprobleme abdecken, und ist einer der größten derzeit verfügbaren Datensätze zum Thema logisches Denken.
Direkte Verwendung:https://go.hyper.ai/ofjBJ
9. MLDR-Datensatz zur mehrsprachigen Dokumentenabfrage
Der Datensatz umfasst 13 verschiedene Sprachen. Es handelt sich um einen mehrsprachigen Datensatz zum Abrufen langer Dokumente, der auf dem mehrsprachigen Korpus von Wikipedia, Wudao und mC4 basiert. Ziel ist es, die Forschung und Entwicklung sprachübergreifender Aufgaben zur Langtextsuche zu unterstützen.
Direkte Verwendung:https://go.hyper.ai/Le0G8
10. MP-20-PXRD Atommaterialien-Benchmark-Datensatz
Der Datensatz besteht aus Materialien, die aus der Materials Project-Datenbank entnommen wurden, mit maximal 20 Atomen in der Elementarzelle. Es enthält 45.229 Materialien, die im Verhältnis 90%, 7,5% und 2,5% für Training, Validierung und Tests verwendet werden.
Direkte Verwendung:https://go.hyper.ai/bUKbv
Ausgewählte öffentliche Tutorials
Diese Woche haben wir 4 Kategorien hochwertiger öffentlicher Tutorials zusammengefasst:
* Audiosynthese-Tutorials: 5
* Tutorials zur Bildgenerierung: 3
* Videosynthese-Tutorials: 2
* Tutorials zum mathematischen Denken: 2
Audiosynthese-Tutorial
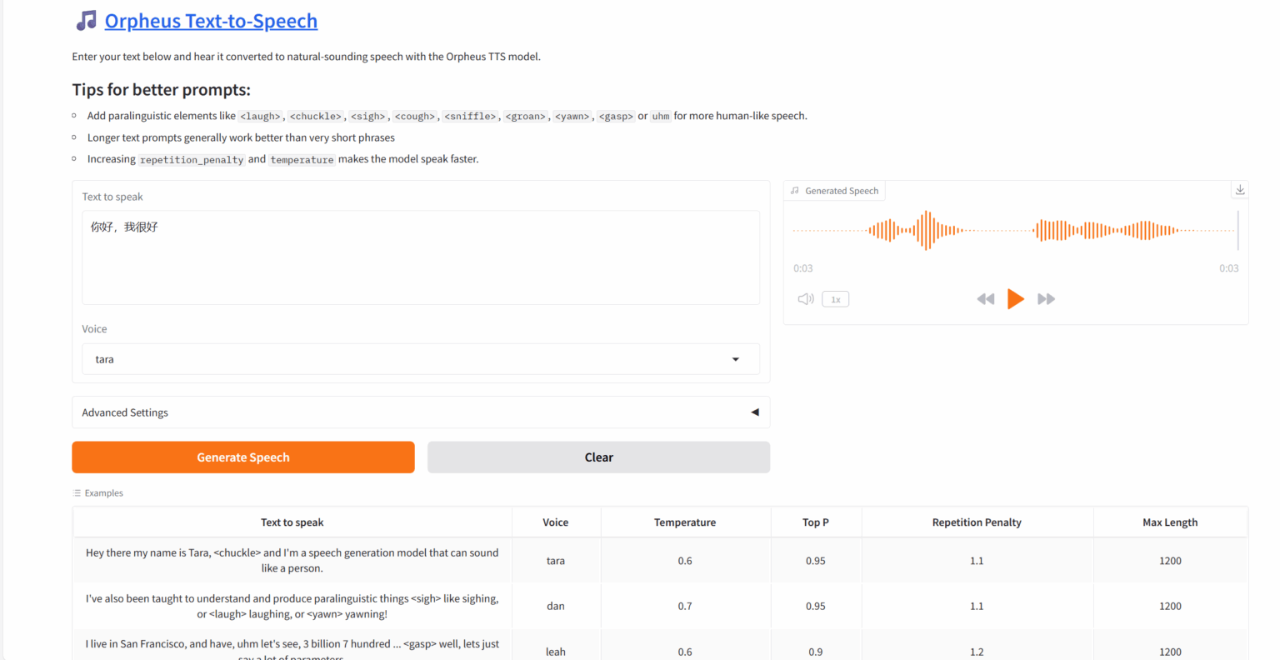
1. Orpheus TTS: Ein mehrsprachiges Text-to-Speech-Modell
Orpheus-TTS kann eine natürliche, emotionale und dem menschlichen Niveau nahekommende Sprache erzeugen, verfügt über Zero-Sample-Sprachklonfunktionen und kann bestimmte Stimmen ohne vorheriges Training imitieren. Benutzer können Tags verwenden, um den emotionalen Ausdruck der Stimme zu steuern und den Realismus der Stimme zu verbessern. Orpheus TTS hat eine geringe Latenz von etwa 200 Millisekunden und ist daher für Echtzeitanwendungen geeignet.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/FGexv
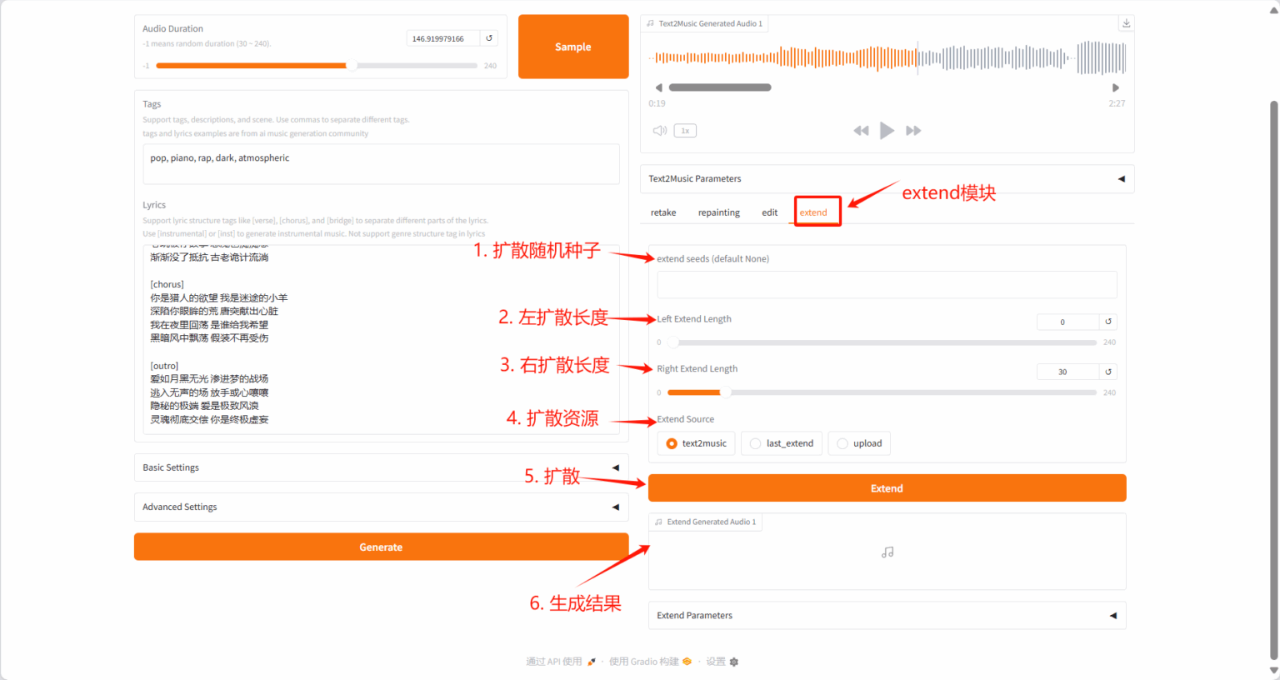
2. ACE-Step: Basismodell zur Musikgenerierung
ACE-Step-v1-3.5B synthetisiert bis zu 4 Minuten Musik in nur 20 Sekunden auf einer A100-GPU, 15-mal schneller als eine LLM-basierte Baseline, und erreicht dabei eine überlegene musikalische Kohärenz und Textausrichtung in Bezug auf melodische, harmonische und rhythmische Metriken. Darüber hinaus bewahrt das Modell feine akustische Details und ermöglicht erweiterte Steuerungsmechanismen wie Stimmenklonen, Songtextbearbeitung, Remixen und Trackgenerierung.
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/Qjxmu
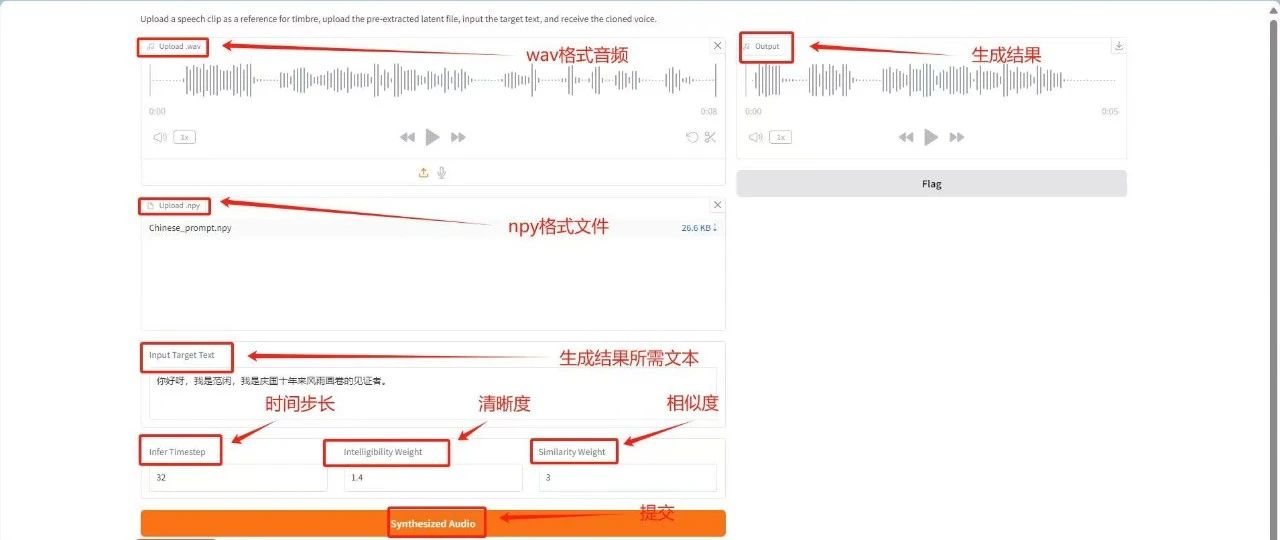
3. MegaTTS3-Bereitstellung mit nur einem Klick
MegaTTS 3 ist ein TTS-System mit einem innovativen, spärlich ausgerichteten, geführten latenten diffusen Transducer (DiT)-Algorithmus, der eine hochmoderne Zero-Shot-TTS-Sprachqualität erreicht und eine äußerst flexible Kontrolle der Akzentstärke unterstützt. Es wird hauptsächlich verwendet, um eingegebenen Text in eine hochwertige, natürliche und flüssige Sprachausgabe umzuwandeln.
In diesem Tutorial wird eine einzelne RTX 4090-Karte verwendet. Über den unten stehenden Link können Sie es mit einem Klick bereitstellen.
Online ausführen:https://go.hyper.ai/rujKs
4. Parakeet-tdt-0.6b-v2 Spracherkennung
Parakeet-tdt-0.6b-v2 basiert auf der FastConformer-Encoder-Architektur und dem TDT-Decoder und kann bis zu 24 Minuten englische Audioclips gleichzeitig effizient transkribieren. Dieses Modell konzentriert sich auf hochpräzise englische Sprachtranskriptionsaufgaben mit geringer Latenz und eignet sich für englische Sprach-zu-Text-Szenarien in Echtzeit (wie Kundendienstgespräche, Besprechungsprotokolle, Sprachassistenten usw.).
Dieses Tutorial verwendet eine einzelne RTX 4090-Rechenressource und das Modell unterstützt nur die englische Spracherkennung.
Online ausführen:https://go.hyper.ai/pWmfu
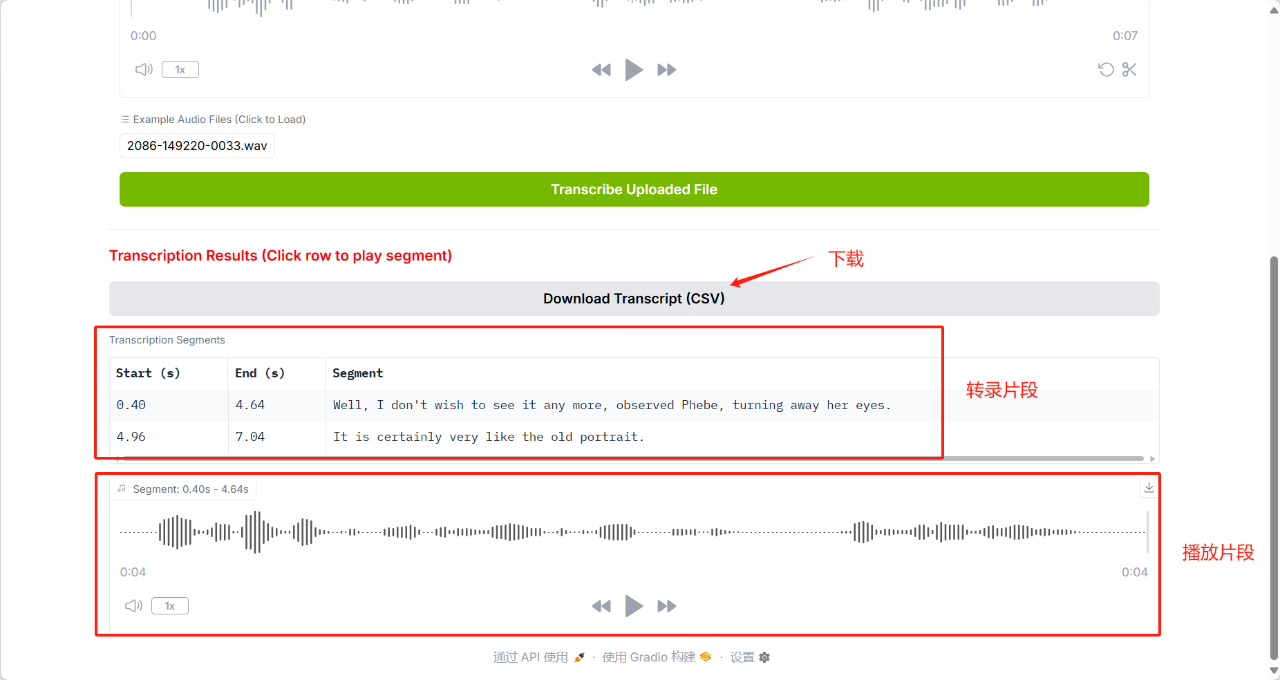
5. Dia-1.6B: Demo zur emotionalen Sprachsynthese
Dia-1.6B kann hochrealistische Gespräche direkt aus Textskripten generieren und unterstützt audiobasierte Emotions- und Tonsteuerung. Es kann auch Geräusche der nonverbalen Kommunikation wie Lachen, Husten, Räuspern usw. erzeugen, wodurch die Unterhaltung natürlicher und lebendiger wird. Dieses Projekt unterstützt auch das Hochladen eigener Audiobeispiele. Das Modell generiert auf der Grundlage der Samples ähnliche Stimmen, um ein Klonen von Stimmabdrücken ohne Samples zu erreichen.
Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte und unterstützt derzeit nur die englische Generierung.
Online ausführen:https://go.hyper.ai/5J3lp
Tutorial zur Bildgenerierung
1. KV-Edit Hintergrundkonsistenz Bildbearbeitung
KV-Edit ist eine trainingsfreie Bildbearbeitungsmethode, die die Hintergrundkonsistenz zwischen dem Originalbild und den bearbeiteten Bildern strikt aufrechterhält und bei verschiedenen Bearbeitungsaufgaben, einschließlich dem Hinzufügen, Entfernen und Ersetzen von Objekten, eine beeindruckende Leistung erzielt.
In diesem Tutorial wird eine einzelne RTX A6000-Karte verwendet. Klicken Sie auf den Link unten, um das Modell schnell zu klonen.
Online ausführen:https://go.hyper.ai/wo2xJ

2. Sana hochauflösende Bildsynthese
Sana ist ein Text-zu-Bild-Framework, das effizient Bilder mit einer Auflösung von bis zu 4096 × 4096 generieren kann. Sana kann hochauflösende, qualitativ hochwertige Bilder mit sehr hoher Geschwindigkeit synthetisieren und verfügt über leistungsstarke Funktionen zur Text-Bild-Ausrichtung.
In diesem Tutorial wird zur Demonstration das Modell Sana-1600M-1024px verwendet und die Rechenleistungsressource nutzt eine einzelne RTX 4090-Karte.
Online ausführen:https://go.hyper.ai/tiP36

3. In-Context Edit: Befehlsgesteuerte Bildgenerierung und -bearbeitung
In-Context Edit ist ein effizientes Framework für die befehlsbasierte Bildbearbeitung. Im Vergleich zu früheren Methoden verfügt ICEdit nur über 1% trainierbare Parameter (200 M) und 0,1% Trainingsdaten (50.000), zeigt eine starke Generalisierungsfähigkeit und kann verschiedene Bearbeitungsaufgaben bewältigen. Im Vergleich zu kommerziellen Modellen wie Gemini und GPT4o ist es Open Source, kostengünstiger, schneller und leistungsstärker.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Wenn Sie die offiziell genannten 9 Sekunden zur Bilderzeugung erreichen möchten, benötigen Sie eine Grafikkarte mit höherer Ausstattung. Derzeit werden nur englische Textbeschreibungen unterstützt.
Online ausführen:https://go.hyper.ai/Ytv6C

Tutorial zur Videoerstellung
1. TransPixeler: Generieren von RGBA-Videos aus Text
TransPixeler behält die Vorteile des ursprünglichen RGB-Modells bei und erreicht mit begrenzten Trainingsdaten eine starke Ausrichtung zwischen RGB- und Alphakanälen, wodurch effektiv vielfältige und konsistente RGBA-Videos generiert werden können und somit die Möglichkeit visueller Effekte und der Erstellung interaktiver Inhalte gefördert wird.
Dieses Tutorial verwendet eine einzelne RTX A6000-Karte als Ressource und die Textbeschreibung unterstützt derzeit nur Englisch.
Online ausführen:https://go.hyper.ai/1OFP9

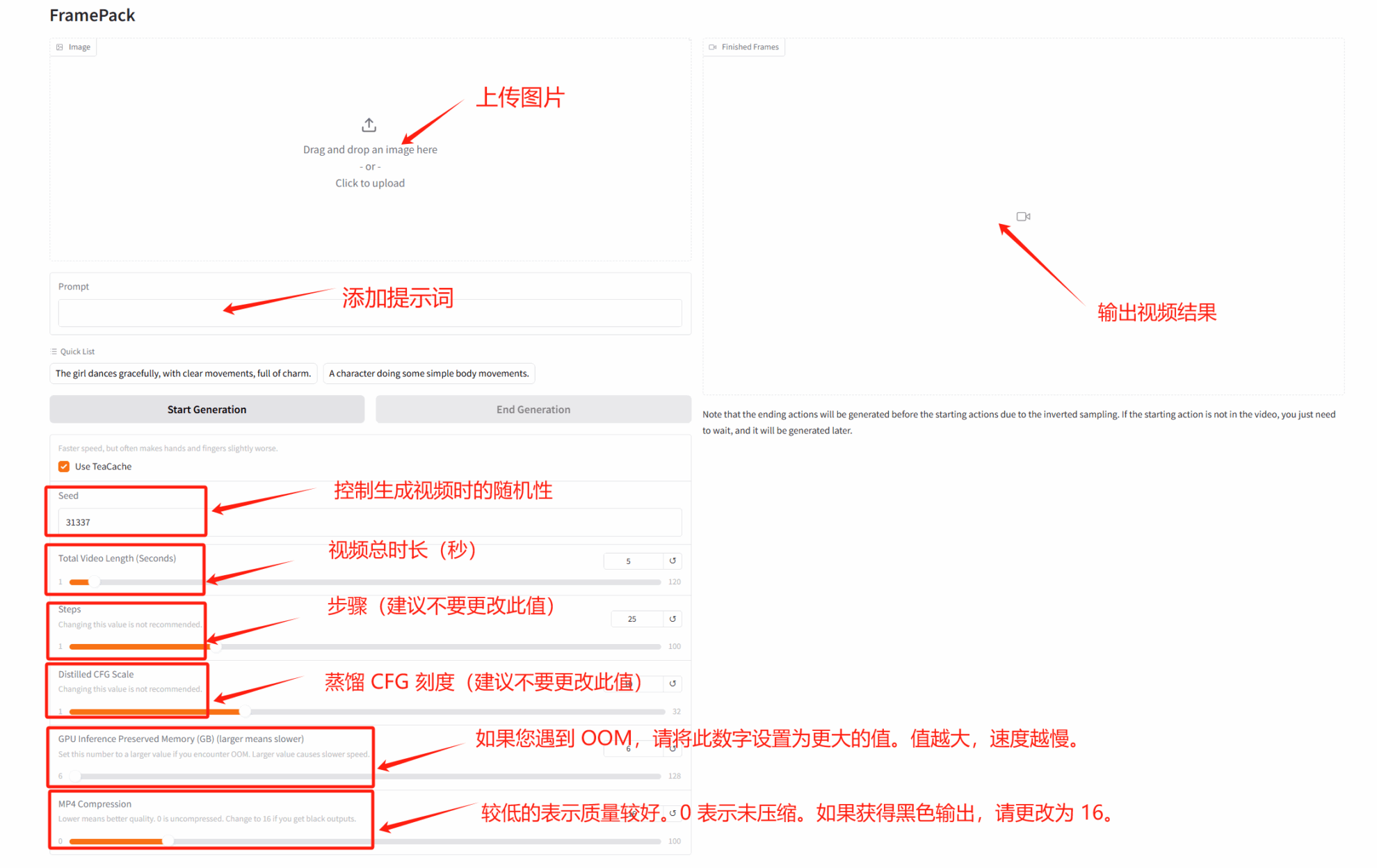
2. FramePack-Demo zur Videogenerierung mit geringem Videospeicher
FramePack verwendet eine innovative neuronale Netzwerkarchitektur, um Probleme wie hohe Videospeichernutzung, Drift und Vergessen bei der herkömmlichen Videogenerierung effektiv zu lösen und die Hardwareanforderungen erheblich zu reduzieren.
Dieses Tutorial verwendet RTX 4090 als Rechenressource. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/rYELB
Tutorial zum mathematischen Denken
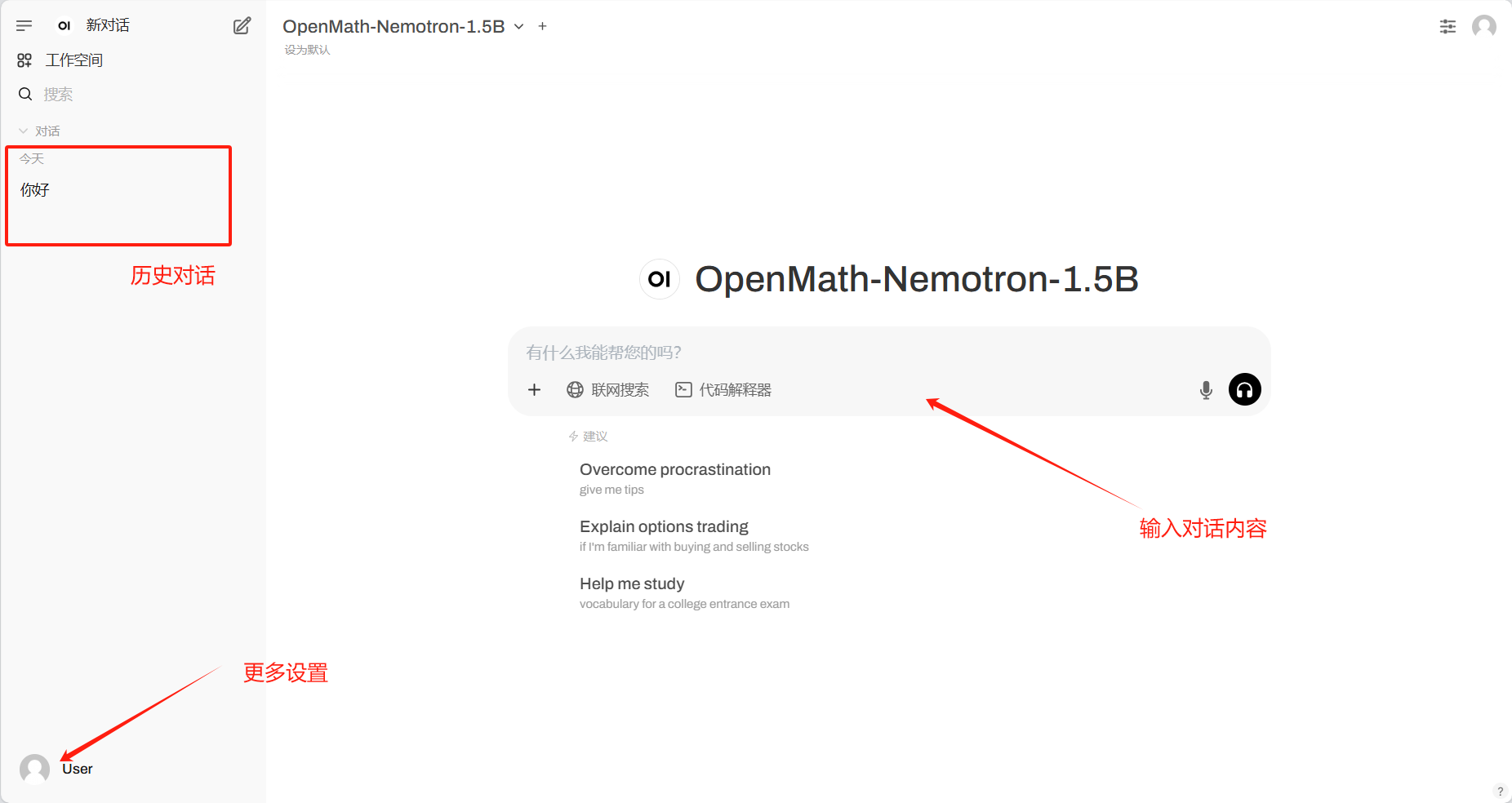
1. Stellen Sie OpenMath-Nemotron-1.5B mit vLLM+Open WebUI bereit
Das Modell wurde durch Feinabstimmung von Qwen/Qwen2.5-Math-1.5B auf dem OpenMathReasoning-Datensatz erstellt. Das Modell erzielt bei gängigen mathematischen Benchmarks hochmoderne Ergebnisse und wurde nun für die kommerzielle Nutzung lizenziert.
Die Rechenressourcen dieses Tutorials verwenden eine einzelne RTX 4090-Karte, unterstützen nur die Berechnung mathematischer Probleme und die Antworten sind auf Englisch.
Online ausführen:https://go.hyper.ai/rasEm
2. Stellen Sie DeepSeek-Prover-V2-7B mit vLLM+Open WebUI bereit
Das wichtigste Merkmal von DeepSeek-Prover-V2-7B ist seine Fähigkeit, informelles mathematisches Denken (d. h. die üblicherweise von Menschen verwendete Denkmethode) nahtlos mit strengen formalen Beweisen zu kombinieren. Dadurch kann das Modell so flexibel denken wie Menschen und so streng demonstrieren wie Computer, wodurch eine integrierte Verschmelzung mathematischen Denkens erreicht wird.
Dieses Tutorial verwendet eine einzelne RTX A6000-Karte als Ressource. Dieses Modell unterstützt nur mathematische Denkprobleme.
Online ausführen:https://go.hyper.ai/JYCI2
Community-Artikel
1. Veröffentlicht im Subjournal von Nature! Die Huazhong University of Science and Technology schlug ein KI-Modell mit Fusionsstrategie vor, um eine genaue Vorhersage des Sterberisikos bei septischem Schock in mehreren Zentren und über verschiedene Fachgebiete hinweg zu erreichen
Ein Forschungsteam des Tongji-Krankenhauses und der School of Medical and Health Management des Tongji Medical College der Huazhong University of Science and Technology hat ein innovatives, auf TOPSIS basierendes Klassifikationsfusionsmodell (TCF) vorgeschlagen, um das Sterberisiko innerhalb von 28 Tagen bei Patienten mit septischem Schock auf der Intensivstation vorherzusagen. Das Modell integriert 7 Modelle des maschinellen Lernens und verfügt über eine hohe Stabilität und Genauigkeit bei der fachübergreifenden und multizentrischen Validierung.
Den vollständigen Bericht ansehen:https://go.hyper.ai/K42Fp
2. Die Universität Oxford und andere haben sich intensiv mit den Gesundheitsdaten von 7,46 Millionen Erwachsenen befasst, um Algorithmen für ein frühes Screening zu entwickeln. So gelang es ihnen, 15 Krebsarten anhand von Blutindikatoren frühzeitig vorherzusagen.
Forschungsteams der Queen Mary University of London und der Oxford University haben gemeinsam zwei neue Algorithmen zur Krebsvorhersage entwickelt, die auf anonymen elektronischen Gesundheitsakten von 7,46 Millionen Erwachsenen in England basieren: Der Basisalgorithmus integriert traditionelle klinische Faktoren und Symptomvariablen und der erweiterte Algorithmus bezieht zusätzlich Blutindikatoren wie ein komplettes Blutbild und Leberfunktionstests mit ein. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Forschungspapiers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/12a8Z
3. Die für ICML 2025 ausgewählte Tsinghua/Renmin-Universität/Byte schlug das erste molekülübergreifende einheitliche Generierungsframework UniMoMo vor, um das Design mehrerer Arzneimittelmoleküle zu erreichen
Das Team von Professor Liu Yang von der Tsinghua-Universität hat zusammen mit den Teams der Renmin-Universität und von ByteDance ein einheitliches Generierungsframework für alle Molekülarten vorgeschlagen: UniMoMo. Dieses Framework stellt einheitlich verschiedene Arten von Molekülen auf der Grundlage molekularer Fragmente dar und ermöglicht so die Entwicklung unterschiedlicher Arten von Bindungsmolekülen für dasselbe Ziel. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/e96ci
Beliebte Enzyklopädieartikel
1. Gated Recurrent Unit
2. Reverse-Sort-Fusion
3. Dreidimensionale Gaußsche Streuung
4. Fallbasiertes Denken
5. Bidirektionales Langzeit-Kurzzeitgedächtnis
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:https://go.hyper.ai/wiki
Juni-Termin für den Gipfel
VLDB 2026 2. Juni 7:59:59
S&P 2026 6. Juni 7:59:59
ICDE 2026 19. Juni 7:59:59
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








