Command Palette
Search for a command to run...
Die Neuesten Erkenntnisse Des AI4S-Teams Von Fei-Fei Li: 16 Innovative Technologien Aus Den Bereichen Biologie/Materialien/Medizin/Diagnose …

Vor nicht allzu langer Zeit,Das Human-Center Artificial Intelligence (HAI) Research Center der Stanford University hat den „2024 Artificial Intelligence Index Report“ veröffentlicht.Als siebtes Meisterwerk von Stanford HAI verfolgt dieser 502 Seiten umfassende Bericht die Entwicklungstrends der globalen künstlichen Intelligenz im Jahr 2023. Im Vergleich zu den Vorjahren wurde der Forschungsumfang erweitert, um grundlegende Trends wie KI-Technologie, die öffentliche Wahrnehmung der KI-Technologie und die politische Dynamik ihrer Entwicklung abzudecken, und es wurden Vorhersagen zu zukünftigen KI-Entwicklungstrends getroffen.

Der Philosoph John Etchemend (links) ist Co-Leiter
Der auffälligste Teil dieses Berichts ist das neu hinzugefügte Kapitel:Erkunden Sie die tiefgreifenden Auswirkungen künstlicher Intelligenz in Wissenschaft und Medizin.Der Bericht präsentiert die brillanten Errungenschaften der KI im wissenschaftlichen Bereich im Jahr 2023 sowie wichtige innovative Ergebnisse, die durch KI im medizinischen Bereich erzielt wurden, darunter bahnbrechende Technologien wie SynthSR und ImmunoSEIRA. Darüber hinaus analysiert der Bericht auch sorgfältig die Trends bei der FDA-Zulassung von KI-Medizingeräten und bietet der Branche wertvolle Referenzen.
Folgen Sie dem offiziellen Konto und antworten Sie mit „HAI2024“, um den vollständigen Bericht herunterzuladen
KI: Ein Motor zur Beschleunigung der wissenschaftlichen Forschung
Der Artificial Intelligence Index Report 2024 besagt, dassIm Jahr 2023 brachte die Industrie 51 bekannte Modelle für maschinelles Lernen hervor, während die Wissenschaft lediglich 15 beisteuerte. Darüber hinaus stammen 108 neu veröffentlichte Basismodelle aus der Industrie und 28 aus der Wissenschaft.
Obwohl die Entwicklung in der Wissenschaft deutlich langsamer verläuft als in der Industrie, ist es wichtig zu wissen, dass KI im Bereich der wissenschaftlichen Entdeckungen erst ab 2022 offiziell eingesetzt wurde. Von AlphaDev, das die Effizienz der Algorithmussortierung optimiert, bis hin zu GNoME, das den Prozess der Materialentdeckung revolutioniert, erleben wir derzeit die Entstehung immer wichtigerer und relevanterer KI-Anwendungen.
Heute ist die KI in Bereichen wie Materialwissenschaften, Klimawandel und Informatik weit verbreitet. Glücklicherweise übernimmt China in dieser Runde des Wandels die Führung.Laut dem „China AI for Science Innovation Map Research Report“, der vom Chinesischen Institut für Wissenschafts- und Technologieinformationen und dem Forschungszentrum für die Entwicklung künstlicher Intelligenz der nächsten Generation des Ministeriums für Wissenschaft und Technologie zusammengestellt wurde, steht mein Land bei der Anzahl der veröffentlichten Artikel in der KI-gesteuerten wissenschaftlichen Forschung an erster Stelle, und die im Inland produzierte Basissoftware für die wissenschaftliche KI-Forschung wird immer ausgereifter und bietet Forschern umfangreiche Datensätze, grundlegende Modelle und spezialisierte Werkzeuge.
Generell ist die Anwendung von KI im wissenschaftlichen Bereich vielfältig und fördert die Entwicklung und den Fortschritt der Wissenschaft in einem beispiellosen Tempo. Es ist jedoch zu beachten, dass im aktuellen Entwicklungsstadium der KI für die WissenschaftProbleme wie der Mangel an umfassenden Talenten, die Schwierigkeit, technische Lösungen wiederzuverwenden, und die schlechte Qualität der Forschungsdaten in vertikalen Disziplinen wurden nach und nach aufgedeckt.
Beispielsweise stechen in der Diskussion rund um die Frage „Sollten KI-Talente wissenschaftliche Forschung betreiben oder sollten wissenschaftliche Forschungstalente KI erlernen?“ Forscher mit interdisziplinärem Wissenshintergrund hervor. Sie verfügen nicht nur über tiefe Einblicke in ihre wissenschaftlichen Forschungsgebiete, sondern sind auch in der Lage, sich schnell verschiedene KI-Tools und -Technologien anzueignen. Allerdings ist ihr Mangel vorstellbar und die Entwicklung umfassender Talente lässt sich nicht über Nacht erreichen. Daher ist die Frage, wie schnell eine Kommunikationsbrücke zwischen KI und wissenschaftlicher Forschung aufgebaut werden kann, eine wichtige Frage im Zusammenhang mit der groß angelegten Förderung von KI für die Wissenschaft.
Gleichzeitig besteht keine Notwendigkeit, näher auf die umfangreichen Felder der wissenschaftlichen Forschung einzugehen. Aufgrund leicht unterschiedlicher Forschungsrichtungen haben verschiedene Forschungsgruppen möglicherweise unterschiedliche Anforderungen an KI-Tools. Wenn es für jedes Team schwierig ist, Forscher mit interdisziplinärem Hintergrund zu haben, kann die Senkung der Hemmschwelle für den Einsatz von KI-Tools und die Vereinfachung des Modellfeinabstimmungsprozesses möglicherweise auch dazu beitragen, die Förderung von KI im Bereich der wissenschaftlichen Forschung bis zu einem gewissen Grad zu beschleunigen.
Beschleunigen Sie Updates, Selbstiteration und die Weiterentwicklung der Technologie
Fortschritte in der KI-Technologie haben die Breite und Tiefe ihrer Anwendungsmöglichkeiten erweitert, stellen gleichzeitig aber auch immer höhere Anforderungen an die Algorithmen. Derzeit haben die meisten Algorithmen ein Stadium erreicht, in dem man sich bei ihrer weiteren Optimierung kaum noch auf menschliche Experten verlassen kann, was zu einer kontinuierlichen Verschärfung der Rechenengpässe führt. Wissenschaftler haben jedoch nie aufgehört, das Gebiet der Algorithmen zu erforschen.
AlphaDev
AlphaGos Meisterstück nachbilden
Sortieralgorithmen sind grundlegende Werkzeuge für Computersysteme, um Datenelemente zu ordnen. Um in diesem Bereich innovative Durchbrüche zu erzielen, verfolgte Google DeepMind einen innovativen Ansatz und erforschte den relativ wenig erforschten Bereich der Computer-Assembleranweisungen.Durch das AlphaDev-System kann DeepMind effizientere Sortieralgorithmen direkt auf der Ebene der CPU-Assembleranweisungen finden.
Das AlphaDev-System besteht aus zwei Kernkomponenten: dem Lernalgorithmus und der Darstellungsfunktion.
Der Lernalgorithmus ist eine Erweiterung des fortschrittlichen AlphaZero-Algorithmus und kombiniert Deep Reinforcement Learning (DRL) und zufällige Suchoptimierungsalgorithmen, um groß angelegte Befehlssuchaufgaben durchzuführen. Die Darstellungsfunktion basiert auf der Transformer-Architektur, die die zugrunde liegende Struktur der Assemblersprache erfassen und in eine spezielle Sequenzdarstellung umwandeln kann.
Mit dem AlphaDev-SystemDeepMind hat erfolgreich Sortieralgorithmen für kurze Sequenzen mit fester Länge entdeckt, nämlich Sort 3, Sort 4 und Sort 5, die den aktuellen manuell optimierten Algorithmen überlegen sind, und hat den relevanten Code in die LLVM-Standard-C++-Bibliothek integriert.Insbesondere bei der Entdeckung des Sort 3-Algorithmus wählte AlphaDev einen scheinbar kontraintuitiven Ansatz, der in Wirklichkeit eine Abkürzung darstellte und an den „37. Zug“ erinnerte, den AlphaGo in seinem Spiel gegen den legendären Go-Spieler Lee Sedol verwendete – eine unerwartete Strategie, die letztendlich zum Sieg führte.
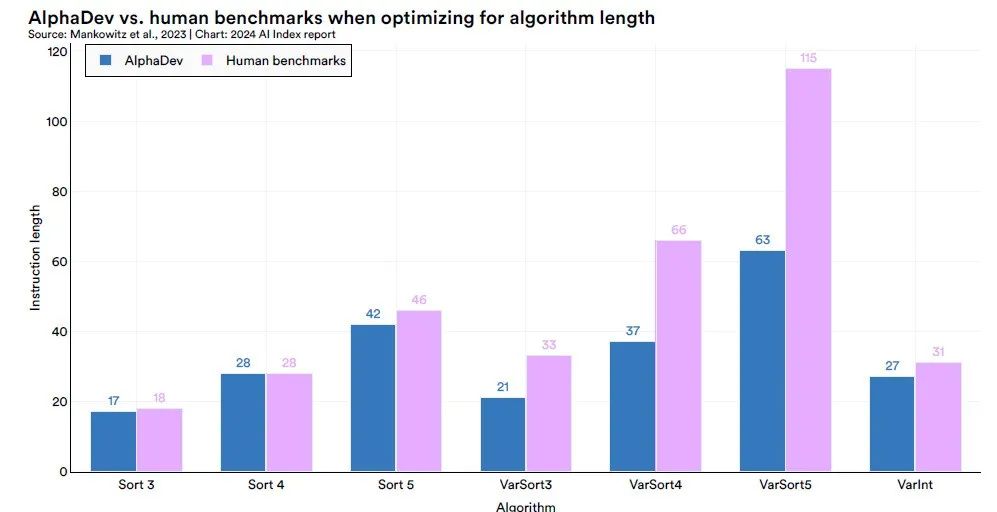
Die Anwendungen von AlphaDev sind nicht auf Sortieralgorithmen beschränkt. DeepMind verallgemeinerte seine Methode und wandte sie auch auf Hash-Algorithmen im Bereich von 9 bis 16 Bytes an, wodurch eine signifikante Geschwindigkeitssteigerung von 30% erreicht wurde. Dies zeigt, dass AlphaDev über ein breites Potenzial und einen großen Anwendungswert bei der Optimierung zugrunde liegender Computeraufgaben verfügt.
Link zum Artikel:
https://www.nature.com/articles/s41586-023-06004-9
FlexiCubes
Generieren Sie hochwertige 3D-Modelle mithilfe von KI
Von der Szenenrekonstruktion bis hin zu generativen KI-Tracks hat die neue Generation von KI-Modellen bemerkenswerte Erfolge bei der Generierung realistischer und detaillierter 3D-Modelle erzielt. Da diese Modelle normalerweise als standardmäßige Dreiecksnetze erstellt werden, ist die Qualität des Netzes von entscheidender Bedeutung. zu diesem Zweck,Forscher von Nvidia haben mit FlexiCubes eine neue Methode zur Netzgenerierung entwickelt, die die Netzqualität in der Pipeline zur 3D-Netzwerkgenerierung deutlich verbessert und in die Physik-Engine integriert werden kann, um auf einfache Weise flexible Objekte in 3D-Modellen zu erstellen.
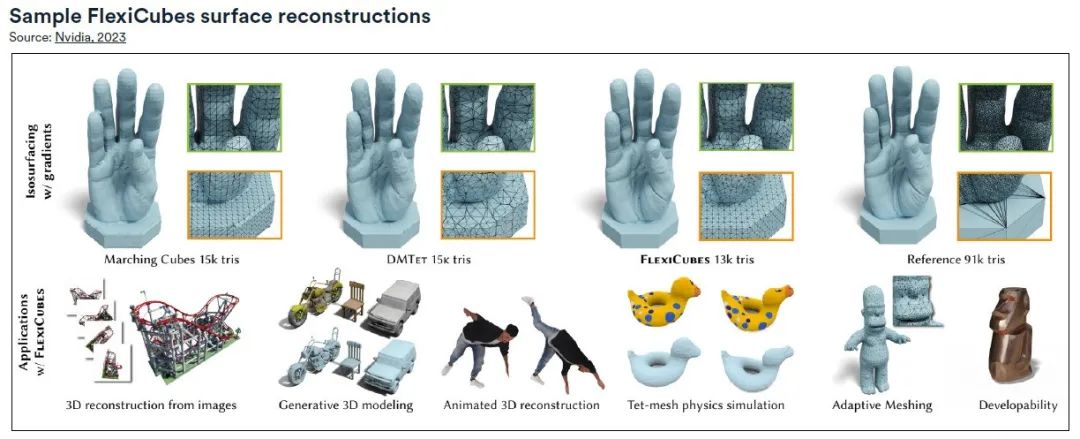
Die Kernidee von FlexiCubes besteht darin, „flexible“ Parameter einzuführen, die präzise Anpassungen im Prozess der Netzgenerierung ermöglichen.Durch die Aktualisierung dieser Parameter während des Optimierungsprozesses wird die Qualität des Netzes erheblich verbessert. Dieser Ansatz hebt FlexiCubes deutlich von herkömmlichen gitterbasierten Pipelines wie dem weit verbreiteten Marching Cubes-Algorithmus ab und ermöglicht so den nahtlosen Ersatz optimierungsbasierter KI-Pipelines.
Die von FlexiCubes generierten hochwertigen Netze zeichnen sich durch die Darstellung komplexer Details aus und verbessern den Gesamtrealismus und die Wiedergabetreue der KI-generierten 3D-Modelle. Diese Netze sind besonders nützlich für physikalische Simulationen in Bereichen wie Photogrammetrie und generative KI, da sie es KI-Pipelines ermöglichen, Details in komplexen Formen präzise wiederzugeben.
Link zum Artikel:
https://research.nvidia.com/labs/toronto-ai/flexicubes
Beschleunigen Sie die Erstellung und verbessern Sie die Effizienz über den menschlichen Aufwand hinaus
Synbot
KI-gestützter Roboterchemiker
Tief in den Tiefen chemischer Labore vollzieht sich still und leise eine Revolution: Die Synthese organischer Verbindungen ist kein langsamer und langwieriger Prozess mehr, sondern wird durch die Magie der Automatisierung beschleunigt Wirklichkeit.Im Mittelpunkt dieser Transformation steht der Synbot, ein autonomer synthetischer Roboter, der von Wissenschaftlern bei Samsung Electronics entwickelt wurde.
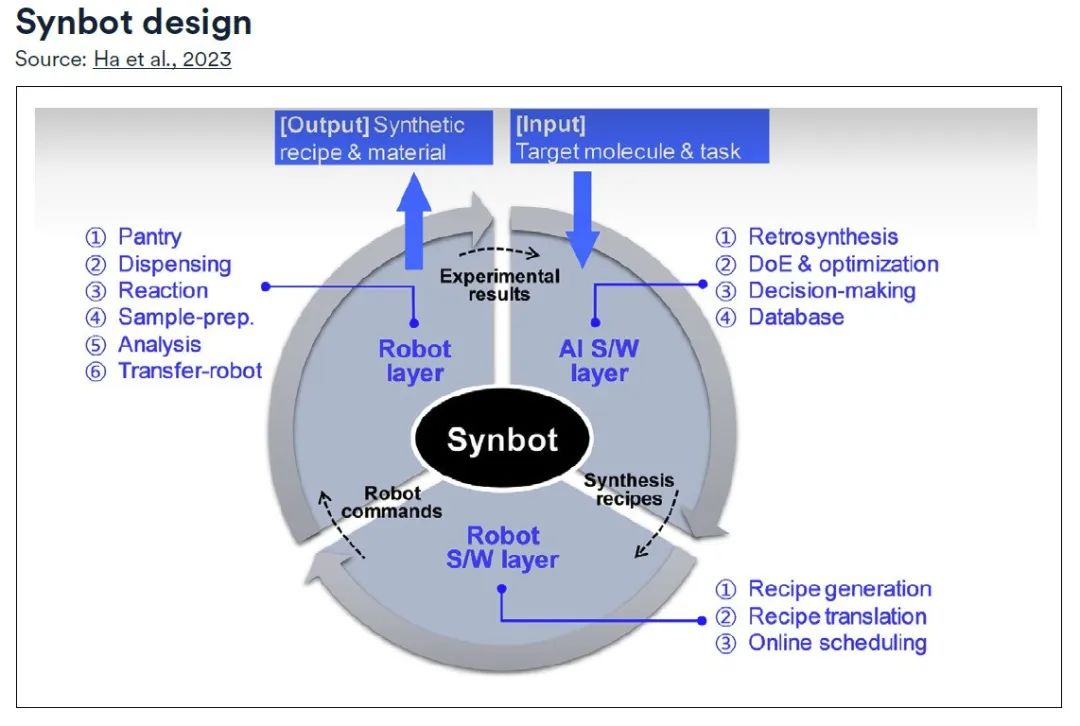
Konkret besteht Synbot aus drei Schichten:
* AI S/W-Schicht:Leiten Sie den umfassenden Planungsprozess, ausgestattet mit Retrosynthesemodulen, experimentellen Design- und Optimierungsmodulen, und verwenden Sie Entscheidungsmodule, um die experimentelle Richtung zu steuern.
* Roboter-S/W-Schicht:Verantwortlich für die Umwandlung in umsetzbare Befehle für den Roboter durch das Rezeptgenerierungsmodul und das Übersetzungsmodul;* Roboterebene:Unter der Aufsicht des Online-Planungsmoduls werden die verschiedenen Funktionen des Syntheselabors modularisiert und die geplanten Rezepte systematisch ausgeführt, wobei die Datenbank kontinuierlich aktualisiert wird, bis die vordefinierten Ziele erreicht sind.
Untersuchungen zeigen, dassDer Synbot kann in 24 Stunden durchschnittlich 12 Reaktionen durchführen. Unter der Annahme, dass ein menschlicher Forscher zwei solcher Experimente pro Tag durchführen kann, ist Synbot mindestens sechsmal effizienter als seine menschlichen Kollegen.Durch die Integration von Synbot werden Wissenschaftler von langwierigen Vorgängen befreit und können mehr Energie in Innovation und Forschung investieren.
Link zum Artikel:
https://www.science.org/doi/full/10.1126/sciadv.adj0461
GNoME
Den Materialentdeckungsprozess neu erfinden
Google DeepMind veröffentlichte einen Artikel in Nature, in dem es heißt:Das auf Materialerkundung basierende KI-Tool GNoME (Graph Networks for Materials Exploration) hat 2,2 Millionen neue Kristallvorhersagen entdeckt (entspricht fast 800 Jahren von menschlichen Wissenschaftlern angesammeltem Wissen), von denen 380.000 stabile Kristallstrukturen sind.Man hofft, dass einige Materialien durch experimentelle Synthese technologische Veränderungen auslösen können, etwa die nächste Generation von Batterien und Supraleitern.
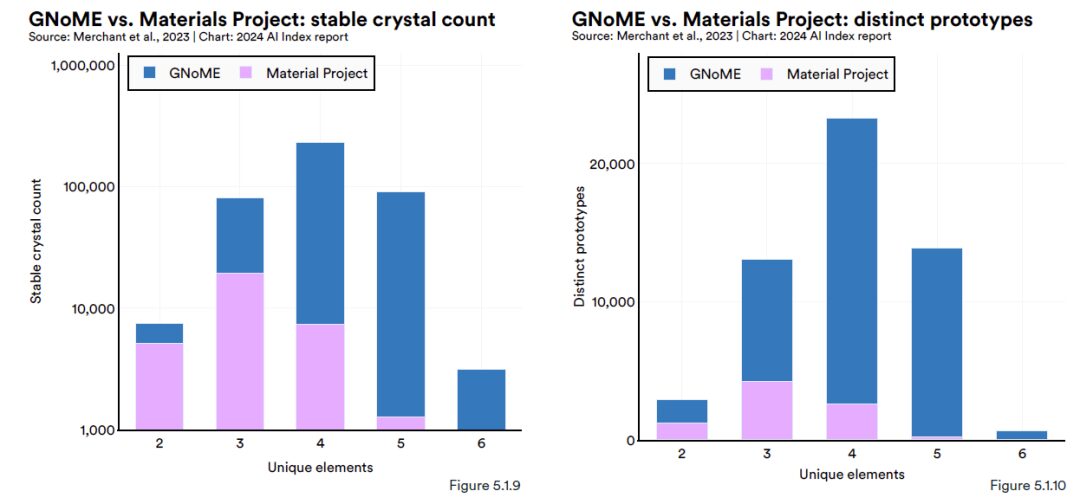
GNoME ist ein erweitertes Graph-Neural-Network-Modell (GNN). Die Eingabedaten liegen hauptsächlich in Form von Graphen vor und bilden Verbindungen, die denen zwischen Atomen ähneln, was es GNoME auch erleichtert, neue kristalline Materialien zu entdecken. Es wird berichtet, dass GNoME die Struktur neuer stabiler Kristalle vorhersagen, sie dann mittels DFT (Dichtefunktionaltheorie) testen und die daraus resultierenden hochwertigen Trainingsdaten wieder in das Modelltraining einspeisen kann.
In diesem StadiumDas neue Modell wird die Genauigkeit der Vorhersage der Materialstabilität von etwa 50% auf 80% und die Entdeckungsrate neuer Materialien von weniger als 10% auf mehr als 80% erhöhen.(Klicken Sie hier, um den vollständigen Bericht anzuzeigen: 800 Jahre vor der Menschheit? DeepMind veröffentlicht GNoME und verwendet Deep Learning, um 2,2 Millionen neue Kristalle vorherzusagen)
Beschleunigen Sie den Wandel und gehen Sie ruhig mit dem „grauen Nashorn“ der ökologischen Umwelt um
GraphCast
Erstellung der präzisesten globalen Wettervorhersage
GraphCast, veröffentlicht von Google DeepMind, ist ein Wettervorhersagesystem, das auf maschinellem Lernen und Graph Neural Networks (GNNs) basiert. Es verwendet eine „Encode-Process-Decode“-Konfiguration, verfügt über insgesamt 36,7 Millionen Parameter und kann Vorhersagen mit einer hohen Auflösung von 0,25 Längen-/Breitengraden (28 km x 28 km am Äquator) treffen.Das Verbreitungsgebiet erstreckt sich über die gesamte Erdoberfläche. An jedem Gitterpunkt sagt das Modell fünf Variablen der Erdoberfläche (einschließlich Temperatur, Windgeschwindigkeit, Windrichtung, mittlerer Luftdruck auf Meereshöhe usw.) sowie sechs atmosphärische Variablen einschließlich spezifischer Luftfeuchtigkeit, Windgeschwindigkeit, Windrichtung und Temperatur in 37 verschiedenen Höhen voraus.
Im umfassenden BasistestIm Vergleich zu HRES (High Resolution Forecast) bietet GraphCast genauere Prognosen für fast 90% von 1.380 getesteten Variablen.Einer vergleichenden Analyse zufolge kann GraphCast Unwetter auch früher erkennen als herkömmliche Vorhersagemodelle. (Klicken Sie hier für den vollständigen Bericht: Hailstorm Center sammelt Daten, große Modelle unterstützen die Vorhersage extremer Wettervorhersagen und „Storm Chasers“ stehen auf der Bühne)
Hochwasservorhersage
Künstliche Intelligenz verändert Hochwasservorhersage
Im Jahr 2018 startete Google die Google Flood Forecasting Initiative. Dabei werden KI und leistungsstarke Rechenleistung eingesetzt, um bessere Modelle zur Hochwasservorhersage zu erstellen und mit Regierungen in mehreren Ländern zusammenzuarbeiten. Im Jahr 2023Das Forschungsteam von Google hat ein auf maschinellem Lernen basierendes Flussvorhersagemodell entwickelt, das Hochwasser fünf Tage im Voraus zuverlässig vorhersagen kann. Bei der Vorhersage von Hochwasserereignissen, die einmal in fünf Jahren auftreten, ist die Leistung besser oder gleichwertig mit der aktuellen Vorhersage von Hochwasserereignissen, die einmal im Jahr auftreten. Das System kann mehr als 80 Länder abdecken.
Diese Studie erstellte ein fortschrittliches Flussvorhersagemodell durch die Anwendung von zwei Long Short-Term Memory Networks (LSTM).Die Kernarchitektur des Modells basiert auf dem Encoder-Decoder-Framework.Insbesondere ist das Hindcast-LSTM-Modul für die Verarbeitung historischer Wetterdaten verantwortlich, während das Forecast-LSTM-Modul prognostizierte Wetterdaten verarbeitet. Die Ausgabe des Modells sind die Wahrscheinlichkeitsverteilungsparameter für jeden Vorhersagezeitpunkt, die eine Wahrscheinlichkeitsvorhersage der Strömung eines bestimmten Flusses zu einem bestimmten Zeitpunkt liefern können.
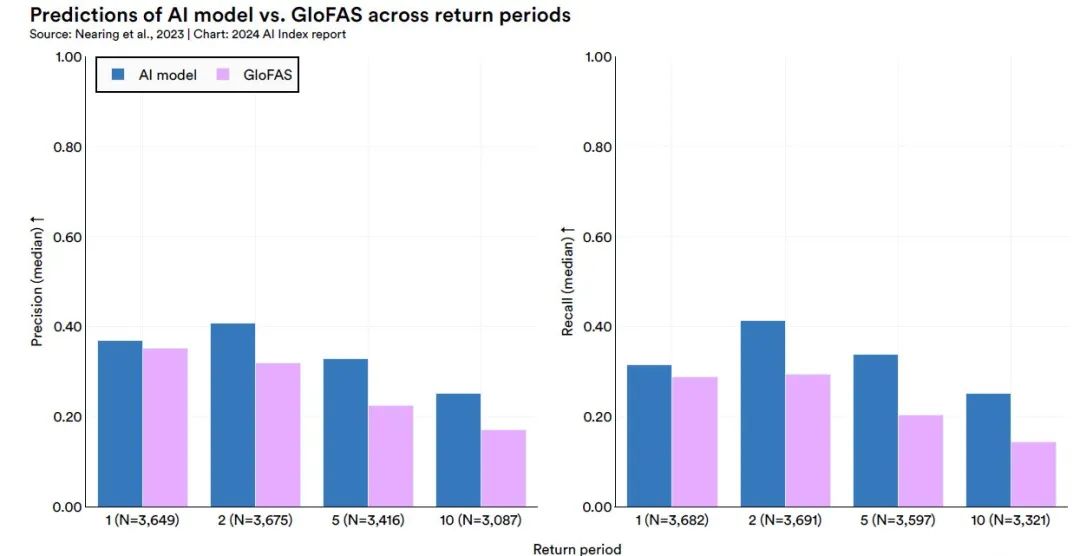
Die Ergebnisse der Studie zeigten, dassDas Modell übertrifft das derzeit weltweit führende Modellierungssystem, das Copernicus Emergency Management Service Global Flood Awareness System (GloFAS).Dieses Ergebnis bestätigt das Potenzial und die Zuverlässigkeit des vorgeschlagenen Modells im Bereich der Flussvorhersage und bietet ein neues technisches Mittel zur Hochwasserwarnung und zum Wasserressourcenmanagement. (Klicken Sie hier, um den vollständigen Bericht anzuzeigen: Googles Hochwasservorhersagemodell wird erneut in Nature veröffentlicht, übertrifft das weltweit führende System und deckt über 80 Länder ab.)
KI: Eine neue Ära in der Medizin
Der „2024 Artificial Intelligence Index Report“ zeigt, dass die KI-Technologie in vielen Bereichen wie der medizinischen Bildgebung, medizinischen Fragen und Antworten, der medizinischen Diagnose usw. Ergebnisse erzielt hat. Tatsächlich ist die Anwendung von KI im medizinischen Gesundheitsbereich den Menschen seit langem bekannt. Durch Algorithmen des maschinellen Lernens ist KI in der Lage, große Mengen medizinischer Daten zu analysieren und Ärzten dabei zu helfen, Krankheiten genauer zu diagnostizieren. Beispielsweise kann KI bei der Krebserkennung subtile Anomalien in medizinischen Bildern erkennen und so die Erfolgsquote einer Frühdiagnose verbessern.
Darüber hinaus spielt KI auch in der Arzneimittelforschung und -entwicklung eine wichtige Rolle.einerseits,KI hat unser Verständnis von Wirkstoffzielen und der Synthese von Verbindungen vertieft, die Schritte der Arzneimittelentdeckung optimiert und die Chancen für die erfolgreiche Markteinführung neuer Medikamente erheblich erhöht.auf der anderen Seite,Mithilfe von KI-Technologie werden die Entwicklungszyklen neuer Medikamente verkürzt, Kosten gespart und die Effizienz der Medikamentenentwicklung sowie die Wettbewerbsfähigkeit der Unternehmen deutlich verbessert.
Es ist erwähnenswert, dass der „2024 Artificial Intelligence Index Report“ auch medizinische Geräte mit künstlicher Intelligenz zusammenfasst und die Zahl der Zulassungen für KI-bezogene medizinische Geräte durch die US-amerikanische Food and Drug Administration (FDA) weiter zunimmt. Im Jahr 2022 hat die FDA 139 KI-bezogene Medizinprodukte zugelassen, ein Anstieg von 12,11 TP3T gegenüber dem Vorjahr. Diese Zahl hat sich seit 2012 mehr als 45-mal erhöht, was den weitverbreiteten Einsatz von KI in medizinischen Anwendungen in der realen Welt zeigt.
Obwohl die Anwendung der KI-Technologie in der tatsächlichen medizinischen Versorgung viele Chancen mit sich gebracht hat, ist sie auch mit einer Reihe von Herausforderungen verbunden, die bewältigt werden müssen, wie etwa ethische Fragen im Zusammenhang mit KI, Datenschutz, technische Engpässe, Aufsicht und Rechenschaftspflicht, interdisziplinäre Zusammenarbeit und klinische Anwendbarkeit. Insbesondere,AAufgrund der „Black Box“-Natur des I-Modells ist sein Entscheidungsprozess schwer zu erklären, was eine große Herausforderung für die medizinische Diagnose darstellt, die ein hohes Maß an Transparenz und Nachvollziehbarkeit erfordert.Mangelnde Erklärbarkeit kann das Vertrauen der Ärzte in KI-gestützte Diagnoseergebnisse beeinträchtigen.
Daher ist es neben der technologischen Iteration weiterhin erforderlich, dass die Regierung und die betreffenden Unternehmen gemeinsam Lösungen vorantreiben, um die Lücken in Richtlinien, Standards, Aufsicht, Sicherheit usw. zu schließen und die „Blackbox“-Eigenschaften zu überwinden.
Medizinische Bildgebung: Bereitstellung umfassenderer und detaillierterer Lösungen
Die Anwendung von KI-Technologie im Bereich der medizinischen Bildgebung wird immer vielfältiger und umfassender. Von der Diagnoseunterstützung über die Verbesserung von Arbeitsabläufen bis hin zur Förderung personalisierter Medizin wird KI zu einem unverzichtbaren Werkzeug für die medizinische Bildgebung.
SynthSR
Konvertieren Sie hochauflösende Bilder und reparieren Sie Läsionen
SynthSR wurde vom Computer Science and Artificial Intelligence Laboratory des MIT entwickelt und trainiert ein Convolutional Neural Network (CNN) mit Superauflösung mithilfe eines frei zugänglichen Datensatzes von 1 mm großen isotropen Hochfeld-MRT-Scans und einer präzisen Segmentierung von 39 interessanten Regionen (ROIs) im Gehirn.Die Technologie konzentriert sich auf T1- und T2-gewichtete MRT-Sequenzen des Gehirns mit niedrigem Feld (0,064 T) und verwendet dabei die MPRAGE-Akquisitionstechnologie (Magnetization-Prepared Rapid Gradient Echo), um qualitativ hochwertige Bilder mit einer isotropen räumlichen Auflösung von 1 mm zu erzeugen.
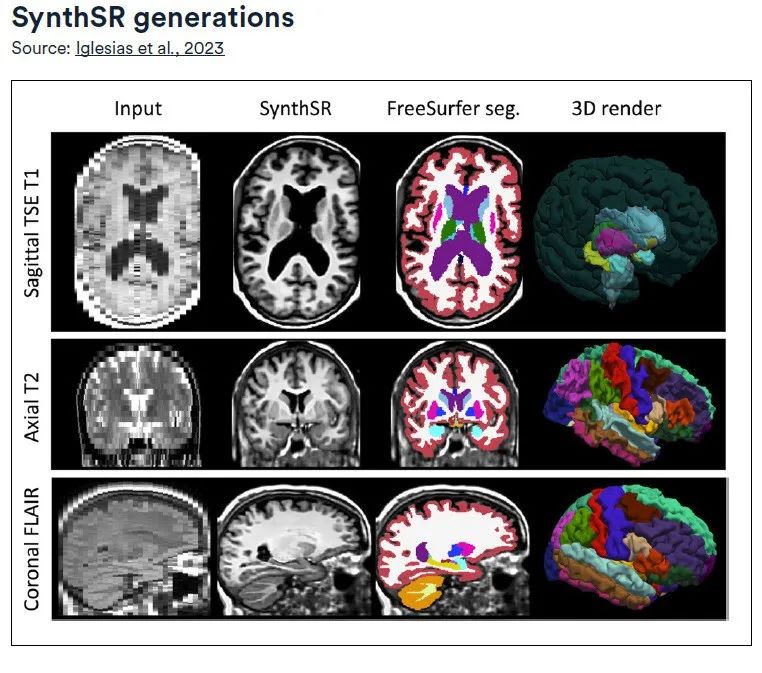
Die erweiterten Funktionen von SynthSR sind:Es kann klinische MRT-Scandaten unterschiedlicher Richtungen, Auflösungen und Kontraste in 1 mm große isotrope MPRAGE-Bilder umwandeln und dabei Läsionen reparieren.
Die konvertierten synthetischen MPRAGE-Bilder können direkt auf vorhandene 3D-Bildanalysetools der Gehirn-MRT angewendet werden, wie etwa Bildregistrierung oder -segmentierung.Es ist keine zusätzliche Schulung erforderlich.Darüber hinaus wurde in der Studie durch den Vergleich der hirnmorphometrischen Daten synthetischer Bilder mit tatsächlichen Bildern hoher Feldstärke das Anwendungspotenzial von LF-SynthSR im Bereich der quantitativen Neuroradiologie weiter bestätigt.
Link zum Artikel:
http://arxiv.org/pdf/2012.13340v1.pdf
CT Panda
Früherkennung von Bauchspeicheldrüsenkrebs
Angesichts der versteckten Lage des Bauchspeicheldrüsenkrebses und des Fehlens offensichtlicher Manifestationen in einfachen CT-Bildern,Die Alibaba DAMO Academy nutzte in Zusammenarbeit mit Forschungsteams von mehr als einem Dutzend medizinischer Einrichtungen auf der ganzen Welt KI, um Bauchspeicheldrüsenkrebs bei asymptomatischen Personen zu untersuchen, baute ein einzigartiges Deep-Learning-Framework auf und trainierte schließlich das PANDA-Modell für die Früherkennung von Bauchspeicheldrüsenkrebs.
Das PANDA-Modell ist ein fortschrittliches medizinisches Bildanalysetool, das mehrere Deep-Learning-Techniken kombiniert, um die Effizienz und Genauigkeit der Erkennung von Pankreasläsionen zu verbessern. Das Modell verwendet zunächst ein Segmentierungsnetzwerk (U-Net), um die Pankreasregion genau zu lokalisieren, und verwendet dann ein Multitasking-fähiges Convolutional Neural Network (CNN), um Anomalien im Bild zu identifizieren. Schließlich wurde ein Zweikanal-Transformer-Modell verwendet, um die erkannten Anomalien zu klassifizieren und die spezifischen Pankreasläsionstypen zu identifizieren.
Der Hauptvorteil dieser Technologie besteht darin, dass sie mithilfe von KI-Algorithmen winzige Läsionsmerkmale in einfachen CT-Bildern vergrößern und identifizieren kann, die mit bloßem Auge nur schwer zu erkennen sind.Dadurch wird nicht nur eine effiziente und sichere Früherkennung von Bauchspeicheldrüsenkrebs erreicht, sondern auch das Problem der hohen Falsch-Positiv-Rate bei früheren Screening-Methoden wird effektiv gelöst.
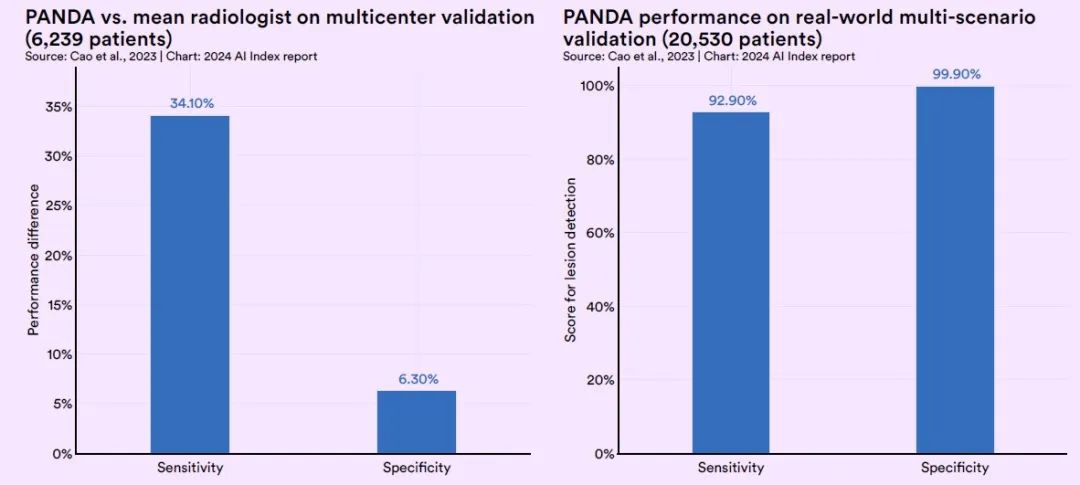
Im Validierungstest war die Sensitivität von PANDA um 34,11 TP3T höher als die von gewöhnlichen Radiologen und seine Spezifität um 6,31 TP3T höher als die von gewöhnlichen Radiologen.In einem groß angelegten Realwelttest mit etwa 20.000 Patienten hatte PANDA eine Sensitivität von 92,9% und eine Spezifität von 99,9%.(Klicken Sie hier, um den vollständigen Bericht anzuzeigen: Unter 20.000 Fällen wurden 31 Fehldiagnosen festgestellt, und die Alibaba Damo Academy übernahm die Führung bei der Veröffentlichung von „Plain Scan CT + großes Modell“ zur Untersuchung von Bauchspeicheldrüsenkrebs.)
Medizinische Diagnose: Entwicklung personalisierter, genauer Diagnose- und Behandlungspläne
Von der Verbesserung der Diagnoseeffizienz und -genauigkeit bis hin zur Bereitstellung personalisierter Behandlungspläne bietet die KI-Technologie im Bereich der medizinischen Diagnose großes Potenzial und trägt dazu bei, die Qualität medizinischer Dienstleistungen und das Patientenerlebnis zu verbessern.
Gekoppelte plasmonische Infrarotsensoren
Verbesserte Diagnose neurodegenerativer Erkrankungen
Im Bereich der Diagnose neurodegenerativer Erkrankungen stellt der Mangel an wirksamen Instrumenten zur Erkennung präklinischer Biomarker die Frühdiagnose von Krankheiten wie dem Parkinson-Syndrom und der Alzheimer-Krankheit vor große Herausforderungen. Traditionelle Nachweismethoden wie Massenspektrometrie und Enzyme-linked Immunosorbent Assay (ELISA) sind zwar bis zu einem gewissen Grad hilfreich, können jedoch Veränderungen im Strukturzustand von Biomarkern nur begrenzt erkennen.
Um dieses Problem zu lösen,Ein Forschungsteam der EPFL hat eine innovative Diagnosemethode entwickelt, die neuronale Netzwerktechnologie, plasmonische Infrarotsensoren mithilfe der oberflächenverstärkten Infrarotabsorptionsspektroskopie (SEIRA) und Immunassay-Technologie (ImmunoSEIRA) kombiniert, um eine quantitative Analyse des Stadiums und des Verlaufs neurodegenerativer Erkrankungen zu ermöglichen.
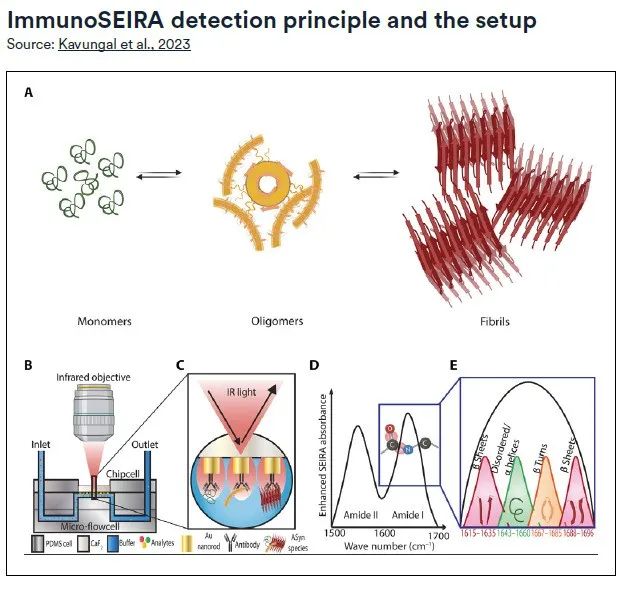
Der ImmunoSEIRA-Sensor verwendet eine Reihe von Goldnanostäben, die mit Antikörpern gegen bestimmte Proteine modifiziert sind. So können Zielbiomarker aus extrem kleinen Probenmengen in Echtzeit erfasst und Strukturanalysen an ihnen durchgeführt werden. Anschließend wurden neuronale Netzwerke verwendet, um fehlgefaltete Proteine, Oligomere und Fibrillenaggregate zu identifizieren, wodurch eine beispiellose Erkennungsgenauigkeit erreicht wurde. Die Einführung dieser Methode bietet eine neue technische Möglichkeit zur Frühdiagnose und genauen Beurteilung neurodegenerativer Erkrankungen.
CoDoC
Logische Integration zwischen KI und ärztlicher Diagnose
Google DeepMind hat ein künstliches Intelligenzsystem für medizinische Hilfe namens CoDoC entwickelt, das eine detaillierte Interpretation und Analyse medizinischer Bilder ermöglichen soll. Durch Lernen kann das System entscheiden, wann es sich auf sein eigenes Urteil verlässt und wann es die Meinung des Arztes übernimmt.
Insbesondere untersuchte das DeepMind-Team verschiedene Anwendungsszenarien, in denen Kliniker KI-Tools zur Unterstützung bei der Interpretation medizinischer Bilder verwenden. Für jeden theoretischen Fall in einem klinischen Umfeld benötigt das CoDoC-System nur drei Eingaben für jeden Fall im Trainingsdatensatz:* Erste,Ein Vertrauenswert für die vorhergesagte AI-Ausgabe, der von 0 (definitiv keine Krankheit) bis 1 (definitiv Krankheit) reicht;* Zweitens,Interpretation medizinischer Bilder durch Kliniker;
* endlich,Die objektive Existenz von Krankheit.
Es ist erwähnenswert, dassDas CoDoC-System erfordert keinen direkten Zugriff auf die medizinischen Bilder selbst.
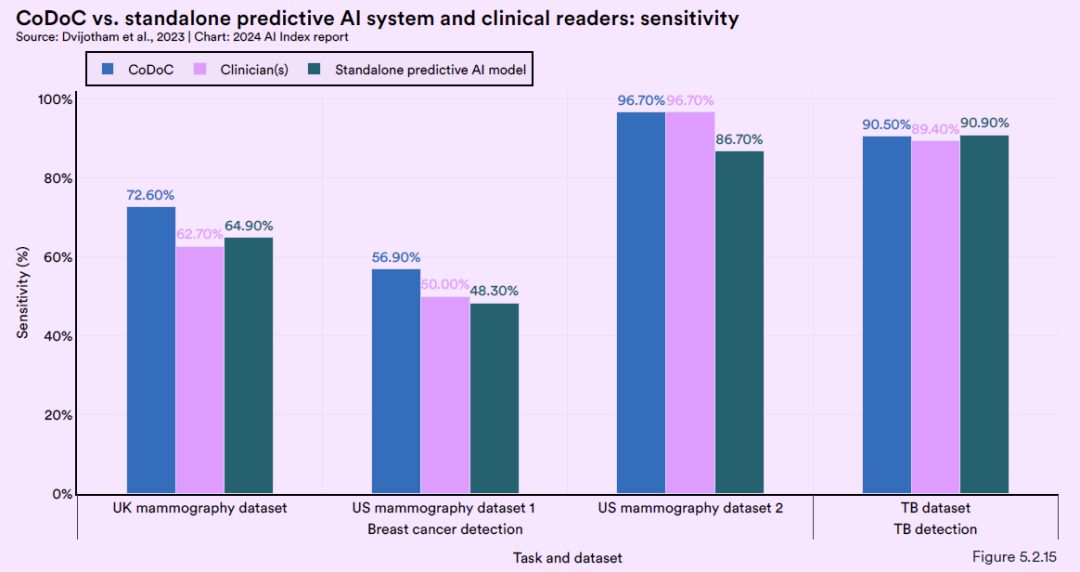
Darüber hinaus hat DeepMind umfassende Tests am CoDoC-System unter Verwendung mehrerer anonymisierter historischer Datensätze aus der realen Welt durchgeführt. Testergebnisse zeigen, dass die Kombination menschlicher medizinischer Expertise mit Vorhersagen von KI-Modellen die genaueste Diagnose liefern kann.Seine Genauigkeit übertrifft die Genauigkeit, die mit jeder der beiden Methoden allein erreicht werden kann.Diese Erkenntnis unterstreicht die Bedeutung der Zusammenarbeit von KI mit menschlichen Experten und bietet neue Perspektiven zur Verbesserung der Genauigkeit und Zuverlässigkeit medizinischer Bilddiagnosen.
Medizinische Fragen und Antworten: Verbessern Sie die Diagnosegenauigkeit, optimieren Sie Behandlungspläne und verbessern Sie das Serviceerlebnis Ihrer Patienten
Im Jahr 2020 schlugen Forscher ein auf Wissensgraphen basierendes medizinisches Frage-Antwort-System namens MedQA vor, das Wissensgraphen verwendet, um strukturierte und halbstrukturierte Daten im medizinischen Bereich darzustellen und zu speichern und dann durch Graphensuche, Schlussfolgerungen oder Abgleichtechniken Antworten aus dem Wissensgraphen abruft oder generiert. Seit der Veröffentlichung von MedQA hat die Fähigkeit der KI, medizinische Fragen zu beantworten, größere Aufmerksamkeit erhalten.
GPT-4 Medprompt
Genauigkeit übertrifft 90%
Das vom Microsoft-Forschungsteam entwickelte GPT-4 Medprompt übertraf im MedQA-Datensatz (Fragen zur medizinischen Zulassungsprüfung in den USA) erstmals die Genauigkeit von 90%.Übertrifft eine Reihe von Feinabstimmungsmethoden wie BioGPT und Med-PaLM. Die Forscher sagten außerdem, dass die Medprompt-Methode universell und nicht nur in der Medizin, sondern auch in Berufen wie Elektrotechnik, maschinellem Lernen und Recht anwendbar sei.
Medprompt ist eine Kombination aus mehreren Aufforderungsstrategien, darunter:* Dynamische Auswahl weniger Stichproben:Die Forscher verwendeten zunächst das Modell „Text-Embedding-ADA-002“, um Vektordarstellungen für jede Trainingsprobe und Testprobe zu generieren. Anschließend werden für jede Testprobe die ähnlichsten k Proben aus den Trainingsproben basierend auf der Vektorähnlichkeit ausgewählt.* Selbst generierte Gedankenkette:Bei der Chain of Thought (CoT)-Methode wird das Modell Schritt für Schritt denken gelassen und es werden eine Reihe von Zwischenschritten beim Denken generiert. Im Vergleich zu den von Experten handgefertigten Beispielen für Gedankenketten im Med-PaLM 2-Modell sind die von GPT-4 generierten Begründungen für Gedankenketten länger und die schrittweise Argumentationslogik feiner abgestuft.
* Option Shuffle-Integration:Wenn GPT-4 Multiple-Choice-Fragen beantwortet, kann es zu einer Verzerrung kommen, d. h., unabhängig von den Optionen wird es dazu tendieren, immer A oder immer B zu wählen. Dies ist eine Positionsverzerrung. Um dieses Problem zu verringern, entschieden sich die Forscher, die ursprüngliche Reihenfolge der Optionen zu ändern und GPT-4 dann mehrere Vorhersagerunden durchführen zu lassen, wobei in jeder Runde eine andere Reihenfolge der Optionen verwendet wurde.

Die Studie zeigte, dass Medprompt den bestplatzierten Flan-PaLM 540B im Jahr 2022 in den Multiple-Choice-Abschnitten mehrerer bekannter medizinischer Benchmark-Tests, darunter PubMedQA, MedMCQA und MMLU, um 3,0, 21,5 bzw. 16,2 Prozentpunkte übertraf. Seine Leistung übertraf auch das damals fortschrittlichste Med-PaLM 2.
MediTron-70B
Bestes Open-Source-Modell für große Sprachen im Gesundheitswesen
Da es sich bei GPT-4 Medprompt um ein Closed-Source-System handelt, ist die kostenlose Nutzung durch die breite Öffentlichkeit eingeschränkt. Um dieses Problem zu lösen,Forscher der Eidgenössischen Technischen Hochschule Lausanne entwickelten auf Basis dieses Systems den MediTron-70B mit dem Ziel, eineEin Open Source, leistungsstarkes Sprachmodell im großen Maßstab für den medizinischen Bereich.
MediTron ist ein Deep-Learning-Algorithmus.Basierend auf der Llama 2-Architektur und optimiert mit Nvidias verteiltem Trainer Megatron-LM,Gleichzeitig erfolgte eine erweiterte Vorausbildung anhand eines umfassenden medizinischen Korpus. Das Korpus ist eine sorgfältige Auswahl von Artikeln, Abstracts und international anerkannten medizinischen Richtlinien von PubMed.
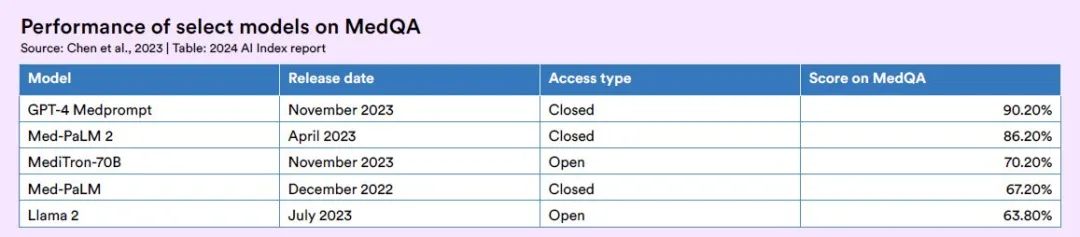
Die MediTron-Serie umfasst zwei Modelle: MediTron-7B und MediTron-70B. In,Die Leistung von MediTron-70B hat die von GPT-3.5 und Med-PaLM übertroffen und liegt nahe am Niveau von GPT-4 und Med-PaLM-2.
Um die Entwicklung medizinischer LLMs mit Open Source zu fördern, hat das Entwicklungsteam das von ihm verwendete medizinische Vortrainingskorpus und den Gewichtscode des MediTron-Modells veröffentlicht. MediTron-70B erreicht bei MedQA die höchste Punktzahl unter den Open-Source-Modellen, eine Leistung, die einen wichtigen Fortschritt im Bereich der medizinischen Open-Source-LLMs darstellt.
Link zum Artikel:
https://arxiv.org/pdf/2311.16079.pdf
MedAlign
Reduzieren Sie den Verwaltungsaufwand im Gesundheitswesen
Aktuelle Datensätze zur Beantwortung von Fragen und Antworten in elektronischen Patientenakten (EHR) für Textgenerierungsaufgaben im Gesundheitswesen erfassen die Komplexität, mit der Kliniker bei der Analyse des Informationsbedarfs und der Dokumentenverarbeitung konfrontiert sind, nicht ausreichend.
Um diese Lücke zu schließen, hat ein Team von 15 Klinikern aus verschiedenen Fachgebieten MedAlign – Ein Benchmark-Datensatz basierend auf EHR-Daten. Der Datensatz enthält 983 reale klinische Fragen und die dazugehörigen Anweisungen sowie Antworten von 303 Klinikern. Durch die Analyse von 276 longitudinalen EHR-Daten wurden Anweisungs-Antwort-Paare erstellt.
Diese Arbeit befasst sich nicht nur mit dem Fehlen eines Bewertungsmaßstabs für die Praktikabilität von LLMs bei komplexen klinischen Aufgaben, sondern fördert auch den Forschungsfortschritt der natürlichen Sprachgenerierung im Gesundheitswesen, indem sie einen realistischen und umfassenden Datensatz für Befehlsantworten bereitstellt.
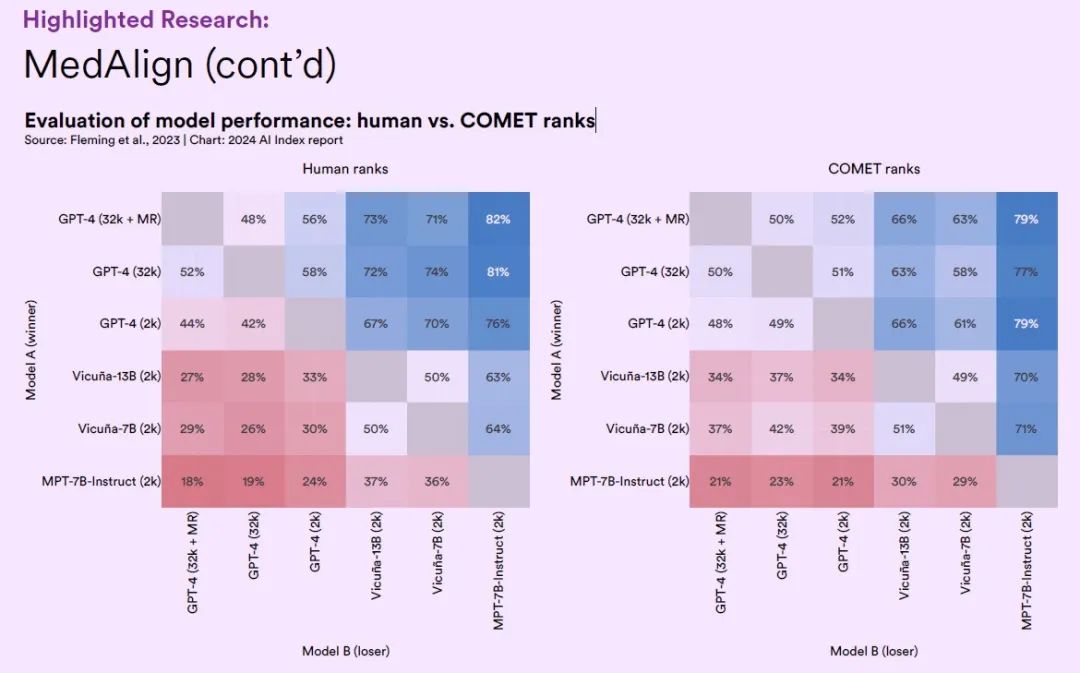
Anhand des MedAlign-Datensatzes testeten die Forscher sechs große Sprachmodelle aus unterschiedlichen allgemeinen Domänen und bewerteten die Genauigkeit und Qualität der von jedem großen Modell durch die Kliniker generierten Antworten.
Die Ergebnisse zeigen, dassDie mehrstufig optimierte GPT-4-Modellvariante hat eine Genauigkeit von 65,0% erreicht, die im Allgemeinen anderen LLMs vorgezogen wird. Als erster Benchmark-Datensatz, der EHR-Anwendungen umfassend abdeckt, stellt MedAlign einen wichtigen Schritt nach vorn bei der Nutzung künstlicher Intelligenztechnologie zur Reduzierung des Verwaltungsaufwands im Gesundheitswesen dar.
Link zum Artikel:
https://arxiv.org/pdf/2308.14089.pdf
Medizinische Forschung: Mit KI die stärkste Verteidigungslinie für die menschliche Gesundheit aufbauen
Mit dem kontinuierlichen technologischen Fortschritt ist die Anwendung der KI-Technologie im Bereich der medizinischen Forschung umfangreicher und gründlicher geworden. Heute nutzen Wissenschaftler die Möglichkeiten der KI, um den Code der menschlichen Gene gründlich zu erforschen und uns mithilfe der KI beim Aufbau einer soliden medizinischen Verteidigungslinie zu helfen.
AlphaMissence
Pathogene Missense-Mutationen in Genen effektiv identifizieren
Basierend auf AlphaFold hat das Google DeepMind-Team ein neues KI-Modell weiterentwickelt – AlphaMissense.Das Modell kombiniert das hochpräzise Proteinstrukturmodell von AlphaFold und den aus verwandten Sequenzen extrahierten Algorithmus der eingeschränkten Evolution. Der Trainingsprozess von AlphaMissense ist in zwei Phasen unterteilt:
* Die erste Phase ähnelt dem Training von AlphaFold und konzentriert sich auf die Verbesserung der Gewichte des Proteinsprachenmodells.
* In der zweiten Phase geht es darum, das Modell zu verfeinern, um die Pathogenität genauer abzubilden. Dabei wird der Mutation basierend auf ihrer Häufigkeit in der Population eine Bezeichnung als gutartig oder pathogen zugewiesen.
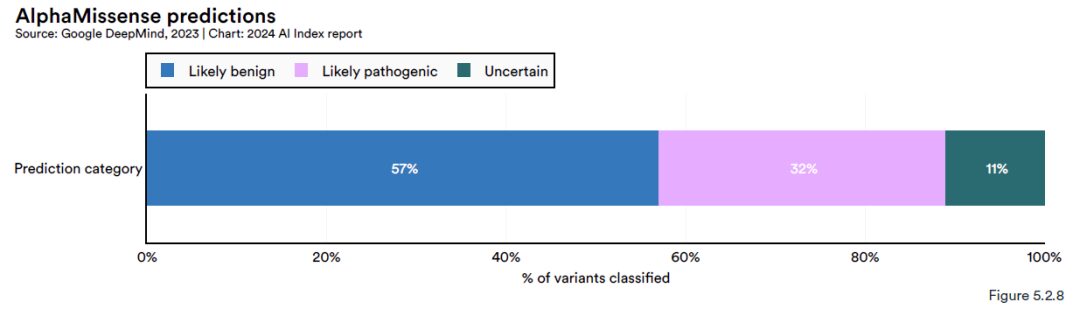
Die Ergebnisse der Studie zeigen, dassAlphaMissense hat erfolgreich 71 Millionen Missense-Mutationen in menschlichen proteinkodierenden Genen vorhergesagt.Missense-Mutationen sind vererbte Variationen, die die Proteinfunktion beeinträchtigen und zu einer Reihe von Krankheiten, darunter auch Krebs, führen können. Zu diesen potenziellen Missense-Varianten gehörenAlphaMissense konnte 891 TP3T-Varianten klassifizieren, von denen etwa 571 TP3T als wahrscheinlich gutartige Varianten (wahrscheinlich gutartig), 321 TP3T als wahrscheinlich pathogene Varianten (wahrscheinlich pathogen) und die restlichen Varianten als Varianten ungewisser Natur (unsicher) eingestuft wurden.
Diese Klassifizierungsfähigkeit übertrifft die menschlicher Annotatoren bei weitem, die unter allen Missense-Mutationen nur 0,11 TP3T identifizieren konnten. Die hohe Effizienz und Genauigkeit von AlphaMissense machen es zu einem leistungsstarken Werkzeug für die Erforschung und klinische Diagnose genetischer Erkrankungen.
Link zum Artikel:
https://www.science.org/doi/10.1126/science.adg7492
EVEscape
Frühwarnsystem für Pandemien
Ein Forschungsteam der Harvard Medical School und der Universität Oxford hat gemeinsam ein innovatives universelles modulares Framework entwickelt: EVEscape.Möglichkeit, das Fluchtpotenzial des Virus vorherzusagen, ohne sich während der Pandemie auf Sequenzierungsdaten oder Informationen zur Antikörperstruktur verlassen zu müssen.
Die Genauigkeit von EVEscape bei der Vorhersage pandemischer SARS-CoV-2-Mutationen ist vergleichbar mit der Hochdurchsatz-Technologie Deep Mutation Scanning (DMS) und ihre Anwendung ist nicht auf SARS-CoV-2 beschränkt, sondern kann auf andere Virustypen ausgeweitet werden. Dieses Frühwarnsystem dient als Grundlage für Entscheidungen und Vorsorgemaßnahmen im Bereich der öffentlichen Gesundheit und trägt dazu bei, die negativen Auswirkungen der Pandemie auf die menschliche Gesundheit und die sozioökonomische Entwicklung zu minimieren.
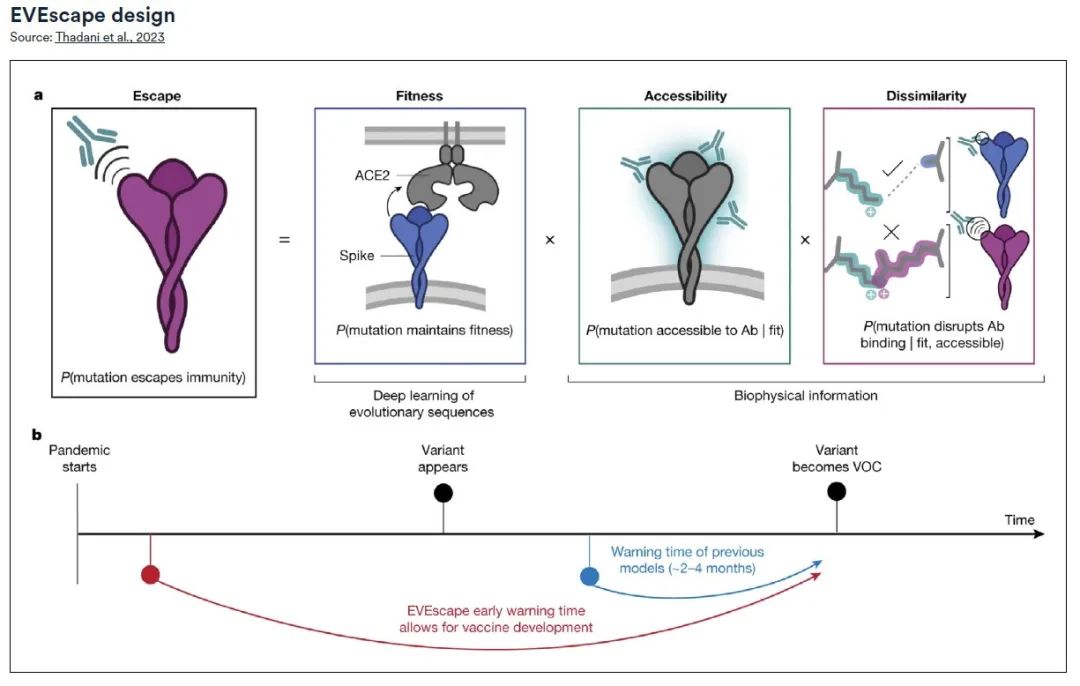
Das EVEscape-Framework besteht aus zwei Hauptteilen:* Ein Teil ist ein Modell zur Generierung evolutionärer Sequenzen,Das Modell bietet Einblicke in mögliche Virusmutationen, ähnlich dem im EVE-Projekt (Evolutionary Virus Escape) verwendeten Modell.
* Ein weiterer Teil ist eine Datenbank mit detaillierten biologischen und strukturellen Informationen über das Virus.Durch die Integration dieser beiden Komponenten ist EVEscape in der Lage, die Eigenschaften viraler Varianten vorherzusagen, bevor sie tatsächlich auftreten.
Durch eine retrospektive Analyse der SARS-CoV-2-Pandemie bestätigte das Forschungsteam die Wirksamkeit von EVEscape bei der Vorhersage von Mutationen mit Pandemie-Escape-Potenzial, und zwar Monate früher als Methoden, die auf traditionellen Antikörper- und serologischen Experimenten beruhen, bei gleichzeitig vergleichbarer Genauigkeit. Die frühzeitige Identifizierung potenzieller Escape-Mutationen mithilfe von EVEscape kann wichtige Informationen für die Entwicklung von Impfstoffen und Therapeutika liefern, um die Ausbreitung des Virus wirksamer zu kontrollieren.
Link zum Artikel:
https://doi.org/10.1038/s41586-023-06617-0
Referenz zum menschlichen Pangenom
Erster Entwurf des menschlichen Pangenoms entschlüsselt
Zu Beginn des 21. Jahrhunderts veröffentlichte das Humangenomprojekt erfolgreich den vorläufigen Entwurf des menschlichen Referenzgenoms und markierte damit einen Durchbruch im Verständnis der Menschheit über ihren eigenen Lebensbauplan. Aufgrund der damaligen Einschränkungen der Sequenzierungstechnologie enthielt der Entwurf jedoch mehrere nicht ausgefüllte leere Bereiche.
Im Jahr 2023 entwickelte ein internationales Konsortium aus 119 Wissenschaftlern aus 60 Institutionen unter der Leitung der University of Washington School of Medicine und der University of California mithilfe von künstlicher Intelligenz den ersten aktualisierten und repräsentativeren Entwurf des menschlichen Pangenoms.
Der Entwurf verwendete fortschrittliche „Long-Read-Sequenzierungs“-Technologie, um eine eingehende Analyse von 94 Genomproben von 47 Personen mit unterschiedlichem Abstammungshintergrund aus der ganzen Welt durchzuführen.Die langen DNA-Fragmente wurden dann mithilfe eines angepassten Algorithmus zu einer vollständigeren Genomsequenz zusammengesetzt. Die Ergebnisse zeigten, dass der Entwurf eine 99%-Abdeckung der erwarteten Sequenz erreichte und 99% auch in Bezug auf Struktur und Basenpaargenauigkeit übertraf.
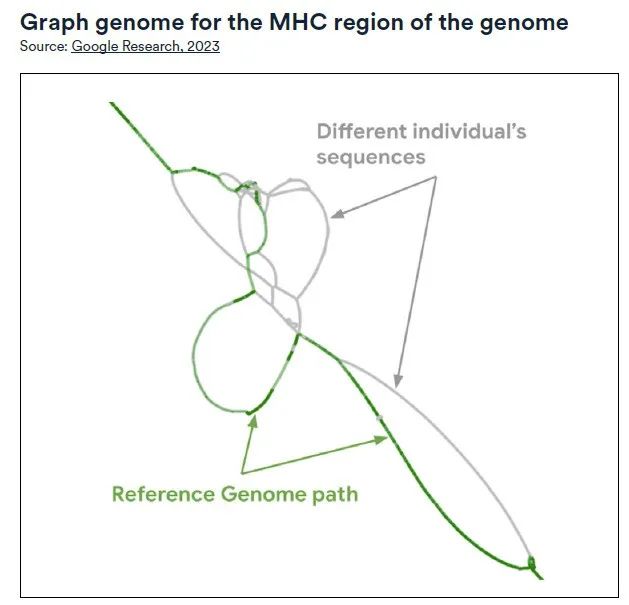
Im Vergleich zum alten, auf GRCh38 basierenden Arbeitsablauf ist der neue Entwurf bei der Analyse von Kurzlesedaten effizienter.Der Fehler bei der Entdeckung kleiner genetischer Varianten wurde um 34% reduziert, während die Entdeckungsrate struktureller Varianten des Haplotyps um 104% verbessert wurde, was 119 Millionen Basenpaare hinzufügte.Darüber hinaus enthüllte der neue Entwurf auch zwei wichtige neue Komponenten, die die Genexpression regulieren: HIRA und SATB2. Diese Erkenntnisse sind von großer Bedeutung für ein tieferes Verständnis der Struktur und Funktion des menschlichen Genoms.
2024: KI bestimmt die Zukunft der wissenschaftlichen Forschung
Künstliche Intelligenz mit ihrem erstaunlichen Potenzial wird zu einer zentralen Triebkraft für den wissenschaftlichen Fortschritt und die Weiterentwicklung der Medizin. Im Jahr 2024 wird die rasante Entwicklung der KI zu revolutionären Veränderungen in der wissenschaftlichen Forschung und Medizin führen, und zwar mit einer Geschwindigkeit und Wirkung, die weitaus größer ist als je zuvor. KI beschleunigt nicht nur die Wissensansammlung und den Innovationszyklus, sondern definiert auch die Art und Weise neu, wie wir komplexe Probleme verstehen und lösen.
Im Bereich der wissenschaftlichen ForschungKI-Algorithmen und -Modelle unterstützen Wissenschaftler bei der Verarbeitung und Analyse riesiger Datensätze und bringen tiefe Erkenntnisse ans Licht, die hinter den Daten verborgen sind. Sie haben enorme Vorteile bei der Simulation und Vorhersage des Verhaltens komplexer Systeme gezeigt und zu bahnbrechenden Entdeckungen in vielen Bereichen der Grundlagenforschung wie Physik, Chemie und Biologie geführt.
Im medizinischen BereichKI-gestützte Diagnosetools werden immer präziser und ermöglichen eine frühere Erkennung von Krankheitsanzeichen und eine rechtzeitigere Behandlung der Patienten. Gleichzeitig kann die Anwendung von KI in der personalisierten Medizin durch die Analyse individueller genetischer Informationen und Biomarker präzisere Behandlungspläne für Patienten erstellen, wodurch die Behandlungsergebnisse und die Lebensqualität der Patienten erheblich verbessert werden.
Auch,Die Rolle der KI bei der Arzneimittelentwicklung kann nicht unterschätzt werden.Durch die Vorhersage der Aktivität von Molekülen und der Nebenwirkungen von Medikamenten verkürzt es den Zyklus neuer Medikamente vom Labor bis zur Markteinführung erheblich, senkt die F&E-Kosten und beschleunigt den Prozess der Markteinführung neuer Medikamente.
Man kann sagen, dass jeder Fortschrittsschritt in der KI wie ein Stein ist, der in den langen Fluss der menschlichen Weisheit geworfen wird, Wellen schlägt und die Grenzen der wissenschaftlichen Forschung und Medizin erweitert. Menschen, die gut mit Werkzeugen umgehen können, werden die Kraft dieser Erregungen letztendlich nutzen, um in eine neue Ära größerer Intelligenz und Gesundheit zu gelangen.








