Command Palette
Search for a command to run...
6 Klassische Machine-Learning-Datensätze, Gewählt Von 3w+-Benutzern, Zur Sammlung Empfohlen

Inhalt auf einen Blick: Diese Ausgabe fasst 6 Datensätze mit der größten Anzahl superneuronaler Downloads zusammen und deckt Bereiche wie Bilderkennung, maschinelle Übersetzung und Fernerkundung ab. Diese Datensätze sind von hoher Qualität und großem Umfang und aufgrund ihrer Popularitätsbescheinigung eine Sammlung und Aufbewahrung wert. Schlüsselwörter: Datensatz, maschinelle Übersetzung, maschinelles Sehen
Datensätze sind die Grundlage für das Training von Modellen des maschinellen Lernens. Hochwertige öffentliche Datensätze sind von großer Bedeutung für die Modellierung von Trainingseffekten und der Zuverlässigkeit von Forschungsergebnissen.
Seit seiner Einführung hat HyperAI eine große Anzahl hochwertiger öffentlicher Datensätze für Data-Science-Praktiker bereitgestellt.In dieser Ausgabe haben wir 6 beliebte Datensätze ausgewählt.Es wurde insgesamt 32.569 Mal heruntergeladen.Ich hoffe, dass diese Datensätze den Entwicklern weiterhin von Nutzen sein können~
Hinweis: Die in diesem Artikel sortierten Datensätze stammen alle von der Website:
Nr. 6: Datensatz zur 3D-Rekonstruktion des Tanks-Tempels
Verlag:Intel Labs
Enthaltene Menge:HD-Video von 21 Objekttypen
Datentyp:Video
Geschätzte Größe:52,53 GB
Veröffentlichungszeit:2017
Downloadadresse:hyper.ai/datasets/5148

Der Bilddatensatz „Tanks Temple“ bietet hochauflösende Videos, aus denen Forscher Bilder sammeln können.Führen Sie eine dreidimensionale Rekonstruktion basierend auf dem Bild durch.Der Datensatz umfasst zwei Kategorien: Trainingsdaten und Testdaten, wobei die Testdaten in eine Mittel- und eine Fortgeschrittenengruppe unterteilt sind.
Nr. 5: DOTA-Luftbilddatensatz
Verlag:Wuhan-Universität
Enthaltene Menge:2.806 Luftbilder
Datentyp:Bilder
Geschätzte Größe:35,38 GB
Veröffentlichungszeit:2017
Downloadadresse:hyper.ai/datasets/4920

DOTA steht für A Large-scale Dataset for Object DeTection in Aerial Images (Ein großformatiger Datensatz zur Objekterkennung in Luftbildern). Es handelt sich um einen Bilddatensatz mit 2.806 Luftbildern.Es dient der Zielerkennung in Luftbildern, um Objekte im Bild zu finden und auszuwerten.
Zu diesen Bildquellen zählen unterschiedliche Sensoren und Plattformen. Die Pixelgröße jedes Bildes reicht von 800*800 bis 4000*4000 und enthält Objekte mit unterschiedlichen Maßstäben, Ausrichtungen und Formen.
Frühere Versionen finden Sie unter:
DOTA-Datensatz: 2.806 Fernerkundungsbilder, fast 190.000 annotierte Instanzen
Nr. 4: VGG-Face2-Gesichtserkennungsdatensatz
Verlag:Universität Oxford
Enthaltene Menge:3,31 Millionen Bilder
Datentyp:Bilder
Geschätzte Größe:37,49 GB
Veröffentlichungszeit:2015
Downloadadresse:hyper.ai/datasets/5711

VGG-Face2 ist ein Gesichtsbilddatensatz, der Gesichtsdaten von insgesamt 9131 Personen enthält. Die Bilder stammen alle aus der Bildersuche von Google.Die Personen im Datensatz unterscheiden sich stark hinsichtlich Körperhaltung, Alter, Rasse und Beruf.Dieser Datensatz wurde 2015 von der Visual Geometry Group des Department of Engineering Science der Universität Oxford veröffentlicht und das zugehörige Papier trägt den Titel „Deep Face Recognition“.
Nr. 3: UCAS-AOD Fernerkundungsbilddatensatz
Verlag:Universität der Chinesischen Akademie der Wissenschaften
Enthaltene Menge:910 Bilder
Datentyp:Bilder
Geschätzte Größe:3,24 GB
Veröffentlichungszeit:2014
Downloadadresse:hyper.ai/datasets/5419

UCAS-AOD ist ein Fernerkundungsbilddatensatz.Zur Flugzeug- und Fahrzeuginspektion.Dieser Datensatz wurde erstmals 2014 von der University of Science and Technology of China veröffentlicht und 2015 ergänzt. Zu den zugehörigen Artikeln gehört „Orientation Robust Object Detection in Aerial Images Using Deep Convolutional Neural Network“.
Nr. 2: OpenMantra-Comic-Maschinenübersetzungsdatensatz
Verlag:Universität Tokio
Enthaltene Menge:214 Seiten Comics
Datentyp:JSON-Dateien, Bilder
Geschätzte Größe:32,46 MB
Veröffentlichungszeit:2020
Downloadadresse:hyper.ai/datasets/14137
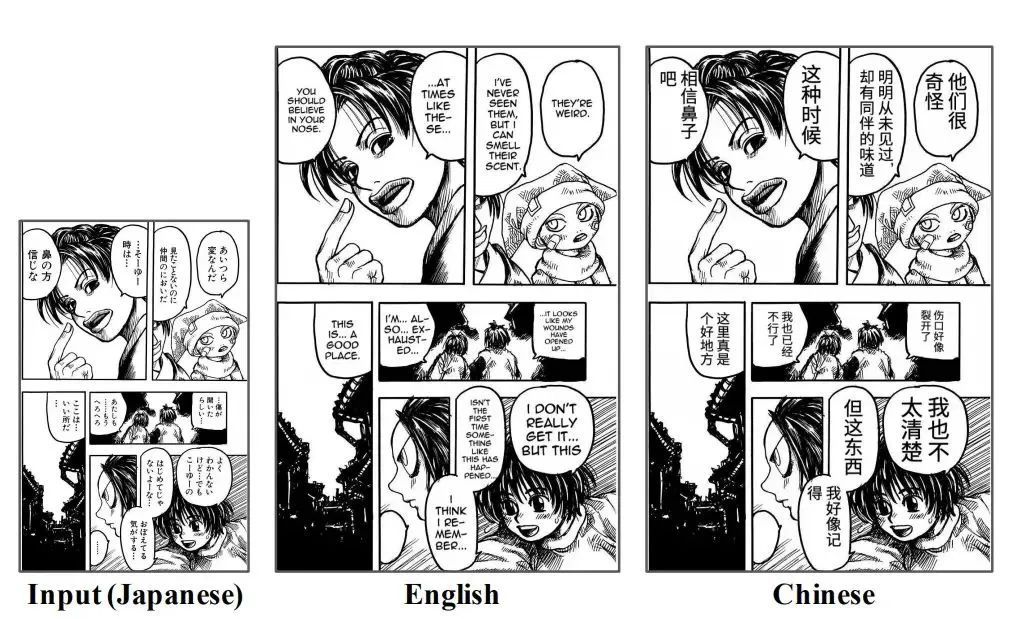
OpenMantra ist ein Datensatz zur maschinellen Übersetzungsbewertung japanischer Comics, der Comics in fünf verschiedenen Stilen enthält (Fantasy, Romantik, Kampf, Mystery, Slice of Life).Der Datensatz enthält 1593 Sätze, 848 Szenen und 214 Comicseiten.Veröffentlicht vom Mantra Team, Universität Tokio.
Frühere Pushs finden Sie unter:
HyperAI: Comic-Übersetzung, eingebettete Wort-KI, Artikel der Universität Tokio in AAAI‘21 enthalten 3 Likes · 1 Kommentar
Nr. 1: ImageNet 10-Bilderkennungsdatensatz
Verlag:Princeton Universität
Enthaltene Menge:15 Millionen Bilder
Datentyp:Bilder
Geschätzte Größe:860,55 GB
Veröffentlichungszeit:2009
Downloadadresse:hyper.ai/datasets/4889

ImageNet ist derzeit die weltweit größte Bilderkennungsdatenbank, die von Fei-Fei Li, Professor an der Stanford University, und anderen erstellt wurde.Wird hauptsächlich zur Bildklassifizierung und Zielerkennung im Bereich der maschinellen Bildverarbeitung verwendet.
Der Datensatz ist gemäß der WordNet-Hierarchie organisiert, wobei jeder Knoten (auch Kategorie genannt) aus Hunderten oder sogar Tausenden von Bildern besteht. Der Datensatz enthält insgesamt 22.000 Bildkategorien und rund 15 Millionen Bilder.
Frühere Versionen finden Sie unter:
Diese Entscheidung machte Fei-Fei Li zur Königin der KI-Branchemp.weixin.qq.com/s/VyKUmG512pFJ3XTgVf4Qjg
Oben sind die 6 häufig heruntergeladenen Datensätze von hyper.ai aufgeführt, die in dieser Ausgabe empfohlen werden. Klicken Sie am Ende des Artikels auf weitere hochwertige öffentliche Datensätze für die Datenwissenschaft.Lesen Sie den Originalartikel,Oder besuchen Sie den folgenden Link zum Herunterladen:
Dieser Artikel wurde erstmals auf dem öffentlichen WeChat-Konto „HyperAI Super Neural Network“ veröffentlicht.6 klassische Machine-Learning-Datensätze, gewählt von 3w+-Benutzern, zur Sammlung empfohlen』
-- über--








