HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي

Paper2Video: توليد فيديو تلقائي من الأوراق العلمية

سد الفجوة بين الوعد والأداء لترميز FP4 في التصغير الدقيق


























Paper2Video: توليد فيديو تلقائي من الأوراق العلمية
سد الفجوة بين الوعد والأداء لترميز FP4 في التصغير الدقيق
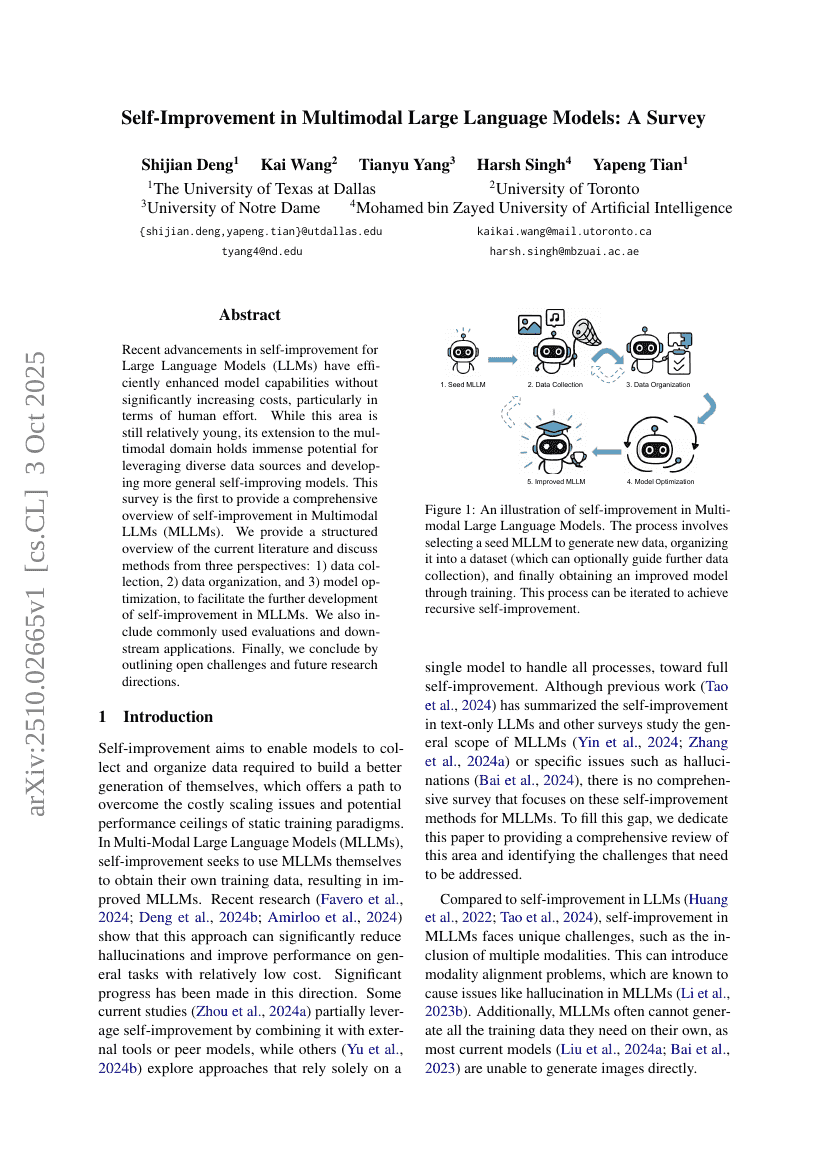
التحسين الذاتي في النماذج الكبيرة لغوية متعددة الوسائط: مراجعة
أضف سياساتك! تحسين السياسات الروبوتية القائمة على التشتت أو التدفق من خلال التكوين على مستوى التوزيع في وقت الاختبار
تنمو النماذج الكبيرة للتفكير بشكل أفضل من خلال التوافق من خلال التفكير الخاطئ
نماذج اللغة الكبيرة متعددة الوسائط الفعّالة من خلال التقطيع المتسق التدريجي
أبريل-1.5-15ب-فكيّر
StockBench: هل يمكن لوكالات الذكاء الاصطناعي الكبيرة أن تُتداول الأسهم بربحية في الأسواق الحقيقية؟
التدريب التفاعلي: تحسين الشبكة العصبية المدعومة بالتعليقات
StealthAttack: تسميم بالانفجار الثلاثي الأبعاد المتماسك عبر وهم موجه بالكثافة
ExGRPO: التعلّم من التجربة لاستنتاج الاستنتاج
Self-Forcing++: نحو توليد فيديو عالي الجودة بمقاييس دقيقة
LongCodeZip: ضغط السياق الطويل للنماذج اللغوية للبرمجة
PIPer: إعداد البيئة على الجهاز من خلال التعلم المعزز عبر الإنترنت
إعادة التفكير في نماذج المكافأة لتمديد الوقت المخصص للاختبار في مجالات متعددة
الاستكشاف في نماذج اللغة الكبيرة عبر تحسين تخصيص الميزانية: RL للحقيبة السياقية
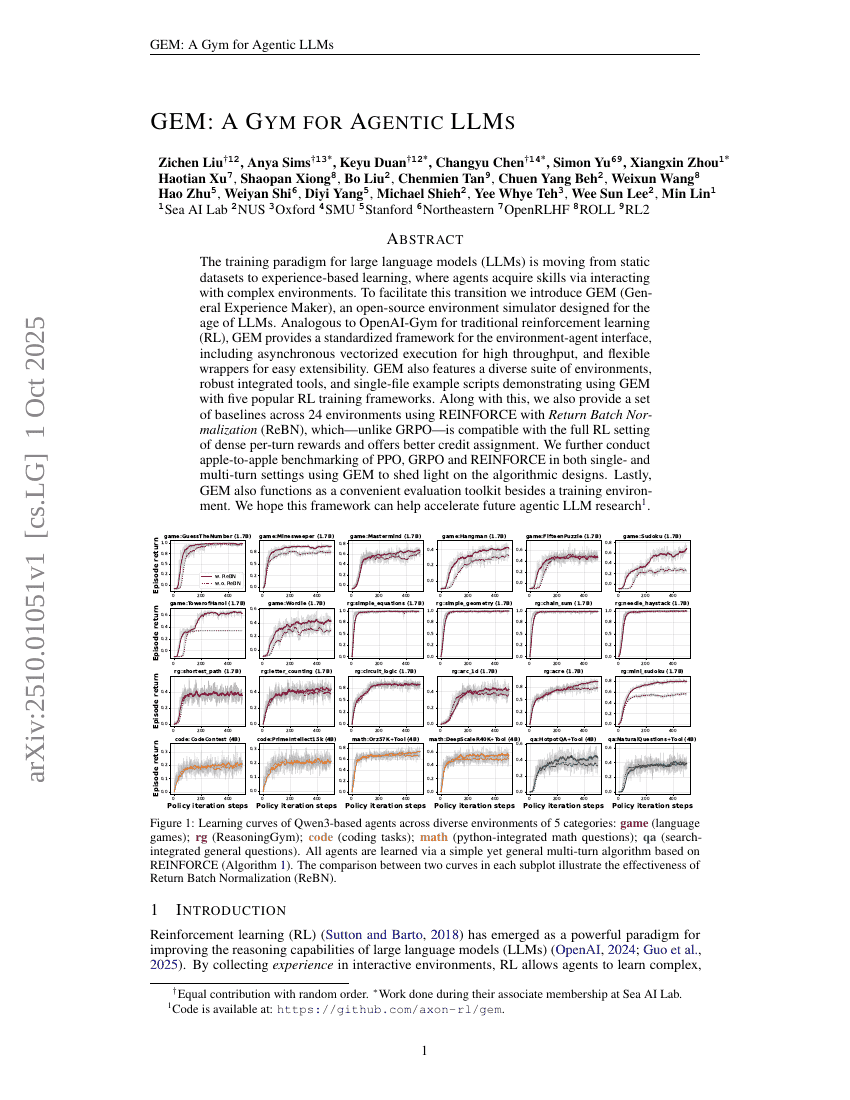
GEM: حديقة ألعاب للنماذج اللغوية الواعية
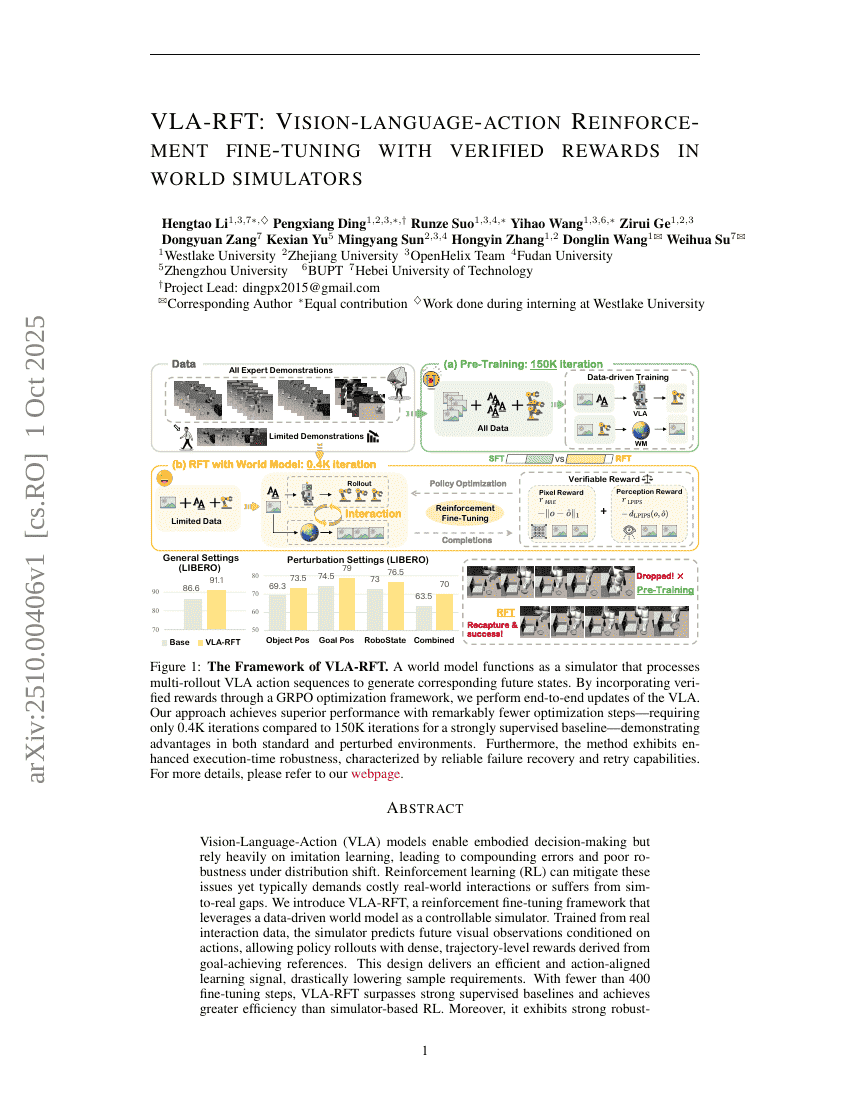
VLA-RFT: التدريب الدقيق المعزز بالفعل واللغة والرؤية مع مكافآت مُتحقق منها في محاكيات العالم
ديب سيرش: التغلب على عقبة التعلم المعزز مع مكافآت قابلة للتحقق من خلال البحث الشجري مونت كارلو
OceanGym: بيئة معيارية للوكالات المتشكلة تحت الماء
ترث رل: تحفيز نماذج لغة كبيرة صادقة من خلال التعلم المعزز
الانتصار في مخاطرة التخفيض: نهج موحد للتخفيض المشترك للعينات والرموز لتحقيق التخصيص الفعّال الخاضع للإشراف
مُفْرَخَة التنين: الربط المفقود بين المحول والأنماط العصبية
صفر الرؤية: تحسين ذاتي مُ-scalable للنماذج اللغوية والبصرية من خلال لعب ذاتي استراتيجي مُمَلَّه
MCPMark: معيار لاختبار التحميل في الاستخدامات الواقعية والشاملة لـ MCP
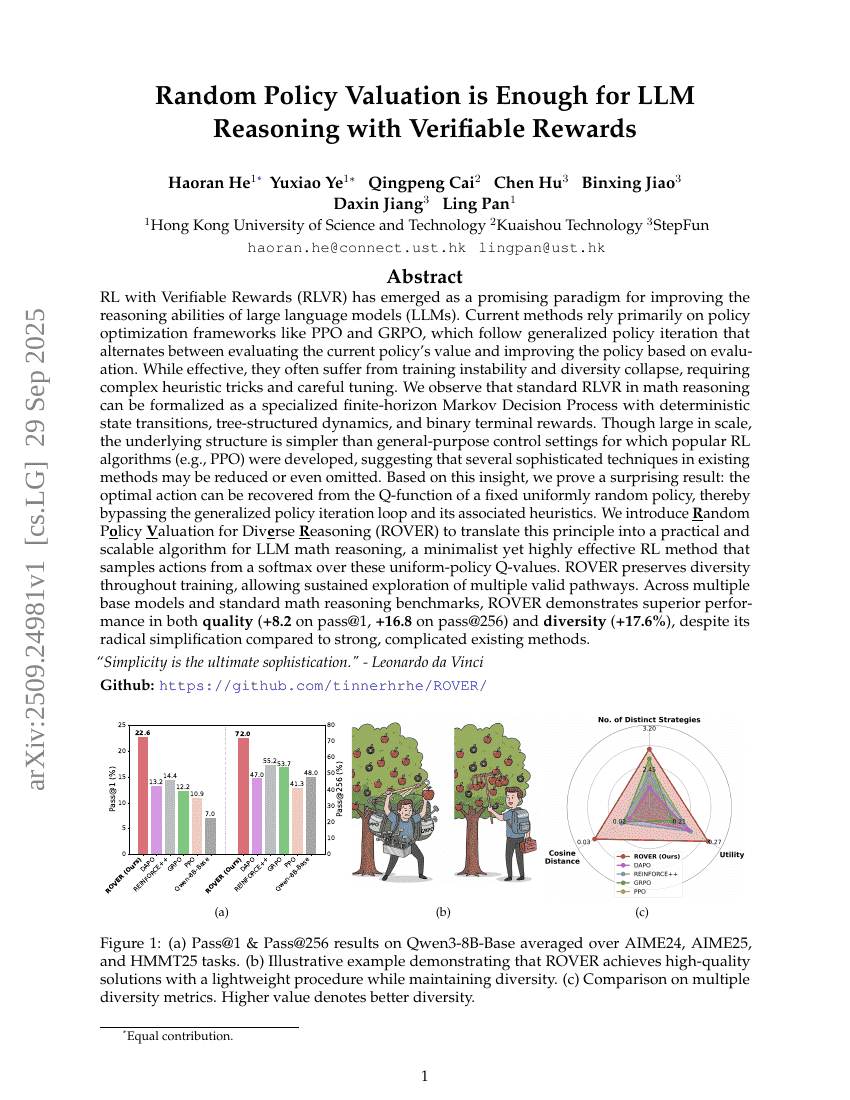
كفاية تقييم السياسة العشوائية للتفكير في نماذج اللغة الكبيرة مع المكافآت القابلة للتحقق
تمكين عُلماء الذكاء الاصطناعي من خلال أداة Universe
متى يكون الاستدلال مهمًا؟ دراسة مُحكَمة لمساهمة الاستدلال في أداء النموذج
تحسين التفضيلات ناش متعددة اللاعبين
StableToken: مُحَوِّل صوتيّ للسياق مُقاوم للضوضاء لنموذج لغوي صوتي مُرن
التحفيز اللغوي التلقائي: ما وراء الندرة في محولات التشتت من خلال الانتباه الخطي النادر القابل للضبط الدقيق
سيمبل فولد: طي البروتينات أبسط مما تظن
التحسين الذاتي في النماذج الكبيرة لغوية متعددة الوسائط: مراجعة
أضف سياساتك! تحسين السياسات الروبوتية القائمة على التشتت أو التدفق من خلال التكوين على مستوى التوزيع في وقت الاختبار
تنمو النماذج الكبيرة للتفكير بشكل أفضل من خلال التوافق من خلال التفكير الخاطئ
نماذج اللغة الكبيرة متعددة الوسائط الفعّالة من خلال التقطيع المتسق التدريجي
أبريل-1.5-15ب-فكيّر
StockBench: هل يمكن لوكالات الذكاء الاصطناعي الكبيرة أن تُتداول الأسهم بربحية في الأسواق الحقيقية؟
التدريب التفاعلي: تحسين الشبكة العصبية المدعومة بالتعليقات
StealthAttack: تسميم بالانفجار الثلاثي الأبعاد المتماسك عبر وهم موجه بالكثافة
ExGRPO: التعلّم من التجربة لاستنتاج الاستنتاج
Self-Forcing++: نحو توليد فيديو عالي الجودة بمقاييس دقيقة
LongCodeZip: ضغط السياق الطويل للنماذج اللغوية للبرمجة
PIPer: إعداد البيئة على الجهاز من خلال التعلم المعزز عبر الإنترنت
إعادة التفكير في نماذج المكافأة لتمديد الوقت المخصص للاختبار في مجالات متعددة
الاستكشاف في نماذج اللغة الكبيرة عبر تحسين تخصيص الميزانية: RL للحقيبة السياقية
GEM: حديقة ألعاب للنماذج اللغوية الواعية
VLA-RFT: التدريب الدقيق المعزز بالفعل واللغة والرؤية مع مكافآت مُتحقق منها في محاكيات العالم
ديب سيرش: التغلب على عقبة التعلم المعزز مع مكافآت قابلة للتحقق من خلال البحث الشجري مونت كارلو
OceanGym: بيئة معيارية للوكالات المتشكلة تحت الماء
ترث رل: تحفيز نماذج لغة كبيرة صادقة من خلال التعلم المعزز
الانتصار في مخاطرة التخفيض: نهج موحد للتخفيض المشترك للعينات والرموز لتحقيق التخصيص الفعّال الخاضع للإشراف
مُفْرَخَة التنين: الربط المفقود بين المحول والأنماط العصبية
صفر الرؤية: تحسين ذاتي مُ-scalable للنماذج اللغوية والبصرية من خلال لعب ذاتي استراتيجي مُمَلَّه
MCPMark: معيار لاختبار التحميل في الاستخدامات الواقعية والشاملة لـ MCP
كفاية تقييم السياسة العشوائية للتفكير في نماذج اللغة الكبيرة مع المكافآت القابلة للتحقق
تمكين عُلماء الذكاء الاصطناعي من خلال أداة Universe
متى يكون الاستدلال مهمًا؟ دراسة مُحكَمة لمساهمة الاستدلال في أداء النموذج
تحسين التفضيلات ناش متعددة اللاعبين
StableToken: مُحَوِّل صوتيّ للسياق مُقاوم للضوضاء لنموذج لغوي صوتي مُرن
التحفيز اللغوي التلقائي: ما وراء الندرة في محولات التشتت من خلال الانتباه الخطي النادر القابل للضبط الدقيق
سيمبل فولد: طي البروتينات أبسط مما تظن