Command Palette
Search for a command to run...
GSM-Symbolic: فهم قيود الاستدلال الرياضي في نماذج اللغات الكبيرة
GSM-Symbolic: فهم قيود الاستدلال الرياضي في نماذج اللغات الكبيرة
Iman Mirzadeh Keivan Alizadeh Oncel Tuzel Samy Bengio Hooman Shahrokhi Mehrdad Farajtabar
الملخص
أحدثت التطورات الأخيرة في نماذج اللغات الكبيرة (LLMs) اهتمامًا كبيرًا بقدراتها على الاستدلال الرياضي. وعلى الرغم من تحسّن الأداء على معيار GSM8K الأكثر شيوعًا، لا تزال هناك تساؤلات حول موثوقية مقاييس التقييم المُبلَّغ عنها، وذلك بالتزامن مع تقدم قدرات الاستدلال في نماذج اللغات الكبيرة (LLMs). ولتجاوز قيود التقييمات الحالية، نقدم "GSM-Symbolic"، وهو معيار تحسين تم إنشاؤه باستخدام قوالب رمزية تتيح توليد مجموعة متنوعة من الأسئلة. يمكّننا "GSM-Symbolic" من إجراء تقييمات أكثر تحكمًا، حيث يقدم رؤى أساسية ومقاييس أكثر موثوقية لقياس قدرات الاستدلال في النماذج. وتكشف نتائجنا أن نماذج اللغات الكبيرة (LLMs) تظهر تفاوتًا ملحوظًا عند الاستجابة لتطبيقات مختلفة لنفس السؤال. تحديدًا، ينخفض أداء النماذج عند تغيير القيم الرقمية في السؤال فقط ضمن معيار "GSM-Symbolic". علاوة على ذلك، نتقصى هشاشة الاستدلال الرياضي في هذه النماذج ونُظهر أن أدائها يتدهور بشكل ملحوظ مع زيادة عدد الجمل في السؤال. ونفترض أن هذا التراجع يعود إلى حقيقة أن نماذج اللغات الكبيرة (LLMs) الحالية غير قادرة على القيام بالاستدلال المنطقي الحقيقي، بل تحاول فقط محاكاة خطوات الاستدلال الملاحظة في بيانات التدريب الخاصة بها.
One-sentence Summary
The authors introduce GSM-Symbolic, a benchmark utilizing symbolic templates to generate diverse questions that overcome limitations in existing evaluations such as GSM8K by revealing performance variance across numerical instantiations and significant deterioration with increased clause counts, indicating models replicate training patterns rather than perform genuine logical reasoning.
Key Contributions
- This work introduces GSM-Symbolic, an improved benchmark created from symbolic templates that allow for the generation of a diverse set of questions. The benchmark enables more controllable evaluations and provides reliable metrics for measuring the reasoning capabilities of models.
- Findings reveal that large language models exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of models declines when only the numerical values in the question are altered within the GSM-Symbolic benchmark.
- The research demonstrates that model performance significantly deteriorates as the number of clauses in a question increases. These findings support the hypothesis that current models lack genuine logical reasoning and instead replicate steps observed in training data.
Introduction
Mathematical reasoning is vital for deploying artificial intelligence in scientific and real-world applications. Current evaluations rely on static benchmarks like GSM8K, which limit robustness testing and risk data contamination. The authors address these gaps with GSM-Symbolic, a benchmark utilizing symbolic templates to generate diverse question variants for controlled evaluation. Their findings show that model performance varies across question instantiations and drops when numerical values or irrelevant clauses change. These results suggest Large Language Models depend on pattern matching rather than genuine logical reasoning.
Dataset
-
Dataset Composition and Sources
- The authors base their work on the GSM8K dataset, which includes over 8000 grade school math questions split into 7473 training and 1319 test examples.
- They introduce GSM-Symbolic to generate numerous instances with controlled difficulty, addressing risks of data contamination and sensitivity to minor question modifications.
-
Processing and Key Details
- Templates are created from GSM8K test examples by identifying variables, domains, and conditions such as divisibility to ensure whole number answers.
- Common proper names are used for persons, foods, and currencies while automated checks verify that original values do not appear in the template.
- Manual review covers 10 random samples per template, with additional review triggered if fewer than two models answer a question correctly during evaluation.
- Numerical ranges align with the original GSM8K test set to focus on logical reasoning rather than arithmetic skills within known accuracy boundaries.
-
Model Usage and Evaluation
- The data serves as a reliable evaluation framework to view LLM performance as a distribution across various problem instances.
- This approach assesses mathematical capabilities and robustness to diverse problem difficulties and augmentations beyond a single fixed metric.
Experiment
This work evaluates the reasoning capabilities of various large language models using GSM-Symbolic, a benchmark generated by mutating GSM8K templates to test reliability and robustness. Results indicate significant performance variance across different question instantiations, with original GSM8K metrics often overstating true capability due to potential data contamination. Additional experiments demonstrate that reasoning abilities are fragile, as accuracy declines with increased numerical complexity or irrelevant information, suggesting models rely on pattern matching rather than formal logical understanding.
The authors evaluate various large language models on the GSM8K benchmark and its symbolic variants to assess reasoning reliability. The results indicate a consistent performance drop when models are tested on symbolic variations compared to the original GSM8K dataset, suggesting potential data contamination or reliance on pattern matching rather than formal reasoning. Furthermore, increasing question difficulty or adding irrelevant information leads to significant degradation in accuracy across all tested models. Models generally achieve higher accuracy on the standard GSM8K benchmark compared to the symbolic variations. Increasing question difficulty by adding clauses leads to lower performance scores compared to the base symbolic version. Adding seemingly relevant but inconsequential information results in the lowest performance scores across the board.
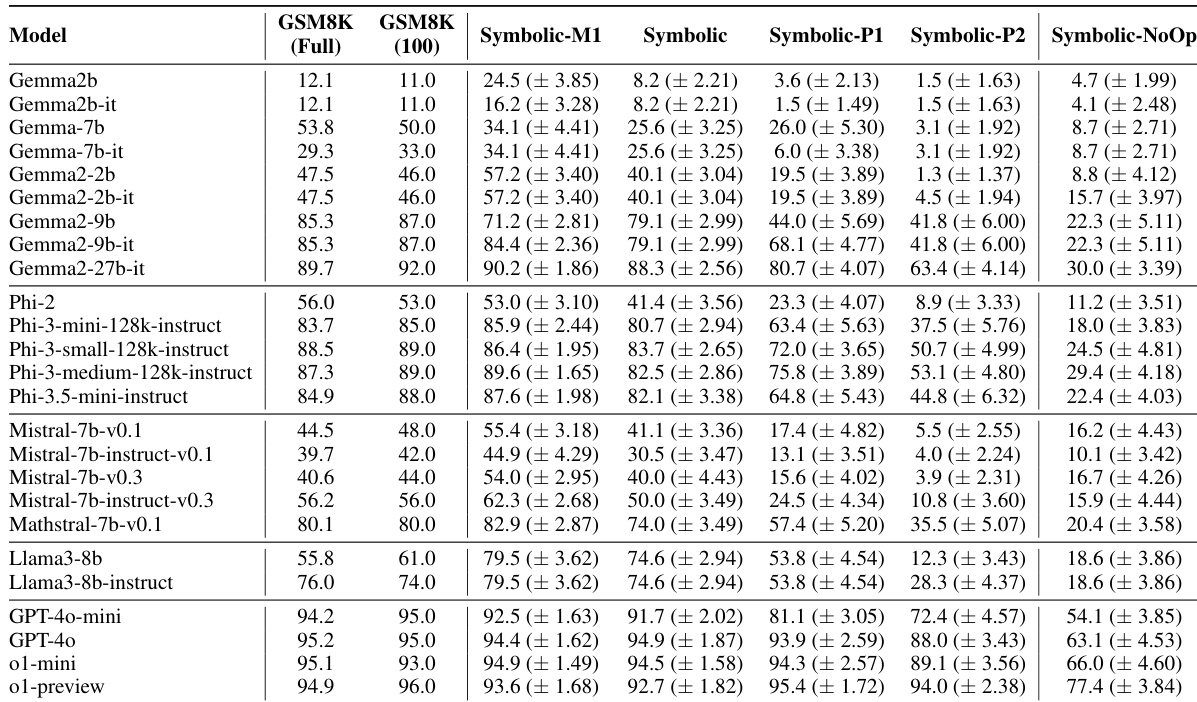
The authors compare model performance across the original GSM8K benchmark and three modified variants designed to test reasoning robustness through symbolic changes and increased difficulty. The results indicate that the original GSM8K benchmark consistently achieves higher overall accuracy compared to the modified versions, suggesting that these variations introduce challenges that slightly reduce model performance. The original GSM8K benchmark demonstrates superior overall performance compared to the modified GSM-Symbolic and GSM-P variants. Increasing question difficulty through added clauses results in a measurable drop in accuracy, with GSM-P1 and GSM-P2 scoring lower than GSM-Symbolic. Models maintain high accuracy across the benchmarks, though the specific variant of the test has a noticeable impact on the final results.
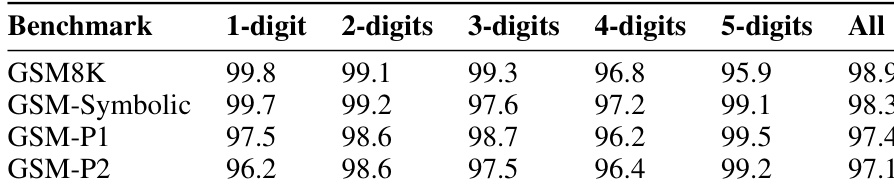
The authors evaluate large language models on the GSM8K benchmark and modified variants to assess reasoning reliability and robustness against symbolic changes. Results indicate a consistent performance drop on these variations compared to the original dataset, suggesting a potential reliance on pattern matching rather than formal reasoning. Furthermore, increasing question difficulty or adding irrelevant information leads to significant accuracy degradation across all tested models.