Command Palette
Search for a command to run...
لياب: تسريع النماذج اللغوية الكبيرة للرياضيات الرسمية باستخدام أطر العمل الوكيلية
لياب: تسريع النماذج اللغوية الكبيرة للرياضيات الرسمية باستخدام أطر العمل الوكيلية
الملخص
تُظهر النماذج اللغوية الكبيرة (LLMs) قدرة قوية على الاستدلال الرياضي غير الرسمي، لكنها تواجه صعوبات في توليد براهين قابلة للتحقق آلياً بلغات رسمية مثل Lean. نقدم إطار عمل LEAP (LLM-in-Lean Environment Agentic Prover)، وهو إطار عملي (Agentic) يمكّن النماذج الأساسية متعددة الأغراض من تحقيق أداءً متفوقاً في البرهان الآلي للنظريات الرسمية. يستفيد LEAP من قدرات النموذج الأساسي، مثل الاستدلال غير الرسمي، واتباع التعليمات، والتحسين الذاتي التكراري. من خلال تفكيك المشكلات المعقدة إلى وحدات أصغر، يربط النظام بين بناء البراهين الرسمية والمخططات غير الرسمية من خلال التفاعل المستمر مع مترجم Lean. ولتقديم تقييم دقيق يتجاوز الاختبارات المعيارية التي أصبحت مشبعة بشكل متزايد، نقدم Lean-IMO-Bench، وهو اختبار معياري يعتمد على مشبهات بأسلوب أولمبياد الرياضيات الدولية (IMO) مُصاغة بلغة Lean، تتميز بإعلانات قصيرة لكنها تتطلب برهنة متعددة الخطوات وغير روتينية عبر طيف واسع من مستويات الصعوبة. تجريبياً، في مسابقة بوثامان لعام 2025 (Putnam Competition)، وهي مسابقة رياضية سنوية للطلاب الجامعيين في أمريكا الشمالية، نجح LEAP في حل جميع المشكلات الـ12، مساوياً بذلك أحدث الإنجازات التي حققتها النماذج الرائدة في الرياضيات الرسمية؛ وعلى Lean-IMO-Bench، ارتفع معدل الحل الرسمي لمرة واحدة (one-shot) للنماذج اللغوية الكبيرة العامة لدى LEAP من أقل من 10% إلى 70%، متجاوزاً بشكل ملحوظ الحد المعايير البالغ 48% الذي وضعته أنظمة متخصصة في أولمبياد الرياضيات الدولية على مستوى الحصول على الميدالية الذهبية. علاوة على ذلك، نوضح المنفعة البحثية لـLEAP من خلال أتمتة صياغة البراهين المعقدة لتحديات تركيبية مفتوحة، بما في ذلك برهان مُتحقق من صحة لجزء فرعي رئيسي في تحلل هاملتونيان (Hamiltonian decomposition) الخاص برتب كايلي الزوجية وفقاً لعمل كنوث (Knuth).
One-sentence Summary
LEAP (LLM-in-Lean Environment Agentic Prover) enables general-purpose foundation models to achieve state-of-the-art performance in automated formal theorem proving by bridging formal proof construction with informal blueprints through continuous interaction with the Lean compiler, solving all 12 problems in the 2025 Putnam Competition and boosting one-shot formal solve rates from below 10% to 70% on the Lean-IMO-Bench while autonomously formalizing complex proofs for open combinatorial challenges including a verified proof for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.
Key Contributions
- The paper introduces LEAP, an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance in automated formal theorem proving. This method decomposes complex problems into smaller units and bridges formal proof construction with informal blueprints through continuous interaction with the Lean compiler.
- To provide rigorous evaluation beyond saturated benchmarks, the work presents Lean-IMO-Bench, a collection of IMO-style problems formalized in Lean with highly non-routine and multi-step proofs. This dataset targets elementary statements requiring structurally intricate solutions across a wide range of difficulty levels.
- Experimental results demonstrate that LEAP solves all 12 problems on the 2025 Putnam Competition and increases the one-shot formal solve rate on Lean-IMO-Bench from below 10% to 70%. These findings indicate that structured, iterative interaction with the proof environment is more critical than formal language comprehension alone for general-purpose LLMs.
Introduction
Large Language Models excel at informal mathematical reasoning but struggle to generate mechanically verifiable proofs in formal languages like Lean. This limitation matters because natural language solutions often contain hallucinations that are difficult to verify, whereas formal languages provide automated verification with guaranteed accuracy. Existing approaches typically rely on specialized models fine-tuned on formal corpora or hybrid systems where general models only handle informal reasoning. To address this, the authors introduce LEAP, an agentic framework that enables general-purpose foundation models to achieve leading performance in automated formal theorem proving without specialized fine-tuning. LEAP decomposes complex problems into smaller units and iteratively refines proofs using compiler feedback to bridge informal blueprints with formal construction. Additionally, the team releases Lean-IMO-Bench to evaluate progress on challenging multi-step problems beyond saturated benchmarks.
Dataset
- Dataset Composition and Source: The authors introduce LEAN-IMO-BENCH, a curated collection of 60 problems building upon the IMO-ProofBench suite from Luong et al. (2025).
- Subset Details: The benchmark divides evenly into a Basic set and an Advanced set of 30 problems each. The Basic set spans pre-IMO to IMO-Medium difficulty with 8 algebra, 8 combinatorics, 8 number theory, and 6 geometry problems. The Advanced set includes novel problems up to IMO-Hard difficulty featuring 8 algebra, 8 combinatorics, 6 number theory, and 8 geometry problems.
- Usage in Paper: The team utilizes this data primarily for the Formal Theorem Proving task to evaluate model performance, noting that natural language reasoning does not guarantee success in formal code generation.
- Processing and Verification: Lean experts manually formalized and verified every problem statement to ensure high accuracy. The corresponding Lean solutions are kept concise to avoid overhead from complex modern mathematical theories while relying on elementary mathematical backgrounds.
Method
The authors introduce LEAP, an agentic framework for automated theorem proving that leverages hierarchical decomposition and planning to bridge the gap between general LLMs and formal verification. Rather than synthesizing a complete proof in a single pass, LEAP incrementally drafts blueprints, decomposes Lean goals into supporting lemmas, and maintains the evolving proof plan as an AND-OR DAG.
The overall workflow is depicted in the framework diagram below.
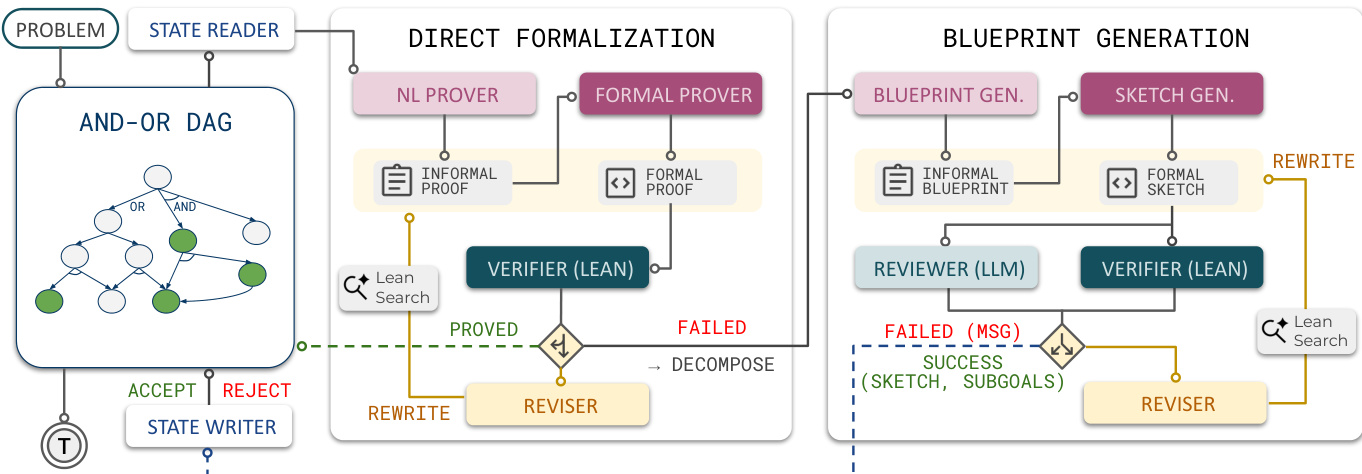
Given an input theorem, the system registers the Lean statement as the root goal, represented as an OR node in the AND-OR DAG. A State Reader retrieves the current goal's statement, dependencies, and related lemmas. LEAP first attempts a direct proof strategy. This involves an NL Prover generating an informal argument, which a Formal Prover translates into Lean code. A Verifier checks the candidate against the Lean compiler. If the proof fails, a Reviser uses feedback to attempt a rewrite.
If direct proving fails, the system shifts to a decomposition strategy known as Blueprint Generation. The agent drafts an informal blueprint proposing intermediate lemmas, then translates this plan into a Lean proof sketch. Crucially, the sketch proves the current goal assuming only the proposed lemmas are true: the main theorem body is sorry-free, while sorry placeholders are permitted only in the newly proposed lemma statements. This sketch is validated by a Verifier (Lean) and a Reviewer (LLM). The Reviewer assesses whether the subgoals are relevant and make the problem easier, acting as a search filter to prevent the agent from expanding weak blueprints.
When a sketch is accepted, it is added as an AND node, and the proposed lemmas are added as child OR nodes. This ensures that once all child subgoals are proved, the parent goal is also proved. The State Writer then checks that the update preserves acyclicity before committing it to the DAG. The agent then recursively processes the newly created subgoals.
The dependency structure of the proof plan is illustrated in the DAG example below.
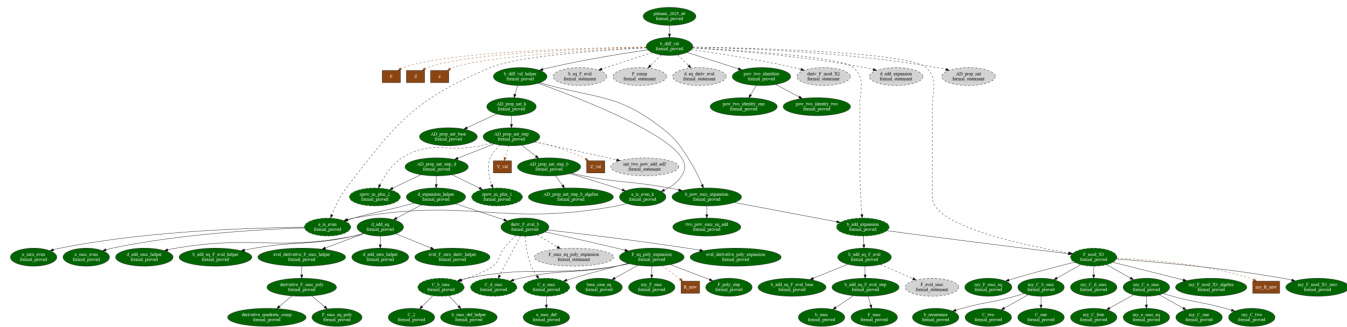
This structure supports two central advantages. First, monotone refinement allows the search to focus on expanding descendants without restructuring the established dependency order. Second, lemma memoization stores intermediate lemma statements as shared nodes, allowing them to be reused whenever the same subproblem arises in different branches. This also supports anticipatory lemma planning, where auxiliary lemmas not immediately required by the current sketch are proposed to support later proof steps.
The method relies on three tightly coupled design choices. Hierarchical memoization via the DAG preserves progress and reuses lemmas across branches. Interleaved informal-formal planning connects natural-language strategies with executable Lean code, ensuring that each formal attempt is paired with an informal rationale. Finally, verification-guided proof search uses compiler feedback and LLM-based review to accept, revise, decompose, or abandon candidate branches, effectively guiding the search through the formal proof space.
Experiment
The evaluation assesses the LEAP framework against multiple baselines on the Putnam 2025 and Lean-IMO-Bench datasets to validate its formal proving capabilities. Results indicate that LEAP significantly outperforms specialized and general models by resolving complex search bottlenecks and achieving complete success on challenging benchmarks where others fail. Ablation studies further demonstrate that the system's DAG-based memory and LLM-guided review mechanisms are critical for reducing redundant derivations and pruning unproductive proof branches, while case studies on open combinatorial problems confirm the framework's ability to autonomously synthesize rigorous proofs for intricate mathematical tasks.
The study compares one-shot and iterative formalization performance between a specialized automated theorem prover and a general foundation model. The general model demonstrates significant improvement when allowed iterative revision steps, whereas the specialized model shows no benefit from the feedback loop. This highlights the importance of general reasoning capabilities for handling the complex context required in iterative proof generation. The general foundation model outperforms the specialized prover in both one-shot and iterative evaluation settings. Iterative revision steps lead to substantial performance gains for the general model, while the specialized model fails to benefit from the feedback loop. These findings suggest that interpreting compiler errors and maintaining context are capabilities where general models excel over specialized provers.

The authors compare a full DAG architecture against a naive tree variant to evaluate the impact of global lemma sharing on formal proof generation. The results indicate that the Full DAG configuration consistently outperforms the baseline, particularly in advanced algebra and number theory tasks where it achieves perfect solve rates. This suggests that maintaining a global proof memory significantly enhances the system's ability to handle complex mathematical reasoning. The Full DAG configuration achieves perfect performance in Algebra and Number Theory across both difficulty tiers, whereas the tree baseline struggles with advanced Number Theory. Overall performance shows a substantial improvement with the Full DAG setup, especially in the Advanced set where the tree baseline performs significantly worse. While Geometry remains the most challenging category, the Full DAG configuration manages to solve some problems where the Naive Tree baseline fails completely.

The data presents baseline performance of Gemini models on the Lean-IMO-Bench across three evaluation tasks: natural language proofing, formal theorem proving, and formal proof translation. While natural language proof generation achieves moderate success, the models struggle significantly with generating or translating formal Lean proofs. Performance consistently degrades when moving from the Basic set to the Advanced set, highlighting the difficulty current foundation models face with complex formal verification without specialized agentic frameworks. Natural language proof generation outperforms formal theorem proving and proof translation tasks. Performance drops significantly on the Advanced set compared to the Basic set for all evaluated tasks. Average success rates for formal tasks remain very low even with extensive sampling attempts.

The the the table compares the problem-solving capabilities of the LEAP framework against various baseline methods on the Putnam 2025 benchmark. While direct formalization baselines fail to solve any problems, the proposed LEAP framework achieves a perfect solve rate across the entire dataset. This performance significantly outperforms other systems, including the specialized Aristotle model which solves a majority but not all problems. Direct formalization baselines like Gemini-3.1-pro and Goedel-Prover-V2-32B fail to solve any of the benchmark problems. The LEAP framework successfully solves all problems in the benchmark, achieving a higher success rate than all other compared methods. Specialized systems like Aristotle and Hilbert show partial success but fall short of the complete coverage achieved by LEAP.

The evaluation on the Lean-IMO-Bench compares the proposed LEAP framework against direct formalization and agentic baselines across Basic and Advanced difficulty tiers. Results indicate that while baseline methods struggle significantly with increased complexity and specific domains like Geometry, LEAP demonstrates superior robustness and generalization. The proposed method achieves the highest overall performance and maintains perfect solve rates in Algebra and Number Theory regardless of difficulty. LEAP achieves the highest overall solve rates on the benchmark, outperforming specialized and general-purpose baselines across both difficulty tiers. Baseline models exhibit significant performance drops on the Advanced set, whereas LEAP maintains strong consistency, including perfect scores in Algebra and Number Theory. Geometry proves to be a difficult category for all methods, with performance remaining negligible across the board.
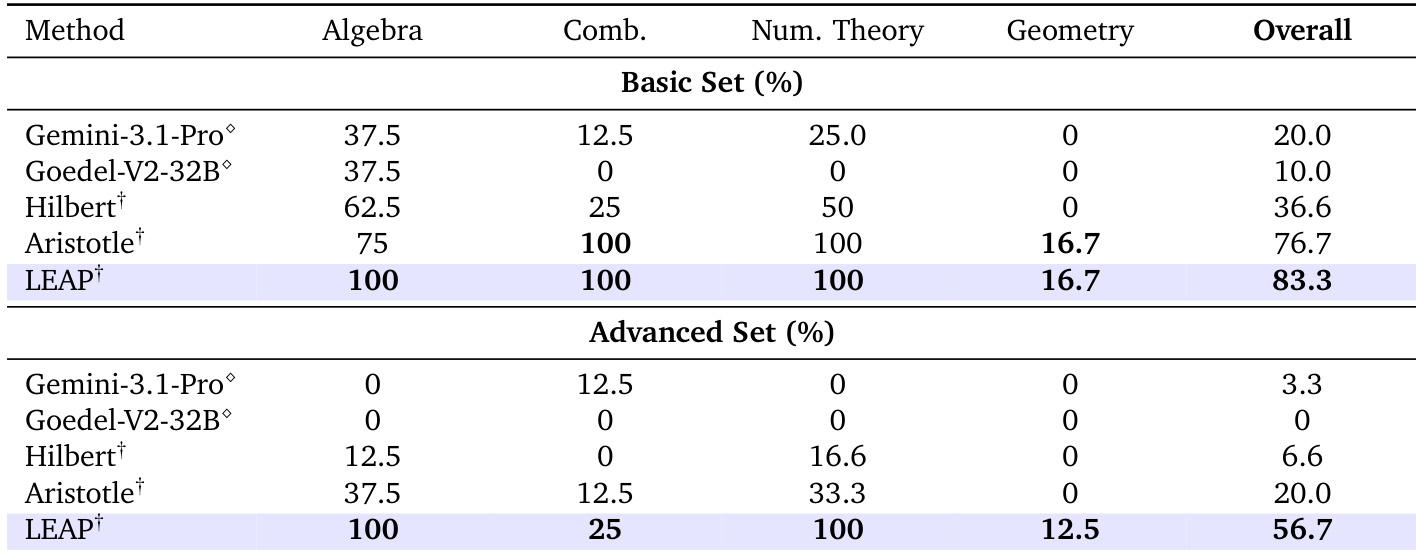
Comparative evaluations indicate that general foundation models benefit significantly from iterative revision steps and outperform specialized provers in handling complex reasoning contexts. Architectural analysis reveals that a Full DAG configuration with global lemma sharing substantially enhances performance on advanced algebra and number theory tasks compared to naive tree baselines. While standard models struggle with formal proof generation on difficult benchmarks, the proposed LEAP framework demonstrates superior robustness by achieving perfect solve rates across multiple evaluation sets.