Command Palette
Search for a command to run...
تقترح شركة Meta علماء بيانات الذكاء الاصطناعي، وتقوم شركة Autodata ببناء مجموعات بيانات تدريب/تقييم عالية الجودة.

في السنوات الأخيرة، أدى التحسين المستمر لقدرات النماذج واسعة النطاق إلى إعادة تشكيل مسار تطوير الذكاء الاصطناعي. ومع ذلك، يتزايد الإجماع على أن معيار أداء النموذج يتحول تدريجيًا من كونه "مدفوعًا بابتكار الخوارزميات" إلى كونه "مدفوعًا بجودة البيانات". في ظل ندرة البيانات عالية الجودة المصنفة يدويًا وارتفاع تكلفتها، أصبحت البيانات الاصطناعية تدريجيًا أسلوبًا داعمًا مهمًا في مرحلة ما بعد التدريب. فهي قادرة على توليد حالات هامشية وسيناريوهات نادرة نسبيًا في مجموعات البيانات الواقعية؛ وتقليل صعوبة ووقت التصنيف اليدوي؛ وفي بعض الحالات، توليد عينات تدريبية بتوزيعات أكثر تعقيدًا من البيانات البشرية.
مع ظهور نماذج اللغة الكبيرة (LLMs)، طُرحت "التعليم الذاتي" كطريقة لتوليد بيانات اصطناعية باستخدام نماذج قليلة أو معدومة. وانطلاقًا من ذلك، يُدمج "التعليم الذاتي المُؤَسَّس" مصادر خارجية، كالمستندات، كقيود للحد من التشويش وتعزيز التنوع. إضافةً إلى ذلك، يُدخل "التعليم الذاتي المُوجَّه" استدلالًا تسلسليًا أثناء عملية التوليد لبناء مهام أكثر تعقيدًا ودقة. وأخيرًا، تسمح فئة من أساليب "التحدي الذاتي" للوكيل المُتحدِّي بالتفاعل مع الأداة قبل اقتراح المهمة ووظيفة تقييمها. مع ذلك، لا تستطيع أي من هذه الأساليب التحكم المباشر في صعوبة البيانات وجودتها، مما يُؤدي إلى ظهور استراتيجيات تحسينية كالتصفية والتطوير والتنقيح.
وفي هذا السياق،اقترح فريق أبحاث الذكاء الاصطناعي الأساسي في ميتا (FAIR at Meta) طريقة عامة تسمى Autodata.تم توحيد وتعميم جميع الطرق المذكورة أعلاه. في هذا الإطار، يتولى نظام ذكي، يعمل كـ"عالم بيانات"، مسؤولية بناء البيانات وتنظيمها، محاكياً بذلك سير عمل عالم البيانات البشري لإنتاج بيانات عالية الجودة. لا تقتصر هذه العملية على توليد البيانات الأولية فحسب، بل تشمل أيضاً مرحلة تحليل البيانات (على غرار "المراجعة البشرية")، وتقييم أدائها، وتلخيص التجارب، والعمل بشكل متكرر على توليد حلول بيانات أفضل بناءً على هذه التقييمات.
أجرى الباحثون تجارب على مهام بحثية في علوم الحاسوب، ومهام استدلال قانوني، ومهام استدلال رياضي، وحققوا نتائج أفضل مقارنةً بأساليب بناء البيانات الاصطناعية التقليدية. علاوة على ذلك، أدى التحسين الفائق لوكيل عالم البيانات نفسه إلى تحسينات ملحوظة في الأداء.
تم نشر نتائج البحث ذات الصلة، بعنوان "Autodata: عالم بيانات فاعل لإنشاء بيانات اصطناعية عالية الجودة"، كنسخة أولية على موقع arXiv.
أبرز الأبحاث:
* توفر طريقة توليد البيانات القائمة على الوكلاء مسارًا لتحويل موارد الحوسبة الاستدلالية إلى بيانات تدريب نموذجية ذات جودة أعلى.
* يمكن أيضًا تحسين أداء وكيل عالم البيانات نفسه، مما يؤدي إلى تحسينات كبيرة في الأداء دون الحاجة إلى توجيهات بشرية أو هندسة.
* يمتلك هذا البحث القدرة على تغيير كيفية بناء المهام والمعايير المستقبلية لدفع طليعة تطوير الذكاء الاصطناعي.

عنوان الورقة:
https://hyper.ai/papers/2606.25996
مجموعة البيانات: تغطي ثلاثة سيناريوهات مهام أساسية
غطى إطار عمل Autodata ثلاثة سيناريوهات مهام أساسية في التجارب: مشاكل البحث في علوم الحاسوب، ومهام الاستدلال القانوني، ومهام الاستدلال العلمي القائمة على الكائنات الرياضية.تعتمد هذه المهام على أنظمة مصادر بيانات مختلفة لاختبار قدرة الإطار على التعميم في ظل هياكل معرفية مختلفة.
في مهام علوم الحاسوب،قام الباحثون بمعالجة أكثر من 10000 ورقة بحثية في علوم الحاسوب من مجموعة بيانات S2ORC (2022 وما بعدها).تم توليد 2800 عينة مقبولة باستخدام برنامج Agentic Self-Instruct.بعد انتهاء الحلقة، تُصفّى هذه العينات باستخدام مُدقِّق جودة قائم على خوارزمية Kimi-K2.6 لإزالة العينات التي تحتوي على مشاكل مثل تسريب معلومات خاصة بالورقة البحثية، أو عدم كفاية السياق، أو تنسيق معايير التقييم غير الصحيح. في النهاية، تُحتفظ بـ 1300 عينة عالية الجودة كمجموعة بيانات Agentic Self-Instruct لتدريب التعلّم المعزز.
في مهام الاستدلال القانوني،تُستقى البيانات من وثائق قانونية متاحة للعموم، مثل "مجموعة القوانين"، بما في ذلك أحكام المحاكم والآراء القانونية، ويتم تقييمها على منصة PRBench-Legal ومجموعتها الفرعية الصعبة PRBench-Legal-Hard. على عكس الأوراق العلمية،تتميز النصوص القانونية بقيود منطقية هيكلية أقوى واعتماد أكبر على السوابق القضائية، لذا فإن مهمة التوليد تركز بشكل أكبر على القدرة على استخراج الحقائق وتطبيق القواعد.
في مهام التفكير العلمييستند هذا البحث إلى مجموعة بيانات برينسيبيا. وقد تم إنشاء هذه المجموعة باستخدام منهجية CoT للتعليم الذاتي، وهي تغطي نطاقًا واسعًا من محتوى المقررات الدراسية في تصنيفي MSC2020 وPHYS. يتكون معيار برينسيبيا من مجموعة فرعية من المعايير الرياضية والفيزيائية الموجودة والمُعَلَّمة من قِبَل مُعلِّمين. وقد خضعت هذه الأسئلة لعملية تدقيق للتأكد من أن الإجابات تتضمن كائنات رياضية.
في جميع المهام، لا يقتصر هدف Autodata على توليد أزواج من الأسئلة والأجوبة فحسب، بل يهدف إلى توليد بيانات تدريبية يمكنها التمييز بشكل فعال بين النماذج الضعيفة والقوية.
البيانات الآلية: توظيف وكلاء أذكياء مستقلين لمحاكاة دور علماء البيانات.
يظهر التصميم الرئيسي لبرنامج Autodata في الشكل أدناه.يستخدم هذا الإطار وكيلًا ذكيًا مستقلًا لمحاكاة دور عالم البيانات.من خلال توليد البيانات بشكل متكرر، وإجراء عمليات التحقق النوعية وتقييمات الأداء الكمية، وتحليل الأفكار المكتسبة بشكل شامل، وتحديث طريقة توليد البيانات وفقًا لذلك، يمكن بناء أشكال تنفيذ مختلفة على هذا النموذج.
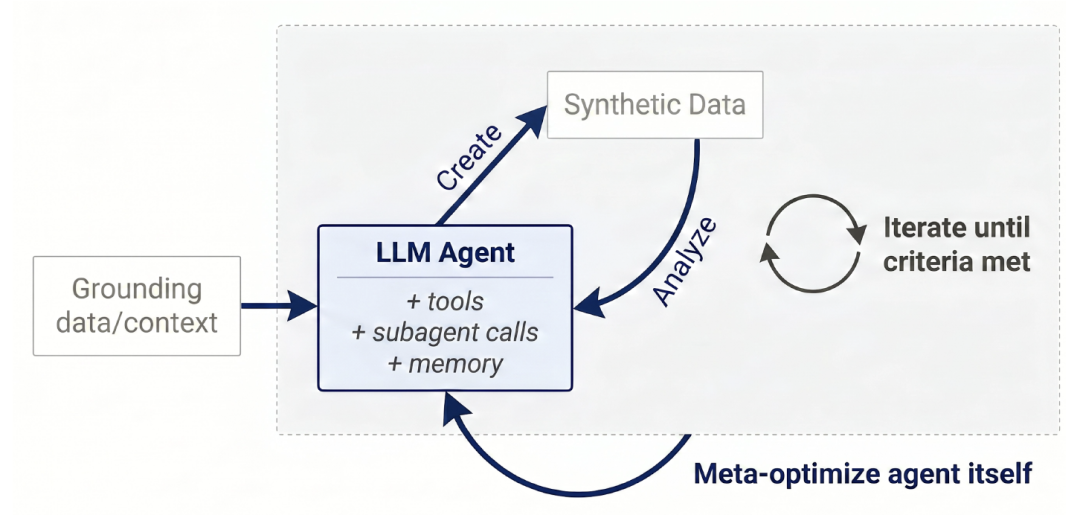
سير عمل البيانات الآلية
تتكون الحلقة الكلية من المكونات التالية:
① إنشاء البيانات
يُوفّر وكيل Autodata بيانات أساسية (مثل وثائق مُحدّدة في مجالات كالرياضيات والقانون والبرمجة، أو مصادر بيانات أخرى خاصة بالمهمة) للمساعدة في توليد البيانات. يستطيع هذا الوكيل استخدام الأدوات أو مهاراته وخبراته الحالية، والاستفادة من الموارد الحاسوبية من مرحلة الاستدلال، لتوليد بيانات التدريب والقياس المعياري لتدريب النموذج أو تقييمه. يُمكن تكرار خطوة توليد البيانات هذه بعد التحليل والتعلم اللاحقين، مما يُحسّن جودة البيانات باستمرار.
② تحليل البيانات
بعد الحصول على البيانات التي يُنتجها النظام، يقوم بتحليلها لتلخيص نقاط قوته وضعفه، وكيفية تحسينها. يمكن إجراء هذا التحليل على مستويات مختلفة: على مستوى عينة واحدة (مثل تقييم صحة المثال وجودته العالية ومدى صعوبته)، أو على مستوى مجموعة البيانات بأكملها (مثل تقييم تنوع العينات وقدرتها على تحسين أداء النموذج كبيانات تدريب). تُعاد نتائج هذه التحليلات إلى مرحلة توليد البيانات، مما يُنتج بيانات أفضل في التكرار التالي، حتى يتم استيفاء شرط التوقف.
③ حلقة عالم البيانات الشاملة
يتناوب النظام باستمرار بين "توليد البيانات وتحليلها" حتى يرضى بجودتها، لينتج في النهاية مجموعة بيانات تدريبية أو معيارية عالية الجودة. ويمكن إضافة آليات أمان أو قيود محددة إلى الحلقة الخارجية لمنع اختراق النظام. وتتيح هذه الحلقة القائمة على النظام للنموذج تجميع نتائج التعلم واستخدامها باستمرار طوال العملية.
④ تحسين أداء عالم البيانات
يمكن أيضًا تحسين أداء البرنامج نفسه لجعله أكثر ملاءمةً للعمل كعالم بيانات. يتمثل أحد الأساليب في تحسين إطار عمل البرنامج باستخدام طرق مشابهة للبحث التلقائي أو التحليل الفائق، والاستفادة من نفس الهدف الداخلي (أي "توليد بيانات أفضل") لتوجيه تحسين الأداء الخارجي، وبالتالي تحسين نظام البرنامج بأكمله.
في تطبيقها، تقترح الورقة البحثية التوجيه الذاتي الوكيل كطريقة لتجسيد البيانات الذاتية، كما هو موضح في الشكل أدناه:
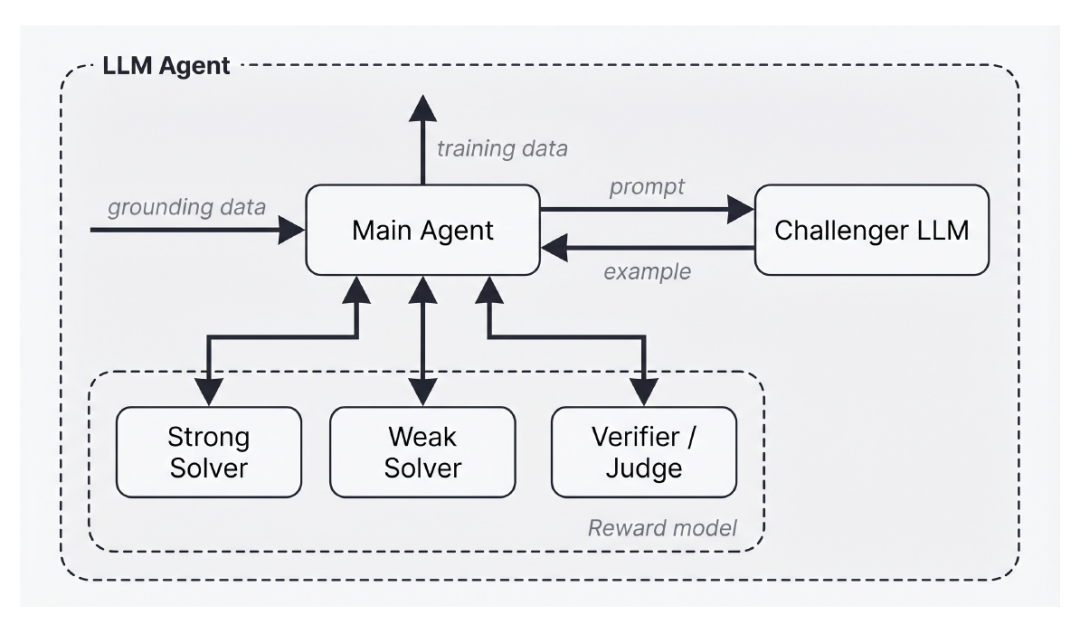
طريقة التوجيه الذاتي الفاعلية ذات التباين الضعيف-القوي
يمكن للوكيل الرئيسي المنسق في هذه الطريقة الوصول إلى أربعة وكلاء فرعيين بناءً على نموذج اللغة الكبير (LLM):
* المتحدي: يقوم بإنشاء عينات تدريبية بناءً على مطالبات مفصلة يقدمها الوكيل الرئيسي؛
* مُحلِّل ضعيف: نموذج يكافح عادةً لحل بيانات التدريب المُولَّدة؛
* مُحلِّل قوي: نموذج يمكنه عادةً حل بيانات التدريب المُولَّدة بنجاح؛
* المدقق/الحكم: بعد تقديم العينات وحلول النماذج، يقوم المدقق/الحكم بفحص جودة الحلول وإعادة نتائج التعلم إلى الوكيل الرئيسي.
يهدف هذا النظام إلى توليد بيانات تدريبية تمكّن المستخدمين ذوي القدرات العالية من إنجاز المهام بنجاح، بينما يواجه المستخدمون ذوو القدرات المنخفضة صعوبة. يقوم نظام التعلم الآلي الرئيسي بتحليل ملاحظات المراجعين وتحديث التلميحات المُرسلة للمُتحدّين وفقًا لذلك. تتكرر هذه العملية باستمرار لتوليد عينات عالية الصعوبة لتدريب المستخدمين ذوي القدرات المنخفضة.
عرض النتائج: حققنا نتائج متفوقة مقارنة بأساليب بناء البيانات الاصطناعية التقليدية
غطت تجارب الباحثين ثلاثة مجالات للمهام، مما يؤكد فعالية إطار عمل Autodata عبر أبعاد متعددة.
مهام علوم الحاسوب
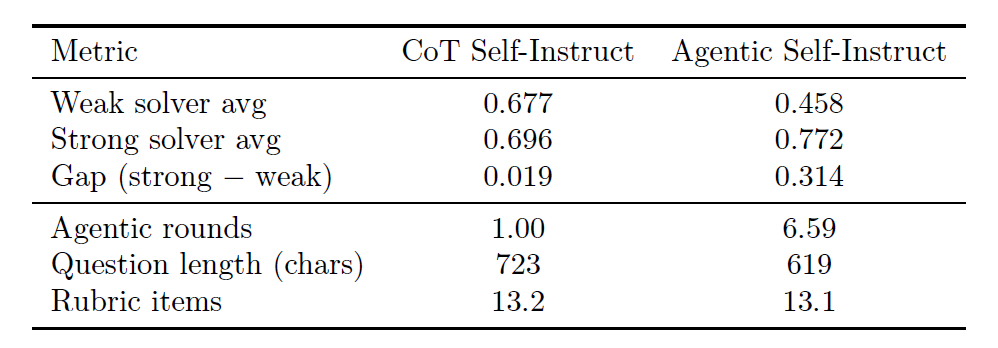
في مهام علوم الحاسوب، تعمل البيانات التي يتم إنشاؤها بواسطة التوجيه الذاتي الوكيل على تقليل معدل الارتباك بشكل كبير بين النماذج الضعيفة والقوية، مما يجعل إشارة التدريب أكثر وضوحًا.
في المسائل التي تم توليدها باستخدام طريقة CoT Self-Instruct الأساسية، حقق المُحلِّل الضعيف متوسط درجة 0.677. ومع ذلك، في المسائل نفسها التي تم توليدها باستخدام طريقة Agentic Self-Instruct، انخفضت درجة المُحلِّل الضعيف بمقدار 22 نقطة مئوية (من 0.677 إلى 0.458)، بينما ارتفعت درجة المُحلِّل القوي بمقدار 8 نقاط مئوية (من 0.696 إلى 0.772)، كما هو موضح في الجدول أدناه.يشير هذا إلى أن السؤال المقبول النهائي له تأثير تحفيزي أكبر على قدرة النموذج القوي على التفكير العميق.
في تدريب التعلم المعزز، على مجموعة اختبار CoT Self-Instruct الأبسط (الجانب الأيسر من الجدول أدناه)، يُحسّن التدريب باستخدام بيانات CoT متوسط الأداء عند 3 للنموذج الأساسي 4B من 0.630 إلى 0.727، بينما يُحسّنه التدريب باستخدام بيانات Agentic إلى 0.774. أما على مجموعة اختبار Agentic الأكثر صعوبة (الجانب الأيمن من الجدول أدناه)، فالنتائج المقابلة هي: 0.366 (النموذج الأساسي) ← 0.500 (تدريب CoT) ← 0.632 (تدريب Agentic). ويُلاحظ أن الفرق بين الطريقتين أكبر بكثير على هذه المجموعة (أكثر من ضعف الفرق في مجموعة اختبار CoT)، كما يُظهر مقياس best@3 الترتيب نفسه.
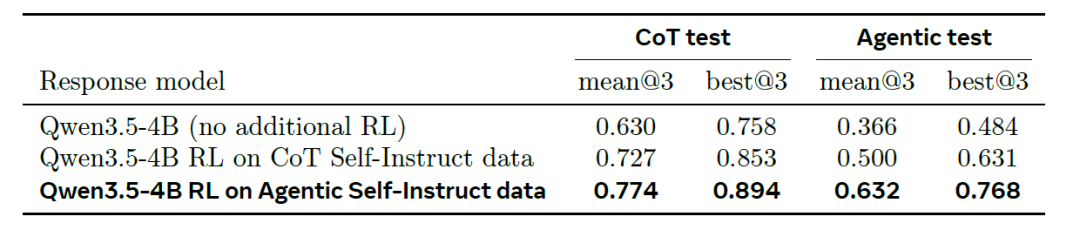
أظهر النموذج المُدرَّب باستخدام خوارزمية Agentic قابلية نقل البيانات في كلا الاتجاهين (+0.05 على مجموعة اختبار CoT و+0.13 على مجموعة اختبار Agentic الأكثر صعوبة). تشير هذه الميزة الكبيرة إلى أن بيانات التدريب الأكثر تمييزًا التي تُنتجها خوارزمية Agentic يمكن أن تُترجم إلى قدرات استدلالية أقوى.
مهمة الاستدلال القانوني
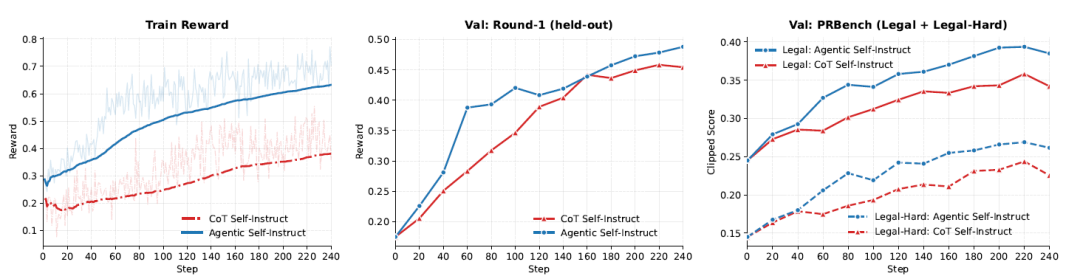
في مهام الاستدلال القانوني، كشفت الأبحاث عن ظاهرة معاكسة ولكنها لا تقل أهمية: غالبًا ما تكون البيانات المُولَّدة بواسطة نموذج CoT التقليدي بالغة الصعوبة، مما يؤدي إلى عدم قدرة النماذج الضعيفة على تقديم إشارات تدرج فعالة تقريبًا (مما ينتج عنه عدد كبير من المخرجات ذات الدرجة الصفرية). يُعيد برنامج Autodata، من خلال تقديم آلية تقييم أكثر دقة، صعوبة البيانات إلى "النطاق القابل للتعلم"، مما يُحسِّن بشكل كبير من استقرار وفعالية تدريب GRPO.
استخدم الباحثون خوارزمية GRPO لتدريب Qwen3.5-4B على مصدرين للبيانات: 2800 زوج من الأسئلة القانونية ومعايير التقييم (التدريب الذاتي الآلي والتدريب الذاتي التعاوني). خلال التدريب، تم اختبار مجموعة البيانات كل 20 خطوة على مجموعتي تقييم: مجموعة اختبار تعاوني تحتوي على 100 سؤال، ومجموعة PRBench مقسمة إلى قسمين: قانوني/قانوني-صعب. تم تقييم جميع المكافآت والنتائج باستخدام Kimi-K2.6. يوضح منحنى التدريب في الشكل أدناه أنه عند كل نقطة تقييم...تتصدر الأساليب الآلية باستمرار في مكافآت التدريب، ومجموعات التحقق من صحة CoT، وPRBench-Legal.
مهمة التفكير العلمي
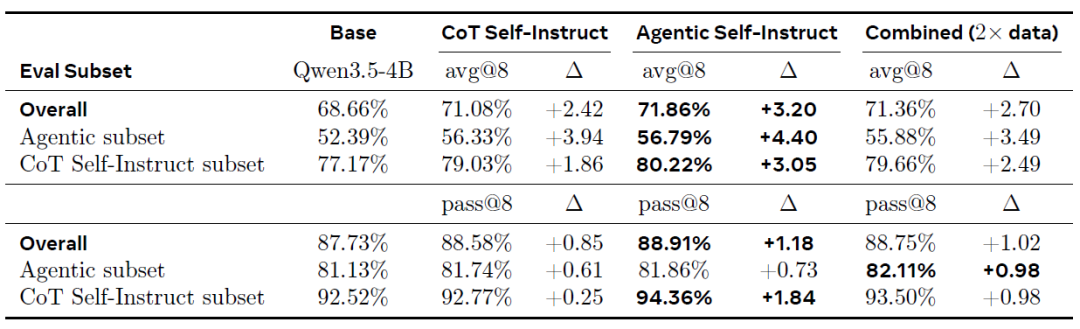
في مهام الاستدلال العلمي، يُظهر نموذج التوجيه الذاتي الفاعل تفوقًا ملحوظًا. ففي مجموعة التحقق المجمعة (كما هو موضح في الجدول أدناه)، حقق التدريب باستخدام بيانات التوجيه الذاتي الفاعل أكبر تحسن إجمالي (+3.20% avg@8)، متفوقًا على الاستخدام المباشر لبيانات التوجيه الذاتي CoT (+2.42%) والبيانات المجمعة (+2.70%).
تقييم نتائج تدريب التعلم المعزز على مهام الاستدلال العلمي
من أهم النتائج أن نموذج "التعليم الذاتي الآلي" لا يزال يحقق تحسناً أكبر في الأداء حتى على مجموعة التحقق غير المُحسَّنة من نموذج "التعلم الآلي" (CoT) (+3.05% مقابل +1.86% لنموذج CoT). وهذا يشير إلى أن...يمكن نقل التدريب على المهام الأكثر صعوبة إلى المهام الأبسط: من خلال التكرار على عينات عالية الصعوبة تم إنشاؤها من خلال عملية فاعلة، يمكن تعلم قدرات التفكير العامة، بدلاً من أن تقتصر على توزيع صعوبة محدد.
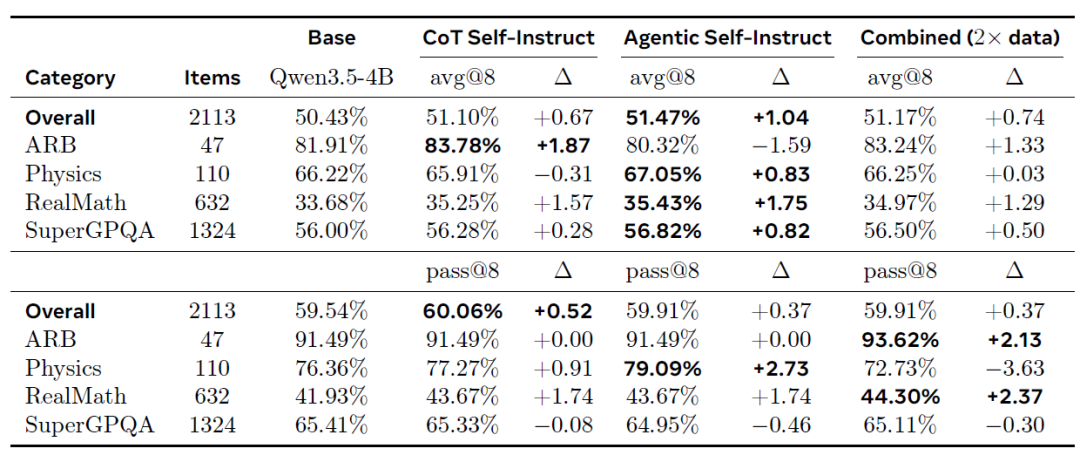
في اختبار برينسيبيا المعياري خارج نطاق التوزيع (كما هو موضح في الجدول أدناه)، حقق برنامج "التعليم الذاتي الآلي" أفضل متوسط تحسن (+1.04% avg@8) وتصدر باستمرار فئات متعددة، لا سيما RealMath (+1.75%) وSuperGPQA (+0.82%). ويؤكد هذا التأثير الانتقالي أن المسائل الأكثر صعوبة التي يولدها برنامج "التعليم الذاتي الآلي" قادرة على تحسين قدرات الاستدلال القوي.
خاتمة
باختصار، يقترح مشروع Autodata نموذجًا جديدًا لتوليد البيانات: نمذجة عملية توليد البيانات كحلقة علم بيانات مدفوعة بعامل ذكي. ضمن هذا الإطار، يتم توحيد توليد البيانات وتقييمها وتحليل الأعطال وتحسين السياسات في نظام واحد مغلق الحلقة. وتُظهر تجارب التحسين الفائق الإضافية أنه يمكن أيضًا تحسين عامل علم البيانات نفسه، مما يُحسّن جودة البيانات دون الحاجة إلى تدخل بشري.
بشكل عام، تكمن المساهمة الأساسية لهذا البحث في توفير آلية لتحويل الموارد الحاسوبية المستخدمة في مرحلة الاستدلال إلى القدرة على توليد بيانات تدريب عالية الجودة. وفي المستقبل، لا يزال هذا التوجه واعدًا للتوسع، بما في ذلك تكييف المهام على نطاق أوسع، وتعزيز التعاون بين العوامل في مراحل متعددة، والتحسين الشامل على مستوى مجموعة البيانات. علاوة على ذلك، يُعدّ إعادة إدخال التغذية الراجعة البشرية في العملية لتشكيل آلية تحسين تعاونية مع العامل اتجاهًا مهمًا للتطوير المستقبلي.








