Command Palette
Search for a command to run...
أصدرت MIT/IBM مجموعة بيانات ChartNet، وهي أكبر مجموعة بيانات للرسوم البيانية الاصطناعية حتى الآن، حيث أنتجت 1.5 مليون عينة متنوعة من الرسوم البيانية.

على مدى العامين الماضيين، تجاوز تطور النماذج متعددة الوسائط الكبيرة التوقعات بكثير. فمن التعرف على محتوى الصور إلى فهم المستندات المعقدة وتحليل معلومات الفيديو، تعمل نماذج اللغة المرئية (VLMs) باستمرار على توسيع آفاق قدراتها. ومع ذلك، هناك عنصر مرئي واحد يبدو بسيطًا ولكنه في غاية الصعوبة، ولا يزال يتسبب في تعطل العديد من النماذج المتقدمة بشكل متكرر، ألا وهو الرسوم البيانية.
بالنسبة للبشر، يمكن للرسوم البيانية الشريطية والخطية والانتشارية أن تنقل بسرعة الاتجاهات والمقارنات والاستنتاجات الرئيسية. أما بالنسبة للذكاء الاصطناعي، فالرسوم البيانية تتجاوز كونها مجرد صور. إذ تحتاج النماذج ليس فقط إلى التعرف على العناصر المرئية، بل أيضًا إلى فهم العلاقات بين المحاور ونقاط البيانات والمفاتيح والتسميات، بالإضافة إلى إجراء عمليات استخراج البيانات الرقمية وتحليل الاتجاهات، وحتى الاستدلال السببي. بعبارة أخرى، يُعد فهم الرسوم البيانية مهمة معقدة تتطلب قدرات معرفية بصرية ورقمية ولغوية، ولا تستطيع نماذج التعلم الآلي المرئي الحالية تحقيق ذلك إلا جزئيًا.
في السنوات الأخيرة، ساهمت بعض مجموعات البيانات في تطوير الأبحاث ذات الصلة، إلا أنها تعاني عمومًا من ثلاث مشكلات: صغر حجمها، ومحدودية أنواع الرسوم البيانية، ونقص المعلومات متعددة الوسائط. تركز العديد من مجموعات البيانات على مهمة واحدة فقط (مثل الإجابة على الأسئلة أو وصف الرسوم البيانية) أو تفتقر إلى الوسائط الرئيسية، لذا لا تزال النماذج مفتوحة المصدر متأخرة عن الأنظمة الاحتكارية في مهام الاستدلال المعقدة المتعلقة بالرسوم البيانية.
لسد هذه الفجوة،تم اقتراح ChartNet من قبل العديد من الخبراء من معهد ماساتشوستس للتكنولوجيا، ومختبر أبحاث الحوسبة التابع لمعهد ماساتشوستس للتكنولوجيا وشركة IBM، وقسم أبحاث IBM.—مجموعة بيانات متعددة الوسائط عالية الجودة تضم ملايين السجلات لفهم الرسوم البيانية، مصممة لتعزيز فهم الرسوم البيانية وقدرات الاستدلال.
تُعدّ هذه أكبر مجموعة بيانات للرسوم البيانية الاصطناعية حتى الآن، إذ تستخدم عملية توليف مبتكرة موجهة بالبرمجة لإنشاء 1.5 مليون عينة متنوعة من الرسوم البيانية تغطي 24 نوعًا من الرسوم البيانية و6 مكتبات رسم بياني. وقد أثبتت تجارب واسعة النطاق جدوى ChartNet، مُظهرةً أن نموذجها الأمثل المُحسّن يتفوق على نماذج أكبر بكثير وعلى GPT-4o في جميع المهام.
استخدم مجموعة البيانات عبر الإنترنت:https://go.hyper.ai/lGPsc
سيتم نشر نتائج البحث ذات الصلة، بعنوان "ChartNet: مجموعة بيانات متعددة الوسائط عالية الجودة على نطاق مليون من أجل فهم قوي للمخططات"، في مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط.
أبرز الأبحاث:
تتيح عملية التوليف والتوليد الموجهة بالرمز في ChartNet إنشاء عينات من المخططات على نطاق واسع، مع التقاط المعلومات المرئية والهيكلية والرقمية والنصية حول فهم المخطط.
يدمج ChartNet بيانات العالم الحقيقي والبيانات المصنفة يدويًا، ويتضمن مجموعة فرعية متخصصة تدعم التأشير المرئي وتحليل الأمان، مما يزيد من قيمة مجموعات البيانات في تدريب النماذج وتقييمها.
يمكن أن يؤدي الضبط الدقيق على مجموعة البيانات هذه إلى تحسين أداء نموذج اللغة المرئية باستمرار في مهام مثل إعادة بناء المخططات واستخراج البيانات وتلخيص المخططات.

عنوان الورقة:
https://hyper.ai/papers/2603.27064
مجموعة البيانات: تتكون من 1.5 مليون عينة اصطناعية متعددة الوسائط ومتوافقة
تتكون مجموعة البيانات الأساسية لـ ChartNet من 1.5 مليون عينة اصطناعية متعددة الوسائط متوافقة.تتضمن كل عينة: صورة بيانية، وشفرة برمجية للرسم، وبيانات جدولية، ووصفًا باللغة الطبيعية، وزوجًا من الأسئلة والأجوبة مع استدلال متسلسل. يوضح الشكل التالي نظرة عامة شاملة على سمات البيانات وأنواع الرسوم البيانية ومكتبات الرسم المستخدمة.
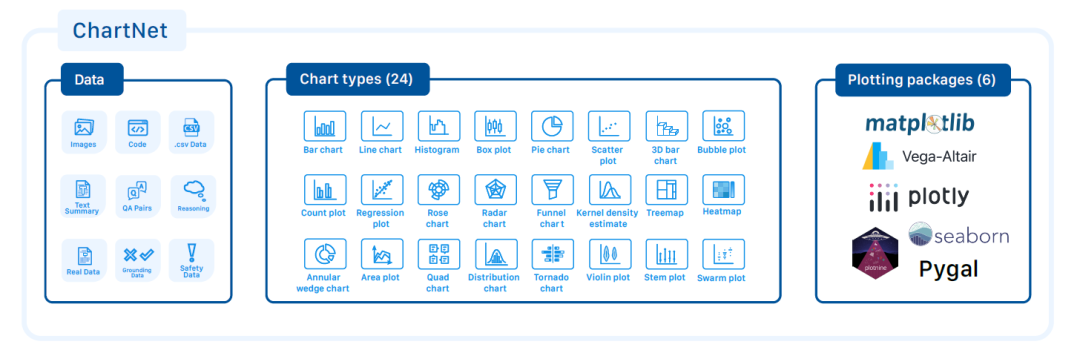
ولتغطية النطاق الكامل لقدرات فهم الرسوم البيانية، يتضمن ChartNet أيضًا العديد من المجموعات الفرعية المتخصصة: البيانات المصنفة يدويًا، والرسوم البيانية الواقعية، وبيانات التأسيس، وبيانات الأمان.
بيانات المخطط المركب المصنفة يدويًا:يحتوي على 96643 صورة بيانية اصطناعية متناسقة، ووصف، وبيانات جدولية، وكلها خضعت للتحقق والتعليق البشري الصارم.
بيانات رسوم بيانية واقعية عالية الجودة:لإثراء مجموعة الرسوم البيانية الاصطناعية، قام الباحثون بتجميع وشرح 30,000 رسم بياني من واقع الحياة، صادرة عن مؤسسات إعلامية وبيانات دولية مرموقة، مثل البنك الدولي، وشركة باين آند كومباني، ومركز بيو للأبحاث، ومشروع "عالمنا في بيانات"، وغيرها من دور النشر العالمية الشهيرة. تغطي هذه المجموعة طيفًا واسعًا من المواضيع المعاصرة، بما في ذلك الاقتصاد، والتكنولوجيا، والجغرافيا السياسية، وعلوم البيئة، والاتجاهات الاجتماعية، مع ضمان تنوع البيانات وملاءمتها للواقع. وقد تم استبعاد الرسوم البيانية ذات المحتوى المعلوماتي المنخفض أو الجودة المتدنية لضمان سهولة فهمها.
ضمان جودة البيانات الأساسية:لا تزال نماذج العرض المرئي الحديثة (VLM) تواجه صعوبة في تحديد مناطق المخططات والعناصر التركيبية ذات الصلة بأسئلة محددة. ولتحسين هذه القدرة، أنشأ الباحثون نموذجًا مرجعيًا للأسئلة والأجوبة. في البداية، استخرجوا تعليقات توضيحية هندسية من عناصر ترميز الرسم (المحاور، والعلامات، وخطوط الشبكة، والمفاتيح، والكتل الرسومية) لتوليد تعليقات مرجعية كثيفة للمخطط. ثم استُخدمت طريقة تعتمد على الانتروبيا لتصفية المربعات المحيطة. بعد ذلك، وباستخدام التعليقات المرجعية المُولَّدة، أُنشئت مجموعة من الأسئلة والأجوبة النموذجية لكل مخطط لتحديد مدى التطابق بين التخطيط المكاني المتوقع للعناصر المرئية والمحتوى الفعلي داخل المخطط.
يُشفّر الموقع المتوقع في سلسلة الإجابة باستخدام تمثيل مربع محيط متسلسل. تتضمن القوالب عناصر مرئية فريدة ومتكررة، تجمع بين الفهارس، وتسميات النصوص داخل المخطط، والسمات المرئية مثل لون العنصر لإنشاء تعبيرات الاستشهاد. يدعم المُولّد الإجابات القصيرة والطويلة، ويمكنه اختياريًا تضمين معلومات أساسية. تُولّد مجموعة البيانات النهائية زوجًا واحدًا من أسئلة وأجوبة لكل مخطط من خلال أخذ عينات موحدة عبر جميع أنواع القوالب وطرائق الإخراج. بالإضافة إلى ذلك، يتم إنشاء أزواج أسئلة وأجوبة أساسية قائمة على الاستدلال باستخدام gpt-oss-120b.
بيانات الأمان:لمعالجة المخاوف الأمنية، قام الباحثون بتوسيع عملية توليد البيانات لإنتاج بيانات متوافقة مع الأمن فيما يتعلق بالرسوم البيانية، مما يقلل من المحتوى الضار في مخرجات النموذج وخطر "كسر الحماية".
الفكرة الأساسية لـ ChartNet: توليف الرسوم البيانية الموجهة بالبرمجة من أجل التوليد التلقائي.
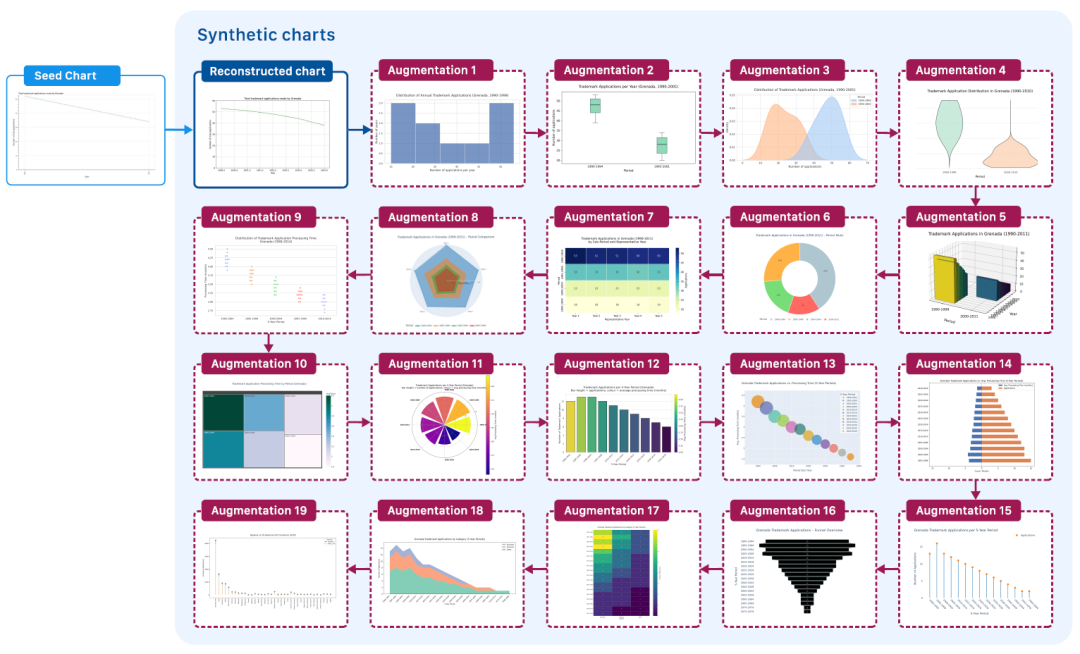
تتلخص الفكرة الأساسية وراء توليد البيانات في ChartNet في إمكانية إنشاء الرسوم البيانية برمجياً، حيث يعمل رمز الرسم القابل للتنفيذ كتمثيل وسيط منظم لعرض البيانات. وقد اقترح الباحثون عملية توليد رسوم بيانية آلية واسعة النطاق موجهة بالرمز (انظر الشكل أدناه)، تبدأ بكمية محدودة من بيانات صور الرسوم البيانية ("البذور") وتستخدم نموذج لغة مرئية (VLM) لإخراج رمز يمكنه إعادة بناء هذه الرسوم البيانية بشكل تقريبي.
عملية تحسين المخططات الموجهة بالبرمجة
وعلى وجه التحديد، تتضمن عملية توليد البيانات المراحل التالية:
① إعادة بناء المخطط إلى الكود:تُستخدم مكتبة VLM لإنشاء كود رسم بياني بلغة بايثون لإعادة بناء مجموعة معينة من صور المخططات بشكل تقريبي. في هذه المرحلة، يتم اختيار 150,000 صورة مخطط فريدة من مجموعة بيانات TinyChart كعناصر أساسية، ولكن العملية لا تعتمد بشكل محدد على اختيار هذه العناصر.
② تحسين المخططات الموجهة بالبرمجة:باستخدام كود الرسم البياني المُولّد كمدخلات، يُعاد كتابة الكود بشكل متكرر باستخدام نموذج لغوي كبير (LLM). مع الحفاظ على صلة الكود بالتكرار السابق، تُعدّل قيم البيانات الأساسية والتسميات لتتوافق بشكل أفضل مع نوع الرسم البياني المطلوب. يوضح الشكل أدناه عملية تحسين الكود التكرارية وعرض الرسم البياني؛ تُعد هذه المرحلة خطوة أساسية في توسيع نطاق مجموعة البيانات، حيث يمكن لكل صورة أولية أن تُولّد أي عدد من المتغيرات.
③ عرض المخطط البياني:قم بتنفيذ جميع أكواد الرسم البياني المُولَّدة لإنتاج صور المخططات، وسيتم إقران البرامج النصية التي تم تنفيذها بنجاح بالصور التي تم إنشاؤها.
④ تصفية الجودة:يتم تقييم كل صورة من صور المخطط باستخدام VLM للكشف عن فئات عيوب العرض المحتملة المختلفة (مثل تداخل النص، وقص التسميات، وحجب عناصر المخطط، وما إلى ذلك)، وسيتم إزالة الصور التي بها مشاكل بصرية ورمز الرسم الخاص بها.
⑤ توليد السمات الموجهة بالرمز:أخيرًا، تُستخدم VLM لإنشاء سمات دلالية إضافية لأزواج صورة الرسم البياني والرمز. تُستخرج قيم البيانات والتسميات من الرسم البياني ضمن سياق الرمز، ويتم إنشاء تمثيل جدولي للبيانات. علاوة على ذلك، من خلال دمج المعلومات المرئية والرمز والبيانات الجدولية، يتم إنشاء وصف للرسم البياني مع أساس منطقي.
إنه يحقق تحسينات كبيرة ومتسقة في جميع مهام فهم الرسوم البيانية.
للتحقق من فعالية ChartNet في تحسين قدرة النموذج على فهم الرسوم البيانية، قام الباحثون بتدريب نماذج اللغة المرئية بأحجام مختلفة على مجموعة بيانات ChartNet، بما في ذلك النماذج فائقة الصغر (≤1 مليار معلمة)، والصغيرة (≤4 مليار معلمة)، والمتوسطة (≤7 مليار معلمة).
بشكل عام، يؤدي الضبط الدقيق على مجموعة بيانات ChartNet إلى تحسينات كبيرة ومتسقة في جميع مهام فهم المخططات (انظر الجدول أدناه) - إن توحيد وحجم هذه التحسينات مستقل عن حجم النموذج.وهذا يوضح أن نماذج التعلم الافتراضي الحالية تفتقر إلى فرص التدريب عالي الجودة متعدد الوسائط الخاضع للإشراف على الرسم البياني، في حين أن ChartNet يسد هذه الفجوة بشكل فعال.
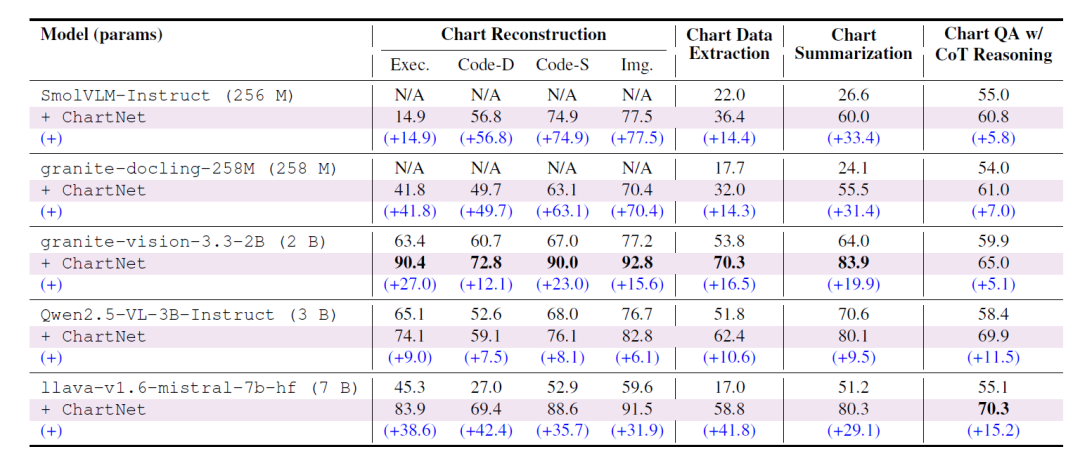
① إعادة بناء المخطط
حققت النماذج المدربة على مجموعة بيانات "تحويل المخططات إلى أكواد" تحسينات ملحوظة في معدل تنفيذ الأكواد، واتساق البيانات، والتشابه الهيكلي/البرمجي، وتشابه الصور: فالنماذج فائقة الصغر (SmolVLM-256M، Granite-Docling-258M) التي كانت عاجزة سابقًا عن إعادة بناء المخططات، أصبحت الآن تتمتع بكامل وظائفها؛ أما النماذج الأصغر حجمًا (مثل Granite-Vision-2B) فقد حققت إعادة بناء شبه مثالية، مع تجاوز العديد من المقاييس 90%؛ وحقق نموذج LLaVA-7B تحسنًا يصل إلى +42.4 نقطة في اتساق البيانات. يشير هذا الاتجاه المستقل عن الحجم إلى أن مواءمة ChartNet متعددة الوسائط بين الصور والأكواد توفر للنموذج إشرافًا منظمًا كان مفقودًا سابقًا في مجموعة البيانات.
② استخراج بيانات الرسم البياني
يُحسّن ChartNet بشكلٍ ملحوظ قدرة جميع النماذج على استخلاص الجداول الرقمية مباشرةً من الرسوم البيانية، حيث حقق Granite-Vision-2B أفضل أداء عند 70.31 نقطة في اختبار TP3T. ويُظهر LLaVA-7B المُحسّن بدقة تحسّنًا في الأداء بمقدار 41.8 نقطة، متجاوزًا جميع النماذج الأساسية مفتوحة المصدر، بل وحتى GPT-4o (الذي حقق 46.71 نقطة فقط في اختبار TP3T). يُبرهن هذا على أهمية الربط الوثيق بين الرسوم البيانية المُولّدة برمجيًا وبيانات CSV في ChartNet، مما يسمح للنموذج بالوصول إلى كلٍ من الشكل الهندسي المرئي والبنية الرقمية الكامنة.
③ ملخص الرسم البياني
تحسّنت جودة التلخيص لجميع عائلات النماذج بشكل ملحوظ، حيث تراوحت الزيادات بين +9.5 (Qwen2.5-VL-3B) و+31.4 (Granite-Docling-2B). وبلغت دقة نموذج Granite-Vision-2B المُحسّن 83.9%، متجاوزًا بذلك GPT-4o وجميع النماذج الأساسية مفتوحة المصدر المذكورة في الجدول 3، بما في ذلك النماذج ذات حجم المعلمات الأكبر بعشرة أضعاف. يُبيّن هذا أن التلخيص التركيبي لـ ChartNet (الذي يتم إنشاؤه بالاشتراك بين الكود والرسوم البيانية المُعالجة) يُوفّر إشارات إشرافية مُهيكلة وكاملة دلاليًا لفهم الرسوم البيانية الوصفية.
④ أسئلة وأجوبة مع مراعاة المنطق
في مهام الاستدلال المعقدة ومتعددة المراحل، أظهر كل نموذج تحسنًا مطردًا في الدقة - أظهر LLaVA-7B أكبر تحسن (+15.17)، حيث وصل إلى 70.3%، متجاوزًا نموذج استدلال المخطط المخصص ChartGemma وجميع نماذج المصادر المفتوحة المماثلة أو الأكبر حجمًا (بما في ذلك GPT-4o).
⑤ مقارنة مع النماذج الجاهزة
يُظهر الجدول أدناه أن النموذج المُحسَّن بواسطة ChartNet يتفوق على النموذج الجاهز ذي المعلمات الأكبر في جميع المقاييس تقريبًا. بعد التحسين، تتفوق النماذج ذات المعلمات 2 مليار أو 7 مليارات باستمرار على النماذج ذات المقياس من 20 مليار إلى 72 مليار. وعلى وجه الخصوص، في مهام إعادة بناء الرسوم البيانية واستخراج البيانات، يتفوق النموذج المُحسَّن بواسطة ChartNet بشكل كبير على GPT-40.
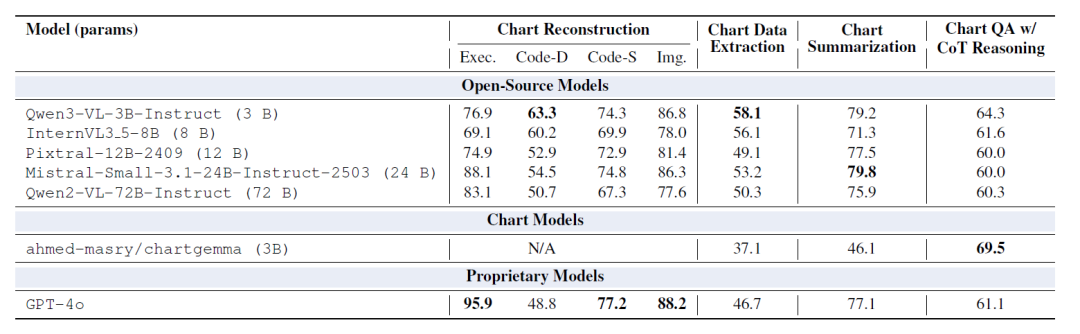
يشير هذا إلى أنه بالنسبة للمجالات التي تكون فيها الرؤية والبيانات الرقمية واللغة مرتبطة ارتباطًا وثيقًا، مثل فهم الرسوم البيانية، فإن توفير إشراف متعدد الوسائط عالي الجودة ومتوافق مع التعليمات البرمجية يكون أكثر فعالية من مجرد زيادة حجم النموذج.
⑥ التعميم على المعايير العامة
كما هو موضح في الجدول أدناه، بعد ضبط النموذج بدقة على مجموعة بيانات ChartNet الأساسية، حققت جميع النماذج تحسينات ملحوظة على المعايير العامة: فقد تحسن أداء Granite-Vision-2B من 1.6 إلى 12.4 BLEU على ChartCap، ومن 30.8 إلى 58.4 على ChartMimic-v2؛ حتى النموذج فائق الصغر (SmolVLM-256M) حقق قفزة كبيرة في الأداء. وكان هذا التحسن ثابتًا في كلٍ من مهام تلخيص الرسوم البيانية وتوليد الشفرة البرمجية منها، مما يدل على إمكانية نقل نظام الإشراف على محاذاة الوسائط المتعددة في ChartNet بفعالية إلى معايير واقعية، وليس فقط إلى توزيعات التدريب الاصطناعية.
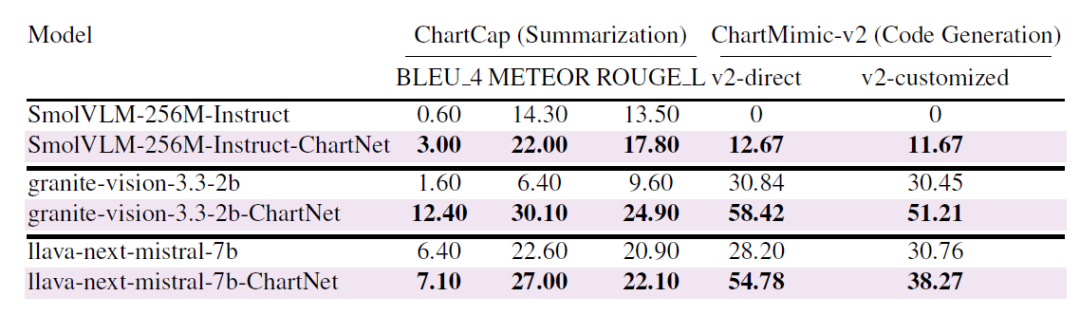
تحسين قدرة بيانات ChartNet الاصطناعية على التعميم على معيارين عامين من العالم الحقيقي
خاتمة
يهدف مشروع ChartNet إلى معالجة إحدى العقبات الرئيسية في مجال فهم الرسوم البيانية: وهي نقص الإشارات الإشرافية عالية الدقة وواسعة النطاق لمواءمة الصور، والرموز البرمجية المرسومة، والبيانات الرقمية، والأوصاف النصية، ومسارات الاستدلال. يوفر المشروع منصة أساسية مفتوحة وقابلة للتطوير لأبحاث النمذجة متعددة الوسائط في مجالات الاستدلال العددي، وفهم التصورات، وتحليل المستندات، ومواءمة الرموز البرمجية، مما يدفع النمذجة المرئية (VLM) من مجرد "وصف الرسوم البيانية" إلى "فهم المعلومات المنظمة المشفرة في الرسوم البيانية".
قالت جوفانا كونديك، طالبة الدراسات العليا في قسم الهندسة الكهربائية وعلوم الحاسوب في معهد ماساتشوستس للتكنولوجيا والمؤلفة الأولى للورقة البحثية المتعلقة بـ ChartNet: "ركزت العديد من مجموعات بيانات التدريب السابقة فقط على الإجابة عن أسئلة بسيطة حول الرسوم البيانية. لقد حاولنا تجاوز ذلك مع ChartNet، من خلال توليد بيانات تدعم فهمًا شاملاً وعميقًا للرسوم البيانية."
يخطط الباحثون في المستقبل لمواصلة توسيع نطاق ChartNet من خلال دمج بيانات أكثر تعقيدًا، وبالتالي خلق قيمة حقيقية لمزيد من الصناعات.
مراجع:
https://arxiv.org/abs/2603.27064
https://news.mit.edu/2026/mit-researchers-teach-ai-models-to-interpret-charts-0603