Command Palette
Search for a command to run...
تقرير أسبوعي عن الأبحاث | يستكشف مشروع مايكروسوفت MAI-Thinking التطور الذاتي للتعلم المعزز الخالص، محققًا دقة AIME تبلغ 97%؛ ويحقق مشروع VLM³ تعميم المهام ثلاثية الأبعاد باستخدام إحداثيات نصية عادية دون تعديلات معمارية... نظرة سريعة على أحدث الأبحاث في مجال الذكاء الاصطناعي لهذا الأسبوع

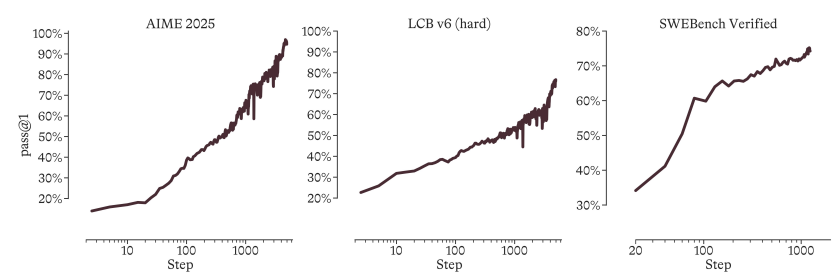
لا تعتمد التطورات في مجال الذكاء الاصطناعي على تحقيق اختراقات في النماذج الفردية فحسب، بل الأهم من ذلك هو بناء أنظمة قادرة على التحسين الذاتي المستمر. ولتحقيق هذه الغاية، ينظر فريق الذكاء الاصطناعي في مايكروسوفت إلى تطوير النماذج على أنه مشكلة تحسين على مستوى النظام.تم اقتراح إطار عمل "آلة تسلق التلال" المصمم لتحقيق تحسينات سريعة ومستدامة في الأداء."وبناءً على ذلك، تم تدريب نموذج استدلال MoE MAI-Thinking-1 بإجمالي معلمات 1T ومعلمات تنشيط 35B من الصفر.
يتجاهل النموذج تمامًا بيانات التقطير من نماذج الطرف الثالث خلال مرحلة التدريب المسبق ويقدم خوارزمية GRPO مع التحكم التكيفي في الإنتروبيا وآلية التقطير الذاتي خلال مرحلة التعلم المعزز (RL).تظهر النتائج التجريبية أنه حتى عند البدء بدون أي مسارات استدلال مسبقة، يمكن لـ MAI-Thinking-1 تحقيق نمو أداء خطي لوغاريتمي مستقر على المدى الطويل.وفي النهاية، حقق مستويات متطورة من الاستدلال المعقد وتوليد التعليمات البرمجية على المعايير الأساسية مثل AIME 2025 (97.0%) و SWE-Bench Pro (52.8%).
رابط الورقة:https://go.hyper.ai/QeSWd
أحدث أبحاث الذكاء الاصطناعي:https://go.hyper.ai/hzChC
لمساعدة المزيد من المستخدمين على فهم أحدث التطورات في مجال الذكاء الاصطناعي في الأوساط الأكاديمية،يحتوي موقع HyperAI الإلكتروني (hyper.ai) الآن على قسم "أحدث الأوراق البحثية"، والذي يتم تحديثه بانتظام بأحدث أوراق البحث في مجال الذكاء الاصطناعي.إليكم 9 أبحاث شائعة في مجال الذكاء الاصطناعي نوصي بها. دعونا نلقي نظرة سريعة على أحدث إنجازات الذكاء الاصطناعي لهذا الأسبوع ⬇️
توصيات الورقة البحثية لهذا الأسبوع
1. MAI-Thinking-1
عنوان الورقة:
MAI-Thinking-1: بناء آلة تسلق التلال
اقترح فريق الذكاء الاصطناعي في مايكروسوفت منهجية "تسلق التل"، حيث تعامل مع تطوير النموذج كمشكلة تحسين على مستوى النظام. درّب الفريق نموذج الاستدلال MAI-Thinking-1 من الصفر، بإجمالي 1 تريليون مُعامل و35 مليار مُعامل تنشيط. اعتمد التدريب المسبق للنموذج كليًا على بيانات نقية، دون استخدام أي بيانات مُعالجة من جهات خارجية. خلال مرحلة التعلم المعزز، حقق الفريق نموًا مستقرًا وطويل الأمد في الأداء دون مسار استدلال أولي، وذلك باستخدام خوارزمية GRPO مع تحكم تكيفي في الإنتروبيا وآلية التقطير الذاتي. يدمج النموذج في نهاية المطاف قدرات من ثلاثة مجالات خبرة: العلوم والتكنولوجيا والهندسة والرياضيات، ووكيل البرمجة، والأمن، مُظهرًا أداءً رائدًا في الاستدلال والبرمجة على معايير مثل AIME 2025 (97.0%) وSWE-Bench Pro (52.8%).
ورقة وتفسير مفصل:https://go.hyper.ai/QeSWd
2. VLM³
عنوان الورقة:
VLM³: نماذج لغة الرؤية هي متعلمون ثلاثي الأبعاد أصليون
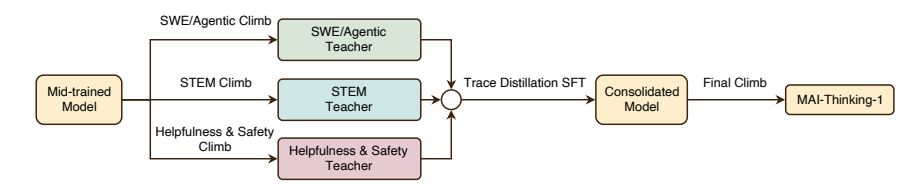
اكتشف ميتا وفريقه، من خلال تجارب واسعة النطاق، أن تمكين نماذج التعلم المرئي (VLMs) من أداء التعلم ثلاثي الأبعاد بكفاءة لا يتطلب بنى معقدة أو تصاميم متخصصة؛ بل يتطلب فقط طول بؤري موحد، وإدخال مراجع بكسل نصية، واستراتيجيات معقولة لدمج البيانات وتوسيعها. بناءً على هذا الاكتشاف، اقترح فريق البحث VLM³، وهو تصميم بسيط يسمح لنماذج التعلم المرئي القياسية بأداء مهام متعددة في آن واحد، مثل تقدير العمق، ومطابقة البكسل، وتقدير وضعية الكاميرا، وفهم الأبعاد الثلاثية على مستوى الكائن. مع الحفاظ على البنية الأصلية وطريقة التدريب النصية، اقترب أداء VLM³ من أداء النماذج المرئية الخبيرة، بل ونافسه، مما يوفر مسارًا جديدًا أبسط وأكثر قابلية للتوسع لنماذج التعلم المرئي العامة لتعلم العالم ثلاثي الأبعاد.
ورقة وتفسير مفصل:https://go.hyper.ai/5ks6r
3. تحديد موقع أي شيء
عنوان الورقة:
تحديد موقع أي شيء: تأريض سريع وعالي الجودة للرؤية واللغة مع فك تشفير الصندوق المتوازي
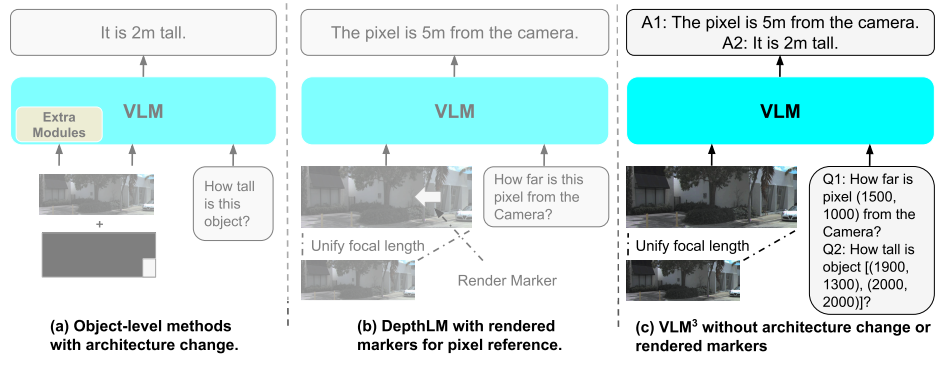
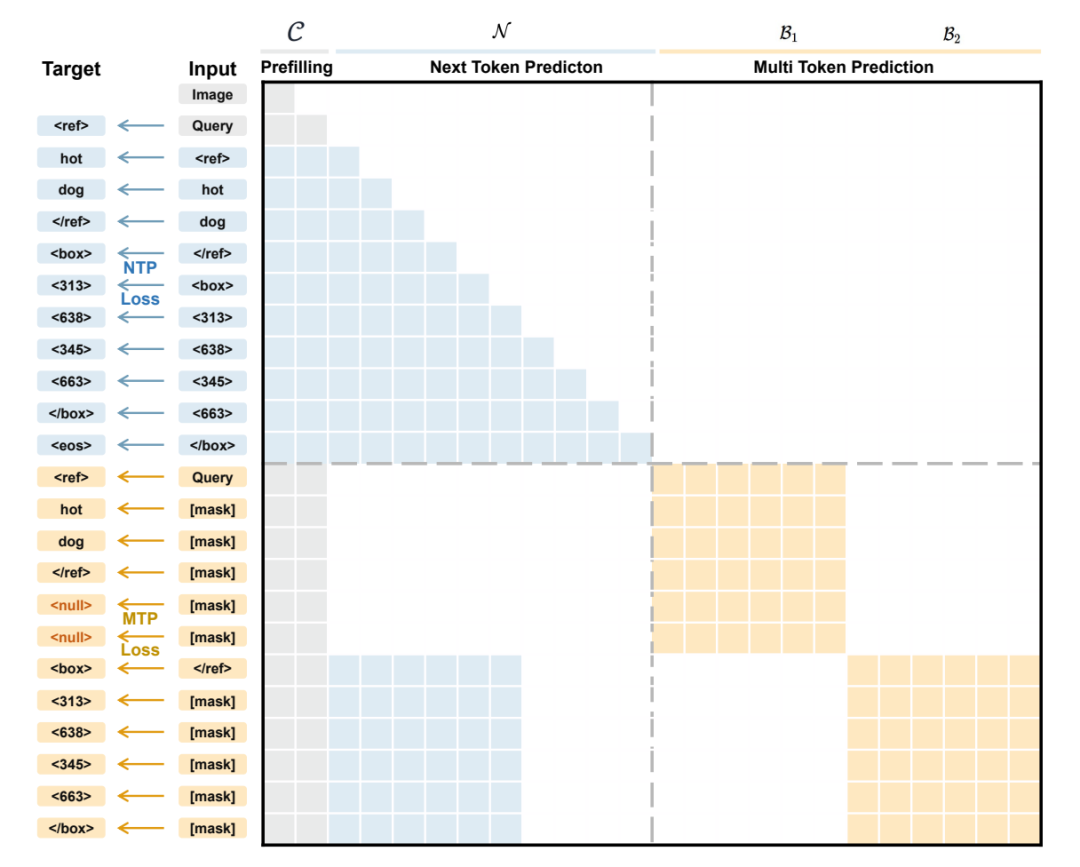
تعتمد نماذج اللغة المرئية الحالية عادةً على نمذجة تحديد موقع الكائنات كعملية توليد تدريجية لرموز الإحداثيات، مما يتطلب التنبؤ المتسلسل بإحداثيات المربع المحيط. لا يتجاهل هذا فقط العلاقات الهندسية داخل المربعات، بل يحد أيضًا من سرعة الاستدلال. لمعالجة هذه المشكلة، اقترح فريق NVIDIA تقنية LocateAnything، التي تستخدم آلية فك تشفير المربعات المتوازية (PBD) للتعامل مع المربع المحيط كوحدة أساسية، حيث تولد مجموعة إحداثياته الكاملة بالتوازي في خطوة واحدة. وبالاقتران مع مجموعة بيانات ضخمة تضم 138 مليون استعلام، ووضع استدلال هجين مع تصحيح ذكي للأخطاء، يحقق هذا النموذج إنتاجية فك تشفير أعلى ودقة تحديد موقع أفضل في مؤشر تقاطع الاتحاد العالي (IoU) عبر معايير متعددة، مما يدفع حدود السرعة والدقة لمهام تحديد الموقع والكشف المرئي الموحدة.
ورقة وتفسير مفصل:https://go.hyper.ai/C8jXC
تكوين مجموعة البيانات ومصدرها: قام فريق البحث بإنشاء LocateAnything-Data، وهي مجموعة بيانات واسعة النطاق تحتوي على 12 مليون صورة فريدة، و138 مليون استعلام باللغة الطبيعية، و785 مليون مربع إحاطة مصنف.

4. كوين-في إل إيه
عنوان الورقة:
Qwen-VLA: توحيد نمذجة الرؤية واللغة والحركة عبر المهام والبيئات وتجسيدات الروبوت
لطالما اعتمدت أبحاث الذكاء المجسد على نماذج متخصصة لمهام محددة، مما أدى إلى قدرات مجزأة وتعميم محدود. يقترح فريق تشيان وين نموذج Qwen-VLA، وهو نموذج أساسي موحد للرؤية واللغة والحركة. من خلال وحدة فك تشفير الحركة القائمة على DiT، يوسع النموذج نطاق إدراك وفهم واستدلال الرؤية واللغة ليشمل الحركات المستمرة وتوليد المسارات. يستخدم النموذج تدريبًا مسبقًا مشتركًا واسع النطاق، يشمل مسارات تشغيل الروبوت، وعروضًا توضيحية من منظور الشخص الأول، وبيانات محاكاة، ومهام ملاحة، وإشارات مساعدة للرؤية واللغة. كما يتكيف مع منصات الروبوت المختلفة من خلال آلية مشروطة لإشارات الإدراك المجسد. يدمج Qwen-VLA التشغيل والملاحة وتوقع المسار في إطار عمل موحد، مما يحقق قابلية النقل عبر المهام والبيئات وأشكال الروبوت. تُظهر التجارب أن النموذج يُظهر أداءً مستقرًا متعدد المهام وقدرات تعميم خارج التوزيع عبر معايير متعددة للتشغيل والملاحة.
ورقة وتفسير مفصل:https://go.hyper.ai/5x2Tj
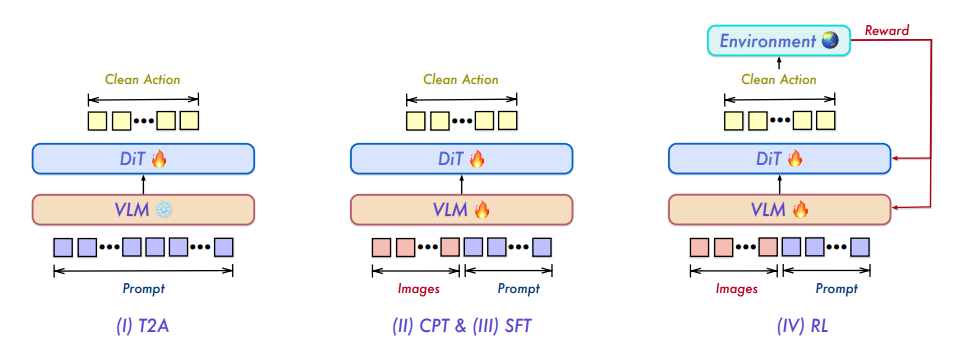
تكوين مجموعة البيانات ومصادرها: قام فريق البحث بإنشاء مجموعة بيانات كبيرة ومتنوعة مُدرَّبة مسبقًا لتوحيد نمذجة المرئيات واللغة والحركة. تشمل مصادر البيانات أكثر من عشرة معايير عامة للروبوتات، ومجموعة بيانات فيديو بشرية كبيرة، وبيانات خاصة تم جمعها داخليًا، وخطوط محاكاة تم إنشاؤها داخليًا.

5. SDPG
عنوان الورقة:
تدرج السياسة المُستخلص ذاتيًا
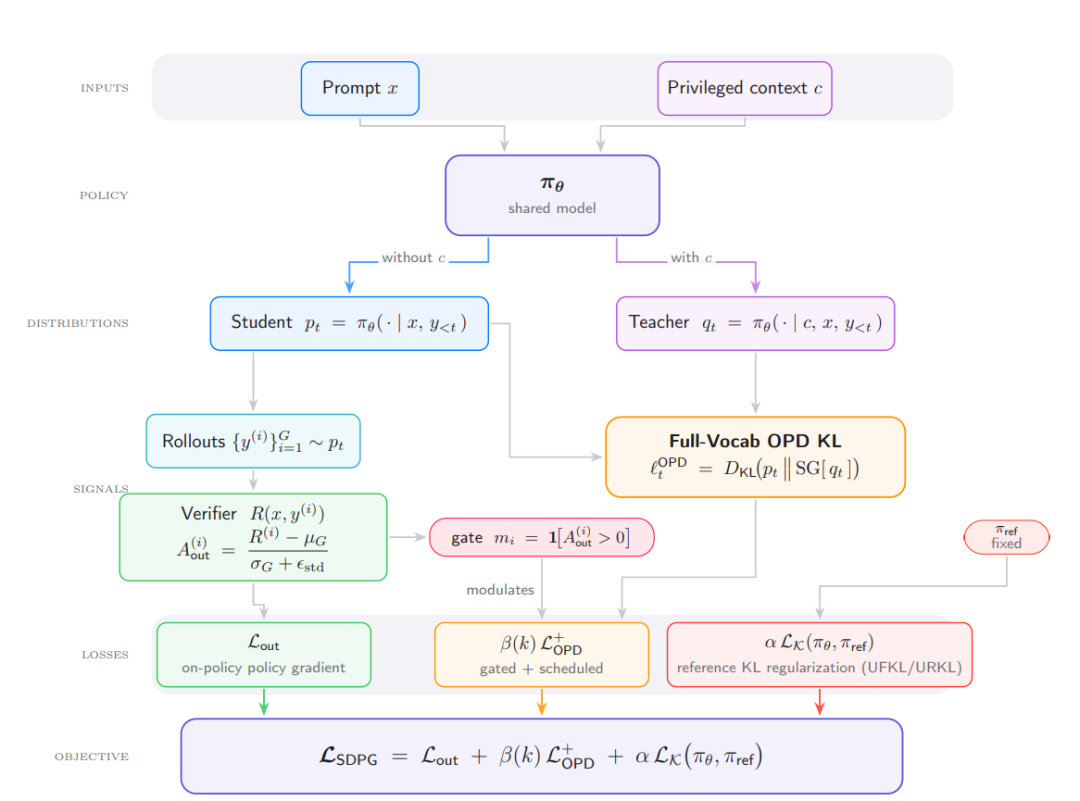
تستخدم تقنية التقطير الذاتي القائم على السياسات (SDPG) السياق المميز للنموذج للإشراف على نتائجه المُولَّدة ذاتيًا، مما يوفر إشارات تعلم أكثر كثافة لتعلم التعزيز بالمكافأة المتفرقة. ويمكن صياغتها رسميًا على أنها دالة خسارة عكسية بين الطالب والمعلم (KL) على كامل المفردات. وانطلاقًا من هذا، اقترح باحثون من جامعة كاليفورنيا في لوس أنجلوس (UCLA) وجامعة برينستون إطار عمل SDPG، الذي يجمع بين ميزة التحقق النسبي للمجموعة، وتطبيع الانحراف المعياري، والتقطير الذاتي للمفردات الكاملة عبر الإنترنت، وتنظيم KL للسياسة المرجعية. وتُظهر التجارب أن SDPG تُحسِّن الاستقرار والأداء مقارنةً بتقنية RLVR وطرق التقطير الذاتي الحالية.
ورقة وتفسير مفصل:https://go.hyper.ai/p5irp
6. GSM-الرمزي
عنوان الورقة:
GSM-Symbolic: فهم حدود الاستدلال الرياضي في نماذج اللغة الكبيرة
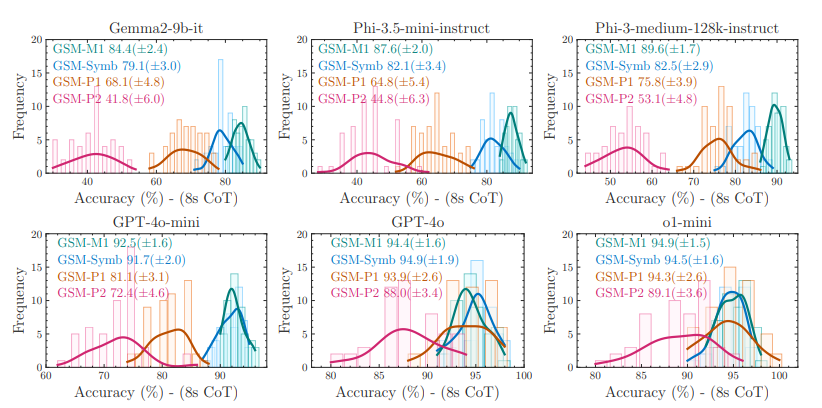
تشير الأبحاث إلى أن معايير GSM8K التقليدية غير كافية لتعكس بدقة الأداء الحقيقي للنماذج. لذلك، قام فريق آبل بإنشاء معيار قابل للتحكم، GSM-Symbolic، بالاعتماد على قوالب رمزية. تُظهر التجارب أن مجرد تغيير الأرقام أو أسماء الكيانات في الأسئلة يُسبب تقلبات كبيرة في أداء النماذج الكبيرة؛ كما أن إضافة عبارات مُشتتة غير ذات صلة تُقلل الدقة بشكل كبير. يفترض فريق البحث أن نماذج التعلم الآلي الحالية لا تمتلك قدرات استدلال منطقي حقيقية، بل تُحاول إعادة إنتاج خطوات الاستدلال المُلاحظة في بيانات التدريب الخاصة بها.
ورقة وتفسير مفصل:https://go.hyper.ai/n3UfJ
7. MUSE-Autoskill
عنوان الورقة:
MUSE-Autoskill: وكلاء يتطورون ذاتيًا من خلال إنشاء المهارات والذاكرة والإدارة والتقييم
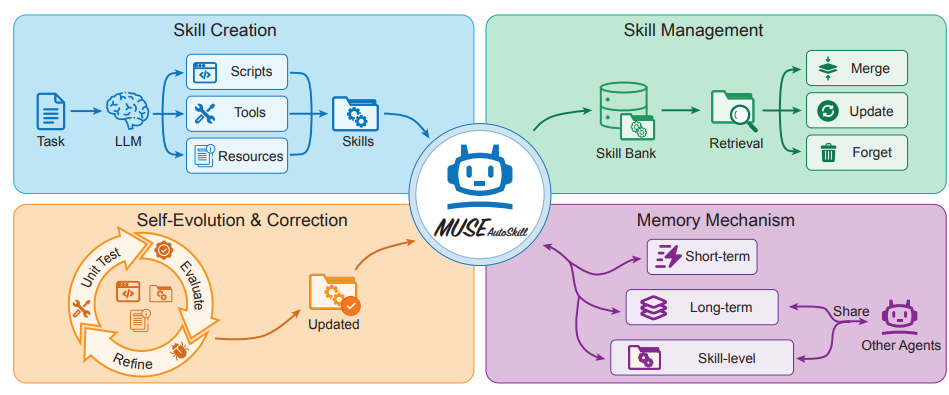
اقترحت فرقٌ من بينها ByteDance إطار عمل MUSE-Autoskill للوكلاء الأذكياء، الذي يوحّد إنشاء المهارات وحفظها وإدارتها وتقييمها وتحسينها ضمن دورة حياة كاملة. يتجاوز هذا الإطار قيود المهارات التقليدية الثابتة والمعزولة من خلال إدخال ذاكرة على مستوى المهارة لتراكم الخبرة عبر المهام. تُقدّم التجارب على منصة SkillsBench أدلةً أوليةً على أن المهارات المُدارة وفقًا لدورة حياتها تُحسّن معدل نجاح المهام، وكفاءة التنفيذ، وإمكانية إعادة الاستخدام، وقابلية النقل بين الوكلاء، مما يُبرز أهمية التعامل مع المهارات كأصول طويلة الأمد، ومُدركة للخبرة، وقابلة للاختبار.
ورقة وتفسير مفصل:https://go.hyper.ai/mdgB2
8. نيموترون 3 ألترا
عنوان الورقة:
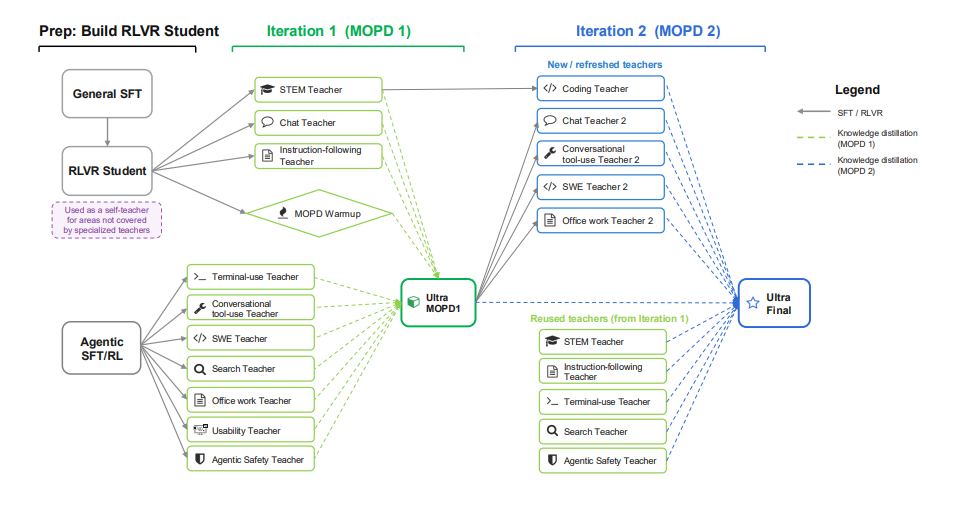
نيموترون 3 ألترا: نموذج مامبا-ترانسفورمر هجين مفتوح وفعال يجمع بين مجموعة من الخبراء من أجل الاستدلال الفاعل
أصدرت NVIDIA نموذج Nemotron 3 Ultra، وهو نموذج لغوي يعتمد على Mamba-Attention MoE، ويضم 550 مليار مُعامل و55 مليار مُعامل تنشيط. تم تدريب هذا النموذج مسبقًا على 20 تريليون رمز، مع توسيع طول السياق إلى مليون رمز، وتدريبه لاحقًا باستخدام SFT وRL وتقنية تقطير السياسات عبر الإنترنت متعددة المعلمين (MOPD). وبفضل توظيف تقنيات مثل LatentMoE، والتنبؤ متعدد الرموز، وNVFP4، وRLVR، وMOPD، والتحكم في ميزانية الاستدلال، يحقق Nemotron 3 Ultra إنتاجية استدلال أعلى بست مرات تقريبًا من نماذج اللغة العامة الحالية، مع الحفاظ على دقة عالية، مما يجعله مناسبًا لمهام الوكلاء المستقلين طويلة الأمد.
ورقة وتفسير مفصل:https://go.hyper.ai/lm6S1
9. كوزموس 3
عنوان الورقة:
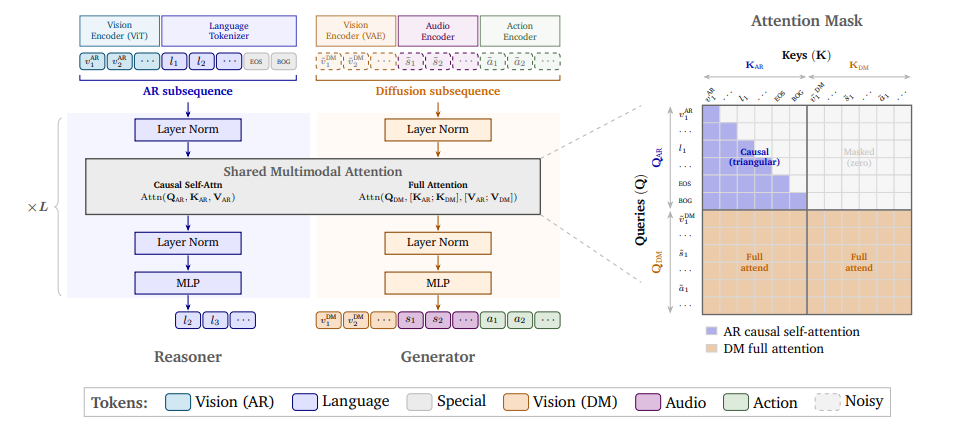
كوزموس 3: نماذج العالم متعددة الوسائط للذكاء الاصطناعي الفيزيائي
أصدرت NVIDIA برنامج Cosmos 3، وهو عبارة عن مجموعة من نماذج العالم متعددة الوسائط التي تعالج وتولد اللغة والصور والفيديو والصوت وتسلسلات الحركة ضمن بنية Transformer هجينة موحدة. يدعم Cosmos 3 تكوينات إدخال/إخراج مرنة للغاية، حيث يدمج نماذج اللغة المرئية ومولدات الفيديو ومحاكيات العالم ونماذج الحركة في إطار عمل واحد. تُظهر التقييمات أنه يحقق نتائج متقدمة في مهام الفهم والتوليد المتنوعة، مما يؤكد صلاحية نماذج العالم متعددة الوسائط كشبكات أساسية عامة للوكلاء المجسدين. وقد صُنفت النماذج المُدربة لاحقًا كأفضل نماذج مفتوحة المصدر لتحويل النص إلى صورة/الصورة إلى فيديو، وأفضل نماذج السياسات.
ورقة وتفسير مفصل:https://go.hyper.ai/RoY2u
هذا هو محتوى توصيات البحث لهذا الأسبوع. لمزيد من أبحاث الذكاء الاصطناعي المتطورة، يُرجى زيارة قسم "أحدث الأبحاث" على الموقع الرسمي لـ hyper.ai.
نرحب أيضًا بفرق البحث لتقديم نتائج وأوراق بحثية عالية الجودة إلينا. يمكن للمهتمين إضافة حساب نيوروستار على وي تشات (معرف وي تشات: Hyperai01).
نراكم في الاسبوع القادم!








