Command Palette
Search for a command to run...
إنجازٌ ثوري في مجال تحويل النص إلى كلام بدون أخذ عينات! بضع ثوانٍ من الصوت المرجعي، يساعدك OmniVoice على استنساخ مئات اللغات بسهولة؛ 17 لغة دفعة واحدة: يحل MDPbench المشكلة الرئيسية لتحليل أنظمة النصوص ذات الموارد المحدودة.

تدعم نماذج تحويل النص إلى كلام (TTS) الحالية التي لا تتطلب تدريبًا مسبقًا عددًا محدودًا من اللغات، متجاهلةً عددًا كبيرًا من اللغات ذات الموارد المحدودة. وللتغلب على هذا القيد،أطلق فريق Kaldi من الجيل التالي التابع لشركة Xiaomi AI Labs برنامج OmniVoice، وهو نموذج تحويل النص إلى كلام واسع النطاق ومتعدد اللغات وبدون تدريب مسبق، ويدعم أكثر من 600 لغة.يتخلى هذا النظام عن البنية التقليدية المعقدة ذات المرحلتين المتتاليتين، ويتبنى إطار عمل مبسطًا أحادي المرحلة منفصلًا غير تراجعي ذاتيًا (NAR) لربط النص مباشرةً بالعلامات الصوتية. وبفضل تدريبه على 581,000 ساعة من البيانات مفتوحة المصدر، يحقق OmniVoice أوسع تغطية لغوية حتى الآن.
حالياً، أطلق موقع HyperAI الإلكتروني [القسم/الميزة ذات الصلة].OmniVoice: يدعم تحويل النص إلى كلام عالي الجودة بأكثر من 600 لغةتعال وجرّبها!
الاستخدام عبر الإنترنت:https://go.hyper.ai/BvKri
نرحب بكم لزيارة موقعنا الإلكتروني الرسمي لمزيد من المعلومات:
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 11 أبريل إلى 17 أبريل:
* مجموعات البيانات العامة عالية الجودة: 11
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 6
* تحليل مقالات المجتمع: مقالتان
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في أبريل: 2
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات مخاطر الإصابة بالسكتة الدماغية
تُعدّ قاعدة بيانات "مخاطر السكتة الدماغية" أداةً لتحليل مخاطر السكتة الدماغية والتنبؤ بها في مجال الرعاية الصحية. وتستند هذه القاعدة إلى عوامل الخطر السريرية الشائعة، وتشمل معلومات ديموغرافية، وتاريخًا طبيًا، وعوامل نمط الحياة، ومؤشرات صحية رئيسية. وتعكس هذه القاعدة احتمالية حدوث السكتة الدماغية في ظل ظروف صحية ونمط حياة مختلفين، بهدف دعم نماذج التعلّم الآلي في التنبؤ بمخاطر السكتة الدماغية وتحليلها، والمساعدة في تحديد العوامل المؤثرة الرئيسية، وبالتالي تحسين قدرات الكشف المبكر والوقاية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/6CTH5
2. مجموعة بيانات حوار تعلم الأدوات المعقدة ToolACE
ToolACE هي مجموعة بيانات آلية لخط أنابيب الوكلاء، مُخصصة لمهام تعلم الأدوات. تحتوي هذه المجموعة على أمثلة لمحادثات متعددة الخطوات، تستدعي 26,507 واجهة برمجة تطبيقات متنوعة. تُولّد هذه العينات من خلال تفاعلات بين عدة وكلاء، وتخضع لعملية ضمان جودة ثنائية الطبقات، تشمل التحقق من القواعد والتحقق من صحة النموذج. يُمثل كل حوار مهمة استرجاع وتحليل معلومات متعددة الخطوات والمصادر، مما يُحاكي سيناريوهات استدعاء الأدوات بشكل واقعي، ويُوفر بيانات تدريب عالية القيمة للتعلم منخفض المستوى (LLM).
الاستخدام عبر الإنترنت:https://go.hyper.ai/o3E12
3.مجموعة بيانات CHOCLO المعيارية الثقافية لأمريكا اللاتينية
تُعدّ مجموعة بيانات CHOCLO مجموعة بيانات مرجعية مصممة خصيصًا لتقييم معرفة نماذج اللغة بثقافة أمريكا اللاتينية. وتهدف إلى تقييم دقة نماذج اللغة في تمثيل ثقافة أمريكا اللاتينية، وهي مصممة لمعالجة قضايا واقعية مثل التقليل من شأن ثقافة أمريكا اللاتينية، وإغفالها، والتحيزات المتعلقة بها في نماذج اللغة.
الاستخدام عبر الإنترنت:https://go.hyper.ai/pjVQi
4. مجموعة بيانات DRACO المعيارية للبحوث المتعمقة متعددة التخصصات
مجموعة بيانات DRACO، التي أصدرها فريق Perplexity، هي مجموعة بيانات مصممة لتقييم مهام البحث المعقدة وتهدف إلى التقييم المنهجي للقدرات الشاملة لأنظمة البحث العميق من حيث الدقة والشمولية والموضوعية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/hIWgS
5. مجموعة بيانات MDPBench المعيارية لتحليل المستندات متعددة اللغات
MDPBench عبارة عن مجموعة بيانات مرجعية لتحليل المستندات الرقمية والصور الفوتوغرافية متعددة اللغات، وهي مصممة لتقييم وتحسين قدرة النماذج على تحليل المستندات متعددة اللغات في سيناريوهات معقدة من العالم الحقيقي.
الاستخدام عبر الإنترنت:https://go.hyper.ai/1Mc9a
6. مجموعة بيانات نموذج العالم
يُعدّ World Model Bench أول معيار عالمي لتقييم القدرات المعرفية لنماذج العالم وأنظمة الذكاء الاصطناعي المُجسّدة. ويهدف إلى تجاوز التقييمات التقليدية لجودة الصور والفيديوهات، مُركّزًا بدلًا من ذلك على القدرات المعرفية للنماذج. بُنيت هذه المجموعة من البيانات حول تقييم قدرات نماذج العالم، مُغطيةً ثلاثة أبعاد أساسية: الإدراك، والمعرفة، والتجسيد. وهي مُقسّمة إلى 10 فئات مهام، تشمل فهم البيئة، والتعرّف على الكيانات وتصنيفها، والاستدلال القائم على التنبؤ، وتتضمن 100 سيناريو مُتنوّع مُصمّم لتقييم القدرات المعرفية وقدرات اتخاذ القرار للنماذج في بيئات مُعقّدة بشكل منهجي.
الاستخدام عبر الإنترنت:https://go.hyper.ai/hY0aP
7. مجموعة بيانات كشف الاحتيال في بطاقات الائتمان
تُعدّ مجموعة بيانات "الاحتيال ببطاقات الائتمان" أداةً لكشف عمليات الاحتيال ببطاقات الائتمان في سيناريوهات المعاملات المالية. وتهدف إلى دعم نماذج التعلّم الآلي في تحديد وتصميم نماذج للمعاملات غير الطبيعية، مع التركيز على حلّ مشكلة عدم توازن البيانات في السيناريوهات المالية، وبالتالي تحسين قدرات الكشف للنماذج في بيئات الأعمال الحقيقية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/3d8nS
8. مجموعة بيانات الكشف عن البريد الإلكتروني العشوائي
مجموعة بيانات الكشف عن البريد الإلكتروني العشوائي هي مجموعة بيانات مصنفة للبريد الإلكتروني تُستخدم في مهام الكشف عن البريد العشوائي. تهدف هذه المجموعة إلى دعم الأبحاث المتعلقة بنمذجة التصنيف، ومعالجة اللغة الطبيعية، وهندسة الميزات، وتحسين قدرة النموذج على تحديد البريد العشوائي.
الاستخدام عبر الإنترنت:https://go.hyper.ai/HkpX5
9. مجموعة بيانات أسئلة صوتية بسيطة
مجموعة بيانات "أسئلة صوتية بسيطة" هي مجموعة بيانات صوتية قصيرة أصدرتها جوجل. تحتوي هذه المجموعة متعددة اللغات على أسئلة صوتية قصيرة بـ 17 لغة من 26 منطقة، بمشاركة ما يقارب 700 متحدث. يقدم كل متحدث ما يصل إلى 250 عينة صوتية، تغطي لغات متعددة مثل العربية والإنجليزية واليابانية والكورية والهندية، وتشمل ظروف تسجيل متنوعة كالبيئات الهادئة وأصوات الخلفية وضوضاء المرور.
الاستخدام عبر الإنترنت:https://go.hyper.ai/lrKpK
10. مجموعة بيانات COCO-2017-Vietnamese للكشف عن الصور الفيتنامية
COCO-2017-Vietnamese هي مجموعة بيانات مُوسّعة للترجمة الفيتنامية، مبنية على مجموعة بيانات Common Objects in Context 2017 التي اقترحتها مايكروسوفت، وقام بتجميعها ونشرها مجتمع AI Enthusiasm. تُقدّم هذه المجموعة ترجمات فيتنامية عالية الجودة إلى جانب أوصاف الصور الإنجليزية الأصلية، مما يوفر معيارًا شاملاً ضمن إطار ثنائي اللغة، مناسبًا لمهام مثل التعليق على الصور والتعلم متعدد الوسائط.
الاستخدام عبر الإنترنت:https://go.hyper.ai/VM6gY
11. مجموعة بيانات GPT-5.4-step-by-step-reasoning
مجموعة بيانات GPT-5.4 للاستدلال التدريجي هي مجموعة بيانات استدلال اصطناعي عالية الكثافة مصممة لنمذجة الاستدلال طويل السلسلة (CoT) ومهام حل المشكلات المعقدة. تحتوي هذه المجموعة على ما يقارب 1500 عينة من المستوى النخبوي تغطي مجالات عالية التعقيد مثل الرياضيات والبرمجة والطب، مع ضبط صعوبة المهام بشكل موحد على مستويي "الخبير" و"ما بعد الدكتوراه".
الاستخدام عبر الإنترنت:https://go.hyper.ai/HjJlT
دروس تعليمية عامة مختارة
1. OmniVoice: يدعم تحويل النص إلى كلام عالي الجودة بأكثر من 600 لغة.
OmniVoice هو نموذج متعدد اللغات لتحويل النص إلى كلام (TTS) طوّره فريق Kaldi من الجيل التالي التابع لمختبر Xiaomi AI، ويدعم توليف الكلام عالي الجودة بأكثر من 600 لغة. يعتمد المشروع على بنية فك تشفير تكرارية غير مقنعة، وينفذ ثلاث وظائف أساسية: استنساخ الصوت، وتصميم الصوت، والصوت التلقائي.
تشغيل عبر الإنترنت:https://go.hyper.ai/BvKri
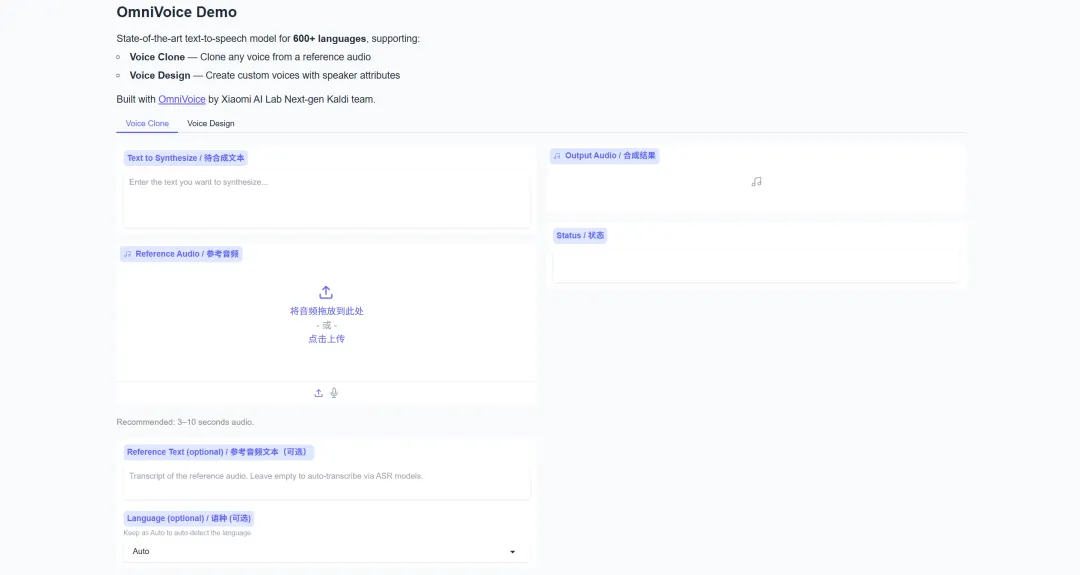
2. مساعد التعلم الشخصي DeepTutor
يُعدّ DeepTutor، الذي أطلقه مختبر ذكاء البيانات بجامعة هونغ كونغ في مارس 2026، نظامًا تعليميًا شاملًا مدعومًا بالذكاء الاصطناعي ومساعدًا شخصيًا للتعلم. يدمج المشروع أربع وحدات وظيفية أساسية: أسئلة وأجوبة معرفية ضخمة قائمة على الوثائق، وتصور تفاعلي للتعلم، وتعزيز المعرفة وتوليد أسئلة تدريبية، بالإضافة إلى البحث المعمق والتوليد الإبداعي، مما يوفر للمتعلمين تجربة تعليمية ذكية متكاملة.
تشغيل عبر الإنترنت:https://go.hyper.ai/8YnI3
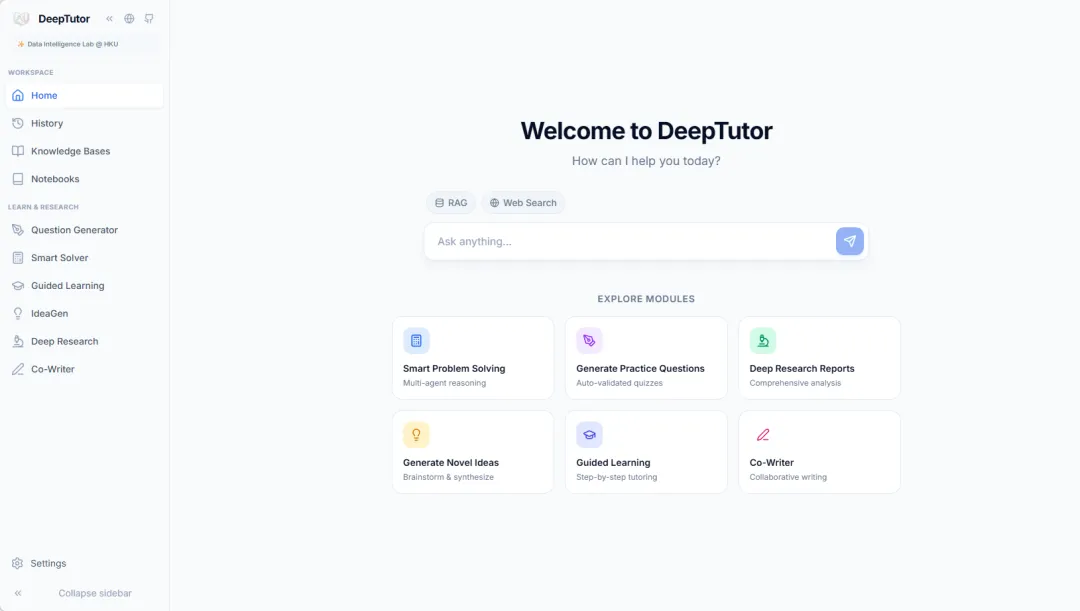
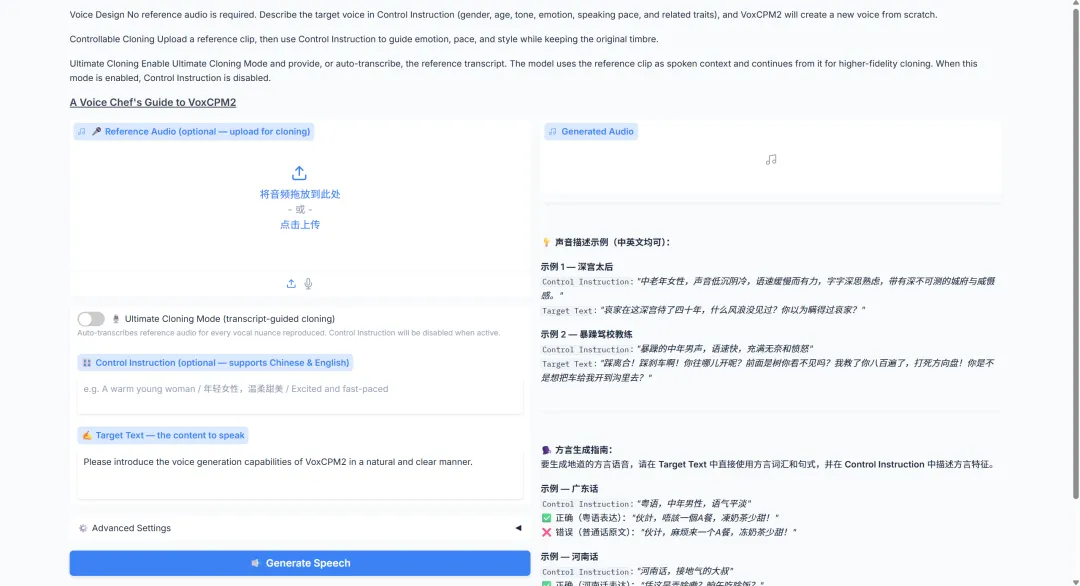
3. إعادة إنتاج الصوت في برنامج VoxCPM2: أكثر من 30 لغة، 9 لهجات
VoxCPM2 هو نموذج لتحويل النص إلى كلام، يعتمد على مقياس 2B من المعلمات، ولا يتطلب مُجزئ كلمات، وقد أصدرته شركة OpenBMB في أبريل 2026. يدعم النموذج 30 لغة، ولا يتطلب أي علامات لغوية إضافية، ويغطي استخدامات متنوعة، منها توليد نغمات جديدة من الصفر، والاستنساخ المُتحكم به بناءً على صوت مرجعي، والاستنساخ المُتقدم من خلال دمج الصوت المرجعي مع النص المكتوب، وضبط النبرة والتعبير تلقائيًا بناءً على محتوى النص. كما تُؤكد المواصفات الرسمية على مخرج بتردد 48 كيلوهرتز، والتوافق مع صوت مرجعي بتردد 16 كيلوهرتز، والتعبير المُراعي للسياق.
تشغيل عبر الإنترنت:https://go.hyper.ai/RLgK9
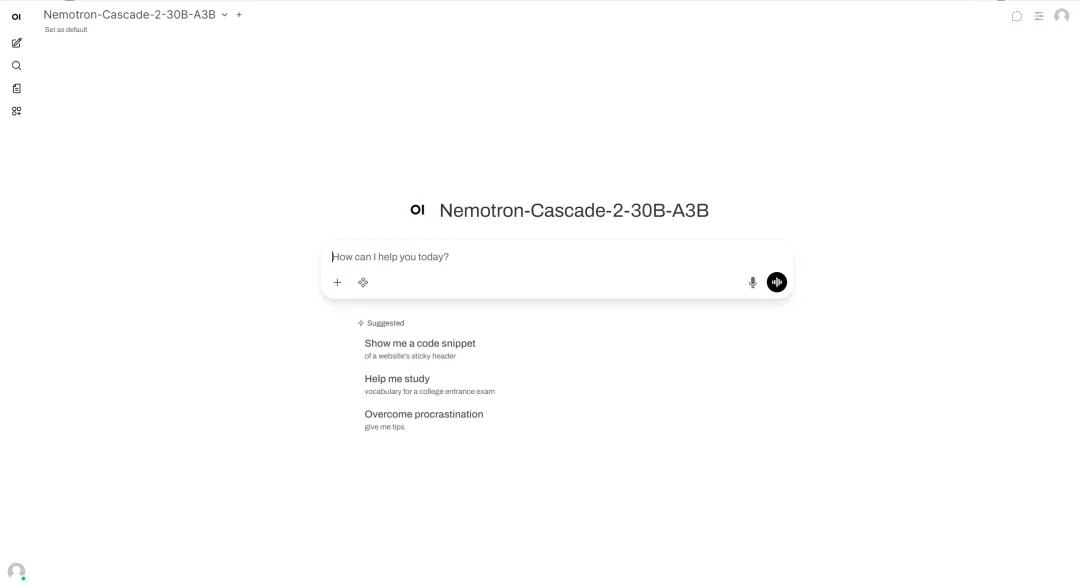
4. نشر Nemotron-Cascade-2-30B-A3B بنقرة واحدة
أصدرت شركة NVIDIA في مارس 2026 نموذج Nemotron-Cascade-2-30B-A3B، وهو نموذج لغوي مفتوح المصدر ذو حجم كبير، يحتوي على 30 مليار وحدة بيانات (MoE) وحوالي 3 مليارات مُعامل مُفعّل، وقد تم تدريبه على نموذج Nemotron-3-Nano-30B-A3B-Base. يركز النموذج بشكل أساسي على توفير قدرات قوية في الاستدلال والحوار والبرمجة والتحكم، مع دعمه في الوقت نفسه لنمطي التفكير والتعليم.
تشغيل عبر الإنترنت:https://go.hyper.ai/GoEaW
5. تقنية إزالة العناصر من الفيديو من خلال Netflix VOID: تقنية ثورية لإزالة العناصر من الفيديو مع مراعاة الوعي الفيزيائي.
Netflix VOID هو نموذج لتحرير الفيديو تم طرحه بشكل مشترك كمصدر مفتوح من قبل فريق Netflix وجامعة صوفيا في أبريل 2026. مع 5 مليارات معلمة، تم تصميم نموذج Netflix VOID لحل مشكلة الاتساق المادي في مرحلة ما بعد إنتاج الأفلام، بهدف التغلب على قيود تقنيات إكمال الفيديو التقليدية في التعامل مع المنطق السببي لتفاعلات الكائنات المعقدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/uZoMl
6. برنامج Fun-CineForge: نموذج موحد للدبلجة بدون عينات في سيناريوهات الأفلام والتلفزيون المتنوعة
Fun-CineForge هو مشروع دبلجة أفلام بدون لقطات تم إطلاقه بشكل مشترك من قبل فريق الكلام في مختبرات تونغي وجامعة العلوم والتكنولوجيا في الصين في يناير 2026. يتضمن المشروع خط أنابيب بيانات شامل لإنتاج مجموعات بيانات دبلجة واسعة النطاق ونموذج دبلجة يعتمد على نموذج متعدد الوسائط كبير (LMM)، مصمم لسيناريوهات أفلام متنوعة.
تشغيل عبر الإنترنت:https://go.hyper.ai/DyQKk
تفسير مقالة المجتمع
1. تصميم جديد مدفوع بالذكاء الاصطناعي لبروتينات ربط الجزيئات الصغيرة المتنوعة: اكتشف فريق من كوريا الجنوبية بروتينًا يمكنه التعرف بشكل انتقائي على هرمونات التوتر.
استخدم فريق بحثي من قسم العلوم البيولوجية في المعهد الكوري المتقدم للعلوم والتكنولوجيا (KAIST) تقنيات التعلم العميق لتوليد بنية البروتين وتصميم تسلسله، وذلك لتصميم بروتينات متنوعة ترتبط بجزيئات صغيرة، مستخدمًا طية NTF2 كهيكل أساسي، ثم حوّلها إلى مستشعرات مشابهة لتقنية التضاعف المحفز كيميائيًا (CID). وقد نجح الباحثون في تصميم بروتين قادر على التعرف بشكل انتقائي على هرمون الكورتيزول، وهو هرمون التوتر، وطوّروا مستشعرًا حيويًا يعتمد على الذكاء الاصطناعي.
شاهد التقرير الكامل:https://go.hyper.ai/FpAXm
2. نجح فريق فرنسي في التنبؤ بـ 2.39 مليون بروتين مضاد للفيروسات واستخدم نموذج التعلم العميق لرسم خريطة المناعة المضادة للفيروسات البكتيرية.
قام باحثون في معهد باستور بفرنسا بتطوير وتحسين ثلاثة نماذج تعلّم عميق متكاملة للتنبؤ واسع النطاق بمقاومة العاثيات. يعتمد نموذج ALBERT_DF كلياً على السياق الجينومي المحلي للاستدلال؛ بينما يستخدم نموذج ESM_DF نموذج لغة البروتين لتحليل تسلسلات الأحماض الأمينية؛ أما نموذج GeneCLR_DF فيدمج معلومات التسلسل مع السياق الجينومي.
شاهد التقرير الكامل:https://go.hyper.ai/J5Oz3
مقالات موسوعية شعبية
1. المهارات
2. الحقيقة الأساسية
3. العنصر البشري في الحلقة
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. دمج الرتب المتبادل
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* يوفر نقاط تنزيل محلية معجلة لأكثر من 2100 مجموعة بيانات عامة
* يتضمن أكثر من 700 درس تعليمي كلاسيكي وشائع عبر الإنترنت
* تحليل أكثر من 300 دراسة حالة من أوراق بحثية حول الذكاء الاصطناعي للعلوم
* يدعم البحث عن أكثر من 700 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








