Command Palette
Search for a command to run...
تقرير أسبوعي عن الأبحاث | يُمكّن برنامج ProgramBench الذكاء الاصطناعي من كتابة برامج من الصفر، مع فشل 9 نماذج رئيسية بشكل جماعي؛ يُظهر ExoActor قدرة قوية على تعميم المشاهد دون بيانات إضافية من العالم الحقيقي... نظرة سريعة على أحدث الأبحاث في مجال الذكاء الاصطناعي لهذا الأسبوع

مع تزايد استخدام نماذج اللغة في تطوير البرمجيات على المدى الطويل، لم تعد المعايير الحالية كافية لقياس أدائها في تصميم بنية النظام، وتقسيم الوحدات، والتنفيذ الهندسي الشامل. ولمعالجة هذه المشكلة، اقترح فريق SWE-Bench معيار ProgramBench: حيث يُزوّد النماذج فقط بالملف التنفيذي ووثائق الاستخدام، ويُطلب منها إعادة كتابة الكود ومحاكاة سلوك البرنامج.
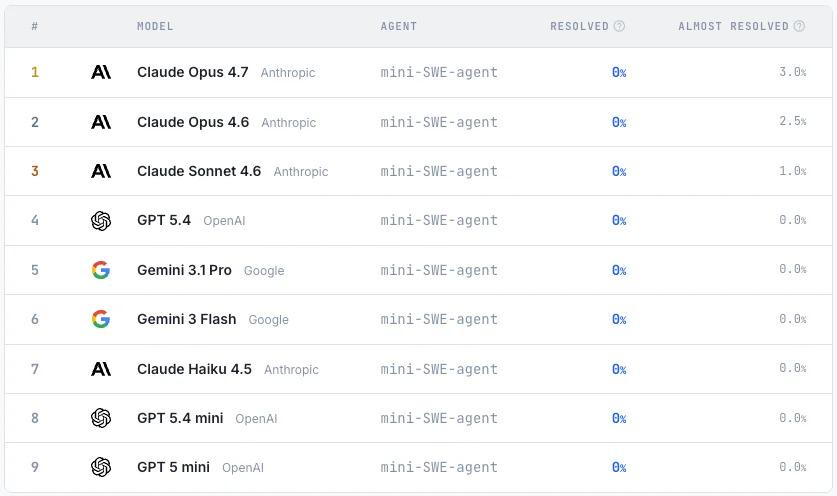
قامت الدراسة بإنشاء 200 مهمة تغطي أنواعًا مختلفة من البرامج، بما في ذلك قواعد البيانات والمترجمات وأدوات سطر الأوامر، وقامت بتقييم الاتساق بين البرنامج الذي تم إنشاؤه بواسطة النموذج والبرنامج الأصلي من خلال الاختبار السلوكي.تظهر النتائج التجريبية أن النماذج السائدة الحالية لا تزال تعاني في إكمال مهام إعادة بناء البرامج المعقدة، ولا يمكن لأي نموذج أن يجتاز جميع الاختبارات.حتى أفضل أداء لنموذج Claude Opus 4.7 لم يحقق سوى معدل نجاح عالٍ في عدد قليل من المهام، مما يشير إلى أن نماذج اللغة الكبيرة لا تزال تعاني من أوجه قصور كبيرة من حيث القدرات الشاملة لهندسة البرمجيات.
رابط الورقة:https://go.hyper.ai/wExzR
أحدث أبحاث الذكاء الاصطناعي:https://go.hyper.ai/hzChC
لمساعدة المزيد من المستخدمين على فهم أحدث التطورات في مجال الذكاء الاصطناعي في الأوساط الأكاديمية،يحتوي موقع HyperAI الإلكتروني (hyper.ai) الآن على قسم "أحدث الأوراق البحثية"، والذي يتم تحديثه بانتظام بأحدث أوراق البحث في مجال الذكاء الاصطناعي.إليكم ثمانية أبحاث شائعة في مجال الذكاء الاصطناعي نوصي بها. دعونا نلقي نظرة سريعة على أحدث إنجازات الذكاء الاصطناعي لهذا الأسبوع ⬇️
توصيات الورقة البحثية لهذا الأسبوع
1. برنامج بنش
عنوان الورقة:
برنامج بنش: هل يمكن لنماذج اللغة إعادة بناء البرامج من الصفر؟
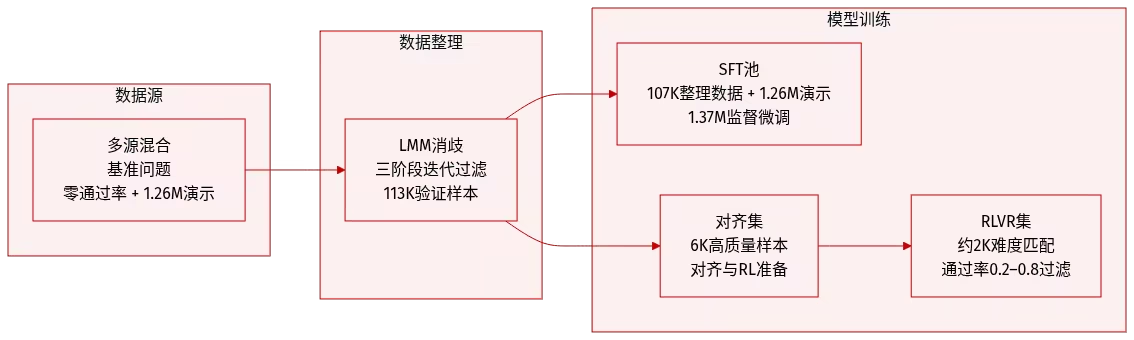
اقترح فريق البحث برنامج ProgramBench لتقييم قدرة برامج هندسة البرمجيات على بناء مشاريع برمجية كاملة من الصفر. يتطلب هذا المعيار من البرنامج تنفيذ قاعدة بيانات برمجية تتصرف بشكل متسق مع ملف تنفيذي مرجعي، بالاعتماد فقط على البرنامج والوثائق، ثم تقييمها من البداية إلى النهاية من خلال اختبار عشوائي موجه من قبل البرنامج.
يحتوي برنامج ProgramBench على 200 مهمة، تغطي أنواعًا مختلفة من البرامج، بما في ذلك أدوات سطر الأوامر، وFFmpeg، وSQLite، ومفسرات PHP. تُظهر التجارب التي أُجريت على تسعة نماذج لغوية أن النماذج الحالية ذات أداء عام محدود. لم ينجح أفضل نموذج إلا في اجتياز اختبار 95% في مهمة 3%، ويُظهر الكود المُولّد عمومًا بنيةً متجانسةً أحادية الملف، وهو ما يختلف اختلافًا كبيرًا عن ممارسات هندسة البرمجيات البشرية.
ورقة وتفسير مفصل:https://go.hyper.ai/wExzR
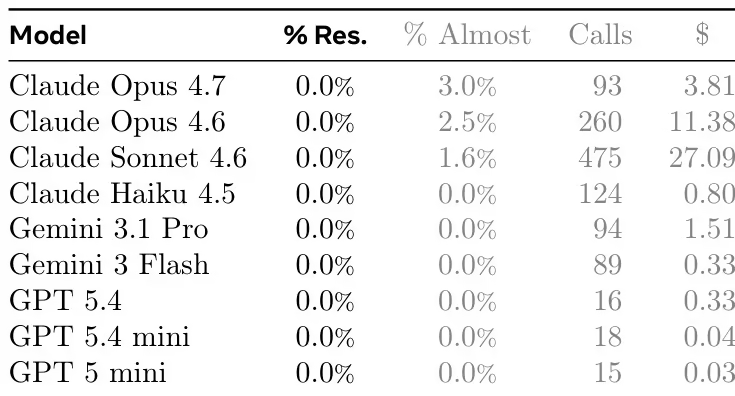
تكوين مجموعة البيانات ومصادرها: جمع المؤلفون 200 مثالًا لمهام من مستودعات GitHub مفتوحة المصدر. تم اختيار المصادر من مشاريع تُنتج ملفات تنفيذية مستقلة، مكتوبة في الغالب بلغات Rust أو Go أو C/C++. تشمل المجموعة فئات وظيفية متنوعة مثل معالجة النصوص، وأدوات النظام، ومترجمات اللغات.

2. عيادة خارجية موحدة
عنوان الورقة:
Uni-OPD: توحيد عملية التقطير على مستوى السياسة باستخدام وصفة ذات منظور مزدوج
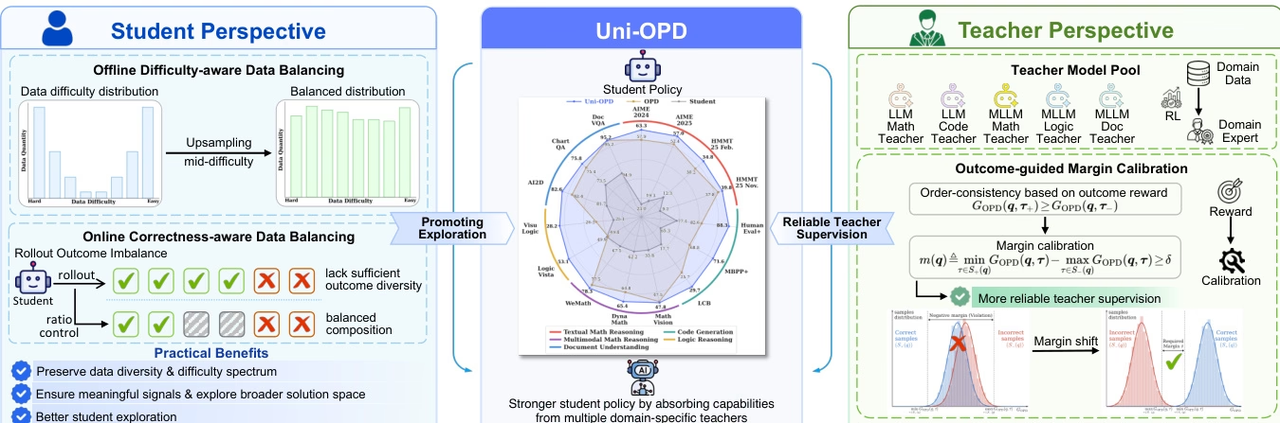
Uni-OPD هو إطار عمل موحد للتقطير عبر الإنترنت لنماذج التعلم الموجه بالقانون (LLMs) ونماذج التعلم الموجه بالتعلم المتعدد (MLLMs)، مصمم لتحسين نقل المعرفة متعددة الخبراء إلى نماذج الطلاب. تشير الأبحاث إلى أن أساليب التقطير عبر الإنترنت الحالية محدودة بشكل أساسي بمشكلتين: عدم كفاية استكشاف الحالات ذات المعلومات العالية، وإشارات إشراف المعلم غير الموثوقة.
لمعالجة هذه المشكلة، يستخدم نظام Uni-OPD استراتيجية تحسين ثنائية المنظور: فمن جانب الطالب، يقدم استراتيجية لموازنة البيانات لتعزيز استكشاف الحالات الغنية بالمعلومات؛ ومن جانب المعلم، يقترح آلية معايرة هامشية موجهة بالنتائج لاستعادة التناسق التسلسلي بين المسارات الصحيحة والخاطئة، مما يحسن موثوقية الإشراف. وقد أكدت التجارب التي شملت خمسة مجالات وستة عشر معيارًا، وتضمنت إعدادات متنوعة مثل المعلم الواحد، والمعلمين المتعددين، والتقطير من القوي إلى الضعيف، والتقطير متعدد الوسائط، فعالية هذه الطريقة.
ورقة وتفسير مفصل:https://go.hyper.ai/8k4du
3. عدم اليقين المخلص
عنوان الورقة:
الهلوسات تقوض الثقة؛ ما وراء المعرفة هو سبيل للمضي قدماً
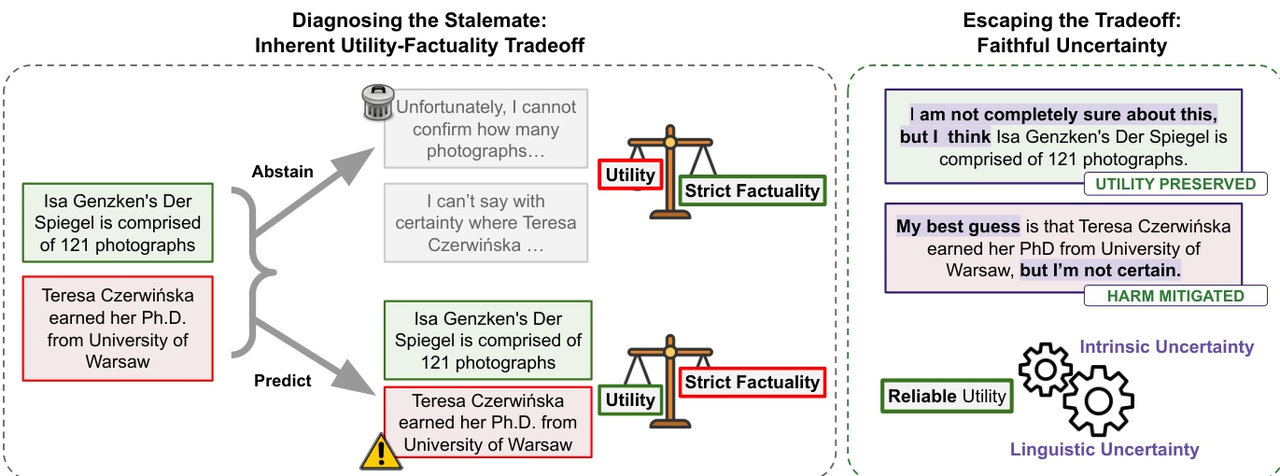
يشير فريق البحث إلى أنه على الرغم من التحسن المستمر في دقة نماذج اللغة الكبيرة من حيث موثوقيتها الواقعية، إلا أن مشكلة "الوهم" لا تزال قائمة، لا سيما في سيناريوهات الإجابة على الأسئلة الواقعية التي تفتقر إلى أدوات خارجية. وتجادل الدراسة بأن التقدم الحالي ينبع من توسيع نطاق المعرفة أكثر من قدرة النموذج الحقيقية على التمييز بين "المعروف" و"المجهول". لذا، قد يشكل القضاء التام على الأوهام مفاضلة طبيعية مع جدوى النموذج.
انطلاقاً من هذا المنظور، تقترح الدراسة مفهوم "الشك الصادق"، مؤكدةً على ضرورة أن تُعبّر النماذج بصدق عن شكها الخاص، بما يضمن التوافق بين الشك اللغوي والإدراك الداخلي. لا تُسهم هذه القدرة المعرفية العليا في تحسين مصداقية النموذج فحسب، بل تُوفر أيضاً آلية تحكم أكثر موثوقية للبحث واتخاذ القرارات في أنظمة الوكلاء الأذكياء.
ورقة وتفسير مفصل:https://go.hyper.ai/G77rj
تكوين مجموعة البيانات ومصدرها: قام المؤلفون بإنشاء مجموعة بيانات اصطناعية تحتوي على 25000 عينة لإعادة إنتاج خصائص توزيع الثقة التجريبية التي سجلها ناكيران وآخرون (2025).

4. موشور
عنوان الورقة:
ما وراء SFT-to-RL: المحاذاة المسبقة عبر التقطير على السياسة باستخدام الصندوق الأسود للتعلم المعزز متعدد الوسائط
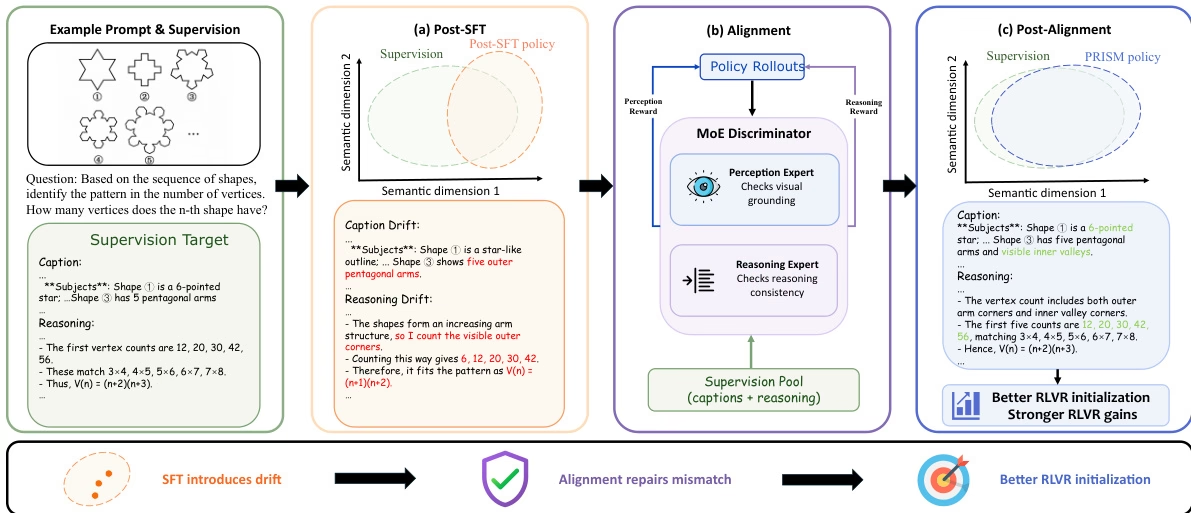
لمعالجة مشكلة تحول التوزيع الذي يؤثر على التعلم المعزز اللاحق أثناء الضبط الدقيق للنماذج متعددة الوسائط الكبيرة، اقترح فريق البحث عملية من ثلاث مراحل تسمى PRISM. تُدخل هذه الطريقة مرحلة مواءمة التوزيع بناءً على التقطير داخل السياسة بين الضبط الدقيق الخاضع للإشراف والتعلم المعزز، وتستخدم مُميز خبير هجين (MoE) لتوفير إشارات تصحيح الفصل.
باستخدام 113000 مجموعة بيانات تجريبية عالية الجودة من Gemini، حسّن PRISM بشكل كبير أداء التعلم المعزز في تجربة Qwen3-VL، مما أدى إلى زيادة دقة نماذج 4B و 8B بمقدار 4.4 و 6.0 نقطة على التوالي.
ورقة وتفسير مفصل:https://go.hyper.ai/5fsD3
تكوين مجموعة البيانات ومصادرها: تُنشئ هذه الورقة البحثية مجموعة بيانات متعددة الوسائط للاستدلال، مستمدة من اختبارات معيارية متاحة للعموم تغطي الاستدلال الرياضي، وفهم الرسوم البيانية العلمية، وتفسير الرسوم البيانية، والاستدلال المكاني. ولتوسيع نطاق التغطية وتعزيز الاستقرار، أُضيفت إلى هذه المجموعة المختارة بعناية 1.26 مليون بيانات تجريبية متاحة للعموم، تم إنشاؤها بواسطة نفس سلسلة نماذج جيميني.
5. إكسوأكتور
عنوان الورقة:
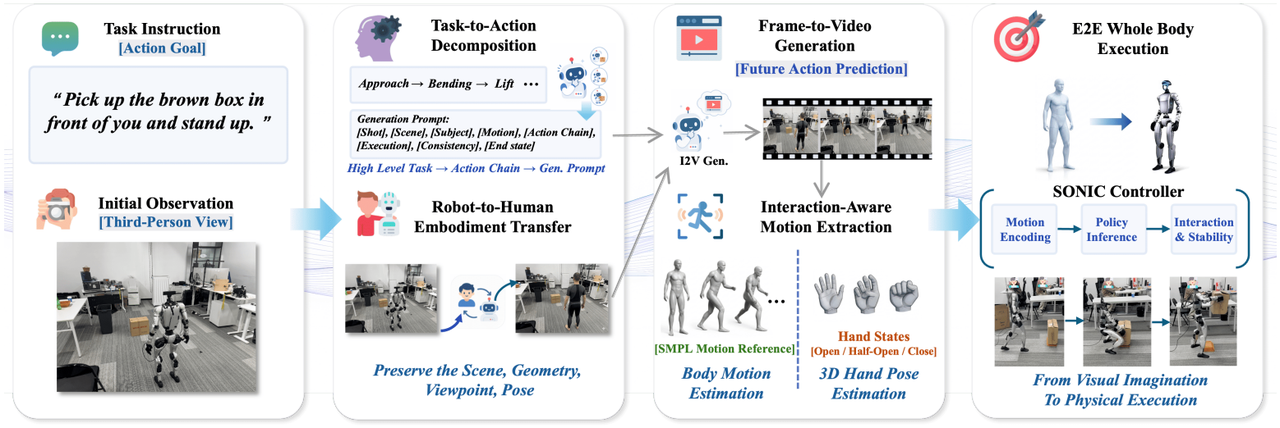
ExoActor: توليد الفيديو الخارجي كتحكم تفاعلي قابل للتعميم للروبوتات البشرية
اقترح فريق البحث إطار عمل ExoActor، الذي يستخدم توليد الفيديو الخارجي كواجهة موحدة لترميز التفاعلات التعاونية بين الروبوت والبيئة والأشياء ضمنيًا. كما يحوّل فيديو التنفيذ المُصنّع إلى سلوكيات روبوتية بشرية قابلة للتنفيذ من خلال تقدير حركة الإنسان ووحدة تحكم عامة في الحركة، مما يُظهر القدرة على التعميم على سيناريوهات جديدة دون الحاجة إلى جمع بيانات إضافية في الموقع.
ورقة وتفسير مفصل:https://go.hyper.ai/OE5IH
6. تحرير-R1
عنوان الورقة:
الاستفادة من التعلم المعزز القائم على التحقق في تحرير الصور
اقترح فريق البحث إطار عمل Edit-R1، وهو إطار عمل للتعلم المعزز لتحرير الصور. على عكس نماذج المكافأة التقليدية التي تُخرج درجة إجمالية فقط، يُقسّم Edit-R1 تعليمات التحرير إلى مبادئ متعددة، ويتحقق من نتائج التحرير عنصرًا بعنصر استنادًا إلى منطق تسلسل الأفكار، مما يُولّد إشارات مكافأة أكثر دقة وقابلية للتفسير. كما يجمع البحث بين الضبط الدقيق الخاضع للإشراف واستراتيجيات التعلم المعزز GCPO لتحسين قدرة نموذج المكافأة على محاكاة تفضيلات المستخدم، ويستخدم GCPO لتدريب نماذج التحرير اللاحقة.
تُظهر النتائج التجريبية أن Edit-RRM يتفوق على نماذج VLM القوية مثل Seed-1.5-VL و Seed-1.6-VL في تقييم تحرير الصور، ويُحسّن بشكل كبير أداء نماذج التحرير مثل FLUX.1-kontext، مع إظهار فوائد كبيرة من توسيع المعلمات.
ورقة وتفسير مفصل:https://go.hyper.ai/MtBLB
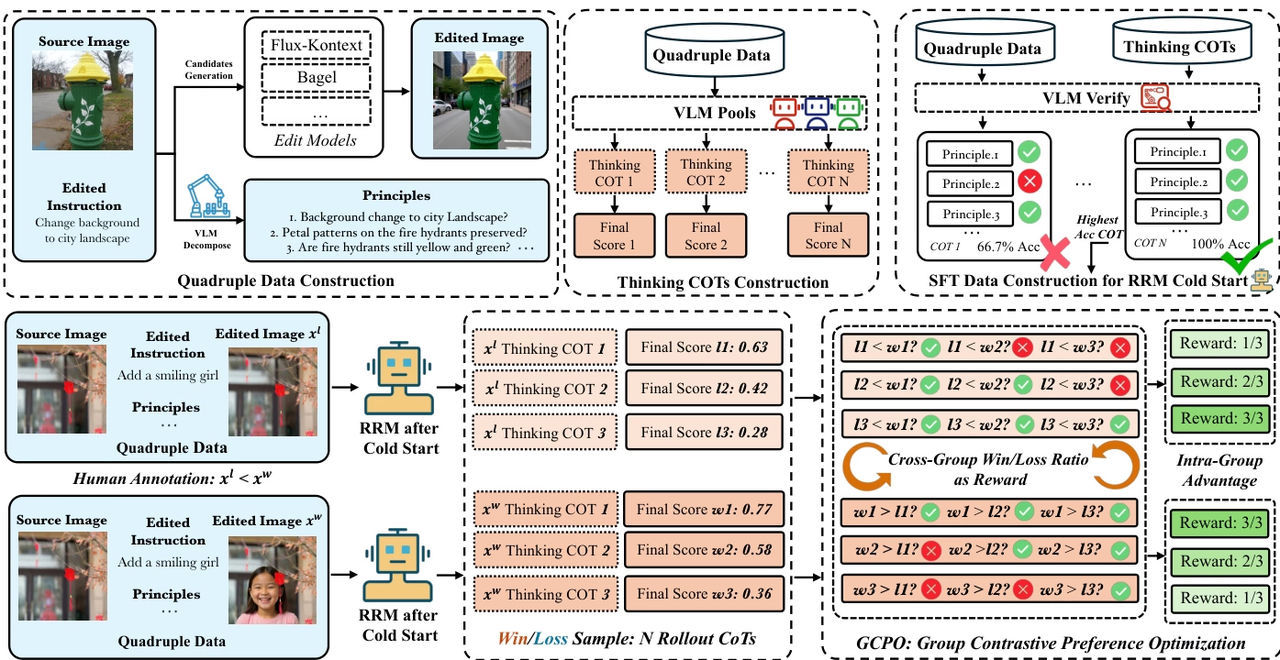
تكوين مجموعة البيانات ومصدرها: قام فريق البحث بإنشاء مجموعة بيانات خاضعة للإشراف لنموذج مكافأة الاستدلال ذي البداية الباردة، وذلك بتجميع 200,000 عينة من معايير تحرير الصور المتاحة للعموم. وتم توسيع هذه المجموعة الأولية لتشمل ما يقارب مليوني مجموعة بيانات رباعية من خلال توليد نماذج متعددة والتحقق المنهجي.

7. تقطير السياسات المتطورة بشكل مشترك
عنوان الورقة:
تقطير السياسات المتطورة بشكل مشترك
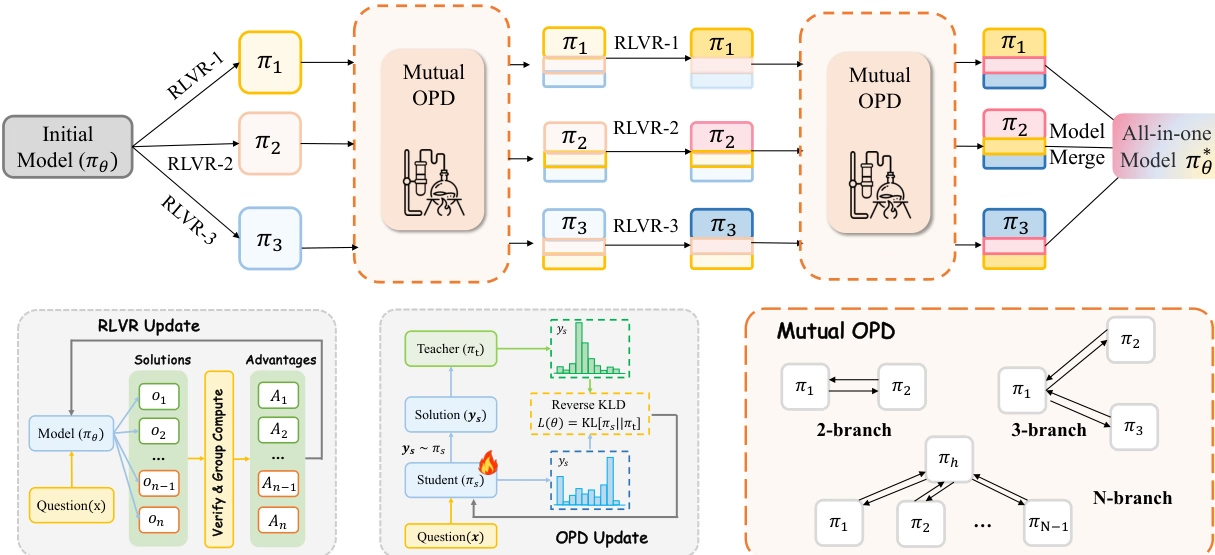
أجرى فريق البحث تحليلًا موحدًا لنموذجي التدريب السائدين بعد التدريب، وهما RLVR و OPD، وأشار إلى أن لكل منهما قيودًا مختلفة في عملية دمج قدرات الخبراء المتعددة: فنموذج RLVR الهجين عرضة لـ "تكاليف تباين القدرات"، بينما تتجنب العملية التقليدية المتمثلة في "تدريب الخبراء أولاً ثم تطبيق OPD" تعارض القدرات، ولكن نظرًا للاختلافات الكبيرة في الأنماط السلوكية بين المعلمين والطلاب، فمن الصعب وراثة قدرات الخبراء بشكل كامل.
لمعالجة هذه المشكلة، تقترح هذه الدراسة استراتيجية تطورية مشتركة، تُسمى CoPD (المعالجة التطورية المشتركة)، تُدخل معالجة ثنائية الاتجاه OPD (مشتق المعالجة البصرية) بالتزامن مع تدريب الخبراء المستمر على RLVR (الاستدلال المرجعي القائم على RLVR). يُمكّن هذا الخبراء من العمل كمعلمين لبعضهم البعض والتطور معًا، مما يُحسّن اتساق السلوك مع الحفاظ على القدرات التكميلية. تُظهر النتائج التجريبية أن CoPD تُدمج بفعالية قدرات الاستدلال النصي والمرئي، متفوقةً بشكل ملحوظ على النماذج الأساسية القوية مثل RLVR الهجين وMOPD، بل وتتجاوز نماذج خبراء المجال في بعض المهام.
ورقة وتفسير مفصل:https://go.hyper.ai/cCyrG

8. كلاو جيم
عنوان الورقة:
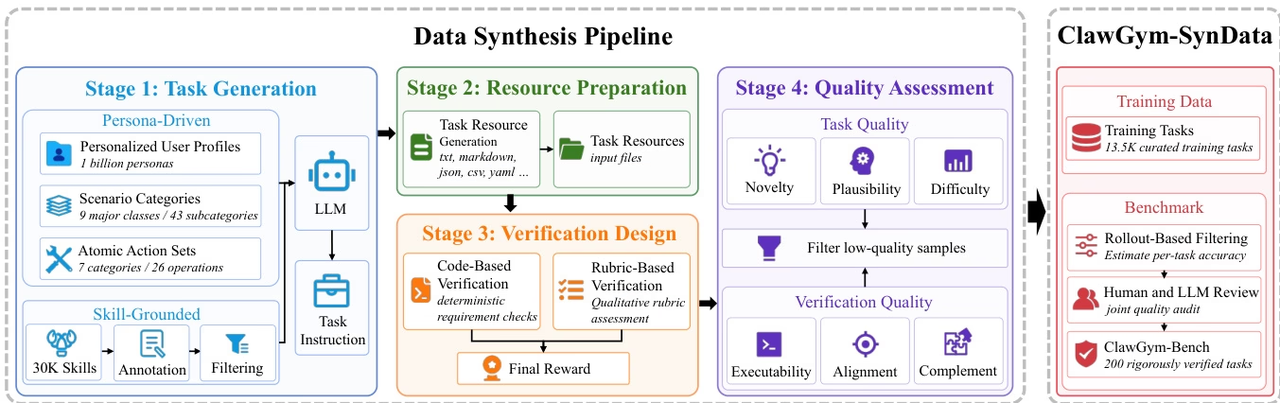
كلو جيم: إطار عمل قابل للتطوير لبناء وكلاء مخالب فعالين
اقترح فريق البحث ClawGym، وهو إطار عمل قابل للتطوير لدورة الحياة الكاملة لتطوير الوكلاء الشخصيين على نمط Claw، لدعم سير العمل المعقد متعدد الخطوات الذي يتضمن الملفات المحلية واستدعاءات الأدوات وحالات مساحة العمل المستمرة.
يتضمن هذا الإطار مجموعة البيانات الاصطناعية ClawGym-SynData، التي تغطي 13500 مهمة مختارة، ويجمع بين النية البشرية، والتشغيل الماهر، وبيئة العمل المحاكاة، وآليات التحقق الهجينة. يتم تدريب وكلاء ClawGym-Agents بناءً على مسارات تنفيذ الصندوق الأسود، ويتم تحسين قدراتهم من خلال مسار تعلم معزز خفيف الوزن. بالإضافة إلى ذلك، تم إنشاء مجموعة مرجعية ClawGym-Bench، التي يتم اختيارها تلقائيًا ومراجعتها ومعايرتها بشكل مشترك من قبل البشر ونموذج التعلم المعزز، وذلك لإجراء تقييم موثوق.
ورقة وتفسير مفصل:https://go.hyper.ai/yZwa5
مصدر مجموعة البيانات: قام فريق البحث بإنشاء بيانات التدريب باستخدام إطار عمل ClawGym-SynData، الذي يجمع بين التوليف التنازلي القائم على الشخصية لسيناريوهات المستخدم المتنوعة والتوليف التصاعدي القائم على تقنية ربط إمكانيات OpenClaw في سير عمل حقيقي.
هذا هو محتوى توصيات البحث لهذا الأسبوع. لمزيد من أبحاث الذكاء الاصطناعي المتطورة، يُرجى زيارة قسم "أحدث الأبحاث" على الموقع الرسمي لـ hyper.ai.
نرحب أيضًا بفرق البحث لتقديم نتائج وأوراق بحثية عالية الجودة إلينا. يمكن للمهتمين إضافة حساب نيوروستار على وي تشات (معرف وي تشات: Hyperai01).
نراكم في الاسبوع القادم!








