Command Palette
Search for a command to run...
إخراج الصور بأربع خطوات / جودة 4K / تسريع 6x، يستخدم PiD انتشار البكسل لتوحيد فك التشفير وإخراج الدقة الفائقة؛ SA-3DAO: مجموعة بيانات تحتوي على 1000 زوج من الصور الحقيقية المقترنة بشبكات ثلاثية الأبعاد مصممة يدويًا بواسطة فنانين.

PiD هو نموذج جديد لفك تشفير الفضاء الكامن، أطلقته شركة NVIDIA. يُعيد هذا النموذج تعريف عملية فك التشفير التقليدية باستخدام VAE، حيث يُصبح توليدًا مشروطًا لانتشار البكسل، مُوحِّدًا بذلك فك التشفير وزيادة الدقة الفائقة في وحدة توليد واحدة. تعمل نماذج الانتشار الكامن التقليدية على استعادة المتغيرات الكامنة للصورة من خلال VAE، مما ينتج عنه دقة إخراج محدودة. علاوة على ذلك، تُعاني مُفكِّكات التشفير المُوجَّهة نحو إعادة البناء من صعوبة استعادة التفاصيل عالية التردد، ولا يُمكنها تصحيح التشوهات في المتغيرات الكامنة.يقدم PiD محولًا خفيف الوزن للمتغيرات الكامنة الواعية بالضوضاء (محول واعٍ بـ Sigma) لحقن المتغيرات الكامنة المشوشة في شبكة العمود الفقري لانتشار البكسل المكاني.يُمكّن هذا النموذج من التعامل مع المتغيرات الكامنة المُزالة التشويش بالكامل، وإنهاء عملية الانتشار قبل الأوان بالنسبة للمتغيرات الكامنة المُزالة التشويش جزئيًا. وبفضل تقنية التقطير DMD2، يُمكن إتمام الاستدلال في أربع خطوات فقط لإزالة التشويش.
يعرض موقع HyperAI الآن "PiD: 4K Super-Resolution Image Generation and Editing"، لذا تعال وجربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/a34Cx
نرحب بكم لزيارة موقعنا الإلكتروني الرسمي لمزيد من المعلومات:
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 19 يونيو إلى 26 يونيو:
* مجموعات بيانات عامة عالية الجودة: 7
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 14
* تفسير المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات إعادة بناء الكائنات ثلاثية الأبعاد للفنانين SAM 3D
مجموعة بيانات SAM 3D Artist Objects هي مجموعة بيانات لربط الشبكات ثلاثية الأبعاد، أصدرتها شركة Meta في يونيو 2026. تهدف هذه المجموعة إلى تقييم أداء خوارزميات إعادة بناء الأشكال والتخطيطات ثلاثية الأبعاد للأجسام في مشاهد واقعية، وتُستخدم على نطاق واسع لاختبار أداء خوارزميات تحويل الصور إلى أجسام ثلاثية الأبعاد، وتحسين النماذج، والأبحاث ذات الصلة في مجال رؤية الحاسوب. تحتوي هذه المجموعة على 1000 زوج من الصور الحقيقية المقترنة بشبكات ثلاثية الأبعاد صممها فنانون محترفون.
الاستخدام عبر الإنترنت:https://go.hyper.ai/rn2aF
2. مجموعة بيانات تقييم الذاكرة طويلة المدى RHELM
RHELM هي مجموعة بيانات لتقييم الذاكرة طويلة المدى، أصدرتها مايكروسوفت عام 2026. تهدف هذه المجموعة إلى تحسين قدرات الذاكرة طويلة المدى، والاستدلال متعدد الخطوات، وتوليف المعلومات الزمنية للنماذج الكبيرة في سيناريوهات معقدة وديناميكية. تُستخدم هذه المجموعة على نطاق واسع في مجالات بحثية مثل تقييم الذاكرة الزمنية طويلة المدى لنماذج اللغة الكبيرة، والتحقق من قدرات التفاعل طويلة المدى لمساعدي الذكاء الاصطناعي، والاستدلال متعدد الخطوات للنماذج الكبيرة، ودمج المعلومات الزمنية، والكشف عن الهلوسة.
الاستخدام عبر الإنترنت:https://go.hyper.ai/OGkUl
3. مجموعة بيانات تقييم المعرفة الثقافية متعددة اللغات MAKIEVAL
MAKIEVAL هي مجموعة بيانات لتقييم المعرفة الثقافية متعددة اللغات، صدرت عام 2026 من مختبر أبحاث MaiNLP بجامعة ميونخ بالتعاون مع مركز ميونخ للتعلم الآلي. تهدف هذه المجموعة إلى توفير معيار واسع النطاق لتقييم المعرفة الثقافية متعددة اللغات لنماذج اللغة الكبيرة، وتُستخدم على نطاق واسع في أبحاث تمثيل المعرفة متعددة اللغات ونمذجة المعرفة الثقافية. تحتوي هذه المجموعة على نصوص مُولّدة بواسطة سبعة نماذج لغوية كبيرة في 13 لغة، و19 دولة/منطقة، و6 مجالات ثقافية، بالإضافة إلى كياناتها الثقافية المستخرجة تلقائيًا ونتائج مواءمتها مع ويكي بيانات.
الاستخدام عبر الإنترنت:https://go.hyper.ai/v7zip
4. مجموعة بيانات استخراج الأدلة من شروط استعلام النطاقات الحرفية
مجموعة بيانات Verbatim Spans، التي أصدرتها جامعة فيينا التقنية بالتعاون مع مختبرات KRLabs في أبريل 2026، هي مجموعة بيانات لاستخراج الأدلة الشرطية من الاستعلامات متعددة المجالات. تهدف هذه المجموعة إلى بناء معيار عام لتدريب نماذج استخراج الأدلة الشرطية من الاستعلامات، وهي قابلة للتطبيق على نطاق واسع في مجال تعزيز الاسترجاع (RAG) ومهام الإجابة على الأسئلة الاستخلاصية. تحتوي مجموعة البيانات على 174,383 صفًا من بيانات التدريب و20,174 صفًا من بيانات التحقق، وتغطي ثلاثة أنواع رئيسية من المدونات: أوراق معالجة اللغة الطبيعية، والإجابة على الأسئلة متعددة المجالات، ومخرجات البرامج والأدوات.
الاستخدام عبر الإنترنت:https://go.hyper.ai/hbpjR
5. مجموعة بيانات الاستدلال الرياضي SFT من Nemotron-SFT-Math-v4
Nemotron-SFT-Math-v4 هي مجموعة بيانات للاستدلال الرياضي، أصدرتها NVIDIA في مايو 2026. تهدف هذه المجموعة إلى معالجة مشكلات عدم اتساق الجودة، ومسارات الاستدلال غير القياسية، وانخفاض الدقة، ومحدودية تنوع السيناريوهات في مجموعات البيانات الرياضية التقليدية، مما يُحسّن بشكل فعّال قدرات النموذج في الاستدلال المنظم، والاستدلال متعدد المسارات، والتحقق من الإجابات. تحتوي هذه المجموعة على 545,431 عينة تدريبية، منها 285,516 عينة استدلال موجهة نحو المحتوى (COT)، و259,915 عينة استدلال باستخدام أداة تتبع الاستدلال (TIR)، وتغطي سيناريوهات رياضية على مستوى المسابقات والبحوث في مجالات الجبر، والهندسة، ونظرية الأعداد، والتوافقية، وغيرها.
الاستخدام عبر الإنترنت:https://go.hyper.ai/6ooPw
6. تأثير الذكاء الاصطناعي على الوظائف ومخاطر التسريح: مجموعة بيانات تأثير الذكاء الاصطناعي على التوظيف
تُعدّ مجموعة بيانات الذكاء الاصطناعي "تأثير الذكاء الاصطناعي على الوظائف ومخاطر التسريح" مجموعة بيانات اصطناعية مُهيكلة للتعلم الآلي، تُعنى بدراسة تأثير الذكاء الاصطناعي على التوظيف. وتهدف هذه المجموعة إلى استكشاف تأثير تبني الذكاء الاصطناعي، وأتمتة الوظائف، وخصائصها، ومهارات القوى العاملة على نتائج التوظيف في الاقتصاد الحديث، ولها تطبيقات واسعة في مهام مثل نمذجة التصنيف، وتحليل القوى العاملة، وبحوث تأثير الأتمتة، ودعم قرارات الموارد البشرية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/38bZl
7. التحول العالمي في المناخ والطاقة 2000-2026 - مجموعة بيانات المناخ والطاقة العالمية
تُعدّ مجموعة بيانات التحول المناخي والطاقي العالمي 2000-2026 مجموعة بيانات عالمية للتحول المناخي والطاقي، تُستخدم في أبحاث تغير المناخ، والتحول الطاقي، وخفض انبعاثات الكربون، بهدف تصوير عمليات تغير المناخ والتحول الطاقي على مستوى العالم بشكل منهجي. وتسجل هذه المجموعة بيانات تغير المناخ والتحول الطاقي العالميين من عام 2000 إلى عام 2026، وتغطي شذوذات درجات الحرارة العالمية والإقليمية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/ogrSa
دروس تعليمية عامة مختارة
1. برنامج PiD: توليد وتحرير الصور بدقة 4K فائقة الوضوح
PiD هو برنامج فك تشفير فائق الدقة سهل الاستخدام من فريق NVIDIA. تستخدم نماذج الانتشار التقليدية مُفكِّك VAE لاستعادة التمثيل الكامن للصورة، مع دقة إخراج محدودة إلى حوالي 1024 بكسل. يستبدل PiD الخطوة الأخيرة من فك تشفير VAE بعملية انتشار في فضاء البكسل، مما يتطلب 4 خطوات فقط لإزالة التشويش لإنتاج صورة 4K واضحة مباشرةً دون أي تقنيات معالجة لاحقة. وبذلك، يتجاوز PiD بشكل ملحوظ عنق الزجاجة في الدقة للطرق التقليدية دون تغيير بنية النموذج الأصلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/a34Cx
2. مولد الفيديو LTX-2.3-turbo
LTX-2.3-turbo هو نموذج مفتوح المصدر لتوليد الفيديو، أطلقته شركة Lightricks في مارس 2026، وهو مصمم لتوسيع آفاق إمكانيات توليد الفيديو مفتوحة المصدر. يستخدم هذا النموذج بنية محول انتشار متطورة، ويجمعها مع قدرات فهم الوسائط المتعددة لتحقيق توليد محتوى فيديو عالي الجودة ومتعدد الدقة.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/oepch
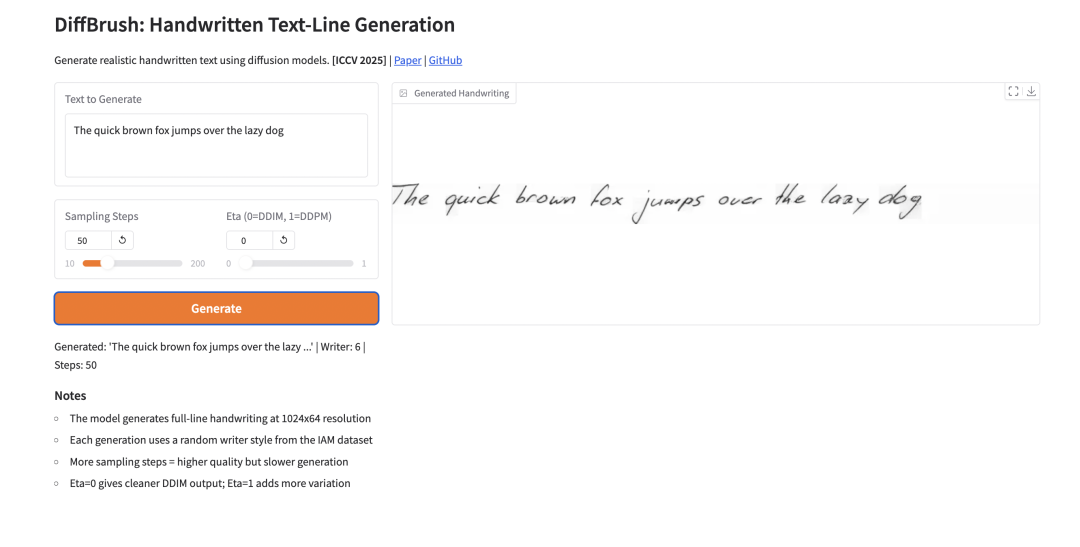
3. DiffBrush: إنشاء سطور نصية مكتوبة بخط اليد
أصدرت جامعة نانكاي وشركة كونلون للتكنولوجيا نموذج DiffBrush لتوليد سطور النصوص المكتوبة بخط اليد في أغسطس 2025، والذي تم اعتماده رسميًا في مؤتمر ICCV 2025 في أكتوبر من العام نفسه. يعتمد النموذج على بنية Stable Diffusion VAE+UNet، ويدعم إدخال أي نص إنجليزي و496 نمطًا من أنماط الكتابة اليدوية من مجموعة بيانات IAM، ويُخرج صورة رمادية بدقة 1024×64. يمكن التحكم بشكل مستقل في محتوى النص ونمط الكتابة اليدوية. يتميز النموذج بسهولة استخدامه، ويمكن استخدامه مباشرةً لتوليد مجموعات تدريب OCR، وتوسيع بيانات الكتابة اليدوية، ومحاكاة المستندات.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/qVvl5
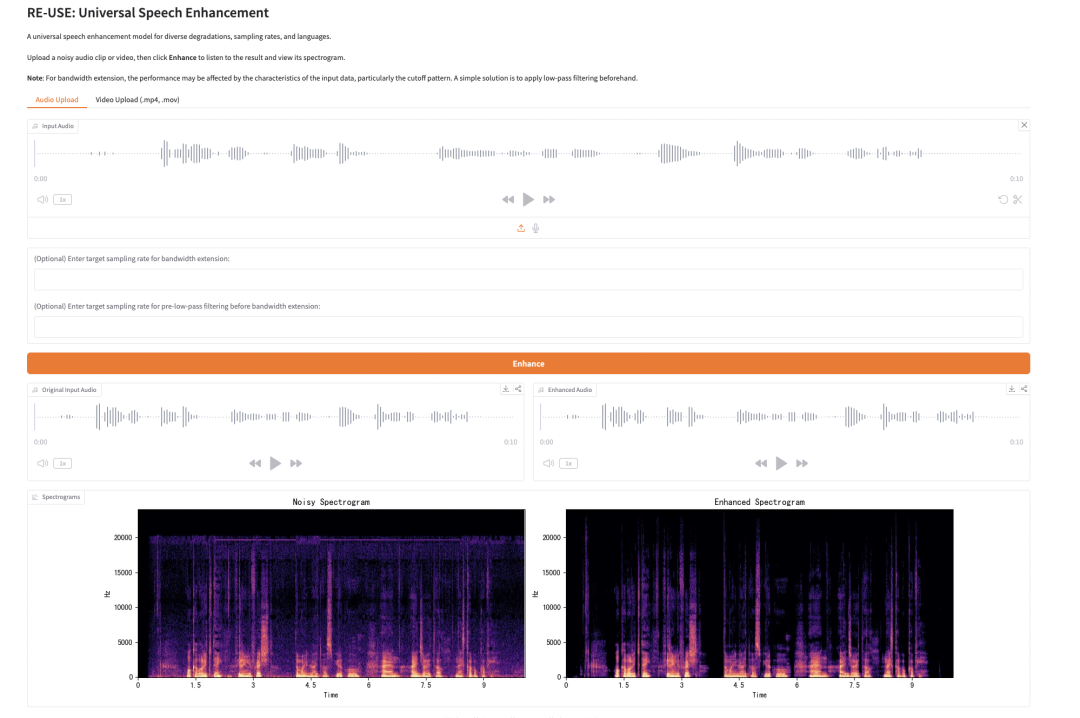
4. إعادة الاستخدام: نموذج عام لتحسين جودة الكلام
RE-USE هو نموذج لتحسين الكلام للأغراض العامة تم إصداره بواسطة NVIDIA في مارس 2026. يعتمد على بنية Mamba، ويمكنه التعامل مع إشارات الكلام المشوشة بمعدلات أخذ عينات وأنواع تدهور مختلفة، وهو مستقل عن اللغة.
تشغيل عبر الإنترنت:https://go.hyper.ai/MJ0p5
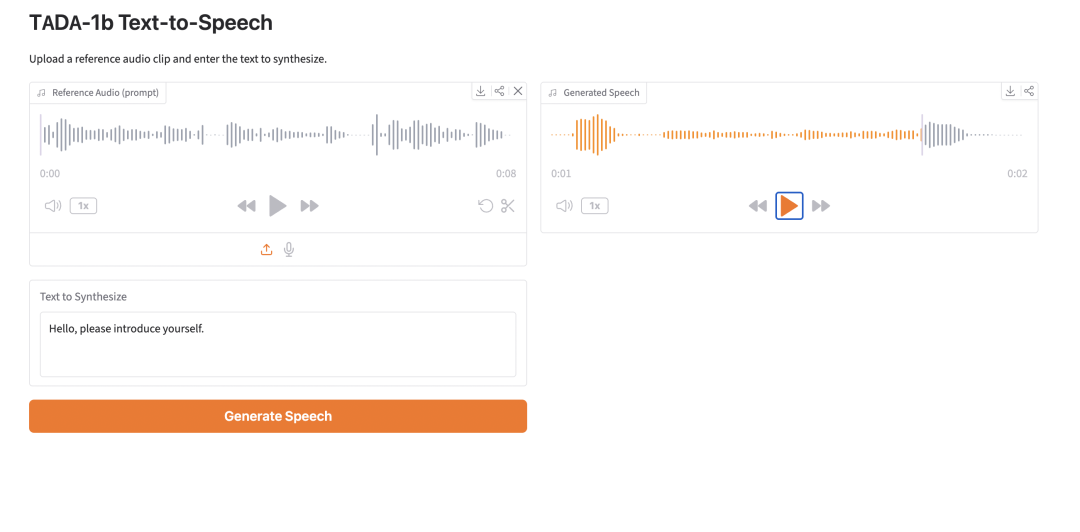
5. TADA-1b: نموذج موحد للكلام واللغة
TADA-1b هو نموذج موحد للكلام واللغة، أصدره فريق HumeAI في فبراير 2026، وهو مصمم خصيصًا لمهام توليد الصوت مثل توليف الكلام، واستنساخ الكلام، والدبلجة متعددة اللغات. يعتمد هذا النموذج على Llama 3.2-1B، ويتميز بقدرات توليد صوت خفيفة الوزن وعالية السرعة ومستقرة، مما يجعله مناسبًا لتحويل النص الإنجليزي إلى كلام (TTS)، واستنساخ الكلام بدون تدريب مسبق، والسرد القصصي الطويل، واستكمال الكلام.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/nCSpT
6. تدريب وتصور Gsplat ثلاثي الأبعاد بتقنية Gaussian Splash
Gsplat مكتبة مفتوحة المصدر لتحويل الصور النقطية ثلاثية الأبعاد إلى صور نقطية، مُسرّعة بتقنية CUDA، طُوّرت بالتعاون بين جامعة بيركلي، وشركة NVIDIA، وجامعة شنغهاي للتكنولوجيا، ومؤسسات أخرى. وقد خضعت المكتبة لتحسينات جذرية استنادًا إلى التنفيذ الأصلي، مما قلّل من استخدام ذاكرة التدريب بمقدار أربعة أضعاف، وخفّض وقت التدريب بمقدار 151 TP3T. وتشمل أبرز ميزاتها التقنية: محرك تحويل الصور النقطية التفاضلي عالي الكفاءة بتقنية CUDA، واستراتيجية تحكم تكيفية في كثافة غاوس، وقاعدة بيانات مرنة متوافقة مع تنسيقات البيانات الشائعة مثل COLMAP، وواجهة عرض مرئي فورية على الويب تعتمد على Viser. وتشمل تطبيقاتها التوائم الرقمية، واستشعار البيئة أثناء القيادة الذاتية، ورقمنة الآثار الثقافية، والتركيب المرئي للتجارة الإلكترونية.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/Zihdr

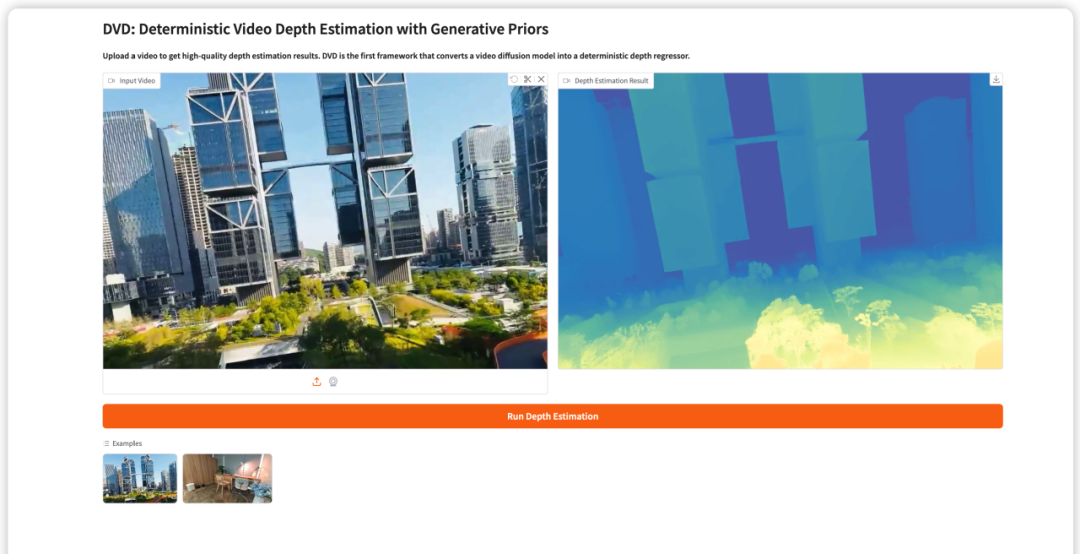
7. قرص DVD: تقدير عمق الفيديو الحتمي بناءً على معلومات مسبقة توليدية
يُعد DVD (تقدير عمق الفيديو الحتمي) أول إطار عمل لتقدير عمق الفيديو الحتمي اقترحه فريق جامعة هونغ كونغ للعلوم والتكنولوجيا (غوانغتشو) في مارس 2026. ومن خلال تحويل نموذج انتشار الفيديو المدرب مسبقًا (Wan2.1) إلى نموذج انحدار عمق الانتشار الأمامي الفردي، فإنه يقضي تمامًا على مشكلة الوهم الهندسي الناجمة عن العشوائية مع الحفاظ على المعرفة الدلالية القوية للنموذج التوليدي.
تشغيل عبر الإنترنت:https://go.hyper.ai/AisLp
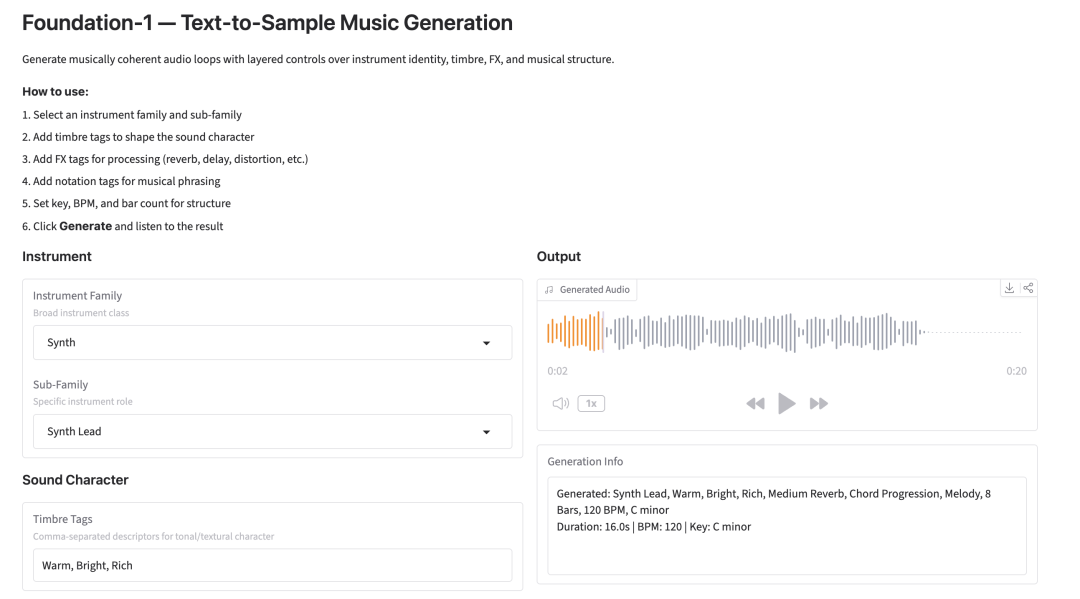
8. الأساس - 1: توليد عينات موسيقية من نص منظم
يُعدّ برنامج Foundation-1، الذي أصدره فريق RoyalCities في مارس 2026، نموذجًا لتوليد الصوت من النصوص إلى العينات، وهو مصمم خصيصًا لسير العمل الاحترافي في إنتاج الموسيقى. يدعم الإصدار الرسمي توليدًا متعدد الطبقات وقابلًا للتحكم، مما يتيح للمستخدمين تخصيص عائلات الآلات الموسيقية، والأنواع الفرعية، والأصوات، والمؤثرات، والأوتار النظرية، وإيقاعات/مفاتيح النوتات الموسيقية، وأطوال المقاييس لتوليد حلقات موسيقية متزامنة إيقاعيًا ومتطابقة نغميًا. علاوة على ذلك، يوفر البرنامج عرضًا توضيحيًا موحدًا عبر الإنترنت يقدم إمكانيات توليد تفاعلية كاملة.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/NxUAC
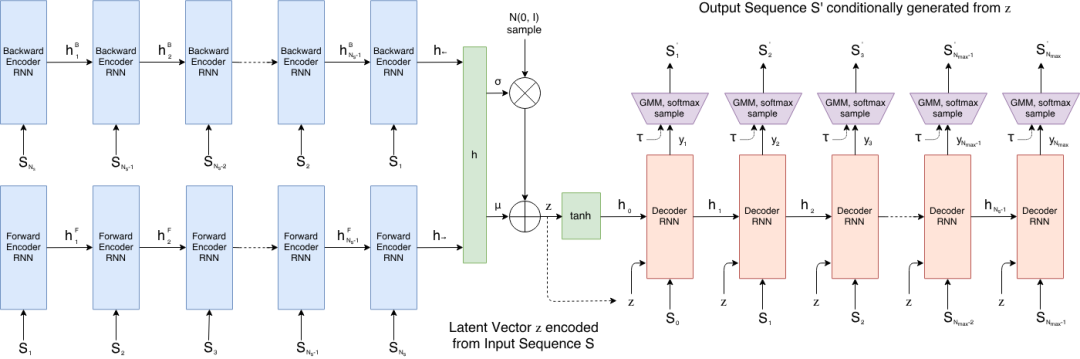
9. Sketch-RNN: توليد الرسومات المتجهة والاستيفاء المكاني الكامن
Sketch-RNN هو نموذج لتوليد تسلسلات الرسومات المتجهة، أطلقه فريق Google Brain عام ٢٠١٧. صُممت هذه الطريقة خصيصًا لبيانات الرسومات اليدوية، والتي تتضمن إزاحات الخطوط ومعلومات حالة القلم. يستطيع النموذج تعلم تمثيلات كامنة متتالية للرسومات، وتوليد تسلسلات جديدة من الرسومات المتجهة. يعتمد Sketch-RNN على بنية مُشفِّر-مُفكِّك، حيث يقوم بربط الرسم المُدخل بمساحة كامنة، ثم يستخدم مُفكِّك شبكة عصبية متكررة لتوليد الخطوط تدريجيًا.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/HmcT9
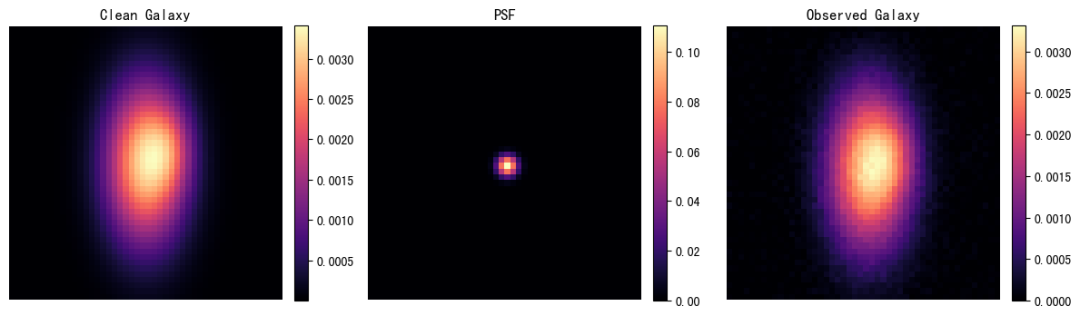
10. Galaxy-Deconv: إطار عمل لإزالة التشويش لصور المجرات ذات العدسات الجاذبية الضعيفة
طُوِّر برنامج Galaxy-Deconv بواسطة تيانياو لي من جامعة تسينغهوا وإيما ألكسندر من جامعة نورث وسترن. يركز المشروع على استعادة صور المجرات ذات العدسات الجاذبية الضعيفة. يستخدم البرنامج خوارزمية ADMM سهلة الاستخدام لإزالة تشويش صور المجرات المتأثرة بضبابية دالة الانتشار النقطي (PSF) والضوضاء. يُنظِّم هذا الدليل التعليمي سير العمل الشائع لإزالة تشويش المجرات في دفتر ملاحظات، ويغطي محاكاة الصور، وتحميل بيانات COSMOS، واستنتاج إزالة التشويش، والتحقق من مجموعة بيانات HDF5، وتمارين أساسية في إزالة التشويش.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/qGvI1
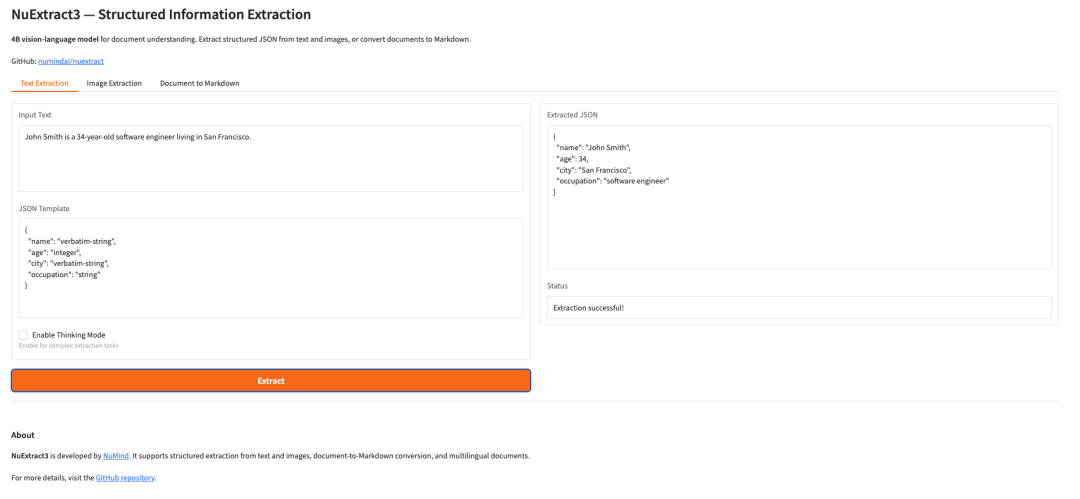
11. NuExtract3: نموذج متعدد الوسائط لفهم المستندات واستخراج المعلومات المنظمة
NuExtract3 هو نموذج لغوي مرئي متعدد الوسائط ذو 4 مليارات مُعامل، أصدرته شركة NuMind في يونيو 2026، وهو مصمم خصيصًا لفهم المستندات. يدمج النموذج إمكانيات استخراج المعلومات المنظمة وتحويل صور المستندات إلى Markdown، ويدعم إدخال النصوص والصور والنصوص والصور المختلطة، ويمكنه إخراج نتائج منظمة مباشرةً بناءً على قوالب JSON التي يقدمها المستخدم، مع الحفاظ الكامل على الجداول والصيغ ومعلومات التنسيق.
تشغيل عبر الإنترنت:https://go.hyper.ai/xirTj
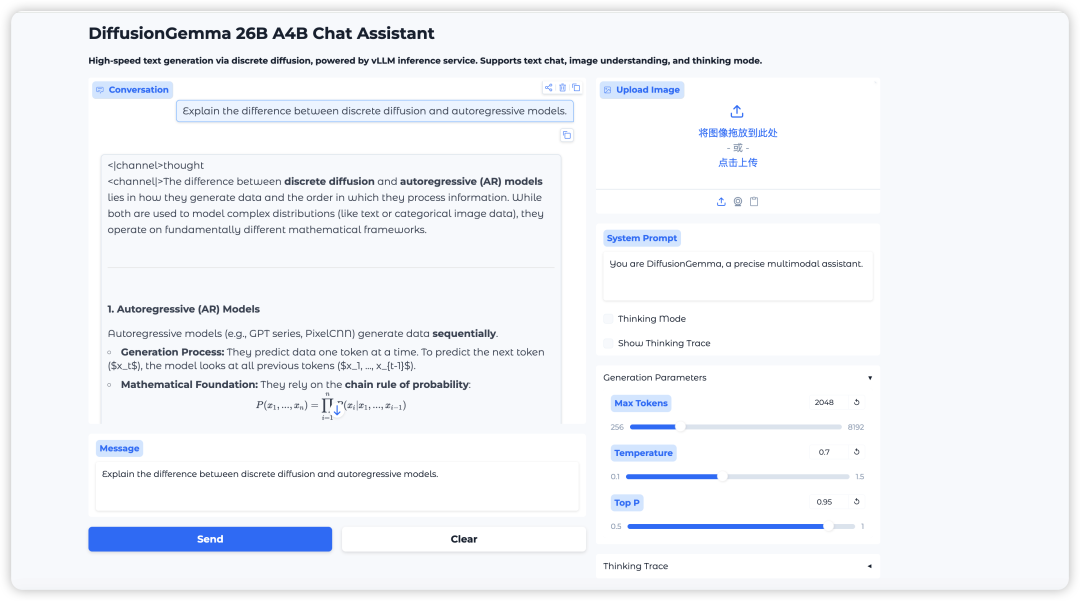
12. DiffusionGemma: نموذج لتوليد النصوص عالي السرعة يعتمد على الانتشار المنفصل
DiffusionGemma هو نموذج لتوليد النصوص طورته جوجل ديب مايند باستخدام تقنيات الانتشار المنفصلة. يعتمد على بنية مزيج الخبراء (MoE) مع 26 مليار مُعامل، بإجمالي 25.2 مليار مُعامل، منها 3.8 مليار مُعامل فقط صالحة. من خلال أخذ عينات الانتشار المتوازي على مستوى الكتل، يحقق سرعات فائقة في توليد النصوص، حيث يُولّد أكثر من 1100 رمز مميز في الثانية على وحدة معالجة رسومية واحدة من نوع H100.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/HV3eM
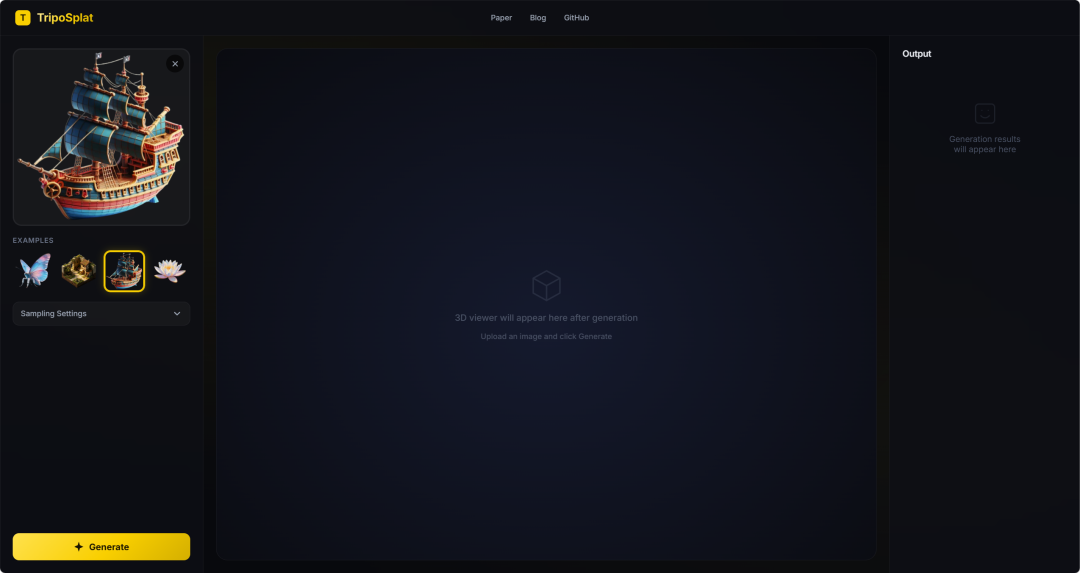
13. TripoSplat: إنشاء أصول غاوسية ثلاثية الأبعاد عالية الجودة من صورة واحدة.
TripoSplat هي طريقة لتوليد نماذج غاوسية ثلاثية الأبعاد من صورة واحدة، تم إصدارها بالاشتراك بين VAST-AI Research وTripoAI في مايو 2026. يستطيع هذا النموذج تحويل صورة ثنائية الأبعاد إلى نموذج غاوسي ثلاثي الأبعاد عالي الجودة، ويتيح التحكم في عدد التوزيعات الغاوسية. يستخدم النموذج تقنية التوزيع الغاوسي المُعتمد على الكثافة (DeG)، حيث يوزع مراكز التوزيع الغاوسي بشكل تكيفي وفقًا للتعقيد الهندسي للكائن، ويستخدم VecSeq لإعادة ترتيب المتغيرات الكامنة غير المنتظمة بشكل حتمي، مما يُحسّن استقرار عملية تدريب النموذج.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/wOxUG
14. نورث ميني كود 1.0: نموذج وكيل لتوليد التعليمات البرمجية ومهام هندسة البرمجيات
يُعدّ North Mini Code 1.0 نموذجًا مفتوح المصدر يعتمد على ترجيح البيانات، وقد أطلقته شركتا Cohere وCohere Labs في يونيو 2026، وهو مُحسَّن لتوليد التعليمات البرمجية، ومهام نقاط النهاية، وسيناريوهات هندسة برمجيات الوكلاء. يدعم هذا النموذج جلسات البرمجة المطولة، وتحليل التعليمات البرمجية، واستخدام الأدوات، والتفكير المتداخل، ويتفوق في تنفيذ الميزات، وكتابة البرامج النصية، وتصحيح الأخطاء، وتخطيط مهام نقاط النهاية، وسير عمل هندسة البرمجيات متعدد المراحل.
قم بتشغيلها عبر الإنترنت: https://go.hyper.ai/ycCuG

💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~
تفسير مقالة المجتمع
1. أصدرت MIT/IBM مجموعة بيانات ChartNet، وهي أكبر مجموعة بيانات للرسوم البيانية الاصطناعية حتى الآن، حيث أنتجت 1.5 مليون عينة متنوعة من الرسوم البيانية.
اقترحت مجموعة من الخبراء من معهد ماساتشوستس للتكنولوجيا ومختبر أبحاث الحوسبة التابع لمعهد ماساتشوستس للتكنولوجيا وشركة آي بي إم للأبحاث ChartNet - وهي مجموعة بيانات متعددة الوسائط عالية الجودة تضم ملايين السجلات لفهم الرسوم البيانية، مصممة لتعزيز فهم الرسوم البيانية وقدرات الاستدلال.
شاهد التقرير الكامل:https://go.hyper.ai/Kk87Q
2. تكشف أحدث ورقة بحثية لشركة جوجل ديب مايند عن الهدف النهائي للذكاء الاصطناعي: من الذكاء الاصطناعي العام إلى الذكاء الاصطناعي الفائق، هناك 4 مسارات و 6 عقبات.
نشرت جوجل ديب مايند، بالتعاون مع عدد من الجامعات المرموقة، ورقة بحثية جديدة تستكشف الأسئلة الجوهرية المحيطة بتطور الذكاء الاصطناعي العام (AGI) إلى الذكاء الاصطناعي الفائق (ASI). ينظر هذا البحث إلى الذكاء كعملية متصلة، ويحلل بدقة المسارات المحتملة والتحديات التي سيواجهها الذكاء الاصطناعي مع استمراره في التطور بعد تجاوزه مستوى الذكاء البشري المتوسط. تقدم الورقة مرجعًا منظمًا وموضوعيًا لفهم المسار طويل الأمد لتطور الذكاء الاصطناعي.
شاهد التقرير الكامل:https://go.hyper.ai/AOObx
3. بفضل الاستفادة من القدرات السياقية الطويلة لـ Gemini 1.5، حقق نظام الرعاية الصحية التفاعلي AMIE من جوجل مستوى التفكير الذي يتمتع به الطبيب العام في 100 سيناريو تتضمن زيارات متعددة للمرضى.
طوّرت دراسة حديثة أجرتها جوجل ديب مايند وجوجل ريسيرش نظامًا جديدًا للوكلاء الأذكياء قائمًا على نموذج التعلم الممتد (LLM)، مستندًا إلى نظام الرعاية الصحية التفاعلي AMIE. يُمكّن هذا النظام من الإدارة السريرية ويُحسّن الحوار بين الطبيب والمريض في سيناريوهات متابعة متعددة. يستفيد AMIE من القدرات السياقية طويلة المدى لنموذج جيميني، جامعًا بين استرجاع السياق والاستدلال المنظم لضمان توافق مخرجاته مع أحدث إرشادات الممارسة السريرية وقوائم الأدوية الموصوفة.
شاهد التقرير الكامل:https://go.hyper.ai/65aHo
4. الذكاء الاصطناعي للمواد يتجه نحو "عصر قابل للتفسير": فريق ياباني يفك لغز التحليل الطيفي عالي الأبعاد، ويحدد السمات الرئيسية لاكتشاف مواد جديدة.
اقترح فريق بحثي من معهد طوكيو للعلوم في اليابان طريقةً لتفسير نماذج التعلم العميق قادرة على معالجة البيانات الطيفية عالية الأبعاد في علم المواد. وقد أنشأ الباحثون مجموعة بيانات حسابية من المبادئ الأولى تحتوي على أطياف الامتصاص الضوئي لـ 2681 من الأكاسيد والكالكوجينيدات والمركبات ذات الصلة. وبالمقارنة مع حسابات نظرية الكثافة الوظيفية القياسية، وبعد تصحيح طاقة بداية الطيف وشكله، أظهرت النتائج المحسوبة توافقًا أفضل بكثير مع الأطياف التجريبية المنشورة.
شاهد التقرير الكامل:https://go.hyper.ai/VJbaU
مقالات موسوعية شعبية
1. نموذج اللغة الكبير (LLM)
2. الهيكل
3. نموذج العمل العالمي (WAM)
4. ترميز الموضع الدوراني (RoPE)
5. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* يوفر نقاط تنزيل محلية معجلة لأكثر من 2100 مجموعة بيانات عامة
* يتضمن أكثر من 700 درس تعليمي كلاسيكي وشائع عبر الإنترنت
* تحليل أكثر من 300 دراسة حالة من أوراق بحثية حول الذكاء الاصطناعي للعلوم
* يدعم البحث عن أكثر من 700 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








