Command Palette
Search for a command to run...
تم تخفيض استخدام الذاكرة بما يصل إلى 751 تيرابايت: اقترح علماء في وزارة الطاقة الأمريكية طريقة تجميع هرمية عبر القنوات، D-CHAG، لتمكين تشغيل مجموعات بيانات متعددة القنوات نموذجية واسعة النطاق للغاية.

تتمتع النماذج العلمية الأساسية القائمة على الرؤية بإمكانات هائلة لدفع عجلة الاكتشاف العلمي والابتكار، ويعود ذلك أساسًا إلى قدرتها على تجميع بيانات الصور من مصادر متنوعة (مثل سيناريوهات الملاحظة الفيزيائية المختلفة) وتعلم الارتباطات المكانية والزمانية باستخدام بنية Transformer. مع ذلك، فإن تجزئة الصور وتجميعها عملية مكلفة حسابيًا، ولم تتمكن الطرق الموزعة الحالية، مثل التوازي الموتري (TP) والتوازي التسلسلي (SP) والتوازي البياناتي (DP)، من معالجة هذا التحدي بشكل كافٍ حتى الآن.
وفي هذا السياق،اقترح باحثون من مختبر أوك ريدج الوطني التابع لوزارة الطاقة الأمريكية طريقة التجميع الهرمي الموزع عبر القنوات (D-CHAG) للنماذج الأساسية.توزع هذه الطريقة عملية التجزئة وتستخدم استراتيجية هرمية لتجميع القنوات، مما يُمكّن من تشغيل نماذج واسعة النطاق للغاية على مجموعات بيانات متعددة القنوات. قيّم الباحثون D-CHAG على مهام التصوير الطيفي الفائق والتنبؤ بالطقس، ووجدوا أن دمج هذه الطريقة مع التوازي الموتري وتجزئة النموذج قلل من استهلاك الذاكرة بما يصل إلى 751 TP3T على حاسوب Frontier العملاق، وحقق تحسينات مستدامة في الإنتاجية بأكثر من الضعف على ما يصل إلى 1024 وحدة معالجة رسومية من AMD.
تم نشر نتائج البحث ذات الصلة، بعنوان "التجميع الهرمي الموزع عبر القنوات لنماذج الأساس"، في SC25.
أبرز الأبحاث:
* يعمل D-CHAG على حل مشكلات عنق الزجاجة في الذاكرة وكفاءة الحساب في تدريب النموذج الأساسي متعدد القنوات.
* بالمقارنة مع استخدام TP وحده، يمكن لـ D-CHAG تحقيق تقليل في حجم الذاكرة يصل إلى 70%، مما يدعم تدريب النماذج واسعة النطاق بشكل أكثر كفاءة.
* تم التحقق من أداء D-CHAG على اثنين من أحمال العمل العلمية: التنبؤ بالطقس والتنبؤ بإخفاء صور النباتات فائقة الطيف.
عنوان الورقة:
https://dl.acm.org/doi/10.1145/3712285.3759870
تابع حسابنا الرسمي على WeChat وأجب بكلمة "cross-channel" في الخلفية للحصول على ملف PDF كامل.
باستخدام مجموعتين نموذجيتين من البيانات متعددة القنوات
استخدمت هذه الدراسة مجموعتين نموذجيتين من البيانات متعددة القنوات للتحقق من فعالية طريقة D-CHAG:صور طيفية فائقة للنباتات ومجموعة بيانات الأرصاد الجوية ERA5.
تم جمع بيانات الصور الطيفية الفائقة للنباتات المستخدمة في التنبؤ الذاتي بالقناع بواسطة مختبر النمط الظاهري النباتي المتقدم (APPL) التابع لمختبر أوك ريدج الوطني (ORNL).تحتوي مجموعة البيانات على 494 صورة طيفية فائقة لأشجار الحور، تحتوي كل منها على 500 قناة طيفية تغطي أطوال موجية من 400 نانومتر إلى 900 نانومتر.
تُستخدم هذه المجموعة من البيانات بشكل أساسي في أبحاث الكتلة الحيوية، وهي مصدر هام لتصنيف النمط الظاهري للنباتات وأبحاث الطاقة الحيوية. تُستخدم هذه الصور في التدريب الذاتي المقنّع، حيث تُستخدم شرائح الصور كرموز للتقنيع. تتمثل مهمة النموذج في التنبؤ بالمحتوى المفقود، وبالتالي تعلم التوزيع الأساسي للبيانات في الصور. والجدير بالذكر أن هذه المجموعة من البيانات لا تستخدم أي أوزان مُدرّبة مسبقًا، ويتم تدريبها بالكامل على التعلم الذاتي، مما يُبرز قابلية تطبيق D-CHAG في مهام التعلم الذاتي عالية القنوات.
أيضًا،في تجربة التنبؤ بالطقس، استخدم فريق البحث مجموعة بيانات إعادة التحليل عالية الدقة ERA5.اختارت الدراسة خمسة متغيرات جوية (الارتفاع الجيوبوتنشالي، ودرجة الحرارة، ومركبة سرعة الرياح u، ومركبة سرعة الرياح v، والرطوبة النوعية) وثلاثة متغيرات سطحية (درجة الحرارة على ارتفاع مترين، ومركبة سرعة الرياح u على ارتفاع 10 أمتار، ومركبة سرعة الرياح v على ارتفاع 10 أمتار)، تغطي أكثر من 10 طبقات ضغط، مما أدى إلى توليد 80 قناة إدخال. ولتكييف البيانات مع تدريب النموذج، أُعيدت معالجة البيانات الأصلية بدقة 0.25 درجة (770 × 1440) إلى دقة 5.625 درجة (32 × 64) باستخدام مجموعة أدوات xESMF وخوارزمية الاستيفاء الثنائي الخطي.
تتمثل مهمة النموذج في التنبؤ بالمتغيرات المناخية للخطوات الزمنية المستقبلية، مثل ارتفاع الجيوبوتنشال 500 هكتوباسكال (Z500)، ودرجة الحرارة 850 هكتوباسكال (T850)، وسرعة الرياح المركبة 10 م u (U10)، وبالتالي التحقق من أداء طريقة D-CHAG في مهام التنبؤ بالسلاسل الزمنية.
D-CHAG: الجمع بين التجميع الهرمي والتجزئة الموزعة
باختصار، طريقة D-CHAG هي دمج لطريقتين مستقلتين:
طريقة التجزئة الموزعة
أثناء عملية الانتشار الأمامي، يقوم كل رتبة TP بتقسيم مجموعة فرعية فقط من قنوات الإدخال.قبل تنفيذ خطوة تجميع القنوات، يجب تنفيذ عملية AllGather لتحقيق الانتباه المتبادل عبر جميع القنوات. نظريًا، يمكن لهذه الطريقة تقليل عبء حساب التجزئة لكل وحدة معالجة رسومية.
التجميع الهرمي عبر القنوات
تتمثل الميزة الرئيسية لهذا النهج في تقليل حجم الذاكرة لكل طبقة انتباه عبر القنوات، لأنه يتم معالجة عدد أقل من القنوات لكل طبقة.مع ذلك، يؤدي زيادة عدد الطبقات إلى زيادة حجم النموذج الإجمالي وزيادة استهلاك الذاكرة. وتكون هذه المفاضلة أكثر ملاءمة لمجموعات البيانات ذات القنوات الكثيرة، لأن آلية الانتباه القياسية بين القنوات تتطلب استهلاكًا أكبر للذاكرة الثانوية.
على الرغم من مزايا كلتا الطريقتين، إلا أنهما تنطويان على بعض العيوب. فعلى سبيل المثال، تتسبب طريقة التجزئة الموزعة في زيادة كبيرة في تكلفة الاتصال بين رتب TP، ولا تحل مشكلة استهلاك الذاكرة الكبير على مستوى القناة؛ بينما تزيد طريقة التجميع الهرمي عبر القنوات من عدد معلمات النموذج لكل وحدة معالجة رسومية. تجمع طريقة D-CHAG بين الطريقتين بطريقة موزعة، ويظهر الهيكل العام في الشكل أدناه.
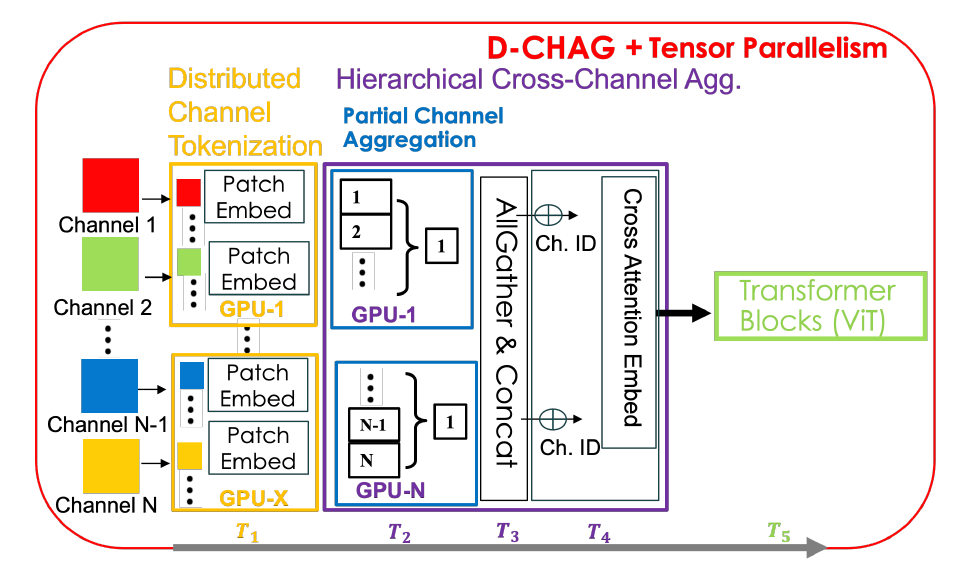
خاصة،تقوم كل رتبة من رتب TP بتقسيم الصور ثنائية الأبعاد إلى رموز في مجموعة القنوات الفرعية الكاملة.بما أن كل وحدة معالجة رسومية (GPU) لا تحتوي إلا على مجموعة فرعية من جميع القنوات، يتم تجميع القنوات محليًا على هذه القنوات - وتُسمى هذه الوحدة بوحدة تجميع القنوات الجزئية. بعد اكتمال تجميع القنوات ضمن كل رتبة TP، تُجمع المخرجات ويُجرى التجميع النهائي باستخدام آلية الانتباه بين القنوات. تُنفذ عملية AllGather واحدة فقط أثناء الانتشار الأمامي؛ أما أثناء الانتشار العكسي، فتُجمع التدرجات ذات الصلة فقط لكل وحدة معالجة رسومية، مما يجنب الحاجة إلى اتصالات إضافية.
يمكن لطريقة D-CHAG الاستفادة الكاملة من مزايا التجزئة الموزعة وتجميع القنوات الهرمي مع التخفيف من أوجه القصور فيها.من خلال توزيع تجميع القنوات الهرمي عبر رتب TP، قلّل الباحثون من اتصال AllGather إلى معالجة قناة واحدة فقط لكل رتبة TP، مما ألغى الحاجة إلى أي اتصال أثناء الانتشار العكسي. علاوة على ذلك، من خلال زيادة عمق النموذج، حافظوا على ميزة تقليل معالجة القنوات لكل طبقة، مع توزيع معلمات النموذج الإضافية عبر رتب TP من خلال وحدات تجميع القنوات الجزئية.
قارنت الدراسة بين استراتيجيتين للتنفيذ:
* D-CHAG-L (الطبقة الخطية): تستخدم وحدة التجميع الهرمي طبقة خطية، والتي تتميز بانخفاض استخدام الذاكرة وهي مناسبة للحالات التي تحتوي على عدد كبير من القنوات.
* D-CHAG-C (طبقة الانتباه المتبادل): تستخدم طبقة الانتباه المتبادل، والتي لها تكلفة حسابية أعلى، ولكنها تحسن الأداء بشكل كبير للنماذج الكبيرة جدًا أو عدد القنوات العالي للغاية.
النتائج: يدعم D-CHAG تدريب نماذج أكبر على مجموعات بيانات عالية القنوات.
بعد بناء نموذج D-CHAG، قام الباحثون بالتحقق من أداء النموذج ثم قاموا بتقييم أدائه بشكل أكبر في مهام التصوير الطيفي الفائق والتنبؤ بالطقس:
تحليل أداء النموذج
يوضح الشكل التالي أداء D-CHAG في ظل تكوينات مختلفة لوحدة تجميع القنوات الجزئية:
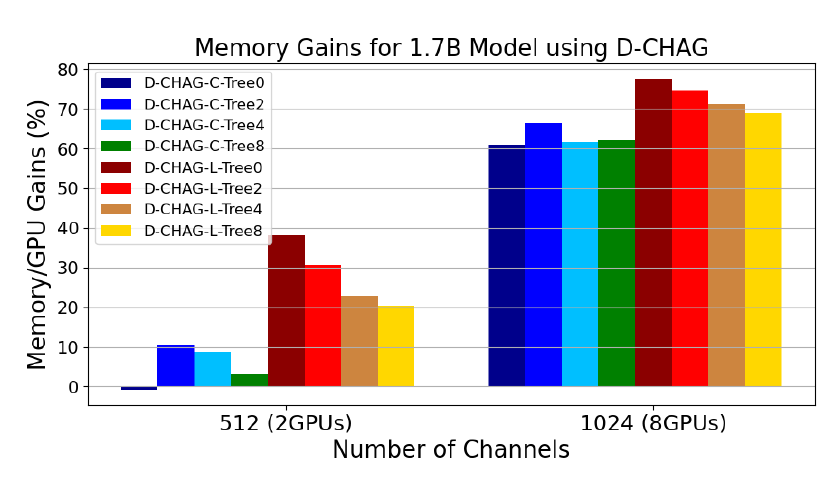
* يشير Tree0 إلى وجود مستوى واحد فقط من التجميع في بعض وحدات التجميع، ويشير Tree2 إلى مستويين، وهكذا؛
* تشير اللاحقتان -C و -L إلى نوع الطبقات المستخدمة: -C تشير إلى أن جميع الطبقات هي طبقات انتباه متقاطع، و -L تشير إلى أن جميع الطبقات خطية.
وتظهر النتائج:
بالنسبة لبيانات 512 قناة، يكون أداء استخدام طبقة الانتباه المتقاطع أحادية الطبقة أقل قليلاً من خط الأساس، ولكنه يمكن أن يحسن الأداء بحوالي 60% لبيانات 1024 قناة.
مع تعمق الهيكل الهرمي، يمكن حتى لبيانات 512 قناة تحقيق تحسينات كبيرة في الأداء، بينما يظل أداء بيانات 1024 قناة مستقرًا نسبيًا.
يمكن أن يؤدي استخدام الطبقات الخطية، حتى مع تسلسل هرمي بسيط، إلى تحسين الأداء في الصور ذات 512 و1024 قناة. في الواقع، يُلاحظ أفضل أداء في D-CHAG-L-Tree0، الذي يحتوي على طبقة تجميع قنوات واحدة فقط. تؤدي إضافة طبقات التجميع إلى زيادة معلمات النموذج وزيادة استهلاك الذاكرة. في حين أن زيادة عدد الطبقات تبدو مفيدة في حالة 512 قناة، إلا أنه بالنسبة لكلا حجمي القنوات، فإن استخدام طبقة خطية واحدة فقط يتفوق على التكوينات الأعمق.
يؤثر D-CHAG-C-Tree0 بشكل سلبي طفيف على الأداء مع وحدتي معالجة رسومية، ولكنه يمكن أن يحقق تحسنًا في الأداء بمقدار 60% عند توسيعه إلى ثماني وحدات معالجة رسومية.
التنبؤ الذاتي بالقناع للصور الطيفية الفائقة للنباتات
يقارن الشكل أدناه خسارة التدريب للطريقة الأساسية وطريقة D-CHAG في تطبيق مشفرات القناع التلقائي لصور النباتات فائقة الطيف. تُظهر النتائج ما يلي:أثناء التدريب، يكون أداء خسارة التدريب لتنفيذ وحدة معالجة الرسومات الواحدة متسقًا للغاية مع أداء طريقة D-CHAG (التي تعمل على وحدتي معالجة رسومات).
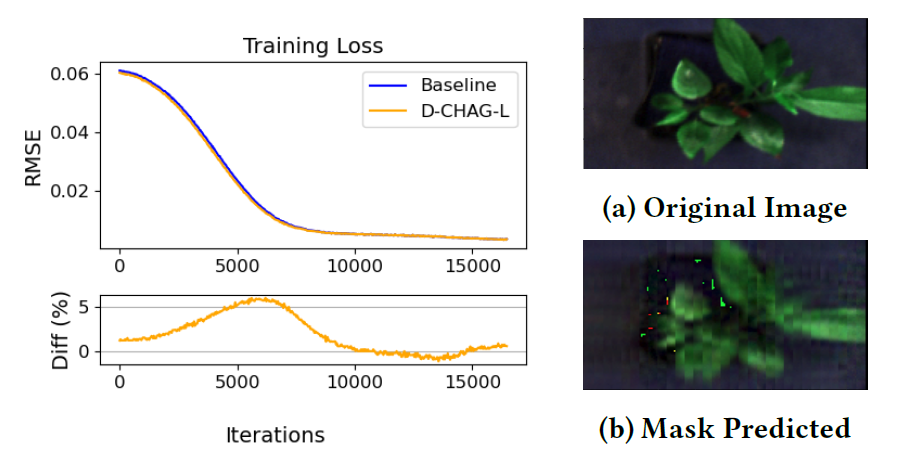
قال لاري يورك، وهو باحث كبير في مجموعة التصوير الجزيئي والخلوي في مختبر أوك ريدج الوطني، إن تقنية D-CHAG يمكن أن تساعد علماء النبات على إكمال المهام بسرعة مثل قياس النشاط الضوئي للنبات مباشرة من الصور، مما يحل محل القياسات اليدوية التي تستغرق وقتًا طويلاً وشاقة.
توقعات الطقس
أجرى الباحثون تجربةً للتنبؤ بالطقس لمدة 30 يومًا باستخدام مجموعة بيانات ERA5. يقارن الشكل أدناه خسارة التدريب وجذر متوسط مربع الخطأ (RMSE) لمتغيرات الاختبار الثلاثة للطريقة الأساسية وطريقة D-CHAG في تطبيقات التنبؤ بالطقس.
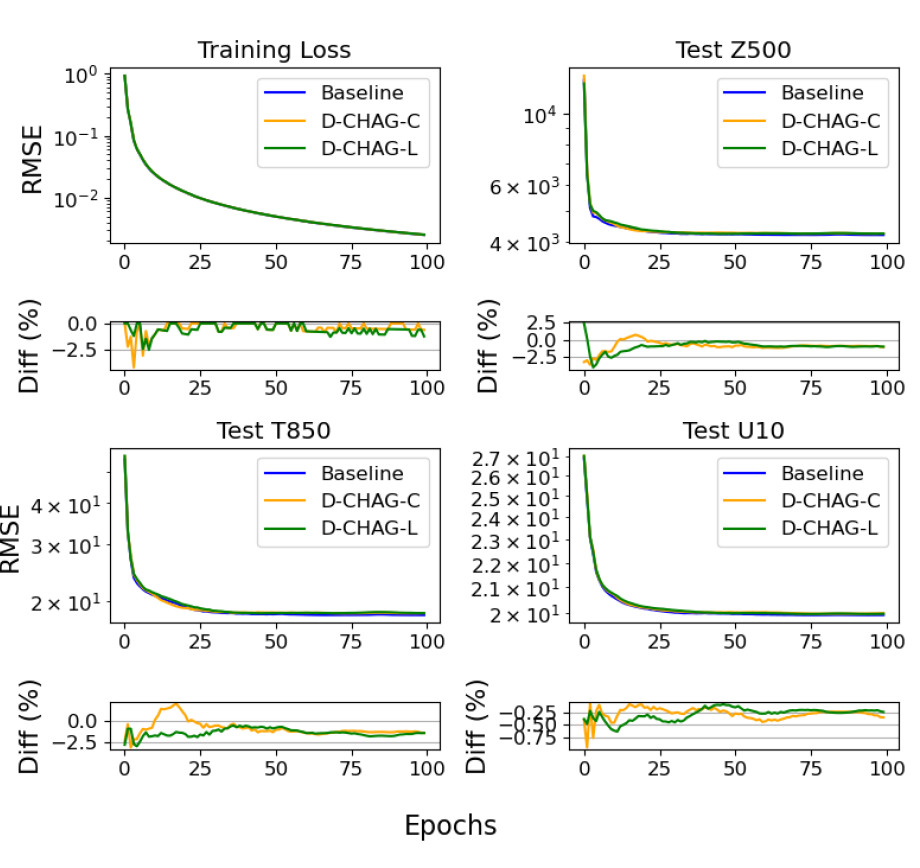
يوضح الجدول أدناه المقارنة النهائية للنموذج في مهام التنبؤ لمدة 7 و 14 و 30 يومًا، بما في ذلك RMSE و MSE ومعامل ارتباط بيرسون (wACC).
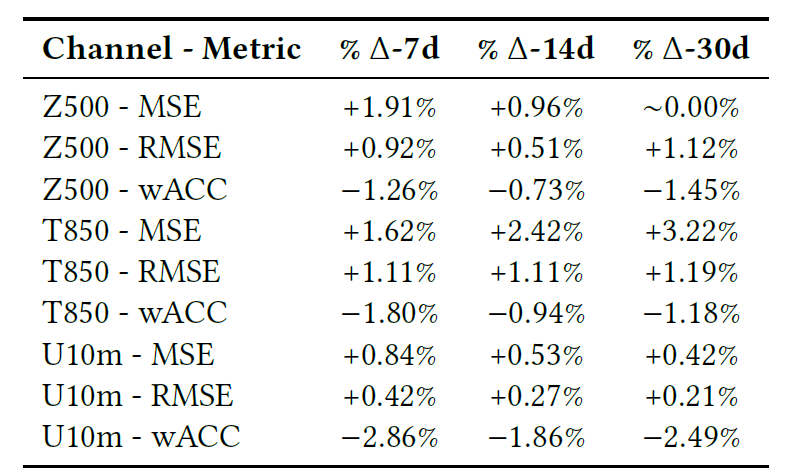
بشكل عام، واستنادًا إلى الرسوم البيانية والجداول، فإن خسارة التدريب متسقة للغاية مع النموذج الأساسي، والانحرافات في المؤشرات المختلفة ضئيلة.
تحسين الأداء مع حجم النموذج
يوضح الشكل أدناه تحسن أداء طريقة D-CHAG مقارنةً باستخدام TP فقط لثلاثة أحجام نماذج مع تكوينات قنوات تتطلب TP:
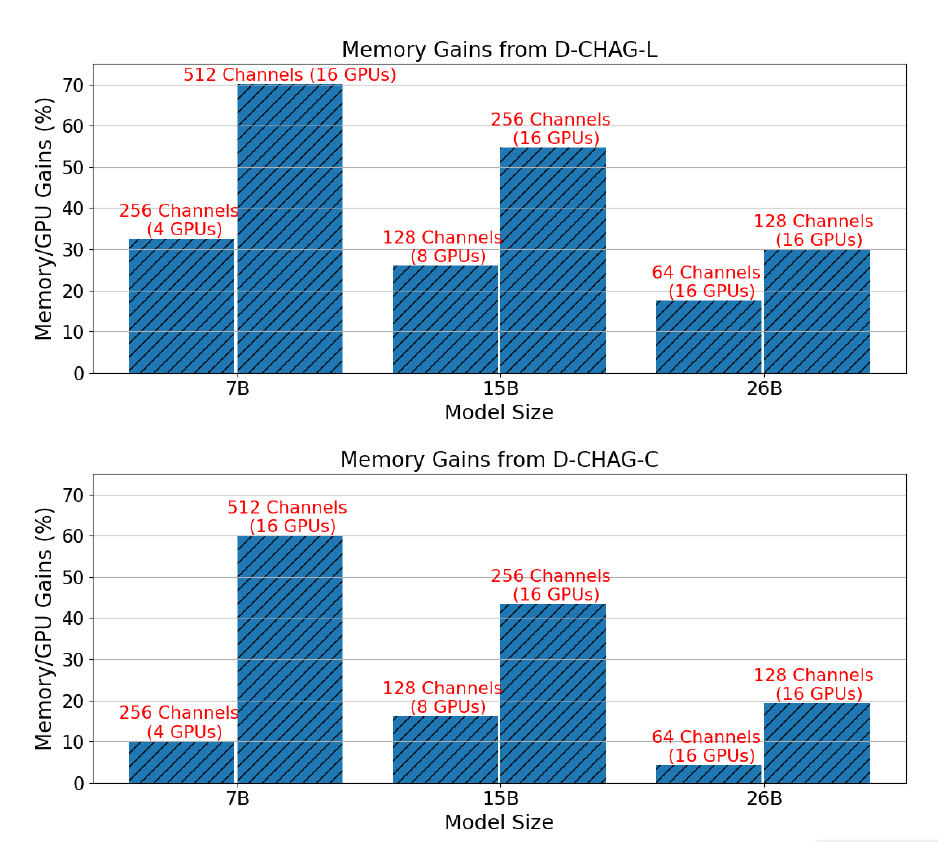
وتظهر النتائج أنبالنسبة لنموذج المعلمات 7B،يمكن أن يؤدي استخدام الطبقات الخطية في وحدة تجميع القنوات الجزئية إلى تحسين الأداء من 30% إلى 70%، بينما يمكن أن يؤدي استخدام طبقات الانتباه المتبادل إلى تحسين الأداء من 10% إلى 60%.بالنسبة لنموذج المعلمات 15B،تجاوزت تحسينات الأداء 20% إلى 50%؛يتراوح تحسن أداء نموذج المعلمات 26B بين 10% و 30%.
علاوة على ذلك، مع ثبات حجم النموذج، يصبح تحسين الأداء أكثر وضوحًا مع زيادة عدد القنوات. ويعود ذلك إلى أنه في ظل بنية معينة، لا تؤدي زيادة عدد القنوات إلى زيادة التكلفة الحسابية لوحدة التحويل، ولكنها تزيد من عبء العمل على وحدات التجزئة وتجميع القنوات.
من ناحية أخرى، لا يمكن لـ TP وحده تدريب الصور التي تحتوي على 26 معلمة و256 قناة، ولكن يمكن لطريقة D-CHAG تدريب نموذج يحتوي على 26 معلمة و512 قناة باستخدام أقل من 80% من الذاكرة المتاحة - وهذا يدل على أن الطريقة يمكنها دعم تدريب نماذج أكبر على مجموعات بيانات عالية القنوات.
ViT: الذكاء الاصطناعي البصري - من النماذج الإدراكية إلى نماذج الأساس البصري العامة
على مدى العقد الماضي، تمحورت نماذج رؤية الحاسوب بشكل أساسي حول "تحسين المهمة الواحدة"، حيث تطورت عمليات التصنيف والكشف والتجزئة وإعادة البناء بشكل مستقل. ومع ذلك، فمع ظهور نماذج أساسية مثل GPT وBERT في مجال معالجة اللغة الطبيعية بفضل بنية Transformer، يشهد مجال الرؤية تحولًا نموذجيًا مماثلًا: من نماذج خاصة بمهام محددة إلى نماذج أساسية عامة للرؤية. وفي هذا السياق، يُعتبر Vision Transformer (ViT) حجر الزاوية التكنولوجي لنماذج الرؤية الأساسية.
كان برنامج Vision Transformer (ViT) أول من أدخل بنية Transformer بشكل كامل في مهام رؤية الحاسوب. وتتمثل فكرته الأساسية في التعامل مع الصورة كسلسلة من رموز الرقع، واستبدال نمذجة مجال الاستقبال المحلي للشبكات العصبية الالتفافية بآلية الانتباه الذاتي. وبشكلٍ أدق، يقسم ViT الصورة المدخلة إلى رقع ذات حجم ثابت، ويربط كل رقعة برمز تضمين، ثم ينمذج العلاقات الشاملة بين الرقع من خلال مُشفِّر Transformer.
بالمقارنة مع الشبكات العصبية التلافيفية التقليدية، تتمتع ViT بمزايا خاصة للبيانات العلمية: فهي مناسبة للبيانات متعددة القنوات عالية الأبعاد (مثل الاستشعار عن بعد والصور الطبية والبيانات الطيفية)، ويمكنها التعامل مع الهياكل المكانية غير الإقليدية (مثل شبكات المناخ والحقول الفيزيائية)، وهي مناسبة للنمذجة عبر القنوات (علاقات الاقتران بين المتغيرات الفيزيائية المختلفة)، وهي أيضًا القضية الأساسية التي تناولتها ورقة D-CHAG.
إلى جانب السيناريوهات المذكورة في البحث أعلاه، تُبرهن تقنية ViT على قيمتها الأساسية في سيناريوهات أخرى. ففي مارس 2025، طوّر الدكتور هان غانغوين، كبير أطباء قسم الأمراض الجلدية في مستشفى جامعة بكين الدولية، وفريقه خوارزمية تعلّم عميق تُسمى AcneDGNet. تدمج هذه الخوارزمية مُحوّل الصور المرئية والشبكات العصبية الالتفافية للحصول على جدول ميزات هرمي أكثر كفاءة، مما يُؤدي إلى تصنيف أكثر دقة. تُظهر التقييمات المستقبلية أن خوارزمية التعلّم العميق لـ AcneDGNet ليست أكثر دقة من خوارزميات أطباء الجلد المبتدئين فحسب، بل تُضاهي أيضًا خوارزميات أطباء الجلد ذوي الخبرة. فهي قادرة على الكشف بدقة عن آفات حب الشباب وتحديد شدتها في مختلف سيناريوهات الرعاية الصحية، مما يُساعد أطباء الجلد والمرضى بشكل فعّال على تشخيص حب الشباب وإدارته في كلٍ من الاستشارات عبر الإنترنت والزيارات الطبية التقليدية.
عنوان الورقة:
تقييم نموذج للكشف عن آفات حب الشباب وتصنيف شدتها لدى السكان الصينيين في سيناريوهات الرعاية الصحية عبر الإنترنت وغير المتصلة بالإنترنت
عنوان الورقة:
https://www.nature.com/articles/s41598-024-84670-z
من منظور صناعي، يُمثل Vision Transformer نقطة تحول حاسمة في تطور الذكاء الاصطناعي البصري، من النماذج الإدراكية إلى النماذج البصرية الأساسية متعددة الأغراض. توفر بنيته الموحدة، Transformer، أساسًا عالميًا للدمج متعدد الوسائط، والتوسع القابل للتطوير، وتحسين النظام، مما يجعل النماذج البصرية بنية أساسية للذكاء الاصطناعي في العلوم. في المستقبل، ستصبح إمكانيات التوازي، وتحسين الذاكرة، ونمذجة القنوات المتعددة التي يتميز بها ViT عوامل تنافسية رئيسية تحدد سرعة ونطاق النشر الصناعي للنماذج البصرية الأساسية.
مراجع:
1.https://phys.org/news/2026-01-empowering-ai-foundation.html
2.https://dl.acm.org/doi/10.1145/3712285.3759870
3.https://mp.weixin.qq.com/s/JvKQPbBQFhofqlVX4jLgSA








