Command Palette
Search for a command to run...
انتقد أعضاء الفريق المؤسس لـ CUDA بشدة cuTile لاستهدافها "على وجه التحديد" Triton؛ هل يمكن لنموذج Tile إعادة تشكيل المشهد التنافسي لنظام برمجة GPU؟

في ديسمبر 2025، وبعد مرور ما يقرب من عشرين عامًا على إصدار CUDA، أطلقت NVIDIA أحدث إصدار، وهو CUDA 13.1. ويكمن التغيير الأساسي في نموذج برمجة CUDA Tile (cuTile) الجديد.تمت إعادة تنظيم بنية نواة وحدة معالجة الرسومات من خلال نموذج برمجة "قائم على البلاطات"، مما يسمح للمطورين بكتابة نوى عالية الأداء دون التلاعب المباشر بلغة CUDA C++ الأساسية.هذا بلا شك إنجاز جدير بالذكر بالنسبة لنظام برمجة وحدة معالجة الرسومات: قد يكون مستوى جديدًا من المنتجات أطلقته NVIDIA لتلبية الطلب المتزايد على المشغلين المخصصين في عصر الذكاء الاصطناعي وزيادة تعزيز تماسك النظام البيئي للبرمجيات.
بعد ظهورها للعلن، أثارت cuTile نقاشًا واسعًا في أوساط المطورين حول دورة تطوير العمليات المخصصة، والمنافسة المباشرة مع Triton، وإمكانية أن تصبح نقطة البداية الافتراضية لتعلم بايثون. ورغم أن cuTile لا تزال في مراحلها الأولى، إلا أن آراء المطورين الحالية تشير إلى أنها تمتلك بالفعل إمكانات هائلة لتصبح نموذجًا جديدًا في البرمجة.
مع تشكّل النظام البيئي ذي الصلة تدريجيًا، تتضح مكانة cuTile وإمكانياتها. على منصة GitHub، وفي المنتديات، وضمن المشاريع الداخلية، أكّد العديد من المهندسين على تحسينات cuTile في تنظيم الكود وسهولة قراءته، بينما حاول بعض مستخدمي المجتمع نقل أكواد CUDA الحالية إلى cuTile. بدعمها لنظام Python البيئي، هل ستصبح cuTile نقطة الدخول الرئيسية لبرمجة وحدات معالجة الرسومات، أم أنها ستخلق تقسيمًا تقنيًا جديدًا للعمل بين CUDA وTriton؟ مع ظهور المزيد من تطبيقات العمل الواقعية، قد تتضح هذه الإجابات تدريجيًا في السنوات القادمة.
كيوتايل: بداية حقبة جديدة من برمجة وحدات معالجة الرسومات "التي تركز على الكود"
لطالما وفرت CUDA للمطورين نموذجًا للأجهزة والبرمجة لتعدد الخيوط أحادي التعليمات (SIMT)، مما يسمح لهم بوصف منطق الحوسبة المتوازية لوحدة معالجة الرسومات (GPU) على مستوى "الخيوط": يتم تقسيم النواة إلى آلاف الخيوط، حيث يقوم كل خيط بتنفيذ جزء صغير من الحساب، وتشكل مجموعات الخيوط كتلًا، ثم يقوم الجهاز بربطها بالمعالج المتعدد المتدفق (SM) للتنفيذ.
ومع ذلك، ومع النمو الهائل في متطلبات الحوسبة، وخاصة نطاق تدريب الذكاء الاصطناعي، على مدى السنوات الثلاث إلى الخمس الماضية، واجهت هذه البرمجة التي تركز على الخيوط المزيد والمزيد من الاختناقات.لا يقتصر الأمر على حاجة الباحثين والمهندسين إلى فهم جدولة الخيوط، بل يتطلب منهم أيضًا دراسة متعمقة لدمج الذاكرة، وتباعد الالتفافات، وحتى تنسيق تنفيذ نوى Tensor. بعبارة أخرى، يتطلب كتابة نواة CUDA عالية الأداء فهمًا شاملاً لجميع جوانب بنية بطاقة الرسومات؛ وإلا، فسيكون من الصعب الاستفادة الكاملة من إمكانيات الجهاز.
يُعد ظهور cuTile استجابة NVIDIA لهذا الاتجاه - مما يسمح للمطورين بالعودة إلى الخوارزميات، مع ترك تحسين أداء الأجهزة للإطار.
خاصة،cuTile هو نموذج برمجة متوازية لوحدات معالجة الرسومات من NVIDIA، وهو أيضًا لغة برمجة خاصة بالمجال (DSL) مبنية على لغة بايثون. يمكنه الاستفادة تلقائيًا من إمكانيات الأجهزة المتقدمة.على سبيل المثال، نوى Tensor ومسرعات ذاكرة Tensor، والحفاظ على قابلية نقل جيدة عبر مختلف بنى NVIDIA GPU.

من الناحية التقنية،يرتكز نظام CUDA Tile على CUDA Tile IR (التمثيل الوسيط)، الذي يُقدّم مجموعة من التعليمات الافتراضية التي تُمكّن من برمجة الأجهزة بطريقة تعتمد على نظام Tile. يستطيع المطورون كتابة تعليمات برمجية عالية المستوى يُمكن تنفيذها بكفاءة عبر أجيال متعددة من وحدات معالجة الرسومات (GPUs) مع الحد الأدنى من التعديلات.
على الرغم من أن تقنية تنفيذ الخيوط المتوازية (PTX) من NVIDIA تضمن قابلية نقل برامج SIMT،ومع ذلك، فإن CUDA Tile IR يوسع منصة CUDA لدعم التطبيقات القائمة على البلاطات بشكل أصلي.يستطيع المطورون التركيز على تقسيم البرامج المتوازية للبيانات إلى وحدات فرعية وكتل فرعية، حيث تتولى لغة CUDA Tile IR عملية ربط هذه الوحدات الفرعية بموارد الأجهزة، بما في ذلك الخيوط، وهياكل الذاكرة، ونوى الموترات. بعبارة أخرى، تتيح البرمجة القائمة على الوحدات الفرعية للمطورين كتابة الخوارزميات من خلال تحديد الوحدات الفرعية وتعريف العمليات الحسابية التي تُجرى عليها، دون الحاجة إلى تهيئة طريقة التنفيذ لكل عنصر من عناصر الخوارزمية على حدة، تاركين هذه التفاصيل للمترجم.
لماذا اختارت شركة NVIDIA تحديث نموذج البرمجة الخاص بها بعد 20 عامًا من تطبيق CUDA؟
يأتي إصدار cuTile بعد ما يقرب من عشرين عامًا من الإصدار الأولي لـ CUDA.منذ إطلاقها عام 2006، تطورت CUDA تدريجيًا من واجهة برمجة لوحدات معالجة الرسومات إلى منظومة متكاملة تشمل أطر العمل، والمترجمات، والمكتبات، وسلاسل الأدوات، ولا تزال تُشكل بنية أساسية لنظام برمجيات NVIDIA حتى يومنا هذا. إن قرار NVIDIA بإطلاق نموذج برمجة جديد لتطوير CUDA في عام 2025 ليس مجرد تطور تقني، بل هو استجابة مباشرة للتغيرات في بيئة الصناعة.
من جهة، أدت التغيرات في أعباء عمل الذكاء الاصطناعي إلى طلب هائل على المُشغّلات المُخصصة، بينما أصبحت سرعة التطوير وتكاليف تصحيح الأخطاء ونقص الكفاءات في لغة CUDA C++ التقليدية من القيود. تستطيع العديد من الفرق تصميم الخوارزميات بسرعة، لكنها تجد صعوبة في كتابة نواة CUDA عالية الأداء وقابلة للصيانة في فترة زمنية قصيرة. يهدف إطلاق cuTile تحديدًا إلى حل هذه المعضلة: فهو يوفر، دون التضحية بالأداء، نقطة دخول سهلة الاستخدام بلغة بايثون، مما يسمح لمزيد من المطورين ببناء مُشغّلات مُخصصة بتكلفة معقولة، وبالتالي خفض العتبة الإجمالية لبرمجة وحدات معالجة الرسومات (GPU) وتقصير دورة التكرار.
بعبارة أخرى،يُعد cuTile خطوة استراتيجية مبكرة من NVIDIA لاستعادة السيطرة على نموذج البرمجة قبل بدء حروب DSL واسعة النطاق بين المشغلين.
من جهة أخرى، وفي ظل اتجاه "التراجع عن هيمنة إنفيديا"، تشتد المنافسة في بيئة برمجيات وحدات معالجة الرسومات: فقد أطلقت AMD منصة الحوسبة المُسرّعة مفتوحة المصدر ROCm، جاذبةً المزيد من مكتبات وأدوات الطرف الثالث للانضمام إليها من خلال بنية مفتوحة وتوسيع نطاق تغطية النظام البيئي؛ بينما أطلقت Intel منصة OneAPI، ساعيةً إلى بناء نموذج برمجة موحد عبر مختلف البنى وتوفير دعم لغات مثل DPC++ لتقليل تعقيد تطوير الأنظمة غير المتجانسة. كل هذا يُضعف احتكار CUDA.
علاوة على ذلك، تتسابق شركات نماذج الذكاء الاصطناعي واسعة النطاق وشركات تصنيع الرقائق الإلكترونية لتطوير لغات برمجة خاصة بها للمشغلات. في أكتوبر 2022، أطلقت OpenAI برنامج Triton، وهو مُجمِّع لغة برمجة مفتوح المصدر للتعلم العميق مُخصَّص لوحدات معالجة الرسومات (GPUs)، يسمح للمطورين بكتابة نواة عالية الأداء لوحدات معالجة الرسومات باستخدام شفرة برمجية موجزة على غرار لغة بايثون، دون الحاجة إلى الخوض في تفاصيل CUDA C++ منخفضة المستوى. ونتيجة لذلك، حظي Triton باهتمام واسع النطاق في أوساط مجتمع المطورين. ويعتقد العديد من الباحثين والمهندسين أن Triton يُسهِّل عملية تطوير مشغلات وحدات معالجة الرسومات. في الوقت نفسه، تُوفِّر لغات TC/tensor المرتبطة بمعيار Meta/FAIR، وأُطر تجميع المشغلات وتحسينها التي بناها مجتمع المطورين حول TVM/Relay/DeepSpeed، خيارات متنوعة للمنافسة في مجالات مُحدَّدة من منظومة البرمجيات.
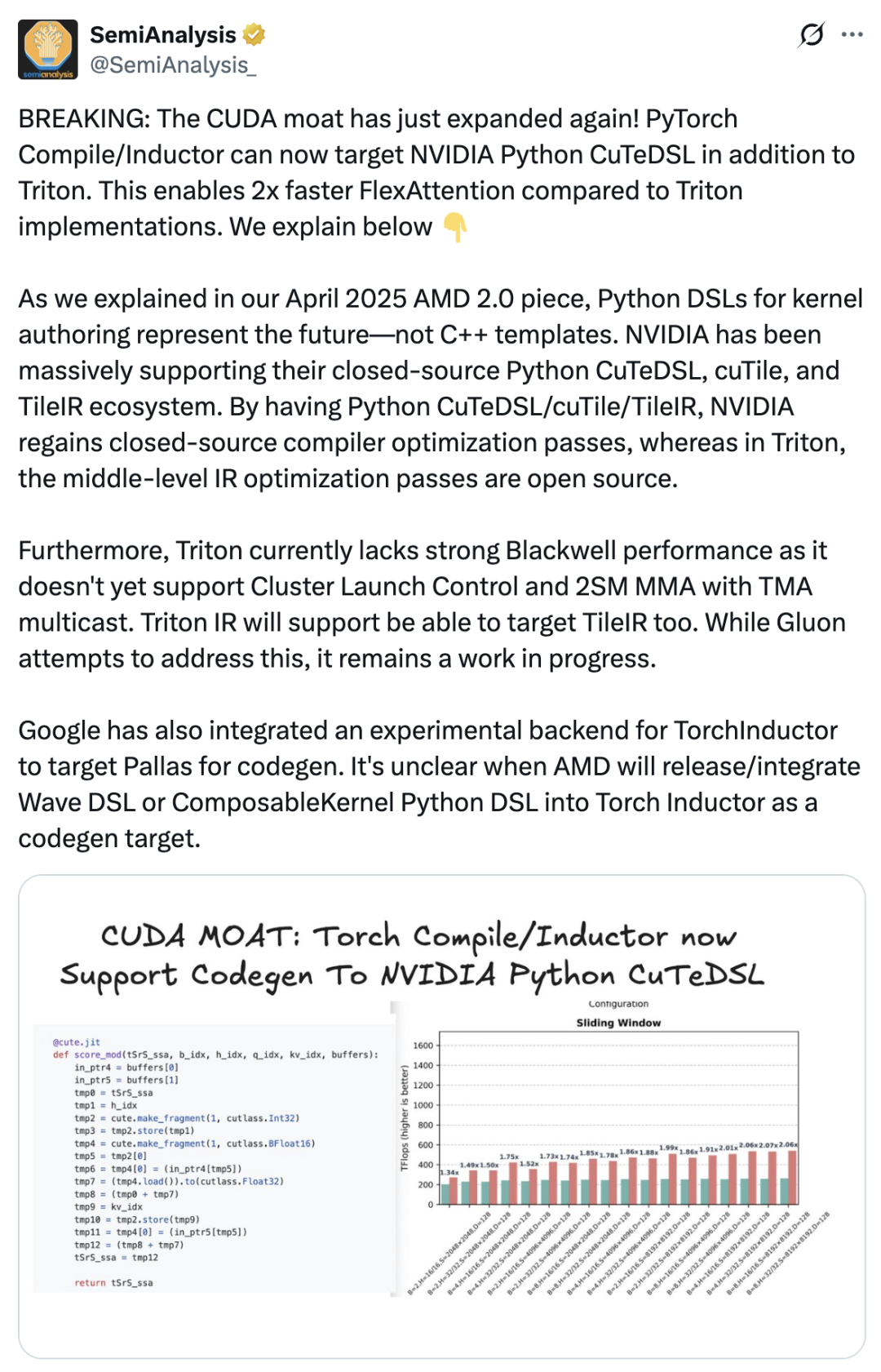
وقد أدى هذا بشكل مباشر إلى ظهور cuTile - من أجل ترسيخ ميزتها التجارية، كان على NVIDIA أن تعمل على تحسين تغليف وتجربة المستخدم لنظام البرامج الخاص بها، حتى يختار المزيد من المطورين البقاء في نظام CUDA البيئي. نشر موقع SemiAnalysis مقالاً ذكر فيه أن إدخال تقنية cuTile يمثل خطوة مهمة من جانب NVIDIA لتعزيز ميزتها التنافسية في مجال CUDA.يدعم مُصرّف PyTorch الآن لغة NVIDIA Python CuTeDSL بالإضافة إلى Triton، مما يجعل FlexAttention أسرع بمرتين من تطبيق Triton. لطالما كانت NVIDIA داعمًا قويًا لنظامها البيئي مغلق المصدر Python CuTeDSL وcuTile وTileIR. ومن خلال Python CuTeDSL/cuTile/TileIR، استعادت NVIDIA إمكانية الوصول إلى تحسينات المُصرّف مغلق المصدر.
هل يتم تقليد Triton؟ عقلية البلاط من cuTile: إليكم ما يقوله المطورون.
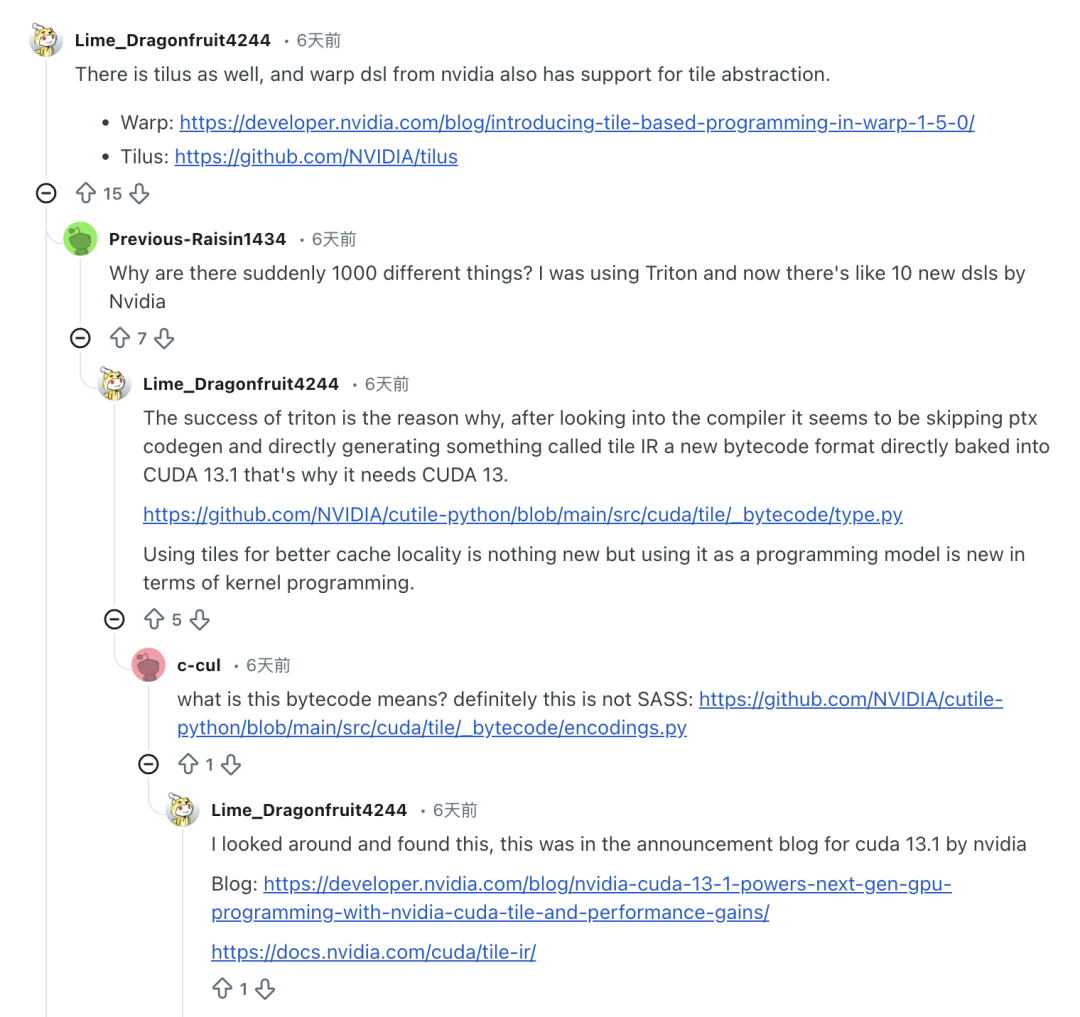
في الحقيقة،كان رد فعل السوق تجاه cuTile مختلطاً بالجدل.أفاد بعض المطورين الذين استخدموا هذه التقنية أنه على الرغم من أن تحسين Tile كان إضافةً مبتكرة، إلا أن العدد الكبير من لغات البرمجة الخاصة بالمجال (DSL) قد أدى إلى صعوبة في التعلم. وعلق مستخدم Reddit Previous-Raisin1434 قائلاً إن لغات البرمجة الخاصة بالمجال الجديدة في cuTile جعلته يشعر بالإرهاق خلال فترة الانتقال.
"لماذا توجد فجأة آلاف الأشياء المختلفة؟ كنت أستخدم Triton من قبل، والآن أصدرت NVIDIA أكثر من 12 لغة برمجة جديدة خاصة بالمجال"، هكذا اشتكى.
في الوقت نفسه، شكك بعض المتخصصين في الصناعة في افتقار cuTile إلى التميز والأصالة، قائلين: "يبدو أن cuTile هو رد NVIDIA على Triton وMojo وThunderKittens، كما لو تم دمجها معًا".

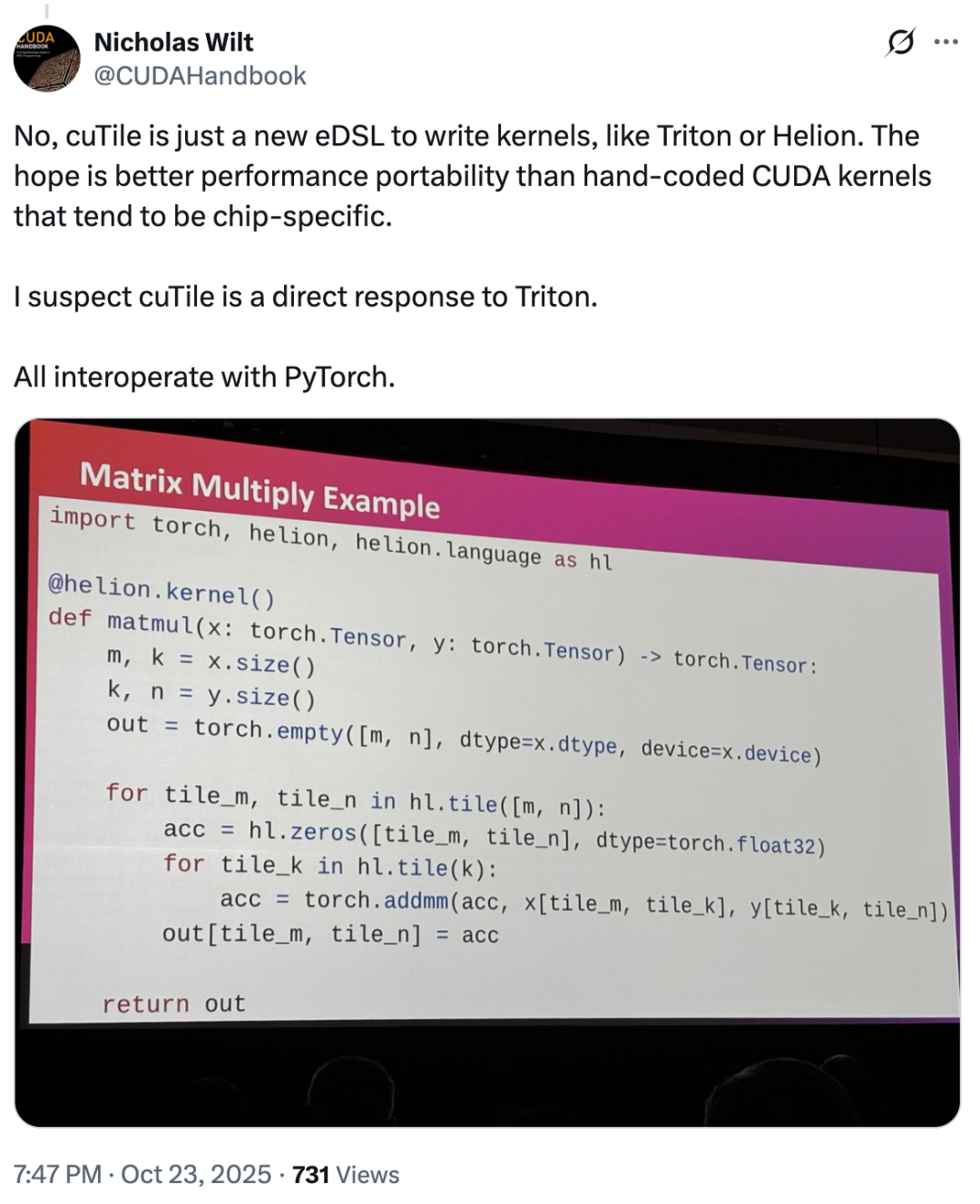
في هذا الصدد،حتى أن نيكولاس ويلت، أحد أعضاء فريق CUDA الأولي، نشر ذلك..."من الصعب عدم الشك في أن cuTile قد تم تطويرها مباشرة لمواجهة Triton. cuTile هي لغة برمجة جديدة خاصة بالمجال لكتابة النواة، تمامًا مثل Triton أو Helion."
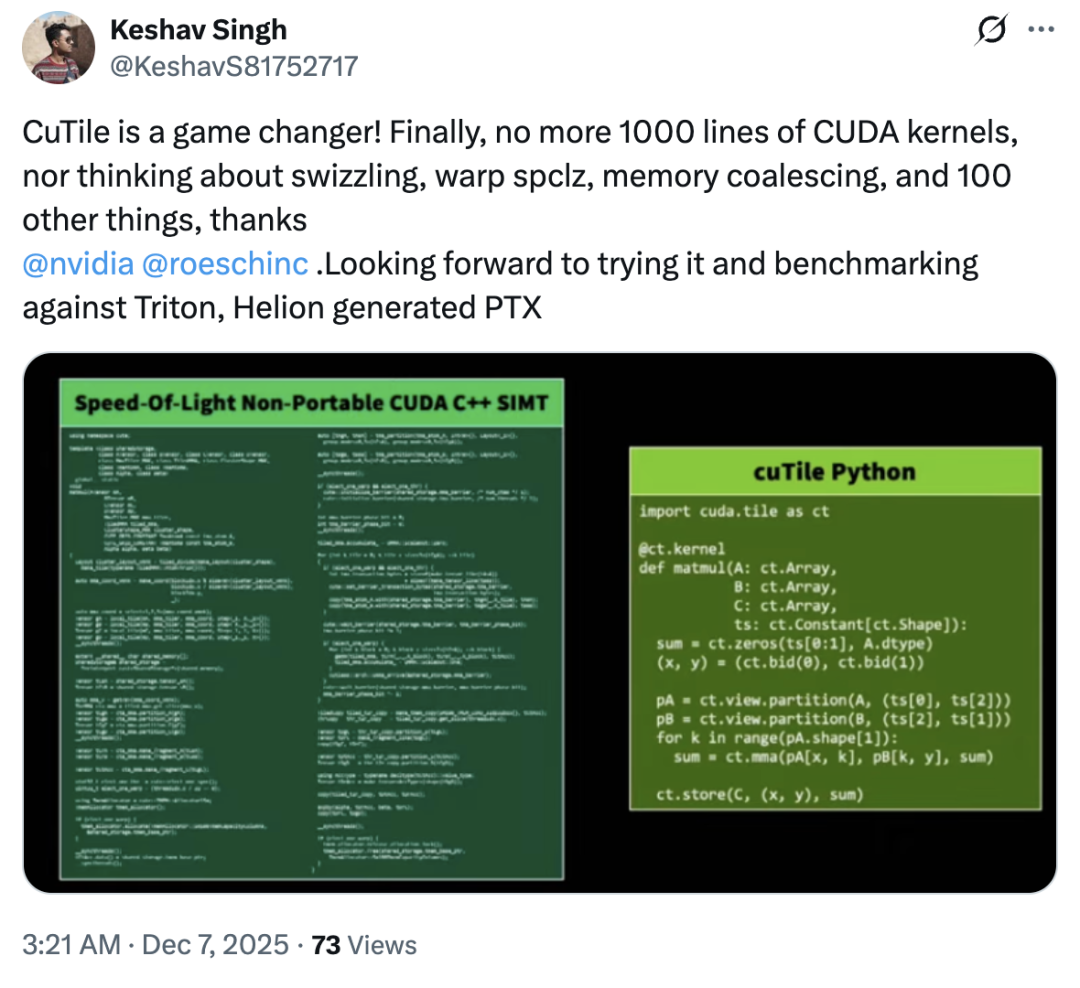
إذن، هل قامت شركة cuTile بنسخ منتج Triton؟ أجاب معظم المستخدمين بالنفي – في الواقع، كان رد فعل السوق تجاه cuTile إيجابيًا بشكل عام، مع وجود عدد قليل فقط من الآراء المعارضة.لم يُبدِ معظم المستخدمين استياءً من هذا التحديث؛ بل إن بعضهم أشاد بـ cuTile ووصفه بأنه "منتج ثوري"."يُغني برنامج cuTile المستخدمين عن القلق بشأن تبديل الذاكرة، و warp spclz، ودمج الذاكرة، وأكثر من مائة مشكلة أخرى."
بحسب مدونة تقنية، فإن جاذبية cuTile الأساسية في كسب المستخدمين تكمن في مفهوم "Tile" الخاص بها، والذي يقدم الحوسبة باستخدام وحدة معالجة الرسومات إلى مستوى أعلى من التجريد.
"في البداية ظننت أن هذا مجرد ربط آخر بلغة بايثون أو غلاف مبسط لـ CUDA، ولكن بعد التعمق في وثائقه وأمثلة عليه، اكتشفت أن لديه طموحات أكبر بكثير." الفكرة الأساسية لـ cuTile هي Tile، وهي ذات صلة بالحوسبة المتوازية وتسريع الأجهزة.التجزئة هي تقنية تحسين كلاسيكية تقسم مجموعات البيانات الكبيرة إلى أجزاء أصغر لتحسين استخدام الذاكرة المؤقتة أو الذاكرة المشتركة. يرتقي cuTile بهذه الفكرة إلى مستوى نموذج برمجي. يذكر الموقع الإلكتروني: "يُمكّن المطورين من التفكير في العمليات الحسابية ووصفها مباشرةً باستخدام التجزئة. لم تعد بحاجة إلى إدارة كيفية تعاون كل خيط في مجموعة من الخيوط، أو كيفية تحميل البيانات من الذاكرة العامة إلى الذاكرة المشتركة، أو كيفية إجراء المزامنة. بدلاً من ذلك، تُحدد تجزئة بياناتك، وتُحدد العمليات التي تُجرى على هذه التجزئة، ويقوم مُصرّف cuTile تلقائيًا بإنشاء رمز نواة فعال للتعامل مع هذه التفاصيل الدقيقة."
على الرغم من أن شركة cuTile لا تزال في مراحلها المبكرة، إلا أن هناك حالات لاستكشاف مسارات الهجرة بشكل استباقي داخل الصناعة.بدأ بعض المتخصصين في مجال الخوارزميات في محاولة بناء أدوات تحويل آلية من CUDA C++ إلى cuTile.الهدف هو بناء جسر عملي بين الشيفرة الهندسية الحالية والنموذج الجديد. ومن بين هذه الجهود، أطلق مطورو مجتمع Reddit مشروعًا مفتوح المصدر يُمكنه ترجمة أجزاء من نواة CUDA إلى تنسيق قائم على البلاطات لتلبية احتياجات الترحيل المحتملة للمجتمع.
مع ذلك، لا توجد إجابة واضحة حول مدى نجاح نموذج "Tile" من NVIDIA، فـ cuTile، كمنتج جديد، لم يدخل بعد مرحلة التحقق. إذا تطورت أدوات الترحيل من CUDA إلى cuTile بشكل أكبر، وإذا أبدى المجتمع استعداده لتشكيل دوائر جديدة من التجارب والنقاشات حول cuTile، فقد يحتل cuTile مكانة غير مسبوقة في منظومة برمجيات وحدات معالجة الرسومات (GPU) المستقبلية.ومع ذلك، فإن نتيجة الفشل في تجاوز هذه العتبات واضحة تمامًا - ربما انتهى الأمر بـ cuTile كتجربة قصيرة في التاريخ الطويل لـ CUDA.في الختام، في ظل بيئة المنافسة الحالية، ستعتمد جاذبية cuTile المستمرة على قدرتها على تحسين تجربة التطوير باستمرار، وتقليل تكاليف الترحيل، وتوفير مزايا أداء لا يمكن الاستغناء عنها للمشغلين المعقدين.
روابط مرجعية:
1.https://byteiota.com/nvidia-cutile-python-gpu-kernel-programming-without-cuda-complexity/
2.https://veyvin.com/archives/github-trending-2025-12-08-nvidia-cutile-python
3.https://cloud.tencent.com/developer/article/2512674
4.https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware








