Command Palette
Search for a command to run...
من "مساعد" إلى "مستخدم"، يُحاكي Microsoft UserLM-8B محادثات بشرية حقيقية، مُحدثًا بذلك طفرةً جديدةً في تحسينات LLM. صُمم Extract-0 لأداءٍ خفيف، ويساعد النماذج ذات المعلمات الصغيرة على استخلاص المعلومات بدقة.

مع التطور السريع لنماذج اللغة الكبيرة (LLMs)، شهدنا ظهور نماذج قوية تعمل بمثابة "مساعدين"، مخصصة لتوفير استجابات مفصلة ومنظمة لتلبية احتياجات المستخدم الصريحة.يخرجفي سياقات المحادثة الواقعية، غالبًا ما لا يُعبّر المستخدمون عن نواياهم كاملةً دفعةً واحدة، بل يكشفون عن المعلومات تدريجيًا خلال جولات محادثة متعددة. كما يُظهر أسلوبهم اللغوي عمومًا سمات التجزئة والتخصيص والتعديل الفوري.في المقابل، لا تُجيد نماذج "المساعدين" التقليدية محاكاة المستخدمين. علاوة على ذلك، كلما كان مساعد برنامج الماجستير في القانون أفضل، كان تمثيله لشخصية المستخدم أكثر تشويشًا. يكشف هذا القيد أيضًا عن نقطة ضعف رئيسية في نظام تقييم برنامج الماجستير في القانون الحالي: نظرًا لنقص شخصيات "المستخدمين" عالية الجودة القادرة على محاكاة المحادثات البشرية بدقة، غالبًا ما تكون بيئات التقييم الحالية مثالية بشكل مبالغ فيه، وتتفوق عليها السياقات المعقدة للتطبيقات الواقعية بشكل كبير.
وفي هذا السياقأطلقت شركة مايكروسوفت أحدث نموذج للغة المستخدم UserLM-8B،بخلاف برامج إدارة التعلم التقليدية، التي عادةً ما تعمل كمساعدين، يُمكن استخدام هذا النموذج، المُدرَّب على مجموعة محادثات WildChat، لمحاكاة دور "المستخدم" في المحادثات، والمشاركة في جولات حوار متعددة، ويُشكل أداةً فعّالة لتقييم قدرات النماذج واسعة النطاق. عند استخدام UserLM لمحاكاة محادثات البرمجة والرياضيات، انخفضت درجة GPT-4o من 74.61 TP3T إلى 57.41 TP3T، مما يؤكد أن بيئات المحاكاة الأكثر واقعية قد تُؤدي إلى انخفاض أداء "المساعد" نظرًا لصعوبة استجابته لتفاصيل تعبيرات المستخدم.
يوفر إطلاق UserLM-8B بيئة اختبار أكثر واقعية ومتانة لتقييم النماذج الكبيرة. من خلال محاكاة محادثات المستخدمين، حتى نماذج المساعدة الحديثة قد تتراجع في الأداء بشكل ملحوظ، مما يُمكّن الباحثين والمطورين من تحديد نقاط ضعف النموذج بدقة أكبر في التفاعلات الواقعية.ويعمل هذا على تعزيز تقييم كفاءة الماجستير في القانون لتجاوز اختبار معياري ثابت ومقارنة النتائج، والتركيز تدريجيا على "تمارين القتال الفعلية" الأقرب إلى الواقع.دع LLM يفهم بشكل أفضل النوايا الحقيقية للمستخدم ويعمل باستمرار على تحسين تجربة المستخدم البشرية.
نموذج محاكاة محادثة المستخدم UserLM-8b متوفر الآن على الموقع الرسمي لشركة HyperAI. تفضلوا بتجربته!
الاستخدام عبر الإنترنت:https://go.hyper.ai/EHcdQ
من 20 أكتوبر إلى 24 أكتوبر، إليك نظرة عامة سريعة على تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 8
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 7
* الأوراق الموصى بها لهذا الأسبوع: 5
* تفسير المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* المؤتمر الأول مع الموعد النهائي في أكتوبر: 1
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات معيار الأداء CP2K_Benchmark
مجموعة بيانات CP2K Benchmark هي مجموعة من مدخلات اختبار الأداء والتحقق، مصممة خصيصًا لبيئات الحوسبة عالية الأداء (HPC). تُستخدم هذه المجموعة، المستمدة من برنامج المحاكاة مفتوح المصدر CP2K، لتقييم أداء حسابات كيمياء الكم وديناميكيات الجزيئات باستخدام منصات أجهزة مختلفة، واستراتيجيات التوازي (MPI/OpenMP)، وإعدادات تحسين التجميع.
الاستخدام المباشر:https://go.hyper.ai/BGnLb
2. مجموعة بيانات معيارية لمحاكاة ديناميكيات البلازما Smilei_Benchmark
Smilei، وهو اختصار لـ Simulation of Matter Irradiated by Light at Extreme Intensities، هو عبارة عن كود جسيمات كهرومغناطيسية في الخلية (PIC) مفتوح المصدر وسهل الاستخدام مصمم لتوفير منصة محاكاة ديناميكية البلازما عالية الدقة وعالية الأداء وقابلة للتطوير لمجالات مثل تفاعل الليزر والبلازما، وتسريع الجسيمات، والمجال القوي QED، وفيزياء الفضاء.
الاستخدام المباشر:https://go.hyper.ai/6VCxB
3. مجموعة بيانات مثال لتحليل الجينوم Gatk_benchmark
GATK (مجموعة أدوات تحليل الجينوم) هي مجموعة أدوات مفتوحة المصدر في مجال المعلوماتية الحيوية، طوّرها معهد برود، وهو مشروع مشترك بين معهد ماساتشوستس للتكنولوجيا وجامعة هارفارد. يهدف المشروع إلى توفير مسار تحليل موحد لبيانات التسلسل عالي الإنتاجية (NGS).
الاستخدام المباشر:https://go.hyper.ai/0VAuf
4. مجموعة بيانات معيار ديناميكيات الجزيئات LAMMPS-Bench
تُستخدم مجموعات بيانات LAMMPS Bench لاختبار ومقارنة أداء LAMMPS (برنامج محاكاة الديناميكيات الجزيئية) على أجهزة وتكوينات مختلفة. هذه المجموعات ليست بيانات تجريبية علمية، بل تُستخدم لتقييم الأداء الحسابي (السرعة، والتوسع، والكفاءة). تحتوي على هياكل محددة، وملفات مجال القوة، ونصوص إدخال، وإحداثيات ذرية أولية، وغيرها. يوفر LAMMPS هذه المجموعات في مجلد "bench/".
الاستخدام المباشر:https://go.hyper.ai/L4gye
5. مجموعة بيانات SFT ذات الضبط الدقيق المُشرف عليها PromptCoT-2.0-SFT-4.8M
PromptCoT-2.0-SFT-4.8M هي مجموعة بيانات مُركّبة واسعة النطاق للمطالبات، مُصمّمة لتوفير مطالبات استدلال عالية الجودة لنماذج اللغات الكبيرة، سواءً للضبط الدقيق أو التدريب الذاتي. تحتوي هذه المجموعة على ما يقارب 4.8 مليون مطالبة استدلال مُركّبة بالكامل مع آثار استدلال، تُغطّي مجالين رئيسيين للاستدلال: الرياضيات والبرمجة.
الاستخدام المباشر:https://go.hyper.ai/f188j
6. استخراج بيانات استخراج معلومات المستند - 0
Extract-0 هي مجموعة بيانات تدريب وتقييم عالية الجودة، مصممة خصيصًا لمهام استخراج معلومات المستندات. تهدف إلى دعم أبحاث تحسين أداء نماذج المعلمات صغيرة الحجم في مهام الاستخراج المعقدة.
الاستخدام المباشر:https://go.hyper.ai/z9BQO
7. مجموعة بيانات معيار إدراك المشاعر EmoBench-M
EmoBench-M هي مجموعة بيانات مرجعية اقترحتها جامعة شنتشن، ومختبر قوانغمينغ، وجامعة ماكاو، ومؤسسات أخرى، لتقييم قدرات فهم المشاعر في نماذج اللغة الكبيرة متعددة الوسائط (MLLMs). تهدف هذه المجموعة إلى سد الثغرات في مجموعات بيانات المشاعر أحادية أو ثابتة في سيناريوهات التفاعل الديناميكي ومتعدد الوسائط، والاقتراب من تعقيد التعبير والإدراك العاطفي البشري في البيئات الواقعية.
الاستخدام المباشر:https://go.hyper.ai/WafXo
8. مجموعة بيانات الاستدلال الهندسي متعدد الوسائط GeoReasoning-10K
GeoReasoning-10K هي مجموعة بيانات استدلالية متعددة الوسائط في الهندسة، مصممة لسد الفجوة بين الوسائط البصرية واللغوية في الهندسة. تحتوي مجموعة البيانات على 10,000 زوج هندسي من الصور والنصوص، مع شروح توضيحية مفصلة للاستدلال الهندسي. يحافظ كل زوج على اتساق البنية الهندسية، والتعبير الدلالي، والعرض المرئي، مما يؤدي إلى محاذاة دلالية متعددة الوسائط بدقة عالية.
الاستخدام المباشر:https://go.hyper.ai/7qisY

دروس تعليمية عامة مختارة
1. UserLM-8b: نموذج محاكاة حوار المستخدم
UserLM-8b هو نموذج محاكاة سلوك المستخدم من مايكروسوفت. بخلاف برامج إدارة التعلم التقليدية، التي تلعب دور "المساعد" في المحادثات، يُحاكي UserLM-8b دور "المستخدم" في المحادثات (المُدرَّب على مجموعة محادثات WildChat)، ويمكن استخدامه لتقييم قدرات المساعدين ذوي القدرات الكبيرة. هذا النموذج ليس مساعدًا نموذجيًا واسع النطاق، ولا يُمكنه محاكاة محادثات أكثر واقعية أو حل المشكلات، ولكنه يُساعد في تطوير مساعدين أكثر كفاءة.
تشغيل عبر الإنترنت:https://go.hyper.ai/EHcdQ
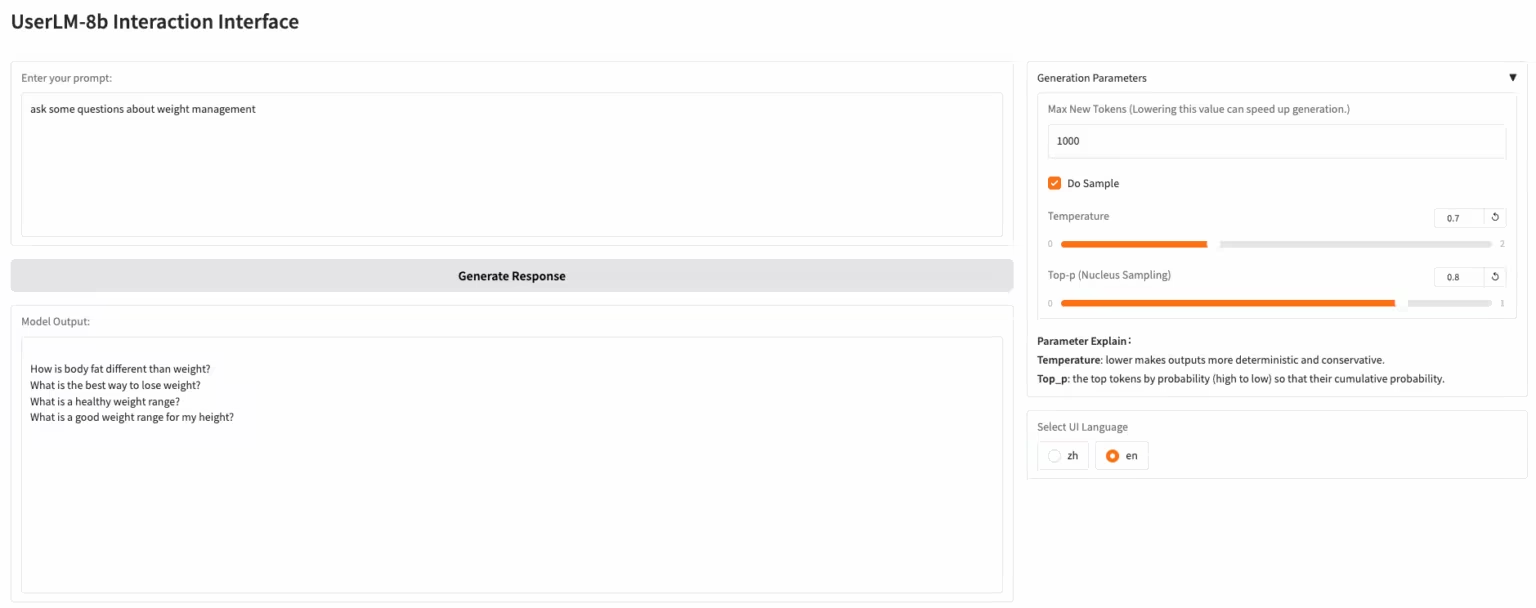
2. MiMo-Audio-7B-Instruct: نموذج صوتي شامل مفتوح المصدر من Xiaomi
MiMo-Audio هو نموذج كلام متكامل من شاومي. توسعت بيانات التدريب المسبق لتشمل أكثر من 100 مليون ساعة، ولاحظ الباحثون أنه يُظهر قدرات تعلم سريعة عبر مجموعة متنوعة من المهام الصوتية. قام الفريق بتقييم هذه القدرات بشكل منهجي، ووجد أن MiMo-Audio-7B-Base حقق أداءً متطورًا (SOTA) في كل من معايير ذكاء الكلام وفهم الصوت للنماذج مفتوحة المصدر.
تشغيل عبر الإنترنت:https://go.hyper.ai/3DWbb
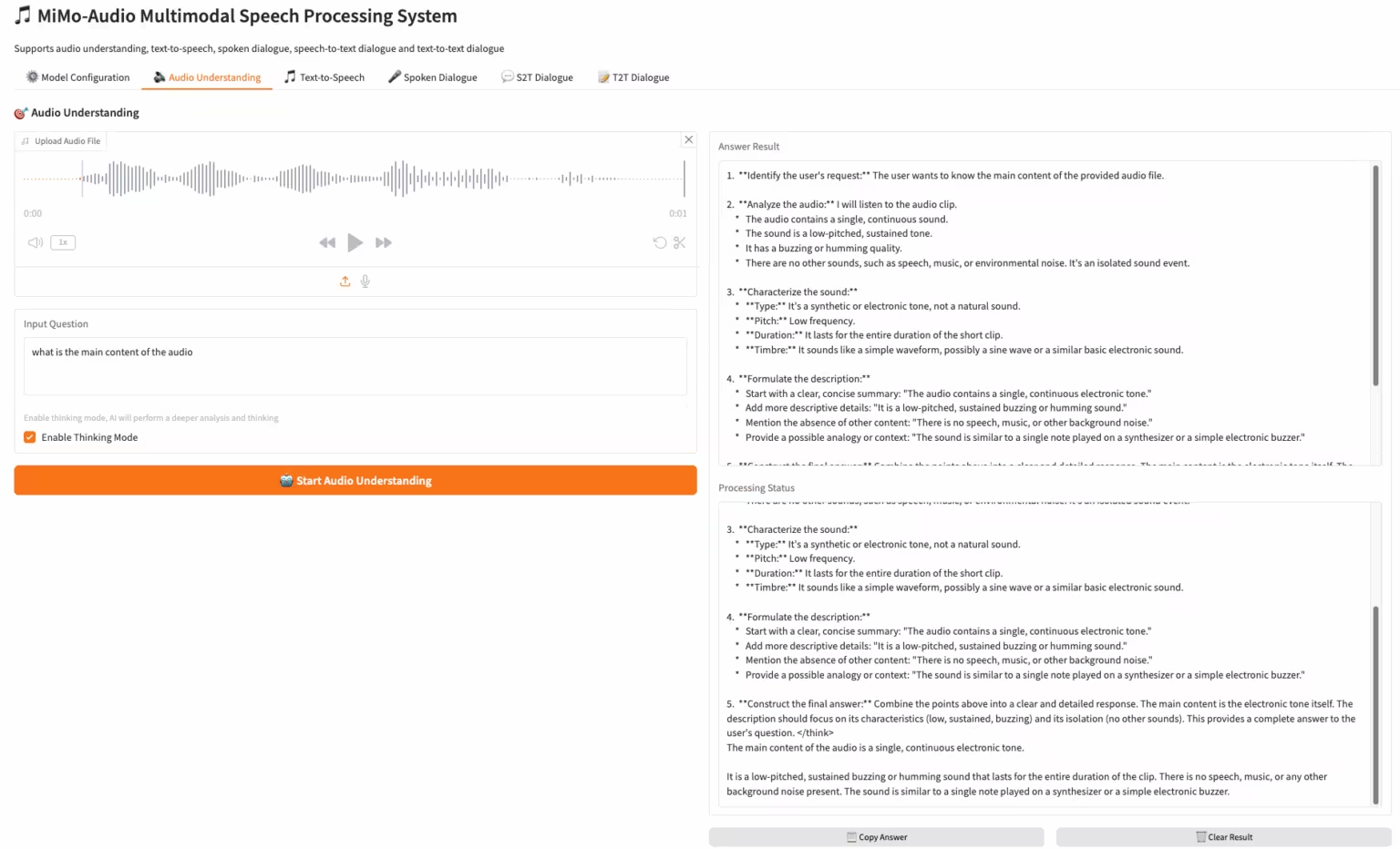
3. Wan2.2-Animate-14B: نموذج مفتوح ومتقدم لتوليد الفيديو واسع النطاق
Wan2.2-Animate-14B هو نموذج توليد حركة مفتوح المصدر، طوّره فريق Alibaba Tongyi Wanxiang. يدعم النموذج كلاً من وضعي محاكاة الحركة وتقمص الأدوار. بالاعتماد على مقاطع فيديو للممثلين، يُمكنه محاكاة تعابير الوجه وحركاته بدقة لإنشاء مقاطع فيديو رسوم متحركة واقعية للغاية للشخصيات.
تشغيل عبر الإنترنت: https://go.hyper.ai/UbtSO
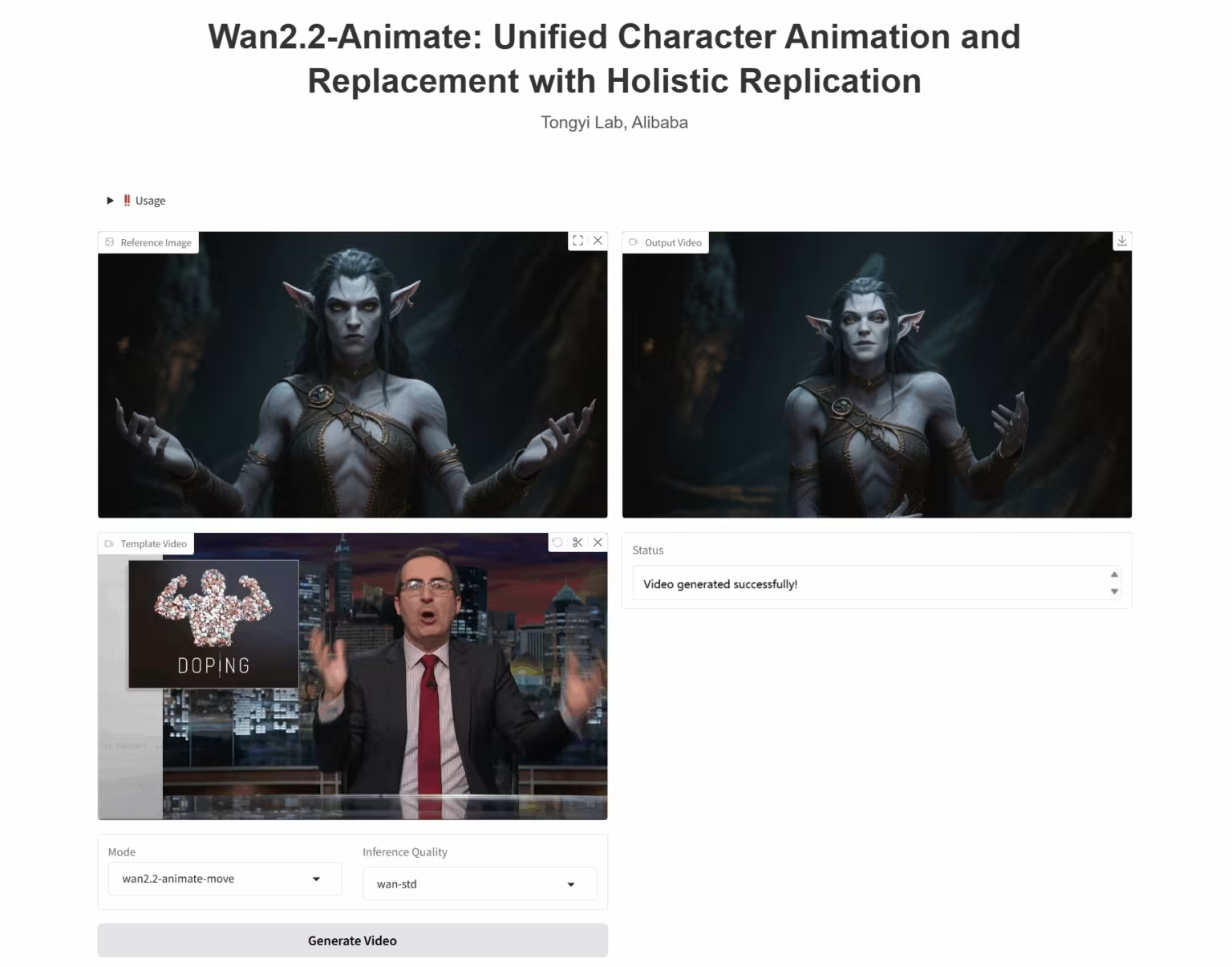
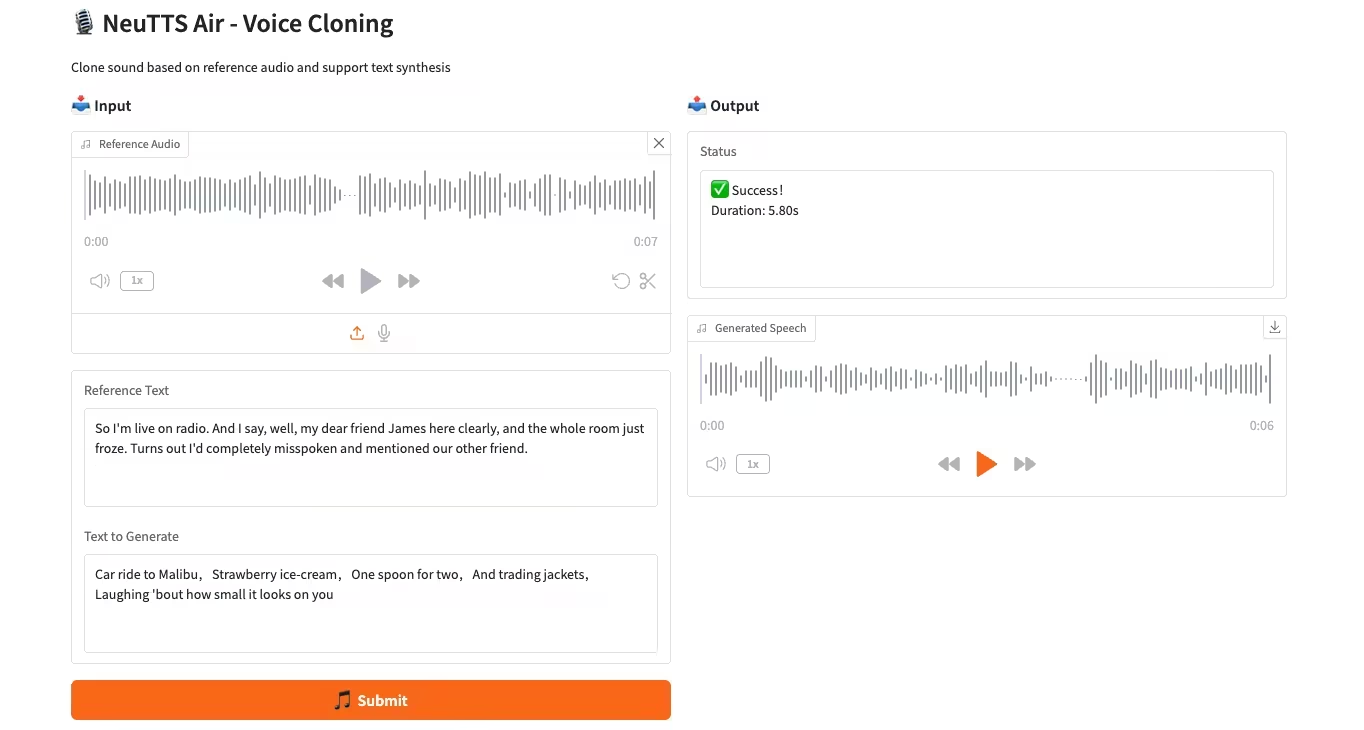
4. نشر وحدة المعالجة المركزية لنموذج استنساخ الصوت NeuTTS-Air
NeuTTS-Air هو نموذج تحويل نص إلى كلام (TTS) شامل من إنتاج Neuphonic. يعتمد هذا النموذج على بنية Qwen LLM الأساسية بسرعة 0.5B وترميز الصوت NeuCodec، ويُظهر قدرات تعلم سريعة في النشر على الجهاز واستنساخ الصوت الفوري. تُظهر تقييمات النظام أن NeuTTS Air يحقق أداءً متطورًا مقارنةً بالنماذج مفتوحة المصدر، لا سيما في معايير التوليف فائقة الواقعية والاستدلال الفوري.
تشغيل عبر الإنترنت:https://go.hyper.ai/KMMG1
5. HuMo-1.7B: إطار عمل لتوليد الفيديو متعدد الوسائط
HuMo هو إطار عمل لتوليد الفيديو متعدد الوسائط، طورته جامعة تسينغهوا ومختبر الإبداع الذكي التابع لشركة بايت دانس، ويركز على توليد مقاطع فيديو تتمحور حول الإنسان. يُنتج هذا الإطار مقاطع فيديو عالية الجودة، ومفصلة، وقابلة للتحكم، تُشبه مقاطع الفيديو البشرية، من مُدخلات متعددة الوسائط، تشمل النصوص والصور والصوت. يدعم هذا النموذج متابعةً دقيقةً لإشارات النص، وحفظًا مُتسقًا للموضوع، ومزامنةً للحركة مُعتمدةً على الصوت.
تشغيل عبر الإنترنت:https://go.hyper.ai/tnyQU
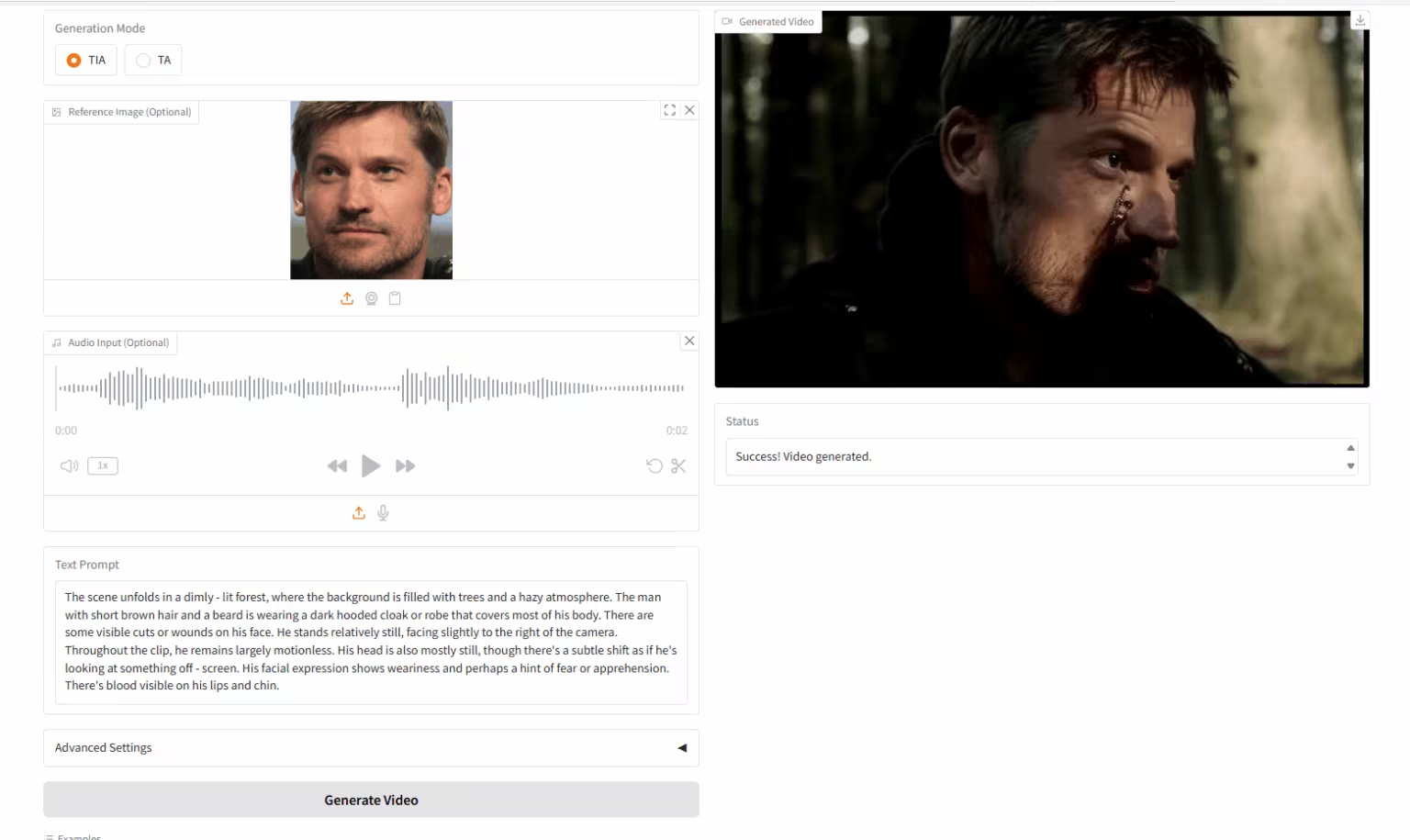
6. HuMo-17B: الإبداع التعاوني ثلاثي الأبعاد
HuMo هو إطار عمل متعدد الوسائط لتوليد الفيديو، أصدرته جامعة تسينغهوا ومختبر بايت دانس للإبداع الذكي. يدعم هذا الإطار توليد مقاطع فيديو من نص-صورة (VideoGen من Text-Image)، ونص-صوت (VideoGen من Text-Audio)، ونص-صورة-صوت (VideoGen من Text-Image-Audio).
تشغيل عبر الإنترنت:https://go.hyper.ai/liAti
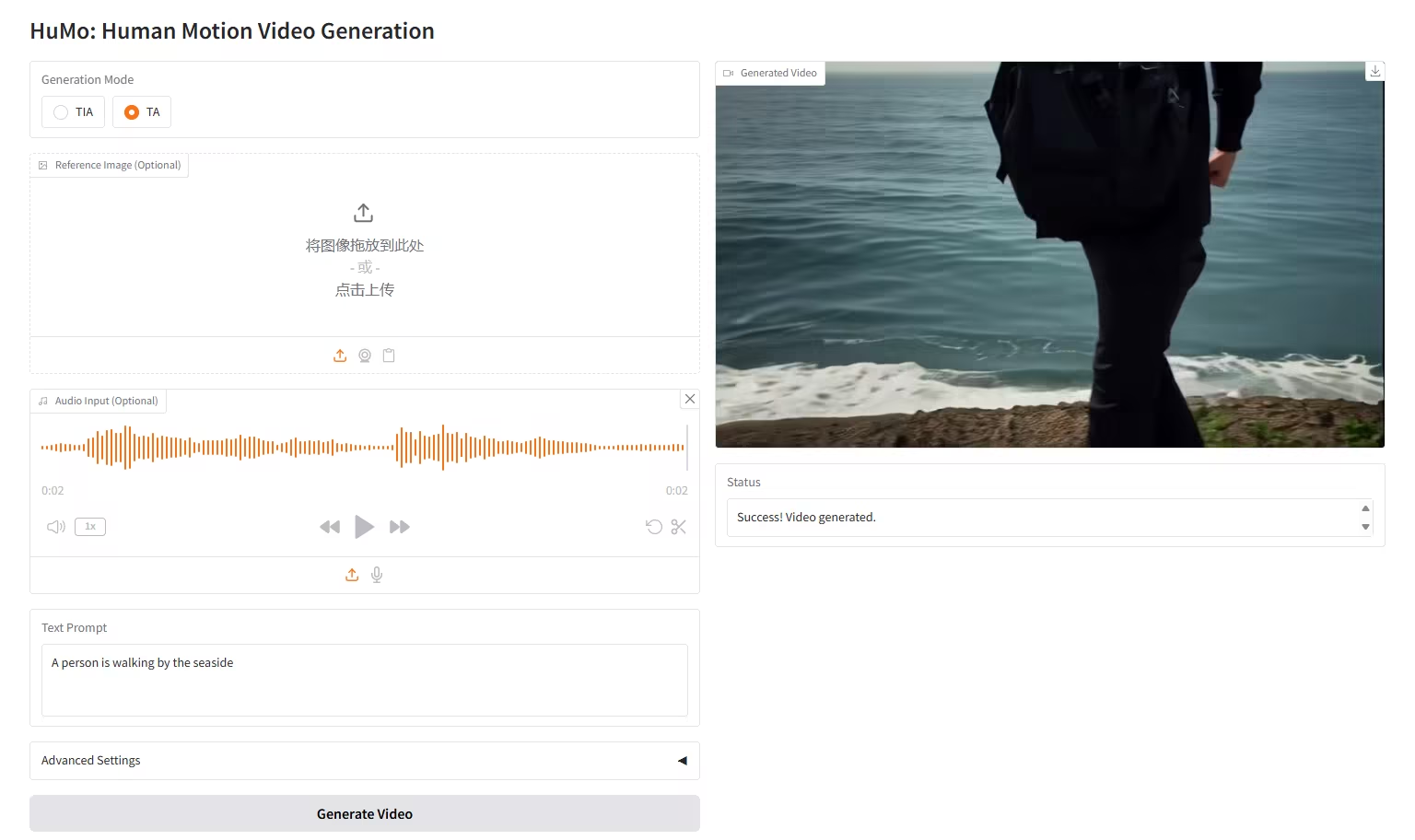
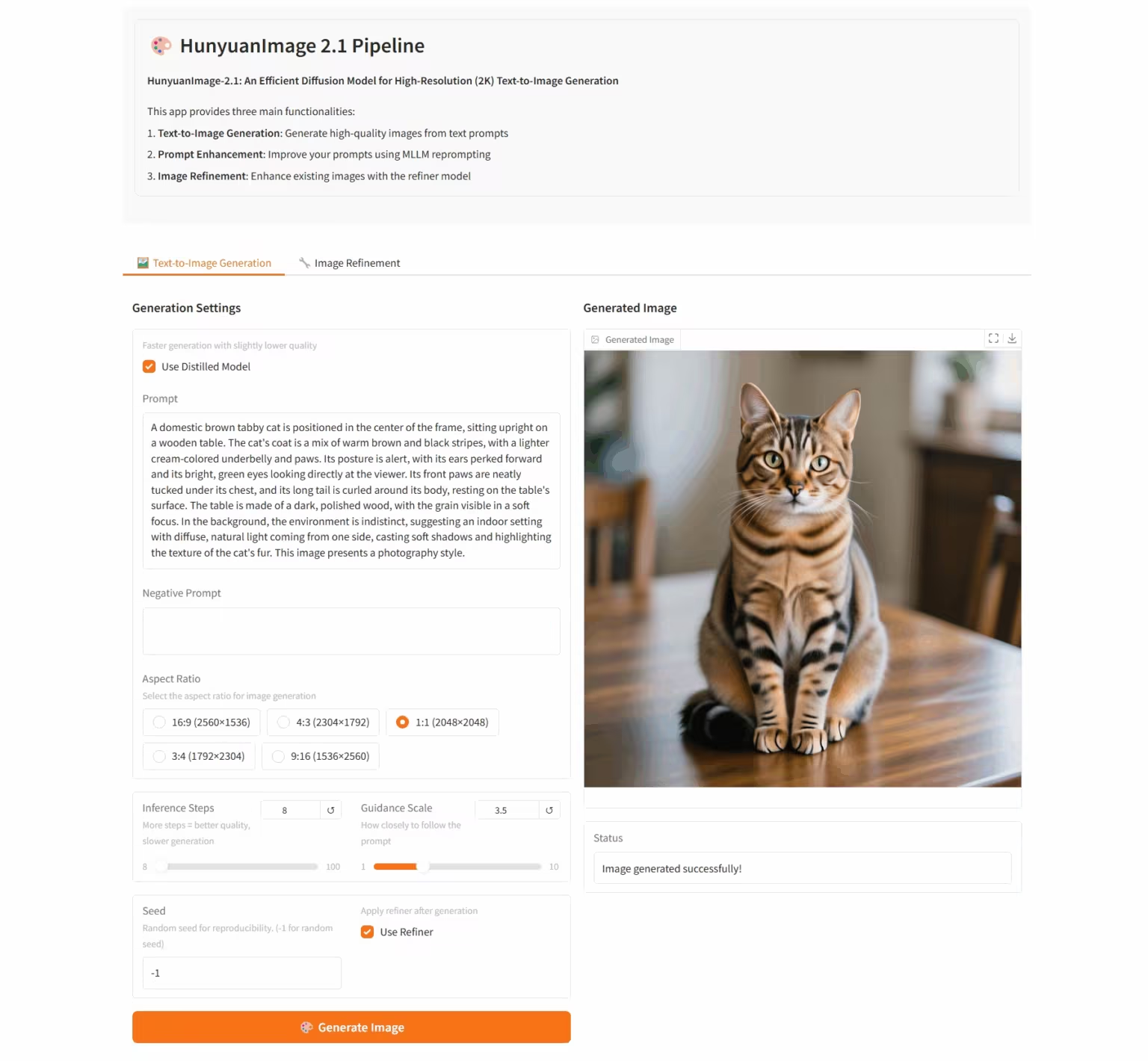
7. HunyuanImage-2.1: نموذج انتشار لصور Wensheng عالية الدقة (2K)
HunyuanImage-2.1 هو نموذج صور نصي مفتوح المصدر، طوّره فريق Tencent Hunyuan. يدعم دقة 2K الأصلية، ويتمتع بقدرات قوية لفهم الدلالات المعقدة، مما يُمكّن من توليد تفاصيل المشهد، وتعبيرات الشخصيات، والحركات بدقة. يدعم النموذج الإدخال باللغتين الصينية والإنجليزية، ويمكنه توليد صور بأنماط متنوعة، مثل القصص المصورة وشخصيات الحركة، مع الحفاظ على تحكم دقيق في النصوص والتفاصيل داخل الصور.
تشغيل عبر الإنترنت:https://go.hyper.ai/hpWNA
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

توصيات الورقة البحثية لهذا الأسبوع
1. دراسة نظرية حول ربط الاحتمالية الداخلية والاتساق الذاتي في استدلالات ماجستير القانون
تقترح هذه الورقة البحثية منهجية RPC (التعقيد والاتساق وتقليم الاستدلال)، وهي منهجية هجينة تجمع بين الرؤى النظرية وتتألف من عنصرين أساسيين: اتساق التعقيد وتقليم الاستدلال. يُظهر كلٌّ من التحليل النظري والنتائج التجريبية على سبع مجموعات بيانات مرجعية قدرة RPC الكبيرة على تقليل أخطاء الاستدلال. والجدير بالذكر أن RPC يحقق أداءً استدلاليًا يُضاهي الاتساق الذاتي، مع تحسين كبير في موثوقية الثقة وخفض تكلفة أخذ العينات بنسبة 50%.
رابط الورقة:https://go.hyper.ai/V3reH
2. كل اهتمام مهم: بنية هجينة فعالة للتفكير في السياق الطويل
يقترح هذا التقرير الفني سلسلة من نماذج الحلقات الخطية، بما في ذلك Ring-mini-linear-2.0 وRing-flash-linear-2.0. يعتمد كلا النموذجين بنية هجينة تدمج بفعالية الانتباه الخطي وانتباه Softmax، مما يقلل بشكل كبير من تكاليف الإدخال/الإخراج والعبء الحسابي في سيناريوهات الاستدلال طويلة المدى.
رابط الورقة:https://go.hyper.ai/xLhP3
3. BAPO: تثبيت التعلم التعزيزي خارج السياسة لطلاب الماجستير في القانون من خلال تحسين السياسات المتوازن باستخدام التقليم التكيفي
تقترح هذه الورقة طريقة بسيطة وفعالة، وهي تحسين السياسة المتوازنة باستخدام القص التكيفي (BAPO)، والتي تضبط حدود القص بشكل ديناميكي، وتعيد التوازن بشكل تكيفي للمساهمات الإيجابية والسلبية، وتحافظ بشكل فعال على إنتروبيا السياسة، وتحسن بشكل كبير استقرار تحسين التعلم التعزيزي.
رابط الورقة:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: نماذج لغوية كبيرة الحجم لعلم البيانات المستقل
تقدم هذه الورقة البحثية DeepAnalyze-8B، أول نموذج لغوي واسع النطاق مصمم خصيصًا لعلم البيانات المستقل. يُؤتمت هذا النموذج العملية من البداية إلى النهاية، بدءًا من مصدر البيانات ووصولًا إلى تقارير البحث المتعمقة المصممة خصيصًا للمحللين. تُظهر النتائج التجريبية أن هذا النموذج، باستخدام 8 مليارات معلمة فقط، يتفوق في الأداء على وكلاء سير العمل السابقين المبنيين على أحدث نماذج اللغات واسعة النطاق المملوكة.
رابط الورقة:https://go.hyper.ai/UTdwP
5. OmniVinci: تحسين البنية والبيانات لفهم متعدد الوسائط
تقترح هذه الورقة مشروع OmniVinci، الذي يهدف إلى بناء نموذج لغوي كبير (LLM) قوي ومفتوح المصدر متعدد الأنماط. أجرى الباحثون أبحاثًا معمقة حول تصميم بنية النموذج واستراتيجيات بناء البيانات، وصمموا ونفذوا عملية بناء وتوليف بيانات، وأنتجوا مجموعة بيانات تضم 24 مليون محادثة أحادية ومتعددة الأنماط.
رابط الورقة:https://go.hyper.ai/c3yQW
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:https://go.hyper.ai/iSYSZ
تفسير مقالة المجتمع
1. تم اختيار NVIDIA لـ NeurIPS 2025، واقترحت نموذج ERDM لحل مشكلات التنبؤ طويلة الأجل، وتستمر توقعاتها المتوسطة والطويلة الأجل في الريادة في معيار EDM.
استنادًا إلى إطار عمل نموذج الانتشار الموضح (EDM)، قام فريق بحثي من NVIDIA وجامعة كاليفورنيا، سان دييغو، بتحسين جدولة الضوضاء، ومعلمات شبكة إزالة الضوضاء، وإجراءات المعالجة المسبقة، واستراتيجيات ترجيح الخسارة، وخوارزميات أخذ العينات بشكل منهجي لتلبية احتياجات نمذجة التسلسل، وبناء نموذج انتشار تسلسل محسن (ERDM).
شاهد التقرير الكامل:https://go.hyper.ai/QZBBl
2. البرنامج التعليمي المضمن | معهد ماساتشوستس للتكنولوجيا وآخرون يطلقون BindCraft، الذي يستدعي AF2 مباشرةً لتحقيق تصميم ذكي للمجمعات البروتينية
اقترح فريق من المعهد الفيدرالي السويسري للتكنولوجيا في لوزان (EPFL) ومعهد ماساتشوستس للتكنولوجيا (MIT) عملية آلية مفتوحة المصدر، تُسمى BindCraft، لتصميم روابط البروتين من الصفر. الفكرة الأساسية هي إعادة توزيع تسلسل الرابط المُتخيل عبر أوزان AlphaFold2 وحساب تدرج الخطأ.
شاهد التقرير الكامل:https://go.hyper.ai/LqNeb
3. ثلاث جوائز نوبل في عامين: تراكم الأبحاث العلمية طويلة الأمد لشركة ألفابت، والذكاء الاصطناعي والحوسبة الكمومية يقودان القوة التكنولوجية والطموح
مع الإعلان عن جوائز نوبل لعام ٢٠٢٥، فاز علماء من شركة ألفابت، الشركة الأم لجوجل، مجددًا. وبصفتها شركة تقنية عملاقة فازت بجوائز نوبل لعامين متتاليين، فإن حصولها على "ثلاث جوائز وخمسة فائزين خلال عامين" ليس مصادفة. بدءًا من فوزها بجائزتي الكيمياء والفيزياء لتكنولوجيا الذكاء الاصطناعي عام ٢٠٢٤، ووصولًا إلى إنجازها البحثي الكمي الذي حصد جائزة الفيزياء هذه المرة، عززت أكثر من عقد من التخطيط الطموح واستراتيجيات البحث قدراتها البحثية العلمية القوية.
شاهد التقرير الكامل:https://go.hyper.ai/mY9Z3
قام معهد ماساتشوستس للتكنولوجيا ببناء نموذج ذكاء اصطناعي توليدي يعتمد على المسبقات الفيزيائية، ويتطلب فقط إدخال نمط طيفي واحد لتحقيق توليد طيفي عبر الأنماط مع ارتباطات تجريبية تصل إلى 99%.
اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا (MIT) نموذج SpectroGen، وهو نموذج ذكاء اصطناعي توليدي قائم على المُسبقات الفيزيائية. باستخدام نمط طيفي واحد فقط كمدخل، يُمكنه توليد أطياف متعددة الأنماط بترابط 99% مع النتائج التجريبية. يُقدم هذا النموذج ابتكارين رئيسيين: أولًا، تمثيل البيانات الطيفية كمنحنيات توزيع رياضية؛ ثانيًا، بناء خوارزمية توليدية مُشفّرة ذاتيًا متغيرة قائمة على المُسبقات الفيزيائية.
شاهد التقرير الكامل:https://go.hyper.ai/OsYY2
5. تتعاون فرق Google في مجال الذكاء الاصطناعي للأرض، مع التركيز على ثلاث نقاط بيانات أساسية وتحسين قدرات التفكير الجغرافي المكاني من خلال 64%.
طورت فرق متعددة في جوجل بشكل مشترك "Earth AI"، وهو نموذج ذكاء اصطناعي جغرافي مكاني ونظام استدلال ذكي. يبني هذا النظام مجموعة مترابطة من نماذج الذكاء الاصطناعي الجغرافي، ويتيح تحليلًا تعاونيًا للبيانات متعددة الوسائط من خلال أدوات استدلال مخصصة. يركز النظام على ثلاثة أنواع أساسية من البيانات: الصور، والسكان، والبيئة، ويربط هذه النماذج الثلاثة باستخدام أدوات مدعومة بـ Gemini. يتجاوز هذا النظام حدود النماذج أحادية النقطة، مما يتيح حتى للمستخدمين غير الخبراء إجراء تحليلات آنية متعددة النطاقات، ودفع أبحاث نظام الأرض نحو رؤى عالمية قابلة للتنفيذ.
شاهد التقرير الكامل:https://go.hyper.ai/djq48
مقالات موسوعية شعبية
1. دال-إي
2. الشبكات الفائقة
3. جبهة باريتو
4. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
5. اندماج الرتب المتبادلة
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي للمؤتمر هو شهر أكتوبر

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1800 مجموعة بيانات عامة
* يتضمن أكثر من 600 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








